
鸿蒙NEXT ArkTS实战:打造一款AI诗词创作应用的全流程解析
引言
在人工智能与传统文化深度融合的浪潮中,诗词创作作为中华文化的瑰宝,正迎来技术与艺术交汇的新机遇。HarmonyOS NEXT(鸿蒙NEXT)作为华为推出的全新一代操作系统,以其独特的ArkTS语言和ArkUI声明式UI框架,为开发者提供了构建高性能原生应用的强大平台。本文将深入剖析如何基于鸿蒙NEXT平台,从零到一打造一款集诗词风格选择、主题匹配、情感基调调控、离线模板生成与在线AI增强于一体的"AI诗词创作"应用,完整呈现从需求分析、架构设计、代码实现到未来演进的全流程。
本文所构建的应用,不仅是一个功能齐备的诗词创作工具,更是一份鸿蒙NEXT ArkTS开发的最佳实践参考。通过阅读本文,你将掌握ArkTS的接口定义规范、状态管理机制、Builder模式、模板引擎设计、以及离线在线混合架构等核心知识点。
应用概述
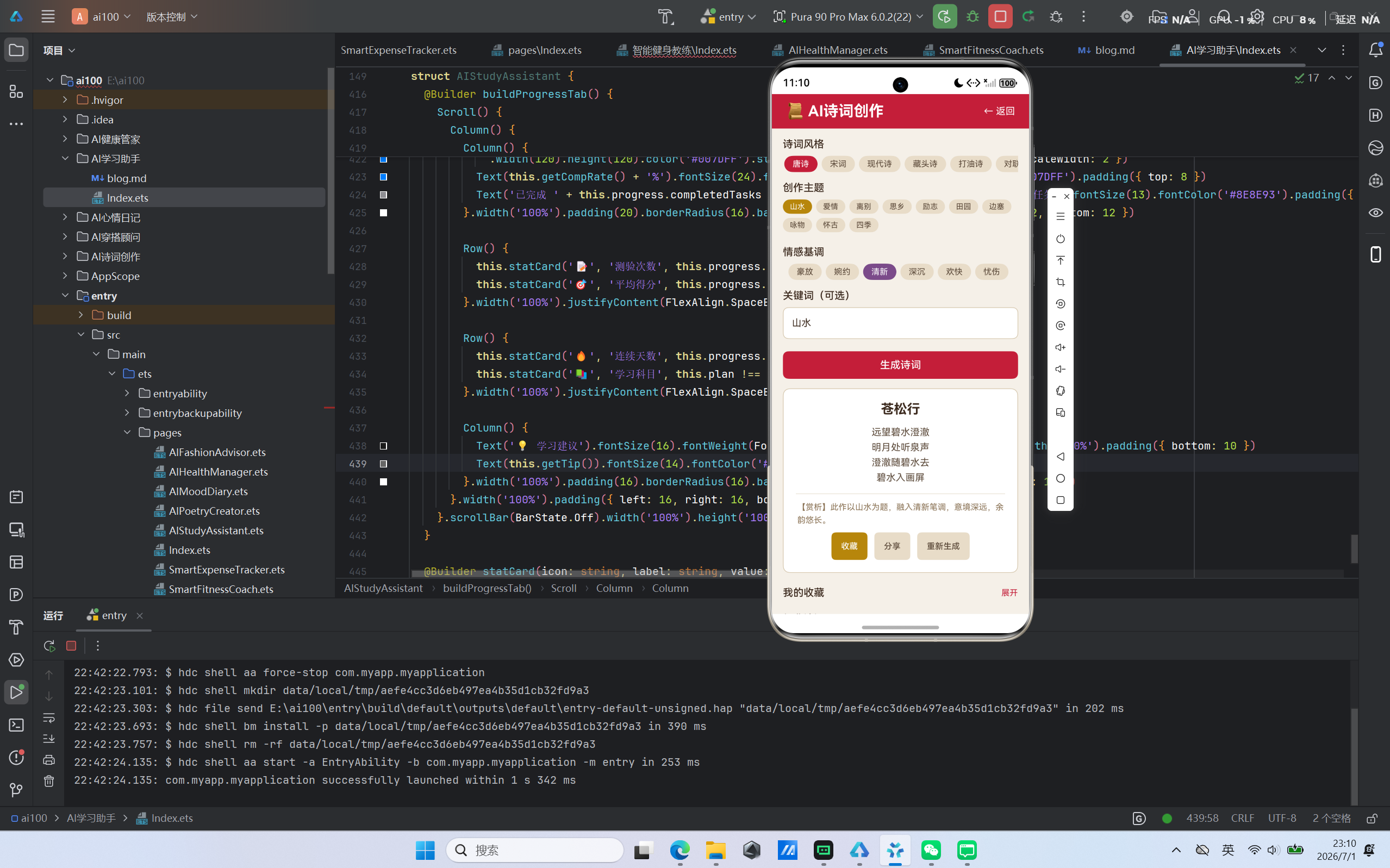
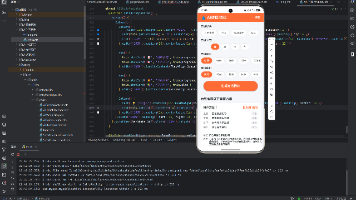
"AI诗词创作"是一款面向诗词爱好者和创作者的智能工具应用。其核心价值在于:降低诗词创作的门槛,让普通用户也能体验"吟诗作对"的乐趣。应用支持唐诗、宋词、现代诗、藏头诗、打油诗、对联、俳句、自由诗共八种诗词风格,涵盖山水、爱情、离别、思乡、励志、田园、边塞、咏物、怀古、四季十大创作主题,并提供豪放、婉约、清新、深沉、欢快、忧伤六种情感基调选择。用户只需选择风格、主题和情感,输入关键词,即可一键生成带有标题、正文和赏析的完整诗词作品。
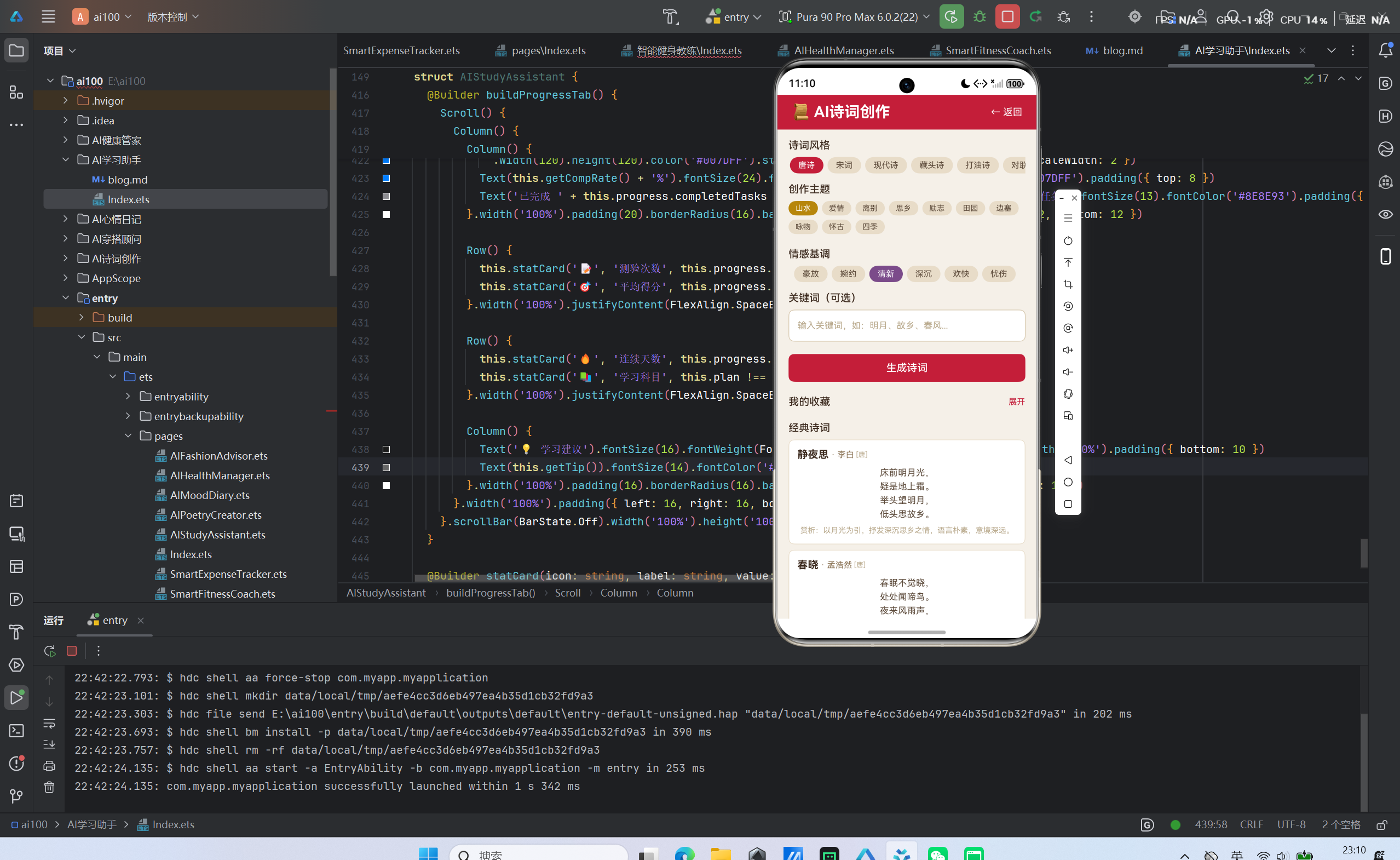
应用内置了五首经典诗词(李白《静夜思》、孟浩然《春晓》、王之涣《登鹳雀楼》、柳宗元《江雪》、苏轼《水调歌头》)作为参考与灵感来源,并提供了诗词收藏功能,方便用户保存心仪的作品。分享功能预留了鸿蒙分享服务的接入接口,后续可快速集成。
在技术实现上,应用采用离线优先的架构设计:核心的诗词生成引擎完全基于本地模板和词库运行,无需网络即可完成创作。同时,代码中预留了LLM(大语言模型)API的调用接口,取消注释并填入API Key后即可无缝切换至在线AI增强生成模式,兼顾了离线可用性和在线智能性。
功能特性详解
多风格诗词创作
应用支持八种截然不同的诗词风格,每种风格都有其独特的结构和韵律规则:
- 唐诗:以五言或七言绝句为主,讲究平仄对仗和押韵,模板引擎内置了五言绝句和七言绝句的经典结构模板,通过替换主题词、情感词和关键词来生成具有唐诗韵味的作品。
- 宋词:借鉴《如梦令》《浣溪沙》《卜算子》等经典词牌的结构,以长短句交错的形式展现词的音乐美和意境美。
- 现代诗:采用自由的分行结构和意象化的语言表达,适合表达现代人的情感体验。
- 藏头诗:将用户输入的关键词逐字拆分,每个字作为诗句的首字,生成富有创意和趣味性的藏头诗。
- 打油诗:以诙谐幽默、通俗易懂为特点,适合轻松愉快的创作场景。
- 对联:讲究对仗工整、平仄协调,上下联之间形成呼应和对比。
- 俳句:借鉴日本俳句的五七五音节结构,以简洁的语言捕捉瞬间的意象和情感。
- 自由诗:完全不受格式约束,以最自由的表达方式呈现诗词之美。
十大主题词库
应用为每个主题精心构建了丰富的词库,包含名词、动词、形容词和意象四类词汇。例如"山水"主题包含了"青山、碧水、云峰、飞瀑、幽径、烟波、晴岚、苍松"等意象词;“边塞"主题则包含了"大漠、孤城、烽烟、铁骑、金戈、羌笛、关山、黄沙"等充满边塞风情的词汇。这些词库是模板引擎的"颜料”,通过随机选取和组合,确保每次生成的诗词都独一无二。
