
【昇腾CANN训练营·巅峰篇】打破显存高墙:FlashAttention 算子在昇腾 NPU 上的极致优化之道
摘要:本文深入探讨了在昇腾NPU上实现高性能FlashAttention的关键技术。针对Transformer中Self-Attention的O(N²)复杂度问题,通过IO感知和分块计算技术,结合昇腾DaVinci架构特性,详细解析了OnlineSoftmax实现、双缓冲流水线优化等核心方法。文章从硬件微架构角度出发,阐述了如何平衡计算与访存瓶颈,实现显存高效利用和算力充分压榨,为开发者提供了在昇
训练营简介 2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro

摘要:在大模型长序列训练中,Self-Attention 的 $O(N^2)$ 复杂度是显存的噩梦。FlashAttention 的横空出世,通过 IO-Awareness(IO 感知) 和 Tiling(分块) 技术,将显存占用降至线性。本文将深入昇腾 Da Vinci 架构 的存储层级,解析如何用 Ascend C 手搓一个高性能的 FlashAttention,并探讨 Online Softmax 与 双缓冲流水线 的工程实现细节。
前言:当 Transformer 遇到“长文恐惧症”
Self-Attention 机制是 Transformer 的灵魂,但它有一个致命的数学缺陷:计算复杂度与序列长度的平方成正比。 计算公式:$\text{Attention}(Q, K, V) = \text{Softmax}(\frac{QK^T}{\sqrt{d_k}})V$
当我们处理 2K 长度时,中间矩阵 $S = QK^T$ 的大小是 $2048 \times 2048$,还可以接受。 但当序列长度扩展到 32K 甚至 128K 时,$S$ 矩阵的大小将达到 $32K \times 32K$,在 FP16 下占用 2GB 显存。这仅仅是一个 Head 的一层! 这就好比你想在厨房(SRAM/UB)里做一道满汉全席,但桌子太小,只能把菜都堆在遥远的仓库(HBM/DDR)里,厨师(AI Core)大部分时间都在往返仓库搬菜,而不是在炒菜。
FlashAttention 的核心思想就是:别把满汉全席一次性搬出来,我们切成小块,在厨房里边搬边炒,炒完直接端走,不留剩菜。
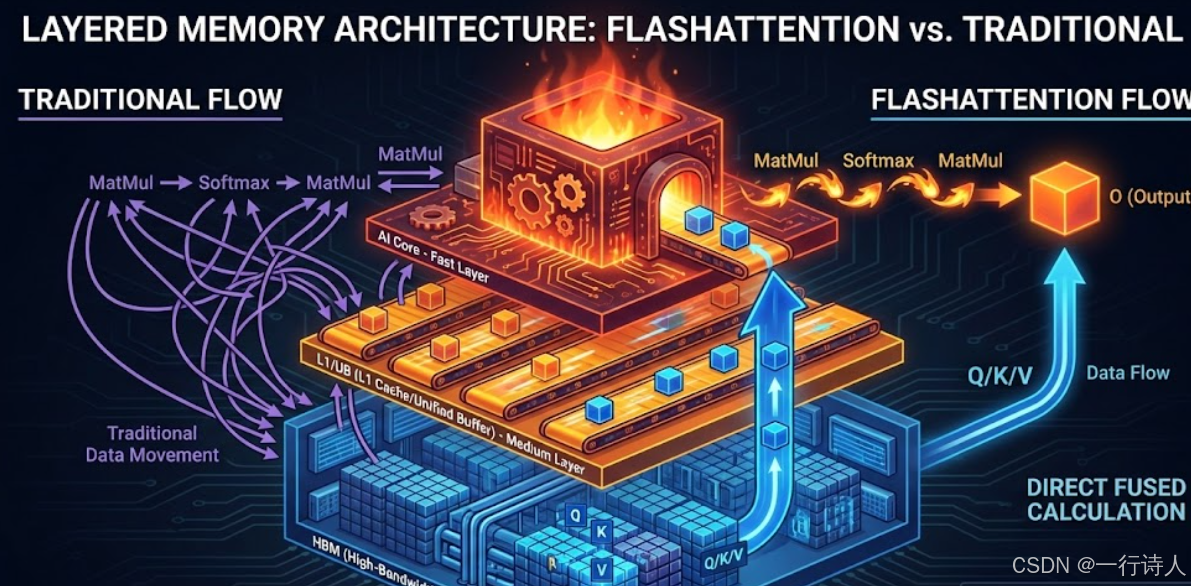
一、 核心图解:达芬奇架构下的“分块烹饪”
在昇腾 NPU 上实现 FlashAttention,本质上是管理 HBM (Global Memory) -> L1 Buffer -> Unified Buffer (UB) 的数据流动。
