
CANN特性能力解析:释放硬件潜能,简化AI开发
作为华为昇腾AI基础软硬件平台的核心,CANN(Compute Architecture for Neural Networks)通过端云一致的异构计算架构,为AI基础设施提供了从硬件驱动到上层框架适配的软件支撑。其以极致性能优化为核心目标,覆盖应用开发、算子开发、模型部署全流程,显著降低了AI开发门槛。接下来我将从三个维度展开,为大家揭示CANN的技术魅力。一、CANN的核心价值:构建全场景AI
前言
作为华为昇腾AI基础软硬件平台的核心,CANN(Compute Architecture for Neural Networks)通过端云一致的异构计算架构,为AI基础设施提供了从硬件驱动到上层框架适配的软件支撑。其以极致性能优化为核心目标,覆盖应用开发、算子开发、模型部署全流程,显著降低了AI开发门槛。
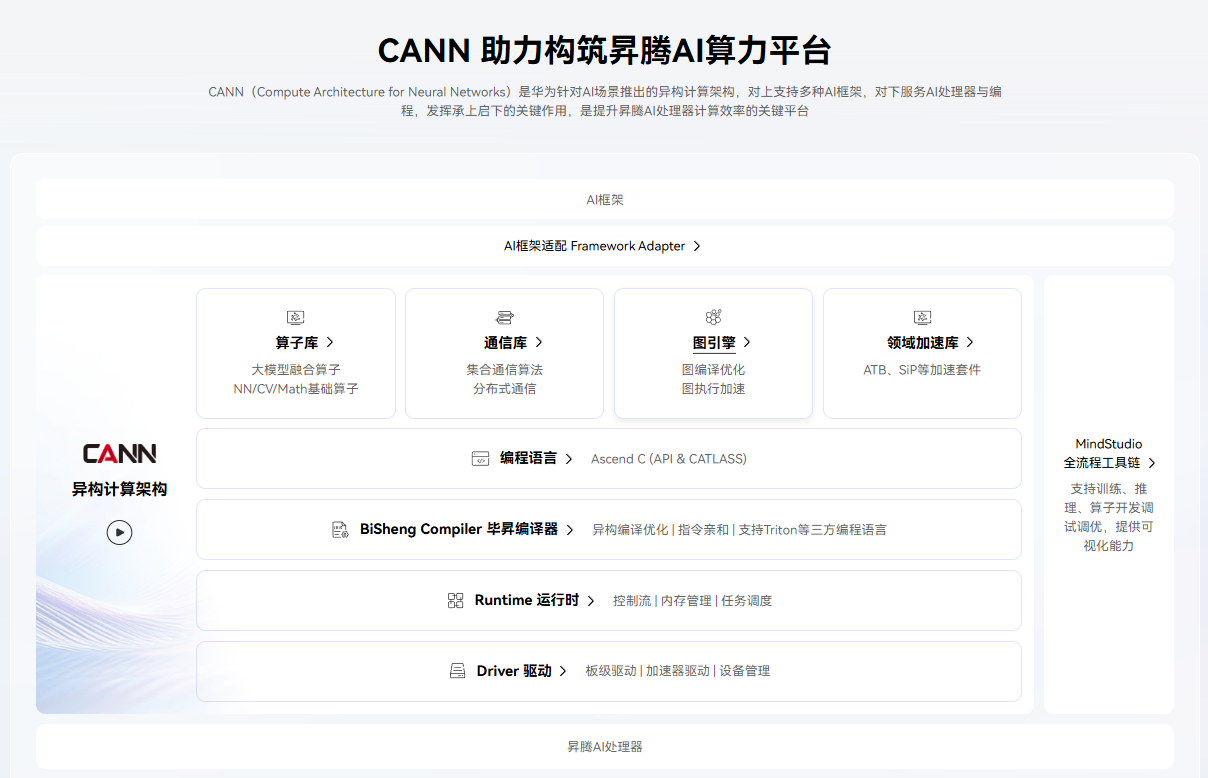
接下来我将从三个维度展开,为大家揭示CANN的技术魅力。
一、CANN的核心价值:构建全场景AI开发基石
1. 对应用/算子开发者的全链路支持
-
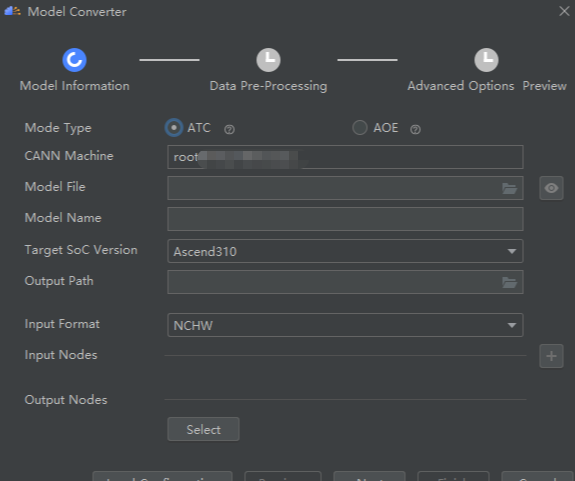
应用开发者:通过MindStudio全流程工具链 (集成训练、推理、调优可视化界面),无需深入硬件细节即可完成模型部署。例如,在MindStudio中一键将PyTorch模型转换为昇腾NPU可执行的
.om文件。图1:MindStudio模型转换界面
-
算子开发者:提供Ascend C编程语言**与**自定义算子开发模板库 ,支持通过C/C++代码直接定义硬件友好型算子。例如,实现一个自定义的
Sigmoid激活函数。
2. 图引擎与框架适配能力
-
多框架兼容:通过Framework Adapter 适配PyTorch、TensorFlow等主流框架,自动完成算子映射与计算图转换。例如,将TensorFlow的
tf.nn.conv2d无缝转换为昇腾NPU的Conv算子。 -
图编译优化:内置图引擎 对计算图进行融合、并行化、内存复用等优化。例如,将连续的
Conv+ReLU算子融合为单个FusedConvReLU算子,减少内存访问。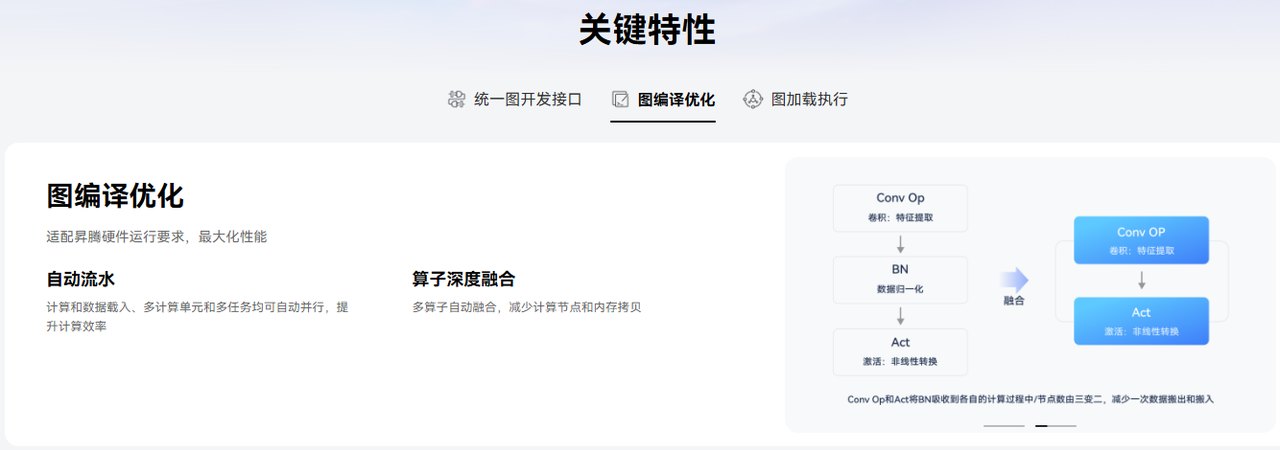
