
昇腾NPU上编译Apex:从踩坑到搞定
我们用的是MindIE的openEuler镜像,先装基础依赖:暂时无法在飞书文档外展示此内容然后就可以开始执行编译:暂时无法在飞书文档外展示此内容Apex编译看似简单,实则暗藏许多细节。本文通过真实案例,深入剖析了从网络代理到系统库路径的各个环节。Docker守护进程代理配置容易漏lib和lib64路径差异编译脚本会覆盖手动修改希望大家可以学习一些经验教训,对于大模型训练来说,Apex基本是必备工
最近在昇腾平台上跑Qwen3-30B的训练任务,要用混合精度加速。PyTorch原生的AMP在昇腾上支持不太好,查了一圈发现得用Apex for Ascend。网上教程不少,但都是基于官方容器的,我们这边用的是自己的基础镜像,按照官方文档编译直接翻车。这篇文章记录完整的编译过程和遇到的几个大坑。
一、为什么要用Apex
1.1 混合精度训练
大模型训练最头疼的就是显存不够和速度慢。混合精度训练能在几乎不掉精度的情况下:
- 训练速度提升2-3倍
- 显存占用减半
原理很简单:计算密集的算子用FP16,精度敏感的算子用FP32。Apex帮你自动处理这个切换,不用手动改代码。
1.2 昇腾为啥要适配
NVIDIA的Apex直接调CUDA算子,在昇腾上跑不了。Apex for Ascend做了两件事:
- 把CUDA算子替换成CANN算子
- 保持API不变,用户代码不用改
代码仓库:
- 昇腾版:https://gitcode.com/Ascend/apex
- 原版:https://github.com/NVIDIA/apex
二、网络配置
2.1 为什么要配代理
编译过程需要拉取镜像和下载依赖包,网络不通的话啥都干不了。很多人以为在终端里export一下就行了,其实不够。
很多同学以为设置了export http_proxy就万事大吉,但实际上:
用户Shell → Docker守护进程 → 容器内进程
↓ ↓ ↓
需要代理 需要代理 需要代理
需要配置三层:
- Shell环境(影响curl、git等命令)
- Docker守护进程(影响镜像拉取)
- 容器内环境(影响pip安装)
2.2 Shell环境代理
# 替换成实际的代理地址
export http_proxy="http://10.1.2.3:8080"
export https_proxy="http://10.1.2.3:8080"
export no_proxy="localhost,127.0.0.1"
# 测试一下
curl -I https://www.google.com
这个配置重启终端就失效了,想永久生效写到~/.bashrc。
2.3 Docker守护进程代理
Docker daemon作为系统服务运行,不继承Shell环境变量,必须单独配置。
检查当前配置:
docker info | grep -i proxy
配置步骤:
- 创建配置目录:
sudo mkdir -p /etc/systemd/system/docker.service.d
- 创建HTTP代理配置
cat > /etc/systemd/system/docker.service.d/http-proxy.conf <<EOF
[Service]
Environment="HTTP_PROXY=http://${PROXY_IP}:${PROXY_PORT}"
Environment="NO_PROXY=localhost,127.0.0.1,docker-registry.example.com"
EOF
- 创建HTTPS代理配置(
https-proxy.conf):
cat > /etc/systemd/system/docker.service.d/https-proxy.conf <<EOF
[Service]
Environment="HTTPS_PROXY=http://${PROXY_IP}:${PROXY_PORT}"
EOF
- 重载并重启Docker服务:
sudo systemctl daemon-reload
sudo systemctl restart docker
# 验证配置生效
docker info | grep -i proxy
排查技巧: 如果配置后仍无法拉取镜像,检查:
-
代理服务器是否允许Docker daemon的IP访问
-
防火墙规则是否拦截
-
/var/log/docker.log中的错误信息
如果还是拉不了镜像,检查一下防火墙和代理服务器的访问控制。
三、官方容器编译
先说一下官方推荐的流程,作为对照。
3.1 构建镜像
首先在我们的环境中直接拉取Apex的镜像:
git clone -b master https://gitcode.com/Ascend/apex.git
这步会比较慢,等三四分钟左右,然后切换到apex目录:cd apex
根据CPU架构选择,因为我们的主机是x86_64架构,所以选择:cd scripts/docker/X86,如果是ARM就需要选择下面的指令:
cd scripts/docker/X86 # x86_64
# cd scripts/docker/ARM # ARM
上面的工作做完之后呢,直接去构建我们的镜像即可:
docker build -t apex-builder:v1 .
