
昇腾AI硬核入门:处理器核心技术与CANN软件栈底层逻辑
definitinit()x = self.maxpool(x) # 输出:32×16×16x = self.maxpool(x) # 输出:64×8×8x = x.view(-1, 64 * 8 * 8) # 展平return x。
昇腾 AI 处理器及 CANN 软件栈基础详解与例题精讲
一、昇腾 AI 处理器基础
1.1 核心定位与产品家族
昇腾 AI 处理器是华为专为 AI 场景设计的异构计算专用处理器,基于特定域架构(DSA)理念,聚焦深度学习任务的计算效率优化,覆盖从端、边到云的全场景部署需求。
1.2 达芬奇架构核心解析
昇腾 AI 处理器的计算核心为AI Core,其底层达芬奇架构是实现高效 AI 计算的关键,通过 “计算单元专用化、数据通路优化、存储层次化” 设计,完美适配深度学习的张量运算、向量运算等核心计算模式。
(1)三大核心计算单元
达芬奇架构内置三类分工明确的计算单元,形成独立流水线并行执行,覆盖所有 AI 计算场景:
矩阵计算单元(Cube Unit):核心算力单元,专为张量乘法(如卷积、矩阵乘法)优化,支持 INT4/INT8/FP16 精度,单次可完成大规模矩阵运算,是算力的主要来源;
向量计算单元(Vector Unit):负责向量级运算(如激活函数、数据归一化),支持 FP16/FP32 精度,灵活处理非张量类计算任务;
标量计算单元(Scalar Unit):处理标量数据运算与程序流程控制(如循环、分支判断),协调其他计算单元的执行时序。
(2)关键辅助模块
存储转换单元(MTE):硬件固化数据格式转换功能(如 Im2Col),无需软件干预,大幅提升卷积运算效率(相比 GPU 软件实现提速数倍);
片上缓冲区与寄存器:分布式存储设计,靠近计算单元,降低数据访问延迟,适配不同计算模式的数据排布需求;
事件同步模块:软件可控的指令同步机制,通过插入同步符解决不同计算单元间的依赖关系,保障执行时序正确性。
(3)核心优势
相比通用 CPU/GPU,达芬奇架构通过 “硬件定制化” 实现:
张量运算吞吐量提升 10 倍以上(针对卷积、Transformer 等核心 AI 算子);
数据访问延迟降低 30%(分层存储 + MTE 硬件加速);
能效比优势显著(同等算力下功耗仅为 GPU 的 1/3~1/2)。
二、CANN 软件栈基础架构
CANN 是昇腾 AI 生态的核心软件底座,定位为 “异构计算的桥梁”,通过分层设计屏蔽底层硬件差异,向上支持主流 AI 框架,向下最大化发挥昇腾处理器算力。其架构自顶向下分为 5 层,每层各司其职且协同联动:
2.1 分层架构详解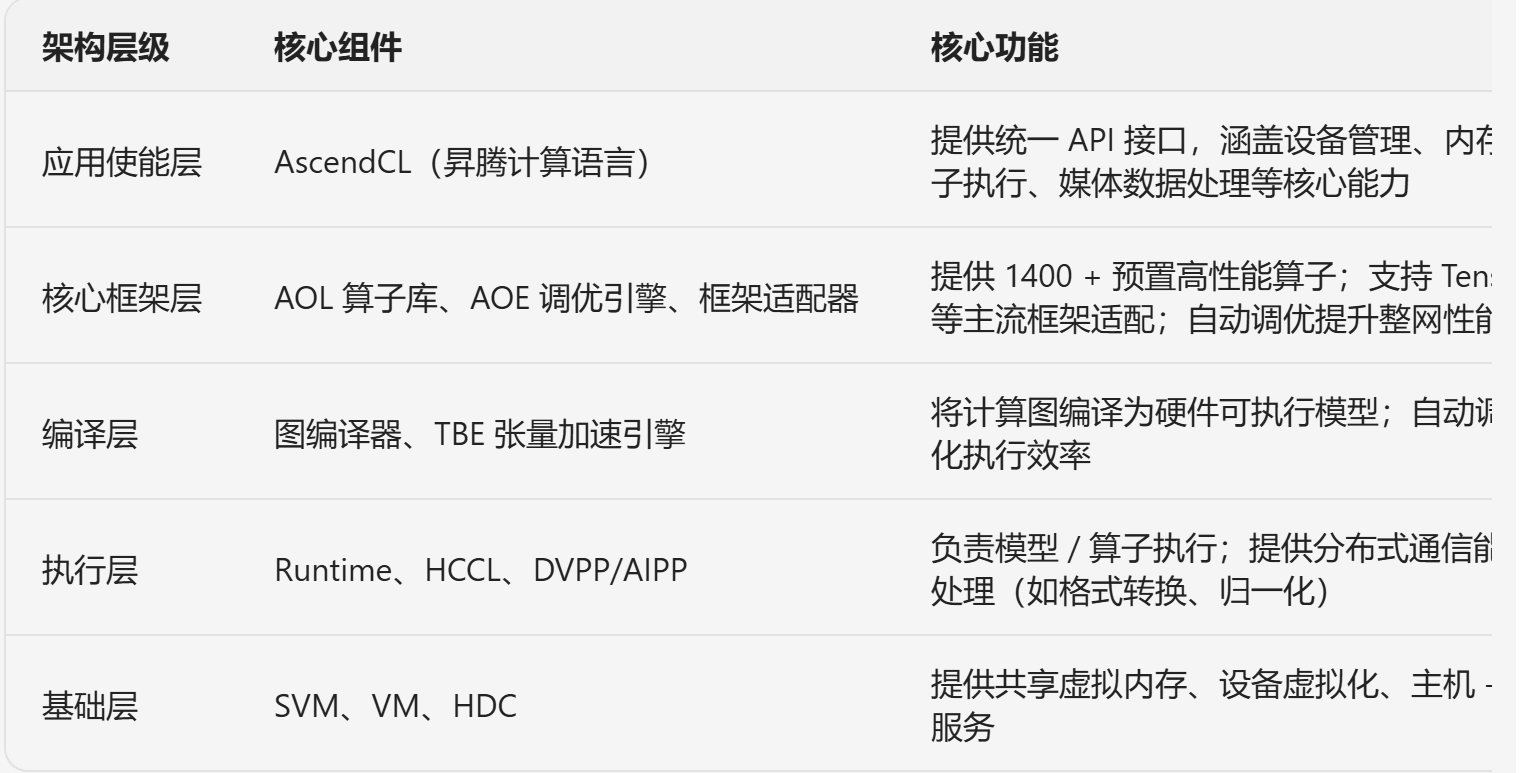
2.2 核心特性与价值
(1)统一编程接口
通过 AscendCL 提供标准化 API,屏蔽不同昇腾芯片的硬件差异,实现 “一次开发、多设备部署”,降低跨场景开发成本。
