
学习 Ascend C 必须掌握的硬件知识
学习 Ascend C 必须掌握的硬件知识写在最前面一、 宏观视角:昇腾处理器的“前店后厂”1.1 异构计算的指挥与执行1.2 Da Vinci 架构的“计算工厂”二、 深入车间:AI Core 的“三驾马车”2.1 控制单元:不仅仅是发指令2.2 计算单元:暴力的“方”与灵活的“圆”A. Cube Unit(矩阵计算单元):暴力的“方”B. Vector Unit(向量计算单元):灵活的“圆”?
学习 Ascend C 必须掌握的硬件知识

写在最前面
版权声明:本文为原创,遵循 CC 4.0 BY-SA 协议。转载请注明出处。
学习 Ascend C 必须掌握的硬件知识
写在最前面
算法工程师从 PyTorch/TensorFlow 下沉到 Ascend C 算子开发时,往往会撞上一堵“隐形的墙”。
你可能会问:
● “为什么我的代码逻辑是对的,但性能只有官方算子的 1/10?”
● “为什么要手动切分数据(Tiling)?不能像 Python 那样直接读吗?”
● “UB、L1、L0、L2 到底是什么鬼?为什么显存要分这么细?”
答案通常不在代码逻辑里,而在硬件架构里。
在 CPU/GPU 上写 Python 时,硬件是被编译器和驱动层层包裹的“黑盒”;但在 Ascend C 的世界里,你可以选择打开这个黑盒。
Ascend C 的核心哲学,就是将昇腾 AI 处理器(NPU) 的硬件资源控制权交还给你。
本文不聊虚的,我们将剥开 NPU 的外壳,拆解 Da Vinci(达芬奇)架构,带你理解高性能算子背后的物理原理。

一、 宏观视角:昇腾处理器的“前店后厂”
1.1 异构计算的指挥与执行
首先,我们要建立一个概念:昇腾 AI 处理器(如 Ascend 910)不是一个简单的计算器,而是一个分工明确的超级工业园区,一个典型的片上系统(SoC)。
当我们说“跑个算子”时,实际上涉及了两个地盘:
1. Host(主机侧):相当于园区的“总调度室” (通常是 x86 或 ARM CPU)。它负责编译代码、分配资源、发号施令。
2. Device(设备侧):全功能的“数字化超级工厂” 。这里有成百上千个干活的单元,
包含多个关键部门:
● AI Core(达芬奇架构算力核心):这是工厂里最核心的“重型流水线”,专门负责矩阵乘法等高强度的张量计算(Tensor)和向量计算(Vector)。
● Control CPU(控制 CPU):这是驻扎在工厂里的**“车间主任”**。它负责处理设备侧的逻辑判断、任务调度,确保流水线(AI Core)能专注于计算,而不被复杂的控制流程打断。
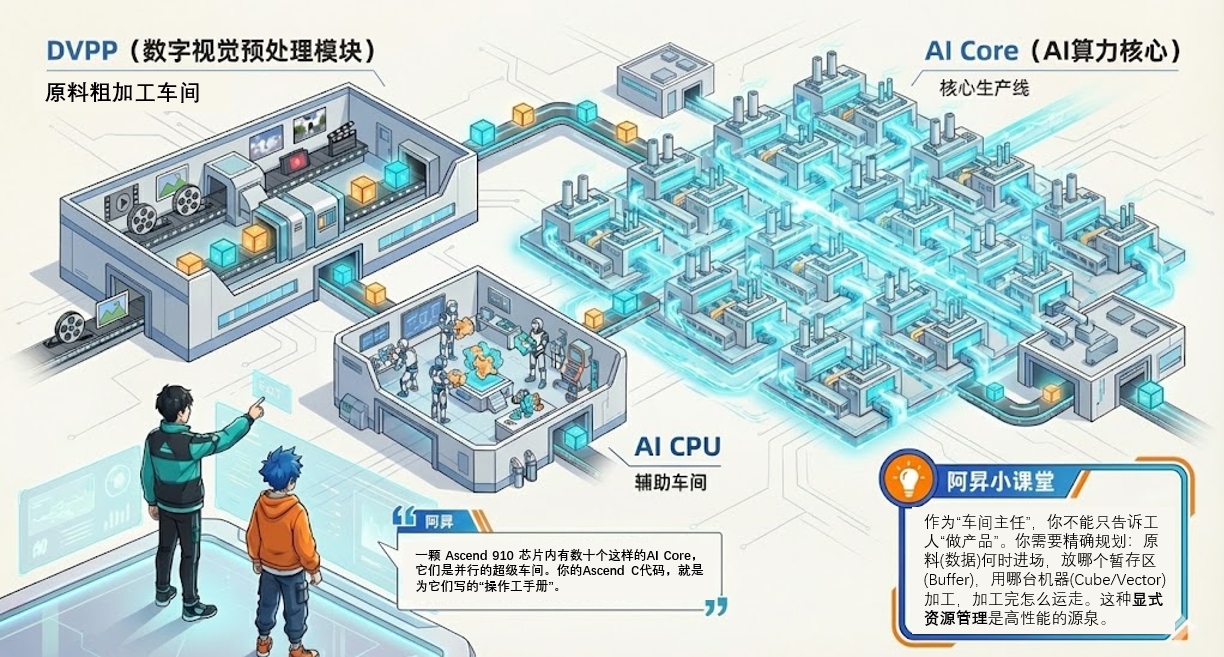
● 其他加速单元:如负责图像视频预处理的 DVPP(数字视觉预处理模块),相当于工厂的“原料预处理车间”。
3.
