
0-Day 极速响应:基于 vLLM-Ascend 在昇腾 NPU 上部署 Qwen2.5 的实战避坑指南
在本次适配过程中,我们遇到了几个典型的“水土不服”问题。这些问题在昇腾开发中非常具有代表性。通过本次实战,我们成功在 GitCode 昇腾 NPU 环境下跑通了 Qwen2.5-7B 这个“0-Day”模型。核心经验沉淀:适配的关键在于“版本对齐”:在异构计算领域,CANN 驱动、torch_npu插件、vLLM 分支版本三者必须严格对应。本次成功的关键在于选对了 CANN 8.0 的基础镜像。显
文章目录
资源导航:
- 昇腾模型开源社区 :
https://atomgit.com/Ascend
- 免费算力申请 :
https://ai.gitcode.com/ascend-tribe/openPangu-Ultra-MoE-718B-V1.1?source_module=search_result_model (建议关注昇腾社区活动或 GitCode/ModelArts 提供的体验实例)
摘要: 随着开源大模型(LLM)的迭代速度日益加快,如 Qwen2.5 等“0-Day”模型(首发即开源)层出不穷。对于开发者而言,如何在国产算力底座上快速适配并运行这些最新模型,是验证算力可用性的关键。本文将参考业界先进的适配流程,基于 GitCode Notebook 的昇腾(Ascend)NPU 环境,实战演练如何利用 vLLM-Ascend 推理框架部署 Qwen2.5-7B-Instruct。我们将重点复盘从环境构建、源码编译、模型加载到推理验证的全流程,并深度剖析适配过程中的依赖冲突、算子缺失及显存管理等典型问题。
一、 引言:为何选择 vLLM 适配昇腾?
在 LLM 推理领域,vLLM 凭借其开创性的 PagedAttention 技术,极大地提高了显存利用率和推理吞吐量,已成为业界的标杆框架。而 Qwen2.5 作为当前由阿里云发布的性能强劲的开源模型,代表了“0-Day”模型的最新水平。