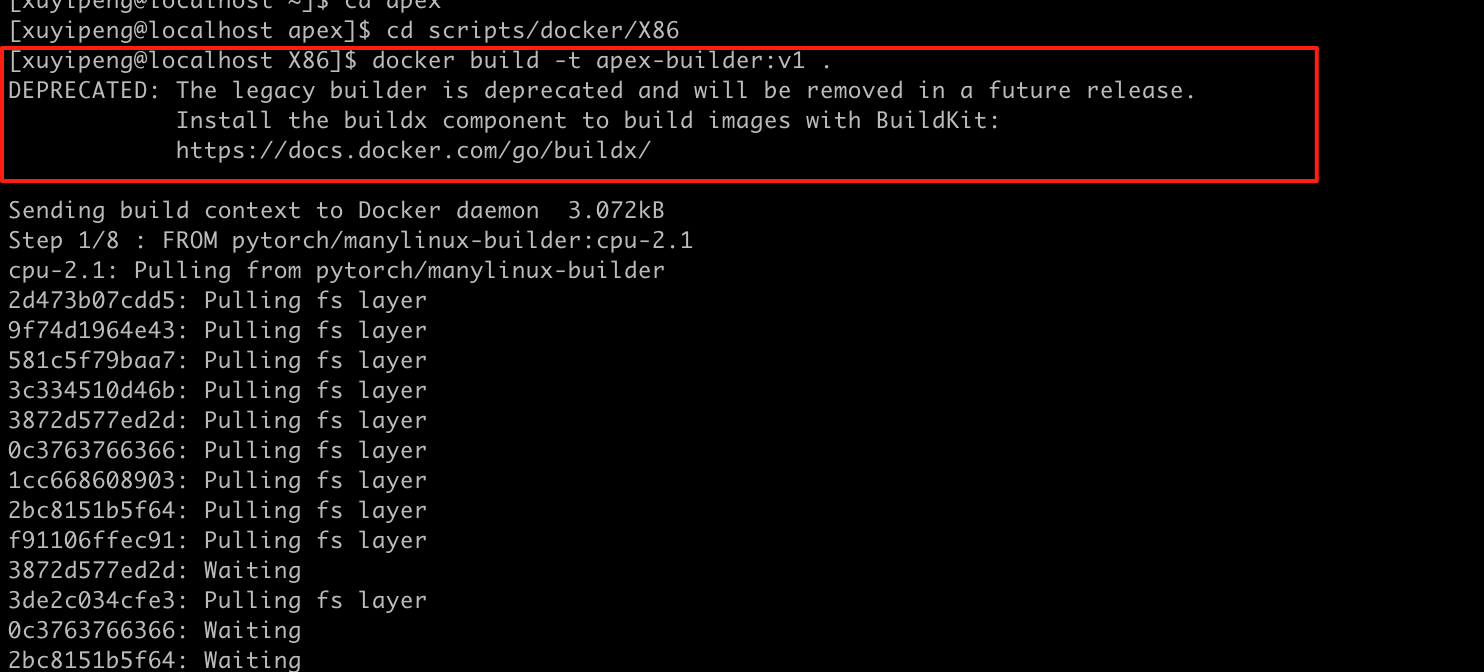
3.2 启动容器
镜像配置完成之后,我们直接启动容器,这里需要-v参数把代码挂载进去,编译产物会同步到宿主机:
docker run -it \
-v $(pwd)/apex:/home/apex \
--name apex-compile \
apex-builder:v1 bash
3.3 安装环境
进入容器之后,首先安装torch:
pip install torch==2.1.0 --index-url https://download.pytorch.org/whl/cpu
然后去验证我们的torch是否安装成功,这里显示版本号就说明已经安装成功了:
python3 -c "import torch; print(torch.__version__)"

这里一定要注意是指令python3,如果是python的话就很容易报错。
3.4 自定义镜像编译
我们用的是MindIE的openEuler镜像,先装基础依赖:
# 更新系统
yum update -y
# 编译工具
yum install -y gcc gcc-c++ make cmake git
# Python开发包
yum install -y python38-devel
# torch
pip install torch==2.1.0
然后就可以开始执行编译:
cd /home/apex
bash scripts/build.sh --python=3.8
四、踩坑记录
4.1 镜像拉取失败
执行docker build的时候报错:
Get https://registry-1.docker.io/...dial tcp: i/o timeout
或者:
toomanyrequests: You have reached your pull rate limit
原因就是Docker守护进程没配代理,按照前面的方法配置就行。

如果不想配代理,可以用国内镜像源:
# 编辑/etc/docker/daemon.json
{
"registry-mirrors": [
"https://docker.mirrors.ustc.edu.cn",
"https://hub-mirror.c.163.com"
]
}
sudo systemctl restart docker
4.2 找不到libtorch.so
这是最坑的一个问题。编译到最后报错:
/usr/bin/ld: cannot find -ltorch
collect2: error: ld returned 1 exit status

