
【昇腾CANN训练营·架构篇】打破内存墙:Ascend C 算子融合(Operator Fusion)的极致心法
摘要:本文深入解析昇腾AI芯片中的UBFusion算子融合技术,通过将多个小算子融合为一个大算子,实现"一次搬运,多次计算"的性能优化。文章对比了标准流水线与融合流水线的差异,详细介绍了AscendC中的两种融合范式:Vector链式融合和Cube+Vector异构融合,并探讨了内存复用和指令并行等优化技巧。该技术能显著降低HBM带宽压力,充分发挥昇腾芯片的算力优势,是提升AI
训练营简介
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro

摘要:在 AI 芯片的性能公式中,计算是廉价的,搬运是昂贵的。昇腾 910B 的算力高达数百 TFLOPS,但 HBM 带宽却相对有限。如果让 AI Core 频繁地从 HBM 读取中间结果,性能将呈断崖式下跌。本文将深入解析 UB Fusion(UB 融合) 机制,探讨如何通过 Ascend C 将多个小算子“捏”成一个大算子,实现“一次搬运,多次计算”的极致性能。
前言:AI Core 的“进食焦虑”
我们可以把 AI Core 想象成一个每秒能吃掉 100 个馒头的大胃王(高算力),而 HBM(Global Memory) 是远在 10 公里外的粮仓。MTE(搬运引擎) 是负责送餐的快递员。
在非融合模式下(比如 PyTorch 默认模式):
-
算
C = A + B:快递员把 A、B 搬来,大胃王吃完,快递员把结果 C 送回粮仓。 -
算
D = ReLU(C):快递员再去粮仓把 C 搬回来,大胃王吃完,把 D 送回粮仓。
你会发现,大胃王大部分时间都在等快递。中间结果 C 明明刚算出来还在嘴边(UB),为什么要吐出来送回粮仓,等会儿再搬回来?
算子融合(Operator Fusion) 的核心就是:让结果 C 留在 UB(Unified Buffer) 里,接着算 ReLU,最后只把 D 送回粮仓。
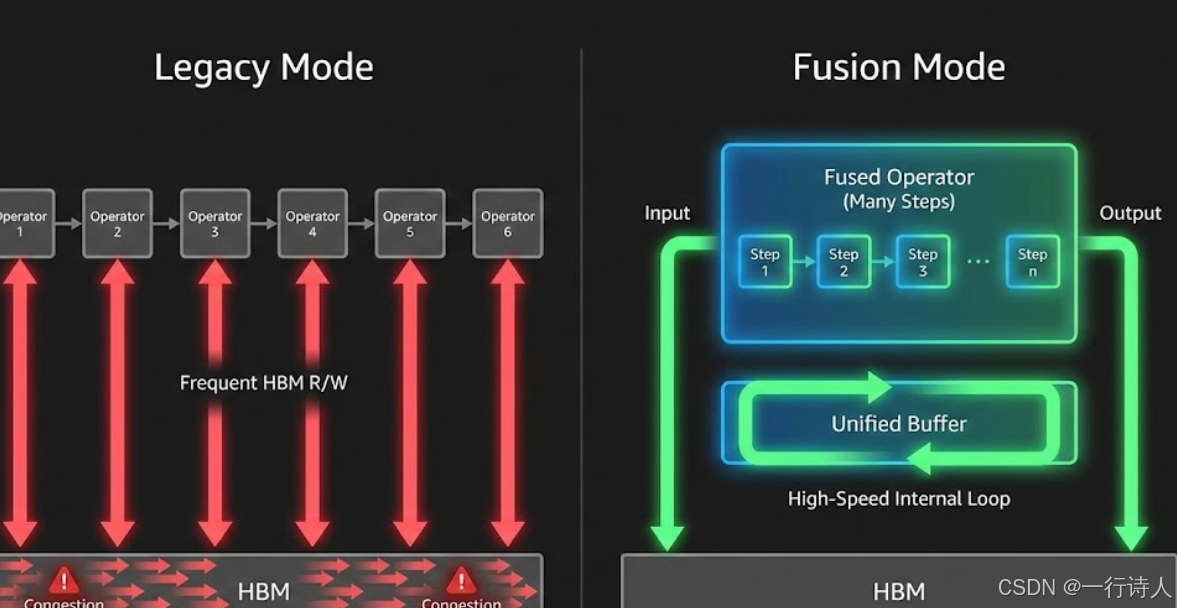
一、 核心图解:UB——达芬奇架构的“熔炉”
在 Da Vinci 架构中,UB (Unified Buffer) 不仅仅是缓存,它是所有 Vector 计算指令的唯一操作数来源。这使得它成为了天然的算子融合场所。
-
Standard Pipeline:
GM -> UB -> ALU -> UB -> GM(反复多次) -
Fused Pipeline:
GM -> UB -> ALU -> UB -> ALU -> UB -> ... -> GM(IO 只有一进一出)
通过融合,我们将 $N$ 次读写降低为 $1$ 次读写,带宽利用率提升 $N$ 倍。
二、 实战:Ascend C 中的融合范式