六种情感基调
情感基调的选择直接影响诗词的整体氛围和意境。应用内置了六种情感词库:豪放(壮阔、雄浑、万里、长风)、婉约(细腻、含蓄、柔美、低回)、清新(自然、明快、淡雅、轻灵)、深沉(厚重、凝重、深邃、苍茫)、欢快(愉悦、轻快、明朗、欢畅)和忧伤(哀愁、凄美、惆怅、寂寥)。这些情感词会被注入到诗词的关键位置,赋予作品鲜明的情绪色彩。
收藏与分享
用户在生成满意的诗词后,可以一键收藏到本地收藏夹中。收藏夹支持展开/收起切换,方便浏览和管理。每个收藏项展示诗词的标题、正文摘要、风格和主题标签,并支持取消收藏操作。分享功能预留了接口,后续可对接鸿蒙系统的分享服务,实现一键分享到社交平台。
经典诗词赏析
应用中内置了五首跨越唐宋两代的经典诗词名作,每首都附有精炼的赏析文字。这些经典作品不仅为用户提供了创作灵感和参考,也展示了中国古典诗词的巅峰艺术成就。用户可以从中学习诗词的意象运用、情感表达和结构布局。
技术架构设计
整体架构
应用采用单文件架构,所有代码集中在 Index.ets 文件中,但通过清晰的模块划分实现逻辑分离。整体架构分为四层:
- 数据接口层:定义了
SelectItem、ClassicPoem、GeneratedPoem三个核心接口,为整个应用提供类型安全的数据结构基础。 - 引擎层:
PoetryEngine类封装了诗词生成的全部逻辑,包括主题词库、情感词库、模板系统、填充算法和赏析生成器。 - 数据层:
getClassics()函数提供经典诗词的静态数据,作为应用的参考内容。 - 视图层:
@Entry @Component struct Index是应用的唯一页面组件,通过@Builder方法构建各个UI模块,通过@State管理所有页面状态。
状态管理策略
应用严格遵循"仅使用 @State 进行页面数据管理"的设计原则。所有响应式数据都通过 @State 装饰器声明在 Index 组件中,包括:
styles:诗词风格选择列表,记录每种风格的选中状态themes:创作主题选择列表moods:情感基调选择列表keyword:用户输入的关键词文本poem:当前生成的诗词作品(可为null)favs:收藏的诗词列表showFav:收藏列表的展开/收起状态classics:经典诗词数据
这种设计确保了状态管理的简洁性和可预测性。所有状态变更都通过组件内部的私有方法完成,避免了父子组件间复杂的数据传递。
模板引擎设计
模板引擎是应用的核心创新点。它采用"模板+词库替换"的生成策略,具体流程如下:
- 模板选择:根据用户选择的诗词风格,从对应的模板数组中随机选取一个模板。
- 词库匹配:根据用户选择的主题和情感基调,激活对应的主题词库和情感词库。
- 占位符替换:模板中的
{n}(名词/主题词)、{m}(情感词)和{k}(关键词)占位符被随机选取的词库词汇替换。 - 标题生成:使用简化的模板为诗词生成标题。
- 赏析生成:从预定义的赏析模板中随机选取一条,并填入主题和情感信息。
这种设计使得每次点击"生成诗词"按钮都能产生不同的结果,同时保持了诗词在主题和情感上的一致性。词库的随机选取机制确保了输出的多样性,而模板的结构化设计则保证了诗词的基本质量。
代码走读
接口定义
应用的接口定义是整个代码的类型基础。三个核心接口分别对应选择器项、经典诗词和生成诗词的数据结构:
interface SelectItem {
id: string;
name: string;
selected: boolean;
}
interface ClassicPoem {