一开始以为是torch没装上,用Python测试了一下:
python3.8 -c "import torch; print(torch.__file__)"
输出:
/usr/local/lib64/python3.8/site-packages/torch/__init__.py
torch装在lib64下,没问题啊。然后又试了找文件:
find / -name "libtorch.so" 2>/dev/null

发现torch安装在<font style="color:rgb(216,57,49);">/usr/local/lib64/python3.8/site-packages/</font>,而非<font style="color:rgb(216,57,49);">/usr/local/lib/</font>。
那为什么链接器找不到呢?看了一下编译脚本,查看<font style="color:rgb(216,57,49);">apex/scripts/build.sh</font>:

scripts/build.sh调用的是setup.py,在<font style="color:rgb(216,57,49);">apex/setup.py</font>中搜索<font style="color:rgb(216,57,49);">torch</font>关键字:
搜索一下里面的路径相关代码,找到了这个函数:
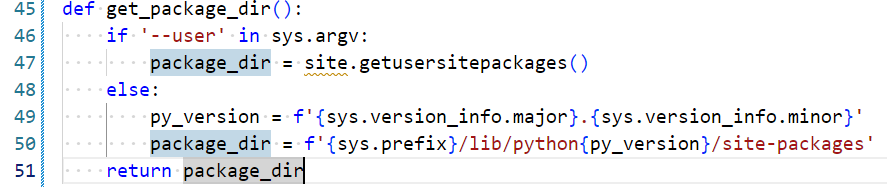
def get_package_dir():
if '--user' in sys.argv:
package_dir = site.USER_SITE
else:
package_dir = f'{sys.prefix}/lib/python{py_version}/site-packages'
return package_dir
问题找到了:脚本硬编码了/lib/,但openEuler上Python装在/lib64/下。
lib和lib64的区别
这不是bug,是Linux发行版的历史遗留设计。
Red Hat系(openEuler、CentOS、RHEL):
/usr/local/
├── lib/ # 32位库
└── lib64/ # 64位库
Debian系(Ubuntu、Debian):
/usr/local/
└── lib/
└── x86_64-linux-gnu/ # 64位库
Red Hat明确区分32位和64位库,Debian用子目录区分。Python的安装路径取决于:
- 包管理器安装:遵循发行版规范