Ascend C 代码,核心就是运行在这些 AI Core 里的“操作工手册”。
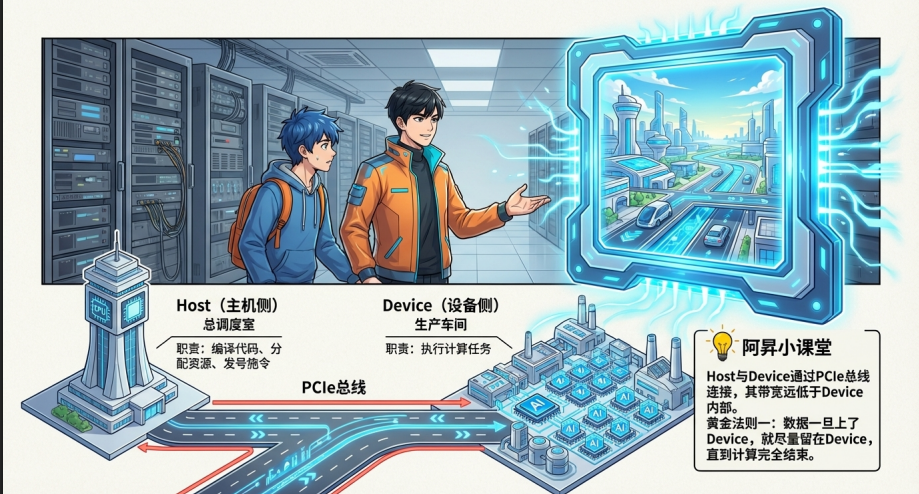
Ascend C 的运行环境建立在Host(主机)与Device(设备) 的异构协作之上。这种协作关系类似于现代化的“前店后厂”模式。
| 组件 | 角色 | 硬件实体 | 职责描述 | Ascend C 视角 |
|---|---|---|---|---|
| Host | 指挥官 | X86/ARM 服务器 CPU | 负责运行操作系统、AI 框架、编译算子、下发任务。 | 负责算子编译、内存分配、内核启动(Kernel Launch)。 |
| Device | 执行者 | Ascend NPU 芯片 | 负责接收 Host 下发的指令流,执行高密度的矩阵与向量计算。 | 算子内核(Kernel)的实际驻留地,代码在此处并行执行。 |
💡核心知识点:Ascend C 采用 Host–Device 异构协同机制,其中 Host 侧主要负责运行时管理与 Tiling 参数计算,Device 侧执行 Kernel 核函数,完成矩阵、向量等计算密集型任务。对算子开发者而言,Device 侧数据流组织的优化点在:根据 Tiling 信息安排 Global Memory 与 Local Memory 之间的数据搬运,并尽量复用片上存储,减少不必要的搬入搬出和中间结果回写,通过流水线与双缓冲等手段提升执行效率。
1.2 Da Vinci 架构的“计算工厂”
我们可以将整个昇腾 AI 处理器想象成一个巨大的现代化制造工厂:
● SoC(片上系统): 整个厂区。
● DVPP(数字视觉预处理模块):原料粗加工车间。专门负责图片解码、视频解压,将非结构化数据转化为 AI Core 能处理的张量。
● AI CPU:辅助车间。负责处理那些 AI Core 难以处理的复杂逻辑或不规则计算(如某些复杂的控制流),但效率较低。
● AI Core(AI 算力核心):核心生产线。这是 Ascend C 代码运行的主战场。一颗 Ascend 910 芯片内部集成了数十个这样的 AI Core,它们是并行的超级车间。
💡 核心知识点: 开发者在编写 Ascend C 算子时,实际上是在担任车间主任。你不能只告诉工人“做这个产品”,你需要精确地规划:原料(数据)什么时候进场,放在哪个暂存区(Buffer),用哪台机器(Cube/Vector)加工,加工完怎么运走。这种显式资源管理(Explicit Resource Management) 是高性能的源泉,也是开发难度的来源。
二、 深入车间:AI Core 的“三驾马车”
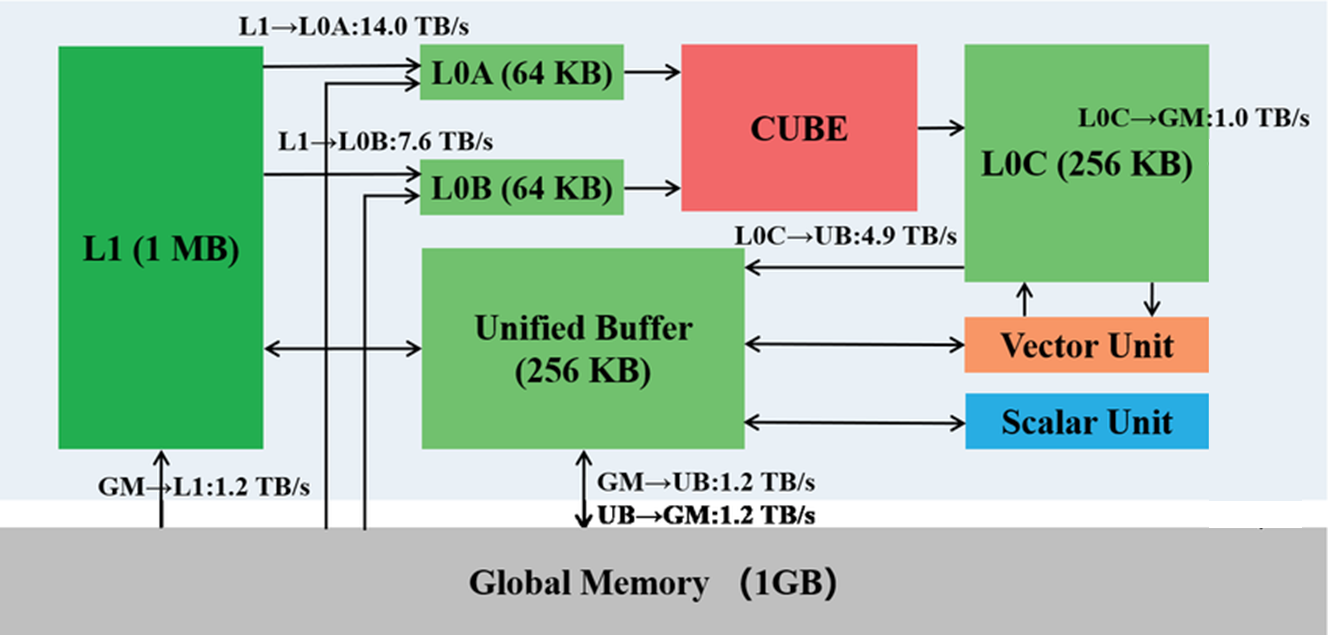