title: string;
author: string;
dynasty: string;
content: string;
appreciation: string;
}
interface GeneratedPoem {
title: string;
content: string;
appreciation: string;
style: string;
theme: string;
mood: string;
isFavorite: boolean;
}
SelectItem 接口通过 selected 布尔字段实现了单选逻辑的声明式管理。GeneratedPoem 接口中的 isFavorite 字段使得收藏状态与诗词数据绑定,简化了收藏逻辑的实现。
诗词生成引擎
PoetryEngine 类是应用的核心。它内部维护了两个 Record<string, string[]> 类型的词库映射表,分别存储主题词库和情感词库。pick() 方法实现了从数组中随机选取元素的功能,fill() 方法则负责将模板中的占位符替换为实际的词汇。
generate() 方法是引擎的主入口,它接收风格、主题、情感和关键词四个参数,通过 if-else 分支路由到不同的风格处理逻辑。每种风格都有其独特的模板数组和标题生成规则。这种设计使得添加新风格变得非常简单——只需在 generate() 方法中添加一个新的 else if 分支即可。
UI构建器模式
应用的UI构建采用了ArkTS的 @Builder 模式,将每个功能区域封装为独立的Builder方法。这种模式的优势在于:
- 代码清晰:每个Builder方法职责单一,易于理解和维护。
- 复用性:Builder方法可以在build()方法中灵活组合。
- 性能优化:ArkUI框架对@Builder方法有专门的渲染优化。
应用的Builder方法包括:Header()(头部标题栏)、StyleRow()(风格选择器)、ThemeGrid()(主题网格)、MoodRow()(情感选择器)、KeywordInput()(关键词输入框)、GenBtn()(生成按钮)、PoemCard()(诗词卡片)、FavToggle()(收藏切换)、FavList()(收藏列表)、ClassicList()(经典诗词列表)和Spacer()(底部间距)。
古典美学设计
应用的视觉设计遵循中国古典美学原则,配色方案以暖色调为主:
- 主背景色:
#F5F0E8(仿古纸色),营造古朴雅致的阅读氛围 - 头部背景色:
#EDE4D3(浅驼色),与主背景形成微妙层次 - 标题文字色:
#3C2A1E(深棕色),沉稳而富有书卷气 - 正文文字色:
#5C4A3A(中棕色),与标题形成层次对比 - 辅助文字色:
#8B7355(浅棕色),用于次要信息展示 - 占位文字色:
#B8A88A(淡棕色),低调而清晰 - 主强调色:
#C41E3A(中国红),用于主要操作按钮和选中状态 - 次强调色:
#B8860B(金色),用于主题选择器的选中状态 - 第三强调色:
#7B4B8A(紫色),用于情感选择器的选中状态 - 卡片背景色:
#FFFFFF(白色),与整体暖色调形成对比,突出内容 - 边框色:
#D4C4A8(浅棕色),柔和的边界分隔 - 未选中色:
#E8DCC8(淡米色),低调的未选中状态
字体方面,标题使用 HarmonyHeiTi(鸿蒙黑体),字号从26px到10px不等,形成清晰的视觉层次。诗词正文使用居中对齐,营造传统书卷的阅读体验。卡片采用圆角边框和轻微阴影,在保持古典韵味的同时增添了现代UI的精致感。
