
模型部署入门—MindSpeed实践指导
作者:昇腾实战派,Ming—L。
·
作者:昇腾实战派,Ming—L
背景和意义
本文档可以作为AI学习者的模型部署入门指导,将介绍在NPU环境上基于MindSpeed-LLM部署Qwen3的实践流程,从本文章主要可以了解到以下内容
- 使用MindSpeed-LLM部署模型
- 结合docker和conda搭建环境
- 搭建过程报错处理
- 模型代码,权重获取方式
- 模型单机运行和双机运行
- 精度指标的简单介绍
环境版本与依赖清单
| 依赖软件 | 版本 |
|---|---|
| 昇腾NPU驱动 | 商发版本 |
| 昇腾NPU固件 | 商发版本 |
| CANN Toolkit(开发套件) | 商发版本 |
| CANN Kernel(算子包) | 商发版本 |
| CANN NNAL(Ascend Transformer Boost加速库) | 商发版本 |
| Python | >=3.10 |
| PyTorch | 2.1.0 |
| torch_npu插件 | 2.1.0 |
| apex | 商发版本 |
| transformers | 4.51.0 |
环境搭建准备
昇腾常用指令了解
- 查看npu信息:npu-smi info
- 查看cann 版本:cat /usr/local/Ascend/ascend-toolkit/latest/version.cfg (这只是个默认地址,具体根据实际引用的CANN地址)
环境搭建
官方安装指导:MindSpeed-LLM: 昇腾LLM分布式训练框架 - Gitee.com
- 安装NPU驱动与固件
- 安装CANN
- 本次实践是在容器环境下实施的,实现环境隔离,先起一个容器
- 案例启动命令
-
docker run -it -u root --ipc=host --net=host --name=ming-test --ipc=host --privileged=true \ # name参数代表新建容器的名字 -e ASCEND_VISIBLE_DEVICES=0-7 \ # 新建容器调用八卡 --device=/dev/davinci0 \ --device=/dev/davinci1 \ --device=/dev/davinci2 \ --device=/dev/davinci3 \ --device=/dev/davinci4 \ --device=/dev/davinci5 \ --device=/dev/davinci6 \ --device=/dev/davinci7 \ --device=/dev/davinci_manager \ --device=/dev/devmm_svm \ --device=/dev/hisi_hdc \ -v /etc/ascend_install.info:/etc/ascend_install.info \ # 必须挂载 -v /usr/local/Ascend/:/usr/local/Ascend/ \ # 挂载宿主机上CANN驱动和固件 -v /usr/local/Ascend/driver:/usr/local/Ascend/driver \ -v /usr/local/Ascend/add-ons/:/usr/local/Ascend/add-ons/ \ -v /usr/local/sbin/npu-smi:/usr/local/sbin/npu-smi \ # 挂载npu-smi命令 -v /usr/local/sbin/:/usr/local/sbin/ \ -v /home/:/home/ \ # 挂载模型数据文件 mindspeed_llm:rc4 \ # 基础镜像名字和版本 /bin/bash
-
- 案例启动命令
- 进入容器后安装conda环境
-
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-aarch64.sh bash Miniconda3-latest-Linux-aarch64.sh -b -p /opt/conda export PATH="/opt/conda/bin:$PATH" - 敲conda指令,验证是否安装成功
-
- conda环境初始化
-
conda init #看下哪些文件是有change的,一般是/root/.bashrc #如果直接init失败,/root/.bashrc change,则执行以下命令完成初始化 source /root/.bashrc - 出现以下标识即初始化成功
-
- 仓库拉取
-
git clone https://gitee.com/ascend/MindSpeed-LLM.git git clone https://github.com/NVIDIA/Megatron-LM.git cd Megatron-LM git checkout core_r0.8.0 cp -r megatron ../MindSpeed-LLM/ cd .. cd MindSpeed-LLM mkdir logs mkdir dataset mkdir ckpt