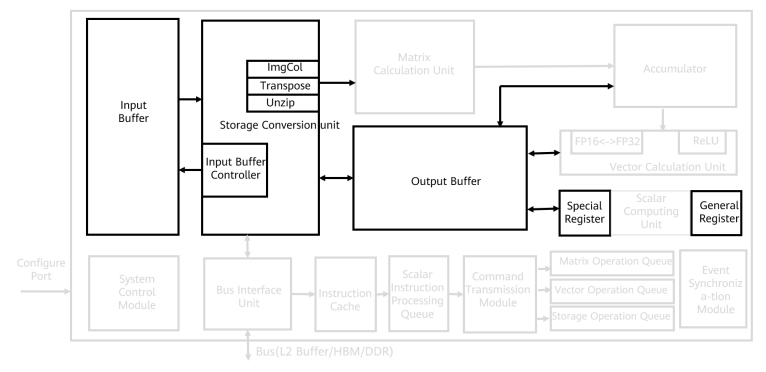
如果把一个 AI Core 比作一条独立生产线,那它主要由三个核心部门组成:控制(大脑)、计算(肌肉)、存储(物流)。
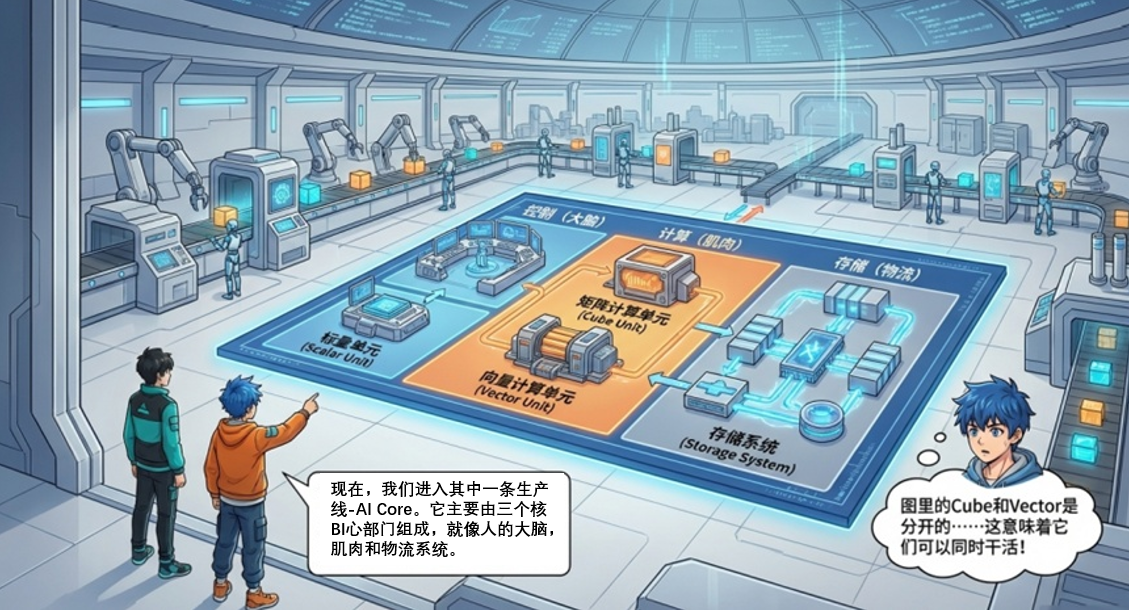
图1为Da Vinci 架构逻辑视图,即AI Core 内部结构图(Ascend 910)。
注意看 Cube、Vector 和 Scalar 的位置:Cube 和 Vector 是独立的,这意味着它们理论上可以同时干活!
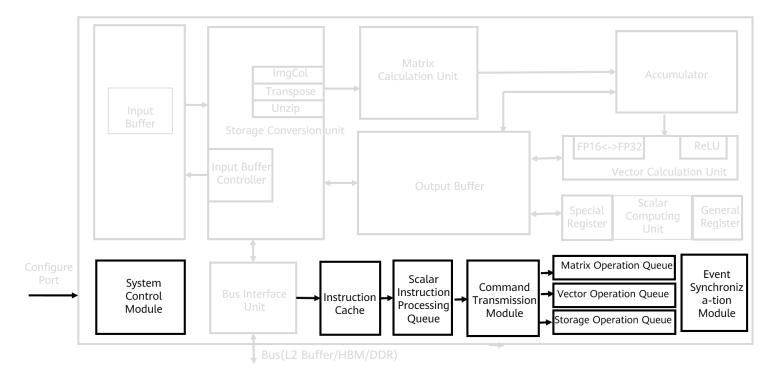
2.1 控制单元:不仅仅是发指令
图为Da Vinci具体架构 (AI Core)中的控制单元(Control Unit)。
指令执行队列(Instruction execution queue):包括矩阵运算队列、向量运算队列和存储转换队列。不同的指令进入相应的运算队列,队列中的指令按照进入顺序执行。
事件同步模块(Event synchronization module):实时控制各指令流水线的执行状态,并分析不同流水线之间的依赖关系,以解决指令流水线之间的数据依赖和同步问题。
AI Core 的大脑是标量单元(Scalar Unit)。很多初学者误以为 Ascend C 代码中的所有逻辑都由高算力的 Cube/Vector 执行,这是一个严重的误解。

● 角色:它是车间的“工长” 。
● 职责:
○ 程序流控制:处理 if/else 分支、for 循环计数。
○ 地址计算:计算数据在内存中的物理地址偏移量(这是极其繁重的工作,因为张量通常是多维的)。
○ 指令发射:读取指令流,如果是标量计算则自己执行;如果是向量或矩阵计算,则将其发射(Dispatch) 到对应的指令队列中,由 Vector 或 Cube 单元异步执行。
💡 核心知识点:在 Ascend C 代码中,当你写下 for (int i = 0; i < tileNum; i++) 时,这行代码是在标量单元上运行的。而循环体内的 Add() 或 Matmul() 只是被标量单元“踢”进了队列。这意味着,标量单元跑得比计算单元快。如果代码逻辑设计不当,标量单元可能早早跑完了整个循环,而计算单元的队列还没处理完,导致流水线失衡。
2.2 计算单元:暴力的“方”与灵活的“圆”
图为Da Vinci具体架构 (AI Core)中的计算单元(Computing Unit)。
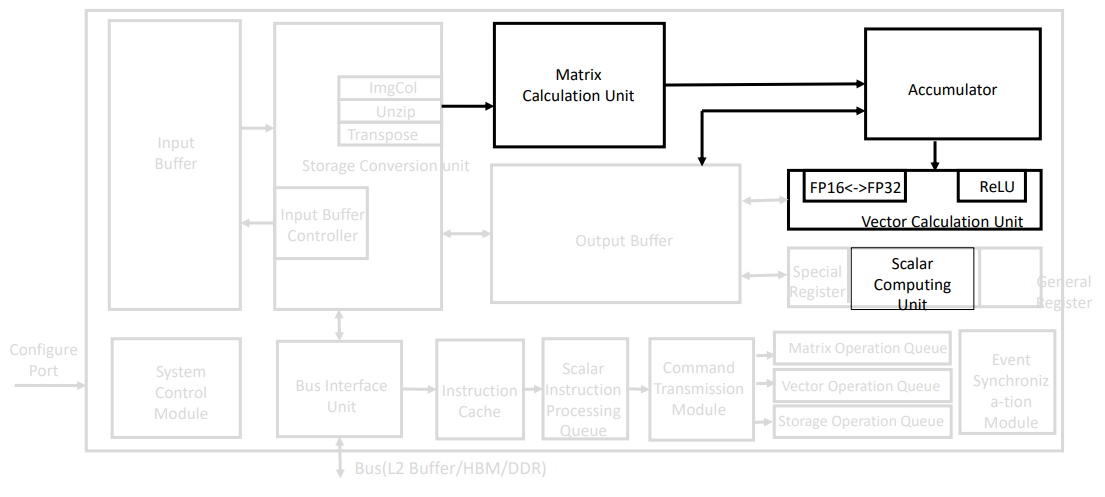
在 AI Core 内部,算力针对 AI 负载特征,分裂为两种极致专用的引擎。
