
华为昇腾 AI 全栈解决方案:从芯片到应用的技术实践
华为昇腾系列 AI 处理器通过"芯片-框架-平台-应用"四层全栈方案,构建了从底层硬件到上层行业应用的完整技术生态。随着昇腾910B、昇腾310B等新一代芯片的发布,以及 MindSpore 框架的持续迭代,昇腾平台正成为企业级 AI 应用开发的首选。昇腾芯片采用达芬奇(Da Vinci)架构,其创新的3D Cube 计算单元可提供高达 2048 TOPS 的 AI 算力,支持混合精度计算。随着
引言
在人工智能算力需求爆发式增长的今天,异构计算架构已成为突破性能瓶颈的关键。华为昇腾系列 AI 处理器通过"芯片-框架-平台-应用"四层全栈方案,构建了从底层硬件到上层行业应用的完整技术生态。本文将深入解析昇腾架构的核心特性,并通过代码示例展示如何基于昇腾平台快速开发 AI 应用。
一、昇腾计算架构核心特性
1.1 达芬奇架构解析
昇腾芯片采用达芬奇(Da Vinci)架构,其创新的3D Cube 计算单元可提供高达 2048 TOPS 的 AI 算力,支持混合精度计算。该架构通过以下技术实现性能突破:
- 张量并行:支持 16×16×16 张量运算
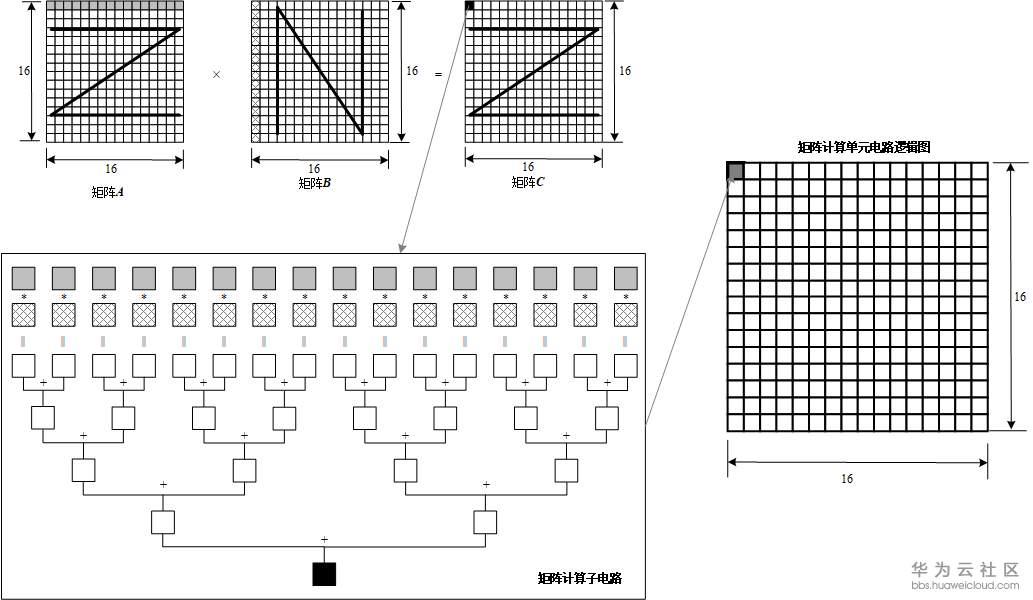
- 灵活精度:同时支持 FP32/FP16/INT8 计算

- 片上智能缓存:多级缓存降低数据访问延迟
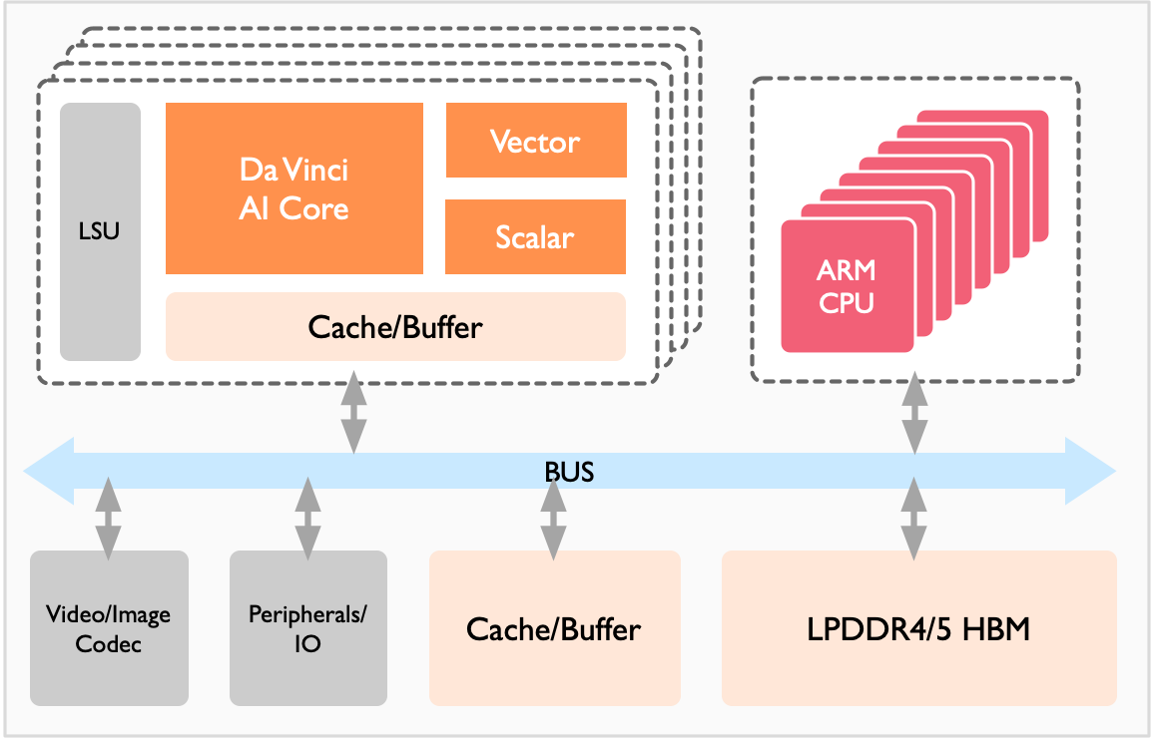
1.2 全栈软件生态
昇腾软件栈提供三层核心组件
graph TD
A[应用层] --> B[框架层]
B --> C[异构计算架构]
C --> D[硬件层]
- 昇腾 AI 框架(MindSpore):全场景统一框架,支持动态图/静态图混合编程
- 异构计算架构(CANN):提供设备管理、任务调度和算子优化能力
- 驱动与固件:深度优化的底层软件栈,支持多芯片协同
二、昇腾平台开发实战
2.1 环境搭建
bash
# 安装昇腾驱动
sudo dpkg -i ascend-driver_22.0.0_amd64.deb
# 配置 CANN 环境
source /usr/local/Ascend/ascend-toolkit/set_env.sh
# 验证安装
npu-smi info
2.2 基于 MindSpore 的图像分类示例
python
import mindspore as ms
from mindspore import nn, ops
from mindspore.dataset import MnistDataset
# 定义 LeNet-5 网络
class LeNet5(nn.Cell):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 6, 5, pad_mode='valid')
self.conv2 = nn.Conv2d(6, 16, 5, pad_mode='valid')
self.fc1 = nn.Dense(16*4*4, 120)
self.fc2 = nn.Dense(120, 84)
self.fc3 = nn.Dense(84, 10)
self.relu = nn.ReLU()
self.max_pool2d = nn.MaxPool2d(kernel_size=2, stride=2)
def construct(self, x):
x = self.max_pool2d(self.relu(self.conv1(x)))
x = self.max_pool2d(self.relu(self.conv2(x)))
