
算子开发的 “避坑指南”:深挖思维导图里的 “隐藏知识点”
昇腾算子开发的四大坑,本质都是 “算子设计与模型需求、硬件特性脱节”:数据类型不匹配是未对齐硬件计算单元特性,Shape 兼容性不足是未考虑实际场景需求,并行策略选错是未匹配算子规模,内存访问低效是未利用硬件内存层级。先明确算子的功能需求(输入输出类型、支持的 Shape 范围);再适配昇腾硬件特性(计算单元支持的类型、内存层级、并行能力);最后用 Ascend C 提供的工具(类型声明、Shap
算子开发避坑指南:揭秘思维导图中的关键细节 在算子开发过程中,新手常会陷入一些看似基础实则关键的陷阱——数据类型不匹配、动态输入适配失败、并行策略选择不当导致性能下降、内存访问效率低下等问题。虽然思维导图中仅简单提及这些要点,但它们背后涉及昇腾硬件架构、Ascend C语法特性和分布式计算逻辑等核心知识。本文将通过实战案例,深入剖析四大常见问题的根源,并提供可直接实施的解决方案与代码示例。
一、数据类型不匹配:编译通过但运行时崩溃 问题本质:硬件适配与类型验证缺失 思维导图中强调"算子的输入输出数据类型"并非冗余提示。昇腾NPU对数据类型有严格要求:不同计算单元(TCU/VCU/SCU)支持的数据类型各异(如TCU最适合FP16计算,SCU更擅长处理FP32),且算子间的数据流转必须保持类型严格匹配。
以LeNet-5为例:Conv2D算子利用TCU进行密集计算,采用FP16既能充分发挥硬件性能,又能节省内存;而全连接层后续可能连接分类器,需要更高精度的FP32来保留计算结果。若忽视这种差异——例如直接将FP16输出的Conv2D结果传递给期望FP32输入的MatMul算子,将引发"数据类型转换失败"的运行时错误;更隐蔽的是,若强制进行类型转换(如FP32转INT8未做量化校准),可能导致模型准确率骤降。
解决方案:明确声明+编译检查+类型适配
-
