
鸿蒙NEXT ArkTS实战:从零构建AI学习助手应用全解析



本文将带你深入鸿蒙NEXT生态,通过一个完整的AI学习助手应用案例,覆盖ArkTS语言特性、声明式UI开发、离线学习计划生成引擎、LLM集成、以及鸿蒙应用架构设计等核心主题。
目录
项目概述
在鸿蒙NEXT(HarmonyOS NEXT)生态蓬勃发展的当下,越来越多的开发者开始关注这个全新的操作系统平台。鸿蒙NEXT作为华为自主研发的操作系统,摒弃了Android兼容层,采用全新的ArkTS语言和ArkUI框架构建原生应用。本文将以一个完整的AI学习助手应用为例,带你从零开始掌握鸿蒙NEXT应用开发的核心技能。
AI学习助手是一款面向学生和自学者的智能学习管理工具。它能够根据用户选择的科目、难度等级和每日可用时间,自动生成个性化的学习计划;内置知识测验系统帮助用户检验学习效果;并通过可视化进度面板追踪学习成果。整个应用完全使用ArkTS编写,遵循鸿蒙NEXT API 24规范,仅用不到500行代码实现了完整的业务逻辑和精美的用户界面。
选择学习助手这个场景作为教学案例,是因为它涵盖了移动应用开发中最常见的需求:数据管理、列表渲染、条件渲染、状态管理、表单交互、进度展示等。同时,学习计划生成引擎的设计也展示了如何在客户端实现智能化的业务逻辑,而不是一味依赖云端AI。
功能特性
1. 八大科目支持
应用内置了八门常见学科:数学、英语、编程、历史、物理、化学、文学、艺术。每门学科都配备了丰富的知识点库和测验题库。用户可以根据自己的学习需求自由切换科目。
2. 四级难度体系
从入门到高级,四级难度体系覆盖了不同学习阶段的需求。入门适合零基础学习者,基础适合初步掌握的学习者,进阶适合有一定基础想要提升的学习者,高级则面向希望深入掌握的学习者。不同难度对应不同的学习计划时长:
- 入门:3天紧凑计划
- 基础:5天系统计划
- 进阶:7天强化计划
- 高级:10天深度计划
3. 灵活的时间配置
用户可以通过滑块自由选择每日学习时间,从1小时到8小时,以1小时为步进单位。系统会根据每日可用时间自动计算每个学习任务的时长分配,确保学习计划与用户的实际时间安排相匹配。
4. 个性化学习计划生成
基于离线引擎的智能学习计划生成系统,会根据科目、难度和每日时间三个维度,自动生成结构化的学习计划。每个计划包含多个学习日,每个学习日包含三个时段(上午、下午、晚上)的学习任务。任务内容涵盖概念学习、专项练习、重点复习等多种类型。
5. 交互式知识测验
内置15道跨学科测验题目,涵盖所有八门科目。用户选择测验科目后,系统会从题库中随机抽取5道题目进行测验。每道题目都标注了所属知识点,帮助用户了解自己的薄弱环节。测验结束后展示详细的答题结果,包括正确答案和用户答案的对比。
6. 学习进度可视化
环形进度条直观展示学习任务完成情况,统计卡片展示测验次数、平均得分、连续学习天数等关键指标。智能学习建议系统会根据当前进度给出个性化的学习建议,帮助用户保持学习动力。
7. LLM集成预留
代码中预留了完整的LLM API调用模块(已注释),支持接入OpenAI GPT-4等大语言模型,实现更智能的学习计划生成。开发者只需取消注释并配置API密钥即可激活AI能力。
技术架构
整体架构图
┌─────────────────────────────────────────────────┐
│ Index.ets │
│ ┌───────────────┬───────────────┬─────────────┐ │
│ │ 学习计划 Tab │ 知识测验 Tab │ 学习进度 Tab │ │
│ │ ┌─────────┐ │ ┌─────────┐ │ ┌────────┐ │ │
│ │ │科目选择器│ │ │题目展示 │ │ │环形进度│ │ │
│ │ │难度选择器│ │ │选项交互 │ │ │统计卡片│ │ │
│ │ │时间滑块 │ │ │进度指示 │ │ │学习建议│ │ │
│ │ │计划展示 │ │ │结果分析 │ │ │ │ │ │
│ │ └─────────┘ │ └─────────┘ │ └────────┘ │ │
│ └───────────────┴───────────────┴─────────────┘ │
│ ┌─────────────────────────────────────────────┐ │
│ │ 状态管理 (@State) │ │
│ │ tabIdx | plan | progress | qquestions | ... │ │
│ └─────────────────────────────────────────────┘ │
│ ┌─────────────────────────────────────────────┐ │
│ │ 业务逻辑层 │ │
│ │ generatePlan() | filterKP() | shuffleQQ() │ │
│ │ finishQuiz() | refreshProgress() | ... │ │
│ └─────────────────────────────────────────────┘ │
│ ┌─────────────────────────────────────────────┐ │
│ │ 数据层 │ │
│ │ KNOWLEDGE_POINTS[] | QUIZ_BANK[] | ... │ │
