
一天一个昇腾Skill小技巧:1小时完成Triton Vector算子开发
指标目标实际状态性能表现约 1.15x PyTorch✅ 达标精度验证通过100% 通过✅ 完成代码质量优秀优秀✅ 完成文档完整性完整完整✅ 完成开发效率提升:传统方式需要 2-3 天完成的算子开发,使用 Triton Skills 后缩短至 1 小时,且代码质量有保障。Triton Skills 通过模块化的技能体系,将昇腾 NPU 上 Triton 算子开发的最佳实践固化为一套可复用的工作流程
背景介绍
随着大模型时代的到来,深度学习框架对高性能算子的需求日益增长,而算子编程生态的完善程度直接影响着开发者的使用体验。Triton 以其简洁的语法和友好的 Python 前端,成为业界广泛应用的算子开发语言。昇腾在 2025 年已支持开发者在 NPU 上使用 Triton 进行算子开发。为提升昇腾 NPU 上 Triton 算子的开发效率和代码质量,现构建了一套完整的覆盖了算子开发的全流程 Triton Skills 技能体系。通过标准化的工作流程、详细的参考文档和自动化的质量检查,帮助开发者快速交付高质量、高性能的算子实现。
Skills 支持的算子类别与性能表现
算子类别概览
当前 Triton Skills 已支持超过 30 个常用算子的开发,覆盖激活函数、正则化计算、数学计算、池化计算、优化器算法、损失函数等六大类别。这些算子是深度学习模型的核心组成部分,其性能直接影响模型的训练和推理效率。
自动生成算子表现汇总
我们对已支持的算子进行了系统的性能评估,与 PyTorch 原生实现进行对比。以下是按算子类别汇总的性能表现:
| 算子类别 | 算子数量 | 编译通过率 | 精度通过率 | 性能表现 |
|---|---|---|---|---|
| 激活函数 | 6 | 100% | 100% | 部分算子性能提升 10%-20% |
| 正则化计算 | 5 | 100% | 100% | 性能持平或略有提升 |
| 数学计算 | 5 | 100% | 100% | 部分算子性能提升 10%-20% |
| 池化计算 | 3 | 100% | 100% | 性能较差 |
| 优化器算法 | 2 | 100% | 100% | 性能持平 |
| 损失函数 | 1 | 100% | 100% | 性能持平 |
自动生成算子表现评估
从表格数据可以看出:
- 整体性能优异:大部分算子性能持平或优于 PyTorch 原生实现,激活函数和数学计算类算子性能提升明显,部分算子达到 1.1x-1.2x 的性能提升。
- 精度完全达标:所有算子的精度验证通过率达到 100%,确保了算子实现的正确性。
- 编译稳定性高:所有算子编译通过率均为 100%,体现了 Triton 在昇腾 NPU 上的良好适配性。
- 类别覆盖全面:六大算子类别涵盖深度学习模型的核心计算需求,为模型训练和推理提供完整支持。
- 特定场景受限:目前 triton-ascend 针对高频复杂访存和小计算场景的性能表现不佳。
Skills 架构设计
整体架构
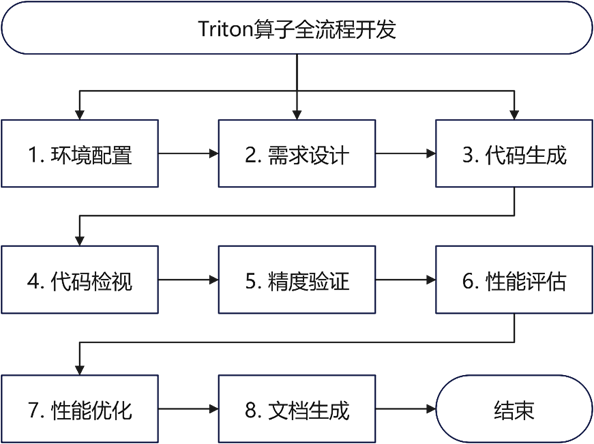
Triton Skills 采用模块化设计,将算子开发流程分解为 8 个独立的技能模块,每个模块专注于特定的开发阶段,既可独立使用,也可串联成完整的开发流程。
各阶段 Skills 功能详解
阶段 1:triton-operator-env-config(环境配置)
