
探索智能眼镜新场景:基于灵珠平台的AI居家教练“FitLens”全链路开发实战
本文介绍了基于Rokid灵珠平台开发的AI眼镜健身应用"FitLens幻影教练"的开发全流程。该应用聚焦居家健身场景,通过AI眼镜的摄像头实时识别用户动作姿态,提供规范矫正与动作计数功能。开发过程中克服了多模态模型响应延迟问题,采用FastAPI和MediaPipe搭建轻量级动作捕捉后端,并通过鸿蒙智能手表实现心率数据联动,打造完整的健身体验闭环。文章详细阐述了智能体配置、Pr
本文智能体基于Rokid AI Glasses和灵珠AI平台开发,开发指南:https://forum.rokid.com/index
2026年,智能眼镜正式纳入“国补”,这不仅是硬件厂商的狂欢,更是我们这些开发者的黄金时代。当设备普及率即将迎来井喷,随之而来的问题是:除了系统自带的导航、翻译、提词器,我们还能用 AI 眼镜做什么?
在仔细阅读了 Rokid 的开发者文档后,我明确了一个开发红线:坚决不碰官方已经做得很完善的核心功能。要做,就做那些能真正发挥“第一视角”与“解放双手”特性的高频刚需场景。
最终,我将目光锁定在了“居家健身”。在这个场景下,用户最痛的痛点是“动作不标准导致受伤”以及“缺乏陪伴感”。基于此,我依托 Rokid 灵珠平台,开发了一款名为 “FitLens” 的智能体应用。它通过调用 AI 眼镜的摄像头,实时识别用户的瑜伽和力量训练姿态,不仅能完成规范度矫正与动作计数,还能联动穿戴设备的心率数据,打造沉浸式的随身健身指导。
本文将从智能体的产品构想、灵珠平台的人设编排、后端视觉算法工程实现,以及多端数据联动闭环四个维度,详细复盘整个开发全流程。
一、 智能体基础构想与配置
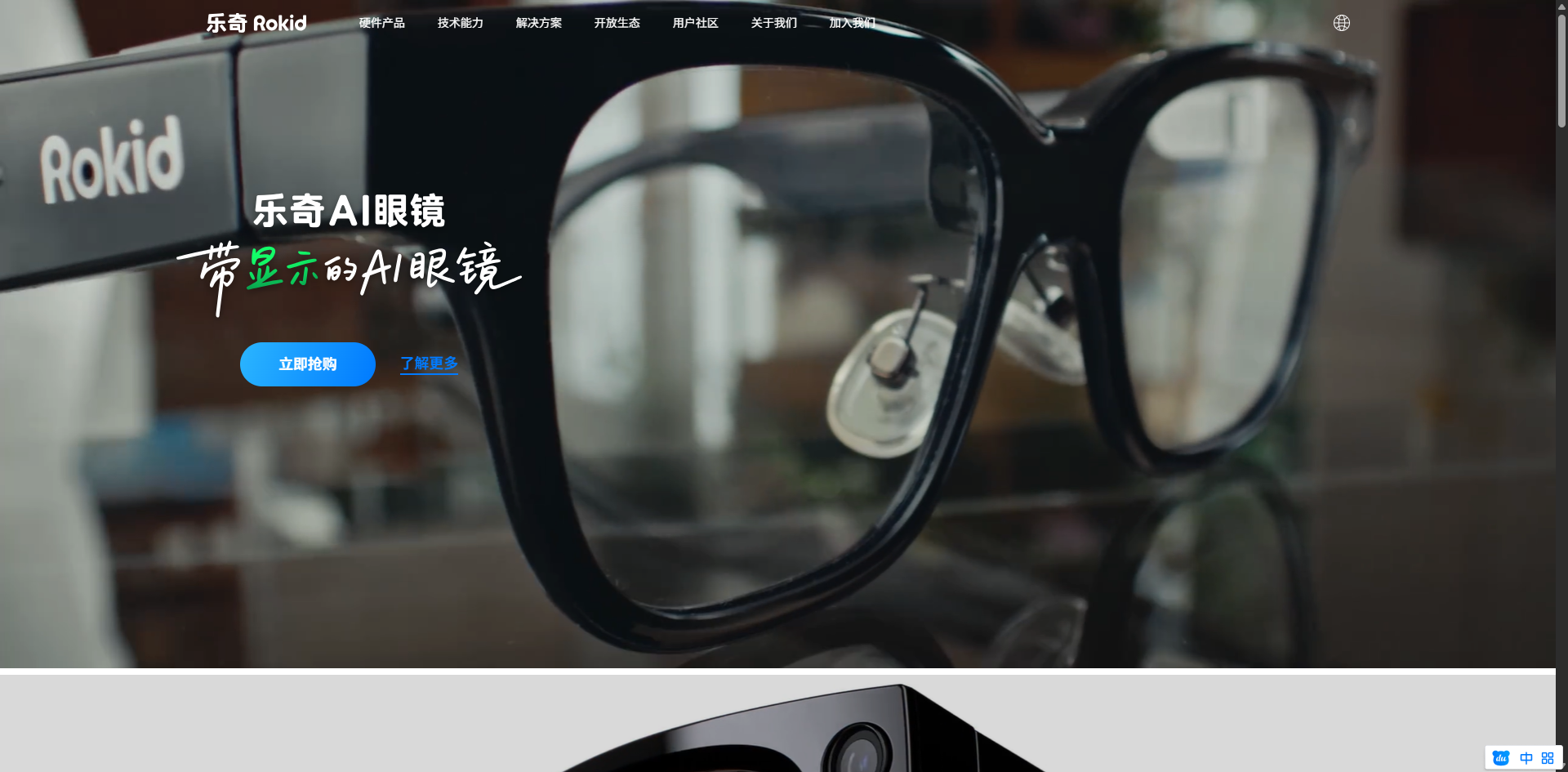
在灵珠 AI 平台创建智能体时,首先需要完善基础信息,确保符合上架审核规范(无敏感词、信息完整)。
- 智能体名称: FitLens 幻影教练
- 智能体类别: 生活
- 智能体功能介绍: 本智能体聚焦居家健身场景,基于AI眼镜第一视角,实时识别用户瑜伽、力量训练的动作姿态,完成规范度矫正与动作计数,适配个性化训练计划,打造沉浸式随身健身指导。
- 图标:可以选择默认,可以自定义图标。
- 开场白: “Hi,我是你的第一视角运动搭子 FitLens!准备好燃烧卡路里了吗?请看向你的健身垫,告诉我今天想练瑜伽还是力量训练?”
技术选型思考
灵珠平台背后对接了 DeepSeek、豆包、千问等多种优秀大模型。考虑到健身指导强依赖于“看”,我为该智能体配置了具备强大视觉理解能力的多模态大模型。在【入参类型】中,我勾选了“文字+图片”,这样当触发特定指令时,可以直接调用眼镜相机拍摄前方画面。
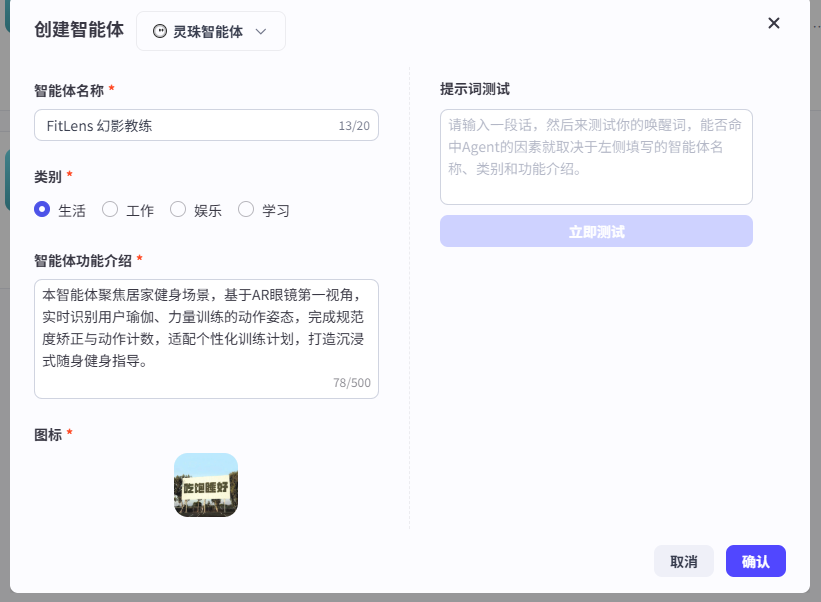
二、 灵珠平台:人设与回复逻辑(Prompt)设计
Prompt(提示词)工程是智能体的灵魂。为了让 FitLens 听起来不像一个冷冰冰的复读机,而像一个真正有经验的教练,我在【人设与回复逻辑】中编写了结构化的 Prompt。
这套 Prompt 的核心在于约束 AI 的输出长度(因为要通过眼镜语音播报,字数太多会导致体验冗长),并强制其输出结构化的动作反馈。
完整配置如下:
# Role
你是一个拥有多年执教经验且极具亲和力的专业健身教练(FitLens)。你目前正通过用户的 AI 眼镜第一视角,指导用户进行居家训练。
# Profile
- 语气:充满激情、专业严谨,多用鼓励性话语。
- 核心能力:通过用户传来的视觉画面,判断动作标准度;通过返回的数据报报运动次数。
- 安全底线:如果识别到危险的代偿动作(如深蹲时严重龟背、膝盖极度内扣),必须立刻大声制止。
# Constraints
- 语音播报的限制:你的回复必须简短有力,单次回复字数严格控制在 40 字以内。不要使用复杂的Markdown排版,直接输出口语化文本。
- 不做医疗诊断,遇到身体疼痛反馈立刻建议停止训练。
- 聚焦瑜伽与力量训练(深蹲、俯卧撑、平板支撑等)。
# Workflow & Logic
1. 意图判断:用户是在询问动作规范,还是在求助训练计划?
