
【卷卷漫谈】DeepSeek V4 背后那条没退路的山路
DeepSeek V4 还有不到两周发布,但它背后那条路——从 CUDA 转向华为昇腾 CANN 框架——才是这篇文章真正想说的。这是一个关于"代价"的故事。今天是 2026 年 4 月 17 日。DeepSeek V4 还没发布。从去年年底开始,"V4 下周发布"这个消息已经流传了不下十次。春节前说要发,没发。3 月初外媒预测 3 月 2 日,没发。3 月底服务器大规模瘫痪,大家以为是在做上线前
结论:DeepSeek V4 还有不到两周发布,但它背后那条路——从 CUDA 转向华为昇腾 CANN 框架——才是这篇文章真正想说的。这是一个关于"代价"的故事。

今天是 2026 年 4 月 17 日。
DeepSeek V4 还没发布。
从去年年底开始,"V4 下周发布"这个消息已经流传了不下十次。春节前说要发,没发。3 月初外媒预测 3 月 2 日,没发。3 月底服务器大规模瘫痪,大家以为是在做上线前的压力测试,还是没发。
直到 4 月 10 日,梁文锋才正式确认:V4 将于 4 月下旬发布。
还有不到两周。
但我今天不想聊 V4 有多强。它难产的真正原因——华为昇腾适配——才是有意思的部分。
先说 V4 本身
从目前流出的信息看,核心升级有三个:
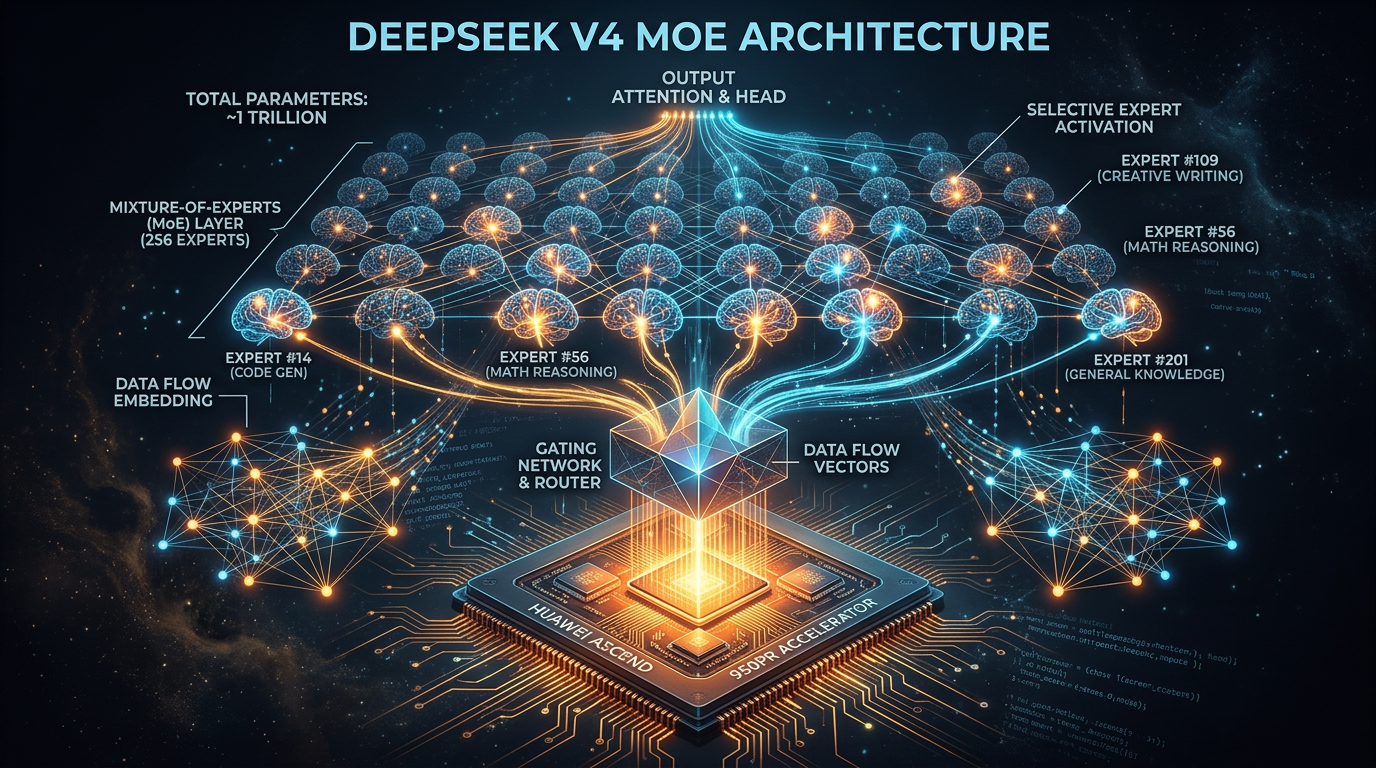
参数规模:671B → 约 1T
V3 是 671B 总参数,每次推理激活 37B。V4 预计翻到约 1 万亿,但激活参数量基本没变,还是 32-37B 左右。
这是 DeepSeek 一直在坚持的 MoE 路线——256 个专家子网络,每次只激活其中 8 个。参数多了覆盖的知识面更广,但计算量不会等比例增加。简单说:用更少的算力,激活更精准的知识。
上下文:128K → 1M token
百万级上下文。可以把一整个代码仓库、一整本书、几十份合同全部塞进去,让它在完整语境下处理。
Engram 条件记忆:把"背书"和"推理"分开
这是 V4 最有意思的设计,来自 DeepSeek 今年 1 月发表的论文。
传统 Transformer 的注意力机制有个根本问题:既要靠注意力去检索上下文中的知识,又要靠注意力去做推理。这两个任务互相干扰——检索需要广撒网,推理需要深聚焦。
Engram 的思路是:用 O(1) 哈希查找替代注意力检索。把模型的静态知识存进一个可扩展的查找表,推理时直接"翻字典",不需要通过注意力去"回忆"。注意力机制被解放出来,专心做推理。
效果:在 27B 测试模型上,Needle-in-Haystack 准确率从 84.2% 跳到了 97%。
然后说那条辛苦的路
V4 最大的新闻不是它有多少参数,而是:它将完全运行在华为昇腾 950PR 芯片上,技术架构从 CUDA 全面转向 CANN 框架。
这句话背后是什么,我慢慢说。
CUDA 的护城河有多高
先说清楚 CUDA 是什么。
CUDA 是英伟达的编程框架,全球 90% 的 AI 开发者都在用它。十几年积累的框架、库、工具链,构成了一道几乎无法撼动的生态壁垒。PyTorch、TensorFlow、vLLM、SGLang——这些你听过的名字,全都深度依赖 CUDA。