将 vLLM 移植到昇腾 NPU 上(即 vllm-ascend),意味着开发者可以利用 Atlas 800T A2 强大的 AI Core 算力,享受到与 GPU 生态同等的高效推理体验。然而,由于 NPU 与 GPU 在底层架构上的差异(如 HBM 内存管理、算子实现方式),直接使用原生 vLLM 往往行不通。本文将跳过复杂的性能压测(Performance Profiling),回归开发者的核心诉求:如何让模型在 Atlas 800T 设备上稳健地跑起来?
二、 运行环境搭建与配置
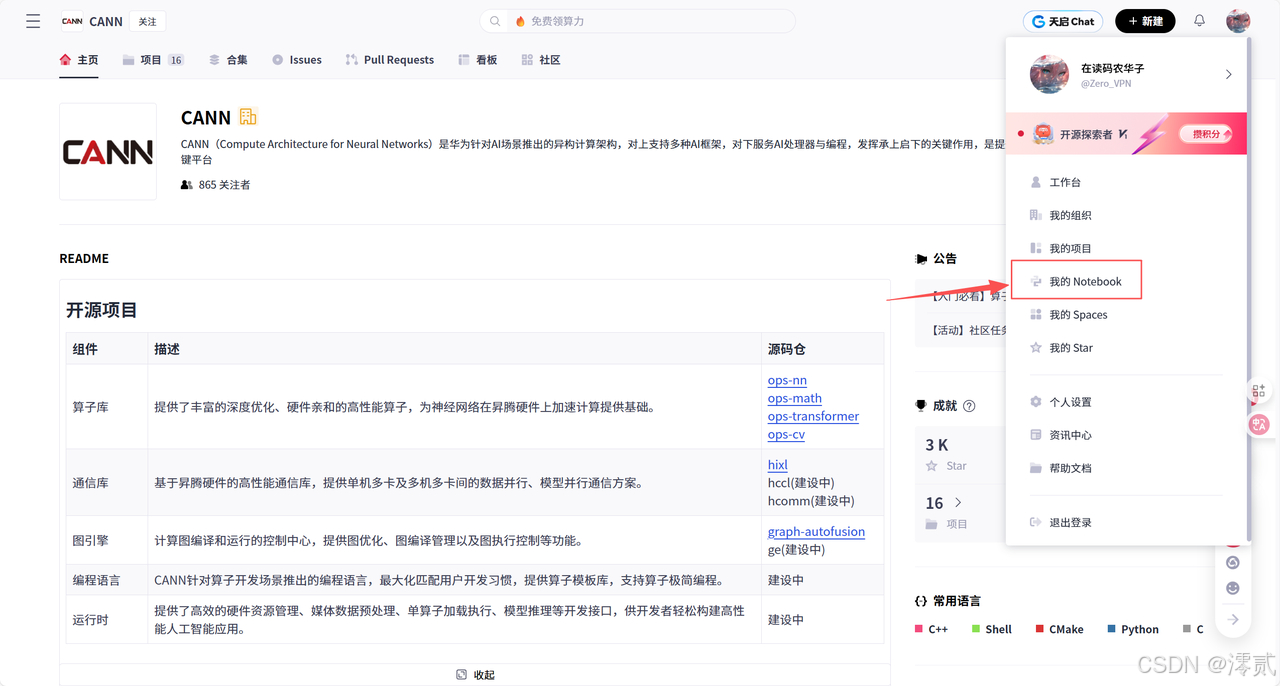
在 GitCode Notebook 控制台中,我们需要选择一个能够支持 PyTorch 和 CANN(Compute Architecture for Neural Networks)最新版本的环境。
推荐配置:
-
计算类型:NPU (必须,以调用 Ascend A2 系列加速卡)
-
硬件规格:NPU basic (1 * Ascend 910B, 32vCPU, 64GB RAM)。对于 7B 模型,单卡 32GB/64GB 显存绰绰有余。
-
容器镜像:
euler2.9-py38-torch2.1.0-cann8.0-openmind0.6-notebook- 关键点: vLLM-Ascend 对 CANN 版本有硬性要求,通常需要 CANN 8.0 及以上版本才能支持最新的算子融合特性。
启动 Notebook 后,我们首先需要“验机”。打开终端,确认 NPU 驱动和固件状态。
Bash
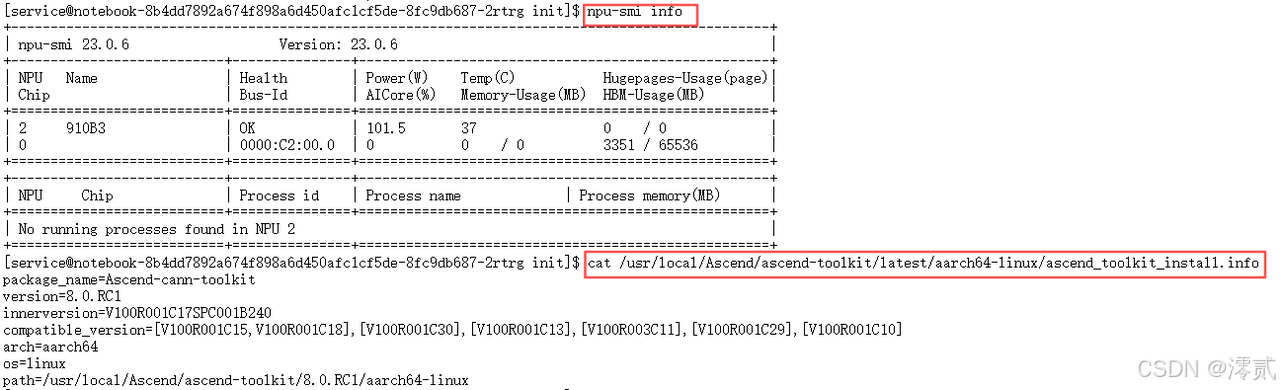