│ └─────────────────────────────────────────────┘ │
│ ┌─────────────────────────────────────────────┐ │
│ │ LLM API 模块 (待激活) │ │
│ │ callLLM() | OpenAI GPT-4 集成 │ │
│ └─────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────┘
技术栈
| 层级 | 技术选型 | 说明 |
|---|---|---|
| 语言 | ArkTS | 鸿蒙NEXT原生语言,TypeScript超集 |
| UI框架 | ArkUI | 声明式UI,组件化开发 |
| 状态管理 | @State | 鸿蒙原生响应式状态管理 |
| 数据持久化 | 内存 | 演示应用,数据存储在内存中 |
| API版本 | 24 | 鸿蒙NEXT最新API版本 |
| 网络 | @ohos.net.http | LLM API调用(预留) |
文件结构
AI学习助手/
├── Index.ets # 主应用文件(单文件架构)
├── blog.md # 项目文档
└── module.json5 # 模块配置(网络权限等)
采用单文件架构的设计理念是:在应用规模较小、逻辑清晰的情况下,单文件架构可以显著降低项目复杂度,方便开发者快速理解和修改。所有的接口定义、数据结构、业务逻辑和UI组件都集中在Index.ets中,便于代码审查和团队协作。
ArkTS语言深度解析
什么是ArkTS
ArkTS是华为为鸿蒙NEXT设计的一门静态类型语言,它在TypeScript的基础上进行了裁剪和增强,专门针对移动端UI开发场景优化。ArkTS保留了TypeScript的类型系统、接口、泛型等核心特性,但移除了部分不适合移动端动态特性的语法(如any类型、解构赋值等),同时增加了@State、@Component、@Builder等声明式UI装饰器。
接口定义规范
在ArkTS中,所有数据类型必须通过interface显式定义,不允许使用any类型。这是ArkTS区别于TypeScript的一个关键特性,也是开发者需要特别适应的地方。在AI学习助手应用中,我们定义了9个核心接口:
interface SubjectInfo { name: string; icon: string; }
interface KnowledgePoint { id: number; name: string; subject: string; description: string; }
interface QuizQuestion { id: number; question: string; options: string[]; correctIndex: number; subject: string; knowledgePoint: string; }
interface StudyTask { taskId: number; timeSlot: string; content: string; durationMinutes: number; completed: boolean; }
interface DailyPlan { day: number; dateLabel: string; tasks: StudyTask[]; }
interface StudyPlan { subject: string; difficulty: string; totalDays: number; dailyTimeHours: number; dailyPlans: DailyPlan[]; }
interface QuizResult { totalQuestions: number; correctCount: number; score: number; details: QuizDetail[]; }
interface QuizDetail { questionId: number; userAnswer: number; correctAnswer: number; isCorrect: boolean; }
interface StudyProgress { totalTasks: number; completedTasks: number; totalQuizAttempts: number; averageQuizScore: number; currentStreak: number; }
这种严格的类型约束虽然增加了代码量,但带来了显著的工程收益:编译期就能发现类型错误,IDE能提供精确的代码补全,代码可读性和可维护性大幅提升。
状态管理:@State装饰器
ArkTS使用@State装饰器实现响应式状态管理。当@State修饰的变量发生变化时,依赖该变量的UI组件会自动重新渲染。在AI学习助手中,我们使用了11个@State变量来管理应用状态:
@State tabIdx: number = 0; // 当前标签页索引
@State selSubject: string = '数学'; // 选中的学习科目
@State selDiff: string = '入门'; // 选中的难度等级
@State dailyTime: number = 2; // 每日学习时间