A. Cube Unit(矩阵计算单元):暴力的“方”
● 翻译:这是一个专门用来做矩阵乘法的“重型压铸机”。
● 专长:它极其强壮,能在极短时间内算完 16 × 16 16 \times 16 16×16 的矩阵乘法 ( C = A × B + B i a s C = A \times B + Bias C=A×B+Bias)。
● 代码启示:它是算力担当,但它“挑食” 。它只能吃特定格式的数据(Fractal 分形格式)。如果你要算卷积或全连接层,必须把数据整理好喂给它。
B. Vector Unit(向量计算单元):灵活的“圆”
● 翻译:这是一把精密的瑞士军刀。
● 专长:处理所有 Cube 做不了的事情。包括 ReLU、Sigmoid、LayerNorm、Add 等点对点(Element-wise)运算。
● 掩码(Mask)机制:这是 Vector 编程的难点。如果你的数据不够填满一排(比如只有 30 个剩余元素,但机器一次算 128 个),你需要用 Mask 机制来“遮盖”不需要计算的通道,防止内存越界或计算错误。
🤔 深度思考:为何要分离 Cube 和 Vector?
为什么不设计一个通用的强大核心?
因为 AI 计算负载具有极端的两极分化特征:
1. 90% 的算力消耗在矩阵乘法(卷积层、全连接层),这需要极致的密度,灵活性要求低——交给 Cube。
2. 10% 的算力消耗在各种复杂的非线性操作(激活、归一化),这需要极致的灵活性,算力密度要求相对低——交给 Vector。
3. 这种分离设计使得 Ascend NPU 在同等芯片面积下,能塞进比主流硬件更多的矩阵算力,从而在 ResNet、BERT 等经典模型上表现出极高的能效比。
三、 存储系统:数据搬运的艺术(重点!)
图为Da Vinci具体架构 (AI Core)中的存储系统(Storage System)。
这个子版块是数据通道,人工智能核心在执行计算任务期间的数据流路径。
达芬奇架构的数据通道具有多输入单输出的特点。考虑到神经网络计算过程中输入数据的类型和数量庞大,并行输入可以提高数据流入效率。相反,在处理多种类型的输入数据后,仅生成一个输出特征矩阵。单输出数据通道减少了芯片硬件资源的消耗。
在现代 AI 芯片中,计算是廉价的,数据搬运是昂贵的。
Da Vinci 架构设计了一套极其复杂的片上存储层次,不仅是为了存数据,更是为了掩盖数据搬运的延迟。
3.1 存储层级金字塔
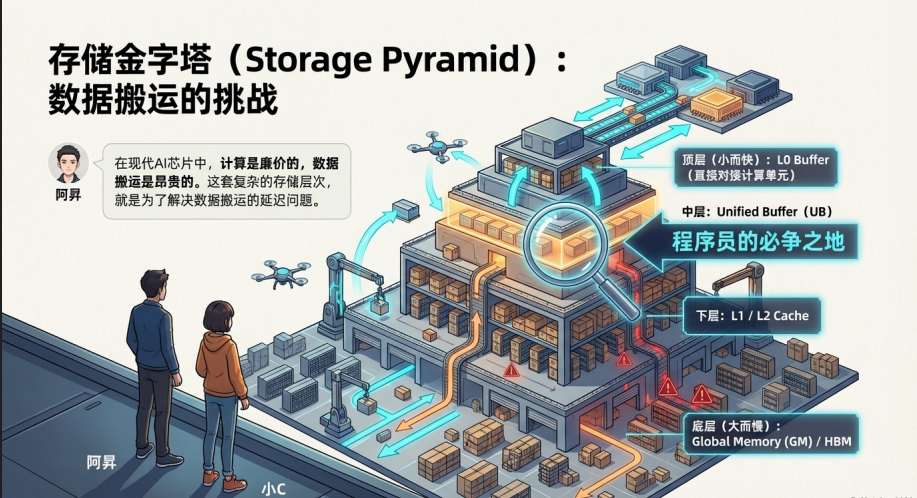
| 存储层级 | 物理位置 | 典型容量 | 速度 | 角色 | Ascend C 类型 |
|---|---|---|---|---|---|