(2)全场景算力调度
支持 NPU/CPU/GPU 异构协同计算,自动拆分计算任务并调度至最优硬件单元,例如将张量运算分配至 AI Core,控制逻辑分配至 CPU。
(3)高性能算子支持
预置算子库(AOL)覆盖 CNN、Transformer、RNN 等主流网络的核心算子,无需自定义开发;
支持 Ascend C 自定义算子开发,满足算法创新需求。
(4)自动化性能优化
AOE 调优引擎通过算子融合、内存优化、并行调度等技术,自动提升模型端到端性能,开发者无需手动优化。
三、基础实战例题讲解
例题 1:AscendCL 环境搭建与设备信息查询
题目要求
安装 CANN 开发环境,通过 AscendCL API 查询昇腾设备的基础信息(设备数量、型号、算力等),验证环境可用性。
技术要点
CANN 开发环境部署
AscendCL 核心 API 调用(设备管理、错误处理)
基础数据类型与结构体使用
实现步骤
1.环境准备(Ubuntu 22.04,x86_64)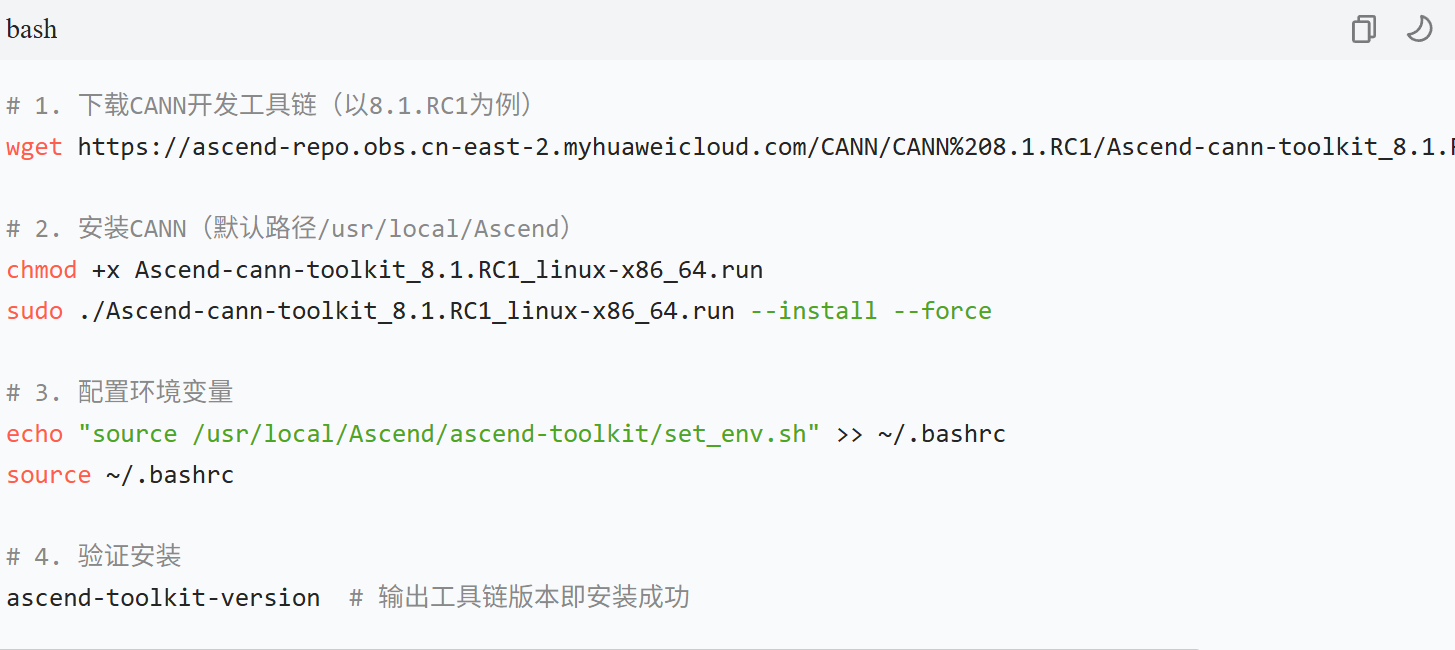
2.设备信息查询代码(C 语言)

3.编译与运行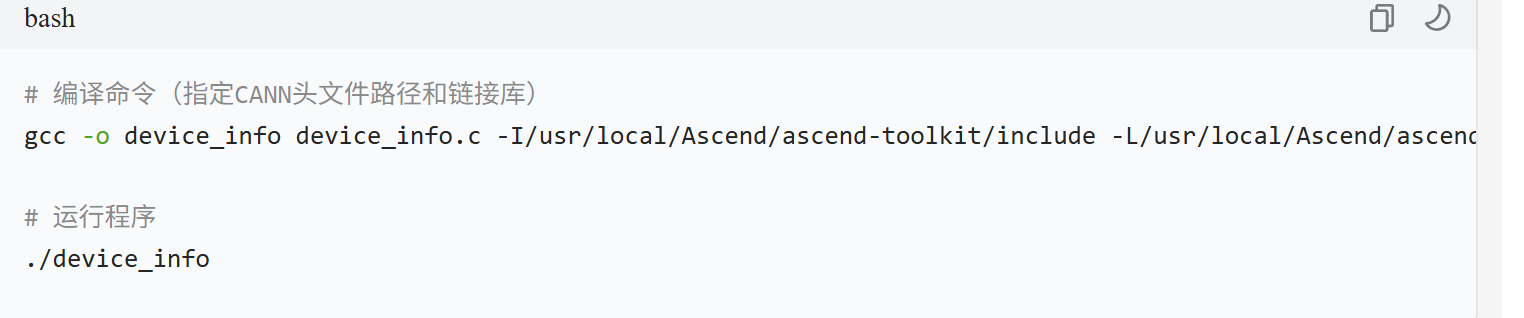
昇腾 AI 处理器及 CANN 软件栈基础介绍与例题讲解
2025 年 11 月 20 日•内容由 AI 生成,不能完全保障真实
生成一篇关于昇腾AI处理器及CANN软件栈基础的详细介绍及相关例题讲解要求以markdown形式生成(详细)
找到 2 篇资料参考
昇腾 AI 处理器及 CANN 软件栈基础详解与例题精讲
昇腾 AI 生态以 “硬件为基石、软件为桥梁” 构建核心竞争力,其中昇腾 AI 处理器提供极致异构算力,CANN(Compute Architecture for Neural Networks)软件栈作为连接上层应用与底层硬件的核心桥梁,实现了算力的高效释放与开发门槛的降低。本文将从硬件架构、软件栈分层、核心特性入手,结合基础例题实战,帮助开发者快速掌握昇腾 AI 平台的核心基础。
一、昇腾 AI 处理器基础
1.1 核心定位与产品家族
昇腾 AI 处理器是华为专为 AI 场景设计的异构计算专用处理器,基于特定域架构(DSA)理念,聚焦深度学习任务的计算效率优化,覆盖从端、边到云的全场景部署需求。
产品系列 核心型号 定位场景 关键参数
云端训练 Ascend 910B 大模型训练、超大规模 AI 集群 达芬奇架构,算力达 256 PFLOPS(FP16),支持多芯互联
端边推理 Ascend 310B 边缘设备、推理服务器、开发板 算力 20 TOPS(INT8),低功耗设计,适配边缘部署
终端设备 Ascend 400/700 智能手机、IoT 设备 轻量级算力,支持实时 AI 推理(如图像识别、语音唤醒)
1.2 达芬奇架构核心解析