在 Ascend C 中实现融合,本质上就是在一个 Kernel 函数里连续调用多个 Compute API,而不进行额外的 CopyOut 和 CopyIn。
2.1 范式一:Vector 链式融合 (Elewise + Elewise)
这是最常见、最简单的融合。例如 Sigmoid = 1 / (1 + Exp(-x))。
错误写法(伪融合): 分别调用 Exp Kernel、Add Kernel、Div Kernel。这依然是多次启动。
正确写法(真融合):
// 假设 xLocal 已经在 UB 中
// 1. Exp
Exp(tmpLocal, xLocal, tileLen);
// 2. Add (利用 Muls 实现 +1)
Adds(tmpLocal, tmpLocal, 1.0h, tileLen);
// 3. Reciprocal (求倒数)
// 此时 tmpLocal 还在 UB 里,直接复用!
Div(yLocal, onesLocal, tmpLocal, tileLen);
// 最后才 CopyOut yLocal
深度思考:这种融合的瓶颈在哪里? 在于 UB 容量。如果算子链太长,中间变量太多,可能会导致 UB 放不下(Register Spilling),被迫切分更小的 Tile,反而降低并行度。
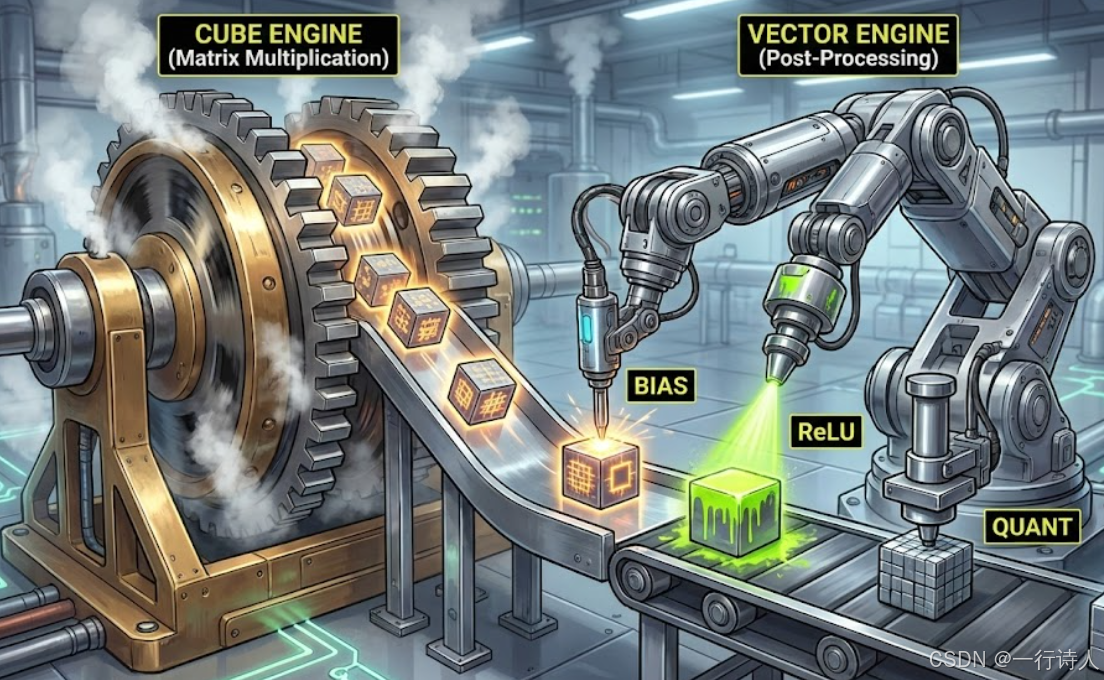
2.2 范式二:Cube + Vector 异构融合 (MatMul + Bias + ReLU)
这是昇腾架构的杀手锏。Cube 算完的结果(L0C)可以直接搬到 UB,这就给了 Vector 介入的机会。
// 定义 Matmul 对象
MatmulObj mm;
mm.SetTensorA(gm_a);
mm.SetTensorB(gm_b);
// 迭代计算
while (mm.Iterate()) {
// 1. 获取 Cube 计算结果到 UB
// 此时数据从 L0C -> UB,格式通常为 Fractal NZ
mm.GetTensorC(ub_c);
// 2. Vector 介入:加 Bias
// 注意:Vector 计算通常需要 ND 格式,或者支持特定格式的加法
// Ascend C 提供了专门的 Axpy 接口或支持 NZ 格式的 Add
Add(ub_c, ub_c, ub_bias, ...);
// 3. Vector 介入:ReLU 激活
Relu(ub_c, ub_c, ...);
// 4. Vector 介入:量化 (Quantization)
// float16 -> int8,节省带宽
Cast(ub_quant, ub_c, RoundMode::CAST_ROUND, ...);
// 5. 最后再一次性搬回 GM
