
昇腾系列--Qwen2.5-Omni推理调优:vllm-ascend开启全图模式+异步,推理性能提升1.2X倍
本文介绍了Qwen2.5-Omni-7B模型在Atlas800TA2硬件上的环境部署和性能优化过程,推理性能提升为原来的1.2X倍
一、Qwen2.5-Omni-7B环境部署
环境信息:
| vllm | 0.11.0 |
| vllm-ascend |
0.11.0 |
| cann |
8.3.RC2 |
| HDK |
25.2.0 |
| 硬件信息 | Atlas800T A2 |
cann安装包下载:
toolkit:Ascend-cann-toolkit_8.3.RC1_linux-aarch64.run
kernels:Ascend-cann-kernels-910b_8.3.RC2_linux-aarch64.run
nnal:Ascend-cann-nnal_8.3.RC2_linux-aarch64.run
环境搭建以及测试参考:
Qwen2.5-Omni-7B环境搭建及aisbench压测指导
二、Qwen2.5-Omni-7B初始性能测试
vllm服务启动命令:
source /usr/local/Ascend/ascend-toolkit/set_env.sh
source /usr/local/Ascend/nnal/atb/set_env.sh
export VLLM_USE_MODELSCOPE=True
export PYTORCH_NPU_ALLOC_CONF=max_split_size_mb:256
export ASCEND_RT_VISIBLE_DEVICES=0
export VLLM_TORCH_PROFILER_DIR="./vllm_profile"
vllm serve /root/autodl-tmp/Qwen2.5-Omni-7B --host 0.0.0.0 --port 9988 \
--max-model-len 4096 \
--max-num-batched-tokens 4096 \
--max-num-seqs 200 \
--gpu-memory-utilization 0.4 \
--dtype bfloat16 \
--tensor-parallel-size 1 \
--trust-remote-code \
--served-model-name Qwen2.5-Omni-7B \
--block-size 128 \
--allowed-local-media-path /root/Omni-7B/benchmark/ais_bench/datasets/ \
--enable-prefix-caching
aisbench压测命令
ais_bench --models vllm_api_stream_chat --datasets vocalsound_gen --summarizer default_perf --mode perf
压测音频数据集总计608个,每个音频30s时长,16K赫兹,输出文本设置为128,并发设置为10-150,性能压测结果如下:
| 音频输入 | 文本输出 | 并发 | TTFT(ms) | TPOT(ms) |
总输出 (token/s) |
| 时长30s且16K赫兹 | 128 | 10 | 743.8 | 30.15 | 278.67 |
| 时长30s且16K赫兹 | 128 | 20 | 1282.08 | 37.29 | 419.4 |
| 时长30s且16K赫兹 | 128 | 30 | 1335.59 | 46.36 | 522.55 |
| 时长30s且16K赫兹 | 128 | 40 | 1333.17 | 56.96 | 586.64 |