核心方法 使用Ascend C的__attribute__((precision("xxx")))关键字显式指定算子数据类型,编译器会自动验证输入输出类型一致性,提前拦截错误;同时根据硬件计算单元特性合理选择数据类型。
-
代码示例:数据类型指定与多场景适配
运行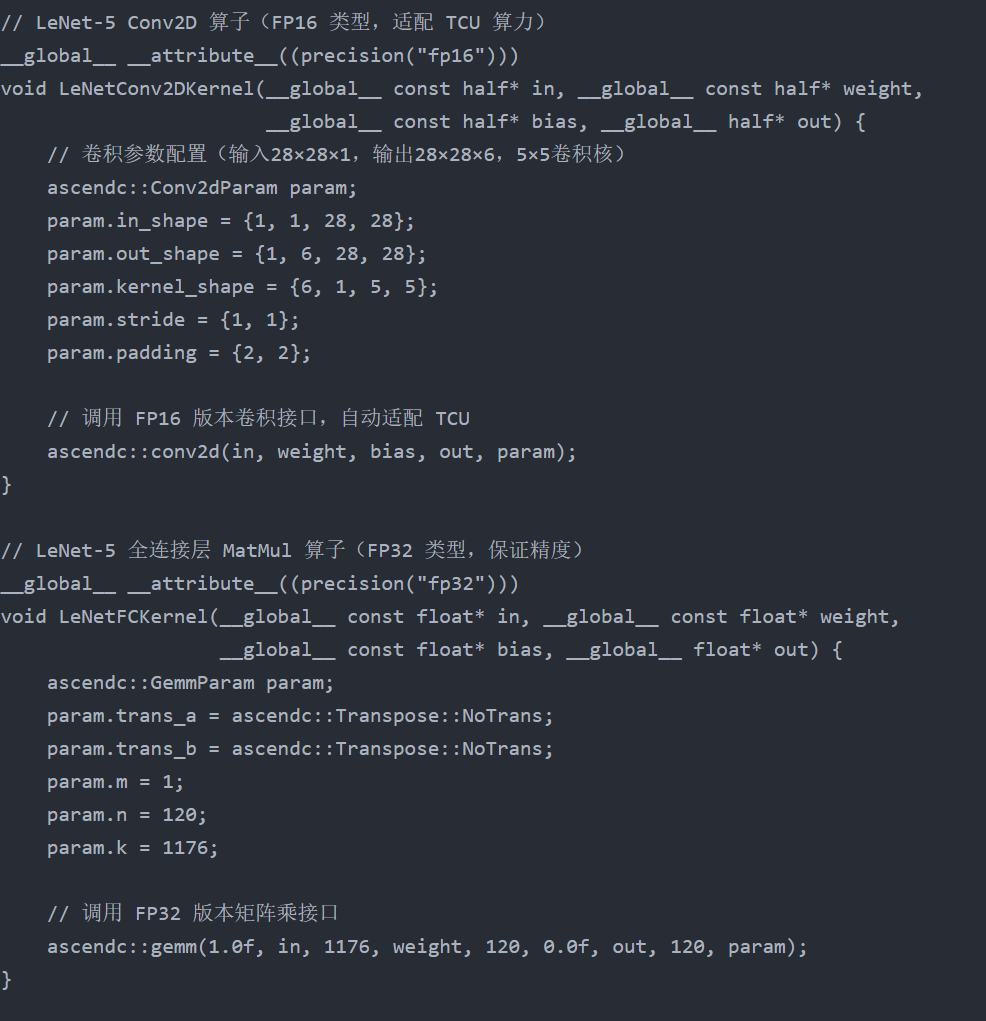
3. 额外提醒
- 常用数据类型选型:卷积、矩阵乘等计算密集型算子用 FP16/INT8(需量化校准),求和、归一化等对精度敏感的算子用 FP32;
- 避免隐式类型转换:若必须转换,用 Ascend C 内置
ascendc::cast函数,比 C++ 原生转换更适配硬件; - 编译时校验:在 CMakeLists 中添加
-Werror=type-mismatch选项,将类型不匹配警告转为错误,强制提前修正。
二、坑 2:算子的 “Shape 兼容性不足”—— 静态适配,动态场景直接失效
坑点本质:未考虑实际场景的输入多样性
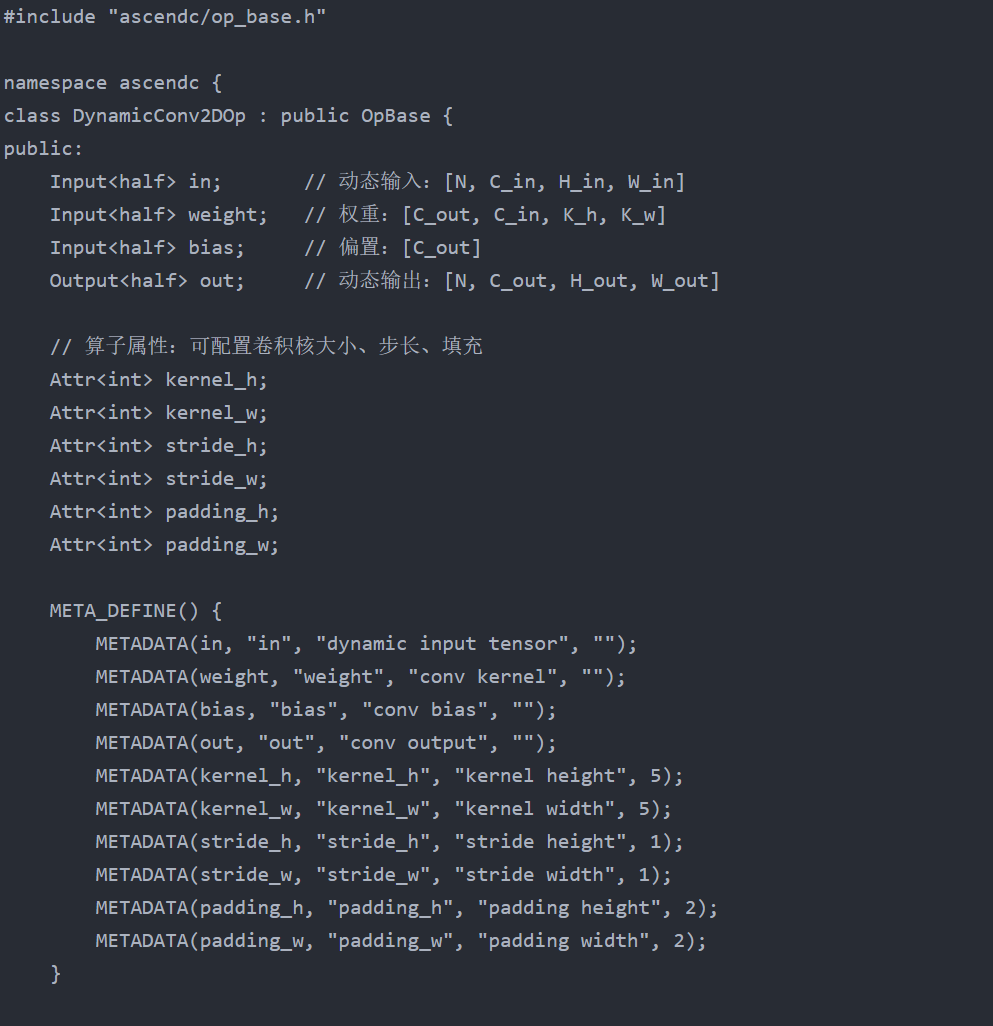
思维导图中的 “动态 Shape 适配” 是新手高频踩坑点。LeNet-5 理论输入是 28×28 的 MNIST 图像,但实际部署时可能遇到不同尺寸的输入(如用户上传的 32×32 手写数字图),或动态 batch size(训练时 batch=64,推理时 batch=1)。若算子硬编码输入输出 Shape(如固定 in_shape = {1, 1, 28, 28}),会直接报 “Shape 不匹配” 错误;更隐蔽的是,若手动计算输出 Shape 时忽略步长、填充等参数,会导致特征图维度错乱,模型推理结果全错。
避坑指南:Shape 自动推断 + 动态维度适配
1. 核心解决方法
利用 Ascend C 的 ShapeInfer 接口和动态维度计算,让算子根据输入 Shape 自动推断输出 Shape,无需硬编码,适配所有合法输入尺寸。