DataCopy(gm_result, ub_quant, ...);
}
这种模式将 Compute-Bound(Cube 密集计算)和 Memory-Bound(Vector 激活/量化)完美结合,掩盖了 Vector 的开销。
三、 进阶:Scope Memory 的复用艺术
在复杂的融合算子中(比如 FlashAttention 或 RMSNorm),我们需要在 UB 中存放很多临时变量(Temp Buffer)。 如果每个变量都 AllocTensor,UB 很快就炸了。
Ascend C 优化技巧:内存复用(Memory Reuse) 由于 TQue 是基于 Pool 管理的,我们可以利用 生命周期互斥 的特性。
{
LocalTensor t1 = que1.AllocTensor();
Exp(t1, ...);
// t1 使用完毕,不再需要
que1.FreeTensor(t1);
}
{
// 此时申请 t2,系统会自动复用刚才 t1 占用的物理内存地址!
LocalTensor t2 = que1.AllocTensor();
Log(t2, ...);
}
通过控制作用域(Scope)或手动 Free,我们可以在有限的 256KB UB 里,跑出极其复杂的算法逻辑。
四、 挑战:指令并行的破坏
融合虽然好,但也有副作用。 在“非融合”模式下,Cube 算 MatMul 时,Vector 可能在算另一个算子的 ReLU,这是 Task-Level Parallelism。 一旦融合到一个 Kernel 里,如果没有精细的流水线编排(如 Double Buffer),很容易变成:Cube 算 -> Vector 算 -> Cube 算。
解决方案: 依然是 Ping-Pong。 当 Block i 在 Vector 进行 ReLU 时,Block i+1 应该已经在 Cube 里进行 MatMul 了。这需要极高超的代码编排能力(参考第 10 期双缓冲文章)。
五、 总结
算子融合是 Ascend C 开发从“入门”到“精通”的必修课。
-
少搬运:每一次
DataCopy都是在向性能妥协。 -
多驻留:让数据尽可能久地停留在 UB 甚至 L0 寄存器中。
-
看整体:不要只盯着某一步计算,要从整个子图(Subgraph)的视角审视数据流向。
当你能够看着一个复杂的 Transformer Block,脑海中自动将其拆解为 MatMul+Bias+Swish 和 Add+LayerNorm 两个超级融合算子时,你就掌握了达芬奇架构的性能密码。
本文基于昇腾 CANN 8.0 架构特性编写。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 22
22 0
0- 0



 已为社区贡献46条内容
已为社区贡献46条内容

所有评论(0)