-
- 依赖安装
-
# python3.10 conda create -n test python=3.10 conda activate test #torch 和 torch_npu pip install torch==2.1.0 pip install torch-npu==2.1.0 #apex安装 https://gitee.com/ascend/apex git clone -b master https://gitee.com/ascend/apex.git cd apex/ bash scripts/build.sh --python=3.10 cd apex/dist/ pip3 uninstall apex pip3 install --upgrade apex-0.1+ascend-{version}.whl # version为python版本和cpu架构 # 安装加速库 git clone https://gitee.com/ascend/MindSpeed.git cd MindSpeed # checkout commit from MindSpeed core_r0.8.0 git checkout 2c085cc9 pip install -r requirements.txt pip install -e . cd ../MindSpeed-LLM # 安装其余依赖库 pip install -r requirements.txt pip install transformers==4.51.0
-

模型部署流程
基于上述流程,已经完成所有的依赖和环境搭建。
单机运行
多机运行
- 跟单机类似的,主要是留意以下内容
-
MASTER_ADDR=localhost #主节点IP MASTER_PORT=6000 #主节点端口 NNODES=1 #机器数 NODE_RANK=0 #主节点为0,第二个为1,以此类推
-
- 需要在两台节点上分布执行脚本,并非真的集群具备自动调度能力。
-
scp -r /xxx/xx root@IP:/xxx/xxx #可能用到的跨机文件复制
-
常见问题与解决方案
- 脚本运行报错:首先观察依赖版本是否正确
- Megatron-LM、Mindspeed,pytorch,torch-npu,transformers等
- 一直报错目录下缺少.idx,.bin文件,但又确定该目录下有此类文件。
- DATA_PATH参数,是一个前缀拼接路径,比如文件路径是/a/a.idx,这个参数就得写/a/a,而不是/a
- 卡进程
- 可能原因1:模型运行需要多机,配置的节点数NNODES大于1,然后你目前只是用单机跑,跟配置不一致。
- 定位方式
-
pip install py-spy # 通过pid打印python进程调用栈 top获取pid py-spy dump -p pid
-
- 缺少环境变量GLOO_SOCKET_IFNAME
-
ifconfig查看网卡名 export HCCL_SOCKET_IFNAME=xx export GLOO_SOCKET_IFNAME=xx - https://support.huawei.com/enterprise/zh/doc/EDOC1100368815/8eb36bd0
-
精度
精度绘制曲线图:https://traininglogparser.openx.huawei.com/
qwen3模型精度指标对比
- 精度通常指两个维度
- 模型实际运行推理时的效果,如回答的内容是否正常。
- Loss函数输出值
- 每个模型的算法可能不同,因此得到的Loss值也不同,因此没法直接根据Loss的值去判断其精度的好坏。
- 那根据Loss值判断好坏主要看两点
- loss曲线能正常收敛;
- 对比GPU基线:平均绝对误差 <= 0.01~0.02 或 平均相对误差 <= 1%,两种目标任一种目标满足即可。
- 实践背景
- 从上述可知,精度其实是需要和某个标杆去对齐的,一般会以开源、GPU作为标杆(看实际需求需求)。
- 本次实践则是在MindSpeed-LLM+NPU 和 LLAMA Factory + GPU 两个环境下分别跑微调,对比下精度。
- 过程
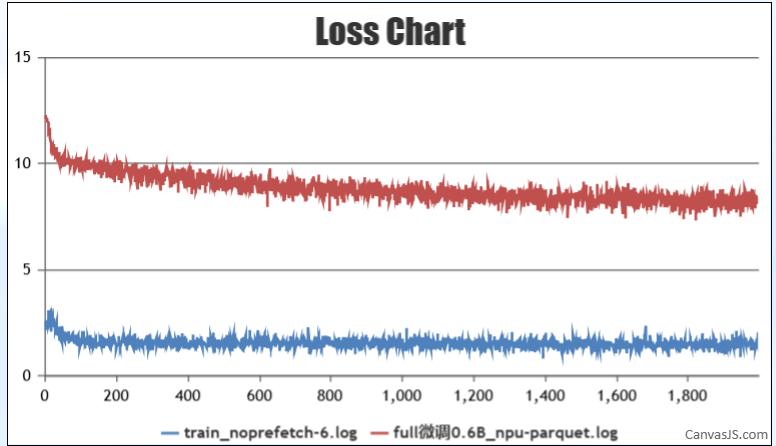
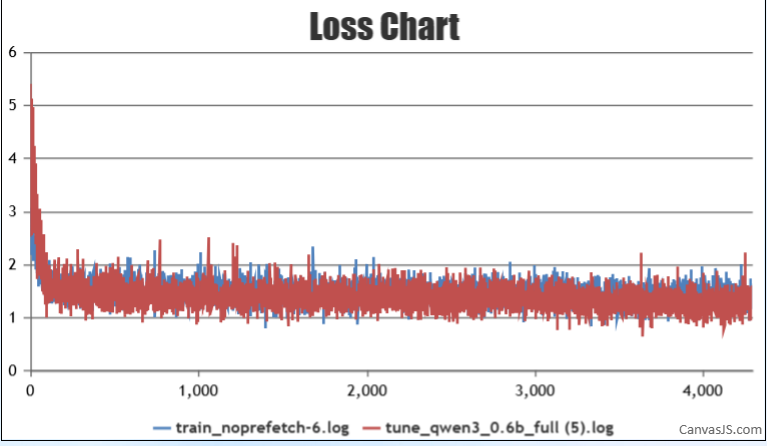
- 首先找同样的qwen3-0.6B模型的权重,和同一份数据集,进行full 微调,第一次发现其精度差距很大,完全不处于同一个数量级,看日志发现是权重没有正确加载
- 修改权重位置,并根据以下文档进行配置对齐,使得精度对齐。
- 首先找同样的qwen3-0.6B模型的权重,和同一份数据集,进行full 微调,第一次发现其精度差距很大,完全不处于同一个数量级,看日志发现是权重没有正确加载

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)