2. 代码示例:动态 Shape 适配的 Conv2D 算子
c
运行
3. 额外提醒
- 关键公式:卷积输出维度计算需严格遵循
H_out = floor((H_in + 2*padding_h - kernel_h) / stride_h) + 1,避免因整数除法精度问题导致维度错误; - 边界校验:在
InferShape中添加合法性检查(如H_out > 0),若输入尺寸过小导致输出维度为负,提前抛出明确错误; - 动态 batch 适配:核函数中避免使用固定 batch 相关的索引计算,用
blockIdx和threadIdx动态定位数据。
三、坑 3:算子的 “并行策略选错”—— 不是所有算子都适合分布式
坑点本质:并行策略与算子规模、硬件架构不匹配
并行计算是提升算子性能的核心,但 “选错策略” 不如 “不并行”。LeNet-5 的全连接层输入是 1176 维向量,权重是 1176×120 矩阵,属于 “计算密集、通信量小” 的算子,用 “数据并行” 拆分 batch 后,多卡可独立计算,效率极高;但如果选错为 “模型并行”(拆分权重矩阵),会导致多卡间频繁通信(每个卡需获取其他卡的权重分片),通信开销远超计算收益,性能反而下降 50% 以上。
更深层的问题是:新手容易混淆 “核内并行”“数据并行”“模型并行” 的适用场景 —— 核内并行针对单卡内的算子计算,数据并行针对多卡间的 batch 拆分,模型并行仅适用于超大规模算子(如千亿参数矩阵乘)。
避坑指南:按算子规模选并行策略
1. 并行策略选型表
| 并行类型 | 适用场景 | 核心工具 / 接口 | 示例算子 |
|---|---|---|---|
| 核内并行 | 单卡内、计算量中等的算子 | Ascend C __parallel_for |
ReLU、MaxPool2D、小尺寸 Conv2D |
| 分布式数据并行 | 多卡、计算密集且通信量小的算子 | PyTorch DDP/Ascend 分布式接口 | 全连接层 MatMul、大尺寸 Conv2D |