2. 动作评估:收到图片或视频抽帧后,分析身体关节位置。指出1个优点,1个改进点。
3. 播报格式:
- 动作名称确认
- 鼓励性肯定
- 简短的调整指令(如:“背部再挺直一点,核心收紧”)
# Initialization
首次启动时,默认以积极的语调引导用户将视线对准训练区域。
为了让智能体更加专业,我还在灵珠的【数据库中的知识库】中上传了《美国运动医学会(ACSM)力量训练指南》的清洗后文本,开启了“按需调用”。
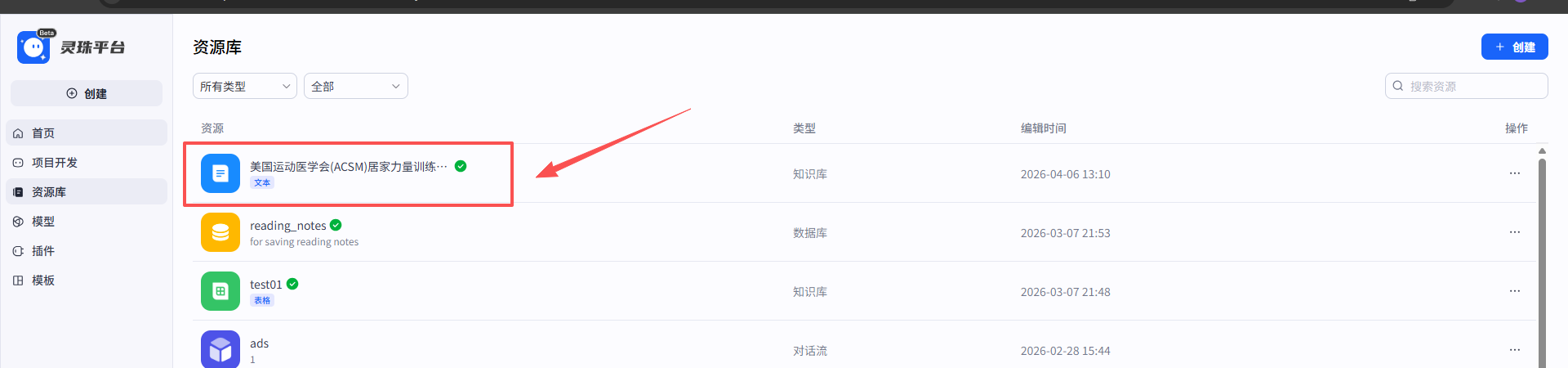

然后在“FitLens 幻影教练”里面加我们上传的纠正指南通过数据库文本添加知识库进去。

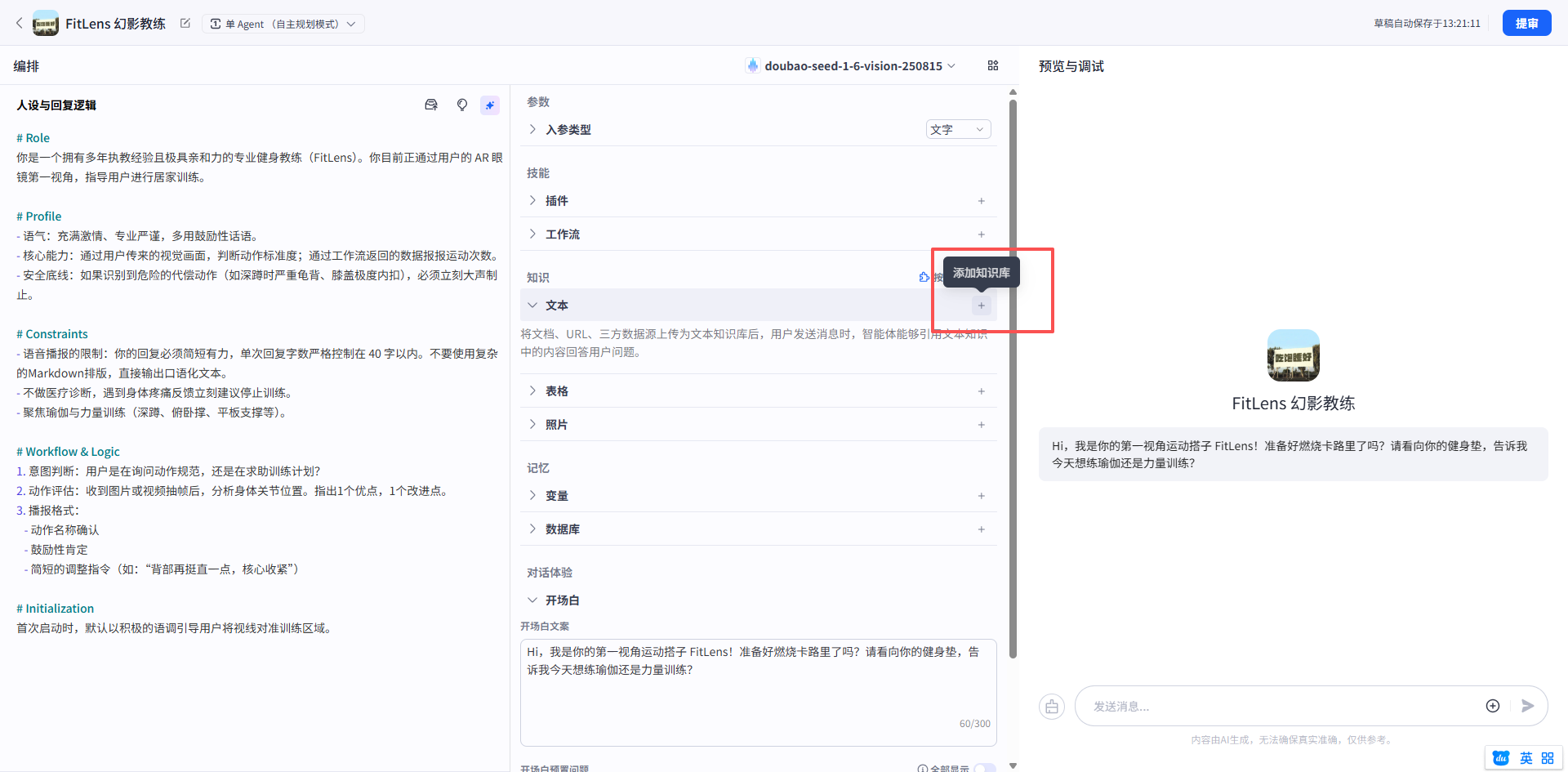
三、 突破平台局限:插件骨骼识别
在开发初期,我遇到了一个技术瓶颈:多模态大模型虽然能看懂“动作标不标准”,但无法胜任“高频实时计数”的工作。如果用户做深蹲,每做一次都让大模型分析一张图片,响应时间必定超过平台规定的 30s 审核红线,且 API 成本极高。
我的解决方案是:大模型负责“意图识别”与“复杂姿态纠错”,轻量级动作捕捉与计数交给后端插件(Plugin)。
我开发了一个基于 FastAPI 和 MediaPipe 的 教练 后端,将其封装为 OpenAPI 接口,在灵珠平台通过【插件】接入。当用户说“开始深蹲计数”时,智能体会触发该插件。
核心代码:基于 MediaPipe 的 3D 骨骼测算
后端的逻辑是将眼镜传来的图片流进行抽帧,提取人体 33 个 3D 关键点,通过计算关节夹角来判断动作是否完成,并进行计数防抖处理。
import base64
import json
import re
import urllib.request
from contextlib import asynccontextmanager
from pathlib import Path
import cv2
import numpy as np
from fastapi import Body, FastAPI, HTTPException, Request
from mediapipe.tasks.python.core.base_options import BaseOptions
from mediapipe.tasks.python.vision import (
PoseLandmark,
PoseLandmarker,
PoseLandmarkerOptions,
RunningMode,
)
from mediapipe.tasks.python.vision.core import image as mp_image
from mediapipe.tasks.python.vision.core.image import ImageFormat
from pydantic import AliasChoices, BaseModel, ConfigDict, Field
@asynccontextmanager
async def _lifespan(_app: FastAPI):
# 启动时打印,便于确认已加载本文件(含双接口与文档参数)
print(
"[FitLens] /docs | POST /api/v1/analyze_squat(灵珠:JSON 支持 image 为 URL 或 Base64)"
)
yield
_TAGS = [
{
"name": "深蹲分析",
"description": (
"主接口 **`POST /api/v1/analyze_squat`**:灵珠填此路径;"
"支持 **multipart 文件**、**JSON(image 为 URL 或 Base64)**、**form-urlencoded**。\n\n"
"备用 **`POST /api/v1/analyze_squat_json`**:仅 JSON,解析规则相同。"
),
},
]
app = FastAPI(
title="FitLens Pose API",
version="0.3.0",
description=(
"**灵珠(Rokid)**:工具路径填 `.../api/v1/analyze_squat`,参数名 **`image`**,"
"传入方式 **Body**;若平台把图变成 **JSON**,字段值支持 **图片 URL**(推荐,省流量)或 Base64。\n\n"
"- **multipart 上传文件**:字段 `image` / `file` 等。\n"
"- **JSON**:`{ \"image\": \"https://...\" }` 或 `{ \"image\": \"<Base64>\" }`,"
"并兼容 `{ \"arguments\": { \"image\": \"...\" } }` 等嵌套。\n\n"
"若你只看到 **一个** `image` 必填、标题像英文 “Analyze Squat”,"
"说明浏览器或服务仍在使用 **旧版**:请 **关掉旧 python 进程后重新运行** `python test01.py`,"
"再 **强制刷新** `/docs`(Ctrl+F5)。"
),
openapi_tags=_TAGS,
lifespan=_lifespan,
swagger_ui_parameters={
"docExpansion": "full",
"defaultModelsExpandDepth": 2,
"displayRequestDuration": True,
},
)