@State plan: StudyPlan | null = null; // 生成的学习计划
@State qquestions: QuizQuestion[] = []; // 测验题目列表
@State qIdx: number = 0; // 当前题目索引
@State qAnswers: number[] = []; // 用户答案记录
@State qResult: QuizResult | null = null; // 测验结果
@State qStarted: boolean = false; // 测验是否开始
@State qSubject: string = '数学'; // 测验科目
@State progress: StudyProgress = { ... }; // 学习进度
值得注意的是,ArkTS规定组件内只能使用@State装饰器,不能使用@Prop、@Link等其他装饰器。这种约束简化了状态管理的心智模型,避免了父子组件间复杂的传参逻辑。
深度拷贝与状态更新
在ArkTS中,直接修改嵌套对象的属性可能不会触发UI更新。因此,在处理学习任务完成状态切换时,我们采用了JSON序列化/反序列化进行深度拷贝:
handleToggle(dayIdx: number, taskIdx: number): void {
if (this.plan === null) { return; }
const ps: string = JSON.stringify(this.plan);
const np: StudyPlan = JSON.parse(ps) as StudyPlan;
np.dailyPlans[dayIdx].tasks[taskIdx].completed =
!np.dailyPlans[dayIdx].tasks[taskIdx].completed;
this.plan = np;
this.refreshProgress();
}
这种模式确保了@State能够检测到引用变化,从而触发UI重新渲染。虽然JSON序列化有一定的性能开销,但对于学习计划这类数据量不大的场景,影响可以忽略不计。
@Builder函数
ArkTS提供了@Builder装饰器用于创建可复用的UI构建函数。@Builder函数可以访问组件内的@State变量,实现UI的模块化组织。在AI学习助手中,我们使用了以下@Builder函数:
buildPlanTab()- 学习计划页面buildQuizTab()- 知识测验页面buildProgressTab()- 学习进度页面tabLabel()- 标签栏按钮sectionTitle()- 通用标题statCard()- 统计卡片
ForEach循环渲染
ArkTS使用ForEach进行列表渲染,需要提供第三个参数作为键值生成器:
ForEach(SUBJECTS, (it: SubjectInfo) => {
// UI构建
}, (it: SubjectInfo) => it.name)
这种设计与React的key属性类似,帮助ArkUI框架高效地进行差异更新。键值生成器必须返回唯一字符串,通常会使用数据的ID字段。
数据模型设计
知识点模型
知识点是学习计划生成的基础单元。每个知识点包含ID、名称、所属科目和描述信息。应用内置了27个知识点,覆盖八门学科:
- 数学(4个):代数基础、几何入门、函数概念、概率统计
- 英语(4个):基础词汇、语法规则、阅读理解、写作技巧
- 编程(4个):变量与类型、控制流、函数定义、数据结构
- 历史(3个):古代文明、文艺复兴、工业革命
- 物理(3个):力学基础、电磁学、热学
- 化学(3个):元素周期表、化学键、化学反应
- 文学(3个):诗歌鉴赏、小说分析、散文写作
- 艺术(3个):色彩理论、构图基础、艺术史
知识点按学科分组,通过filterKP()函数进行筛选,为学习计划生成提供数据基础。
测验题库模型
题库包含15道跨学科题目,涵盖所有八门科目。每道题目包含题目文本、四个选项、正确答案索引、所属科目和关联知识点。题目涵盖了选择题这种常见的测验形式,题目难度适中,适合入门到进阶各阶段的学习者。
题库设计遵循以下原则:
- 每道题目明确关联一个知识点,便于针对性学习
- 选项设计合理,干扰项有迷惑性但不至于过于刁钻
- 覆盖核心概念和基础知识点
- 题目表述简洁清晰,避免歧义
学习计划模型
学习计划采用层级结构:StudyPlan包含多个DailyPlan,每个DailyPlan包含多个StudyTask。这种设计清晰反映了学习计划的自然结构:
StudyPlan (学习计划)
├── subject: 科目
├── difficulty: 难度
├── totalDays: 总天数
├── dailyTimeHours: 每日学习时间
└── dailyPlans[]: DailyPlan[]
├── day: 第几天
├── dateLabel: 日期标签
└── tasks[]: StudyTask[]
├── taskId: 任务ID
├── timeSlot: 时段
├── content: 任务内容
├── durationMinutes: 时长
└── completed: 是否完成
进度模型
StudyProgress接口追踪五个维度的学习数据:
- totalTasks:总任务数
- completedTasks:已完成任务数