| 模型并行 | 多卡、超大规模算子(单卡存不下权重) | 自定义权重拆分逻辑 | 千亿参数 Transformer 注意力层 |
2. 代码示例:不同并行策略的实现
运行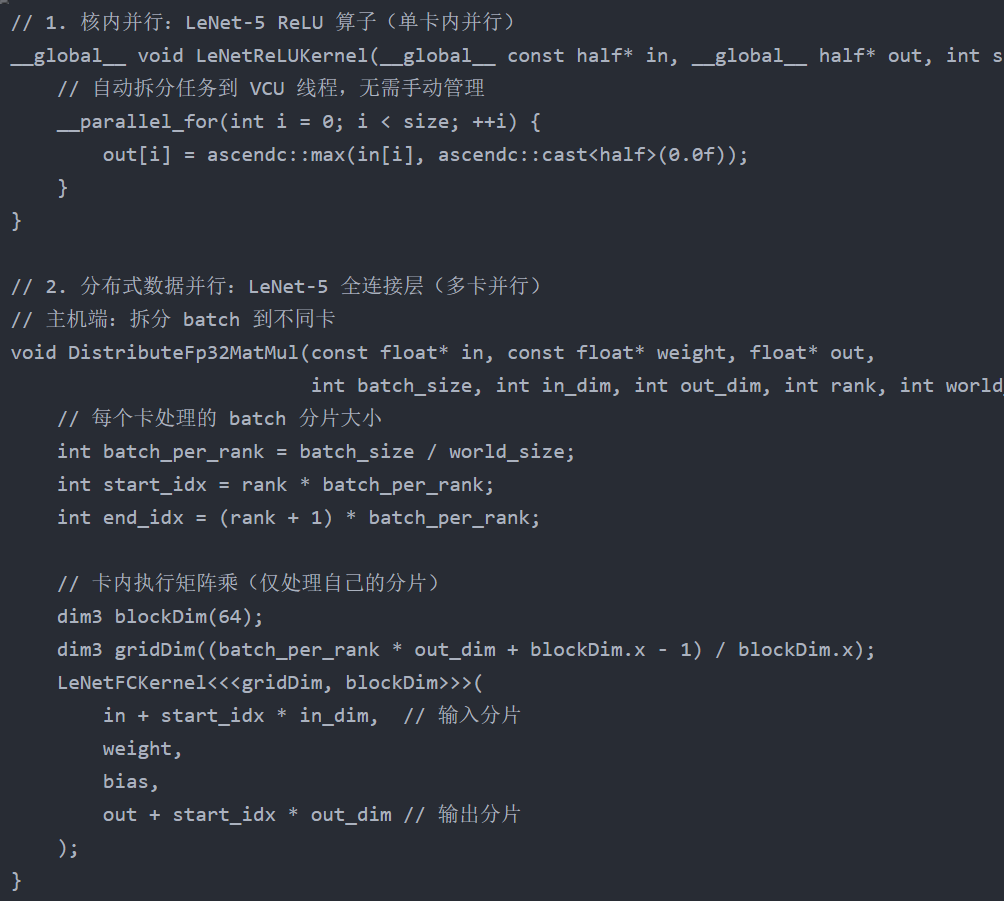
3. 额外提醒
- 小算子禁用分布式:如 MaxPool2D 这类计算量小的算子,分布式通信开销会抵消并行收益,优先用核内并行;
- 数据并行需保证权重一致:多卡训练时,需通过梯度同步(如 DDP 的梯度聚合)确保各卡权重相同;
- 模型并行慎用:仅当权重尺寸超过单卡内存(如 100G 权重)时才考虑,否则优先数据并行。
四、坑 4:算子的 “内存访问低效”—— 全局内存是性能瓶颈
坑点本质:忽视昇腾内存层级的访问差异
思维导图中的 “内存优化” 是提升算子性能的关键,新手常忽略昇腾 NPU 的内存层级特性:全局内存(Global Memory)容量大但访问速度慢(约 100ns / 次),局部内存(Local Memory)容量小但访问速度快(约 1ns / 次),寄存器访问速度最快(亚纳秒级)。
以 LeNet-5 的 Conv2D 算子为例:若每次计算都从全局内存读取卷积核和输入特征图,一个 5×5 卷积核在 28×28 特征图上滑动时,需重复访问卷积核 28×28 次,全局内存访问次数暴增,导致算子性能被内存访问速度限制(而非计算能力)。
避坑指南:数据缓存 + 内存对齐 + 减少冗余访问
1. 核心解决方法
用 Ascend C 的 __local__ 关键字将热点数据(如卷积核、输入特征图分片)缓存到局部内存,减少全局内存访问次数;同时保证数据内存对齐,提升硬件访问效率。
2. 代码示例:内存优化后的 Conv2D 算子
c
运行
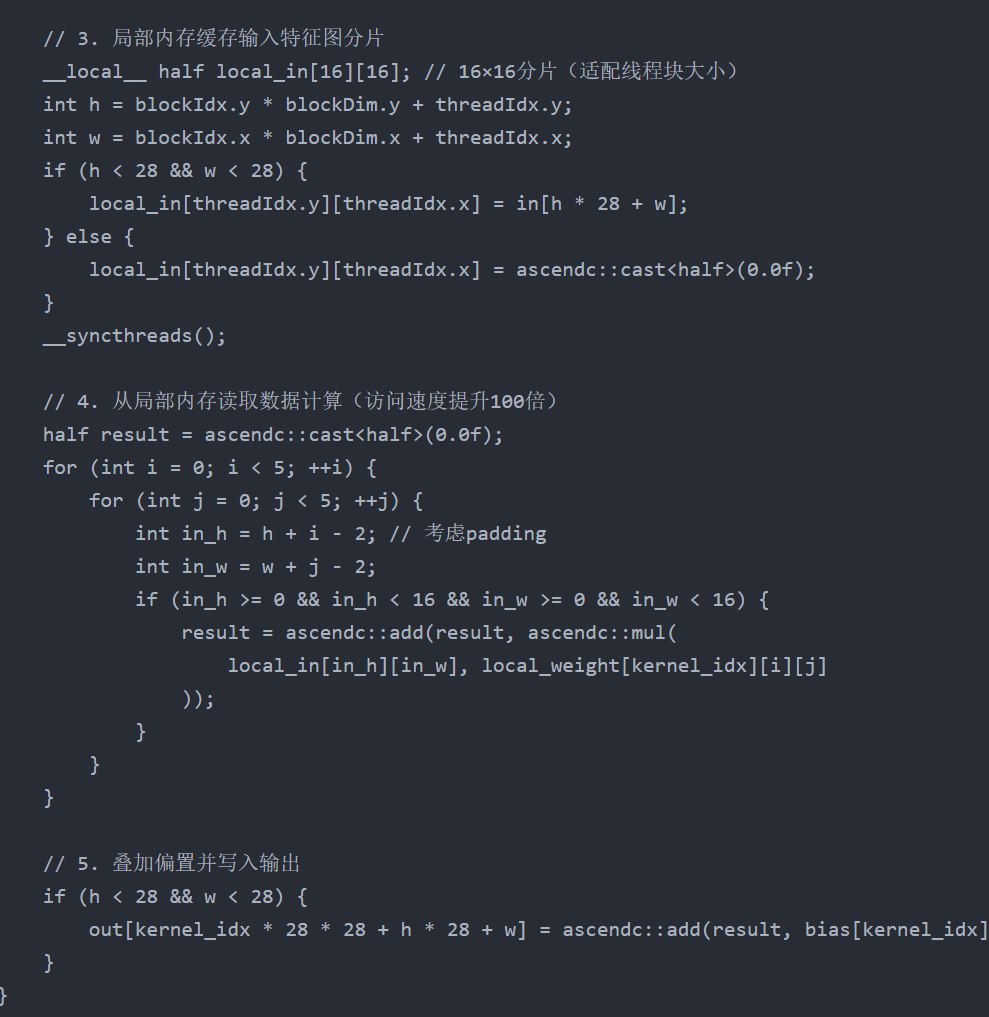
