
昇腾系列--vllm框架性能分析:获取vllm-ascend推理性能数据,通过MindStudio Insight工具分析模型推理的性能瓶颈
本文介绍了vllm-ascend性能数据采集与分析流程。基于Atlas800T A2搭建环境,并采集vllm服务的性能数据,通过MindStudio Insight工具分析性能数据,包括查看总耗时、函数执行时间、CANN调用关系及算子耗时等。
一、抓取vllm-ascend性能数据
环境搭建参考:基于Atlas800T A2 搭建vllm服务推理环境
vllm采集环境变量设置
export VLLM_TORCH_PROFILER_DIR="./vllm_profile"
vllm serve服务启动命令
source /usr/local/Ascend/ascend-toolkit/set_env.sh
source /usr/local/Ascend/nnal/atb/set_env.sh
export VLLM_USE_MODELSCOPE=True
export PYTORCH_NPU_ALLOC_CONF=max_split_size_mb:256
export ASCEND_RT_VISIBLE_DEVICES=0
export VLLM_TORCH_PROFILER_DIR="./vllm_profile"
vllm serve /root/autodl-tmp/Qwen2.5-Omni-7B --host 0.0.0.0 --port 9988 \
--max-model-len 4096 \
--max-num-batched-tokens 4096 \
--max-num-seqs 100 \
--gpu-memory-utilization 0.4 \
--dtype bfloat16 \
--tensor-parallel-size 1 \
--trust-remote-code \
--served-model-name Qwen2.5-Omni-7B \
--block-size 128 \
