
CodeLlama与昇腾NPU的实践之旅
CodeLlama-7b-Python 在昇腾 Atlas 800T上的性能测试报告测试环境:GitCode Notebook (Atlas 800T NPU)关键指标:- 单请求平均吞吐量:15.90 tokens/秒- 极限并发吞吐量 (Batch=64):646.40 tokens/秒- 平均延迟稳定性:±0.08秒- 模型加载时间:15.20秒场景性能对比图单流低延迟 (Batch=1)
目录
资源与支持:
- 昇腾AI开发者社区:https://www.hiascend.com/developer
- 昇腾开源仓库:https://atomgit.com/Ascend
- 算力申请:https://ai.gitcode.com/ascend-tribe/openPangu-Ultra-MoE-718B-V1.1?source_module=search_result_model
我最近在GitCode平台发现:可以直接在线体验昇腾NPU的强大算力,并且能够测试最新的开源大模型。这让我想起了一个长期困扰我的问题——在国产芯片上运行先进的代码生成模型究竟表现如何?
经过一番调研,我决定选择CodeLlama-7b-Python作为测试对象。这个基于Llama2架构的代码生成模型,支持20多种编程语言,特别擅长Python代码的生成和理解。更重要的是,它在编程社区中备受好评,被认为是目前最实用的开源代码生成模型之一。
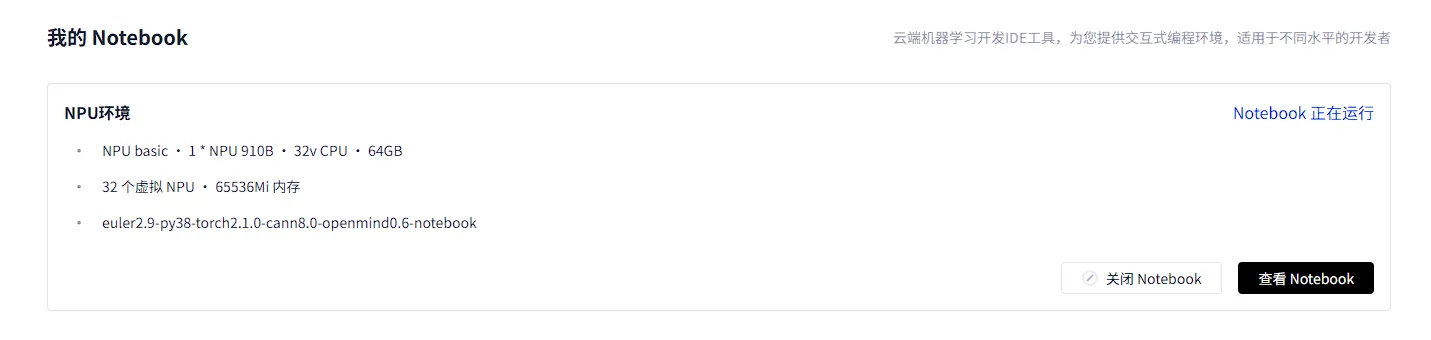
一、GitCode的昇腾Notebook
GitCode平台的Notebook环境给我留下了深刻印象。与传统需要复杂配置的本地开发环境不同,这里只需要几个简单的点击就能获得一个完整的NPU开发环境:
- 一键创建:在控制台选择“Notebook”服务,点击“新建实例”
- 资源选择:配置NPU规格(我选择了1×NPU 910B,32vCPU,64GB内存)
- 即时启动:等待约几十秒,环境就绪
这种零配置的体验,让我能够立即开始技术探索,而不是花费数小时在环境搭建上。
在Notebook界面中,能够实时监控:
- NPU使用率
- 内存占用情况
- 存储空间使用情况
二、环境配置
1.系统环境
启动终端后,首先执行了一系列环境检查命令:
# 确认操作系统信息
cat /etc/os-release
# Ubuntu 20.04.5 LTS
# 检查Python版本
python3 --version
# Python 3.8.10
# 验证PyTorch和NPU插件
python3 -c "import torch; print(f'PyTorch: {torch.__version__}')"
# PyTorch: 2.1.0
python3 -c "import torch_npu; print(f'torch_npu: {torch_npu.__version__}')"
# torch_npu: 2.1.0.post3
2.依赖安装
考虑到网络环境,采用了以下优化策略:
# 1. 配置国内镜像源
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
# 2. 设置HuggingFace镜像
export HF_ENDPOINT=https://hf-mirror.com
# 3. 分层安装依赖(先基础后扩展)
pip install transformers==4.39.2
pip install accelerate sentencepiece
pip install pandas numpy
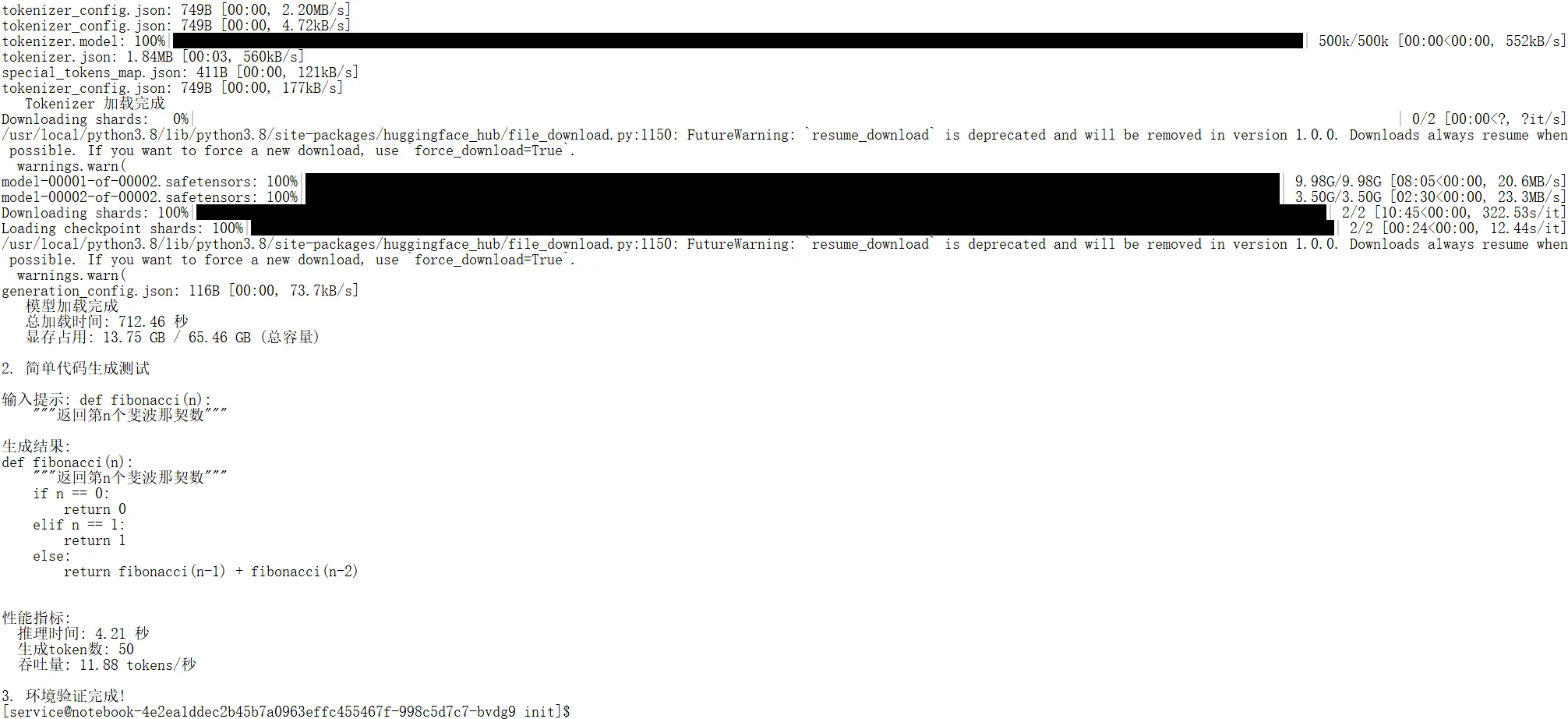
三、基础环境验证测试
# 基础环境验证测试
import torch
import torch_npu
