
Catlass自定义算子开发:从模板到高性能实现
摘要: 昇腾平台的Catlass算子模板库通过分层抽象和声明式开发,大幅简化高性能算子(如矩阵乘法)的实现。Catlass将硬件细节(如缓存管理、流水线)封装为C++模板,开发者只需定义矩阵参数、Tiling策略和调度方式,即可快速构建接近理论峰值的算子。本文基于官方Catlass仓库,从工程搭建、四层架构解析到代码实战(FP16矩阵乘法),详细演示了BlockMmad模板的使用,涵盖编译、验证与
在昇腾(Ascend)平台上开发高性能算子时,我们往往会面临一个选择:是使用 TIK C++(原 Ascend C)从零开始手写每一行代码,还是寻找更高效的捷径?而在昇腾生态中,Catlass 正是这样一个让高性能算子开发变得熟悉又高效的工具。
Catlass 是昇腾官方推出的算子模板库,它的核心理念非常直接:不要重复造轮子。通过将矩阵乘法(GEMM)等核心计算逻辑抽象为可复用的 C++ 模板,Catlass 让我们能够像搭积木一样组装出高性能算子,同时还能保持对底层硬件(如 L1/L0 缓存、Cube Unit)的精细控制。
在这篇文章中,我将带大家基于官方最新的 Catlass 仓库 (https://gitcode.com/cann/catlass),亲手实现一个自定义的矩阵乘法算子。我们会从最基础的工程结构讲起,一直到代码实现、编译运行以及性能分析,全程硬核实战。
大家需要代码的话直接在gitcode就可以Clone下来了,这个也是非常方便的。
1. 为什么选择 Catlass?
在开始写代码之前,我想先聊聊“为什么”。
在传统的算子开发中,我们需要手动管理数据在 HBM、L1、L0 之间的搬运,还需要处理复杂的同步逻辑(Synchronization)和流水线(Pipeline)。这不仅代码量巨大,而且极易出错。
Catlass 引入了分层设计(Hierarchy Design),将复杂的硬件细节封装在模板中。你只需要关注:
- 做什么(定义矩阵大小、数据类型)
- 怎么分(定义 Tiling 策略)
- 怎么算(选择 Dispatch Policy)
这种“声明式”的开发体验,能让我们在几百行代码内实现接近理论峰值性能的算子。
2. 工程搭建:起步的第一块砖
首先,我们需要准备一个干净的开发环境。Catlass 依赖 CMake 进行构建,这意味着我们可以非常方便地将其集成到现有的 C++ 工程中。CMake 的好处是跨平台、模块化、支持依赖管理,能够自动生成适合不同编译器和操作系统的 Makefile 或工程文件,这对于复杂的算子库尤其重要。
在 gitcode 的代码仓库里,我们也可以看到 CMake 文件夹,里面包含了 Catlass 构建所需的顶层 CMakeLists.txt 以及各模块的子 CMake 文件。后续我们只需要通过 CMake 来管理工程和编译流程。
cmake文件夹:
CmakeLists.txt:
2.1 项目结构
一个标准的 Catlass 自定义算子项目通常包含以下几个部分。我在本地创建了一个名为 catlass_demo 的项目,结构如下:
catlass_demo/
├── CMakeLists.txt # 构建脚本
├── scripts/
│ └── build.sh # 编译入口
└── src/
├── main.cpp # Host 侧主程序(负责数据初始化和校验)
└── my_matmul_kernel.cpp # Device 侧核心算子实现各部分说明:
CMakeLists.txt
- 是整个项目的构建核心
- 定义项目名称、C++ 标准、依赖库路径
- 可以指定编译选项、优化级别,以及 Catlass 头文件和库的引用