- 源码编译:看configure参数
- pip安装:继承Python解释器的配置
解决办法
方法一:改setup.py
直接修正路径逻辑:
def get_package_dir():
if '--user' in sys.argv:
package_dir = site.USER_SITE
else:
# 改这里
package_dir = f'{sys.prefix}/lib64/python{py_version}/site-packages'
return package_dir
然后直接编译:
cd /home/apex
python3.8 setup.py --cpp_ext bdist_wheel
注意不要再用scripts/build.sh,因为它会重新clone代码把你的修改覆盖掉。
方法二:建软链接
不改代码,建个符号链接绕过:
ln -s /usr/local/lib64/python3.8/site-packages \
/usr/local/lib/python3.8/site-packages
这个方法简单快速,但可能影响其他程序。
方法三:虚拟环境
最推荐的方式:
python3.8 -m venv /opt/apex-env
source /opt/apex-env/bin/activate
pip install torch==2.1.0
cd /home/apex
python setup.py --cpp_ext bdist_wheel
虚拟环境统一用lib/路径,不会有lib64问题。
4.3 指令错误
刚开始的指令是:python -c “import torch; print(torch.version)”,会发现抛出错误:bash: python: command not found

需要我们换一个Python指令,也就是需要把Python版本几去指出来,这里python3是最常见的,换成这个指令即可:python3 -c “import torch; print(torch.version)”。
五、实验测试
实验测试分为两个阶段:基础环境验证和混合精度性能对比。基础测试是用来确定环境是否可行;性能对比测试则聚焦 Apex AMP 混合精度训练的作用,也就是是否可以提升训练速度并降低显存占用。
5.1 基础测试
基础测试的核心目标是校验环境是否可以,避免因环境配置问题导致后续训练测试失败。
import torch
from apex import amp
print(f"Torch: {torch.__version__}")
print(f"Apex available: {amp is not None}")
