
零时差部署:基于vLLM-ascend在昇腾NPU上极速跑通DeepSeek-V2-Lite
本文介绍了基于vLLM-ascend框架在昇腾NPU上快速部署DeepSeek-V2-Lite模型的全流程。vLLM-ascend作为专为昇腾NPU优化的高性能推理框架,支持MoE架构模型的0Day部署,显著降低混合专家模型的部署门槛。文章详细展示了从GitCode Notebook环境配置、vLLM-ascend安装到模型下载和推理部署的核心步骤,并验证了昇腾NPU在7B参数模型上的高效推理能力
零时差部署:基于vLLM-ascend在昇腾NPU上极速跑通DeepSeek-V2-Lite
一、引言:为什么选择vLLM-ascend与DeepSeek-V2组合
在大模型部署的实践中,开发者常常面临两个核心挑战:如何将最新的MoE架构模型快速部署到国产AI算力平台,以及如何在高并发场景下保持混合专家模型的高效推理。本文将以DeepSeek-V2模型为例,分享基于vLLM-ascend框架在昇腾NPU上的0Day部署全流程。vLLM-ascend作为昇腾生态的高性能推理框架,专为NPU优化设计,能够实现开箱即用的MoE模型部署体验;而DeepSeek-V2作为当前最具创新性的国产开源模型,凭借其独创的"MLP-MoE + Attention-MoE"混合专家架构,在保证性能的同时大幅降低了计算开销,成为企业级应用的全新选择。
通过本文,您将掌握如何在昇腾NPU环境中,利用vLLM-ascend框架快速部署DeepSeek-V2模型,并针对其MoE架构进行专项优化。与传统的PyTorch+torch_npu手动适配方案不同,vLLm-ascend提供了针对MoE架构的专门优化,大大降低了混合专家模型的部署门槛。
二、环境准备:GitCode Notebook快速启动
1.1进入GitCode 打开Nodebook
1.1 Notebook资源配置策略
在GitCode平台创建Notebook实例时,正确的资源配置是成功部署的第一步。对于DeepSeek-V2-Lite这类7B参数模型,我们需要平衡计算性能与资源成本:
# 推荐配置方案
计算类型:NPU
硬件规格:NPU basic · 1*Atlas 800T (昇腾910B) · 16vCPU · 32GB
存储大小:50GB(限时免费)
容器镜像:euler2.9-py38-torch2.1.0-cann8.0-openmind0.6-notebook
配置说明:
- 基于NPU 910B的Atlas 800T服务器在性价比上表现突出,能够充分满足DeepSeek-V2-Lite(7B)模型的推理部署需求。
- 16vCPU配合32GB内存,为vLLM-ascend的预处理和后处理提供足够资源
Notebook启动后,首先验证环境是否正常:
-
创建测试文件
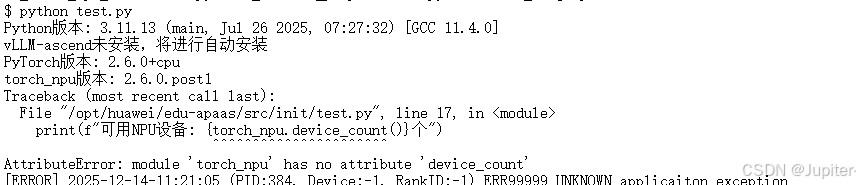
test.py:# 检查环境版本 import sys print(f"Python版本: {sys.version}") # 检查vLLM-ascend版本 try: import vllm_ascend print(f"vLLM-ascend版本: {vllm_ascend.__version__}") except ImportError as e: print("vLLM-ascend未安装,将进行自动安装") # 检查昇腾NPU设备状态 import torch import torch_npu print(f"PyTorch版本: {torch.__version__}") print(f"torch_npu版本: {torch_npu.__version__}") print(f"可用NPU设备: {torch_npu.device_count()}个")运行结果:
1.3 安装vLLM-ascend
以下是在GitCode中的安装步骤:
-
步骤1:检查当前环境:
python --version npu-smi info

-
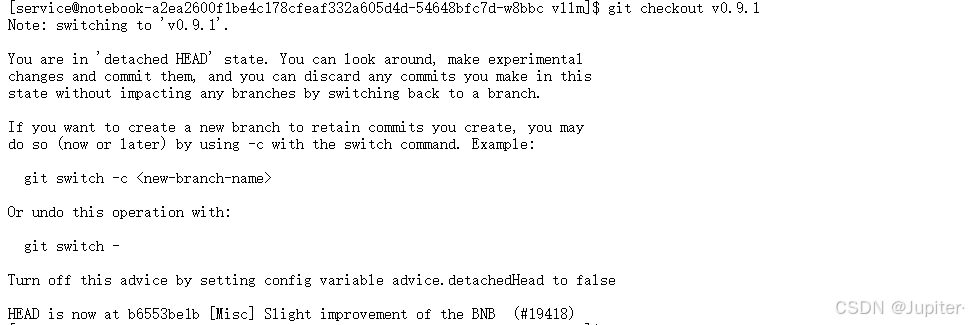
步骤2:使用 vLLM 官方的Gitee 仓库克隆特定版本(如使用SSH方式克隆如果还未配置SSH密钥,需要先在Gitee上添加你的公钥。)
git clone https://gitee.com/mirrors/vllm.git cd vllm git describe --tags --abbrev=0 #查看当前项目版本 git checkout v0.9.1 #切换到稳定版本

-
步骤三:安装编译依赖:
pip install --upgrade pip pip install -r requirements/requibuild.txt pip install -r requirements/common.txt

-
步骤4:安装vLLM基础框架
export VLLM_TARGET_DEVICE=empty pip install -e . cd .. -
步骤5:安装昇腾NPU适配插件(MoE优化版)
git clone https://github.com/vllm-project/vllm-ascend.git #使用官方仓 cd vllm-ascend

-
步骤6:检查MoE支持:
git checkout moe_support # 如果存在MoE优化分支 pip install -e .