x = x.view(-1, 16*4*4)
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
x = self.fc3(x)
return x
# 训练配置
device = ms.get_context('device_target')
print(f"Using device: {device}")
# 加载数据集
dataset = MnistDataset('MNIST', download=True)
dataset = dataset.map(operations=[ms.dataset.vision.Resize((32,32)),
ms.dataset.vision.Normalize(0.1307, 0.3081),
ms.dataset.vision.ToTensor()])
# 模型训练
model = LeNet5()
loss_fn = nn.SoftmaxCrossEntropyWithLogits(sparse=True)
optimizer = nn.Adam(model.trainable_params(), learning_rate=0.001)
model.train()
for epoch in range(5):
for data in dataset.create_tuple_iterator():
x, y = data
loss = loss_fn(model(x), y)
loss.backward()
optimizer.step()
optimizer.clear_grad()
print(f"Epoch {epoch+1}, Loss: {loss.asnumpy():.4f}")
2.3 CANN 算子开发示例
c
#include <stdio.h>
#include "acl/acl.h"
// 自定义加法算子
__global__ void AddKernel(float *a, float *b, float *c, int size) {
int tid = threadIdx.x + blockIdx.x * blockDim.x;
if (tid < size) {
c[tid] = a[tid] + b[tid];
}
}
int main() {
// 初始化昇腾环境
aclInit(nullptr);
aclrtContext context;
aclrtCreateContext(&context, 0);
// 分配设备内存
const int size = 1024;
float *dev_a, *dev_b, *dev_c;
aclrtMalloc((void**)&dev_a, size*sizeof(float), ACL_MEM_MALLOC_HUGE_FIRST);
aclrtMalloc((void**)&dev_b, size*sizeof(float), ACL_MEM_MALLOC_HUGE_FIRST);
aclrtMalloc((void**)&dev_c, size*sizeof(float), ACL_MEM_MALLOC_HUGE_FIRST);
// 数据初始化
float *host_a = new float[size];
float *host_b = new float[size];
float *host_c = new float[size];
for (int i = 0; i < size; i++) {
host_a[i] = i;
host_b[i] = i * 2;
}
// 数据拷贝到设备
