
vLLM-Ascend 实战指南:从环境部署到性能调优的完整避坑手册
摘要:vLLM-Ascend是适配华为昇腾NPU的LLM推理框架插件,通过解耦硬件后端实现大模型高效部署。本文基于Qwen2.5-7B-Instruct实践,总结关键调优经验:1) 环境部署需注意权限管理和依赖版本;2) 版本冲突可通过禁用MoE模块解决;3) W8A8量化可显著降低显存占用;4) 性能优化需配置环境变量(如动态显存扩展)和TorchAir图编译;5) 并发参数需结合npu-smi
为什么选择 vLLM-Ascend?
随着国产 AI 芯片生态的快速发展,华为昇腾 NPU 凭借其高算力密度与 CANN 软件栈的成熟度,已成为大模型推理的重要平台。然而,主流 LLM 推理框架(如 vLLM、TGI)长期以 CUDA 为中心,对 NPU 的原生支持不足。
所以,vLLM-Ascend出现了,它是由社区维护的 vLLM 硬件插件,遵循官方 RFC: Hardware Pluggable 架构,它通过解耦设备的后端,使 vLLM 能够运行于昇腾 NPU。但是需要注意的是,“开箱即用”不等于“一键成功”。在真实环境中,我们开发者常面临 版本冲突、依赖缺失、参数误配、性能未达预期 等问题。本文将结合我在 GitCode Notebook 上的完整实践,系统梳理 vLLM-Ascend 的调踩坑、试调优路径。
环境部署中的“坑”
第一步一般都是环境部署,所以这里的“坑”也是重中之重。
权限陷阱:/home/models 创建失败
初学者常直接执行 mkdir /home/models,却遭遇:
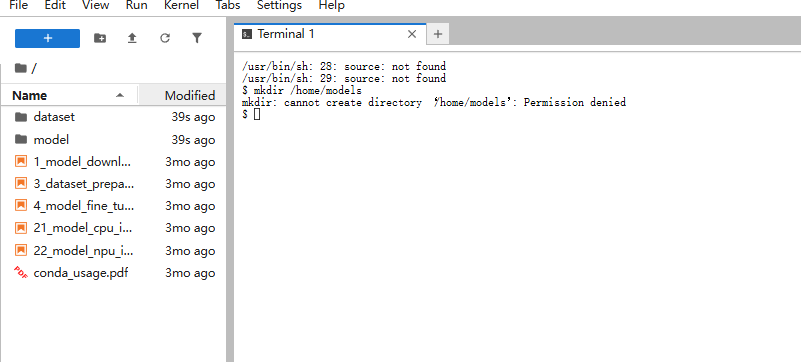
原因:容器中 /home 是系统目录,普通用户无写权限。你的实际家目录是 $HOME(如 /home/service)。
✅ 正确做法:
mkdir -p $HOME/models # 或 ~/models
export MODEL_DIR="$HOME/models"
经验:所有路径操作前,先执行 echo $HOME && pwd 确认工作目录。
依赖缺失:ml-dtypes 与 numpy 警告
安装时常见 pip 警告:
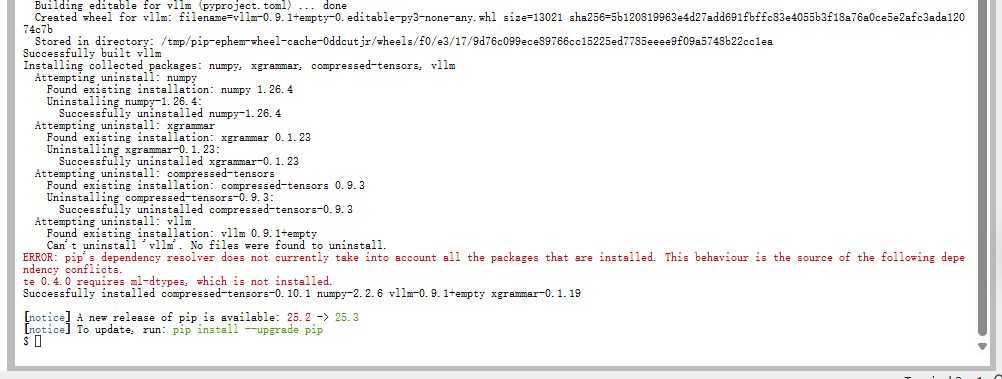
ml-dtypes:必须安装!它是 bfloat16 支持的关键。
pip install ml-dtypesnumpy版本警告:这其实是 pip 误报。NumPy 1.26.4 属于 1.x 系列,完全兼容 opencv。只要import cv2不报错,即可忽略。