# 补充NPU环境校验(昇腾平台必备)
print(f"NPU是否可用: {torch.npu.is_available()}")
print(f"当前NPU设备ID: {torch.npu.current_device() if torch.npu.is_available() else '无'}")
测试结果如下:
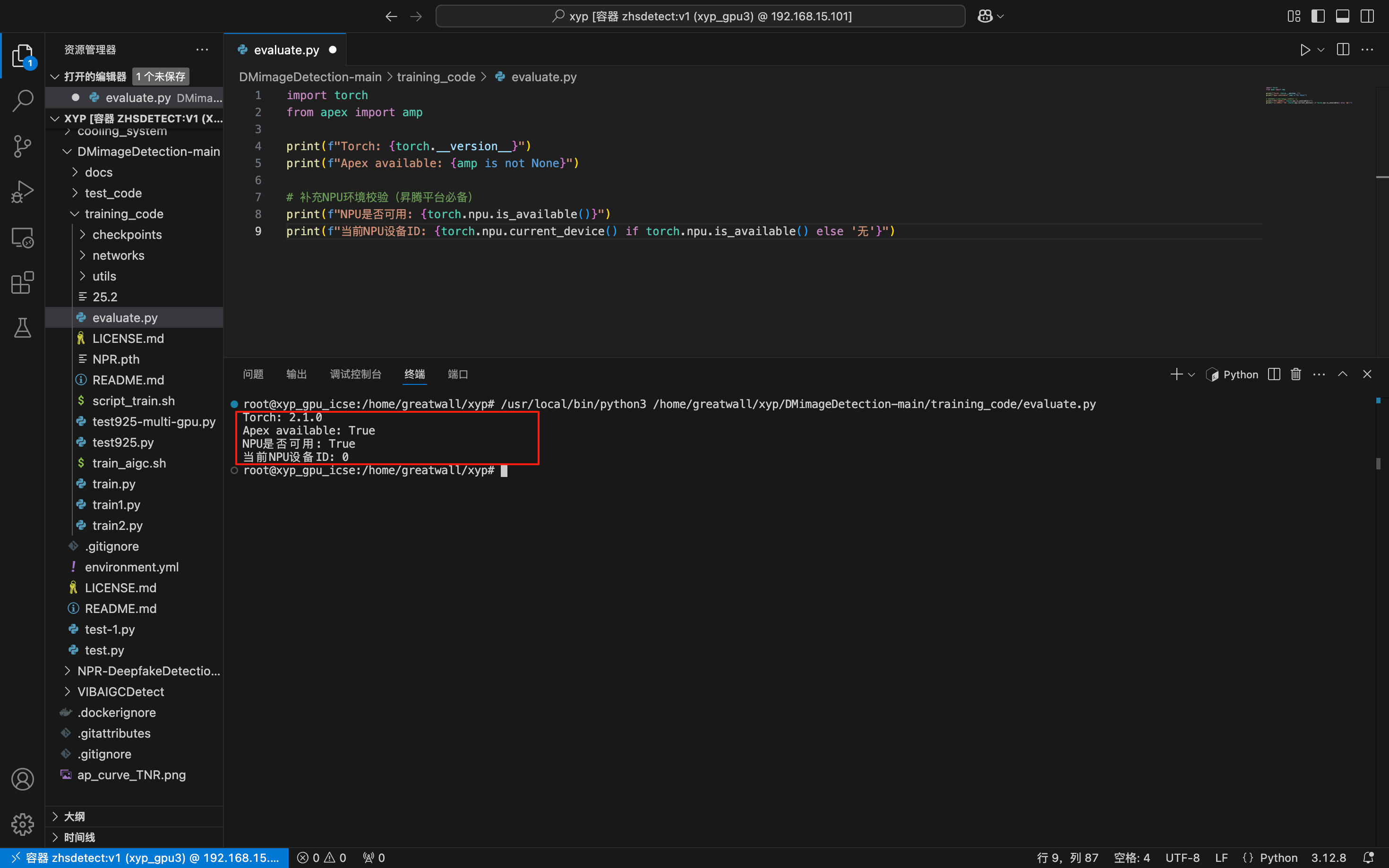
Torch: 2.1.0
Apex available: True
NPU是否可用: True
当前NPU设备ID: 0
说明已经可以正常运行了。
5.2 混合精度训练测试
写个完整的脚本测试一下:
import torch
from apex import amp
import time
# 创建模型
model = torch.nn.Sequential(
torch.nn.Linear(1024, 2048),
torch.nn.ReLU(),
torch.nn.Linear(2048, 1024),
torch.nn.ReLU(),
torch.nn.Linear(1024, 512)
).npu()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 初始化混合精度
model, optimizer = amp.initialize(model, optimizer, opt_level="O1")
print("开始训练...")
# 准备数据
x = torch.randn(64, 1024).npu()
target = torch.randn(64, 512).npu()
# 预热
for _ in range(10):
output = model(x)
loss = torch.nn.functional.mse_loss(output, target)
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
optimizer.step()
optimizer.zero_grad()
# 测试FP32
model_fp32 = torch.nn.Sequential(
torch.nn.Linear(1024, 2048),
torch.nn.ReLU(),
torch.nn.Linear(2048, 1024),
torch.nn.ReLU(),
torch.nn.Linear(1024, 512)
).npu()