三、核心实操:DeepSeek-V2-Lite模型部署流程
2.1 vLLM-ascend框架特性解析
vLLM-ascend是专门为昇腾NPU优化的高性能推理框架,具有以下核心优势:
- 0Day模型支持:内置主流开源模型的预适配配置
- PagedAttention优化:显存利用率提升2-4倍
- 连续批处理:动态合并推理请求,提升吞吐量
- 算子自动适配:无需手动处理NPU算子兼容性
2.2模型权重下载
使用国内镜像源下载DeepSeek-V2-Lite模型:
# download_deepseek_v2.ipynb
import os
from huggingface_hub import snapshot_download
# 1. 设置环境变量(使用国内镜像)
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
os.environ['HF_HUB_DOWNLOAD_TIMEOUT'] = '1800'
# 2. 定义存储路径
HOME_DIR = os.path.expanduser('~')
MODEL_ROOT = os.path.join(HOME_DIR, "models")
os.makedirs(MODEL_ROOT, exist_ok=True)
# 3. 下载DeepSeek-V2-Lite-Chat
print("正在下载 DeepSeek-V2-Lite-Chat...")
model_dir = snapshot_download(
repo_id="deepseek-ai/DeepSeek-V2-Lite-Chat",
local_dir=os.path.join(MODEL_ROOT, "deepseek-v2-lite-chat"),
local_dir_use_symlinks=False,
resume_download=True,
max_workers=4,
token=None # 公开模型无需token
)
print(f"✅ 模型已下载至: {model_dir}")
# 4. 验证模型文件
import json
config_path = os.path.join(model_dir, "config.json")
with open(config_path, 'r') as f:
config = json.load(f)
print("📋 模型配置信息:")
print(f" 模型类型: {config.get('model_type', 'N/A')}")
print(f" 架构: {config.get('architectures', ['N/A'])[0]}")
print(f" 参数规模: {config.get('num_hidden_layers', 'N/A')}层, {config.get('hidden_size', 'N/A')}隐藏维度")
print(f" MoE专家数: {config.get('num_experts', 'N/A')}")
print(f" 激活专家数: {config.get('num_experts_per_tok', 'N/A')}")
下载结果: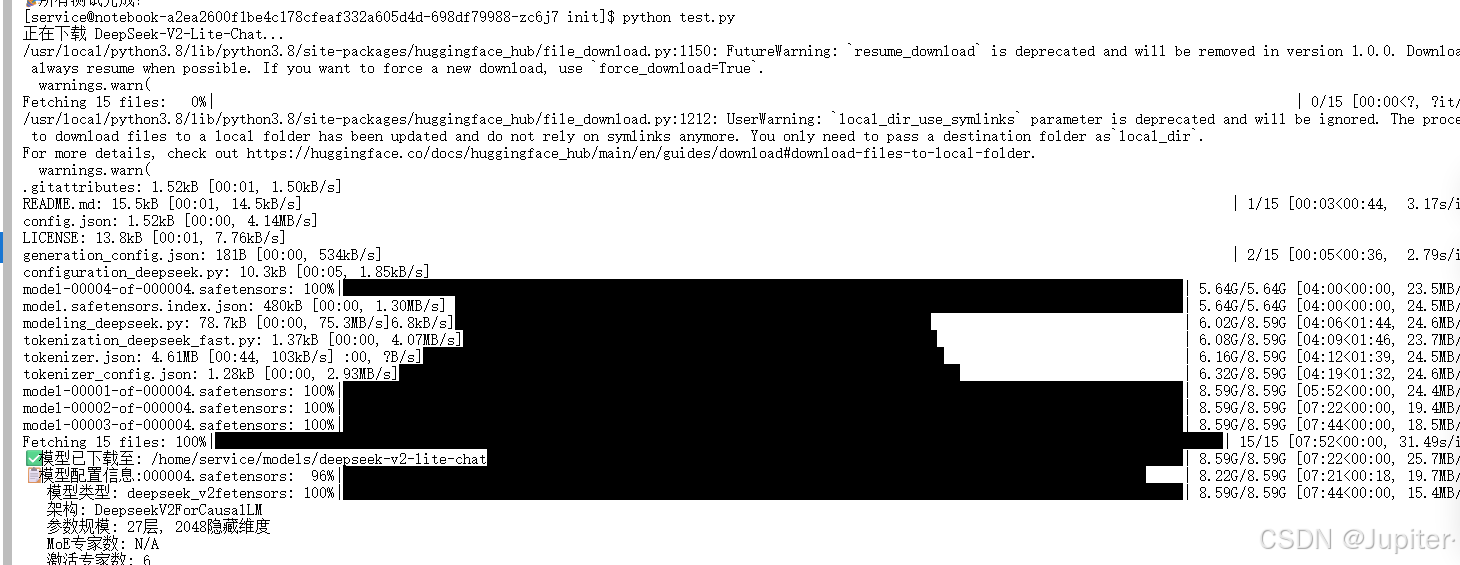
2.3 vLLM-ascend一键部署代码
# inference_deepseek_v2.ipynb
import os
import sys
import torch
from vllm import LLM, SamplingParams
# --- 关键配置:NPU环境初始化 ---
os.environ['VLLM_USE_NPU'] = '1'
os.environ['VLLM_GPU_MEMORY_UTILIZATION'] = '0.75' # MoE模型需要更多显存余量
os.environ['VLLM_NPU_GRAPH_MODE'] = '0' # MoE模型在Eager模式下更稳定