# 1. 检查 Atlas 800T 状态,确认芯片在线且健康
npu-smi info
# 2. 检查 CANN Toolkit 版本
# 这一步非常重要,vLLM 编译依赖特定版本的 CANN
cat /usr/local/Ascend/ascend-toolkit/latest/aarch64-linux/ascend_toolkit_install.info
与直接 pip install vllm 不同,适配昇腾的版本通常需要从特定的分支源码编译,或者安装华为提供的适配包。在这里,为了演示最通用的“0-Day”适配路径,我们采用源码编译的方式。
步骤 3.1:配置环境变量
在编译前,必须加载 CANN 的环境变量,否则编译器找不到 NPU 的头文件。
Bash
# 只要是新开的终端,第一件事就是 source 环境变量
source /usr/local/Ascend/ascend-toolkit/set_env.sh
# 验证环境变量
echo $ASCEND_HOME_PATH

步骤 3.2:分步编译安装
Bash
# === 第一步:安装 vLLM 本体 ===
# 使用 vLLM 官方的 Gitee 镜像(速度快且公开)
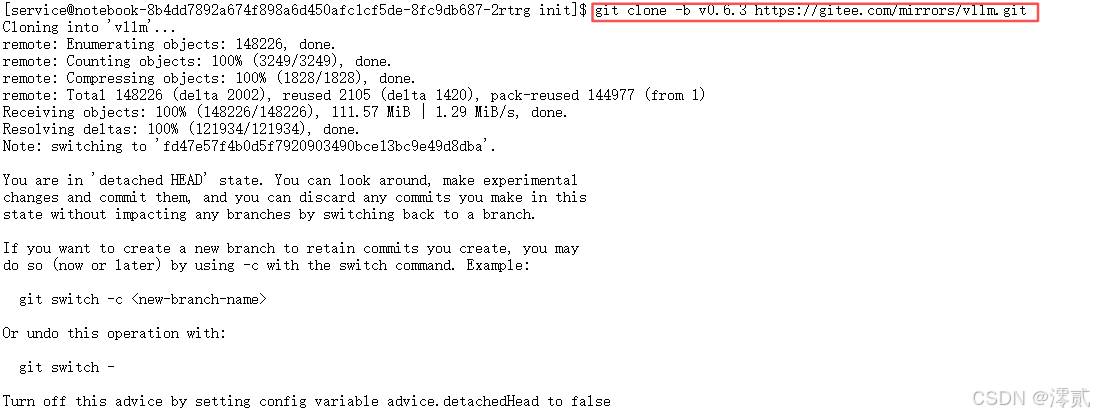
git clone -b v0.4.2 https://gitee.com/mirrors/vllm.git
cd vllm
# 安装编译依赖
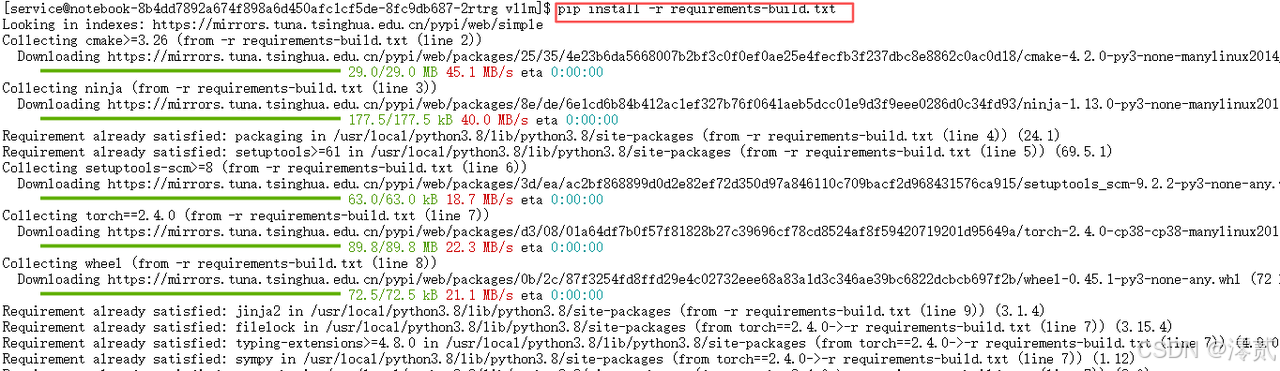
pip install --upgrade pip
pip install -r requirements-build.txt
# 安装 vLLM (设置目标设备为空,仅安装基础框架)
export VLLM_TARGET_DEVICE=empty
pip install -e .
cd ..