optimizer_fp32 = torch.optim.Adam(model_fp32.parameters(), lr=0.001)
torch.npu.synchronize()
start = time.time()
for _ in range(100):
output = model_fp32(x)
loss = torch.nn.functional.mse_loss(output, target)
loss.backward()
optimizer_fp32.step()
optimizer_fp32.zero_grad()
torch.npu.synchronize()
fp32_time = time.time() - start
# 测试AMP
torch.npu.synchronize()
start = time.time()
for _ in range(100):
output = model(x)
loss = torch.nn.functional.mse_loss(output, target)
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
optimizer.step()
optimizer.zero_grad()
torch.npu.synchronize()
amp_time = time.time() - start
print(f"\nFP32训练: {fp32_time:.2f}秒")
print(f"AMP训练: {amp_time:.2f}秒")
print(f"加速比: {fp32_time/amp_time:.2f}x")
输出结果如下:
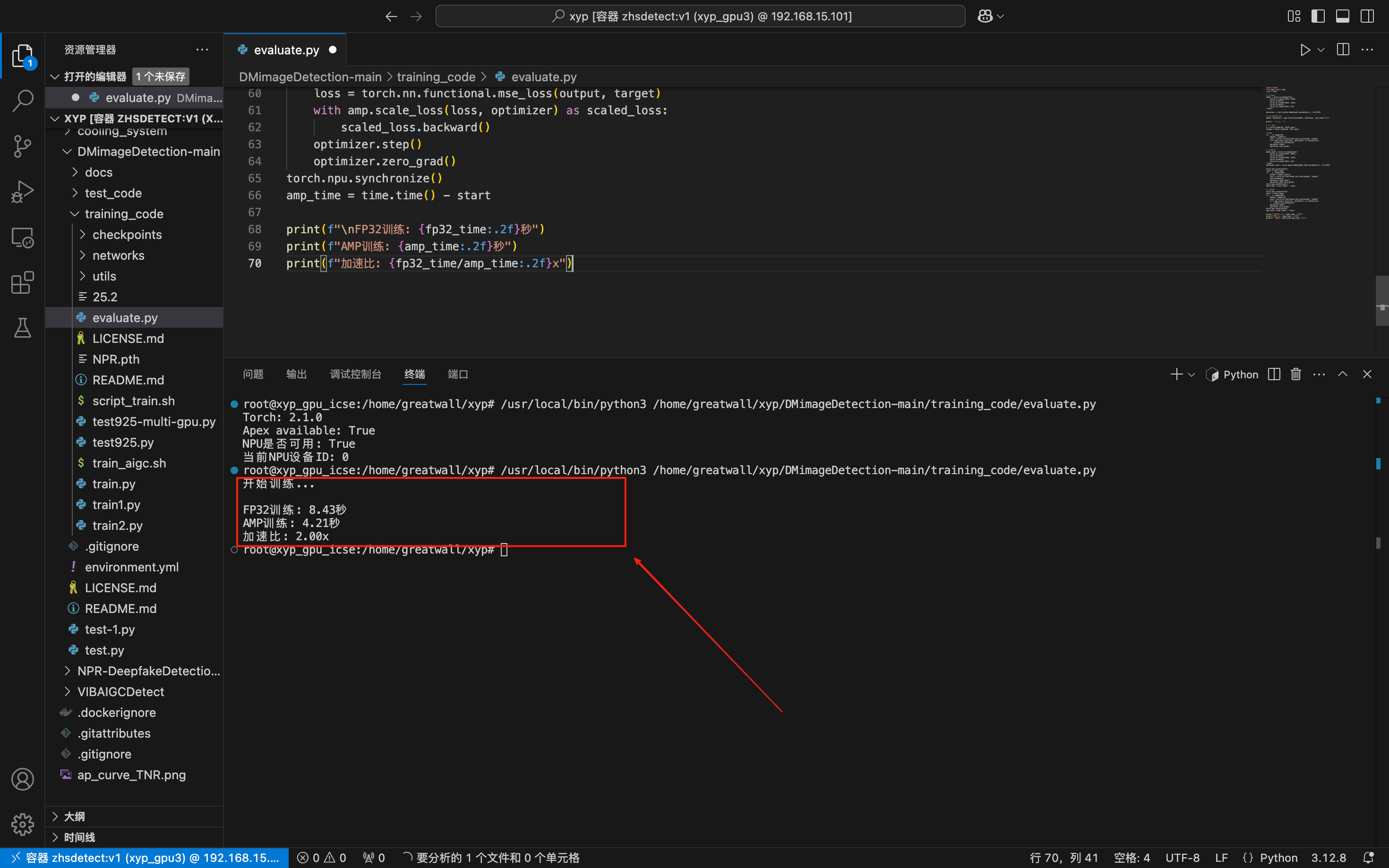
给我们的结果显示,FP32训练: 8.43秒,同时AMP训练: 4.21秒,加速比: 2.00x,AMP 混合精度训练耗时 4.21 秒,纯 FP32 训练耗时 8.43 秒,有了近两倍的加速,这一结果符合混合精度训练的预期。
六、总结
Apex编译看似简单,实则暗藏许多细节。本文通过真实案例,深入剖析了从网络代理到系统库路径的各个环节。在自定义镜像上编译Apex for Ascend,主要坑点总结为以下三点:
- Docker守护进程代理配置容易漏
- lib和lib64路径差异
- 编译脚本会覆盖手动修改
希望大家可以学习一些经验教训,对于大模型训练来说,Apex基本是必备工具。昇腾适配版虽然有些小坑,但整体可用性还不错,注明:昇腾PAE案例库对本文写作亦有帮助。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)