--allowed-local-media-path /root/Omni-7B/benchmark/ais_bench/datasets/ \
--enable-prefix-caching
发送采集请求
curl -X POST http://0.0.0.0:9988/start_profile
开启ais_bench测试
ais_bench --models vllm_api_stream_chat --datasets vocalsound_gen --summarizer default_perf --mode perf
发送停止采集请求
curl -X POST http://0.0.0.0:9988/stop_profile
解析数据
import torch_npu
import torch
from torch_npu.profiler.profiler import analyse
analyse(profiler_path="./vllm_profile/")
查看性能采集数据
ls -rtl vllm_profile/autodl-container-xxxx_ascend_pt

二、分析vllm-ascend性能数据
MindStudio Insight安装包下载
mac 安装包:MindStudio-Insight_8.2.RC1_darwin-x86_64.dmg
windows安装包:MindStudio-Insight_8.2.RC1_win.exe
linux安装包:MindStudio-Insight_8.2.RC1_linux-x86_64.zip
MindStudio Insight快捷键

加载采集性能数据
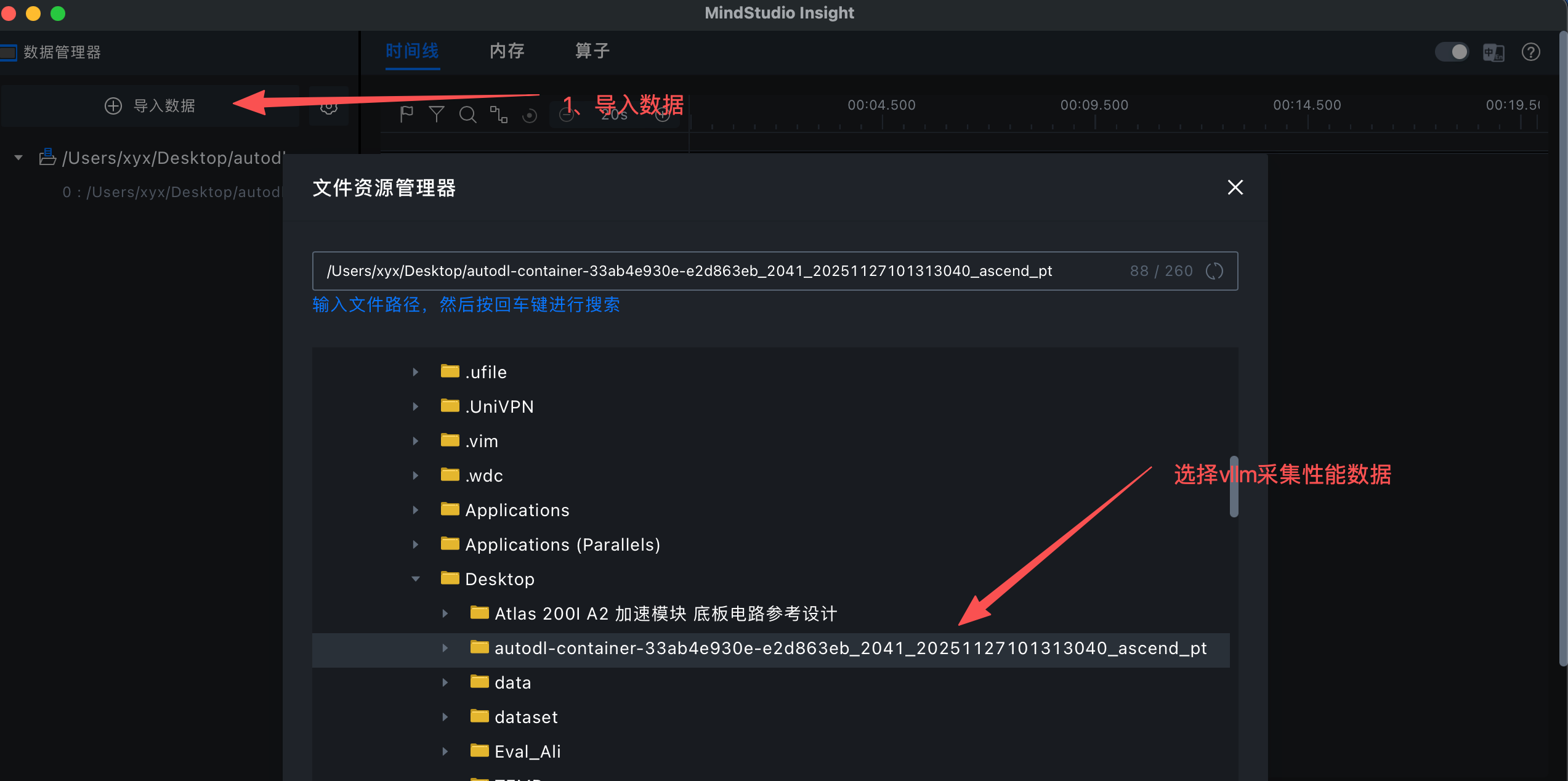
查看总时间耗时
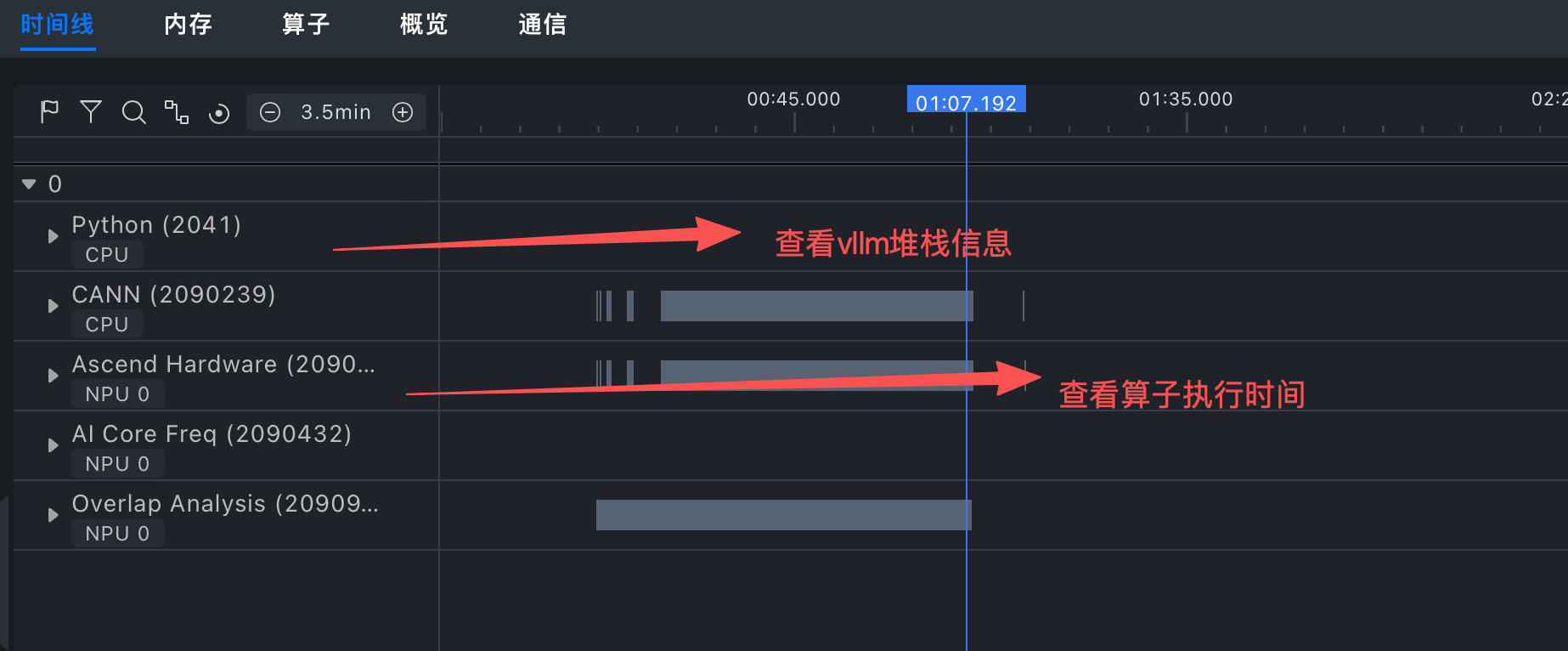
查看vllm堆栈
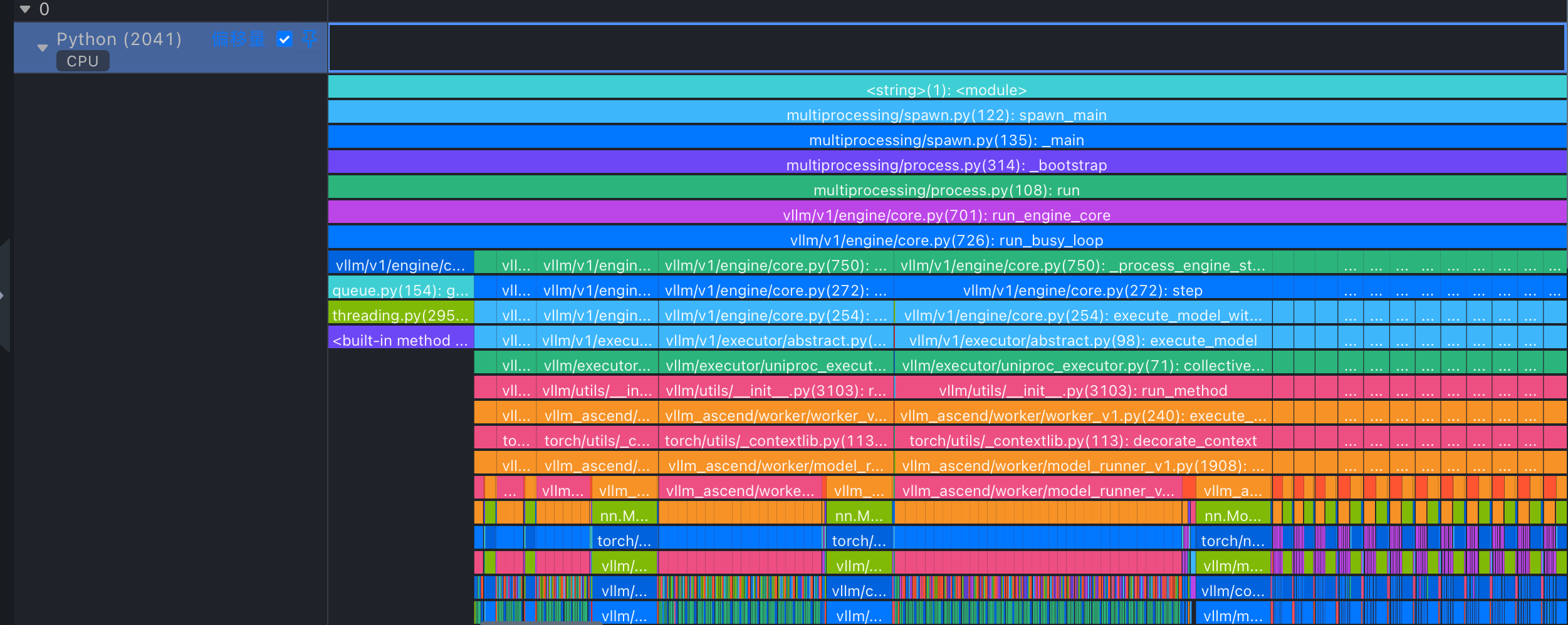
放大(w快捷键)可以看每个函数执行时间
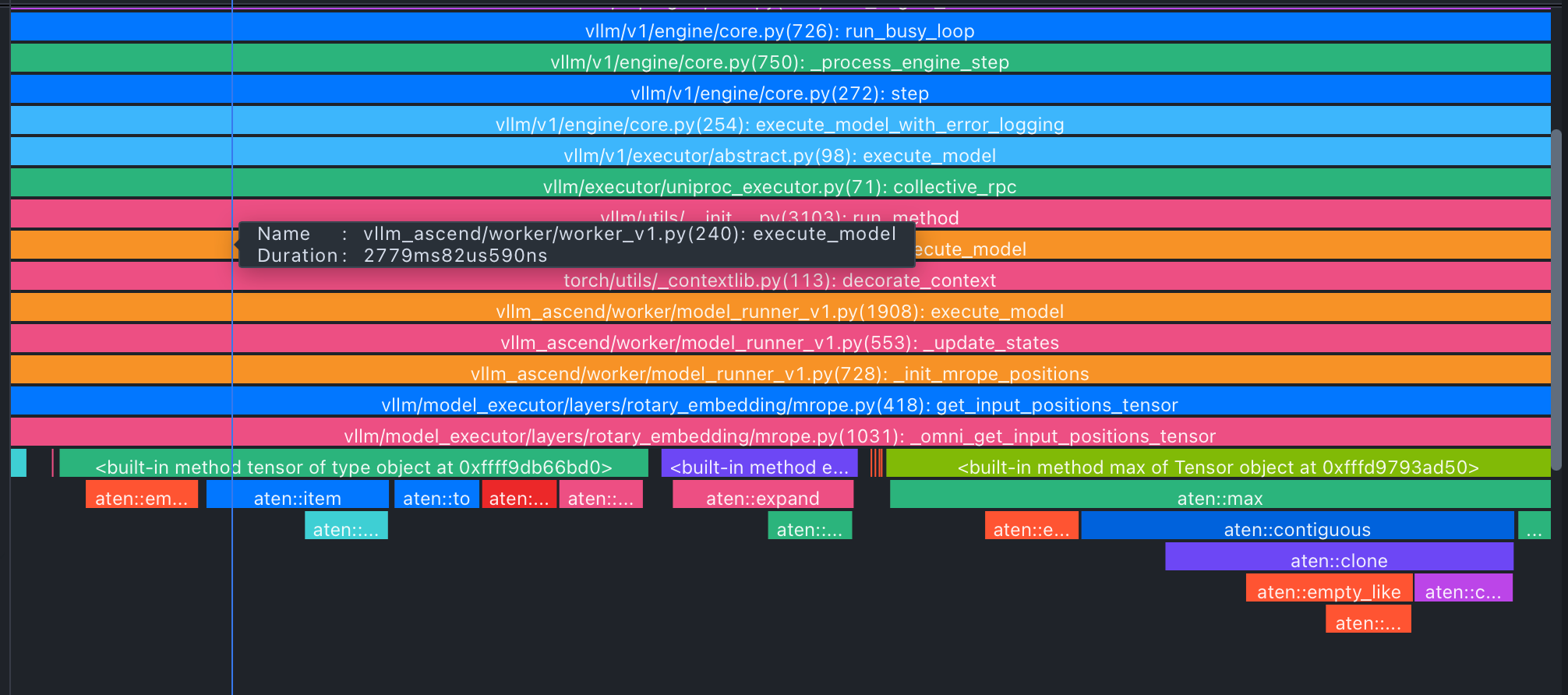