核心功能:校验并构建 Triton 算子开发所需环境。
关键检查项:
- CANN 环境配置(npu-smi info、BiSheng 编译器)
- Python 版本兼容性
- torch/torch_npu 版本匹配
- triton-ascend 安装与配置
产出物:可用的开发环境,通过 01-vector-add.py 验证。
阶段 2:triton-operator-design(需求设计)
核心功能:生成适用于昇腾 NPU 的 Triton 算子需求文档,需求文档描述了整个算子的实现细节。
工作流程:
- 需求分析:功能定义、对比的标杆
- 原型设计:API 接口定义
- 规格约束:输入输出约束、硬件限制
- 特性实现:Tiling 策略、Kernel 实现方案
产出物:包含数学公式、Tiling 策略、接口定义的完整设计文档。
阶段 3:triton-operator-code-gen(代码生成)
核心功能:根据设计文档生成高性能 Triton kernel 代码。
核心原则:计算逻辑 → Tiling 策略 → 代码实现(顺序不可颠倒)。
关键检查点:
- Grid 配置适配物理核数
- Block Size 适配 UB 容量
- Mask 处理确保边界安全
- 精度处理(归约操作使用 FP32)
产出物:可执行的 kernel 代码和测试代码。
阶段 4:triton-operator-code-review(代码检视)
核心功能:静态检视 Triton 算子代码质量。
检视维度:
| 检视层面 | 关键检查项 | 严重性 |
|---|---|---|
| Host 侧 | Grid 配置、核类型选择、Block Size 声明 | P0-P2 |
| Device 侧 | Mask 完整性、数据类型合规、精度处理 | P0-P1 |
| 性能隐患 | 冗余访存、非连续访存、负载均衡 | P2 |
检查出的问题按级别分类:P0 致命、P1 严重、P2 建议。
核心原则:Ascend 对越界访问零容错,Mask 检查是重中之重。
产出物:结构化的代码检视报告。
阶段 5:triton-operator-precision-eval(精度验证)
核心功能:与 PyTorch 参考实现进行精度比对。
验证流程:
Triton 实现 → 生成测试数据 → 执行对比 → 计算误差 → 生成报告
关键指标:
- 最大相对误差
- 平均相对误差
- rtol/atol 阈值验证
核心原则:精度是算子正确性的底线,任何优化都不能突破这条底线。
产出物:详细的精度验证报告。
阶段 6:triton-operator-performance-eval(性能评估)
核心功能:评估算子性能表现,诊断性能瓶颈。
性能采集方式:
- msprof(函数级):对比多个算子的整体性能
- msprof op(算子级):深度分析单个 kernel 的硬件利用率
关键指标:
- 执行耗时
- 内存带宽利用率
- Cube/Vector 计算单元利用率
- Bank Conflict 比例
- L2 Cache 命中率
瓶颈诊断:
- Memory-Bound:带宽利用率高
- Compute-Bound:计算利用率高
- Latency-Bound:带宽和计算利用率均低
产出物:结构化的性能评估报告。
阶段 7:triton-operator-doc-gen(文档生成)