昇腾 AI 处理器的计算核心为AI Core,其底层达芬奇架构是实现高效 AI 计算的关键,通过 “计算单元专用化、数据通路优化、存储层次化” 设计,完美适配深度学习的张量运算、向量运算等核心计算模式。
(1)三大核心计算单元
达芬奇架构内置三类分工明确的计算单元,形成独立流水线并行执行,覆盖所有 AI 计算场景:
矩阵计算单元(Cube Unit):核心算力单元,专为张量乘法(如卷积、矩阵乘法)优化,支持 INT4/INT8/FP16 精度,单次可完成大规模矩阵运算,是算力的主要来源;
向量计算单元(Vector Unit):负责向量级运算(如激活函数、数据归一化),支持 FP16/FP32 精度,灵活处理非张量类计算任务;
标量计算单元(Scalar Unit):处理标量数据运算与程序流程控制(如循环、分支判断),协调其他计算单元的执行时序。
(2)关键辅助模块
存储转换单元(MTE):硬件固化数据格式转换功能(如 Im2Col),无需软件干预,大幅提升卷积运算效率(相比 GPU 软件实现提速数倍);
片上缓冲区与寄存器:分布式存储设计,靠近计算单元,降低数据访问延迟,适配不同计算模式的数据排布需求;
事件同步模块:软件可控的指令同步机制,通过插入同步符解决不同计算单元间的依赖关系,保障执行时序正确性。
(3)核心优势
相比通用 CPU/GPU,达芬奇架构通过 “硬件定制化” 实现:
张量运算吞吐量提升 10 倍以上(针对卷积、Transformer 等核心 AI 算子);
数据访问延迟降低 30%(分层存储 + MTE 硬件加速);
能效比优势显著(同等算力下功耗仅为 GPU 的 1/3~1/2)。
二、CANN 软件栈基础架构
CANN 是昇腾 AI 生态的核心软件底座,定位为 “异构计算的桥梁”,通过分层设计屏蔽底层硬件差异,向上支持主流 AI 框架,向下最大化发挥昇腾处理器算力。其架构自顶向下分为 5 层,每层各司其职且协同联动:
2.1 分层架构详解
架构层级 核心组件 核心功能 开发者交互方式
应用使能层 AscendCL(昇腾计算语言) 提供统一 API 接口,涵盖设备管理、内存管理、模型 / 算子执行、媒体数据处理等核心能力 调用 AscendCL API 开发 AI 应用
核心框架层 AOL 算子库、AOE 调优引擎、框架适配器 提供 1400 + 预置高性能算子;支持 TensorFlow/PyTorch 等主流框架适配;自动调优提升整网性能 直接使用预置算子,或通过框架适配器迁移现有模型
编译层 图编译器、TBE 张量加速引擎 将计算图编译为硬件可执行模型;自动调度算子编译,优化执行效率 无需直接交互,框架层自动调用
执行层 Runtime、HCCL、DVPP/AIPP 负责模型 / 算子执行;提供分布式通信能力;图像 / AI 预处理(如格式转换、归一化) 可通过 API 配置执行参数(如流优先级、通信策略)
