
Ascend C 入门:昇腾算子开发的 “专属工具”
对于 AI 开发者来说,Ascend C 不仅是一门算子开发语言,更是进入昇腾异构计算生态的 “钥匙”。通过 CANN 训练营 2025 第二季的系统学习,新手能快速掌握 Ascend C 的核心语法和开发技巧,理解算子与硬件的适配逻辑,为后续的性能调优、复杂算子开发打下坚实基础。2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程
一、CANN 与 Ascend C 的关系
昇腾 CANN 是 AI 异构计算架构(类似 CUDA 之于 NVIDIA),而Ascend C 是 CANN 生态下的算子开发语言—— 相当于给开发者一把 “适配昇腾硬件的手术刀”,专门用来写高效算子。更形象的比喻:CANN 是 “操作系统”,Ascend C 是 “编程语言”,用 Ascend C 写的算子,能直接调用 CANN 提供的硬件加速接口。
从技术架构来看,CANN 为 Ascend C 提供了三层核心支撑:一是硬件抽象层,屏蔽不同昇腾芯片(如昇腾 310B、910B)的底层差异,让算子开发无需适配具体硬件型号;二是计算引擎层,提供矩阵乘、向量运算等基础计算能力,Ascend C 可通过内置接口直接调用;三是编译优化层,对 Ascend C 代码进行自动并行化、指令优化,最大化释放硬件算力。
反过来,Ascend C 是 CANN 生态的 “算子入口”:开发者通过 Ascend C 编写的算子,可无缝集成到 TensorFlow、PyTorch 等主流框架(通过 CANN 提供的框架适配插件),也可直接部署到端、边、云等不同场景的昇腾设备上。这种 “一次开发、多端部署” 的特性,让 Ascend C 成为连接开发者与昇腾硬件的核心桥梁。
二、先搞懂昇腾 AI 处理器的 “底子”
