
【鸿蒙原生开发会议随记 Pro】 会议随记 Pro v1.1 发布 详解 HarmonyOS NEXT 原生国际化(i18n)架构与最佳实践
在 v1.1 版本中,我们不仅重构了 UI 布局,更引入了完整的多语言支持(简体中文/English)。这看似只是简单翻译,实则是对应用底层架构的一次重要升维。
前言
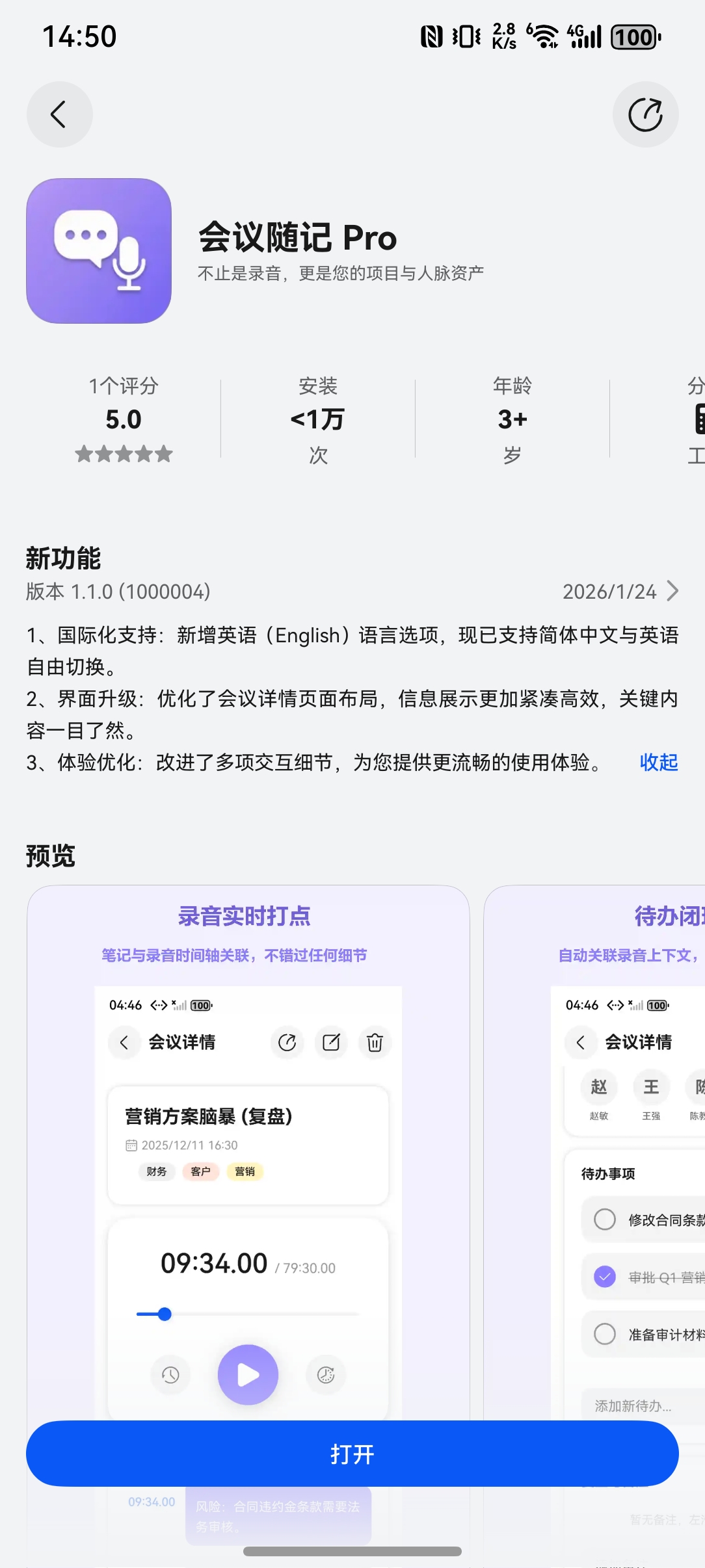
作为一名深耕鸿蒙原生生态的独立开发者,我开发的 《会议随记 Pro》 刚刚完成了 v1.0 到 v1.1 的迭代。
如果说 v1.0 是为了验证极致单机录音与项目管理这一核心 MVP(最小可行性产品),那么 v1.1 则是为了让这个第二大脑具备走向全球的底气。
在 v1.1 版本中,我们不仅重构了 UI 布局,更引入了完整的多语言支持(简体中文/English)。这看似只是简单翻译,实则是对应用底层架构的一次重要升维。
今天,我想跳出单纯的功能介绍,以开发者的视角,和大家聊聊这次更新背后的技术思考,特别是在纯血鸿蒙 HarmonyOS NEXT 中,如何优雅地实现原生国际化?