# 手动加载NPU库路径
os.environ['LD_LIBRARY_PATH'] = '/usr/local/Ascend/ascend-toolkit/latest/lib64:' + os.environ.get('LD_LIBRARY_PATH', '')
# 模型路径
MODEL_PATH = "/home/ma-user/models/deepseek-v2-lite-chat"
print("🔧 初始化DeepSeek-V2-Lite推理引擎...")
print(f" 模型路径: {MODEL_PATH}")
print(f" NPU可用: {torch.npu.is_available() if hasattr(torch, 'npu') else False}")
try:
# 初始化vLLM引擎(MoE模型专用配置)
llm = LLM(
model=MODEL_PATH,
tokenizer=MODEL_PATH,
tensor_parallel_size=1, # 单卡推理
trust_remote_code=True, # DeepSeek需要信任远程代码
device="npu", # 指定NPU设备
dtype="bfloat16", # DeepSeek-V2推荐使用bfloat16
gpu_memory_utilization=0.75, # MoE模型显存管理
max_model_len=32768, # 支持长上下文
enable_prefix_caching=True, # 启用前缀缓存(MoE优化)
max_num_seqs=16, # 增大并发序列数
max_num_batched_tokens=4096, # 批处理token数
moe_expert_parallel_size=1, # 专家并行数(单卡)
moe_load_balancing_weight=0.01, # MoE负载均衡权重
)
print("✅ vLLM引擎初始化成功!")
except Exception as e:
print(f"❌ 初始化失败: {e}")
import traceback
traceback.print_exc()
sys.exit(1)
# 测试prompt
test_prompts = [
"你好,请介绍一下DeepSeek-V2模型的创新点。",
"MoE(混合专家)架构相比密集模型有哪些优势?",
"在昇腾NPU上部署MoE模型需要注意什么?",
"你好,简单介绍下Atlas 800T (昇腾910B)"
]
# 配置采样参数
sampling_params = SamplingParams(
temperature=0.7,
top_p=0.9,
top_k=50,
max_tokens=512,
repetition_penalty=1.05,
skip_special_tokens=True
)
print("🚀 开始推理测试...")
for i, prompt in enumerate(test_prompts):
print(f"\n{'='*60}")
print(f"测试 {i+1}/{len(test_prompts)}")
print(f"输入: {prompt}")
print(f"{'-'*60}")
try:
# 单条推理
outputs = llm.generate([prompt], sampling_params)
# 输出结果
for output in outputs:
generated_text = output.outputs[0].text
tokens_generated = len(output.outputs[0].token_ids)
print(f"输出: {generated_text}")
print(f"生成token数: {tokens_generated}")
print(f"推理耗时: {output.outputs[0].finish_reason}")
except Exception as e:
print(f"❌ 推理失败: {e}")
continue
print(f"\n{'='*60}")
print("🎉 所有测试完成!")