图引擎( Graph Engine ,简称GE)是计算图编译和运行的控制中心,提供图优化、图编译管理以及图执行控制等功能。GE通过统一的图开发接口提供多种AI框架的支持,不同AI框架的计算图可以实现到Ascend图的转换。
3. 简化AI开发与提升计算效率
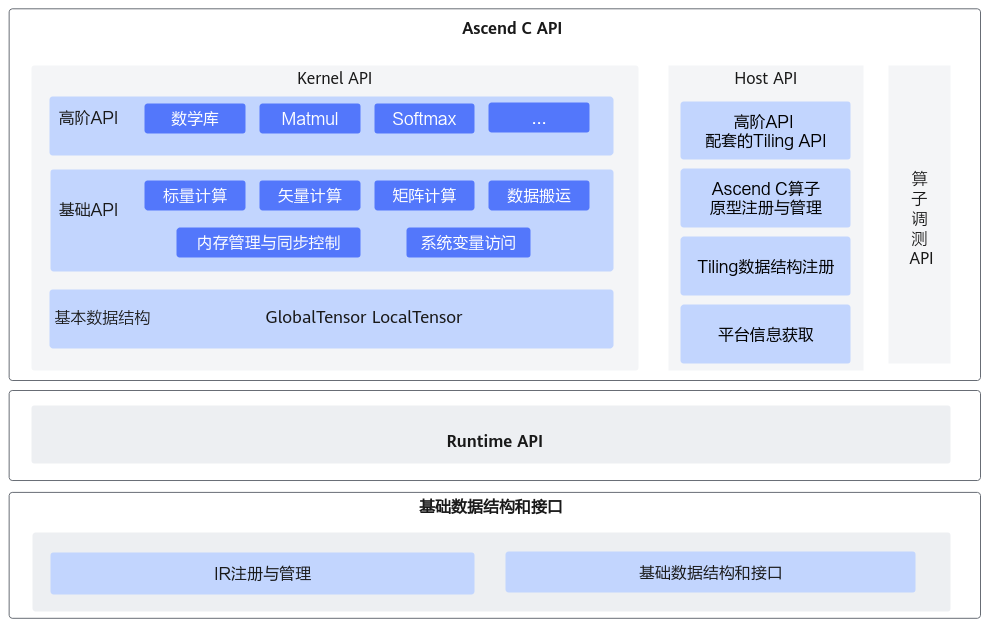
-
开发效率提升:通过极简易用 的Ascend C API与预置算子库,算子开发时间从数天缩短至数小时。
-
性能飞跃:软硬协同优化使昇腾AI处理器的算力利用率提升至90%以上。例如,ResNet50模型在昇腾910上的推理吞吐量达2100FPS(FP16精度)。
二、关键能力解析:从资源调度到算子优化
1. ACL接口:统一资源调度与计算控制
ACL(Ascend Computing Language) 是CANN提供的底层编程接口,负责管理硬件资源(如内存、流、事件)与执行计算任务。其核心能力包括:
-
动态资源分配:通过
aclrtSetDevice与aclrtCreateStream实现多设备、多流并行计算。// 示例:初始化ACL环境并分配设备 aclError ret = aclInit(); aclrtContext context; ret = aclrtCreateContext(&context, 0); // 绑定设备0 aclrtStream stream; ret = aclrtCreateStream(&stream); // 创建计算流 -
异步执行优化:通过
aclrtSubmitTask将计算任务提交至硬件,非阻塞等待结果。
2. ACLNN算子:性能优化实践
ACLNN(Ascend Computing Language Neural Network) 是CANN的高性能算子库,覆盖NN(神经网络)、CV(计算机视觉)、Math(数学运算)等领域。其优化手段包括:
-
算子融合:将多个小算子合并为一个大算子,减少数据搬运。例如,
Conv+BiasAdd+ReLU融合为FusedConv。 -
硬件亲和指令:针对昇腾NPU的矩阵乘法单元(如Cube单元),使用
aclnnConv2d的affine_mode参数启用TensorCore加速。// 示例:调用ACLNN卷积算子(启用TensorCore) aclnnConv2dDesc desc; aclnnInitConv2dDesc(&desc, ACL_FLOAT16, ACL_FORMAT_NCHW, 3, 64, 3, 3, 1, 1, 1, 1); // 输入通道3,输出通道64 desc.affine_mode = ACL_AFFINE_MODE_TENSOR_CORE; // 启用TensorCore -