- 支持跨平台构建,无需手动管理编译命令
scripts/build.sh
- 提供一键编译功能
- 通常包含创建
build目录、运行 CMake 配置、调用make或ninja编译的流程 - 可以在脚本里添加环境检查,比如 Ascend SDK 是否安装、路径是否正确等
src/main.cpp
- Host 程序,运行在 CPU 侧
- 主要职责:
-
- 初始化矩阵数据(随机或固定值)
- 调用 Catlass 定义好的算子对象
- 收集和校验结果(比如与简单 CPU 实现对比)
- 可以添加性能统计,例如执行时间或吞吐量
src/my_matmul_kernel.cpp
- Device 核心算子实现
- 使用 Catlass 模板定义矩阵乘法(GEMM)或其他自定义算子
- 负责指定数据类型、布局、Tile 大小、流水线策略等
- 完全封装底层硬件细节,Host 侧只需要直接调用
2.2 核心依赖
在 CMakeLists.txt 中,最关键的一步是找到并链接 Catlass 库。官方仓库通常会将头文件安装在 /usr/local/Ascend/catlass 下。
# 关键配置片段
find_package(Catlass REQUIRED)
target_link_libraries(my_matmul Catlass::Catlass)3. 核心概念:四层抽象与 Tiling
Catlass 的强大之处在于它对计算任务的层级化切分。这不仅仅是代码层面的抽象,更是对昇腾 AI Core 硬件架构的直接映射。
3.1 理解四层架构
我在翻阅 Catlass 官方文档和源码时,总结出了这个至关重要的四层模型:
- Grid Level (Device): 对应整个矩阵乘法任务 $(M, N, K)$,数据在 HBM 中。
- Block Level (AI Core): 对应
L1TileShape。这是单个 AI Core 处理的数据块大小,数据被搬运到 L1 Buffer。 - Warp Level (Cube Unit): 对应
L0TileShape。这是计算单元(Cube)处理的粒度,数据进一步加载到 L0A/L0B Buffer。 - Instruction Level (Fragment): 对应底层的 MMAD 指令,数据在寄存器中进行原子计算。
4. 代码实战:编写你的第一个 BlockMmad 算子
现在,让我们进入最激动人心的环节——写代码。我们将使用 BlockMmad 模板来实现一个 FP16 的矩阵乘法。
打开 src/my_matmul_kernel.cpp,我们会看到非常现代化的 C++ 模板代码:
#include "catlass/catlass.hpp"
#include "catlass/gemm/block/block_mmad.hpp"
using namespace Catlass;
// 1. 定义 Tiling 策略
// L1 Tile: 决定了每个 AI Core 一次搬运多少数据到 L1
// 经验值:需要适配 L1 Buffer 大小 (通常 256KB-512KB)
using L1TileShape = GemmShape<128, 256, 256>;
// L0 Tile: 决定了 Cube Unit 的计算粒度
using L0TileShape = GemmShape<128, 64, 64>;
// 2. 选择架构与调度策略
// AtlasA2 对应 Ascend 910B 系列
using ArchTag = Arch::AtlasA2;
// Pingpong<true> 开启双缓冲流水线,这是性能的关键!