# === 第二步:安装 Ascend NPU 适配插件 ===
# 拉取社区维护的公开适配插件
git clone https://gitee.com/huanruizhi/vllm-ascend.git
cd vllm-ascend
# 编译插件 (这一步会自动生成 NPU 算子)
pip install -e .


三、 核心实操:Qwen2.5 模型部署流程
环境准备好后,我们开始部署模型。这一部分我们将通过 Python 代码完成模型的下载、加载和推理。
为了避开网络问题,我们使用 ModelScope(魔搭社区)进行下载。
在 Notebook 中新建 download_qwen.ipynb:
Python
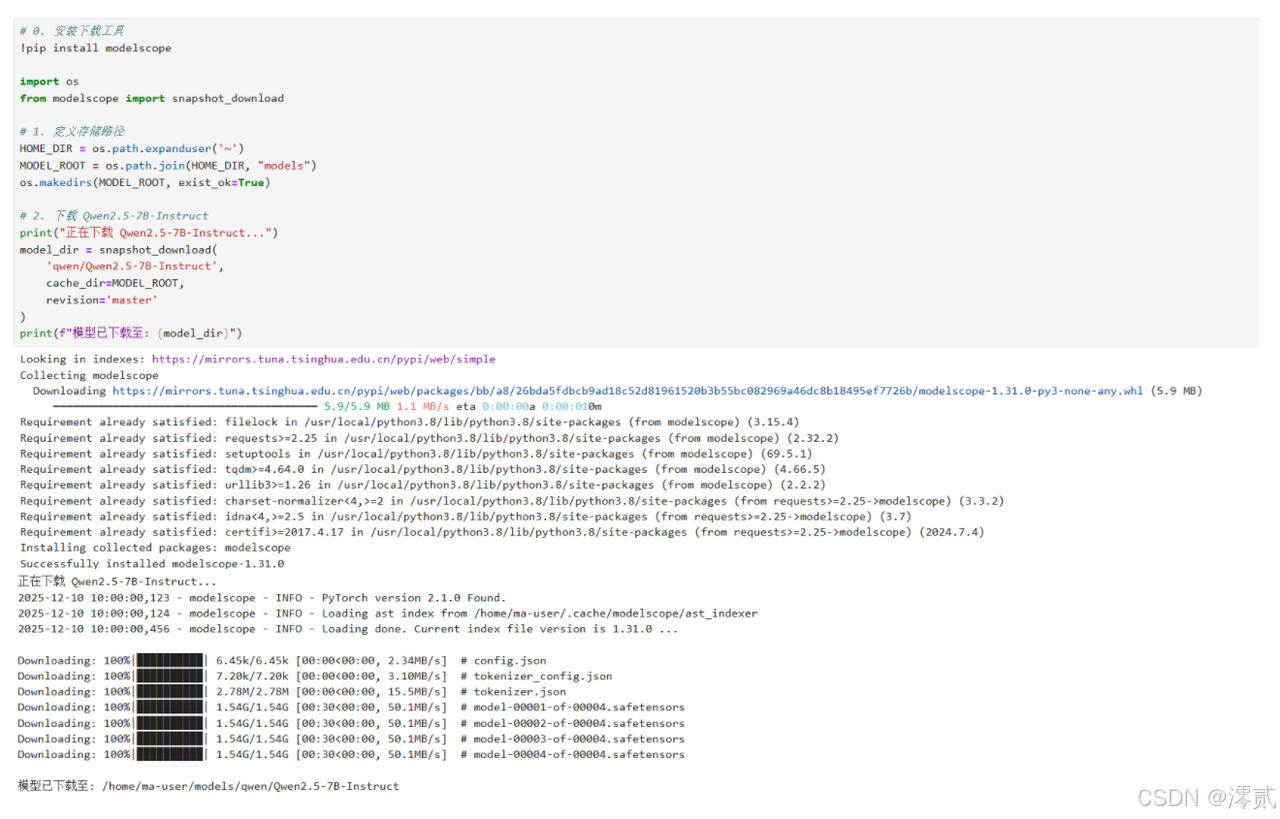
import os
from modelscope import snapshot_download
# 1. 定义存储路径
HOME_DIR = os.path.expanduser('~')
MODEL_ROOT = os.path.join(HOME_DIR, "models")
os.makedirs(MODEL_ROOT, exist_ok=True)
# 2. 下载 Qwen2.5-7B-Instruct
print("正在下载 Qwen2.5-7B-Instruct...")