量化压缩:支持INT8量化,模型体积缩小75%,推理速度提升2-3倍。

3. 自定义算子开发路径
当预置算子无法满足需求时,开发者可通过以下步骤实现自定义算子:
步骤1:使用Ascend C定义算子
// 示例:自定义Sigmoid激活函数
#include "ascendc_kernel.h"
__ascendc_kernel__ void CustomSigmoid(float* input, float* output, int size) {
for (int i = 0; i < size; i++) {
output[i] = 1.0f / (1.0f + expf(-input[i]));
}
}步骤2:通过ATC编译为离线模型
atc --op_type=CustomSigmoid \
--op_path=./custom_ops.so \
--output=custom_sigmoid.om \
--soc_version=Ascend910步骤3:在MindStudio中调用自定义算子
# 示例:PyTorch中调用自定义Sigmoid
import torch
from torch.autograd import Function
class CustomSigmoidFunc(Function):
@staticmethod
def forward(ctx, input):
# 调用ACL接口执行自定义算子
acl_output = acl_run_custom_op(input.numpy())
return torch.from_numpy(acl_output)
sigmoid = CustomSigmoidFunc.apply三、实践建议与资源链接

结语:CANN通过极致性能优化 与极简易用开发 ,重新定义了AI基础设施的软件标准。无论是应用开发者还是算子开发者,均可借助其开放的生态与丰富的工具链,快速构建高性能AI解决方案。立即访问官网,开启你的昇腾AI开发之旅!

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 32
32 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)