| 时长30s且16K赫兹 | 128 | 50 | 1596.3 | 69.32 | 601.72 |
| 时长30s且16K赫兹 | 128 | 60 | 1660.3 | 79.88 | 635.04 |
| 时长30s且16K赫兹 | 128 | 70 | 1712.55 | 94.33 | 638.91 |
| 时长30s且16K赫兹 | 128 | 80 | 3446.69 | 94.55 | 653.4 |
| 时长30s且16K赫兹 | 128 | 90 | 5295.76 | 95.12 | 648.95 |
| 时长30s且16K赫兹 | 128 | 100 | 7212.57 | 96.12 | 641.22 |
| 时长30s且16K赫兹 | 128 | 110 | 8910.67 | 94.96 | 649.04 |
| 时长30s且16K赫兹 | 128 | 120 | 10634.98 | 94.59 | 652.11 |
| 时长30s且16K赫兹 | 128 | 130 | 12336 | 94.52 | 653.15 |
| 时长30s且16K赫兹 | 128 | 140 | 14191.1 | 95.56 | 646.68 |
| 时长30s且16K赫兹 | 128 | 150 | 15639.27 | 95.02 | 652.62 |
三、性能分析及vllm性能优化参数
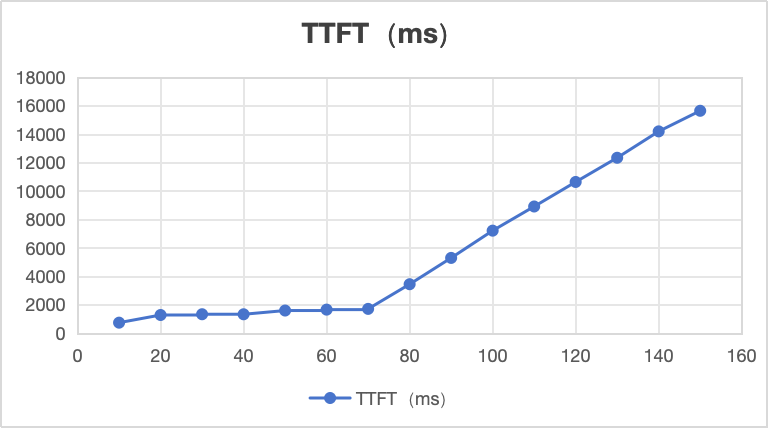
TTFT:首token平均时延,线性图如上:
从上图看,并发到70时,TTFT在2s以内为正常,并发70到150之间,TTFT为线性增长
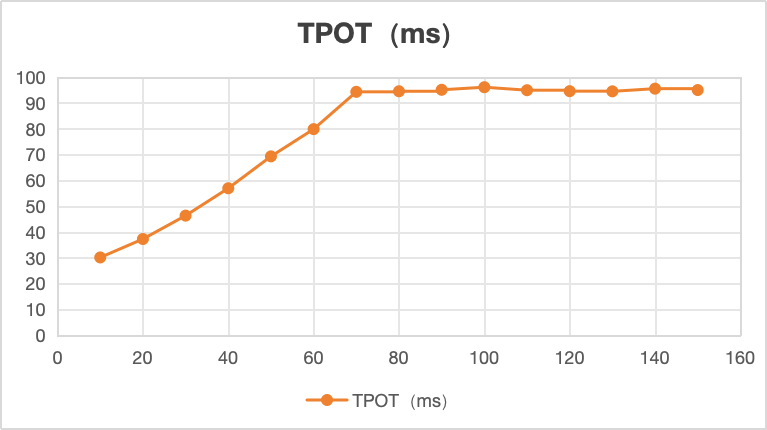
TPOT:解码平均时延,线性图如上:
从上图看,并发70-150时,TPOT平均稳定在90-100ms之间
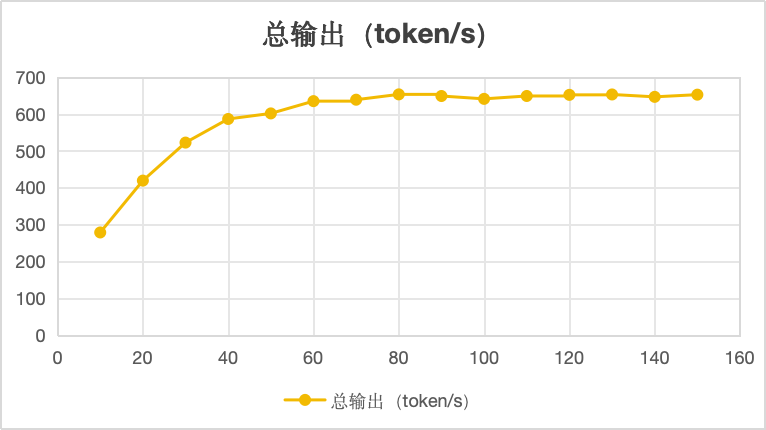
总输出:每秒输出的token数,线性图如上:
从上图看,并发70-150时,总输出稳定在600-650token以内
性能瓶颈分析:并发超过70时,TTFT线性增加,TPOT稳定在90-100ms,总输出token稳定在600-650token以内,所以推理瓶颈卡在TTFT阶段,需要优化TTFT时间
- 全图模式:全图模式CUDA Graph的实现涉及录制和重放机制,减少kernel launch开销和CPU-GPU同步,从而提升推理性能,尤其适用于输入结构固定、反复执行的任务。需要设置vllm启动参数--compilation-config。
- 异步调度:在高并发场景,vLLM 的调度器与推理引擎在不同线程中并行运行,避免了Python GIL(全局解释器锁)对CPU资源的争抢,缩短TTFT的时间。需要设置vllm启动参数--async-scheduling。
- 开启虚拟内存:指示缓存分配器创建特定的内存块分配,这些内存块后续可以扩展,以便能更好地处理内存使用中频繁变更使用内存大小的情况,提高性能。需要设置昇腾环境变量PYTORCH_NPU_ALLOC_CONF。
- AIV通讯特性:通信算法的编排展开位置在Device侧的Vector Core计算单元,多卡推理时参数效果明显,需要设置昇腾环境变量HCCL_OP_EXPANSION_MODE。
四、优化前后性能对比
vllm开启全图模式命令:
source /usr/local/Ascend/ascend-toolkit/set_env.sh
source /usr/local/Ascend/nnal/atb/set_env.sh
export VLLM_USE_MODELSCOPE=True