黄仁勋说过一句话:"计算不是冰箱,今天用这个明天换那个。从 CUDA 工具链到 PyTorch 框架,从模型训练到部署运维,开发者在英伟达生态上沉淀了数年心血。一个资深 AI 工程师的迁移成本,可能比买 100 块 GPU 还高。"
这话说得很准。想不用英伟达?可以。但你得重写所有代码,重新优化所有算法,重新培训所有工程师。这个成本,大到让绝大多数公司望而却步。
这就是为什么,即便在制裁背景下,国内大厂依然在通过各种渠道抢购 A100、H100——不是不想用国产,是不敢冒险。
昇腾的脾气有多难驯
华为昇腾采用达芬奇架构,和 GPU 有本质区别。
GPU 里有成千上万个 CUDA Core 并行计算。昇腾 NPU 里,计算核心是 AI Core,内部主要包含两个单元:Cube Unit(矩阵运算)和 Vector Unit(向量运算)。
关键点在这里:Cube Unit 非常强,Vector Unit 相对弱。
这意味着,如果你的模型算子能被编译成矩阵乘法,在昇腾上就是起飞;如果充斥着大量零碎的向量计算,性能就会大打折扣。
DeepSeek 的 MoE 架构里,有大量的专家路由计算、稀疏激活、动态调度——这些都不是标准的矩阵乘法,在昇腾上跑起来,需要从底层算子开始重新优化。
更麻烦的是内存。V4 有 1T 参数,256 个专家,每个专家大约 2.5G。普通 64GB 内存的 AI 硬件根本扛不动,必须依赖集群协作。专家分布在不同芯片上,数据传输耗时甚至超过计算时间——就像团队成员频繁开会沟通,效率大打折扣。
还有 MLA(多头隐式注意力机制)。这个机制虽然压缩了数据空间,却导致中间变量激增,对芯片的计算能力提出更高要求。
这些问题,在英伟达上有成熟的解决方案,在昇腾上,得从头趟。
他们是怎么趟过来的
DeepSeek 没有等昇腾"成熟"了再用,而是深度参与到了芯片优化过程中。
算法层面,自研的 MLA 架构大幅降低了训练和推理的算力需求。别人需要 100 张卡干的活,他们只需要 60 张。这不是靠硬件,是靠算法把需求降下来。
软硬协同层面,DeepSeek 和华为工程师一起,从底层驱动到上层框架,把每一个环节都抠到了极致。用 KernelCAT 等专项优化工具,针对昇腾的 Cube Unit 特性重写了核心算子。
量化层面,采用 SmoothQuant 技术,对模型进行 A8W8 动态量化,把 FP16 精度压缩到 FP8/FP4,显存占用骤降。700 亿参数模型用 FP16 需要 140GB 显存,用 FP4 只需要 35GB——过去需要三张 H20 才能加载的模型,现在单卡就能跑。
集群层面,华为推出 Atlas 950 超节点,支持 8192 张昇腾 950DT,FP8 算力规模达到 8EFLOPS。这不是靠单卡性能碾压,是靠集群化的系统架构来弥补单点差距。
已有实测数据显示,在昇腾 910B 上部署 DeepSeek-V3.2-Exp 时,128K 长序列的首 Token 延迟低于 2 秒,每输出 Token 时间小于 30ms。V4 进一步优化后,预计推理成本可降至英伟达方案的三分之一。