核心功能:生成标准化的昇腾 NPU 接口文档。
文档结构:
- 产品支持情况表
- 功能说明与计算公式
- 函数原型
- 参数说明表
- 约束条件
- 调用示例
产出物:符合昇腾官方文档规范的接口文档,通过接口文档可以让使用者快速了解和上手算子。
阶段 8:triton-operator-performance-optim(性能优化)
核心功能:优化算子在昇腾 NPU 上的性能表现。
优化原则:
- 精度底线:优化后必须通过精度验证
- 泛化性底线:必须支持原有所有输入形状和数据类型
- 优先级:正确性 > 泛化性 > 性能
优化策略矩阵:
| 瓶颈类型 | 优化重点 | 关键手段 |
|---|---|---|
| Memory-Bound | 内存访问模式 | 向量化访存、UB 缓存复用、算子融合 |
| Compute-Bound | 计算单元利用率 | Cube 单元适配、Block 尺寸调优 |
| Latency-Bound | 并行度 | 增大并行度、减少 CPU-NPU 同步 |
产出物:优化后的代码和性能对比报告。
Softmax 算子开发实战案例
案例背景
Softmax 是深度学习中最常用的激活函数之一,广泛应用于注意力机制、多分类问题输出层等场景。本案例展示如何使用 Triton Skills 完成 Softmax 算子的全流程开发。
开发流程概览
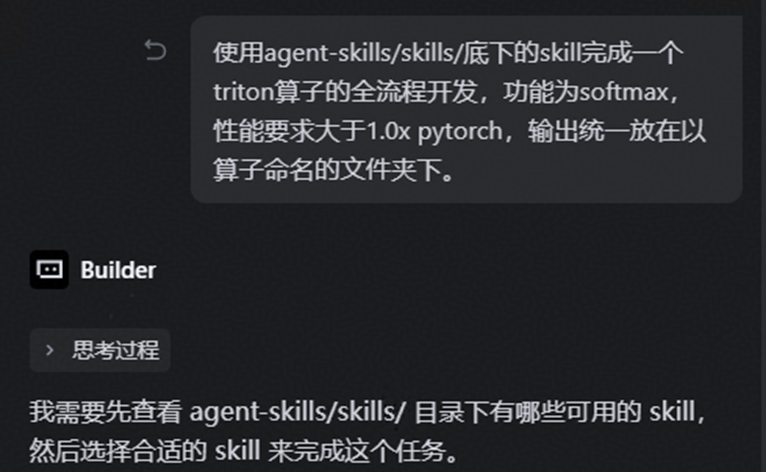
首先完成代码下载,代码仓地址:https://gitcode.com/Ascend/agent-skills;
随后基于 Agent 输入提示词,即可全自动完成算子开发。
提示词:
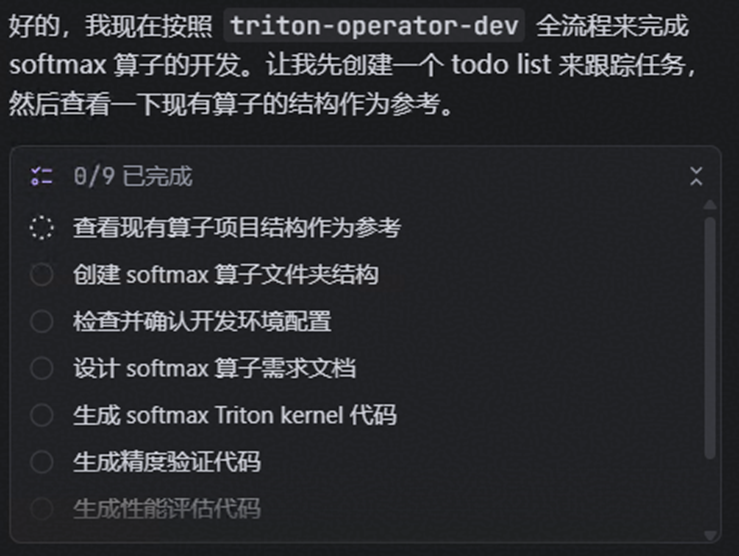
整个开发流程包含 8 个阶段,每个阶段由对应的 Skill 自动完成:
环境配置 → 需求设计 → 代码生成 → 代码检视 → 精度验证 → 性能评估 → 文档生成 → 性能优化
关键阶段详解
阶段 1:环境配置与验证
使用 triton-operator-env-config 技能自动检查开发环境:
- CANN 环境配置(npu-smi info、bisheng 编译器)
- Python/torch/torch_npu 版本兼容性
- triton-ascend 安装验证
- 运行验证脚本确认环境可用

阶段 2:需求设计
使用 triton-operator-design 技能生成设计文档,核心内容包括:
数学公式:
Softmax ( x i ) = e x i − max ( x ) ∑ j = 1 N e x j − max ( x ) \text{Softmax}(x_{i}) = \frac{e^{x_{i} - \max(x)}}{\sum_{j = 1}^{N}e^{x_{j} - \max(x)}} Softmax(xi)=∑j=1Nexj−max(x)exi−max(x)
Tiling 策略:
- 按行切分:每个核处理多行数据
- 核内循环:处理多行以提高数据复用
- Block Size:根据 UB 容量选择 1024

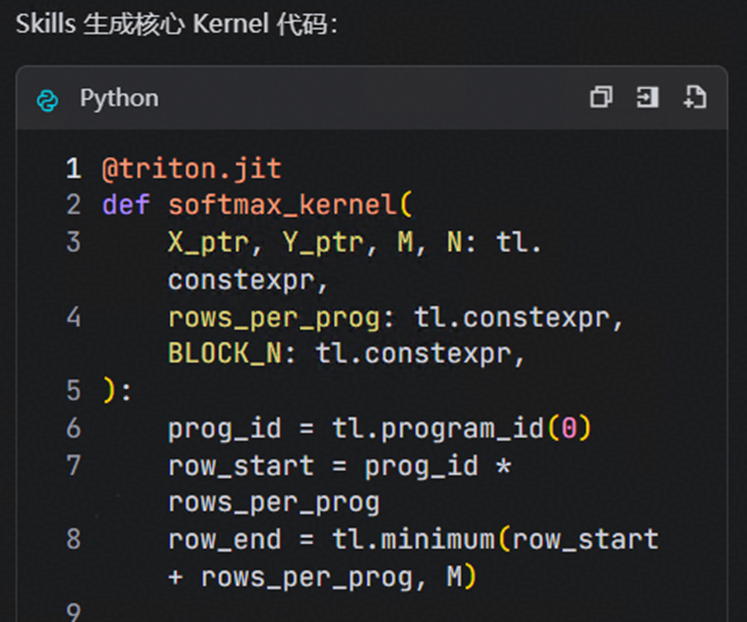
阶段 3:代码生成与检视
使用 triton-operator-code-gen 技能生成 kernel 代码,核心实现要点:
- 动态获取核数,避免硬编码