-
传统 Attention:先算出完整的 $S = QK^T$ 存入 HBM,读取 $S$ 算 Softmax 存入 HBM,再读取 $P$ 和 $V$ 算 $PV$。HBM 读写量巨大。
-
FlashAttention:将 $Q, K, V$ 切分成小块(Block)。在 L1/UB 这种高速缓存中,一次性算完 $Q_i K_j^T$,接着算 Softmax,接着乘 $V_j$,全程中间结果不落盘(不写回 HBM)。
二、 关键技术一:Online Softmax 的 NPU 适配
在上一篇 Softmax 文章中,我们提到了 Online Softmax。在 FlashAttention 中,这是必选项。 因为我们是分块计算的,当计算第一块 $Q_1 K_1^T$ 时,我们并不知道整行的 Max 是多少,也就无法做标准的 Softmax。
我们需要维护两个全局状态变量:
-
m: 当前行的全局最大值。 -
l: 当前行的全局指数和(Exp Sum)。
当新的块 $Q_1 K_2^T$ 算出来后,利用数学公式动态更新 m 和 l,并对已经算出的部分结果 $O$ 进行修正(Rescale)。
Ascend C 实现挑战: 在 NPU 上,Softmax 通常在 Vector Unit 执行,而 MatMul 在 Cube Unit 执行。 FlashAttention 需要频繁地在 Cube(算 $QK^T$)和 Vector(算 Softmax)之间切换。这要求我们精细控制 MTE2 -> Cube -> Vector -> Cube 的数据流,避免流水线断裂。
三、 关键技术二:Tiling 策略与双循环
FlashAttention 的外层循环通常遍历 $Q$ 的分块,内层循环遍历 $K, V$ 的分块。
// 伪代码:Ascend C FlashAttention 逻辑
for (int i = 0; i < Tr; i++) { // 遍历 Q 的分块
// 1. Load Qi 到 L1/UB
DataCopy(Qi_L1, Qi_GM);
for (int j = 0; j < Tc; j++) { // 遍历 K, V 的分块
// 2. Load Kj, Vj 到 L1/UB
// 这里可以使用 Double Buffer 预取技术
DataCopy(Kj_L1, Kj_GM);
DataCopy(Vj_L1, Vj_GM);
// 3. Cube 计算 S_ij = Qi * Kj^T
MatMul(S_ij, Qi_L1, Kj_L1);
// 4. Vector 计算 Online Softmax