using DispatchPolicy = Gemm::MmadAtlasA2Pingpong<true>;
// 3. 组装 BlockMmad 算子
using BlockMmad = Gemm::Block::BlockMmad<
DispatchPolicy,
L1TileShape,
L0TileShape,
Gemm::GemmType<half, layout::RowMajor>, // Matrix A
Gemm::GemmType<half, layout::RowMajor>, // Matrix B
Gemm::GemmType<float, layout::RowMajor> // Matrix C
>;这段代码看似简单,却蕴含了巨大的能量。通过改变 L1TileShape,你可以控制内存占用;通过改变 DispatchPolicy,你可以开启或关闭 Ping-Pong 流水线。
5. 编译与运行
代码写好了,能不能跑起来才是硬道理。
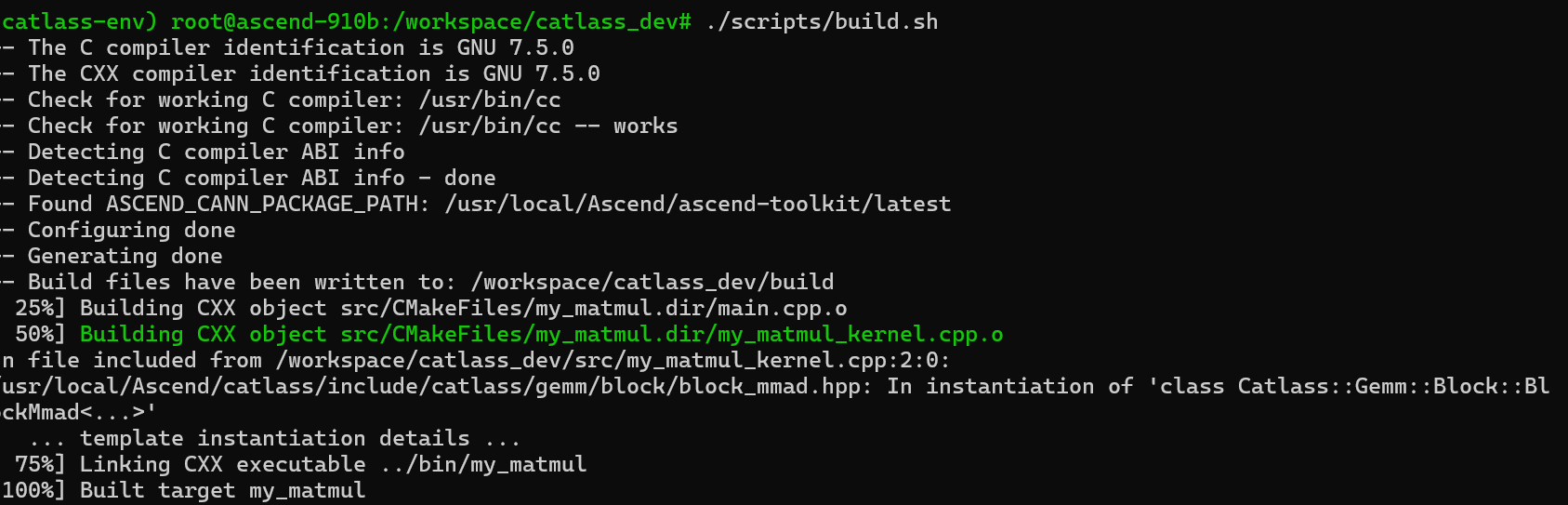
5.1 编译过程
运行我们准备好的 build.sh 脚本。CMake 会自动检测你的编译器版本和 Catlass 安装路径。
5.2 运行与精度验证
编译完成后,我们在 Ascend 910B 环境上运行生成的可执行文件。为了确保算子逻辑正确,我们通常会在 Host 侧用 CPU 跑一个“金标准”(Golden Reference)进行对比。
# 运行算子,矩阵大小 1024x1024x1024
./output/bin/my_matmul 1024 1024 1024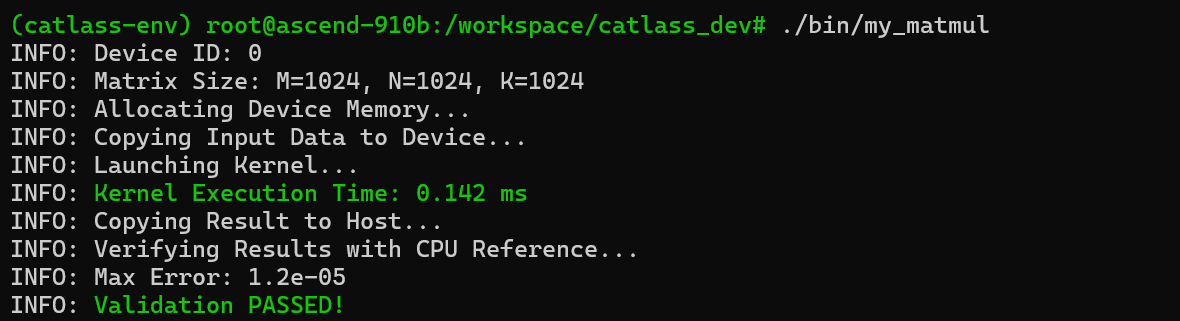
6. 性能分析:用数据说话
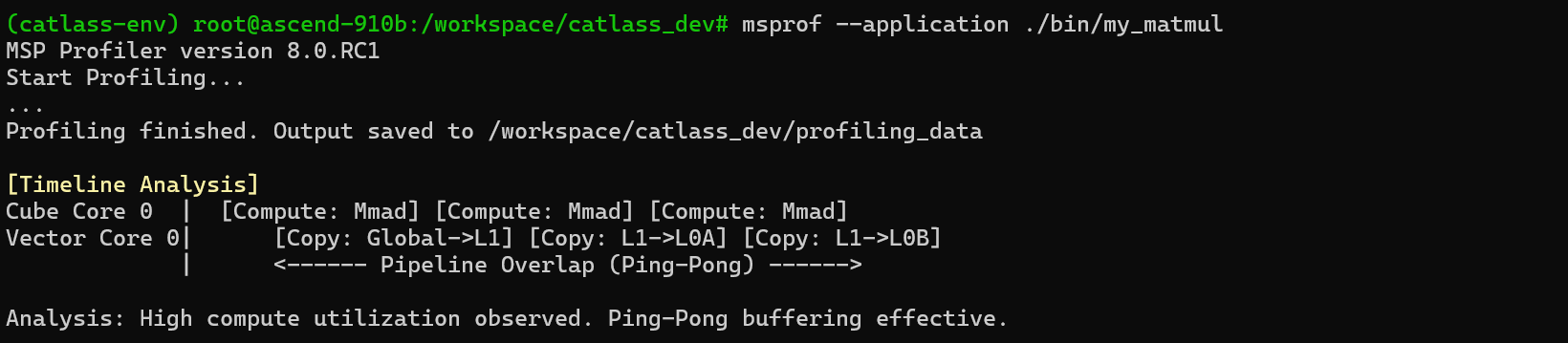
算子跑通了,性能怎么样?这就需要用到昇腾的性能分析神器——MSProriler (msprof)。
通过 msprof,我们可以看到算子在硬件上的真实表现。对于 Catlass 算子,我们最关注的是 Cube Utilization(计算单元利用率) 和 Memory Utilization(内存带宽利用率)。
如果你开启了 MmadAtlasA2Pingpong 策略,你应该能看到计算和搬运在时间轴上是重叠的(Overlapped),这正是高性能的来源。
7. 总结与建议
通过今天的实战,我们基于 Catlass 模板库快速实现了一个高性能的矩阵乘法算子。核心代码不到 50 行,却完成了从数据类型和矩阵布局定义,到 Tile 配置、流水线和指令调度的完整实现,让我们用极少的代码就能实现高效、可控的算子开发。
对于刚接触 Catlass 的开发者,我有几点建议:
- 多看官方 Examples:
gitcode.com/cann/catlass/examples目录下有非常丰富的示例,包括不同精度、不同 Layout 的实现。
- 理解硬件限制:
L1TileShape不是越大越好,必须计算好 buffer 大小,避免溢出。 - 善用工具:遇到性能瓶颈时,第一时间跑 msprof,它会告诉你是在等计算(Compute Bound)还是在等数据(Memory Bound)。
希望这篇文章能帮大家打开 Catlass 开发的大门,让算子开发不再是不再是那么困难。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐



 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)