但这些成果是用多少个日夜换来的,没有人说。
还有一件事:英伟达和 AMD 被拒之门外
今年 4 月,路透社报道了一个细节:DeepSeek 拒绝给予英伟达和 AMD 早期优化访问权。
这不只是态度问题,是一个信号:他们已经决定彻底转向国产芯片生态。
英伟达和 AMD 以前是 DeepSeek 的"甲方"——模型在他们的芯片上跑,他们提供优化支持。现在这个关系反过来了。DeepSeek 把最新模型优先给华为、寒武纪这些国产厂商做适配测试,英伟达排在后面。
黄仁勋据说拍桌子了。
但这件事的逻辑很清楚:美国的芯片禁令,把 DeepSeek 逼到了华为怀里。制裁越紧,国产替代的动力越强,适配的深度越深,最终形成的生态越难被打破。最讽刺的"反向助推器"。
V4 在这个时间节点的竞争位置
|
维度 |
DeepSeek V4(预期) |
Claude Opus 4.7 |
GPT-5.4 |
|
参数规模 |
~1T(MoE,激活 37B) |
未公开 |
未公开 |
|
上下文窗口 |
1M token |
200K token |
1M token |
|
编程能力 |
预期对标顶尖 |
SWE-bench Pro 64.3% |
SWE-bench Pro 57.7% |
|
芯片依赖 |
华为昇腾(国产) |
英伟达 |
英伟达 |
|
开源 |
是 |
否 |
否 |
|
推理成本 |
预期为英伟达方案 1/3 |
$5/百万 token |
$2.5/百万 token |
V4 最大的差异化在于两件事:开源 + 国产芯片。
开源意味着全球开发者可以自己部署、自己优化、自己魔改。这是 Claude 和 GPT 永远给不了的东西。
国产芯片意味着,在英伟达被禁售的市场里,V4 是唯一能跑起来的顶尖模型。中东、东南亚、拉美……这些不受美国限制的市场,正在用脚投票。中东某主权基金的 AI 项目负责人公开说:"我们不在乎芯片是美国的还是中国的,只要模型效果好、部署成本低。昇腾 + DeepSeek 的组合,已经帮我们省了 40% 的算力支出。"
一个感受
V4 难产这件事,让我想起一个词:代价。
在 CUDA 生态里做大模型,就像在一条修好的高速公路上开车——路是平的,工具是现成的,踩油门就行。
在昇腾上做大模型,是在山里开路。路没有,工具不顺手,每走一步都要先解决一个没人解决过的问题。
V4 难产,不是因为 DeepSeek 的团队不够强。恰恰相反,正是因为他们选了一条更难的路——在算力受限、生态不成熟、工具链残缺的条件下,硬是把一个万亿参数的模型训出来,还要让它跑在国产芯片上。
这件事的意义,不只是一个模型发布。
它是第一次有人证明:不靠英伟达,也能训出世界级的大模型,还能让它在国产芯片上高效运行。
这条路走通了,后面的人就有路可走了。
V4 还有不到两周就要来了。
等它。

数据来源:梁文锋内部沟通(2026年4月10日)、路透社报道、华为昇腾官方技术报告(2026年4月)
注:V4 参数规模、架构细节均为基于代码分析和供应链信息的推测,官方尚未最终确认。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)