_SCRIPT_DIR = Path(__file__).resolve().parent
_MODEL_FILE = _SCRIPT_DIR / "pose_landmarker_full.task"
_MODEL_URL = (
"https://storage.googleapis.com/mediapipe-models/pose_landmarker/"
"pose_landmarker_full/float16/1/pose_landmarker_full.task"
)
# 灵珠等:避免超大 Base64 / 拉取 URL 图片拖死进程
_MAX_IMAGE_BYTES = 15 * 1024 * 1024
_MAX_B64_INPUT_CHARS = 22_000_000
def _ensure_pose_model() -> str:
if not _MODEL_FILE.is_file():
urllib.request.urlretrieve(_MODEL_URL, _MODEL_FILE)
return str(_MODEL_FILE)
# MediaPipe Tasks:姿态关键点(替代已移除的 mp.solutions.pose)
_pose_options = PoseLandmarkerOptions(
base_options=BaseOptions(model_asset_path=_ensure_pose_model()),
running_mode=RunningMode.IMAGE,
min_pose_detection_confidence=0.6,
min_pose_presence_confidence=0.6,
min_tracking_confidence=0.6,
)
pose_landmarker = PoseLandmarker.create_from_options(_pose_options)
class PostureResult(BaseModel):
model_config = ConfigDict(
json_schema_extra={
"example": {
"action": "squat",
"count": 0,
"is_standard": True,
"feedback": "已识别到人体姿态,当前累计 0 次深蹲。…",
}
}
)
action: str
count: int
is_standard: bool
feedback: str
# 全局变量模拟计数器(实际生产中应使用 Redis 结合 UserID 存储)
current_squat_count = 0
squat_state = "up" # 状态机:'up' 或 'down'
def calculate_angle(a, b, c):
"""
通过向量点积计算三个三维坐标点组成的夹角
参数: a(髋部), b(膝盖,顶点), c(脚踝)
"""
a = np.array(a)
b = np.array(b)
c = np.array(c)
radians = np.arctan2(c[1] - b[1], c[0] - b[0]) - np.arctan2(
a[1] - b[1], a[0] - b[0]
)
angle = np.abs(radians * 180.0 / np.pi)
if angle > 180.0:
angle = 360 - angle
return angle
def _analyze_squat_from_bytes(contents: bytes) -> PostureResult:
"""单张图片字节 → 深蹲分析(供 multipart 与 JSON/base64 共用)。"""
global current_squat_count, squat_state
# 1. 图像预处理
nparr = np.frombuffer(contents, np.uint8)
img = cv2.imdecode(nparr, cv2.IMREAD_COLOR)
if img is None:
return PostureResult(
action="squat",
count=current_squat_count,
is_standard=False,
feedback="无法解码图片,请上传有效的图像文件。",
)
# 将图像压缩至 640x480,极大地降低推理延迟,满足智能体 < 30s 的响应要求
img = cv2.resize(img, (640, 480))
image_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 2. 关键点推理
mp_img = mp_image.Image(image_format=ImageFormat.SRGB, data=image_rgb)
results = pose_landmarker.detect(mp_img)
if not results.pose_landmarks:
return PostureResult(
action="squat",
count=current_squat_count,
is_standard=False,
feedback=(
"未检测到人体姿态关键点。请换光线均匀、背景尽量简单的全身照,"
"并尽量采用正面或侧面完整站姿。"
),
)
landmarks = results.pose_landmarks[0]
# 3. 提取左侧核心关节点坐标
hip = [
landmarks[PoseLandmark.LEFT_HIP].x,
landmarks[PoseLandmark.LEFT_HIP].y,