写 Ascend C 前,得先了解硬件架构(否则写出来的算子会 “水土不服”):
- 昇腾芯片的 SoC 形态:一颗昇腾芯片包含 “CPU 集群 + AI Core 集群 + DVPP(媒体处理单元)”,算子主要运行在 AI Core 上;CPU 集群负责任务调度、数据预处理等控制类工作,DVPP 专注于图像 / 视频的编解码、格式转换,三者协同完成 AI 计算全流程。
- AI Core 的达芬奇架构:每个 AI Core 分为 “张量计算单元(TCU)+ 向量计算单元(VCU)+ 标量计算单元(SCU)”——TCU 负责大矩阵乘、卷积等高密度计算(算力可达 TFLOPS 级别),VCU 负责向量级运算(如激活函数、数据拼接),SCU 负责控制逻辑(如循环判断、线程同步)。这种分工明确的架构,要求算子开发需 “按需分配计算任务”,才能充分发挥硬件性能。
- 内存层级结构:昇腾 AI Core 的内存分为全局内存(Global Memory)、局部内存(Local Memory)、寄存器(Register),访问速度依次递增(寄存器最快,全局内存最慢),但容量依次递减。算子开发的核心内存优化思路,就是 “让热点数据尽量存放在高速内存中”,减少全局内存访问次数。
- 核间 / 核内分层:“核间” 指多 AI Core 之间的并行(如一颗昇腾 910B 芯片包含 64 个 AI Core,可同时处理多个算子任务),“核内” 指单 AI Core 内 TCU/VCU/SCU 的协同 ——Ascend C 会通过 “并行标记” 自动适配这两种并行场景,开发者无需手动编写复杂的并行调度逻辑。
举个直观例子:一个卷积算子的执行流程,会先由 CPU 调度将输入数据传输到全局内存;再由 AI Core 的 SCU 分配任务,将卷积核数据加载到局部内存;接着由 TCU 并行执行卷积核与输入特征图的矩阵乘运算,VCU 负责累加结果并执行 ReLU 激活;最后由 SCU 将计算结果写回全局内存。理解这个流程,才能在 Ascend C 开发中做出针对性优化。