3. 额外提醒
- 局部内存容量限制:昇腾 AI Core 的局部内存容量有限(通常为几十 KB),缓存数据时需控制尺寸,避免溢出;
- 数据对齐:确保全局内存加载到局部内存的数据按 64 字节对齐(昇腾 NPU 最优访问粒度),可通过
__attribute__((align(64)))声明; - 减少冗余访问:避免重复加载同一数据(如卷积核仅加载 1 次,而非每次计算都加载),最大化局部内存复用率。
五、总结:避坑的核心逻辑 ——“对齐需求,适配硬件”
昇腾算子开发的四大坑,本质都是 “算子设计与模型需求、硬件特性脱节”:数据类型不匹配是未对齐硬件计算单元特性,Shape 兼容性不足是未考虑实际场景需求,并行策略选错是未匹配算子规模,内存访问低效是未利用硬件内存层级。
避坑的关键的是建立 “需求→硬件→实现” 的联动思维:
- 先明确算子的功能需求(输入输出类型、支持的 Shape 范围);
- 再适配昇腾硬件特性(计算单元支持的类型、内存层级、并行能力);
- 最后用 Ascend C 提供的工具(类型声明、Shape 推断、并行接口、内存关键字)落地实现。
后续开发中,可在思维导图中补充 “避坑标注”—— 如在 “数据类型” 后标注 “显式声明 + 编译校验”,在 “并行策略” 后标注 “小核内、大分布式”,在 “内存优化” 后标注 “局部内存缓存”,形成个人专属的开发手册,让坑点提前暴露,效率翻倍。
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https:
//www.hiascend.com/developer/activities/cann20252

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 18
18 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)