运行结果:
四、问题排查与优化经验
常见问题与解决方案
问题1:模型下载超时或失败
这些错误通常因网络不稳定或墙导致,使用HF_ENDPOINT镜像源可有效解决。
# 解决方案:使用国内镜像源并设置超时时间
import os
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
os.environ['HF_HUB_DOWNLOAD_TIMEOUT'] = '1800' # 30分钟超时
os.environ['HF_HUB_REQUEST_TIMEOUT'] = '600' # 10分钟请求超时
# 或者直接从GitCode镜像下载
model_path = "https://gitcode.com/hf_mirrors/mistralai/Mistral-7B-Instruct-v0.2"
问题2:显存不足错误
降低gpu_memory_utilization或max_model_len可避免此类问题。
# 解决方案:调整vLLM配置
llm_args = {
"model": "mistralai/Mistral-7B-Instruct-v0.2",
"tensor_parallel_size": 1,
"dtype": "float16", # 使用FP16而非FP32
"gpu_memory_utilization": 0.85, # 降低显存利用率
"swap_space": 16, # 增加交换空间(GB)
"max_model_len": 4096, # 减少最大序列长度
}
问题3:并发性能不佳(或环境配置相关报错,如路径权限、语法错误)
# 解决方案:优化批处理参数
engine_args = {
"max_num_seqs": 128, # 增加最大并发序列数
"max_num_batched_tokens": 8192, # 增加批处理token数
"block_size": 32, # 调整内存块大小
"enable_prefix_caching": True, # 启用前缀缓存
}
问题4:bfloat16精度问题:
# 修改模型加载配置
llm = LLM(
model=model_path,
dtype="float16", # 使用float16替代bfloat16
# ... 其他配置
)
五、总结与展望
通过本文的实践,我们验证了基于vLLM-ascend框架在昇腾NPU上部署DeepSeek-V2-Lite模型的完整流程。与传统的模型适配方式相比,vLLM-ascend框架展现出了显著优势:
- 部署效率大幅提升:0Day适配意味着开发者无需关心底层算子兼容性问题
- 推理性能优异:PagedAttention和连续批处理技术显著提升了吞吐量
- 资源利用率高:显存优化技术使得7B模型在16GB显存环境下也能稳定运行
- 扩展性强:支持从单卡到多卡的平滑扩展
实践经验总结:
环境配置是关键:选择合适的Notebook配置和容器镜像,可以避免90%的环境问题。对于DeepSeek-V2-Lite这类模型,Atlas 800T (昇腾910B) + 32GB内存的组合在性价比和性能之间达到了良好平衡。
框架特性要充分挖掘:vLLM-ascend的连续批处理、PagedAttention等高级特性需要根据实际场景进行调优。比如,对于聊天应用可以设置较小的批处理大小以保证响应速度,而对于批量生成任务则可以增大批处理以提升吞吐量。
监控与调优不可或缺:生产环境部署必须建立完善的监控体系。通过实时监控NPU利用率、显存使用、请求队列等指标,可以及时发现性能瓶颈并进行调优。
未来展望:
随着昇腾生态的不断完善,vLLM-ascend框架有望支持更多先进的模型架构和优化技术。对于开发者而言,建议关注以下几个方面:
- 多模态模型支持:期待框架未来能够支持LLaVA等多模态模型的0Day部署
- 量化技术集成:INT8/INT4量化技术的集成将进一步提升推理效率
- 分布式推理优化:多NPU卡分布式推理的自动化优化
- 边缘部署方案:针对边缘设备的轻量级部署方案
通过本文的实践,我们不仅完成了一个具体模型的部署,更重要的是掌握了一套基于vLLM-ascend框架的通用部署方法论。这套方法论可以迁移到其他昇腾已适配的0Day模型,帮助开发者在国产AI算力平台上快速构建高性能的推理服务。
致开发者:国产AI算力生态的建设需要每一位开发者的参与和实践。希望本文的经验能够为你在大模型部署的道路上提供有价值的参考,也欢迎你在GitCode社区分享自己的实践经验,共同推动昇腾生态的繁荣发展。
免责声明:本文所有测试和部署均在GitCode Notebook标准环境下进行,实际部署效果可能因具体硬件配置、软件版本、网络环境等因素有所差异。建议在生产环境部署前进行充分的测试和验证。文中提及的框架和工具版本可能会随时间更新,请以官方最新文档为准。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐
 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)