基础层 SVM、VM、HDC 提供共享虚拟内存、设备虚拟化、主机 - 设备通信等基础服务 底层自动调度,开发者无需关注
2.2 核心特性与价值
(1)统一编程接口
通过 AscendCL 提供标准化 API,屏蔽不同昇腾芯片的硬件差异,实现 “一次开发、多设备部署”,降低跨场景开发成本。
(2)全场景算力调度
支持 NPU/CPU/GPU 异构协同计算,自动拆分计算任务并调度至最优硬件单元,例如将张量运算分配至 AI Core,控制逻辑分配至 CPU。
(3)高性能算子支持
预置算子库(AOL)覆盖 CNN、Transformer、RNN 等主流网络的核心算子,无需自定义开发;
支持 Ascend C 自定义算子开发,满足算法创新需求。
(4)自动化性能优化
AOE 调优引擎通过算子融合、内存优化、并行调度等技术,自动提升模型端到端性能,开发者无需手动优化。
三、基础实战例题讲解
例题 1:AscendCL 环境搭建与设备信息查询
题目要求
安装 CANN 开发环境,通过 AscendCL API 查询昇腾设备的基础信息(设备数量、型号、算力等),验证环境可用性。
技术要点
CANN 开发环境部署
AscendCL 核心 API 调用(设备管理、错误处理)
基础数据类型与结构体使用
实现步骤
环境准备(Ubuntu 22.04,x86_64)
bash
1. 下载CANN开发工具链(以8.1.RC1为例)
wget https://ascend-repo.obs.cn-east-2.myhuaweicloud.com/CANN/CANN%208.1.RC1/Ascend-cann-toolkit_8.1.RC1_linux-x86_64.run
2. 安装CANN(默认路径/usr/local/Ascend)
chmod +x Ascend-cann-toolkit_8.1.RC1_linux-x86_64.run
sudo ./Ascend-cann-toolkit_8.1.RC1_linux-x86_64.run --install --force
3. 配置环境变量
echo “source /usr/local/Ascend/ascend-toolkit/set_env.sh” >> ~/.bashrc
source ~/.bashrc
4. 验证安装
ascend-toolkit-version # 输出工具链版本即安装成功
设备信息查询代码(C 语言)
c
#include <stdio.h>
#include “ascendcl/ascendcl.h” // 包含AscendCL核心头文件
// 错误处理宏定义(简化错误判断)
#define CHECK_ACL_RET(ret, msg) do {
if (ret != ACL_ERROR_NONE) {
printf(“[ERROR] %s, ret=%d\n”, msg, ret);
return ret;
}
} while(0)