三、Ascend C 的核心优势(附代码示例 + 深度解析)
为什么用 Ascend C 写算子?它解决了新手的多个痛点,且每个优势都与昇腾硬件架构深度绑定:
1. 天然适配硬件并行:不用手动写多线程,编译期自动优化
昇腾 AI Core 的并行能力(核间多 Core 并行、核内多计算单元并行),通过 Ascend C 的 “并行标记” 即可调用,无需开发者掌握底层线程调度机制:

这三个阶段会重叠执行(如读阶段的第 2 批数据和算阶段的第 1 批数据同时进行),理论上可让硬件利用率达到 100%,开发者无需手动编写流水线逻辑。
(2)内置硬件优化接口
Ascend C 提供了大量封装好的硬件优化接口,新手直接调用即可实现性能提升,无需理解底层指令:

- 深度解析:
__parallel_for是 Ascend C 的核内并行关键字,编译器会根据循环次数 N、硬件计算单元数量,自动拆分循环任务到多个 VCU 线程中执行;如果 N 较大,还会触发 TCU 的向量并行指令,进一步提升计算效率。 - 扩展用法:通过
__parallel_for的可选参数,可指定并行粒度(如每次处理 32 个数据)、线程块大小,适配不同计算场景: 
对于核间并行,Ascend C 通过 “算子任务拆分” 机制自动实现:开发者只需在算子定义中指定 “支持核间并行”,CANN 编译时会根据硬件 AI Core 数量,将输入数据分片到多个 Core 上并行处理,最后合并结果。
2. 降低调优门槛:自动化流水并行 + 内置优化接口
新手调优的最大痛点是 “不知道从哪下手”,Ascend C 通过两大特性降低调优难度:
(1)自动化流水并行调度