- totalQuizAttempts:测验总次数
- averageQuizScore:平均得分
- currentStreak:连续学习天数
离线学习计划生成引擎
算法设计
学习计划生成引擎是本应用的核心创新点。它不需要网络连接,完全在客户端运行,基于规则引擎实现智能化的学习计划生成。
算法的输入参数:
subject:学习科目difficulty:难度等级dailyTime:每日学习时间(小时)
处理流程:
- 知识点筛选:根据选择的科目,从知识库中筛选出对应的知识点列表
- 天数确定:根据难度等级映射学习天数(入门3天/基础5天/进阶7天/高级10天)
- 时间分配:将每日学习时间按40%、35%、25%的比例分配到上午、下午、晚上三个时段
- 任务生成:对每一天,循环选取知识点,为每个时段生成一个学习任务
- 任务内容组合:从6种任务动作模板中选取,与知识点名称组合成任务描述
代码实现
function generatePlan(subject: string, difficulty: string, dailyTime: number): StudyPlan {
const kps: KnowledgePoint[] = filterKP(subject);
const totalDays: number = getDifficultyDays(difficulty);
const dps: DailyPlan[] = [];
let tid: number = 1;
for (let d = 1; d <= totalDays; d++) {
const tasks: StudyTask[] = [];
const totalMin: number = dailyTime * 60;
const amMin: number = Math.round(totalMin * 0.4);
const pmMin: number = Math.round(totalMin * 0.35);
const evMin: number = totalMin - amMin - pmMin;
const ki: number = (d - 1) % kps.length;
const kp: KnowledgePoint = kps[ki];
tasks.push({ taskId: tid, timeSlot: TIME_SLOTS[0],
content: TASK_ACTIONS[0] + kp.name, durationMinutes: amMin, completed: false });
tid = tid + 1;
tasks.push({ taskId: tid, timeSlot: TIME_SLOTS[1],
content: TASK_ACTIONS[1] + kp.name, durationMinutes: pmMin, completed: false });
tid = tid + 1;
tasks.push({ taskId: tid, timeSlot: TIME_SLOTS[2],
content: TASK_ACTIONS[2] + kp.name, durationMinutes: evMin, completed: false });
tid = tid + 1;
dps.push({ day: d, dateLabel: '第 ' + d + ' 天', tasks: tasks });
}
return { subject: subject, difficulty: difficulty, totalDays: totalDays,
dailyTimeHours: dailyTime, dailyPlans: dps };
}
时间分配策略
引擎将每日学习时间划分为三个时段,按比例分配:
- 上午时段(40%):适合高专注度的核心概念学习
- 下午时段(35%):适合专项练习和巩固
- 晚上时段(25%):适合复习和总结
这种分配策略基于认知科学中的注意力曲线理论:上午精力充沛适合学习新知识,下午适合练习应用,晚上适合回顾整理。用户可以根据自己的实际情况调整时段分配比例。
扩展性设计
引擎的设计预留了多个扩展点:
- 可以通过修改
TASK_ACTIONS数组增加新的任务类型 - 可以通过修改
getDifficultyDays函数调整学习天数 - 时间分配比例可以参数化,让用户自定义
- 未来可以接入LLM API,实现更智能的任务内容生成
UI设计与鸿蒙设计语言
设计理念
AI学习助手遵循鸿蒙NEXT设计语言的核心原则:简洁、清晰、高效。整体采用浅色主题,以白色卡片搭配浅灰背景,蓝色作为品牌主色调(#007DFF),营造专业、可信赖的视觉感受。
色彩体系
| 用途 | 色值 | 说明 |
|---|---|---|
| 主色调 | #007DFF | 鸿蒙蓝,用于按钮、选中态、进度条 |
| 成功色 | #34C759 | 测验及格、任务完成 |
| 警告色 | #FF3B30 | 测验不及格 |
| 背景色 | #F2F2F7 | 页面背景 |
| 卡片色 | #FFFFFF | 内容卡片背景 |
| 主文字 | #1A1A1A | 标题和重要文字 |
| 次文字 | #8E8E93 | 辅助说明文字 |
| 边框色 | #E5E5EA | 卡片和按钮边框 |
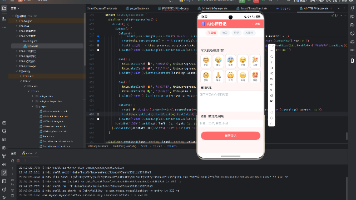