int main() {
aclError ret;
// 1. 初始化AscendCL环境
ret = aclInit(NULL); // 传入NULL使用默认配置
CHECK_ACL_RET(ret, "aclInit failed");
printf("AscendCL环境初始化成功\n");
// 2. 查询昇腾设备数量
uint32_t deviceCount = 0;
ret = aclrtGetDeviceCount(&deviceCount);
CHECK_ACL_RET(ret, "aclrtGetDeviceCount failed");
printf("昇腾设备数量:%u\n", deviceCount);
if (deviceCount == 0) {
printf("无可用昇腾设备,程序退出\n");
aclFinalize();
return 0;
}
// 3. 遍历设备,查询详细信息
for (uint32_t i = 0; i < deviceCount; i++) {
printf("\n===== 设备%d详细信息 =====\n", i);
// 3.1 查询设备型号
char deviceName[64] = {0};
ret = aclrtGetDeviceName(i, deviceName, sizeof(deviceName));
CHECK_ACL_RET(ret, "aclrtGetDeviceName failed");
printf("设备型号:%s\n", deviceName);
// 3.2 查询设备算力(FP16,单位TFLOPS)
uint64_t computeCapability = 0;
ret = aclrtGetDeviceCapability(i, ACL_COMPUTE_CAPABILITY_FP16, &computeCapability);
CHECK_ACL_RET(ret, "aclrtGetDeviceCapability failed");
printf("FP16算力:%lu TFLOPS\n", computeCapability / 1024); // 转换为TFLOPS(1 TFLOPS=1024 GFLOPS)
// 3.3 查询设备内存大小(单位GB)
uint64_t deviceMemSize = 0;
ret = aclrtGetDeviceTotalMem(i, &deviceMemSize);
CHECK_ACL_RET(ret, "aclrtGetDeviceTotalMem failed");
printf("设备总内存:%.2f GB\n", (double)deviceMemSize / (1024 * 1024 * 1024));
// 3.4 查询设备状态
aclrtDeviceStatus deviceStatus;