// 需要处理 m_new, l_new 的更新逻辑
// 以及对旧结果 O_i 的 Rescale
Vector_Softmax_Update(S_ij, O_i, m_i, l_i);
// 5. Cube 计算 O_i += P_ij * Vj
MatMul(O_i, P_ij, Vj_L1);
}
// 6. 最终归一化并 Store Oi
DataCopy(Oi_GM, Oi_L1);
}
深度思考:Block Size 如何定? 昇腾 910B 的 UB 大小通常在 192KB - 256KB 级别。 我们需要在 UB 中同时放下 $Q_i, K_j, V_j$ 以及中间结果 $S_{ij}$。
-
$S_{ij}$ 的大小是 $Br \times Bc$。
-
如果 $Br, Bc$ 太大,UB 爆仓。
-
如果 $Br, Bc$ 太小,Cube 单元的计算效率(利用率)不够,且访存次数变多。 通常需要通过理论计算和 Profiling 实测,找到一个让 Compute Bound(计算瓶颈)和 Memory Bound(访存瓶颈)完美平衡的黄金切分点。
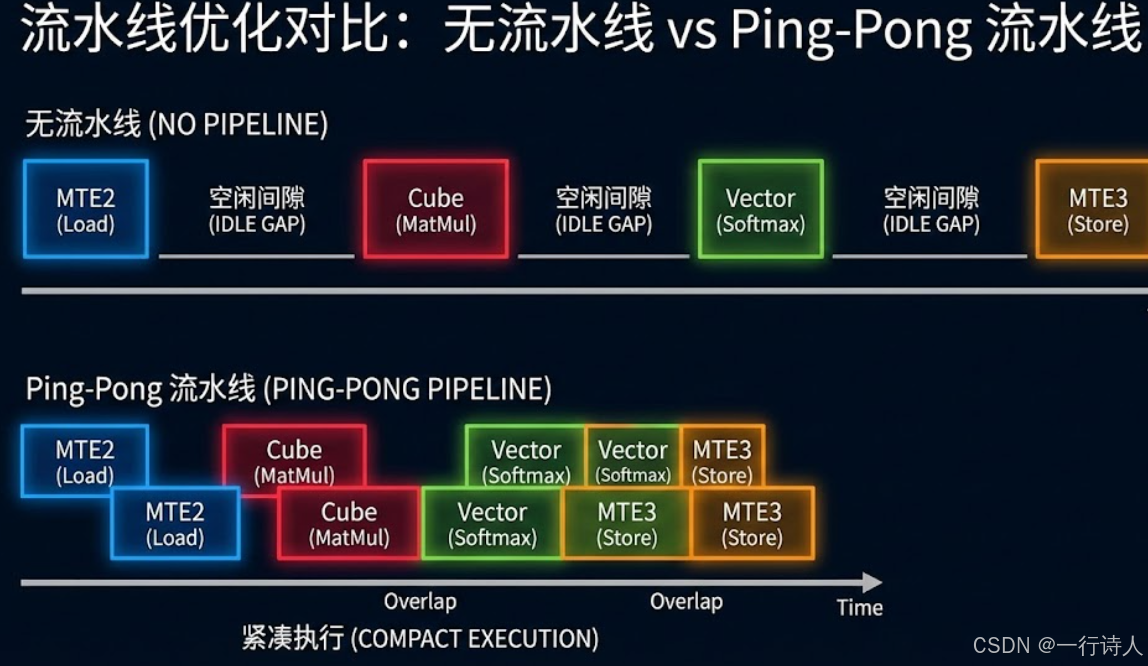
四、 极致优化:Ping-Pong 流水线
在内层循环中,数据的加载(MTE2)和计算(Cube/Vector)是串行的吗? 绝对不行! 必须并行。
Ascend C 提供了 TQue (Queue) 机制来实现双缓冲(Ping-Pong Buffer)。 当 Cube 正在计算第 $j$ 块 $K, V$ 时,MTE2 应该正在疯狂搬运第 $j+1$ 块 $K, V$。
五、 总结
FlashAttention 是算子开发领域的“珠穆朗玛峰”。它不仅考验你对算法数学原理的理解(Online Softmax),更极其考验你对硬件微架构的掌控力:
-
显存管理:精确到 Byte 的 UB 规划。
-
流水编排:Cube 与 Vector 的异构协同,MTE 与 Core 的计算访存重叠。
-
算力压榨:让 Cube 单元始终处于忙碌状态,消灭 Bubble。
当你能在昇腾 NPU 上手写出一个跑赢官方库的 FlashAttention 时,你就不再只是一个 API 调用者,而是一名真正的体系结构工程师。
本文涉及的算法细节基于 FlashAttention-2 论文,硬件特性基于 Ascend 910B AI 处理器。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐
 11
11 0
0- 0



 已为社区贡献46条内容
已为社区贡献46条内容

所有评论(0)