| Global Memory (GM) | 片上芯片 | 32GB+ | 🐢 慢 | 总仓库。容量巨大,但距离计算单元最远。 | GlobalTensor |
| L2 Cache | 片上内存 (SoC级) | 192MB级 | 🚗 中 | 园区中转站。缓解总仓库压力,对程序员透明,但合理的切分能利用它。 | (硬件自动管理) |
| L1 Buffer | AI Core 内部 | 1MB 级 | 🚄 快 | 车间备料区。专门为 Cube 单元服务,暂存大块矩阵数据。 | (内部管理) |
| Unified Buffer (UB) | AI Core 内部 | 256KB级 | 🚀 极快 | 操作台。Vector 单元的独占工作区。 | LocalTensor |
| L0 Buffer | AI Core 内部 | KB 级 | ⚡ 光速 | 机床进料口。紧贴 Cube 单元。 | (内部隐式使用) |
3.2 统一缓冲区(Unified Buffer, UB):程序员的必争之地
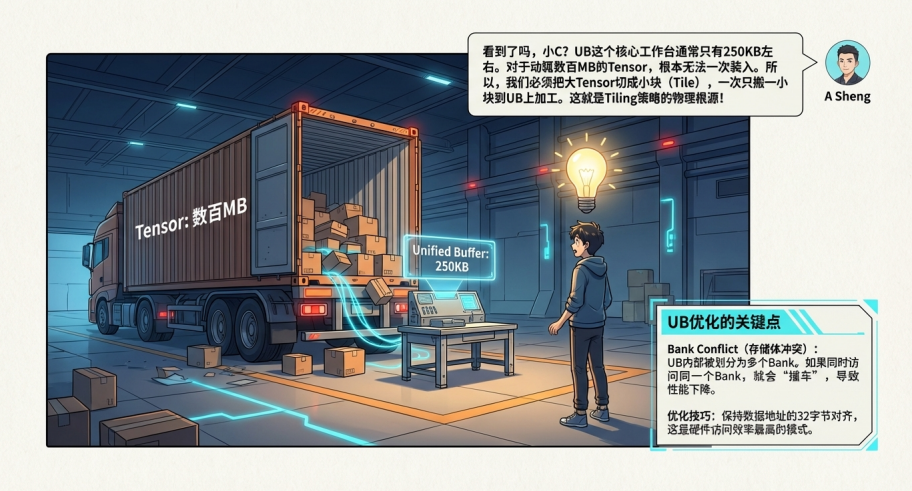
在 Ascend C 编程中,UB 是最核心的资源。
● 瓶颈所在: UB 通常只有 200KB-250KB 左右。对于动辄数百 MB 的 AI 模型 Tensor,显然无法一次装入。
● Tiling(切分)的根源: 因为 UB 放不下,所以我们必须把大 Tensor 切成小块(Tile)。每次只搬运一块到 UB,算完再搬回去。这就是 Ascend C 算子开发中核心步骤 Tiling 策略 的物理根源。
● Bank Conflict(存储体冲突): UB 被物理划分为多个 Bank(存储体)以支持并行读写。如果 Vector 单元试图在一个周期内同时访问同一个 Bank 的不同地址,就会发生冲突,导致串行化,性能骤降。
○ 优化技巧__: 保持数据地址的 32字节对齐(32-Byte Alignment)。Ascend 硬件对齐访问效率最高,非对齐访问可能导致额外的读写周期。
3.3 独立的 L0A/L0B/L0C:为吞吐量而生
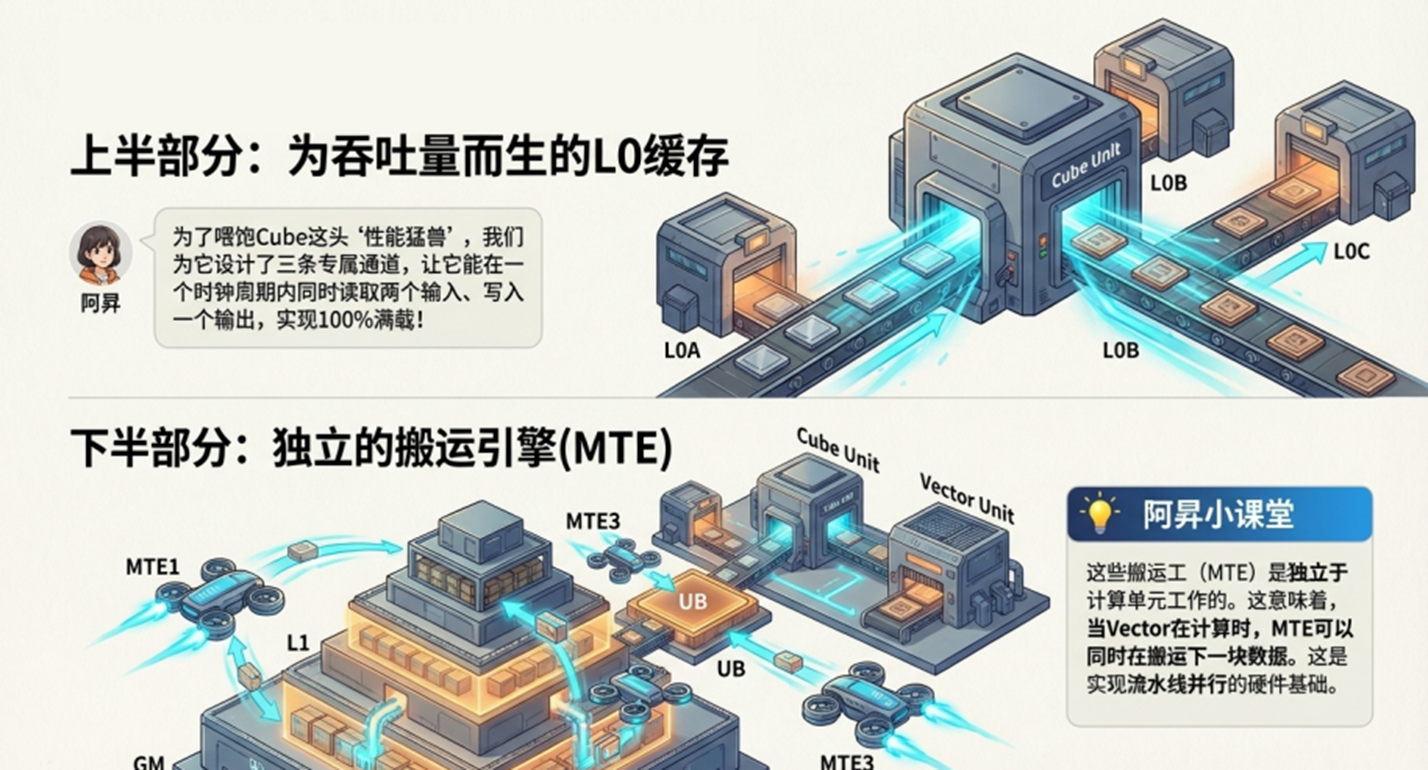
为了喂饱 Cube 单元,Da Vinci 架构将最靠近计算核心的存储(L0)物理拆分为三部分:
● L0A: 存放左矩阵(Left Matrix)。
● L0B: 存放右矩阵(Right Matrix)。
● L0C: 存放结果矩阵(Result Matrix)或中间累加值。
设计意图: 这种物理隔离允许 Cube 单元在同一个时钟周期内,同时从 A 口和 B 口读取数据,并向 C 口写入数据,实现 100% 的流水线满载,没有任何端口争用。