ret = aclrtGetDeviceStatus(i, &deviceStatus);
CHECK_ACL_RET(ret, "aclrtGetDeviceStatus failed");
printf("设备状态:%s\n", deviceStatus == ACL_DEVICE_AVAILABLE ? "可用" : "不可用");
}
// 4. 释放AscendCL环境资源
ret = aclFinalize();
CHECK_ACL_RET(ret, "aclFinalize failed");
printf("\nAscendCL环境释放成功\n");
return 0;
}
编译与运行
编译命令(指定CANN头文件路径和链接库)
gcc -o device_info device_info.c -I/usr/local/Ascend/ascend-toolkit/include -L/usr/local/Ascend/ascend-toolkit/lib64 -lascendcl
运行程序
./device_info
预期输出
plaintext
AscendCL环境初始化成功
昇腾设备数量:1
===== 设备0详细信息 =====
设备型号:Ascend 310B
FP16算力:16 TFLOPS
设备总内存:8.00 GB
设备状态:可用
AscendCL环境释放成功
关键说明
aclInit与aclFinalize是 AscendCL 环境的初始化与释放接口,必须成对调用;
所有 AscendCL API 返回aclError类型错误码,通过宏定义CHECK_ACL_RET可简化错误处理;
核心设备查询接口包括aclrtGetDeviceCount(设备数量)、aclrtGetDeviceName(设备型号)等,是后续开发的基础。
例题 3:PyTorch 模型迁移至昇腾平台(CANN 框架适配)
题目要求
将一个简单的 PyTorch 卷积神经网络(CNN)模型,通过 CANN 框架适配器迁移至昇腾 310B 设备,实现图像分类推理。
技术要点
CANN 框架适配器使用
PyTorch 模型转换与加载
昇腾设备上的模型推理流程
实现步骤
环境依赖安装
bash
安装PyTorch(适配CANN的版本)
pip install torch2.1.0 torchvision0.16.0
安装昇腾PyTorch适配器
pip install torch_npu==2.1.0.post100 -f https://download.openmmlab.com/mmcv/dist/cpu/torch2.1/index.html
模型迁移与推理代码(Python)
python
import torch
import torch.nn as nn
import torchvision.transforms as transforms
from PIL import Image