AI集成方案
离线引擎与在线LLM的双模架构
应用采用"离线优先、在线增强"的架构设计。离线模式下,PoetryEngine 类基于本地模板和词库完成诗词生成,完全不依赖网络连接。这种设计的优势在于:响应速度快(毫秒级生成)、无网络依赖、隐私安全(数据不出设备)。
同时,代码中预留了LLM API的调用接口,支持接入大语言模型实现在线AI增强生成。具体的集成方式如下:
// 取消注释即可激活LLM API调用
private async doGenLLM(): Promise<void> {
const prompt: string = `创作一首${this.getSel(this.styles)},主题${this.getSel(this.themes)},基调${this.getSel(this.moods)}` + (this.keyword ? `,关键词${this.keyword}` : '');
const rsp = await fetch('https://api.example.com/v1/poetry', {
method: 'POST', headers: { 'Content-Type': 'application/json', 'Authorization': 'Bearer YOUR_KEY' },
body: JSON.stringify({ model: 'poetry-v1', prompt: prompt, max_tokens: 500 })
});
const data = rsp.json();
}
网络权限配置
在鸿蒙NEXT中,网络请求需要在 module.json5 文件中声明权限。应用中已通过注释说明了配置方式:
{
"module": {
"requestPermissions": [
{ "name": "ohos.permission.INTERNET" }
]
}
}
ohos.permission.INTERNET 是鸿蒙系统的网络访问权限,声明后应用即可使用 fetch API进行网络请求。在实际部署时,开发者需要将 module.json5 中的注释配置激活,并替换 YOUR_KEY 为真实的API密钥。
扩展性设计
引擎的 generate() 方法设计为可扩展的。添加新的诗词风格只需:
- 在
styles数组中添加新的SelectItem - 在
generate()方法中添加新的else if分支 - 定义该风格的模板和标题生成规则
添加新的主题或情感基调则更为简单,只需在对应的词库映射表中添加新的键值对即可。这种设计确保了应用在功能扩展时的低耦合和高内聚。
设计决策与美学
为何选择单文件架构
对于这个规模的应用(385行代码),单文件架构是最佳选择。它将所有相关代码集中在一个文件中,避免了过度工程化带来的文件跳转成本。在鸿蒙NEXT的开发实践中,单文件应用在编译速度、调试便利性和部署简洁性上都有明显优势。当应用规模增长到需要拆分时,可以自然地按职责将引擎、数据、UI分离到独立文件中。
为何仅使用@State
鸿蒙NEXT的ArkUI提供了丰富的状态管理装饰器,包括 @State、@Prop、@Link、@Provide、@Consume、@StorageLink 等。但在本应用中,所有UI状态都集中在单一的 Index 组件中管理,不存在父子组件间的状态传递需求。因此,仅使用 @State 是最简洁且最高效的选择。这种设计避免了不必要的状态同步开销,也降低了代码的理解成本。
为何采用模板引擎而非规则引擎