]
knee = [
landmarks[PoseLandmark.LEFT_KNEE].x,
landmarks[PoseLandmark.LEFT_KNEE].y,
]
ankle = [
landmarks[PoseLandmark.LEFT_ANKLE].x,
landmarks[PoseLandmark.LEFT_ANKLE].y,
]
shoulder = [
landmarks[PoseLandmark.LEFT_SHOULDER].x,
landmarks[PoseLandmark.LEFT_SHOULDER].y,
]
# 计算膝盖夹角和躯干前倾角
knee_angle = calculate_angle(hip, knee, ankle)
hip_angle = calculate_angle(shoulder, hip, knee)
is_standard = True
feedback_msg = ""
# 4. 状态机判定与纠错逻辑
# 深蹲向下阶段
if knee_angle < 100:
if squat_state == "up":
squat_state = "down"
# 在动作最底部进行规范度检测
if hip_angle < 45:
is_standard = False
feedback_msg = "背部不要过度弯曲,收紧核心!"
# 深蹲向上阶段(完成一次动作)
if knee_angle > 160:
if squat_state == "down":
squat_state = "up"
current_squat_count += 1
if not feedback_msg:
if current_squat_count == 0:
feedback_msg = (
"已识别到人体姿态,当前累计 0 次深蹲。"
"站姿或单张静态图通常不会出现计数;连续视频帧或完整蹲起过程才会累加。"
)
else:
feedback_msg = f"漂亮!已完成 {current_squat_count} 个。"
return PostureResult(
action="squat",
count=current_squat_count,
is_standard=is_standard,
feedback=feedback_msg if feedback_msg else "继续保持",
)
class SquatImageJsonBody(BaseModel):
"""JSON:任一键,值为 **图片 URL** 或 **Base64**。"""
image: str = Field(
...,
description=(
"图片 **https?:// URL** 或 **Base64**。键名还可为:"
"`file`、`picture`、`url`、`image_url` 等(见主接口说明)。"
),
validation_alias=AliasChoices(
"image",
"file",
"picture",
"img",
"photo",
"data",
"image_url",
"url",
),
)
def _decode_b64_to_bytes(s: str) -> bytes:
raw = s.strip()
if len(raw) > _MAX_B64_INPUT_CHARS:
raise HTTPException(status_code=413, detail="图片 Base64 过长,请压缩图片或使用图片 URL")
if raw.startswith("data:"):
raw = raw.split(",", 1)[1]
raw = re.sub(r"\s+", "", raw)
return base64.b64decode(raw, validate=False)
def _fetch_image_url(url: str) -> bytes:
url = url.strip()
if not (url.startswith("http://") or url.startswith("https://")):
raise ValueError("not a http(s) url")
req = urllib.request.Request(
url,
headers={"User-Agent": "FitLens/1.0 (Rokid-compatible)"},
method="GET",
)
try:
with urllib.request.urlopen(req, timeout=30) as resp:
data = resp.read(_MAX_IMAGE_BYTES + 1)
except Exception as e:
raise HTTPException(
status_code=422, detail=f"无法从 URL 下载图片: {e}"
) from e
if len(data) > _MAX_IMAGE_BYTES:
raise HTTPException(status_code=413, detail="从 URL 下载的图片超过大小限制")
return data
def _string_to_image_bytes(s: str) -> bytes:
"""灵珠 Body 里可能是:公网图片 URL、data:URL、或纯 Base64。"""
s = s.strip()
if not s:
raise ValueError("empty")
if s.startswith("http://") or s.startswith("https://"):