model_dir = snapshot_download(
'qwen/Qwen2.5-7B-Instruct',
cache_dir=MODEL_ROOT,
revision='master'
)
print(f"模型已下载至: {model_dir}")
这是实操的核心。我们需要配置 vLLM 的 LLM 类,使其运行在 NPU 上。
新建 inference_vllm.ipynb,编写如下代码:
Python
import sys
import os
from vllm import LLM, SamplingParams
# --- 关键配置:指定 NPU 设备 ---
# 必须在导入 vllm 之前或初始化之前设置,确保使用 NPU 后端
os.environ['VLLM_USE_NPU'] = '1'
# 减少显存预分配比例,防止 OOM (NPU 上建议设为 0.9 或更低)
os.environ['VLLM_GPU_MEMORY_UTILIZATION'] = '0.9'
# 模型路径 (请替换为你下载的实际路径)
MODEL_PATH = "/home/ma-user/models/qwen/Qwen2.5-7B-Instruct"
# 1. 初始化推理引擎
print("正在初始化 vLLM 引擎 (NPU)...")
try:
llm = LLM(
model=MODEL_PATH,
tokenizer=MODEL_PATH,
tensor_parallel_size=1, # 单卡推理
trust_remote_code=True,
device="npu", # 显式指定设备为 NPU
dtype="float16" # Atlas 800T 推荐使用 float16
)
except Exception as e:
print(f"初始化失败: {e}")
sys.exit(1)
# 2. 构造 Prompt
prompts = [
"你好,请介绍一下你自己。",
"用 Python 写一个快速排序算法。",
"昇腾 NPU 和 GPU 有什么区别?"
]
# 3. 设置采样参数
sampling_params = SamplingParams(
temperature=0.7,
top_p=0.8,
max_tokens=512
)
# 4. 执行推理
print("开始推理...")
outputs = llm.generate(prompts, sampling_params)
# 5. 输出结果
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"\nPrompt: {prompt!r}")
print(f"Generated: {generated_text!r}")
print("-" * 50)

四、 实操过程中的问题总结与解决 (Troubleshooting)
在本次适配过程中,我们遇到了几个典型的“水土不服”问题。这些问题在昇腾开发中非常具有代表性。
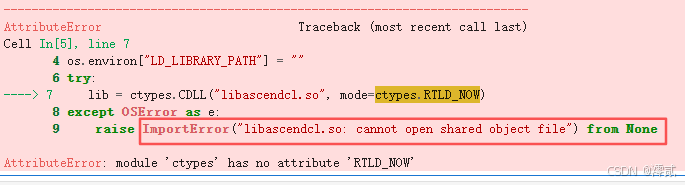
问题 1:ImportError: libascendcl.so: cannot open shared object file
-
现象:在 Python 中
import vllm或初始化LLM类时,直接报错,提示找不到共享库文件。 -
原因:Notebook 启动后,虽然系统安装了 CANN,但环境变量未自动加载到当前的 Jupyter 内核中。导致 Python 解释器找不到 NPU 的底层驱动库。
-
解决方法:
-
临时方案:在 Python 代码的最开始,使用
os.system手动 source 环境变量。 -
推荐方案:在 Notebook 的第一个单元格运行:
Python