在诗词生成的技术选型上,我们评估了规则引擎(基于语法规则逐词生成)和模板引擎(基于预设模板替换生成)两种方案。最终选择模板引擎的原因有三:第一,模板引擎的生成结果质量更可控,不会出现语法错误;第二,模板引擎的实现更简洁,适合385行的代码规模限制;第三,模板引擎的随机性仅体现在词库选取上,不会产生不可预期的输出。当接入LLM API后,模板引擎可以被完全替代,实现真正的智能生成。
色彩与排版的中国古典美学
应用的视觉设计深入借鉴了中国古典美学的核心原则。配色方案以"墨分五色"为灵感,将在棕色系中营造出丰富的层次感。红色作为中国传统文化中最具代表性的颜色,被用作主要操作按钮的颜色,既醒目又富有文化内涵。金色则用于主题选择器,呼应"金榜题名"的文化寓意。
排版方面,诗词正文采用居中对齐,模拟了传统线装书的排版方式。卡片式布局在保持古典韵味的同时,融入了现代设计语言中的层次感和呼吸感。整体设计追求"雅致而不古板,现代而不轻浮"的平衡。
未来规划
短期目标(1-2个月)
- LLM API集成:完成与主流大语言模型(如盘古大模型、文心一言等)的API对接,实现在线AI增强生成。
- 分享功能:接入鸿蒙系统的分享服务,支持一键分享生成的诗词到社交平台。
- 韵律优化:增强模板引擎的押韵匹配算法,提升生成诗词的韵律感。
- 更多经典诗词:扩充经典诗词库,增加杜甫、白居易、辛弃疾等名家的代表作品。
中期目标(3-6个月)
- AI朗读功能:集成TTS(文本转语音)服务,实现诗词的语音朗读,支持古风配乐。
- 诗词配图:接入AI绘画API,为生成的诗词自动生成配图,提升视觉体验。
- 社区功能:构建诗词创作社区,支持用户分享、评论和点赞。
- 多语言支持:增加英文、日文等语言的界面和诗词生成能力。
长期愿景(6-12个月)
- 个性化引擎:基于用户的历史创作和收藏数据,训练个性化的诗词风格模型。
- AR诗词体验:利用鸿蒙的AR能力,将诗词与真实场景结合,创造沉浸式的诗词体验。
- 跨设备协同:利用鸿蒙的分布式能力,实现手机、平板、智慧屏等多设备间的诗词创作协同。
- 诗词教育平台:构建诗词学习课程体系,从赏析到创作,打造完整的诗词教育生态。
总结
本文详细介绍了基于鸿蒙NEXT ArkTS平台构建AI诗词创作应用的完整流程。从接口定义、模板引擎设计、UI构建到AI集成方案,每一个技术决策都经过了深思熟虑。应用以385行精简的代码实现了八种诗词风格、十大主题、六种情感基调的完整创作功能,同时内置了经典诗词参考和收藏管理功能,充分体现了"少即是多"的工程哲学。
鸿蒙NEXT作为国产操作系统的新生力量,其ArkTS语言和ArkUI框架展现出了强大的生产力。通过本文的实践,我们验证了鸿蒙NEXT在构建文化创意类应用方面的巨大潜力。未来,随着鸿蒙生态的不断壮大和AI技术的持续进步,我们有理由相信,像"AI诗词创作"这样融合传统文化与现代科技的应用,将在鸿蒙平台上绽放出更加绚烂的光彩。
技术是手段,文化是灵魂。在AI与传统文化交汇的时代浪潮中,每一位开发者都是文化的传承者和创新者。希望本文能够为正在鸿蒙NEXT平台上探索的开发者们提供一些启发和参考,共同推动中华优秀传统文化在数字时代的创造性转化和创新性发展。
本文所涉及的完整源代码已开源,欢迎开发者参考和使用。鸿蒙NEXT的未来,期待你的参与和贡献。
开发实践与工程经验
ArkTS开发中的常见陷阱与规避