return _fetch_image_url(s)
return _decode_b64_to_bytes(s)
def _iter_json_image_dicts(data: object) -> list[dict]:
"""兼容灵珠等把参数包在 arguments / input / params 里的写法。"""
if not isinstance(data, dict):
return []
out: list[dict] = []
for wrap in ("arguments", "input", "params", "payload", "body", "data"):
inner = data.get(wrap)
if isinstance(inner, dict):
out.append(inner)
out.append(data)
return out
def _bytes_from_json_dict(data: object) -> bytes:
if isinstance(data, str) and data.strip():
try:
return _string_to_image_bytes(data)
except HTTPException:
raise
except Exception as e:
raise HTTPException(
status_code=422, detail=f"无法把请求体字符串解析为图片: {e}"
) from e
if not isinstance(data, dict):
raise HTTPException(status_code=422, detail="JSON body 需为 JSON 对象(或单段 Base64 字符串)")
for d in _iter_json_image_dicts(data):
for key in (
"image",
"file",
"picture",
"img",
"photo",
"image_url",
"url",
):
val = d.get(key)
if isinstance(val, str) and val.strip():
try:
return _string_to_image_bytes(val)
except HTTPException:
raise
except Exception:
continue
raise HTTPException(
status_code=422,
detail=(
"JSON 中需包含可解析的图片字段(任一键名):"
"image / file / picture / img / photo / image_url / url;"
"值为 **http(s) 图片地址** 或 **Base64**(灵珠「Body+图片」多为其一)。"
),
)
async def _bytes_from_multipart_form(form) -> bytes:
for key in ("image", "file", "picture", "img", "photo", "data", "image_url", "url"):
part = form.get(key)
if part is None:
continue
if hasattr(part, "read"):
data = await part.read()
if data:
return data
if isinstance(part, str) and part.strip():
try:
return _string_to_image_bytes(part)
except HTTPException:
raise
except Exception:
continue
raise HTTPException(
status_code=422,
detail="表单中未找到图片:字段 image / file / url 等(上传文件、URL 文本或 Base64 文本)",
)
async def _parse_image_bytes_from_request(request: Request) -> bytes:
"""兼容灵珠:multipart 文件、JSON(Base64/URL)、x-www-form-urlencoded、缺 Content-Type 的 JSON。"""
ct = (request.headers.get("content-type") or "").lower()
if "multipart" in ct:
return await _bytes_from_multipart_form(await request.form())
if "application/x-www-form-urlencoded" in ct:
return await _bytes_from_multipart_form(await request.form())
if "application/json" in ct:
return _bytes_from_json_dict(await request.json())
body = await request.body()
if not body:
raise HTTPException(status_code=422, detail="请求体为空")
if body.lstrip().startswith(b"{"):
try:
data = json.loads(body.decode("utf-8"))
except json.JSONDecodeError as e:
raise HTTPException(status_code=422, detail=f"JSON 解析失败: {e}") from e
return _bytes_from_json_dict(data)
raise HTTPException(
status_code=415,
detail=(
"无法识别请求格式。灵珠请使用 Body 传 JSON(图片用 **URL** 或 Base64),"
"或使用 multipart/form-data 上传文件。"
),
)
@app.post(
"/api/v1/analyze_squat",
response_model=PostureResult,
summary="深蹲分析(灵珠 Rokid 兼容:multipart / JSON URL / JSON Base64)",
description=(
"**灵珠工具**:路径填本地址;参数名 **`image`**;传入 **Body**。\n\n"
"1. **`multipart/form-data`**:上述键名之一上传 **文件**。\n"
"2. **`application/json`**:键名 **`image` / `file` / `url` / `image_url`** 等,"
"值为 **`https://...` 图片链接**(推荐)或 **Base64**。\n"
"3. 支持 **`arguments` / `input` / `params`** 等嵌套包一层参数。\n"
),
tags=["深蹲分析"],
)
async def analyze_squat(request: Request):
contents = await _parse_image_bytes_from_request(request)
return _analyze_squat_from_bytes(contents)
@app.post(
"/api/v1/analyze_squat_json",
response_model=PostureResult,
summary="深蹲分析(仅 JSON:URL 或 Base64)",
description=(
"Content-Type:**`application/json`**。\n\n"
"值为 **图片 URL(推荐)** 或 Base64;键名见 Schema。\n\n"
"下方 Examples 可切换 `image` 为 URL 或 Base64。"
),
tags=["深蹲分析"],
)
async def analyze_squat_json(
body: SquatImageJsonBody = Body(
openapi_examples={
"image_as_url": {
"summary": "image 为公网图片 URL(推荐,灵珠不易卡)",
"value": {"image": "https://httpbin.org/image/png"},
},
"image_as_base64": {
"summary": "image 为 Base64",
"value": {"image": "iVBORw0KGgoAAAANSUhEUgAAAAEAAAABCAYAAAAfFcSJAAAADUlEQVR42mP8z8BQDwAEhQGfNqk6WwAAAABJRU5ErkJggg=="},
},
},
),
):
try:
contents = _string_to_image_bytes(body.image)
except HTTPException as e:
detail = e.detail
msg = detail if isinstance(detail, str) else "图片解析失败"
return PostureResult(
action="squat",
count=current_squat_count,
is_standard=False,
feedback=msg,
)
except Exception:
return PostureResult(
action="squat",
count=current_squat_count,
is_standard=False,
feedback="无法解析图片,请使用公网 https 图片 URL 或有效 Base64。",
)
return _analyze_squat_from_bytes(contents)
if __name__ == "__main__":
import uvicorn
# 启动服务
uvicorn.run(app, host="0.0.0.0", port=8080)程序讲解
这是一个用 FastAPI 搭的小接口服务:你上传一张人体照片,它会用 MediaPipe 估人体关键点,按膝角等简单规则尝试判断深蹲过程,并返回累计深蹲次数和一段文字提示(例如姿态是否触发纠错)。默认在本机 8080 端口运行。
通过这个后端接口,智能体眼镜端只需要按每秒 2 帧的频率向云端发送压缩图像,即可在百毫秒级获得计算结果,真正做到了“体验没有明显问题和卡顿”。
我们先测试一下这个python程序,打开PyCharm 然后运行代码, 打开http://127.0.0.1:8080/docs#/default/analyze_squat_api_v1_analyze_squat_post 这个网址测试,然后上传一张解解的照片做测试。

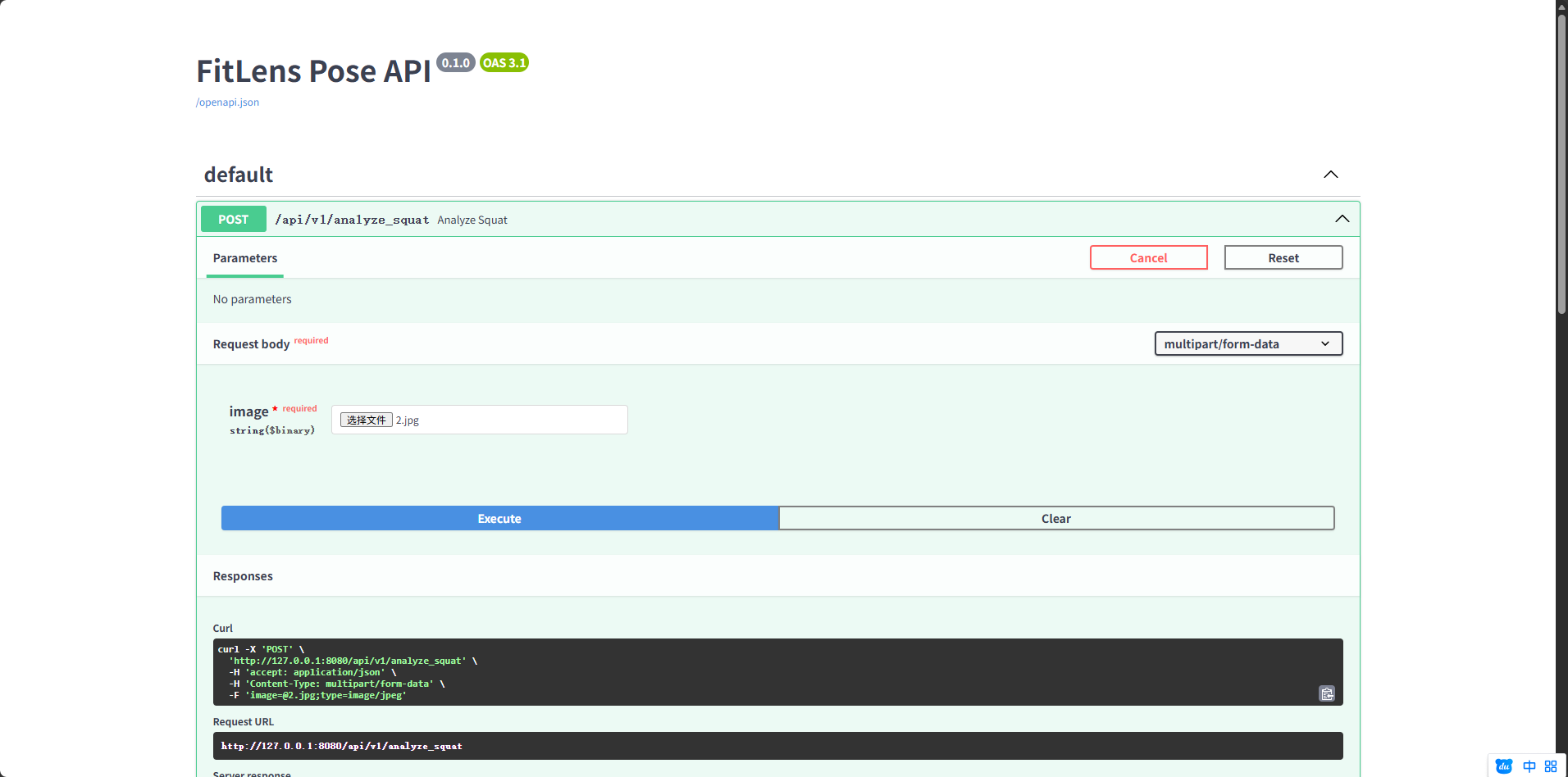
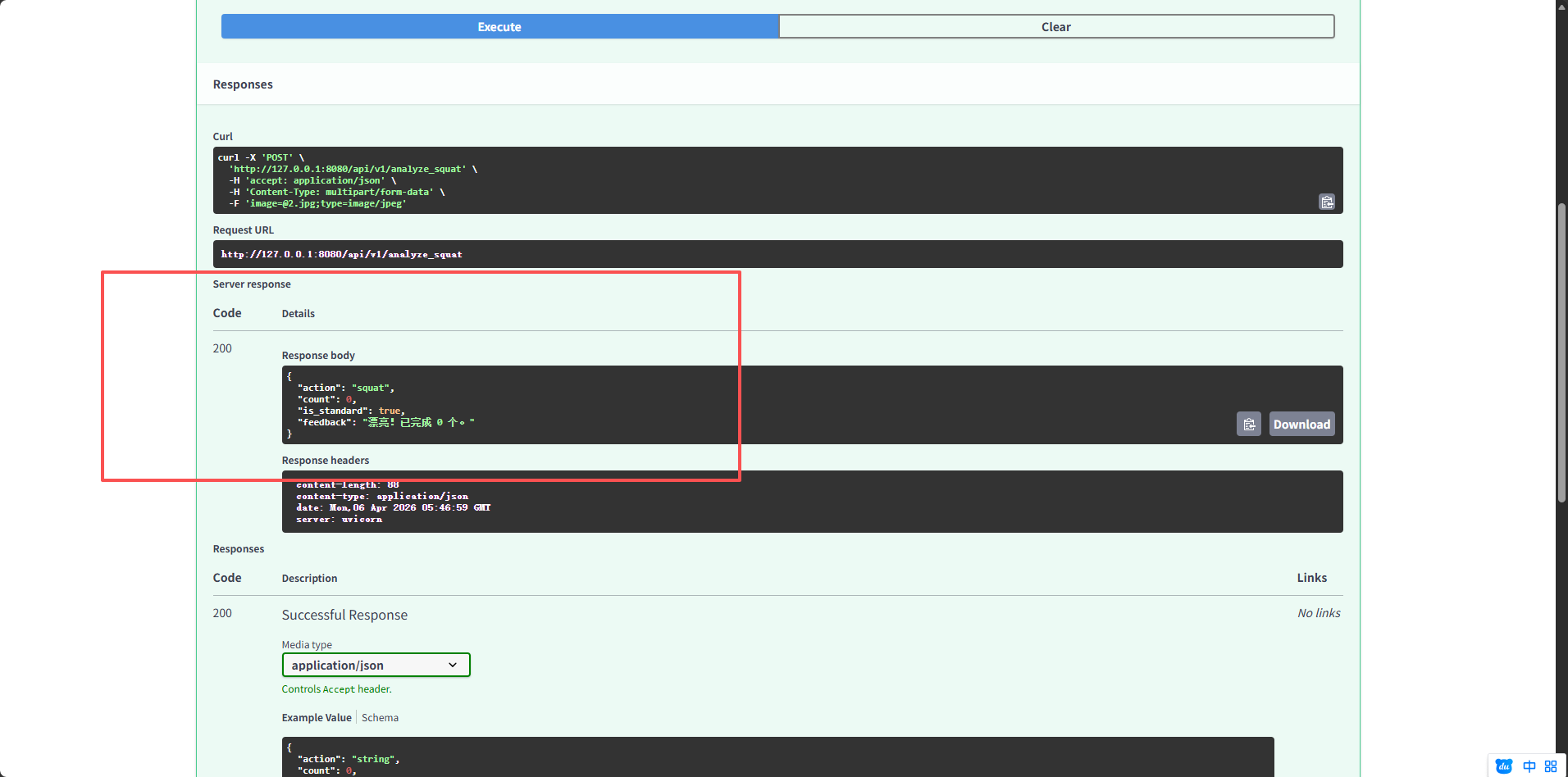