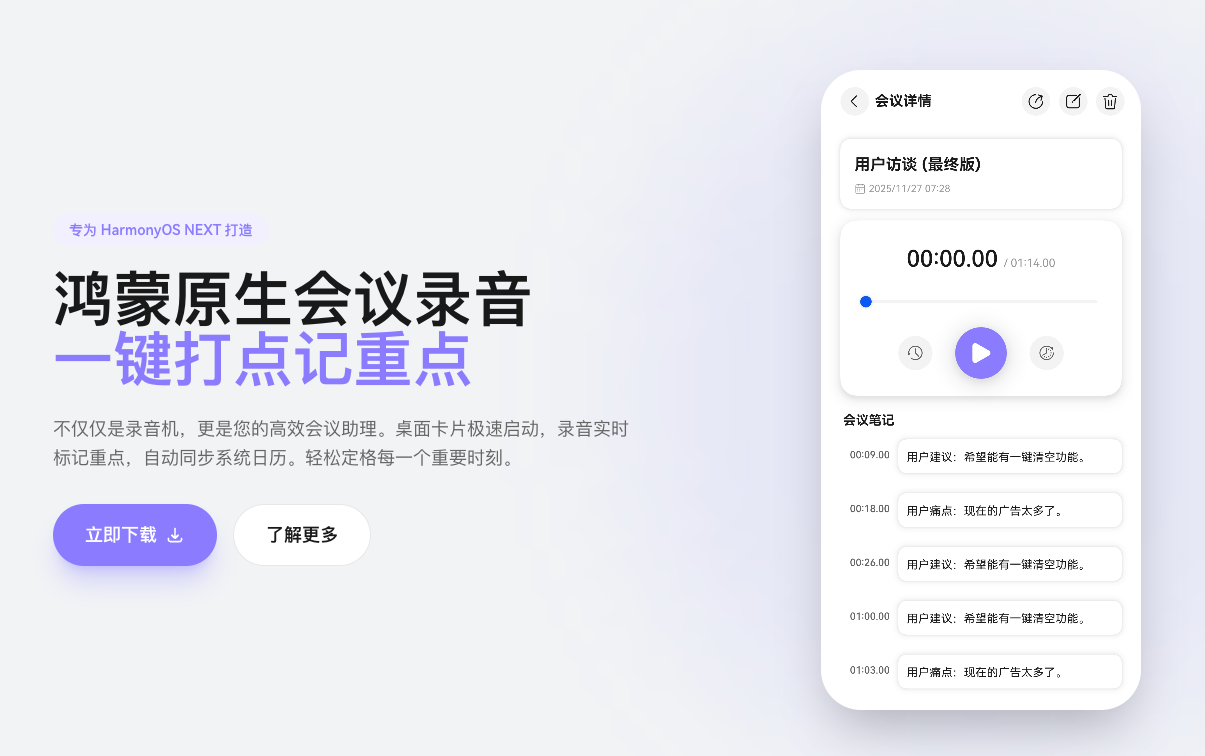
一、v1.1 版本更新概览
在进入硬核技术环节之前,先快速同步一下本次 v1.1 版本的核心变化。
1. 国际化支持(Multi-language Support)
这是本次更新的重头戏。应用不再局限于中文环境,新增了完整的英文(English) 界面支持。
- 无感切换:应用会自动读取系统的语言设置,适配中文或英文。
- 全域覆盖:从首页的 Dashboard,到深层的会议设置、隐私协议,甚至是自动生成的演示数据,全部实现了本地化。
2. 视觉与布局重构(Compact UI)
针对商务人士“信息密度”的高要求,我们优化了会议详情页的布局:
- 紧凑型卡片:将原先松散的信息聚合为卡片,减少滑动距离。
- 信息层级优化:强化了“时间轴笔记”与“待办事项”的视觉权重,让复盘更高效。
3. 体验微调
- 修复了部分场景下长文本截断的问题。
- 优化了 Emoji 选择器的交互手感。
二、鸿蒙原生国际化(i18n)深度解析
对于许多从 Web 前端或 Android 转战鸿蒙的开发者来说,国际化(Internationalization,简称 i18n)往往被误解为“简单的字符串替换”。
但在 HarmonyOS NEXT 的声明式开发体系(ArkUI)中,国际化是一套完整的资源管理机制(Resource Management)。它不仅仅是翻译文字,还包括了对不同国家/地区的度量衡、日期格式、甚至阅读习惯(LTR/RTL)的适配。
1. 核心理念:资源限定词(Qualifiers)与目录优先级
鸿蒙操作系统的资源加载机制非常智能。它不像传统 Web 开发那样需要你写一堆 if (lang === 'en') 的判断逻辑。鸿蒙采用的是**“基于目录结构的资源匹配策略”**。
你的应用是一个巨大的仓库,仓库里有很多个房间(目录)。
- 有一个房间叫
base/element,这里放着“默认物资”。 - 有一个房间叫
en_US/element,这里放着“给美国英语用户准备的物资”。 - 有一个房间叫
zh_CN/element,这里放着“给中国大陆用户准备的物资”。
当用户打开 App 时,系统会先看用户的手机设置。如果用户设置的是英文,系统就会优先去 en_US 房间找;如果找不到,才会去 base 房间找兜底数据。
这种机制最大的好处是:代码逻辑与资源数据彻底解耦。你的 ArkTS 代码中永远只需要引用一个 ID,具体显示什么内容,完全由系统在运行时动态决定。
2. 工程结构实战
在《会议随记 Pro》中,我们严格遵循了鸿蒙的官方推荐结构。
在 resources 目录下,文件结构如下:
resources
├── base
│ ├── element
│ │ ├── string.json // 默认字符串(通常是兜底语言,如中文)