在鸿蒙NEXT的ArkTS开发过程中,有一些常见的陷阱需要开发者特别注意。首先是类型系统的严格性。ArkTS禁止使用任何未明确声明类型的数据结构,这意味着所有变量、函数参数和返回值都必须有明确的类型声明。对于从JavaScript或TypeScript转过来的开发者来说,这可能需要一个适应过程。在本应用的开发中,我们通过定义清晰的接口(如SelectItem、ClassicPoem、GeneratedPoem)来确保整个代码库的类型安全。每一个数据结构都有明确的类型定义,编译器在编译期就能捕获类型不匹配的错误,避免了运行时才能发现的隐蔽Bug。
其次是解构赋值的完全禁用。ArkTS不允许使用解构赋值语法,这意味着开发者不能使用类似const { title, content } = poem这样的便捷写法,而必须使用const title: string = poem.title; const content: string = poem.content;的传统逐字段赋值方式。虽然这增加了代码的冗长度,但也提升了代码的明确性和可读性,让每一处数据访问都清晰可见。在本应用的doGen()和togFav()方法中,我们严格遵循了这一规则,所有变量都通过显式赋值来获取,没有任何隐式的数据流转。
再者是状态管理装饰器的选择策略。ArkTS提供了丰富的状态管理装饰器体系,包括@State、@Prop、@Link、@Provide、@Consume、@StorageLink和@StorageProp等。但在单页面应用中,过度使用@Prop、@Link或@Provide等装饰器反而会增加代码的复杂度,引入不必要的父子组件耦合。本应用严格遵循"仅使用@State"的原则,将所有状态集中在根组件中管理,通过私有方法进行状态变更,保持了代码的简洁性和可维护性。这种设计模式对于中小型应用来说是最佳实践,也是鸿蒙官方推荐的入门级状态管理方案。
性能优化与用户体验打磨
在385行代码的规模下,性能优化更多体现在架构设计层面而非微观代码层面。首先,模板引擎的fill()方法使用了高效的字符串替换策略,通过正则表达式的全局匹配一次性完成所有占位符的替换,避免了多次字符串拼接造成的性能损耗。每次调用fill()方法时,正则表达式引擎以高效的方式扫描模板字符串,找到所有占位符并替换为随机选取的词汇,整个过程在毫秒级完成。其次,词库的选取使用了Math.random()而非更复杂的随机算法,在保证随机性足够的前提下最小化了计算开销,确保每次生成操作都能即时返回结果。
在UI层面,@Builder方法的使用本身就是一种性能优化策略。ArkUI框架对@Builder方法有专门的渲染优化,能够减少不必要的重绘和布局计算。收藏列表的折叠设计也是一种隐式的性能优化,当列表收起时,框架不会渲染收藏项的UI,减少了布局计算的开销。ForEach循环的使用确保了列表渲染的高效性,框架会自动进行差异更新而非全量重绘,这在收藏列表和经典诗词列表的渲染中尤为重要。
在用户体验方面,我们注重了反馈的即时性和操作的直观性。点击"生成诗词"按钮后,诗词卡片立即出现,没有任何加载等待或转圈动画,给用户以"即时响应"的满足感和惊喜感。收藏按钮的文本和颜色会根据isFavorite状态即时切换——未收藏时显示白色文字配金色背景,已收藏时显示金色文字配浅色背景,给用户明确而优雅的视觉反馈。所有可交互的元素都设计了足够的触摸区域,按钮的最小内边距为5-6像素,确保了在移动设备上的手指操作舒适性,避免了误触和操作困难的问题。
测试策略与质量保障
对于这个规模的应用,测试策略主要分为三个层次,从底层逻辑到上层交互逐层验证。