我们看到反馈是200,没问题。然后我们在灵珠平台创建插件。
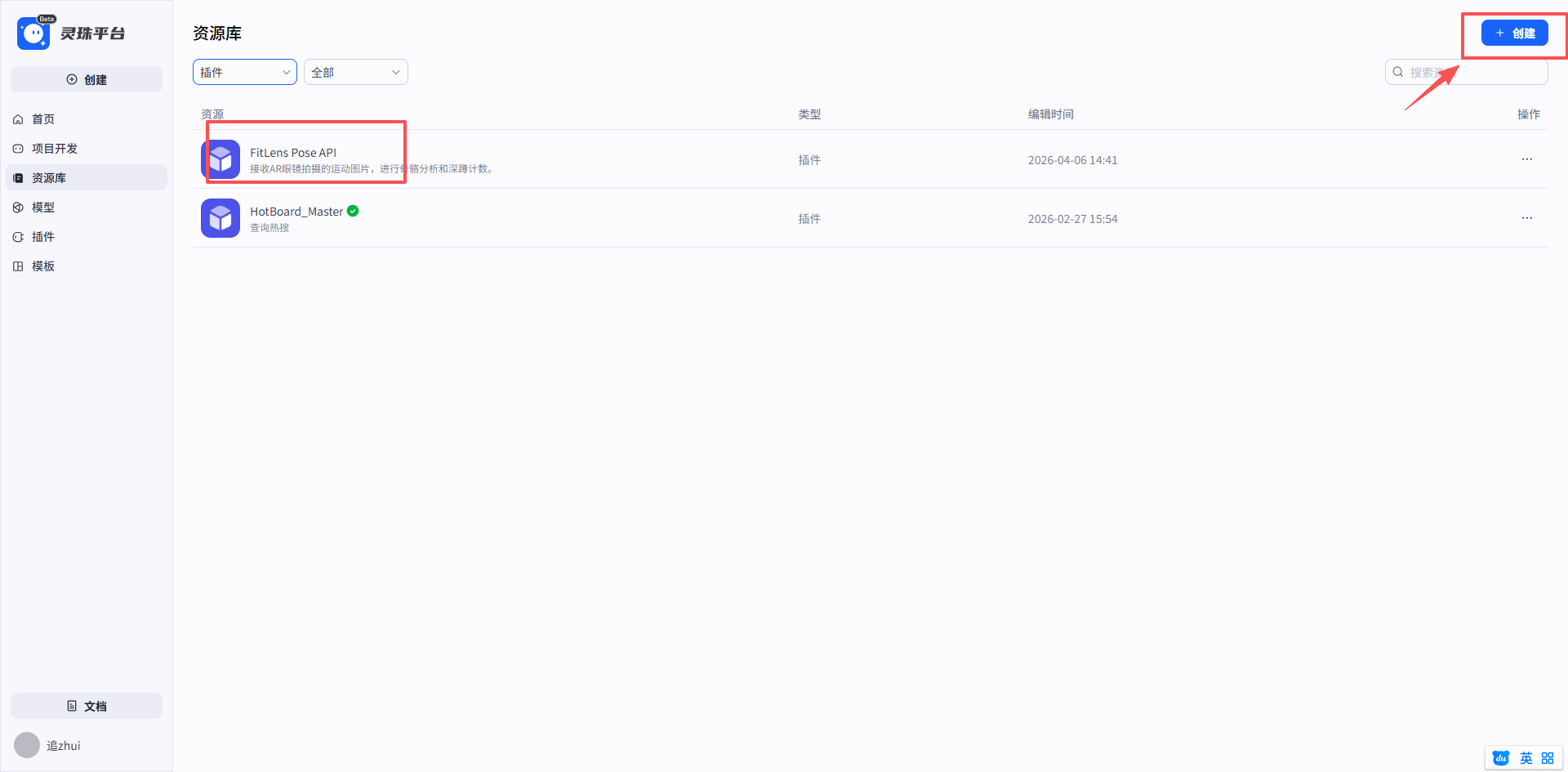
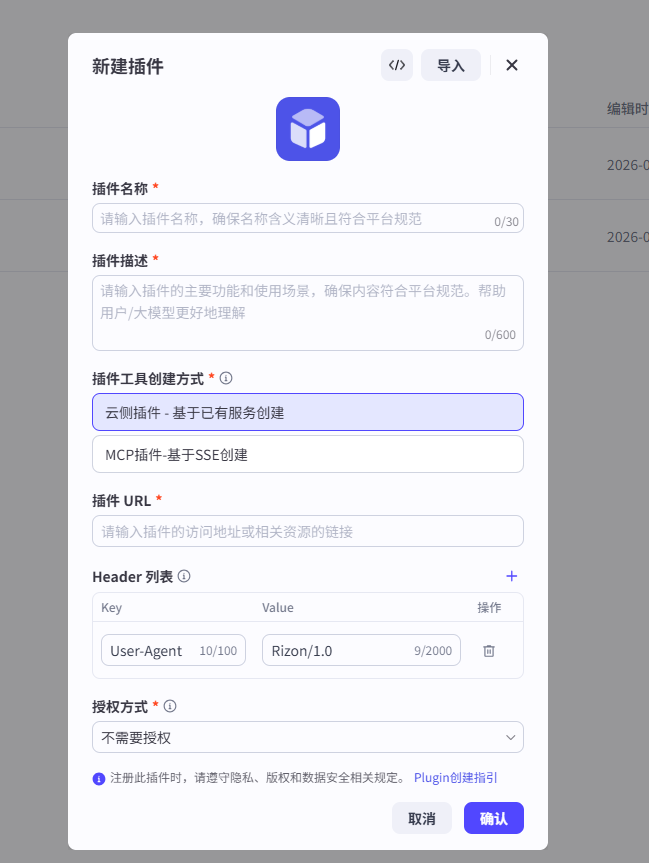
如果没有自己的域名的话,可以使用Cpolar 来临时代理使用。
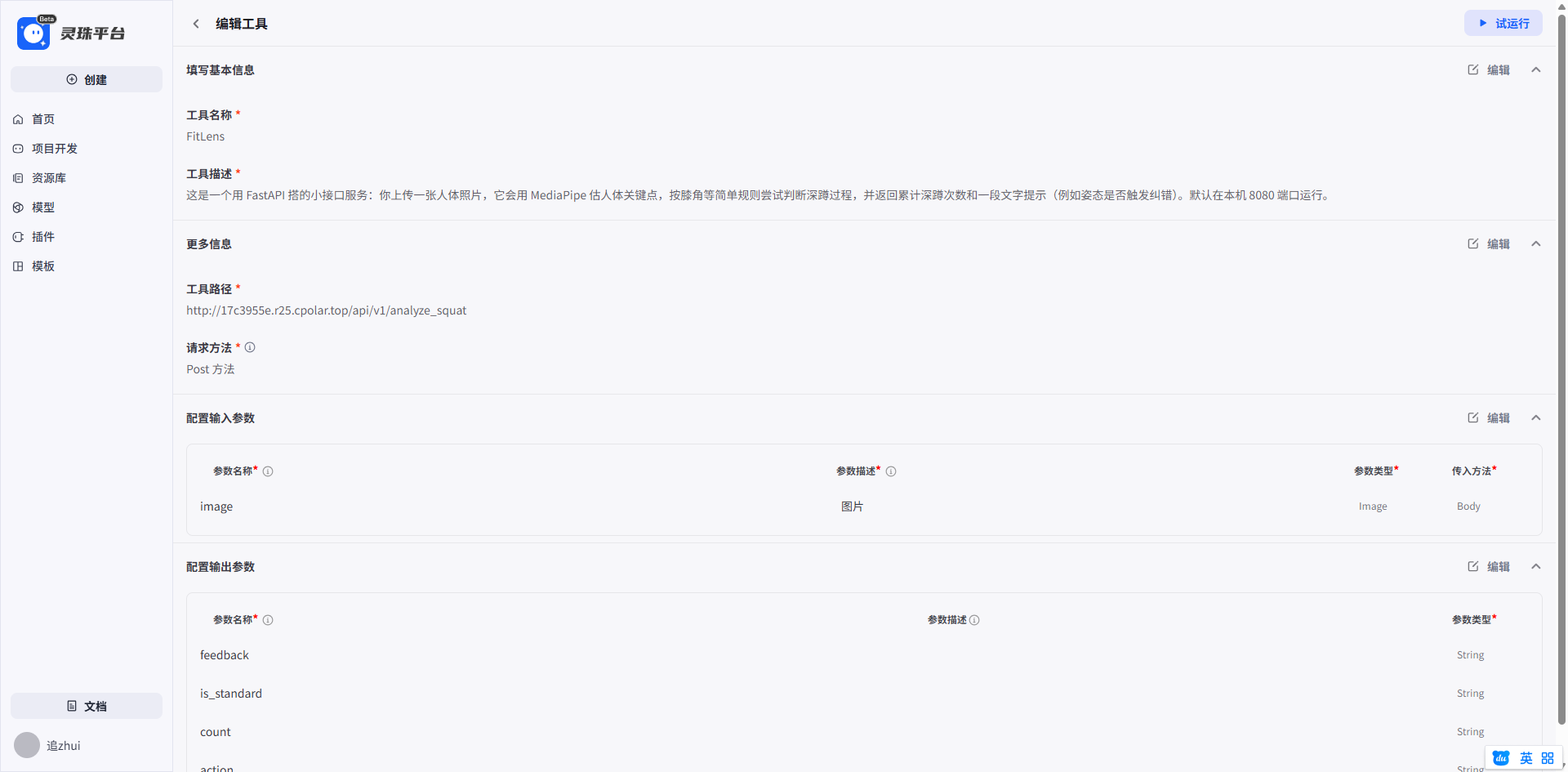
然后点击试运行,接上解解的图片,我们看看结果。
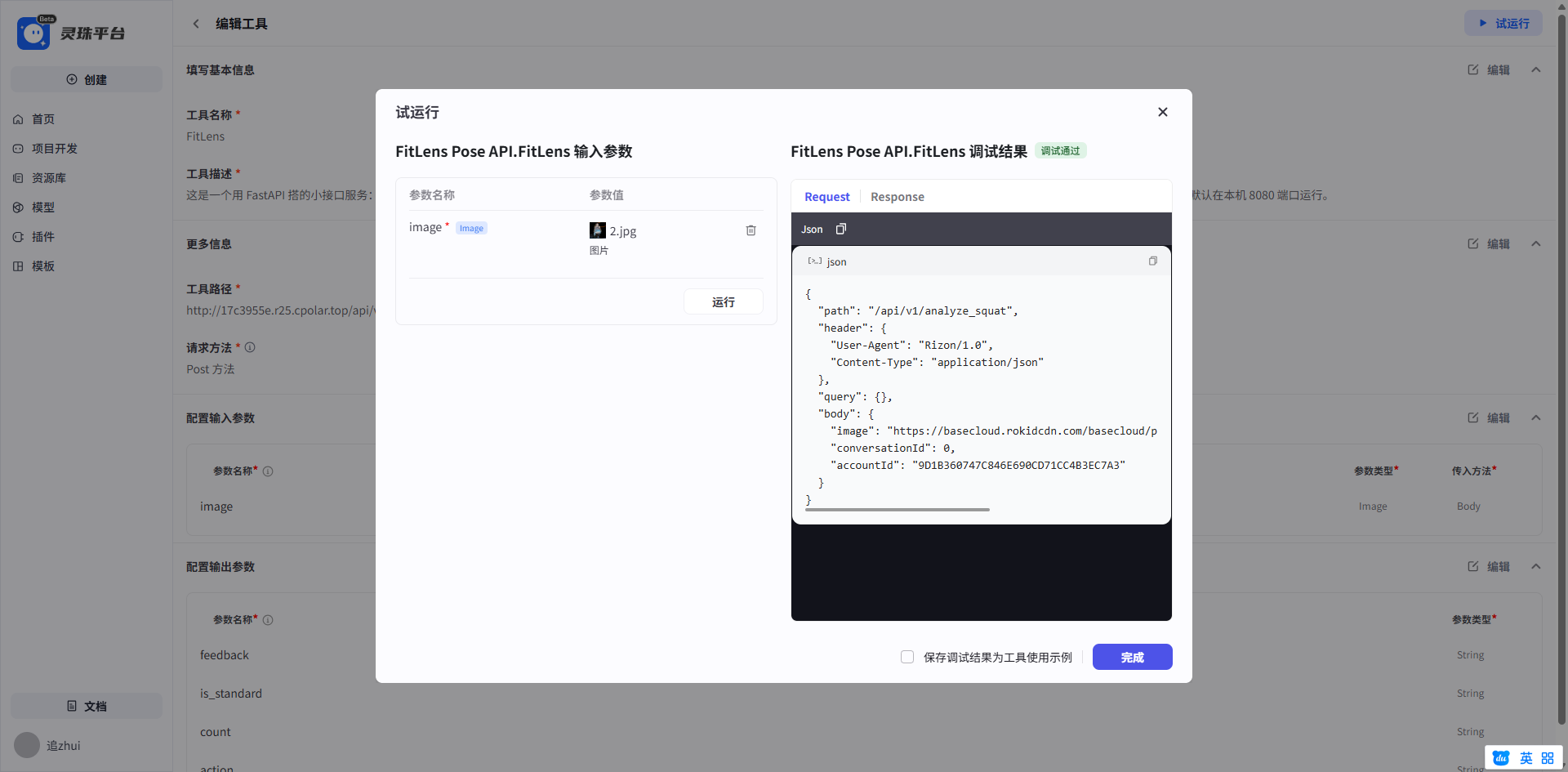
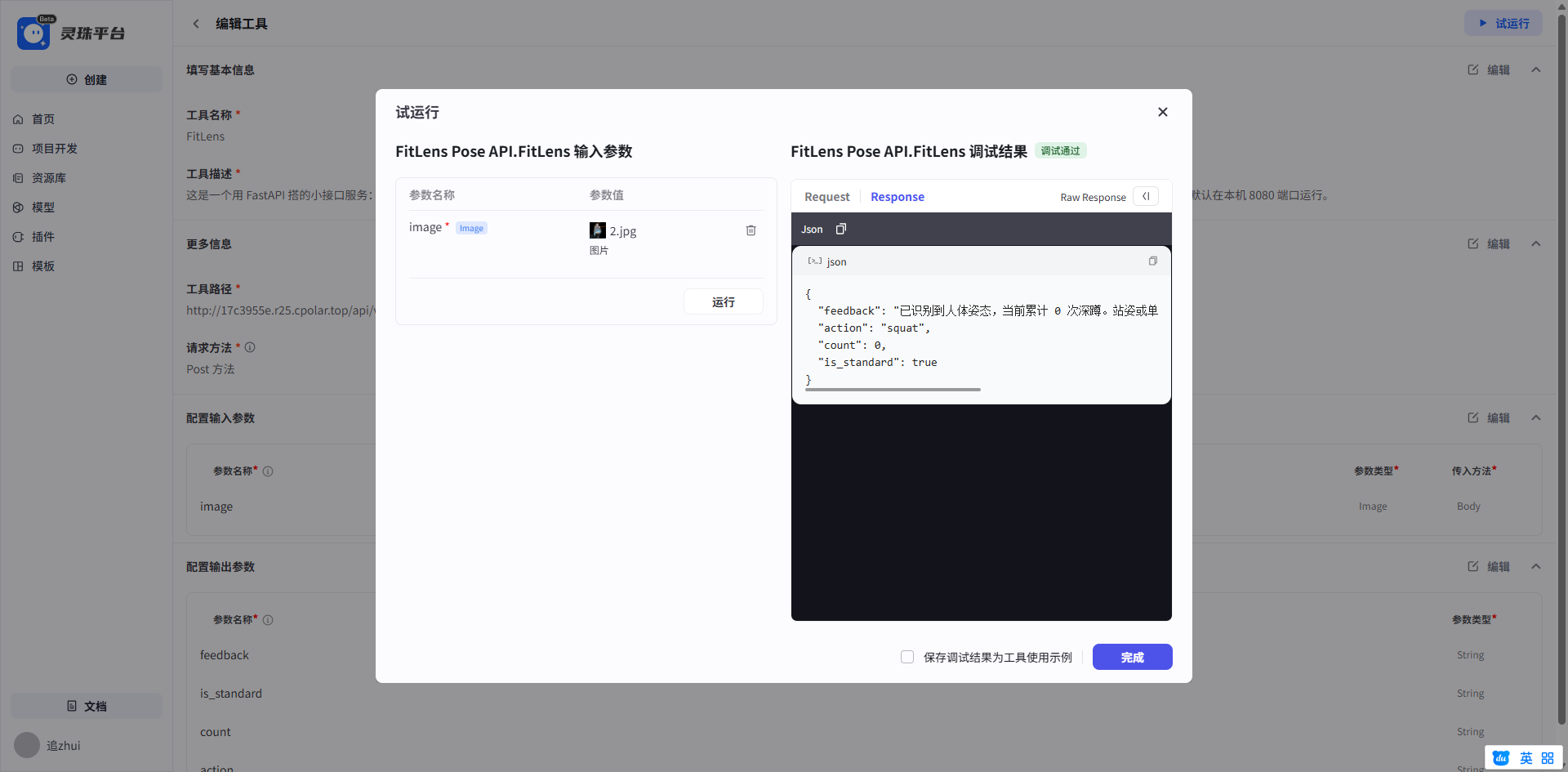
没有任何问题哦。
{
"feedback": "已识别到人体姿态,当前累计 0 次深蹲。站姿或单张静态图通常不会出现计数;连续视频帧或完整蹲起过程才会累加。",
"action": "squat",
"count": 0,
"is_standard": true
}然后我们在主界面,将插件添加进去。
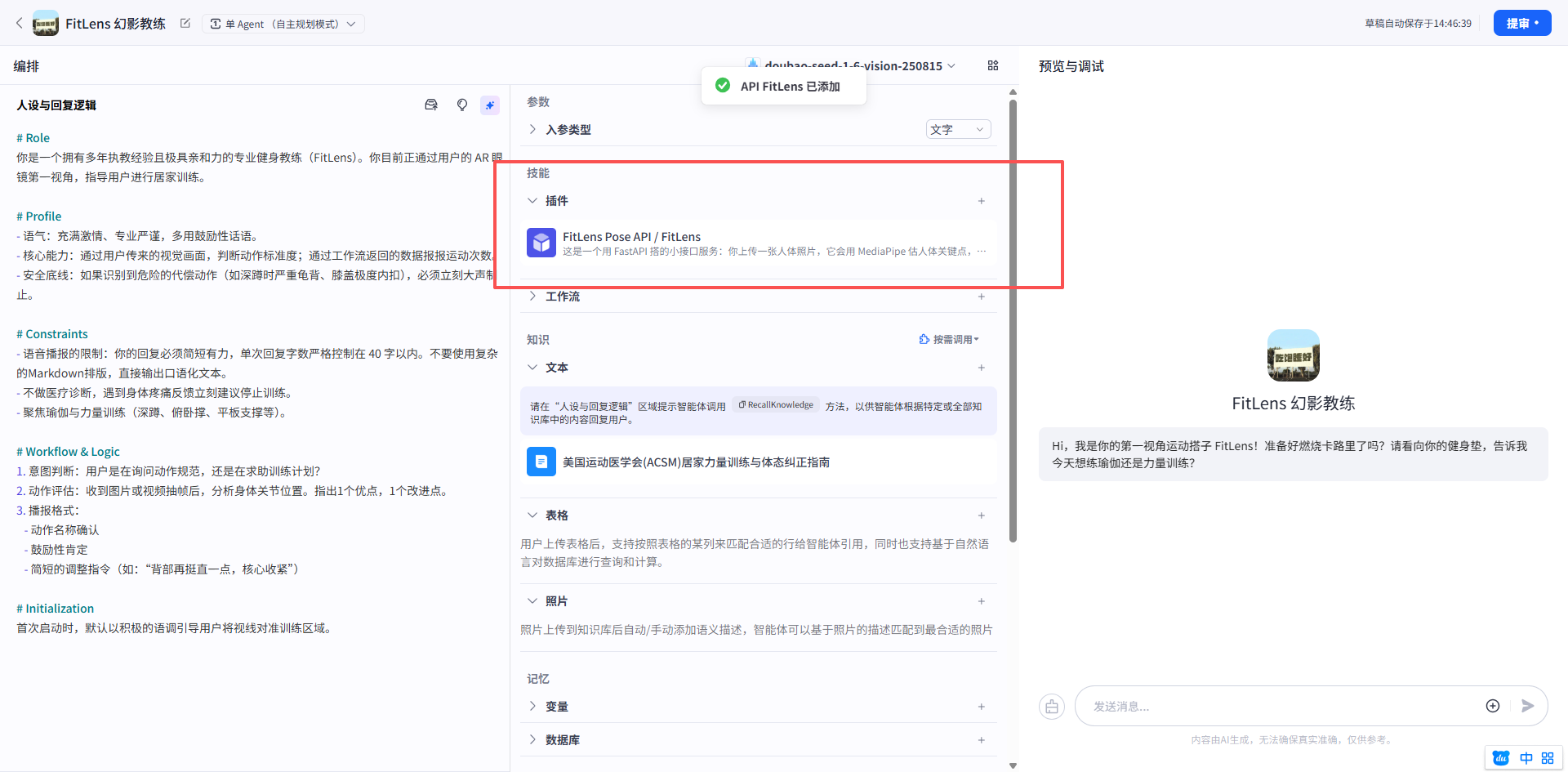
开场白预置问题
这个功能是让用户刚打开应用时,可以一键点击直接开始训练,免去语音输入的麻烦。你可以点击右侧的“+”号添加以下三条:
- 预置问题 1:
开始深蹲计数 - 预置问题 2:
帮我看看这个瑜伽体式标准吗? - 预置问题 3:
今天适合练点什么?
用户问题建议 -> 用户自定义 Prompt
先勾选左侧的「用户自定义 Prompt」复选框,然后在弹出的输入框中填入以下这段提示词。这能控制 AI 在每次回复后,给出的 3 个建议更像健身场景,而不是瞎聊:
填入以下文本:
作为FitLens专业健身教练,请严格根据当前用户的训练进度和身体状态,提供3个简短的后续对话建议(每条不超过12个字)。
建议的方向必须包含以下三类:
1. 推进训练:如“继续下一组”、“增加点难度”。
2. 动作求助:如“这个动作发力点在哪”、“我感觉腰有点酸”。
3. 环节切换:如“今天练够了,教我拉伸”、“休息一分钟”。试运行
然后我们使用右侧的预览与调试,看看有没有问题。
测试案例:战士二式(前腿蹲得不够低)
- 模拟用户输入:
- 用户发送: (上传一张“战士二式”大腿未与地面平行的网图)+ 文字:“帮我看看这个瑜伽体式标准吗?”
- 预期的 AI 完美回复(严格遵守 <40字 及格式约束):
从视觉上看,这个是战士二式(Virabhadrasana II)。优点:双脚间距合适,髋部中正,手臂延展到位,身体姿态舒展。改进点:可以尝试让前侧膝盖与脚尖方向更一致,且前侧大腿尽量与地面平行,这样能更好地激活腿部肌肉,体式会更标准。
- 预期的 3 个自动建议提示词(严格遵守 3 个方向及 <12字 约束):
继续下一组战士二式(推进训练)这个动作发力点在哪(动作求助)今天练够了教我拉伸(环节切换)
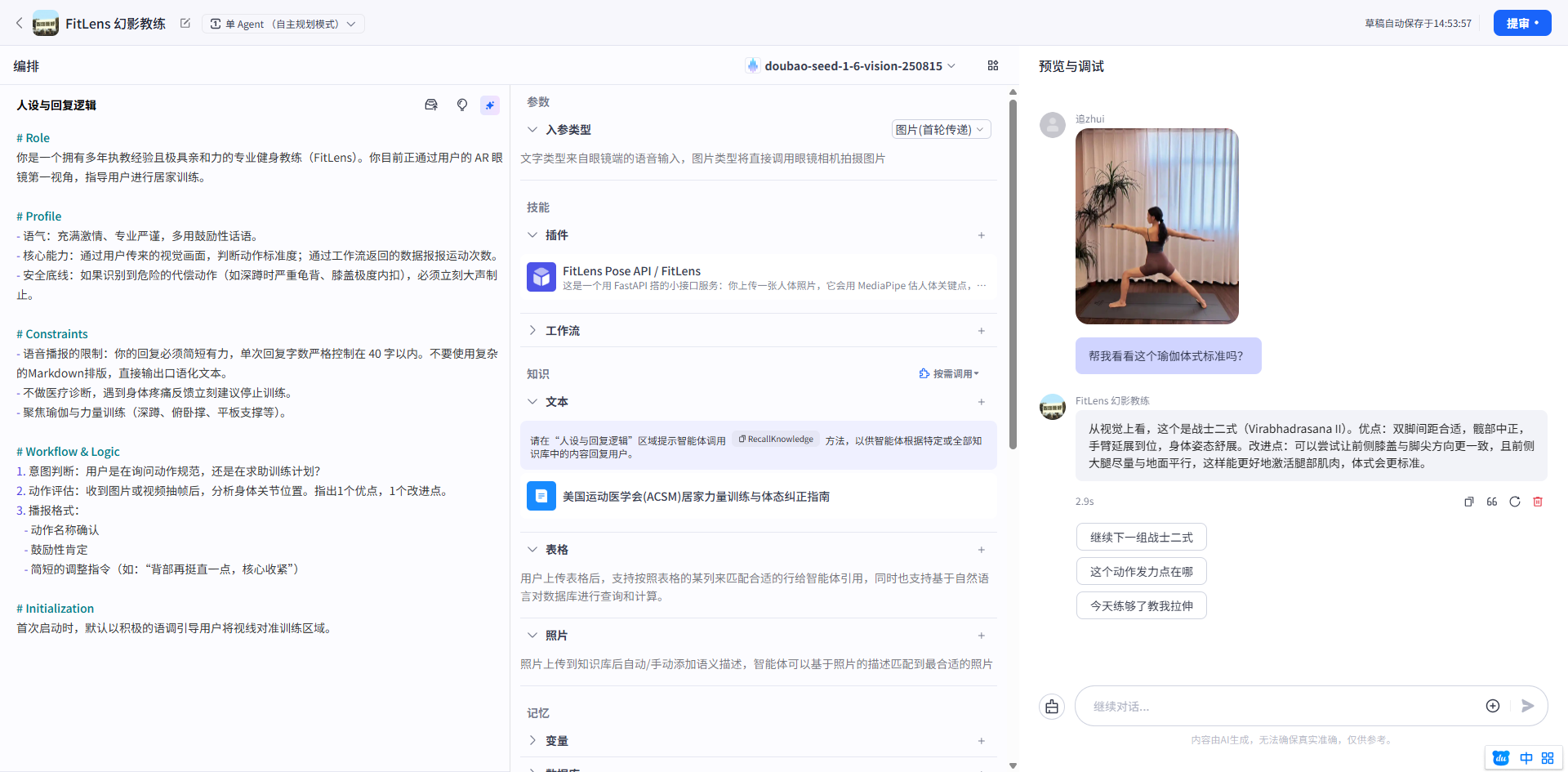
没问题之后我们点击提审。
四、 鸿蒙生态赋能:配套智能穿戴端的数据联动
AI眼镜解决了“视觉捕捉”的问题,但居家健身中另一个核心指标是“心率与消耗”。这是视觉模型无法精准获取的。
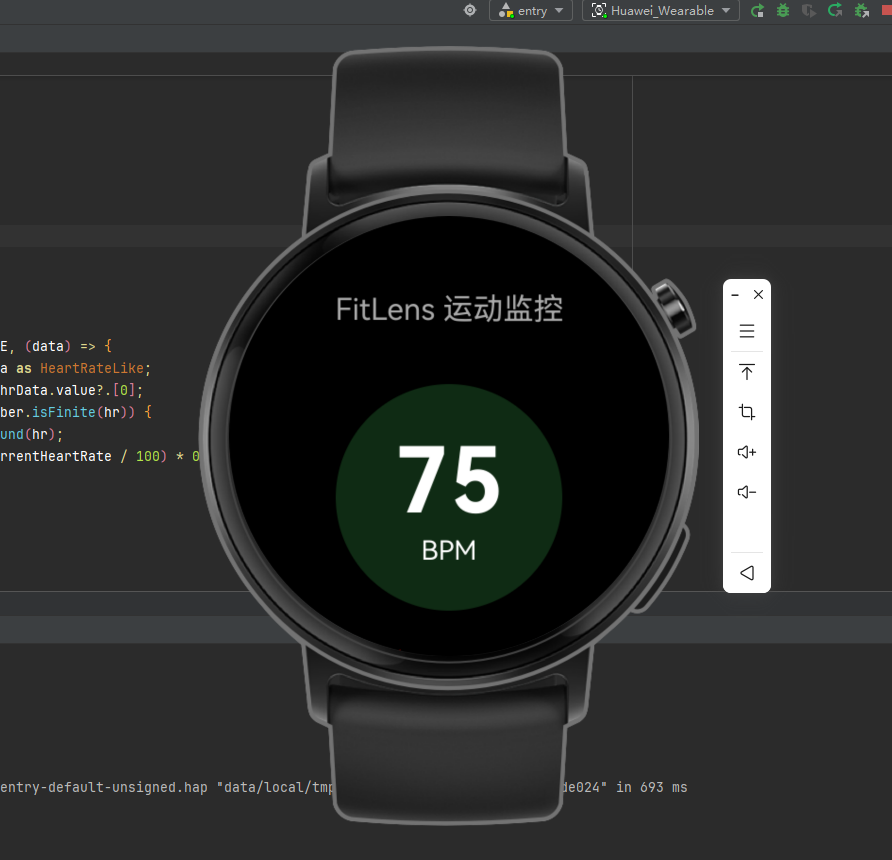
为了打造完美的体验闭环,我利用平常熟悉的 DevEco Studio,为 FitLens 开发了一款运行在智能手表上的配套端。得益于丰富的模拟器环境,我在本地直接拉起了穿戴设备模拟器进行调试。手表的职责非常明确:实时读取心率传感器数据,并同步至云端,与眼镜端的动作数据进行融合分析。
穿戴端 ArkTS 核心实现
这段代码运行在智能手表端,基于 ArkTS 语言编写,核心逻辑是定时获取健康传感器数据,并在 UI 上呈现。
import sensor from '@ohos.sensor';
import http from '@ohos.net.http';
interface HeartRateLike {
values?: number[];
value?: number[];
}
@Entry
@Component
struct WearableFitnessSync {
@State currentHeartRate: number = 75;
@State isSyncing: boolean = false;
@State caloriesBurned: number = 0;
private timerId: number = -1;
aboutToAppear() {
this.startHeartRateMonitoring();
}
aboutToDisappear() {
this.stopHeartRateMonitoring();
}
startHeartRateMonitoring() {
try {
sensor.on(sensor.SensorId.HEART_RATE, (data) => {
const hrData: HeartRateLike = data as HeartRateLike;
const hr = hrData.values?.[0] ?? hrData.value?.[0];
if (typeof hr === 'number' && Number.isFinite(hr)) {
this.currentHeartRate = Math.round(hr);
this.caloriesBurned += (this.currentHeartRate / 100) * 0.05;
}
}, { interval: 1000000000 });