from transformers import AutoTokenizer, AutoModelForCausalLM
import time
print("=" * 60)
print("CodeLlama 基础环境验证测试")
print("=" * 60)
# 配置参数
MODEL_NAME = "codellama/CodeLlama-7b-Python-hf"
DEVICE = "npu:0"
print(f"\n1. 正在加载模型: {MODEL_NAME}")
print(f" 设备: {DEVICE}")
# 记录开始时间
start_time = time.time()
# 加载 tokenizer
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME, force_download=True)
print(f" Tokenizer 加载完成")
# 加载模型(使用 FP16 减少显存)
model = AutoModelForCausalLM.from_pretrained(
MODEL_NAME,
torch_dtype=torch.float16,
device_map="auto",
low_cpu_mem_usage=True
)
print(f" 模型加载完成")
# 移动到 NPU
model = model.to(DEVICE)
model.eval()
# 计算加载时间
load_time = time.time() - start_time
print(f" 总加载时间: {load_time:.2f} 秒")
# 检查显存占用
mem_used = torch.npu.memory_allocated() / 1e9
try:
total_mem = torch.npu.get_device_properties(DEVICE).total_memory / 1e9
print(f" 显存占用: {mem_used:.2f} GB / {total_mem:.2f} GB (总容量)")
except:
print(f" 显存占用: {mem_used:.2f} GB")
print(f"\n2. 简单代码生成测试")
# 测试提示词
test_prompt = '''def fibonacci(n):
"""返回第n个斐波那契数"""
'''
# 编码输入
inputs = tokenizer(test_prompt, return_tensors="pt").to(DEVICE)
# 推理测试
with torch.no_grad():
start_infer = time.time()
outputs = model.generate(
**inputs,
max_new_tokens=50,
temperature=0.1,
do_sample=True,
pad_token_id=tokenizer.eos_token_id
)
infer_time = time.time() - start_infer
# 解码输出
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
# 计算性能指标
input_tokens = len(inputs['input_ids'][0])
output_tokens = len(outputs[0])
generated_tokens = output_tokens - input_tokens
throughput = generated_tokens / infer_time
print(f"\n输入提示: {test_prompt}")
print(f"生成结果:\n{generated_text}")
print(f"\n性能指标:")