export PYTORCH_NPU_ALLOC_CONF=max_split_size_mb:256
export ASCEND_RT_VISIBLE_DEVICES=0
export VLLM_TORCH_PROFILER_DIR="./vllm_profile"
export PYTORCH_NPU_ALLOC_CONF="expandable_segments:True"
export HCCL_OP_EXPANSION_MODE="AIV"
export VLLM_USE_V1=1
vllm serve /root/autodl-tmp/Qwen2.5-Omni-7B --host 0.0.0.0 --port 9988 \
--max-model-len 4096 \
--max-num-batched-tokens 4096 \
--max-num-seqs 200 \
--gpu-memory-utilization 0.8 \
--dtype bfloat16 \
--tensor-parallel-size 1 \
--trust-remote-code \
--served-model-name Qwen2.5-Omni-7B \
--block-size 128 \
--async-scheduling \
--compilation-config '{"cudagraph_mode":"FULL_DECODE_ONLY","cudagraph_capture_sizes":[256,248,240,232,224,216,208,200,192,184,176,168,160,152,144,136,128,120,112,104,96
,88,80,72,64,56,48,40,32,24,16,8,4,2,1]}' \
--allowed-local-media-path /root/Omni-7B/benchmark/ais_bench/datasets/ \
--enable-prefix-caching
开启全图模式后,压测音频数据集性能如下:
| 音频输入 | 文本输出 | 并发 | TTFT(ms) | TPOT(ms) |
总输出 (token/s) |
| 时长30s且16K赫兹 | 128 | 10 | 597 | 27.2 | 314.88 |
| 时长30s且16K赫兹 | 128 | 20 | 1221.11 | 32.21 | 476.16 |
| 时长30s且16K赫兹 | 128 | 30 | 1526.54 | 40.57 | 565.44 |
| 时长30s且16K赫兹 | 128 | 40 | 1722.32 | 49.43 | 627.62 |
| 时长30s且16K赫兹 | 128 | 50 | 1900.33 | 61.3 | 647.01 |
| 时长30s且16K赫兹 | 128 | 60 | 2040.23 | 70.37 | 683.66 |
| 时长30s且16K赫兹 | 128 | 70 | 2146.78 | 77.52 | 735.75 |
| 时长30s且16K赫兹 | 128 | 80 | 2285.76 | 85.8 | 762.34 |
| 时长30s且16K赫兹 | 128 | 90 | 2463.65 | 95.19 | 779.41 |
| 时长30s且16K赫兹 | 128 | 100 | 2609.23 | 105.82 | 777.47 |
| 时长30s且16K赫兹 | 128 | 110 | 2792.71 | 113.69 | 797.46 |
| 时长30s且16K赫兹 | 128 | 120 | 3009.71 | 121.93 | 808.49 |
| 时长30s且16K赫兹 | 128 | 130 | 3199.92 | 133.1 | 809.97 |