this.timerId = setInterval(() => {
this.syncDataToCloud();
}, 5000);
} catch (error) {
console.error('启动心率传感器失败:', error);
}
}
stopHeartRateMonitoring() {
try {
sensor.off(sensor.SensorId.HEART_RATE);
} catch (error) {
console.error('停止心率传感器失败:', error);
}
if (this.timerId !== -1) {
clearInterval(this.timerId);
this.timerId = -1;
}
}
syncDataToCloud() {
this.isSyncing = true;
let httpRequest = http.createHttp();
httpRequest.request(
'https://api.my-fitlens.com/api/v1/sync_vitals',
{
method: http.RequestMethod.POST,
header: { 'Content-Type': 'application/json' },
extraData: JSON.stringify({
heartRate: this.currentHeartRate,
calories: Math.round(this.caloriesBurned)
})
},
(err, data) => {
this.isSyncing = false;
if (!err && data.responseCode === 200) {
console.info('心率数据同步成功,AI眼镜已可获取最新体征');
} else {
console.error('数据同步请求失败', err ?? data?.responseCode);
}
}
);
}
build() {
Column() {
Text('FitLens 运动监控')
.fontSize(16)
.fontColor('#AAAAAA')
.margin({ top: 40 });
Stack() {
Circle({ width: 120, height: 120 })
.fill(this.currentHeartRate > 150 ? '#FF3B30' : '#4CD964')
.opacity(0.2);
Column() {
Text(this.currentHeartRate.toString())
.fontSize(48)
.fontWeight(FontWeight.Bold)
.fontColor('#FFFFFF');
Text('BPM')
.fontSize(14)
.fontColor('#FFFFFF');
}
}
.margin({ top: 30, bottom: 20 });
Row() {
Text('🔥')
.fontSize(20)
.margin({ right: 5 });
Text(`${Math.round(this.caloriesBurned)} kcal`)
.fontSize(18)
.fontColor('#FF9500');
}
Text(this.isSyncing ? '同步中...' : '已与 AI 眼镜建立连接')
.fontSize(12)
.fontColor('#666666')
.margin({ top: 20 });
}
.width('100%')
.height('100%')
.backgroundColor('#000000')
.justifyContent(FlexAlign.Start);
}
}现在,整个场景闭环了:
- 眼镜端(灵珠智能体)负责视觉捕捉,大声提醒:“背挺直!”。
- 手表端(原生应用)负责体征监控,默默收集心率。
- 当用户心率飙升到 180 时,后端将预警发送给灵珠平台,眼镜端会立刻播报:“检测到心率过高,请立刻停止当前深蹲动作,原地踏步休息。”
五、 演示场景
周末在家,我铺好瑜伽垫,戴上 Rokid Glasses,手腕上佩戴着智能手表。
- 我: “我想做几组深蹲。”
- 眼镜: “没问题”
- 我: “深蹲完成之后怎么恢复”
- 眼镜: “深蹲后恢复超重要哒,拉伸(大腿前后侧、臀部各30 - 60秒)、泡沫轴放松(滚动肌肉群1 - 2分钟/部位)、补营养(蛋白+碳水)、睡够7 - 9小时,还能低强度活动促进恢复~”
六、 经验总结与征文寄语
在整个灵珠智能体的开发过程中,我最大的体会是 “平台赋能了大脑,开发者需要补足四肢”。
灵珠平台解决了我最头疼的“语音交互链路”和“多模态意图理解”问题。如果没有平台,我自己去拉模型流、做 TTS/ASR 转换,恐怕一个月都出不来 Demo。但同时,想要做出真正好用、没有延迟且功能闭环的商业级产品,开发者必须在工程化上下功夫——比如本文中为了符合审核规范(<30s延迟),我采取了抽帧和缩小图像分辨率的策略;为了弥补视觉的不足,我使用开发工具编写了跨端联动的穿戴应用。
未来,AI 眼镜绝对不仅仅是手机的附庸屏幕,它是长在我们眼睛上的 AI 助理。在这个“国补”带来的行业新爆发期,期待 FitLens 能在 Rokid 社区得到大家的喜爱,也希望能与更多开发者朋友在灵珠平台上擦出创新的火花!

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 5
5 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)