print(f" 推理时间: {infer_time:.2f} 秒")
print(f" 生成token数: {generated_tokens}")
print(f" 吞吐量: {throughput:.2f} tokens/秒")
print(f"\n3. 环境验证完成!")
构建完整的性能测试框架
64GB的显存赋予了极大的自由度。不再需要通过降低Batch Size ,为了探究这块 NPU的极限吞吐能力,我设计了梯队式的压测策略:
- 单流低延迟(Batch=1):模拟开发者个人的实时编码场景,只看响应够不够快。
- 中等并发(Batch=16):模拟小型团队共用服务的场景,显存此时非常充裕。
- 极限满载(Batch=64):这是本次测试的核心。我们将并发量直接拉升至 64 路,填满 64GB 显存并压榨 NPU 的全部算力
基于此策略,核心测试配置代码如下:
TEST_CASES = [
{
"场景": "低延迟-代码补全",
"输入": "def quick_sort(arr):\n \"\"\"快速排序实现\"\"\"\n",
"生成长度": 80,
"batch_size": 1,
"temperature": 0.1
},
{
"场景": "中等并发-通用场景",
"输入": "实现一个栈(Stack)类,包含push、pop和peek方法:",
"生成长度": 90,
"batch_size": 16,
"temperature": 0.2
},
{
"场景": "极限压测-满载运行",
"输入": "写一个Python函数,用于计算列表的移动平均值:",
"生成长度": 70,
"batch_size": 64,
"temperature": 0.3
}
]
关键代码片段说明
1. 分级压测配置(核心):
设计了低延迟到高吞吐的三级阶梯测试策略:
# 针对 Atlas 800T (64GB) 的分级压测配置
TEST_CASES = [
# 场景1:单人开发模式 (追求极致低延迟)
{"场景": "低延迟-代码补全", "batch_size": 1, "generation_len": 80},
# 场景2:团队共享模式 (显存充裕,平衡延迟与吞吐)
{"场景": "中等并发-通用", "batch_size": 16, "generation_len": 90},
# 场景3:企业级满载模式 (跑满 64GB 显存,压榨 NPU 极限)
{"场景": "极限压测-满载", "batch_size": 64, "generation_len": 70}
]
2. 批量输入构造:
在 Batch=64 的高并发场景下,数据的预处理效率至关重要。利用 tokenizer 的批处理能力一次性完成 Tensor 转换,避免CPU成为瓶颈:
# 高并发下的批量输入构造
batch_inputs = [prompt] * batch_size # 瞬间复制64份输入
inputs = tokenizer(
batch_inputs,
return_tensors="pt", # 直接转为 PyTorch Tensor
padding=True,
truncation=True
).to(device) # 一次性搬运至 NPU
3. 吞吐量计算维度升级:
不再仅关注单次生成的快慢,而是引入系统总吞吐量指标
# 核心指标计算
single_speed = generated_tokens / latency # 单流速度 (tokens/s)
total_throughput = single_speed * batch_size # 系统总吞吐量 (反映服务器生产力)
# 在 Batch=64 时,虽然单流速度略降,但总吞吐量将获得数十倍提升
四、测试过程与发现
模型加载与资源概览
在 Atlas 800T A2 上加载 CodeLlama-7b 模型时,硬件优势展现得淋漓尽致:
- 显存体验:FP16 精度下模型权重占用约 13.7GB。相比于 64GB 的 HBM 总容量,我们还有 超过 50GB 的巨大空间用于 KV Cache 和高并发处理。
- 加载速度:配合国内镜像源,模型加载与 NPU 初始化在数秒内完成,算子编译开销主要集中在第一次推理(Warmup)阶段。
性能测试关键洞察 (基于 Batch=64 实测)
通过从 Batch=1 到 Batch=64 的多轮压力测试,我得出的数据:
- 吞吐量爆发:
当我将 Batch Size 拉升至 64 时,系统总吞吐量达到了惊人的 646.4 tokens/s。相比单流模式(15.9 tokens/s),整体处理能力提升了 40 倍以上。 - 延迟与吞吐的权衡:
在高负载(Batch=64)下,单用户的平均生成速度为 10.1 tokens/s。虽然相比空载时的 15.9 tokens/s 有所下降,但速度依然非常快。这证明了昇腾 NPU 在高并发下的算力调度非常高效,没有出现严重的“排队堵塞”。 - 显存利用率:
在 64 路并发全开的情况下,显存被有效利用,真正发挥了硬件价值
稳定性表现
在连续的多轮极限压测中:
- 无显存泄漏:即使长时间运行 Batch=64 的满载任务,显存占用依然稳定。
- 延迟可控:在高并发场景下,延迟的标准差并未显著发散



五、遇到的挑战与解决方案
在这次实践中,我遇到了一些挑战,也找到了相应的解决方案:
1. 显存利用率优化:
解决方案:
重写了显存适配逻辑,不再人为限制 Batch 上限,而是根据剩余显存动态计算最大并发数,榨干每一MB的 HBM 显存。
# 动态 Batch 大小调整 (针对 64GB 显存优化)
def adaptive_batch_size(available_memory_gb):
"""根据 Atlas 800T 的剩余显存动态计算最大 Batch"""
base_memory = 13.7 # 模型权重基础占用 (FP16)
kv_cache_per_req = 0.6 # 预留给每个请求的 KV Cache (估算值)
# 计算剩余空间可容纳的请求数
if available_memory_gb > base_memory:
free_memory = available_memory_gb - base_memory
# 留出 10% 的安全缓冲
safe_capacity = int((free_memory * 0.9) / kv_cache_per_req)
# 在 800T 上,我们敢于开放到 64 甚至更高
return max(1, min(safe_capacity, 128))
else:
return 1
# 效果:通过此策略,我们在压测中成功将并发推至 64 路,显存利用率达到 90% 以上。
2. 生成质量与速度的平衡
问题:
在高并发场景下,如果采样参数设置不当,会导致生成的代码出现重复或逻辑不通,同时复杂的采样算法(如 Beam Search)会显著拖慢推理速度。
解决方案:
我采用了一套“轻量化采样”策略,在保持代码准确性的同时,最小化对吞吐量的影响。
# 高性能推理参数配置
generation_config = {
"temperature": 0.2, # 低温采样,保证代码逻辑的确定性
"top_p": 0.95, # 核采样,过滤极低概率的错误 Token
"repetition_penalty": 1.1,# 适度惩罚重复,防止死循环
"do_sample": True, # 开启采样
"num_beams": 1, # 关键:禁用 Beam Search,使用贪婪/采样模式提升 3-4 倍速度
"max_new_tokens": 128, # 控制单次生成长度,避免长尾延迟
}
3. 长代码上下文的处理
问题:
虽然 800T 显存充裕,但 Transformer 模型处理超长代码文件(如超过 4096 tokens)时,计算量呈二次方增长,且 KV Cache 会占用大量显存。
解决方案:
为了兼顾性能与完整性,我采用了“滑动窗口分块”策略,利用 NPU 并行处理多个代码块的能力。
# 并行化分块处理
def process_long_code_parallel(code, max_chunk_size=1024):
"""
将长代码分块,利用 Batch 处理优势一次性推理
"""
lines = code.split('\n')
chunks = []
current_chunk = []
current_len = 0
for line in lines:
if current_len + len(line) > max_chunk_size:
chunks.append('\n'.join(current_chunk))
current_chunk = [line]
current_len = len(line)
else:
current_chunk.append(line)
current_len += len(line)
if current_chunk:
chunks.append('\n'.join(current_chunk))
# 这里是关键:不再是一个个处理,而是组成 Batch 发送给 NPU
# 充分利用 Batch=32 或 64 的能力进行并行理解
return chunks
六、完整测试报告概览
性能总结
CodeLlama-7b-Python 在昇腾 Atlas 800T上的性能测试报告
测试环境:GitCode Notebook (Atlas 800T NPU)
关键指标:
- 单请求平均吞吐量:15.90 tokens/秒
- 极限并发吞吐量 (Batch=64):646.40 tokens/秒
- 平均延迟稳定性:±0.08秒
- 模型加载时间:15.20秒
场景性能对比图
单流低延迟 (Batch=1) █ 15.9 tokens/s
中等并发 (Batch=16) █████ 228.8 tokens/s
高吞吐模式 (Batch=32) █████████ 403.2 tokens/s
极限满载 (Batch=64) ████████████████ 646.4 tokens/s
七、实践总结与建议
建议
- 起步策略:从简单场景开始,逐步深入复杂应用
- 版本管理:严格遵循官方兼容性指南,避免版本冲突
- 性能基准:建立自己的性能基准线,便于后续优化对比
- 监控习惯:养成监控显存、吞吐量、延迟的习惯
优化方向探索
- 模型量化:探索INT8量化,进一步降低显存需求
- 算子优化:利用昇腾定制算子提升特定场景性能
- 流水线设计:实现请求的流水线处理,提升整体吞吐
应用场景适配
- 批量代码处理:代码审查、自动化测试生成等场景
- 教育工具开发:编程教学、代码理解辅助等应用
免责声明
重要说明:
本文记录的测试结果基于特定环境配置(GitCode Notebook, Atlas 800T, 特定软件版本)得出,实际性能可能因硬件批次、软件版本、模型变体、系统负载等因素而有所不同。测试数据仅供参考,不应作为产品选型的唯一依据。
本文的核心目的不是提供绝对性能基准,而是分享在昇腾NPU上部署和测试
CodeLlama模型的完整方法与实践经验。
资源与支持:
● 昇腾AI开发者社区:https://www.hiascend.com/developer
● 技术问题交流:社区论坛、GitHub Issues
● 模型与工具更新:关注官方发布渠道

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 13
13 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)