3.4 搬运引擎(MTE):不仅是搬运工
连接这些存储层级的通道并非简单的总线,而是由名为 MTE (Memory Transfer Engine) 的专用硬件负责。
● MTE1: 负责将数据从 L1 搬到 L0(给 Cube 供货)。
● MTE2: 负责将数据从 GM 搬运到 L1/UB(从仓库进货)。
● MTE3: 负责将数据从 L1/UB/L0 搬运回 GM(向仓库发货)。
💡 核心知识点:MTE 是独立于 Vector 和 Cube 工作的。这意味着,当 Vector 在计算时,MTE2 可以同时在搬运下一块数据。这是实现流水线并行(Pipeline Parallelism) 的硬件基础。
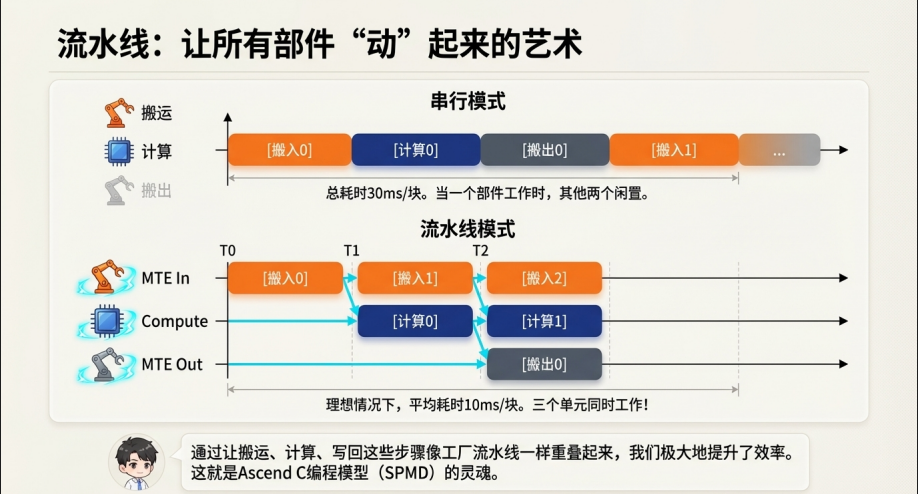
四、 流水线(Pipeline):SPMD 编程模型的灵魂
理解了计算和存储,现在我们需要让它们动起来。Ascend C 采用的是 SPMD(Single Program Multiple Data,单程序多数据) 编程模型。这意味着你编写的一个 Kernel 函数,会被复制到多个 AI Core 上并行运行,每个 Core 处理数据的一部分。
但在单个 AI Core 内部,如何让 MTE(搬运)和 Vector/Cube(计算)并行起来?这就需要流水线设计。
4.1 传统的串行模式 vs 流水线模式
假设处理一块数据需要三步:搬入(CopyIn)、计算(Compute)、搬出(CopyOut)。
● 串行模式: 搬入(10ms) -> 计算(10ms) -> 搬出(10ms)。总耗时 30ms。此时,当 MTE 在搬运时,Vector 是闲置的。
● 流水线模式:
○ T0: 搬入 Block 0。
○ T1:计算 Block 0 的同时,搬入 Block 1。
○ T2:搬出 Block 0 的同时,计算 Block 1,同时 搬入 Block 2。
○ 结果: 理想情况下,除了开头和结尾,每个时间段都有三个单元在同时工作。处理一块数据的平均时间从 30ms 缩短到了 10ms(取决于最慢的那个阶段)。
4.2 抽象与实现:TPipe 与 TQue
Ascend C 通过 TPipe 和 TQue 类将这种复杂的硬件行为封装起来。
● TPipe(管道对象): 它是片上内存资源的管理者。你通过它来申请 UB 空间,它本质上是在管理 AI Core 内的 SRAM 资源池。
● TQue(队列对象): 它是流水线阶段之间的连接器,也是同步屏障(Synchronization Barrier) 的硬件实现。
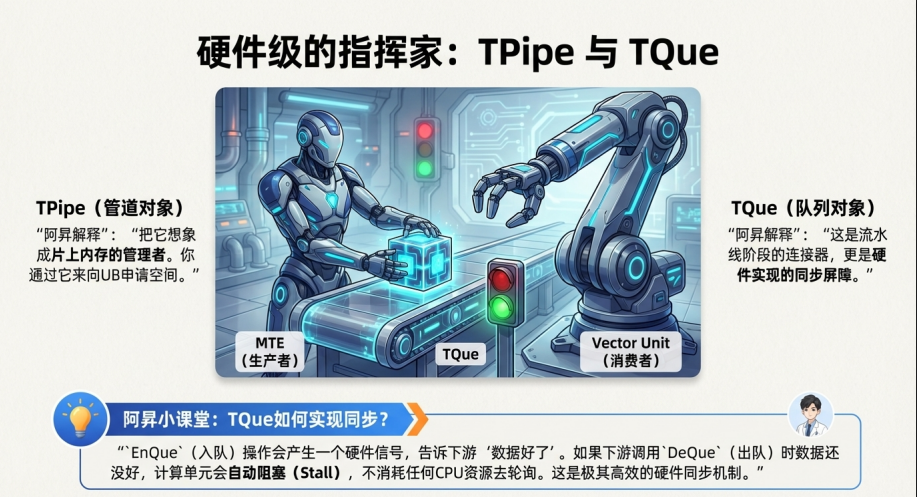
💡 核心知识点:TQue 如何实现同步?