查看cann调用和算子关系
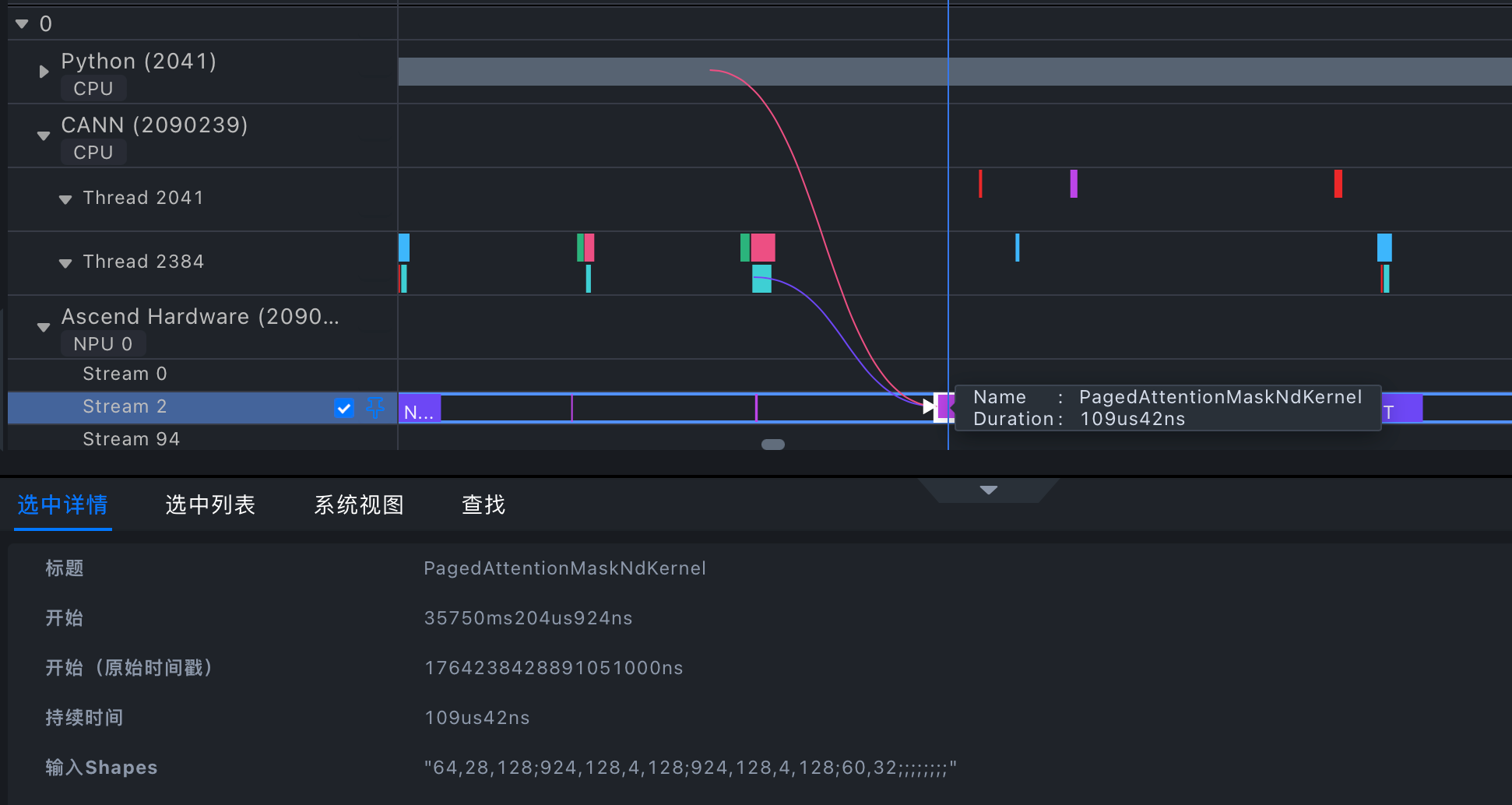
查看算子执行时间
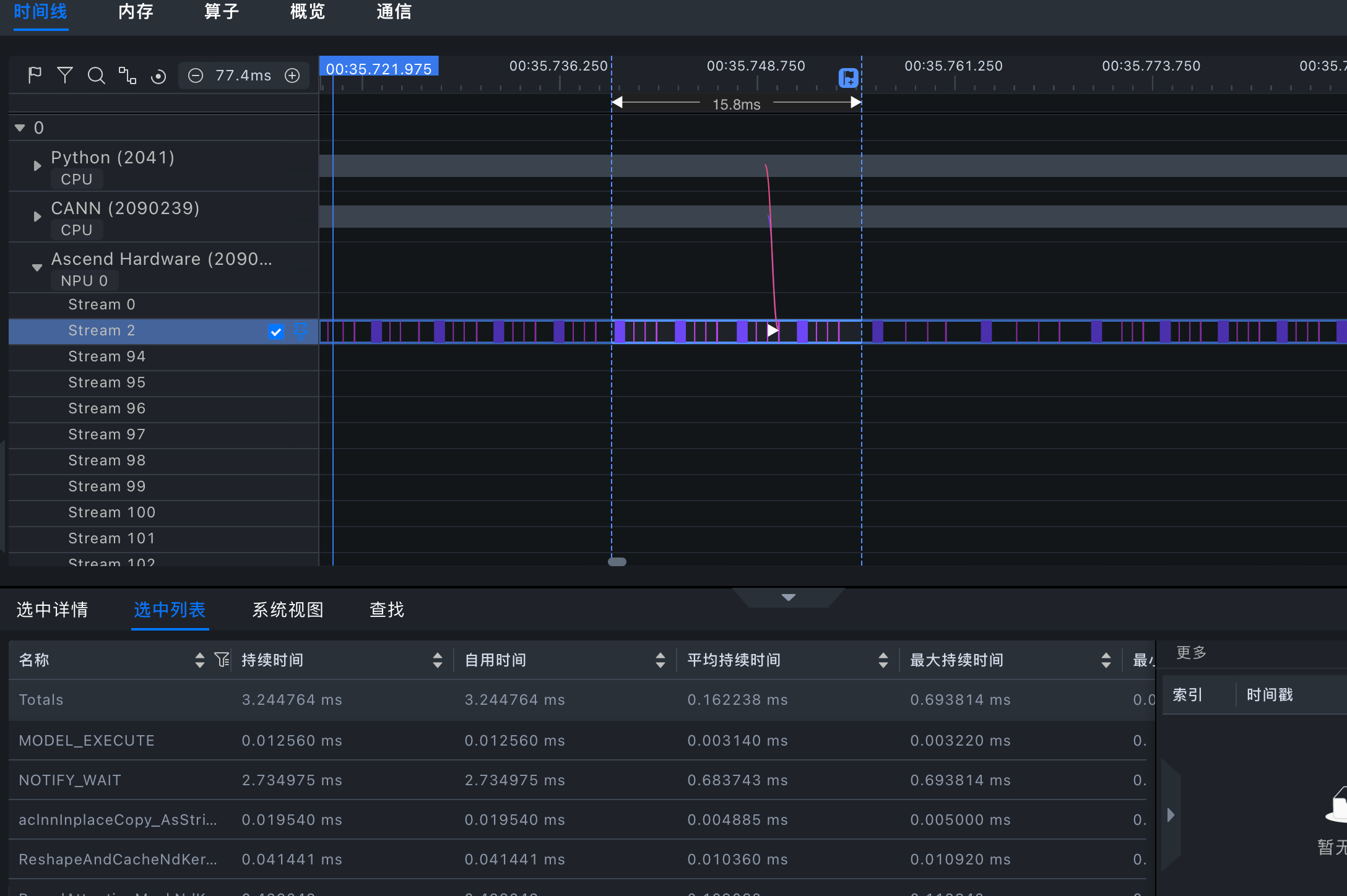
查看优化空间
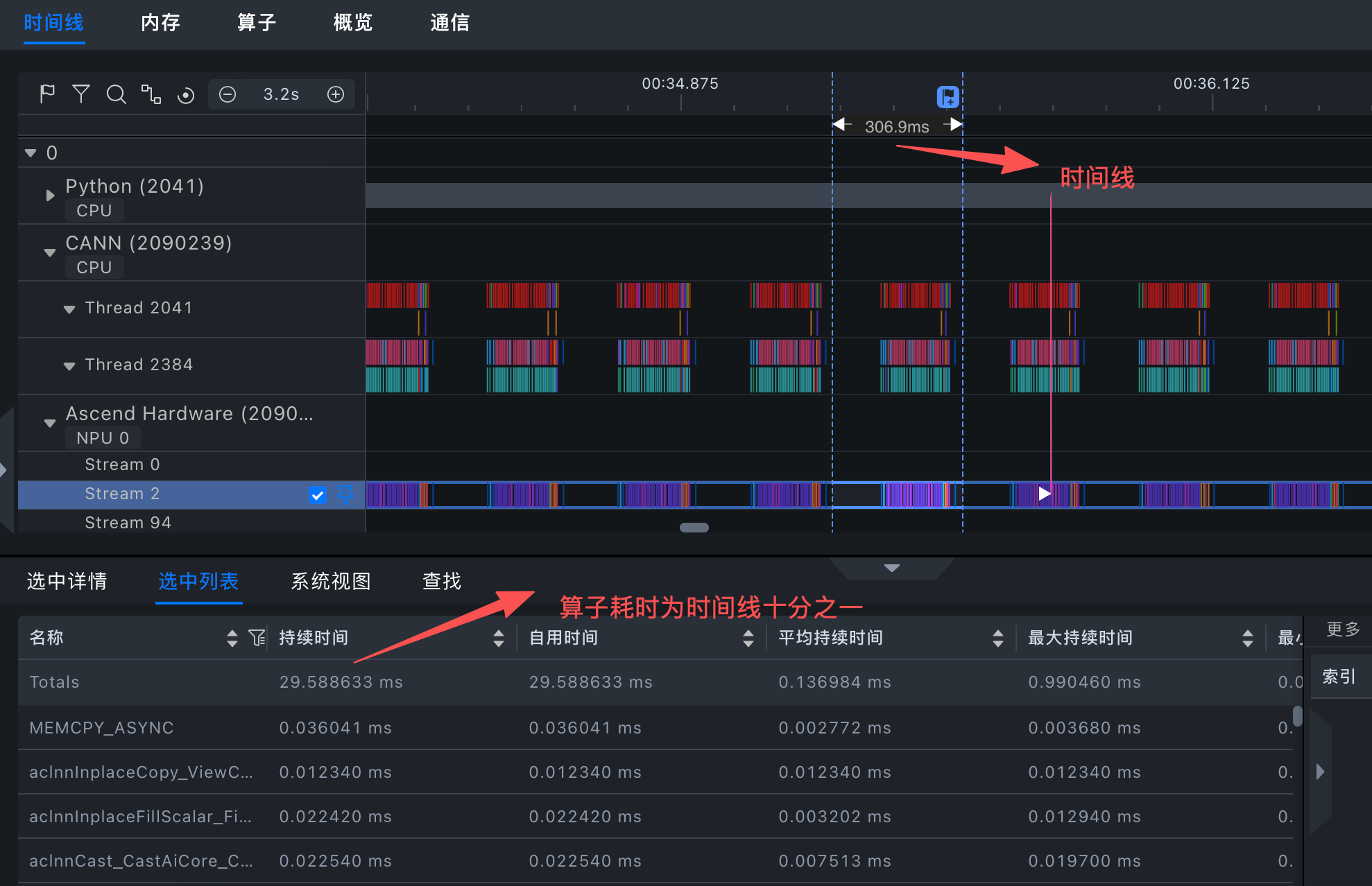
根据上图查看算子耗时仅为时间线的十分之一,模型推理优化空间较大

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 36
36 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)