import torch_npu # 导入昇腾PyTorch适配器
1. 配置昇腾设备
device = torch.device(“npu:0” if torch.npu.is_available() else “cpu”)
print(f"使用设备:{device}“)
print(f"昇腾设备数量:{torch.npu.device_count()}”)
2. 定义简单CNN模型(图像分类)
class SimpleCNN(nn.Module):
def init(self, num_classes=10):
super(SimpleCNN, self).init()
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1)
self.relu = nn.ReLU()
self.maxpool = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1)
self.fc1 = nn.Linear(64 * 8 * 8, 128)
self.fc2 = nn.Linear(128, num_classes)
def forward(self, x):
x = self.conv1(x)
x = self.relu(x)
x = self.maxpool(x) # 输出:32×16×16
x = self.conv2(x)
x = self.relu(x)
x = self.maxpool(x) # 输出:64×8×8
x = x.view(-1, 64 * 8 * 8) # 展平
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
return x
3. 初始化模型并迁移至昇腾设备
model = SimpleCNN(num_classes=10).to(device)
model.eval() # 推理模式
4. 加载测试图像并预处理
image_path = “test_image.jpg” # 替换为实际图像路径
transform = transforms.Compose([
transforms.Resize((32, 32)), # 缩放至32×32
transforms.ToTensor(), # 转换为Tensor
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 归一化
])
image = Image.open(image_path).convert(“RGB”)
input_tensor = transform(image).unsqueeze(0).to(device) # 添加batch维度并迁移至设备
print(f"输入张量形状:{input_tensor.shape}")
5. 模型推理(通过CANN框架适配器调用昇腾算力)