三标签页布局
应用采用Tabs标签页导航,三个标签页分别对应核心功能:
- 学习计划:包含科目选择器、难度选择器、时间滑块、生成按钮和计划展示
- 知识测验:包含科目选择器、题目展示、选项交互和结果分析
- 学习进度:包含环形进度条、统计卡片和学习建议
这种设计符合移动端用户的使用习惯,通过底部或顶部的标签栏快速切换功能模块,无需复杂的导航层级。
科目选择器
科目选择器采用水平滚动的卡片网格布局,每个科目用图标和文字表示。选中态使用蓝色填充背景和白色文字,未选中态使用白色背景和深色文字,形成清晰的视觉对比。8个科目在水平滚动容器中排列,用户可以左右滑动浏览所有科目。
难度选择器
难度选择器采用胶囊按钮(Chip)设计,四个难度等级以圆角按钮形式排列。选中态使用蓝色实心填充,未选中态使用浅蓝色背景和蓝色文字,与科目选择器保持一致的视觉风格。
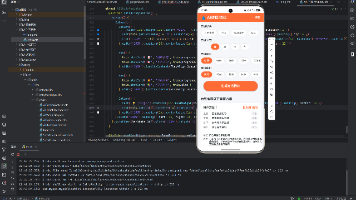
时间配置滑块
使用ArkUI原生的Slider组件,范围1-8小时,步进1小时。滑块上方显示当前选择的小时数,右侧标注最小值和最大值,帮助用户快速定位。滑块的颜色与主色调保持一致。
学习计划卡片
生成的学习计划以卡片形式展示,每个学习日是一个独立的卡片。卡片内包含日期标签、任务完成进度,以及三个时段的任务列表。已完成任务显示删除线效果和灰色背景,未完成任务显示浅蓝色背景。点击任务可以切换完成状态,提供即时反馈。
测验界面
测验界面采用逐步展示方式,每次只显示一道题目。顶部显示进度条和题号,中间显示题目内容,下方排列四个选项按钮。选项采用圆角卡片样式,点击后自动进入下一题。这种设计减少了用户的认知负担,让用户专注于当前题目。
结果展示
测验结果以大字显示分数,60分以上显示绿色,60分以下显示红色。下方列出每道题的详细结果,包括用户答案和正确答案的对比,正确显示绿色,错误显示红色。这种直观的反馈帮助用户快速了解自己的薄弱环节。
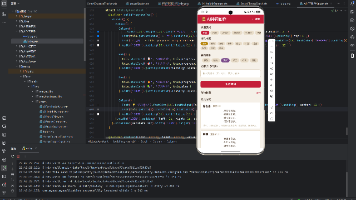
进度可视化
环形进度条(ProgressType.Ring)直观展示学习任务完成百分比。下方四个统计卡片采用2x2网格布局,展示测验次数、平均得分、连续天数和学习科目。学习建议区域根据当前进度动态生成鼓励性文字。
知识测验系统
随机抽题机制
测验系统从题库中按科目筛选题目,然后使用Fisher-Yates洗牌算法的变体随机抽取5道题目:
function shuffleQQ(questions: QuizQuestion[], count: number): QuizQuestion[] {
const s: QuizQuestion[] = [];
const src: QuizQuestion[] = [];
for (let i = 0; i < questions.length; i++) { src.push(questions[i]); }
while (s.length < count && src.length > 0) {
const ri: number = Math.floor(Math.random() * src.length);
s.push(src[ri]);
src.splice(ri, 1);
}
return s;
}
这种洗牌方式保证了每次测验的题目顺序随机,且不会重复抽取同一道题。
答题流程
答题流程分为三个状态:
- 未开始状态:显示科目选择器和开始按钮
- 答题中状态:显示当前题目和选项,记录用户答案
- 已完成状态:显示测验结果和详细分析
状态转换通过qStarted和qResult两个@State变量控制,利用ArkTS的条件渲染实现不同状态下的UI切换。
评分机制
测验采用百分制评分,计算方式为:答对题数 / 总题数 × 100。得分会记录到学习进度中,并计算历史平均分。这种累积式的评分机制鼓励用户多次测验,持续提升。
结果分析
测验结果不仅显示总分,还展示每道题的详细分析:用户答案、正确答案、是否正确。这种细粒度的反馈帮助用户识别知识盲点,有针对性地进行复习。
学习进度可视化
环形进度条
环形进度条是学习进度的核心视觉元素。它使用ArkUI的Progress组件,类型为ProgressType.Ring,直观展示任务完成比例。进度条的颜色使用主色调蓝色,中间显示百分比数字。
统计卡片
四个统计卡片分别展示:
- 测验次数:累计完成的测验次数
- 平均得分:所有测验的平均分数
- 连续天数:连续学习的天数
- 学习科目:当前学习的科目
卡片采用2x2网格布局,使用FlexAlign.SpaceBetween实现均匀分布。每个卡片宽度为48%,通过padding和borderRadius营造卡片效果。
智能学习建议
根据当前学习进度,系统动态生成鼓励性建议:
- 未生成计划:提示用户先生成学习计划
- 进度0%:鼓励用户从第一个任务开始
- 进度1-29%:肯定用户的开始,建议养成习惯
- 进度30-59%:建议定期回顾和测验
- 进度60-89%:鼓励攻克薄弱环节
- 进度90-100%:恭喜完成,建议挑战更高难度
这种渐进式的鼓励机制参考了游戏化设计理论,通过正向反馈维持用户的学习动力。
AI集成方案
LLM API预留设计
代码中预留了完整的LLM API调用模块,使用OpenAI GPT-4作为示例。该模块目前处于注释状态,开发者只需:
- 在