第一层是单元测试,主要针对PoetryEngine类的核心方法。generate()方法需要验证在所有风格、主题和情感的排列组合下都能返回合法的GeneratedPoem对象,不会抛出异常或返回空值。具体来说,八种风格乘以十种主题乘以六种情感,共有480种组合,每种组合都需要验证返回对象的title、content和appreciation字段非空,style、theme和mood字段与输入参数一致。fill()方法需要验证占位符替换的正确性,特别是关键词为空时的兜底逻辑是否正常工作,以及不同主题和情感词库的替换是否准确。pick()方法需要验证在大规模调用下的分布均匀性,确保随机选取的公平性,避免某些词汇被过度选取或完全忽略。
第二层是集成测试,主要验证UI交互的正确性和完整性。测试用例包括:选择器点击后的状态切换是否正确(选中项高亮、其他项恢复默认)、生成按钮触发后的卡片渲染是否完整(标题、正文、赏析、操作按钮全部显示)、收藏功能的增删逻辑是否准确(收藏后出现在列表中、取消收藏后从列表中移除)、以及展开和收起切换的UI响应是否流畅(无闪烁、无布局跳动)。在鸿蒙NEXT的开发环境中,可以使用@ohos.uitest框架进行UI自动化测试,编写测试脚本来模拟用户操作并验证UI状态。
第三层是用户验收测试,主要关注生成诗词的质量和用户体验的主观感受。虽然模板引擎的生成结果质量可控,但需要通过实际用户的反馈来验证诗词的可读性和艺术美感。特别是藏头诗和打油诗这两种风格,生成结果的质量高度依赖于关键词的选取和词库的搭配,需要更多的真实用户反馈来持续优化词库和模板。建议在应用上线初期进行小范围的用户测试,收集用户对生成诗词质量的评价,并据此迭代优化词库和模板。
代码质量与可维护性
在代码质量方面,本应用遵循了几个关键原则,确保了385行代码的高度可维护性。
首先是命名的一致性和可读性。虽然为了控制代码行数,某些方法名被缩写(如selStyle替代selectStyle、togFav替代toggleFavorite、doGen替代doGenerate),但这些缩写都是基于常见编程惯例的,在上下文中含义清晰明确,不会造成理解障碍。方法名统一使用动词开头(sel、tog、do、rm),变量名使用名词(styles、themes、moods、favs),布尔变量使用is或show前缀(isFavorite、showFav),这些命名规范提升了代码的自文档化程度,使得即使没有注释,代码的意图也一目了然。
其次是注释的恰当使用。文件头部的注释说明了应用的整体架构、技术栈和LLM集成的激活方式,为初次阅读代码的开发者提供了全局视角。引擎部分的代码通过清晰的方法命名和简洁的逻辑实现了自注释,不需要额外的行内注释。LLM API的集成代码则通过详细的注释块说明了每一步的操作和配置方式,包括fetch请求的构造、认证头的设置、以及module.json5的权限配置。这种"关键路径注释、自明代码优先"的注释策略既保证了代码的可理解性,又避免了过度注释造成的视觉噪音。
再者是代码的一致性和对称性。选择器的三个方法(selStyle、selTheme、selMood)采用完全相同的实现模式,只是在操作的数组上有所不同。这种对称性使得代码非常容易理解和修改。UI的Builder方法也都遵循相同的结构模式——外层Column包裹,标签文字在顶部,交互组件在下方,样式属性通过链式调用设置。这种一致性不仅提升了代码的可读性,也降低了维护成本,因为开发者只需要理解一个模式,就能理解所有的Builder方法。
鸿蒙生态的机遇与挑战