│ │ └── color.json // 颜色资源
│ └── media // 通用图片
├── en_US (限定词目录:英文-美国)
│ └── element
│ └── string.json // 英文翻译
└── zh_CN (限定词目录:中文-中国)
└── element
└── string.json // 中文特有优化
关键点解析:
string.json:这是存储键值对的核心文件。所有的文案都必须提取到这里,严禁在代码中写死字符串(Hardcode)。- 匹配规则:当系统语言为
en-US时,优先级为en_US>en(如果存在) >base。
三、从 0 到 1 实现多语言的代码实战
接下来,我将通过《会议随记 Pro》中的真实代码片段,演示如何在 ArkTS 中实现这一机制。
场景一:基础静态文本的替换
这是最常见的场景,比如标题、按钮文字。
步骤 1:定义资源 (JSON)
首先,我们在 base/element/string.json 中定义 Key:
{
"string": [
{
"name": "emoji_selector_title",
"value": "会议标记"
},
{
"name": "btn_confirm",
"value": "确认"
}
]
}
然后,在 en_US/element/string.json 中定义相同的 Key,但 Value 不同:
{
"string": [
{
"name": "emoji_selector_title",
"value": "Meeting Markers"
},
{
"name": "btn_confirm",
"value": "Confirm"
}
]
}
步骤 2:在 UI 中使用 ($r 语法)
在 ArkTS 组件中,我们不再写字符串字面量,而是使用 $r() 函数。
$r 是 Resource 的缩写,它的参数格式是 'app.type.name'。
// 修改前 (Hardcode - 反面教材)
Text('会议标记')
.fontSize(14)
// 修改后 (i18n - 最佳实践)
Text($r('app.string.emoji_selector_title'))
.fontSize(14)
技术原理:
$r 返回的并不是一个 string 类型,而是一个 Resource 对象。ArkUI 的组件(如 Text, Button)内部已经做好了适配,当它们接收到 Resource 对象时,会在渲染的一瞬间,去 Resource Manager 查找当前语言对应的文本。这意味着,如果用户在运行过程中切了系统语言,应用不需要重启,界面会自动刷新!
场景二:带参数的动态文本格式化
在会议列表中,我们经常需要显示“已选 3 项”或者“第 5 个文件”。这种包含数字或变量的文本,怎么翻译?