TQue 并非简单的软件链表,它直接对应硬件的同步寄存器/信号量机制。
1. EnQue(入队): 生产者(如 MTE2)完成数据搬运后,调用 EnQue。这不仅是把 Tensor 指针放入队列,更重要的是硬件产生一个信号,告诉下游“数据好了”。
2. DeQue(出队): 消费者(如 Vector)调用 DeQue。如果队列为空(数据还没搬完),Vector 单元会自动阻塞(Stall),挂起等待,直到上游发出信号。
这种机制极其高效,消除了软件轮询(Polling)的开销,确保了硬件层面的严格同步。
代码案例:防止TPipe在对象内部被创建和初始化
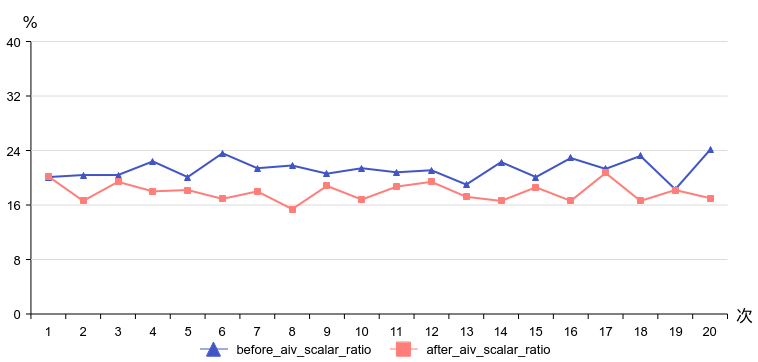
组图为Ascend C 官方文档 - 流水线优化中的流水线与双缓冲示意图
展示串行执行 vs 流水线执行的时间轴对比,体现“Ping-Pong”操作。根据剖面数据比较,标量时间得到了显著优化。平均时间减少17%,从281微秒降至236微秒。平均scalar_time延迟率从21%降至17%。因此,这种优化指标可以在标量界限场景中使用。
图1 优化前后aiv_scalar_time比较
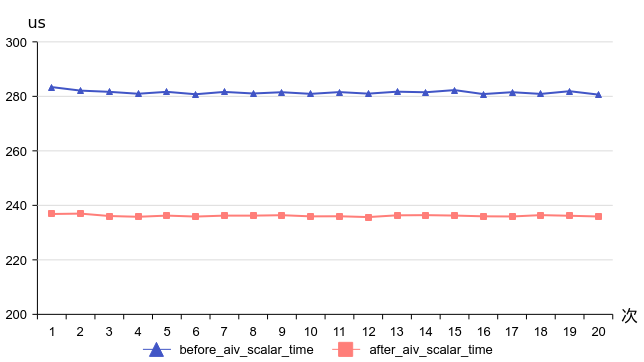
图2 优化前后aiv_scalar_ratio比较
错误:在代码中,TPipe 对象由 KernelExample 类创建并初始化,这会影响编译器的标量折叠优化。因此,NPU上的标量会增加。
template <typename ComputeT> class KernelExample {
public:
__aicore__ inline KernelExample() {}
__aicore__ inline void Init(...)
{
...
pipe.InitBuffer(xxxBuf, BUFFER_NUM, xxxSize);
...
}
private:
...
TPipe pipe;
...
};
extern "C" __global__ __aicore__ void example_kernel(...)
{
...
KernelExample<float> op;
op.Init(...);
...
}
正确:代码中TPipe 对象由内核入口函数创建,TPipe 指针存储在 KernelExample 类中。
template <typename ComputeT> class KernelExample {
public:
__aicore__ inline KernelExample() {}
__aicore__ inline void Init(..., TPipe* pipeIn)
{
...
pipe = pipeIn;
pipe->InitBuffer(xxxBuf, BUFFER_NUM, xxxSize);
...
}
private:
...
TPipe* pipe;
...
};
extern "C" __global__ __aicore__ void example_kernel(...)
{
...
TPipe pipe;
KernelExample<float> op;
op.Init(..., &pipe);
...