aclrtMemcpy(dev_a, size*sizeof(float), host_a, size*sizeof(float),
ACL_MEMCPY_HOST_TO_DEVICE);
aclrtMemcpy(dev_b, size*sizeof(float), host_b, size*sizeof(float),
ACL_MEMCPY_HOST_TO_DEVICE);
// 执行核函数
dim3 block(256);
dim3 grid((size + block.x - 1) / block.x);
AddKernel<<<grid, block>>>(dev_a, dev_b, dev_c, size);
// 结果拷贝回主机
aclrtMemcpy(host_c, size*sizeof(float), dev_c, size*sizeof(float),
ACL_MEMCPY_DEVICE_TO_HOST);
// 验证结果
for (int i = 0; i < 10; i++) {
printf("%f + %f = %f\n", host_a[i], host_b[i], host_c[i]);
}
// 资源释放
delete[] host_a;
delete[] host_b;
delete[] host_c;
aclrtFree(dev_a);
aclrtFree(dev_b);
aclrtFree(dev_c);
aclrtDestroyContext(context);
aclFinalize();
return 0;
}
三、行业应用场景
3.1 智慧城市
昇腾平台支持亿级像素视频实时分析,在智慧城市领域实现:
- 交通流量实时监测
- 异常行为智能识别
- 公共安全事件预警

3.2 医疗影像
基于昇腾芯片的医学影像分析系统可实现:
- 肺结节检测准确率 > 95%
- 眼底图像分析速度提升 10 倍
- 多模态数据融合诊断
3.3 工业质检
在智能制造场景中,昇腾方案实现:
- 产品缺陷检测精度达 99.9%
- 检测效率提升 50 倍
- 支持 24/7 不间断工作

四、性能优化实践
4.1 模型优化技巧
1. 量化策略
python
from mindspore import quant
# 对模型进行INT8量化
quantizer = quant.create_quant_config()
quant_model = quant.quantize_model(model, quantizer)
2. 算子融合
python
# 开启算子融合优化
ms.set_context(opt_level="O2")
4.2 多卡并行训练
python
# 配置分布式训练
from mindspore.communication import init
init()
model = LeNet5()
model = nn.DistributedDataParallel(model)
结尾
华为昇腾 AI 全栈解决方案通过硬件创新与软件生态的深度协同,为开发者提供了从底层芯片到上层应用的完整技术支撑。随着昇腾910B、昇腾310B等新一代芯片的发布,以及 MindSpore 框架的持续迭代,昇腾平台正成为企业级 AI 应用开发的首选。
随着 AI 计算需求的不断演进,昇腾平台将持续推动人工智能技术在各行业的深度应用,助力企业实现智能化转型。
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐
 35
35 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)