经验:不要盲目升级 numpy,可能破坏 torch_npu 兼容性。
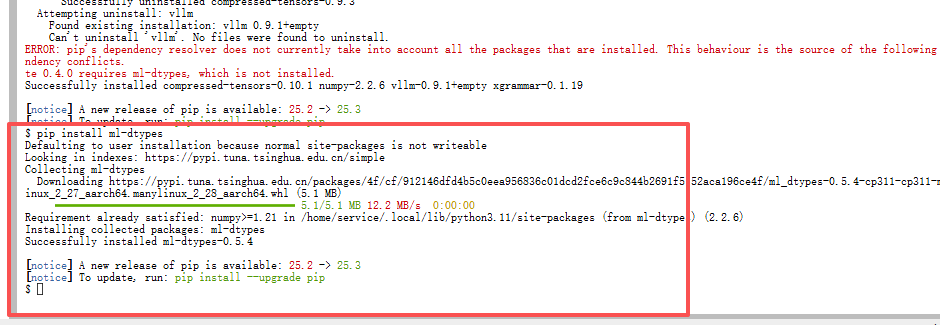
插件加载成功,但 _C 缺失?
执行 import vllm 时看到:
WARNING: Failed to import from vllm._C with ModuleNotFoundError("No module named 'vllm._C'")不要慌不要慌!vllm._C 是 CUDA 扩展库。在 Ascend 后端,核心算子由 torch_npu 提供(如 npu_fused_infer_attention_score),不依赖 _C。
验证方法:只要服务能启动并生成文本,这个警告可安全忽略。
版本兼容性的“坑”
核心错误:ImportError: cannot import name 'get_ep_group'
这是导致服务崩溃的 致命错误,典型日志如下:
from vllm.distributed import get_ep_group
ImportError: cannot import name 'get_ep_group'根因分析:
- vLLM 主仓 v0.9.1 未包含 MoE(Mixture of Experts)通信接口。
- vLLM-Ascend
v0.9.1-dev分支已提前集成 MoE 支持,尝试导入get_ep_group。 - 版本错配 导致运行时崩溃。
解决方案:两条路径
路径 A:严格对齐版本(推荐用于 MoE 模型)
- 查阅 vLLM-Ascend 官方 Release Notes,找到与 vLLM v0.9.1 完全匹配的 commit SHA。
- 执行
git checkout <SHA>后重装。
路径 B:绕过 MoE 代码路径(推荐用于稠密模型)
适用于 Qwen、Llama、ChatGLM 等非 MoE 模型:
- 移除所有 MoE 相关启动参数:
- --enable-expert-parallel
- --data-parallel-size 1
- --additional-config '{..., "enable_weight_nz_layout": true}'- 这样 vLLM-Ascend 不会加载
draft_model_runner.py等 MoE 模块,从而避开导入错误。
经验:除非部署 DeepSeek-R1、Qwen-MoE 等模型,否则一律不要启用 --enable-expert-parallel。
模型选择与量化策略
为何选用 Qwen2.5-7B-Instruct?