}
4.3 终极武器:双缓冲(Double Buffering)
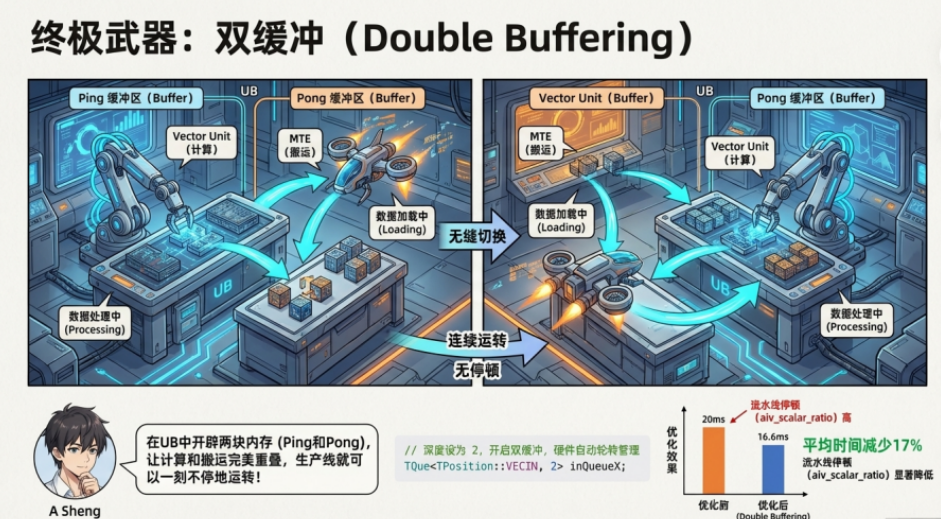
为了让流水线完美重叠,Ascend C 推荐使用双缓冲策略。
● 原理: 在 UB 中开辟两块大小相同的内存区域(Ping 和 Pong)。
● 过程:
○ 当 Vector 正在猛烈计算 Ping 块数据时;
○ MTE2 悄悄地把下一波数据搬运到 Pong 块中。
○ 当 Vector 算完 Ping,无缝切换到 Pong,此时 MTE2 开始覆盖 Ping 块。
● 代码体现: 在 Ascend C 中,只需在创建 TQue 时设置深度为 2:
// 深度设为 2,开启双缓冲,硬件自动轮转管理
TQue<TPosition::VECIN, 2> inQueueX;
五、 开发者实战指南:将知识转化为代码
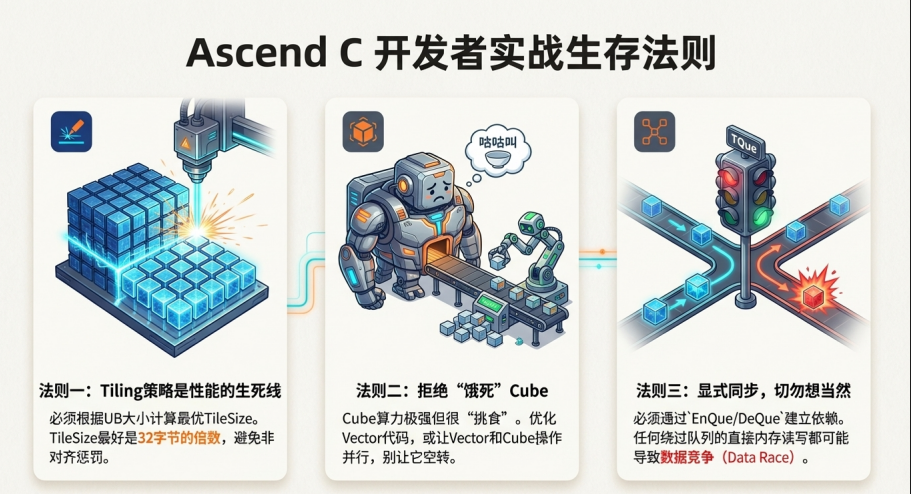
掌握了上述硬件知识,我们总结出 Ascend C 开发者的几条生存法则:
5.1 Tiling 策略是性能的生死线
不要试图一次性处理所有数据。必须根据 UB 的大小(硬件限制)计算出最优的 TileSize。
● 公式参考: TileSize ≈ (UB_Capacity / 2) / sizeof(DataType)。除以 2 是为了留给双缓冲。
● 对齐原则: 计算出的 TileSize 最好是 32 字节的倍数,以满足 MTE 的突发传输要求,避免“非对齐”带来的性能惩罚。
5.2 拒绝“饿死” Cube
Cube 单元算力极强,但它很挑食(只吃 L1 里的分形数据)。如果你的 Vector 单元处理数据预处理(Quantization, Padding)太慢,Cube 就会空转。
● 建议: 在设计算子时,尽量让 Vector 操作和 Cube 操作并行。如果必须串行,务必优化 Vector 代码,利用好 SIMD 的每一个 lane。
5.3 显式同步,切勿想当然
不要假设“代码写在前面就会先执行完毕”。由于 MTE 和 Vector 是异步的,必须通过 TQue 的 EnQue/DeQue 来建立依赖关系。任何绕过队列直接读写内存的行为,都可能导致严重的数据竞争(Data Race)——即读到了上一次的旧数据,或者写入的数据被未完成的搬运覆盖。
六、 结语
学习 Ascend C,本质上是一次向底层硬件的“回归”。在 CPU 上,我们被缓存和操作系统保护得很好;但在 NPU 上,我们需要重新拾起对时钟周期、内存带宽和流水线气泡的敏感度。
Da Vinci 架构通过Cube/Vector 的分离解决了算力密度与灵活性的矛盾,通过显式管理的存储层级解决了内存墙问题,通过硬件队列同步解决了流水线编排问题。对于开发者而言,理解这些硬件图谱,就掌握了通往极致 AI 性能的钥匙。

参考资料与延伸阅读:
1. Atlas AI Computing Platform (Official Lecture)
a. 来源:香港中文大学 (CUHK)
b. 简介:详细的昇腾 Atlas 计算平台架构讲义,包含清晰的硬件框图。
2. https://www.cmc.ca/wp-content/uploads/2020/03/Zhan-Xu-Huawei.pdf
a. 来源:CMC Microsystems / Huawei
b. 简介:华为官方关于达芬奇架构的深度技术演示文稿,解释了 Cube/Vector 设计理念。
3. https://www.researchgate.net/figure/DaVinci-architecture-of-Huawei-Ascend-NPU-AI-core_fig2_394174807
a. 来源:ResearchGate
b. 简介:高分辨率的 AI Core 内部逻辑架构图,清晰展示了各单元的数据通路。
a. 来源:HiAscend 社区
b. 简介:官方文档中关于性能优化、流水线设计和 Tiling 策略的权威指南。
5. https://cs.nju.edu.cn/tianchen/lunwen/2025/asplos25-yuhang.pdf
a. 来源:南京大学 (NJU) / ASPLOS 2025
b. 简介:最新的学术论文,深入剖析了昇腾架构的性能潜力与优化方法。
hello,这里是 晓雨的笔记本 。如果你喜欢我的文章,欢迎三连给我鼓励和支持:👍点赞 📁 关注 💬评论,我会给大家带来更多有用有趣的文章。
原文链接 👉 ,⚡️更新更及时。
欢迎大家点开下面名片,添加好友交流。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐



 162
162 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)