Ascend C 编译器会自动将算子的 “读数据→计算→写结果” 拆成流水线,让 AI Core 的计算单元和内存访问单元 “并行工作”,避免硬件空闲。例如一个 “乘加” 算子(
output[i] = input[i] * weight[i] + bias[i]),流水线会分为三个阶段:- 读阶段:从全局内存读取 input、weight、bias 数据到局部内存;
- 算阶段:TCU/VCU 执行乘加运算;
- 写阶段:将计算结果写回全局内存。
- 优势解析:
ascendc::gemm接口已针对昇腾 TCU 进行深度优化,支持不同矩阵维度、数据类型的自动适配,性能接近硬件理论上限,比新手手动编写的矩阵乘算子性能高 3-5 倍。
3. 兼容通用规范 + 硬件特性:兼顾易用性和性能
Ascend C 遵循 C/C++11 及以上标准,同时提供硬件专属扩展,让熟悉 C/C++ 的开发者能快速上手:
(1)兼容 C/C++ 标准语法
开发者可直接使用 C/C++ 的变量定义、循环、条件判断等语法,无需学习全新的语言体系:
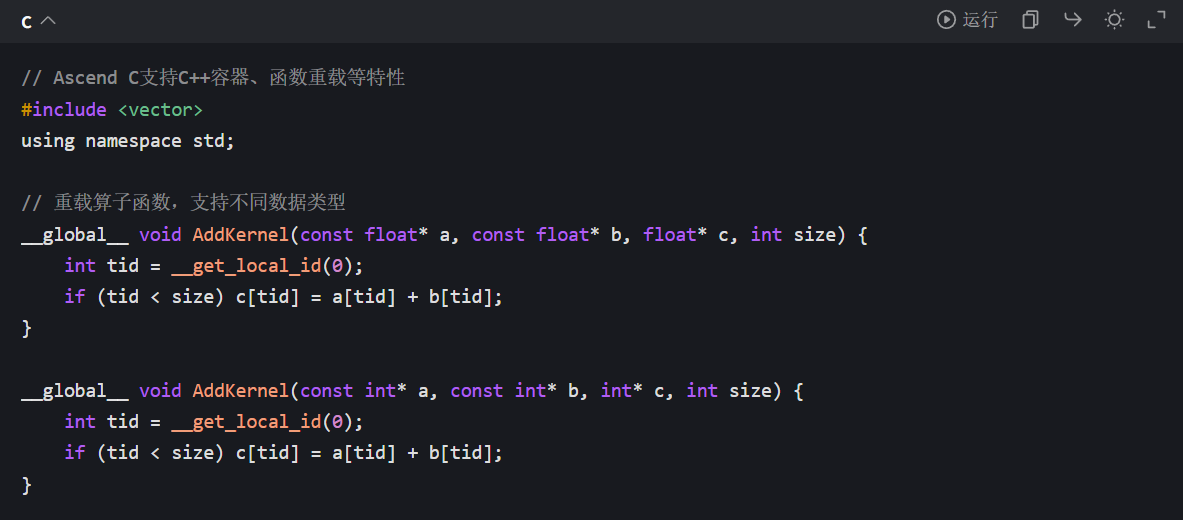
2)硬件专属变量限定符
通过关键字声明变量的内存存储位置,实现内存优化:
| 限定符 | 内存位置 | 适用场景 | 示例代码 |
|---|---|---|---|
__global__ |
全局内存 | 多线程共享数据、输入输出数据 | __global__ float input[N]; |
__local__ |
局部内存 | 线程块内共享数据、热点数据缓存 | __local__ float cache[256]; |
__private__ |
线程私有内存 | 线程独立变量 | __private__ int tid = __get_local_id(0); |
示例:利用__local__缓存热点数据,减少全局内存访问:
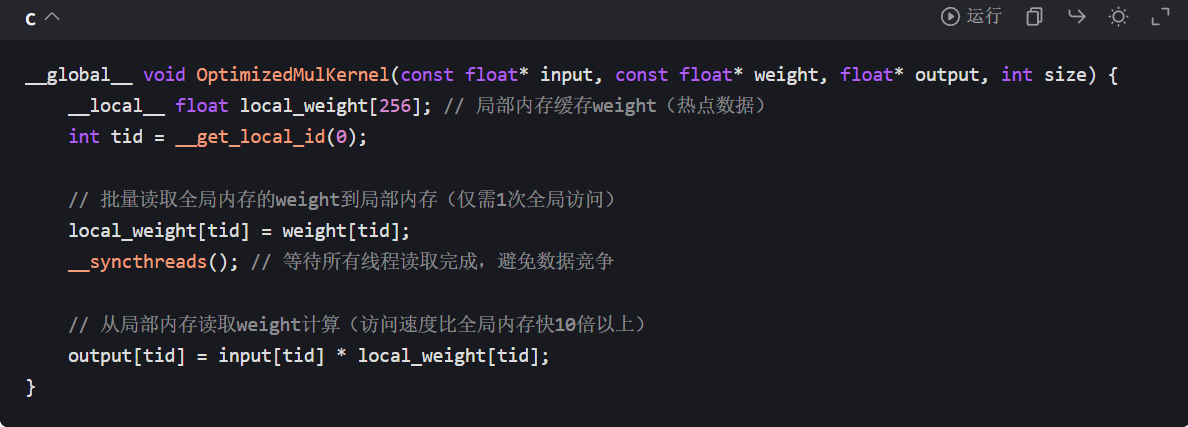
4. 完善的错误处理与调试支持
新手开发时最怕 “报错无头绪”,Ascend C 提供了结构化的错误处理机制和调试接口:
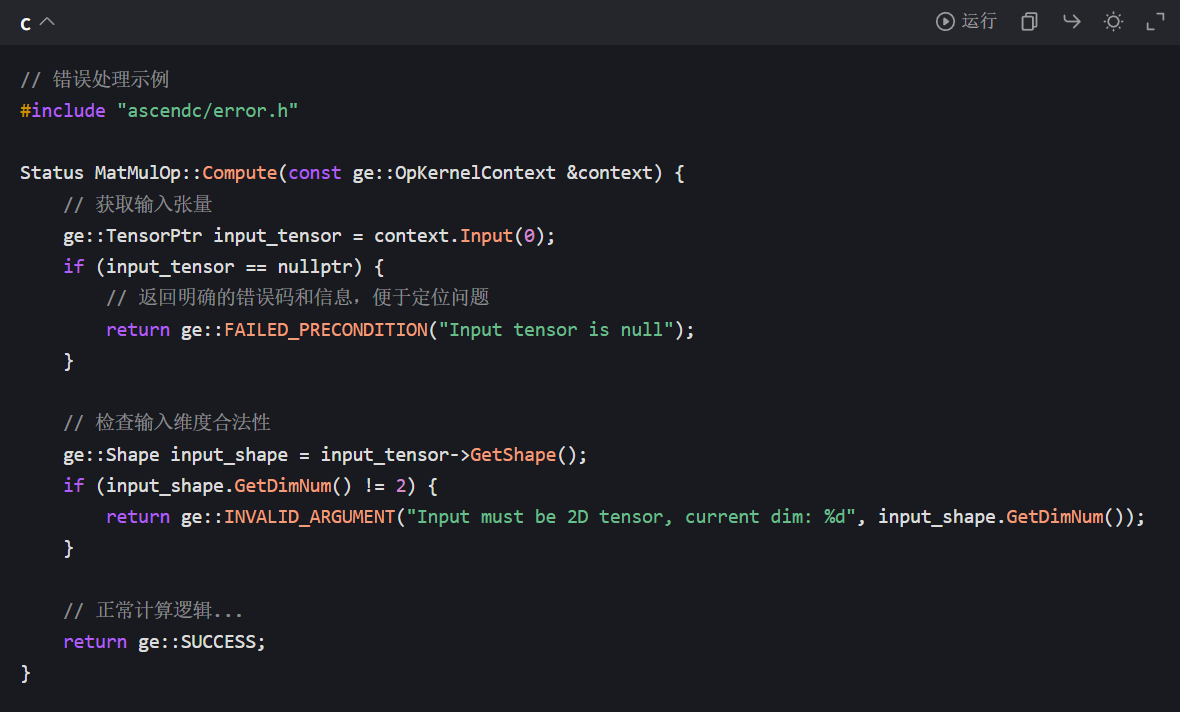
配合昇腾调试工具(如 Ascend Debugger),可实时查看算子运行时的内存数据、线程状态、硬件寄存器值,快速定位 “计算错误”“性能瓶颈” 等问题。
四、从训练营学 Ascend C:手把手带你落地实战
CANN 训练营 2025 第二季的「Ascend C 概述」课,会从 “是什么→怎么用” 拆解,兼顾理论与实操,让新手能快速上手:
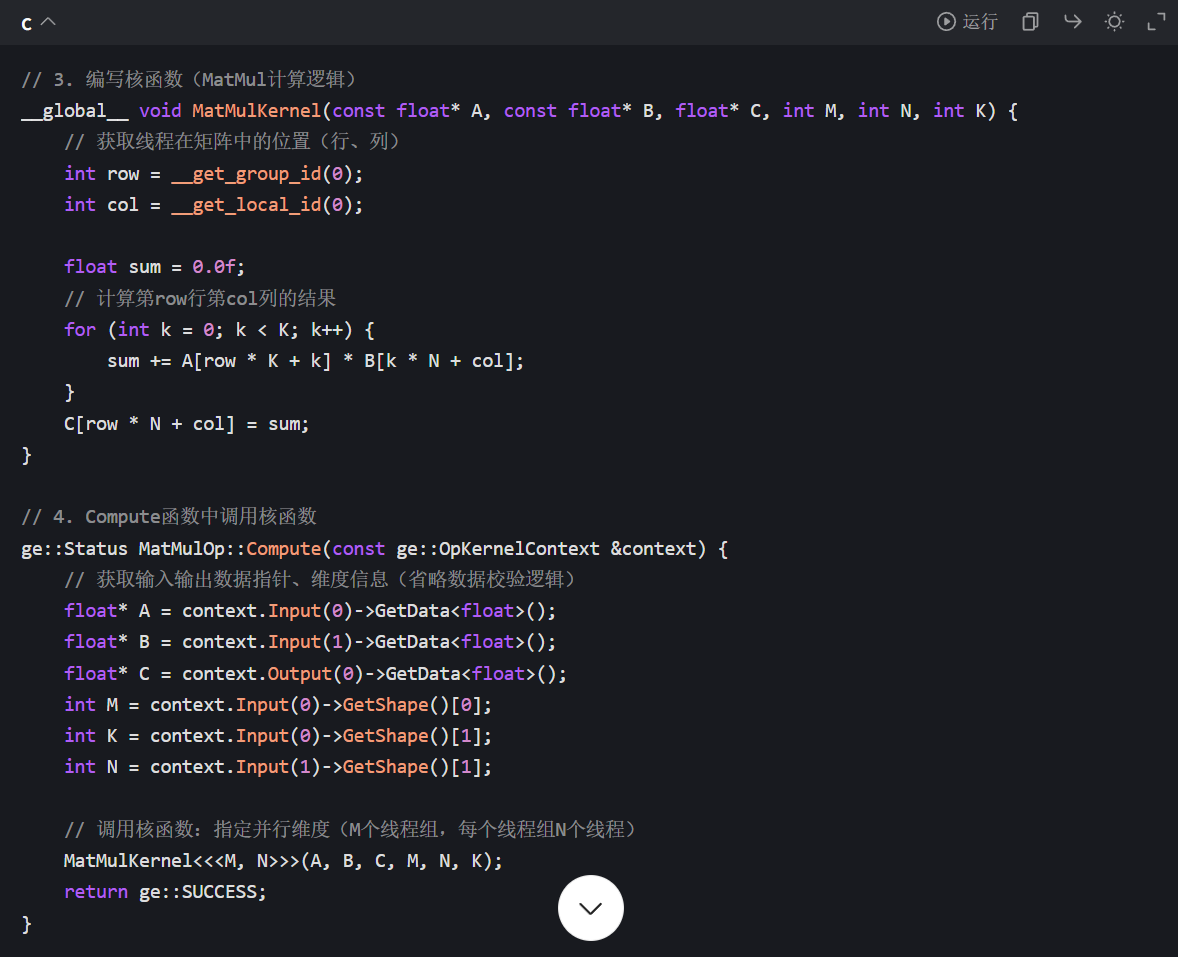
1. 全流程实战:从代码编写到 NPU 运行
讲师会现场演示 “用 Ascend C 写一个简单的 MatMul 算子”,覆盖完整开发链路:
(1)算子定义与接口声明
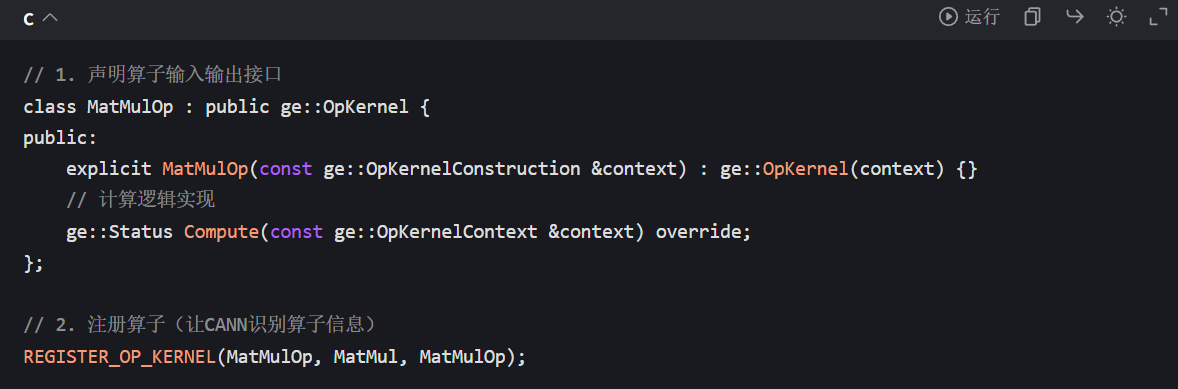
(2)核函数编写与并行优化
对于 AI 开发者来说,Ascend C 不仅是一门算子开发语言,更是进入昇腾异构计算生态的 “钥匙”。通过 CANN 训练营 2025 第二季的系统学习,新手能快速掌握 Ascend C 的核心语法和开发技巧,理解算子与硬件的适配逻辑,为后续的性能调优、复杂算子开发打下坚实基础。
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:
https://www.hiascend.com/developer/activities/cann20252

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)