|
维度 |
DeepSeek-R1-671B (MoE) |
Qwen2.5-7B-Instruct |
|
参数量 |
~671B(激活 36B) |
7B(全激活) |
|
架构 |
MoE(128 experts) |
稠密 Transformer |
|
显存需求 |
> 60GB(单卡难运行) |
< 15GB(W8A8) |
|
部署复杂度 |
高(需 EP/TP/DP) |
低(仅 TP=1) |
|
中文能力 |
强 |
极强(阿里系优化) |
当然!!主要原因还是因为gitcode上的Notebook只有50G的存储
量化:W8A8 是昇腾的“黄金标准”
vLLM-Ascend 通过 --quantization ascend 自动启用 W8A8 量化:
- 权重(W):INT8
- 激活(A):FP16/BF16(运行时动态量化)
效果:
- 模型显存从 14GB → 7–8GB
- 推理速度提升 15–20%(减少内存带宽压力)
- 精度损失极小(< 0.5% on MMLU)
启动命令:
vllm serve $MODEL_PATH \
--quantization ascend \
--dtype bfloat16 \ # 关键!避免 float16 精度坍塌
...经验:不要手动下载量化模型!vLLM-Ascend 在加载时自动转换,确保与最新算子对齐。
性能调优:从“能跑”到“跑得快”
关键环境变量
这些变量直接影响 NPU 内存分配与通信效率:
export VLLM_USE_V1=1 # 启用 vLLM V1 架构(Ascend 必须)
export PYTORCH_NPU_ALLOC_CONF=expandable_segments:True # 动态显存扩展
export VLLM_ASCEND_ENABLE_FLASHCOMM=1 # 启用 Flash Communication 优化
export VLLM_ASCEND_ENABLE_TOPK_OPTIMIZE=1 # TopK 算子融合(生成阶段加速)
经验:expandable_segments:True 可避免“显存碎片”导致的 OOM。
TorchAir 图模式:性能压榨利器
TorchAir 是 CANN 提供的 图编译优化器,可融合算子、消除冗余,提升吞吐。
启用方式:
--additional-config '{
"torchair_graph_config": {
"enabled": true,
"graph_batch_sizes": [1, 4, 8, 16] # 预编译常用 batch size
}
}'效果:
- 吞吐量提升 10–25%
- 首 token 延迟略增(因图编译开销),但后续 token 更快
⚠️ 注意:
- 初次调试建议关闭(加
--enforce-eager),稳定后再开启。 graph_batch_sizes需覆盖你的实际请求分布。
显存与并发参数调优
Qwen2.5-7B 的推荐配置:
|
参数 |
推荐值 |
说明 |
|
|
|
充分利用 Qwen2.5 的 32K 上下文 |
|
|
|
控制 batch 内总 token 数,防 OOM |
|
|
|
最大并发请求数(实测 32 稳定) |
|
|
|
显存利用率(15GB / 64GB ≈ 0.23,可设更高) |
经验:通过npu-smi info -t usagemem -i 0实时监控显存,逐步提高max-num-seqs直至接近上限。
常见问题速查表
|
问题现象 |
根本原因 |
解决方案 |
|
|
用户无 |
改用 |
|
|
vLLM 与 vLLM-Ascend 版本不匹配 |
移除 |
|
服务启动但无响应 |
未启用 |
添加 |
|
中文输出乱码 |
tokenizer 未加载 |
确保 |
|
|
容器未预装 curl |
|
|
显存 OOM |
|
降低并发或 |
总结
vLLM-Ascend 为昇腾 NPU 带来了工业级 LLM 推理能力,但它的调试过程充满细节陷阱。本文以Qwen2.5-7B-Instruct 单卡部署的踩坑经历,提炼出以下核心经验:
- 环境隔离:始终在
$HOME下操作,避免权限问题; - 版本对齐:非 MoE 模型务必禁用 Expert Parallel;
- 量化必开:
--quantization ascend+--dtype bfloat16是黄金组合; - 图模式后启:先确保功能正确,再开启 TorchAir 优化;
- 监控先行:用
npu-smi实时跟踪显存与算力。
随着 vLLM 主仓对硬件插件的支持完善,以及 CANN 对动态 shape、稀疏计算的增强,vLLM-Ascend 的性能一定会进一步提升。对于我们这些开发展来说,掌握这套调试调优方法论,可以快速将各类开源大模型高效部署于国产 NPU 平台,真正实现“国产芯片 + 国产模型 + 开源框架”的自主可控 AI 推理闭环。如果大家在实践中遇到了什么问题,推荐去找找“昇腾PAE案例库”,说不定可以得到启发。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 12
12 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)