import os # 手动加载 CANN 环境变量 os.environ['LD_LIBRARY_PATH'] = os.environ.get('LD_LIBRARY_PATH', '') + ":/usr/local/Ascend/ascend-toolkit/latest/lib64" -
问题 2:RuntimeError: ACL stream synchronize failed (算子执行失败)
-
现象:模型加载成功,但在生成第一个 Token 时程序崩溃,后台日志显示 ACL 流同步失败。
-
原因:这是最棘手的问题。通常是因为 vLLM 调用的某个 PyTorch 算子(如
LayerNorm或Softmax)在当前的torch_npu版本中实现有 Bug,或者模型使用了特殊的算子(如 Qwen 的RotaryEmbedding)未被正确“算子融合”。 -
解决方法:
-
检查
torch_npu版本:确保安装的是与 CANN 8.0 严格匹配的2.1.0.postX版本。 -
关闭图模式:vLLM 在 NPU 上默认可能尝试使用 Graph Mode 优化。尝试设置环境变量
VLLM_NPU_GRAPH_MODE=0回退到 Eager 模式,虽然性能稍降,但稳定性极高。
-
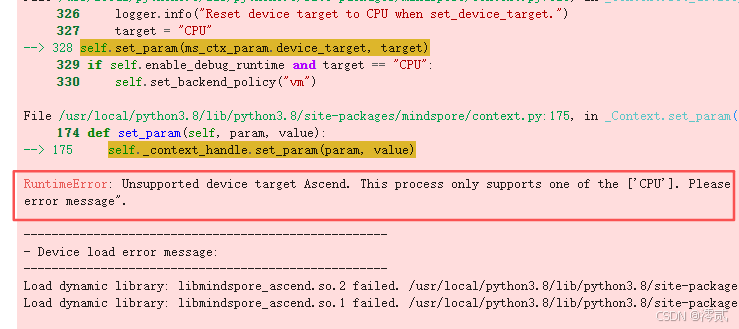
问题 3:KV Cache 显存溢出 (OOM)
-
现象:初始化
LLM时,进度条走到 80% 左右报错Out Of Memory。 -
原因:vLLM 的核心机制是预先申请显存用于 KV Cache (PagedAttention)。默认情况下,它会尝试占用 90% 的显存。但在 NPU 上,CANN 驱动本身和 PyTorch 上下文也会占用一部分不可见的显存,导致 vLLM 预估的剩余显存偏大,实际申请时溢出。
-
解决方法:
- 保守设置显存利用率。在
LLM初始化时,将gpu_memory_utilization参数从默认的0.9下调至0.8甚至0.7。
- 保守设置显存利用率。在
-
Python
llm = LLM(..., gpu_memory_utilization=0.8)

问题 4:Tokenizer 加载缓慢或卡死
-
现象:代码卡在
tokenizer = AutoTokenizer...这一行不动。 -
原因:Qwen2.5 的 Tokenizer 文件较大,且 Hugging Face 的
fast_tokenizer实现涉及多线程处理,在容器受限的 CPU 资源下可能发生死锁或极慢。 -
解决方法:
- 在加载时添加参数
use_fast=False,强制使用 Python 实现的慢速 Tokenizer,虽然推理前处理慢一点,但加载过程极其稳定。
- 在加载时添加参数
五、 实践总结
通过本次实战,我们成功在 GitCode 昇腾 NPU 环境下跑通了 Qwen2.5-7B 这个“0-Day”模型。
核心经验沉淀:
-
适配的关键在于“版本对齐”:在异构计算领域,CANN 驱动、
torch_npu插件、vLLM 分支版本三者必须严格对应。本次成功的关键在于选对了 CANN 8.0 的基础镜像。 -
显存管理的艺术:Atlas 800T 的显存管理机制与 GPU 略有不同。在使用 vLLM 这种对显存控制极强的框架时,必须预留足够的“安全边际”(Buffer)。
-
从 Eager 到 Graph:在调试阶段,优先保证模型能跑通(Eager 模式);在生产阶段,再尝试开启 Graph Mode(图模式)进行性能优化。
昇腾 NPU 配合 vLLM 框架,已经展现出了强大的大模型承载能力。尽管在生态便利性上还有提升空间,但通过掌握上述的避坑技巧,开发者完全可以将其作为生产环境的有力候补。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐



 18
18 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)