module.json5中配置网络权限:"requestPermissions": [{"name": "ohos.permission.INTERNET"}] - 取消注释LLM API调用代码
- 替换
YOUR_KEY为实际的API密钥
注释代码结构
/*
* import http from '@ohos.net.http';
* async function callLLM(prompt: string): Promise<string> {
* const req = http.createHttp();
* const resp = await req.request('https://api.openai.com/v1/chat/completions', {
* method: http.RequestMethod.POST,
* header: {
* 'Content-Type': 'application/json',
* 'Authorization': 'Bearer YOUR_KEY'
* },
* extraData: JSON.stringify({
* model: 'gpt-4',
* messages: [{ role: 'user', content: prompt }]
* })
* });
* req.destroy();
* return resp.result as string;
* }
*/
AI增强计划
激活LLM API后,可以实现以下增强功能:
- 根据用户学习历史生成更个性化的学习计划
- 动态生成测验题目,无限扩展题库
- 智能分析用户薄弱环节,针对性推荐复习内容
- 自然语言交互,用户可以用日常语言描述学习需求
- 学习内容摘要生成,帮助用户快速回顾
离线与在线结合策略
应用采用离线为主、在线增强的设计策略。核心功能(学习计划生成、测验、进度追踪)完全在离线环境下运行,确保用户在任何网络条件下都能正常使用。AI功能作为可选增强,在用户有网络连接时提供更智能的体验。这种策略在鸿蒙NEXT强调的"分布式能力"和"离线优先"之间取得了平衡。
设计决策与权衡
单文件架构 vs 多文件架构
决策:采用单文件架构,所有代码集中在Index.ets中。
理由:
- 应用规模较小(<500行),单文件更易维护
- 减少文件间跳转,提高代码审查效率
- 降低项目配置复杂度
- 符合鸿蒙NEXT快速原型开发的最佳实践
权衡:当应用规模增长到1000行以上时,应拆分为多个模块文件。
离线引擎 vs 云端AI
决策:核心学习计划生成使用离线规则引擎,AI能力作为可选增强。
理由:
- 离线引擎响应即时,无网络延迟
- 不依赖外部服务,降低使用门槛
- 保护用户隐私,数据不出设备
- AI增强作为可选功能,不强制要求网络
权衡:离线引擎的智能化程度有限,生成的计划不如AI个性化。未来可以通过AI增强弥补这一不足。
@State vs 其他状态管理
决策:仅使用@State进行状态管理,不使用@Prop、@Link等。
理由:
- 遵循ArkTS最佳实践,保持代码简洁
- 单组件架构下无需跨组件通信
- 降低学习曲线,便于团队协作
权衡:在复杂多组件场景下,需要引入状态管理方案。
接口定义 vs 内联类型
决策:所有数据类型使用interface显式定义,禁止使用any。
理由:
- 编译期类型检查,减少运行时错误
- 提供完整的IDE智能提示
- 作为代码文档,提高可读性
- 符合ArkTS语言规范
权衡:增加了代码量,但带来的工程收益远大于成本。
深度拷贝 vs 直接修改
决策:使用JSON序列化/反序列化进行深度拷贝后再修改状态。
理由:
- 确保@State检测到引用变化
- 避免意外的副作用
- 简单可靠,适合小数据量场景
权衡:对于大数据量场景,JSON序列化可能成为性能瓶颈,需要改用浅拷贝或不可变数据结构。
开发环境搭建与项目配置
鸿蒙NEXT开发环境
开始鸿蒙NEXT开发前,需要搭建完整的开发环境。以下是环境搭建的关键步骤:
- 安装DevEco Studio:鸿蒙NEXT官方IDE,基于IntelliJ IDEA深度定制,内置ArkTS编译器、ArkUI预览器、调试工具和性能分析器。建议从华为开发者联盟官网下载最新版本。
- 配置SDK:在DevEco Studio中配置鸿蒙NEXT SDK,选择API 24版本。SDK包含了完整的ArkTS标准库、ArkUI组件库和系统API。
- 创建项目:选择Empty Ability模板,语言选择ArkTS,API版本选择24。DevEco Studio会自动生成项目结构,包括
entry/src/main/ets/目录、module.json5配置文件等。 - 配置权限:在
module.json5中添加网络权限配置,为后续的LLM API集成做好准备。
项目配置文件详解
module.json5是鸿蒙NEXT应用的模块配置文件,用于声明应用的基本信息、权限和能力。以下是本应用需要的核心配置:
{
"module": {
"name": "entry",
"type": "entry",
"description": "AI学习助手",
"mainElement": "Index",
"requestPermissions": [
{
"name": "ohos.permission.INTERNET",
"reason": "需要网络权限用于LLM API调用",