| 时长30s且16K赫兹 | 128 | 140 | 3458.03 | 142.73 | 806.69 |
| 时长30s且16K赫兹 | 128 | 150 | 3734.11 | 152.91 | 807.79 |
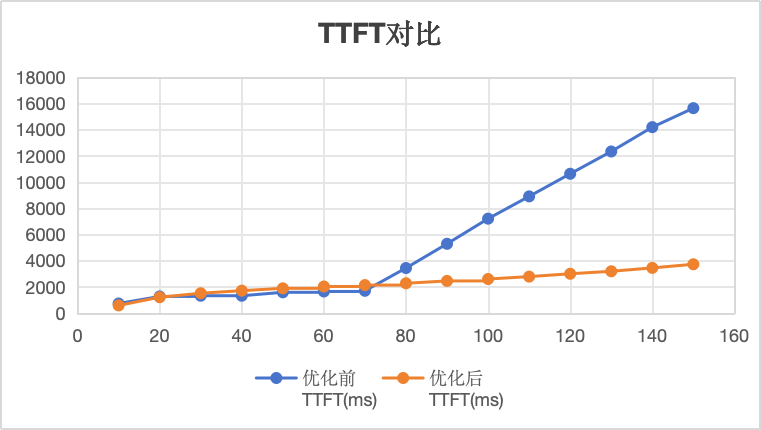
TTFT对比:优化后,并发10-150时,TTFT耗时在4s以内,并缓慢增长。
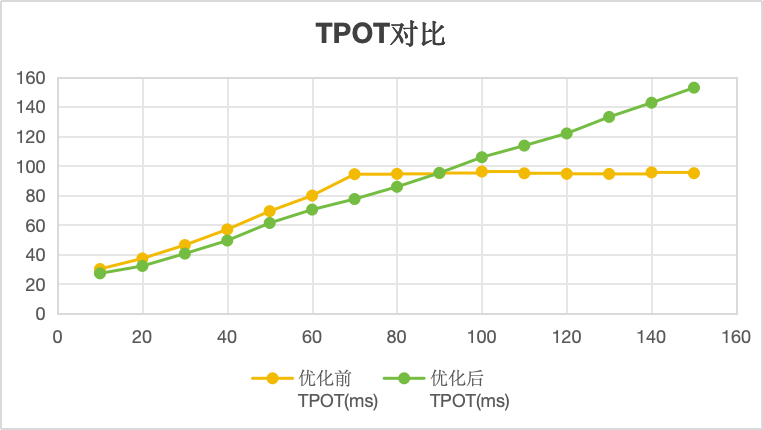
TPOT对比:优化后,并发10-150是,TPOT耗时为线性增长,瓶颈消失。
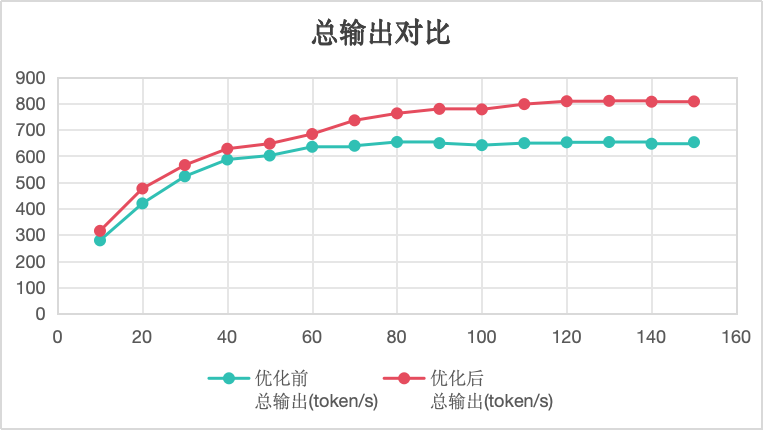
总输出对比:优化后,并发在70-100之间,总输出在缓慢增长中。
| 并发 | 优化前 TTFT(ms) |
优化后 TTFT(ms) |
优化前 TPOT(ms) |
优化后 TPOT(ms) |
优化前 总输出(token/s) |
优化后 总输出(token/s) |
| 10 | 743.8 | 597 | 30.15 | 27.2 | 278.67 | 314.88 |
| 20 | 1282.08 | 1221.11 | 37.29 | 32.21 | 419.4 | 476.16 |
| 30 | 1335.59 | 1526.54 | 46.36 | 40.57 | 522.55 | 565.44 |
| 40 | 1333.17 | 1722.32 | 56.96 | 49.43 | 586.64 | 627.62 |
| 50 | 1596.3 | 1900.33 | 69.32 | 61.3 | 601.72 | 647.01 |
| 60 | 1660.3 | 2040.23 | 79.88 | 70.37 | 635.04 | 683.66 |
| 70 | 1712.55 | 2146.78 | 94.33 | 77.52 | 638.91 | 735.75 |
| 80 | 3446.69 | 2285.76 | 94.55 | 85.8 | 653.4 | 762.34 |
| 90 | 5295.76 | 2463.65 | 95.12 | 95.19 | 648.95 | 779.41 |
| 100 | 7212.57 | 2609.23 | 96.12 | 105.82 | 641.22 | 777.47 |
| 110 | 8910.67 | 2792.71 | 94.96 | 113.69 | 649.04 | 797.46 |
| 120 | 10634.98 | 3009.71 | 94.59 | 121.93 | 652.11 | 808.49 |
| 130 | 12336 | 3199.92 | 94.52 | 133.1 | 653.15 | 809.97 |
| 140 | 14191.1 | 3458.03 | 95.56 | 142.73 | 646.68 | 806.69 |
| 150 | 15639.27 | 3734.11 | 95.02 | 152.91 | 652.62 | 807.79 |
限定TTFT时间在3s以内,TPOT小于100ms时:
- 优化前支持70并发,总输出为638.91token/s
- 优化后支持90并发,总输出为779.41token/s
- 优化后并发为原来的1.28倍,总输出为原来1.21倍

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐
 37
37 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)