英语和中文的语序不同,简单的字符串拼接("已选 " + count)在多语言中是行不通的。
解决方案:占位符
我们利用标准化的格式化占位符:
%d:整数%s:字符串%f:浮点数
资源定义 (string.json):
// base
{ "name": "selected_count_fmt", "value": "已选 %d 项" }
// en_US
{ "name": "selected_count_fmt", "value": "%d items selected" }
代码调用:
$r 函数支持传入第二个、第三个参数作为变量。
@Component
struct SelectionBar {
@Prop count: number;
build() {
// 自动将 this.count 填入 %d 的位置
// 中文显示:已选 5 项
// 英文显示:5 items selected
Text($r('app.string.selected_count_fmt', this.count))
.fontSize(12)
}
}
这种方式完美解决了语序问题,是开发者的必备技能。
场景三:高阶难点——逻辑层(非UI)的资源获取
这是我在开发 v1.1 时遇到的最大坑,也是本文最想分享的干货。
在 UI 组件(build 函数内),我们可以直接用 $r。但是,在 逻辑代码 或者 数据层 中,我们无法直接使用 $r。
遇到的问题:
在《会议随记 Pro》的 TagSelector(标签选择器)组件中,我们需要一个推荐标签池。
// 错误做法
// 如果这样写,数组里存的是 Resource 对象,而不是字符串
// 后续进行 includes() 判断或存入数据库时会由类型错误
const TAGS = [ $r('app.string.tag_urgent'), $r('app.string.tag_todo') ];
我们需要在代码运行的时候,把资源 ID 同步转换 为真实的字符串(String)。
解决方案:ResourceManager
我们需要手动调用鸿蒙的资源管理器。这通常在组件的 aboutToAppear 生命周期中进行。
1. 定义资源数组(只存 ID):
const TAG_RES_IDS: Resource[] = [
$r('app.string.tag_review'),
$r('app.string.tag_weekly'),
$r('app.string.tag_urgent')
];
2. 在逻辑中加载字符串:
@Component
export struct TagSelector {
@State recommendTags: string[] = [];
aboutToAppear() {
// 获取当前上下文
const context = getContext(this);
// 获取资源管理器
const manager = context.resourceManager;
// 遍历资源 ID,同步获取对应的字符串
this.recommendTags = TAG_RES_IDS.map(res => {
try {
// getStringSync 是 API 12 的核心方法,同步读取
return manager.getStringSync(res.id);
} catch (e) {
return ''; // 兜底防止崩溃
}
});
}
// 现在 recommendTags 里存的就是 ["评审", "周会"] 或 ["Review", "Weekly"]
// 可以放心地进行逻辑判断了
}
深度解读:
resourceManager.getStringSync(res.id) 是连接“资源世界”和“代码世界”的桥梁。它允许我们在非 UI 渲染阶段(如数据初始化、数据库存储前预处理、日志记录)获取到用户当前所见到的真实文本。
这在生成演示数据时尤为重要。在 v1.1 的更新中,我们的 DemoDataManager 会在生成模拟数据前检测系统语言,如果是英文环境,就利用这套机制加载英文的模拟会议标题和内容,让新用户的开箱体验没有任何割裂感。
四、国际化开发的心得与避坑指南
在完成这次重构后,我有几点心得想分享给各位开发者:
1. 尽早开始,不要拖延
不要觉得我的 App 刚起步,先写死中文没事。后期提取字符串是一项极其枯燥且容易出错的体力活。从第一行代码开始,就坚持使用 $r。哪怕你暂时只有中文,也请把它放在 string.json 里。
2. 语义化命名 Key
Key 的命名决定了可维护性。
-
错误:
text1,button_red(不知所云) -
正确:
meeting_detail_title,btn_delete_confirm(模块_功能_位置)建议按照
页面_组件_语义的格式来命名。
3. 注意长度适配 (UI Adaptation)
同一个词,英文往往比中文长。
- 中文:“编辑” (2个字符)
- 英文:“Edit” (4个字符)
- 中文:“会议录音实时转写” (9个字符)
- 英文:“Real-time meeting audio transcription” (30+字符)
在 v1.1 的 UI 重构中,我们将许多固定宽度的 Row 或 Button 改为了 Flex 布局或使用了 layoutWeight,并设置了 textOverflow: Ellipsis(省略号),就是为了防止英文文案撑爆界面。
4. 敏感数据的本地化
我们在 v1.1 中加入了 mic_reason(麦克风权限理由)和 media_reason(媒体库权限理由)的翻译。这在应用上架审核时非常重要。如果用户的系统是英文,但弹出的权限请求框是中文,会被视为体验不合格甚至导致拒审。
总结
《会议随记 Pro》的 v1.1 更新,表面看是多了个语言选项,实则是应用架构的一次成熟度跃升。
通过 HarmonyOS NEXT 强大的资源管理系统,我们用一套代码完美适配了多种文化环境。
这不仅拓展了潜在的用户群体,更重要的是,它体现了我们对每一位用户,无论他使用何种语言——的尊重。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐
 21
21 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)