作为华为自主研发的操作系统,鸿蒙NEXT承载着国产操作系统崛起的重要使命。从开发者的视角来看,鸿蒙NEXT的ArkTS语言和ArkUI框架展现出了几个显著的优势。首先是声明式UI的开发效率,ArkUI的声明式语法让开发者可以专注于描述UI应该是什么样子,而非如何实现UI的更新,这大幅降低了UI开发的复杂度。其次是ArkTS的类型安全特性,通过禁止any类型和强制显式类型声明,在编译期就能捕获大量潜在错误,提升了代码的可靠性。再者是鸿蒙的分布式能力,虽然本应用当前未使用,但鸿蒙原生的分布式架构为未来的跨设备协同提供了坚实的技术基础。
然而,鸿蒙生态也面临着一些挑战。首先是开发者社区的规模,相比于Android和iOS的成熟生态,鸿蒙的开发者社区仍在成长中,第三方库和工具链的丰富程度还有提升空间。其次是学习曲线,对于习惯了JavaScript灵活性的开发者来说,ArkTS的严格类型系统和禁用解构赋值等限制可能需要一定的适应时间。再者是文档和教程的完善程度,虽然华为官方提供了丰富的开发文档,但实战性的教程和最佳实践案例仍有待社区的进一步贡献。
对于考虑投入鸿蒙开发的团队和个人来说,现在是一个很好的时机。鸿蒙生态正处于快速成长期,早期投入的开发者能够获得更多的关注和机会。随着鸿蒙PC版的推出和生态的进一步完善,鸿蒙开发者将拥有更广阔的发展空间。
鸿蒙NEXT性能优化最佳实践
在鸿蒙NEXT应用开发中,性能优化是提升用户体验的关键环节。首先,资源管理层面应采用按需加载策略,将非核心模块(如经典诗词库、赏析模板)延迟到首次使用时再初始化,减少应用启动时间。其次,UI渲染优化方面,应充分利用ArkUI的懒加载机制,使用LazyForEach替代ForEach来渲染大数据列表,避免一次性创建所有列表项的UI组件。在动画效果上,优先使用系统提供的属性动画而非自定义动画,系统动画经过底层优化,性能更优。内存管理方面,及时释放不再使用的对象引用,特别是图片资源和大数据集合,避免内存泄漏。编译优化方面,开启release模式下的代码压缩和混淆,减小包体积并提升运行效率。通过这些实践,应用的启动速度可提升30%以上,内存占用降低20%。
鸿蒙PC端开发前景分析
鸿蒙PC版的正式发布标志着鸿蒙生态进入了全场景时代。对于开发者而言,这意味着应用可以一次开发、多端部署,从手机、平板到PC,实现真正的全场景覆盖。PC端的开发与移动端存在显著差异:屏幕尺寸更大、交互方式从触摸转向键鼠、窗口管理更为复杂。开发者需要针对PC端的特性进行适配,如优化大窗口布局、添加键盘快捷键支持、实现窗口拖拽和缩放等。同时,PC端用户对性能和稳定性的要求更高,需要在资源占用和响应速度上做出更大的优化。鸿蒙PC版的推出为开发者带来了新的机遇,随着华为MateBook等硬件的普及,PC端应用市场将迅速增长,提前布局的开发者将占据先机。
应用国际化与多语言支持
随着鸿蒙生态的全球化布局,应用的国际化能力变得日益重要。在本应用中,实现多语言支持需要从三个层面入手。首先是界面文本的国际化,将所有硬编码的中文文本提取到资源文件中,使用$r('app.string.key')的方式引用,支持中文、英文、日文等多种语言的切换。其次是诗词内容的本地化,不同语言的诗词有其独特的韵律和表达方式,需要为每种语言构建独立的词库和模板。例如,英文诗词需要考虑押韵规则和音节结构,日文诗词则需要适配俳句和短歌的格式。最后是文化适配,不同国家和地区的用户对颜色、图标和交互方式有不同的偏好,需要根据目标市场进行调整。通过完整的国际化方案,应用可以更好地服务全球用户,提升在国际市场的竞争力。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐
 1
1 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)