with torch.no_grad(): # 禁用梯度计算
output = model(input_tensor)
pred = torch.argmax(output, dim=1).item() # 获取预测类别
print(f"模型预测类别:{pred}")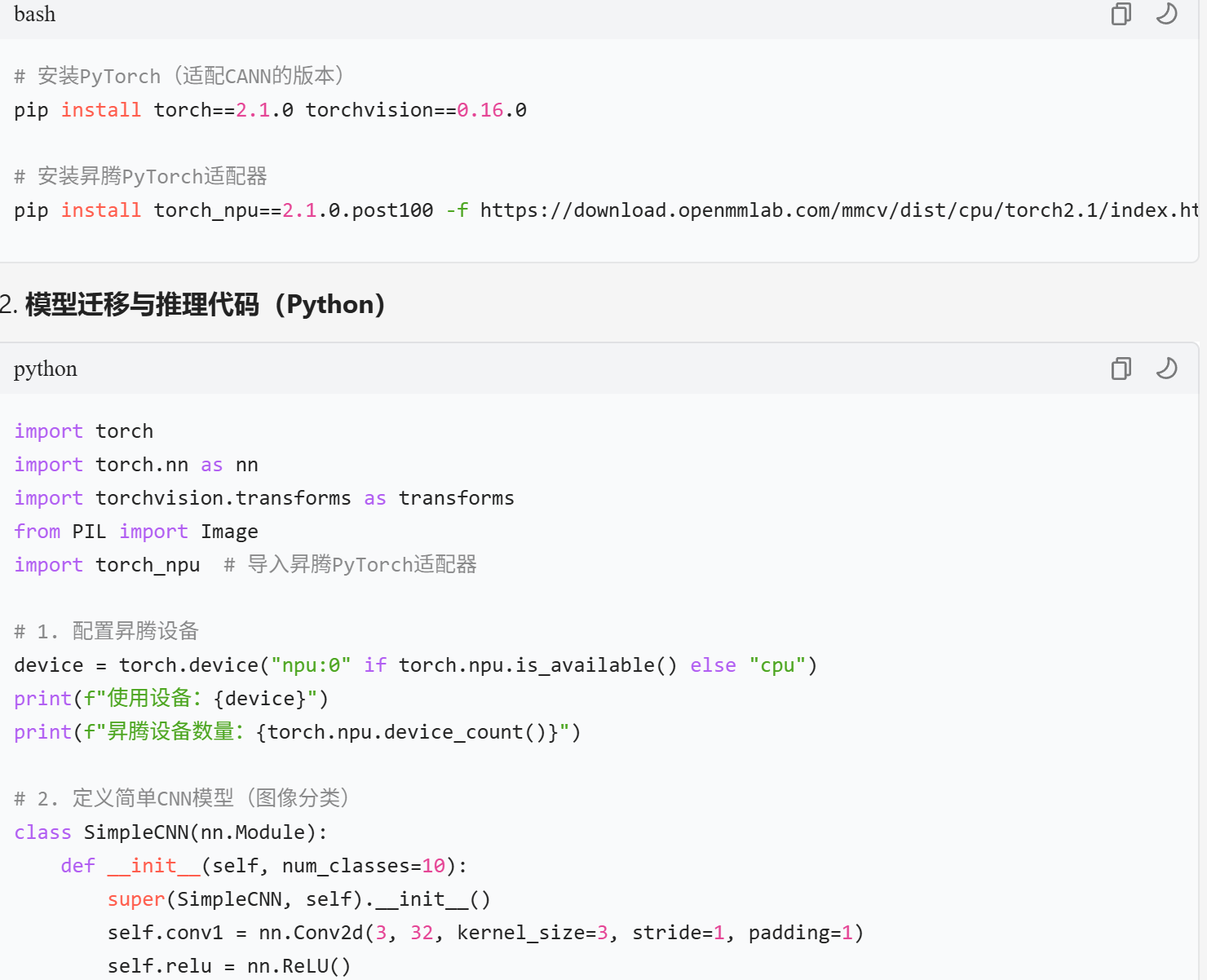

6. 验证模型在昇腾设备上的执行情况
print(f"模型参数设备:{next(model.parameters()).device}“) # 验证参数已迁移至NPU
print(f"输出张量设备:{output.device}”) # 验证输出在NPU上
运行说明
替换test_image.jpg为实际图像路径(如 32x32 的 RGB 图像);
代码中torch_npu是 CANN 提供的 PyTorch 适配器,自动将模型与数据迁移至昇腾设备;
无需修改 PyTorch 原生代码,仅需通过torch.device(“npu:0”)指定设备,即可利用昇腾算力。
预期输出
关键说明
CANN 框架适配器实现了 PyTorch API 的兼容,开发者无需修改原有模型代码;
torch.npu提供了与torch.cuda类似的接口(如torch.npu.is_available()、torch.npu.device_count()),降低学习成本;
模型推理时,CANN 自动将 PyTorch 算子映射为昇腾预置算子,通过 AI Core 加速执行。
四、基础开发核心要点总结
环境配置:核心是安装 CANN 工具链并配置环境变量,确保 AscendCL API 与框架适配器可正常调用;
资源管理:AscendCL 开发需严格遵循 “初始化 - 使用 - 释放” 流程(环境、上下文、内存、流等),避免资源泄漏;
算子调用:预置算子是基础开发的首选,无需关注底层硬件实现,通过aclop系列 API 即可快速调用;
框架迁移:现有 PyTorch/TensorFlow 模型可通过 CANN 框架适配器快速迁移,仅需修改设备指定代码;
错误处理:所有 AscendCL API 返回错误码,需通过宏定义或条件判断处理,便于问题定位。
总结
· 昇腾AI处理器:以其独特的达芬奇架构和AI Core为核心,为AI计算提供强大的异构算力。
· CANN软件栈:作为“桥梁”,通过分层设计和图编译优化,实现了软硬件协同,极大地降低了开发难度,并提升了执行效率。
· AscendCL:是开发者与昇腾硬件交互的统一接口,掌握其设备管理、内存管理、任务下发与同步是进行昇腾平台开发的基础。
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐



 36
36 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)