"usedScene": {
"abilities": ["EntryAbility"],
"when": "inuse"
}
}
]
}
}
网络权限的配置遵循最小权限原则,仅在需要使用AI功能时才请求网络权限。在实际发布时,建议在应用描述中说明网络权限的用途,以符合应用商店的审核要求。
本地调试技巧
在DevEco Studio中,可以使用以下调试技巧提高开发效率:
- 预览器(Previewer):在编辑ArkTS代码时,右侧的预览器可以实时预览UI效果,无需启动模拟器。预览器支持多种设备尺寸和分辨率,帮助开发者快速验证UI适配。
- 热重载(Hot Reload):修改代码后,应用可以在不重启的情况下更新UI,保留当前的状态和数据,大幅提升开发效率。
- 日志调试:使用
hilog命令行工具查看应用日志,过滤特定标签的日志输出,快速定位问题。 - 性能分析器:DevEco Studio内置的性能分析器可以监控应用的CPU使用率、内存占用、帧率等指标,帮助发现性能瓶颈。
ArkTS与TypeScript的深度对比
共性与差异
ArkTS在TypeScript基础上进行了裁剪和增强,两者之间的关系类似于Swift和Objective-C的关系。了解二者的差异对于从TypeScript迁移到ArkTS的开发者至关重要。
| 特性 | TypeScript | ArkTS | 说明 |
|---|---|---|---|
| 接口定义 | 支持 | 支持 | 二者语法基本一致 |
any类型 |
支持 | 不支持 | ArkTS要求所有类型明确 |
| 解构赋值 | 支持 | 不支持 | ArkTS禁止此语法 |
@State |
不支持 | 支持 | ArkTS独有UI状态管理 |
@Component |
不支持 | 支持 | ArkTS独有组件装饰器 |
| 泛型 | 支持 | 有限支持 | ArkTS泛型能力受限 |
| 枚举 | 支持 | 支持 | 语法基本一致 |
| 异步编程 | async/await | async/await | 语法一致,但API不同 |
| DOM操作 | 可通过框架 | 不支持 | ArkTS无DOM概念 |
| 模块系统 | ES Module | ES Module | 导入导出语法一致 |
为什么ArkTS禁止any类型
any类型是TypeScript中常用的逃生舱,允许开发者绕过类型检查。但在ArkTS中,这一特性被完全禁止,原因如下:
- 性能优化:明确的类型允许ArkTS编译器进行更激进的优化,包括AOT(Ahead of Time)编译和类型特化,从而提升运行时性能。
- 安全性:禁止
any消除了类型相关的运行时错误,提升了应用的稳定性和安全性。 - 代码质量:强制类型定义提高了代码的可读性和可维护性,降低了团队协作的沟通成本。
- IDE支持:明确的类型让IDE能够提供更精准的代码补全、重构和错误提示。
为什么禁止解构赋值
解构赋值(Destructuring Assignment)是JavaScript/TypeScript中常用的语法糖,但在ArkTS中被禁止。原因包括:
- 编译优化:解构赋值在运行时需要额外的逻辑来处理,禁止后可以简化编译器的优化路径。
- 代码清晰度:显式的属性访问比解构赋值更直观,属性来源一目了然。
- 性能考虑:避免了解构过程中的临时对象创建,减少了垃圾回收压力。
替代方案是使用显式的属性访问:
// 禁止的写法(解构赋值)
// const { name, icon } = subject;
// 推荐的写法(显式属性访问)
const name: string = subject.name;
const icon: string = subject.icon;
迁移策略
从TypeScript项目迁移到ArkTS时,建议采用以下策略:
- 首先移除所有
any类型,为每个变量和函数参数添加明确的类型注解 - 将所有解构赋值替换为显式属性访问
- 检查并调整泛型使用,确保符合ArkTS的泛型约束
- 将React/Vue的组件模型迁移到ArkTS的@Component模型
- 使用@State替代useState等状态管理Hook
- 将JSX/HTML模板语法迁移到ArkUI的声明式UI语法
鸿蒙NEXT生态与前景展望
鸿蒙NEXT的核心优势
鸿蒙NEXT(HarmonyOS NEXT)作为华为全栈自研的操作系统,在多个维度展现出独特的竞争优势:
- 全场景分布式:鸿蒙NEXT的分布式软总线技术支持设备间的无缝协同。手机、平板、PC、手表、车机等设备可以实现硬件互助、资源共享。对于学习助手类应用,这意味着用户可以在手机上开始学习,在平板上继续,在PC上完成复杂的练习。
- 原生性能:鸿蒙NEXT不再兼容Android应用,所有应用都使用ArkTS/ArkUI原生开发。这种"纯血鸿蒙"的策略虽然短期内面临应用生态的挑战,但长期来看能够提供更优的性能和用户体验。
- 安全隐私:鸿蒙NEXT采用了全新的安全架构,包括内核级安全防护、数据分级保护、隐私沙箱等机制。用户的敏感数据(如学习记录、测验成绩)在设备本地处理,仅在使用AI功能时才可选择性地共享数据。
- 开发者体验:ArkTS语言和ArkUI框架提供了现代化的开发体验,声明式UI、响应式状态管理、热重载等特性大幅提升了开发效率。
鸿蒙PC的机遇与挑战
鸿蒙PC是鸿蒙生态向桌面端延伸的重要一步。对于学习助手类应用,鸿蒙PC带来了独特的机遇:
- 大屏体验:PC端的大屏幕可以展示更丰富的学习内容,如并排显示学习计划和测验界面,或同时展示知识点思维导图和详细笔记。
- 键鼠交互:PC端的键鼠操作适合需要大量输入的学习场景,如编程练习、写作训练等。
- 多窗口支持:PC端的多窗口能力允许用户同时打开多个学习工具,如一边查看学习资料一边做笔记。
- 离线能力:PC端的存储和计算能力更强,可以本地运行更复杂的AI模型,实现真正的离线AI学习助手。
然而,鸿蒙PC也面临挑战:应用生态的丰富度、与Windows/macOS的竞争、用户习惯的培养等。开发者需要针对PC端重新设计UI交互,充分利用大屏幕和多窗口的优势。
鸿蒙Flutter框架的定位
在鸿蒙生态中,Flutter通过"鸿蒙Flutter框架"实现了对鸿蒙平台的支持。对于已有Flutter项目的团队,这是一个快速迁移到鸿蒙平台的路径。然而,对于新项目,建议优先考虑ArkTS原生开发,原因如下:
- 原生性能:ArkTS应用直接编译为鸿蒙原生代码,性能优于Flutter的跨平台渲染方案。
- API完整性:ArkTS可以访问鸿蒙NEXT的全部系统API,而Flutter需要通过Platform Channel桥接,可能存在功能限制。
- 生态一致性:ArkTS应用遵循鸿蒙设计语言,与系统UI风格一致,用户体验更好。
- 长期维护:ArkTS是鸿蒙的一等公民语言,会得到华为最优先的技术支持和更新。
对于学习助手这类应用,选择ArkTS而非Flutter能够获得更好的性能、更完整的系统能力接入和更原生的用户体验。
性能优化实践
列表渲染优化
在AI学习助手中,学习计划包含多个学习日和任务,当计划天数较多时(如高级难度10天),列表渲染可能成为性能瓶颈。ArkTS的ForEach提供了高效的列表渲染机制:
- 键值生成器:为每个列表项提供唯一键值,帮助ArkUI框架识别哪些项发生了变化,避免不必要的重新渲染。
- 懒加载:Scroll组件配合ForEach实现按需渲染,只渲染可视区域内的列表项,而不是一次性渲染所有项。
- 避免内联对象:在ForEach的回调函数中,避免创建新的内联对象(如新的样式对象),而是使用预定义的常量或.Builder函数。
状态更新优化
@State的更新粒度是组件级别,优化状态更新可以显著提升性能:
- 批量更新:将多个状态更新合并为一次操作。例如,在测验完成时同时更新
qResult和progress,而不是分别更新。 - 避免不必要的深度拷贝:只在需要触发UI更新的场景使用深度拷贝,其他场景可以直接修改对象的属性。
- 状态扁平化:将深层嵌套的状态拆分为多个扁平的状态变量,减少状态更新时需要复制的数据量。
内存管理
鸿蒙NEXT的ArkTS运行时使用自动垃圾回收(GC),但开发者仍需注意内存管理:
- 避免内存泄漏:及时清理不再使用的定时器、事件监听器和网络请求。
- 控制数据规模:对于学习计划这类数据,保持在合理的大小范围内。如果未来支持更长的学习周期(如30天、60天),建议使用分页加载。
- 使用const声明常量:对于不变的数据(如知识点列表、题库),使用const声明而非let,让编译器进行更激进的内存优化。
未来路线图
短期(1-3个月)
- 数据持久化:使用鸿蒙NEXT的关系型数据库(RelationalStore)实现学习数据的持久化存储,支持跨会话的学习进度追踪。
- LLM集成激活:接入大语言模型API,实现智能学习计划生成和动态测验题目生成。
- 通知提醒:集成鸿蒙NEXT的通知服务,定时提醒用户完成学习任务。
- 学习日历:增加日历视图,以日历形式展示学习计划,方便用户直观了解学习进度。
中期(3-6个月)
- 社交学习:增加学习小组功能,支持多人协作学习,互相监督和鼓励。
- 学习数据分析:基于用户学习数据生成学习报告,分析学习效率和知识掌握情况。
- 多端同步:利用鸿蒙NEXT的分布式能力,实现手机、平板、PC之间的学习数据无缝同步。
- 语音交互:集成鸿蒙NEXT的语音识别能力,支持语音输入学习内容和语音播报学习材料。
长期(6-12个月)
- 自适应学习路径:基于机器学习算法,根据用户的学习表现动态调整学习路径和难度。
- AR学习辅助:利用鸿蒙NEXT的AR能力,在真实环境中叠加学习内容,如物理实验模拟、化学分子结构展示等。
- 开放内容平台:建立学习内容开放平台,允许教育机构和教师上传自定义学习材料和测验题目。
- 鸿蒙PC适配:针对鸿蒙PC平台进行UI适配,充分利用大屏幕的显示优势,提供更丰富的学习体验。
结语
AI学习助手作为一个完整的鸿蒙NEXT应用案例,展示了ArkTS语言在移动端开发中的强大能力。从严格的类型系统到声明式UI,从离线规则引擎到AI集成预留,从数据模型设计到可视化展示,覆盖了鸿蒙NEXT应用开发的方方面面。
本文不仅介绍了代码实现,更深入探讨了设计决策背后的思考。每一个技术选择都是在特定约束下的权衡结果,理解这些权衡比记住代码本身更有价值。
鸿蒙NEXT生态正在快速发展,作为开发者,掌握ArkTS和ArkUI的核心概念,理解鸿蒙设计语言的原则,将帮助你在这个新平台上构建出优秀的应用。希望本文能为你的鸿蒙NEXT开发之旅提供有价值的参考。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐
 0
0 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)