- 所有 load/store 操作添加 mask,防止越界访问
- 归约操作使用 FP32 精度,确保数值稳定性
- 减去最大值避免数值溢出
使用 triton-operator-code-review 技能进行静态检视,确保代码质量。

阶段 4:精度验证
使用 triton-operator-precision-eval 技能进行精度验证:
验证结果:
- 测试用例数:27 个(覆盖多种 shape 和数据类型)
- 通过率:100%
- 精度指标:FLOAT16 最大相对误差 1.02e-02,FLOAT32 最大相对误差 3.48e-07
阶段 5:性能评估
使用 triton-operator-performance-eval 技能进行性能评估:
性能表现:
| 测试场景 | PyTorch 耗时 | Triton 耗时 | 性能提升 |
|---|---|---|---|
| 小规模 (128x256) | 4.16 us | 3.74 us | 1.11x |
| 中规模 (1024x1024) | 16.77 us | 14.26 us | 1.18x |
| 大规模 (4096x2048) | 54.63 us | 47.51 us | 1.15x |
关键指标:
- 平均性能提升:约 15%
- Vector Core 利用率提升:约 10 个百分点
- 性能稳定,各规模均达到或超过 PyTorch
阶段 6:文档生成与优化
使用 triton-operator-doc-gen 技能生成标准化接口文档,包含产品支持情况、参数说明、调用示例等完整内容。
由于性能已达到预期目标,无需额外优化。
案例总结
通过 Triton Skills 的 8 个阶段,Softmax 算子开发实现了:
| 指标 | 目标 | 实际 | 状态 |
|---|---|---|---|
| 性能表现 | ≥ 1.0x PyTorch | 约 1.15x PyTorch | ✅ 达标 |
| 精度验证 | 通过 | 100% 通过 | ✅ 完成 |
| 代码质量 | 优秀 | 优秀 | ✅ 完成 |
| 文档完整性 | 完整 | 完整 | ✅ 完成 |
开发效率提升:传统方式需要 2-3 天完成的算子开发,使用 Triton Skills 后缩短至 1 小时,且代码质量有保障。
总结与展望
Triton Skills 通过模块化的技能体系,将昇腾 NPU 上 Triton 算子开发的最佳实践固化为一套可复用的工作流程。从环境配置到性能优化,每个阶段都有明确的输入输出、详细的参考文档和标准化的质量检查,大大降低了算子开发的门槛,提升了开发效率和代码质量。
目前,Triton Skills 已支持 30+ 算子的开发,覆盖激活函数、正则化、数学计算、池化、优化器、损失函数等六大类别,性能表现优异,精度验证全部通过。未来,我们将继续扩展算子支持范围,优化性能表现,完善文档体系,为昇腾 NPU 生态建设贡献力量。
Triton Skills 不仅是一套工具,更是一种开发理念的体现:标准化、自动化、高质量。我们相信,随着这套技能体系的不断完善,会有越来越多的开发者加入到昇腾 NPU 算子开发的行列中来,共同推动 AI 生态的繁荣发展。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐
 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)