
FlexRibbon模型性能优化实践
作者:昇腾实战派
知识地图:https://blog.csdn.net/Lumos_Lovegood/article/details/161455142
1. 背景概述
随着深度学习模型复杂度的不断提升,如何在异构计算平台上实现接近主流GPU的推理性能成为开发者面临的重要挑战。
本文以FlexRibbon模型在Atlas 800I A3硬件平台上的性能优化为例,系统介绍了模型完整优化方案。通过组合应用流水线并行、算子优化、内存布局调整等多种技术手段,显著提升了模型在昇腾平台上的执行效率,为同类模型的性能优化提供了可复用的实践经验。
2. 问题描述
在Atlas 800I A3机器上,FlexRibbon模型初始性能未能充分发挥硬件潜力。通过性能剖析发现,模型中存在大量小算子拼接、冗余内存操作和计算流程瓶颈,导致整体计算效率偏低。
3. 优化方案与效果总览
优化方案如下:
- 流水线并行与绑核优化:性能提升10+%
- RotaryEmbedding模块重构:性能提升10+%
- 批处理大小优化:提高显存
- 计算操作优化:优化transpose和mask_fill操作
4. 性能优化实施细节
4.1 流水线并行与CPU绑核
通过启用任务队列和CPU亲和性配置,优化计算资源调度:
export TASK_QUEUE_ENABLE=2
export CPU_AFFINITY_CONF=1
此项优化实现了计算任务的高效调度,减少了线程切换开销。
4.2 RotaryEmbedding模块深度优化
模型中的PairPlainEncoder、DiffusionModule3和AADiffusionModule三个核心模块均依赖RotaryEmbedding计算,该模块成为关键性能瓶颈。
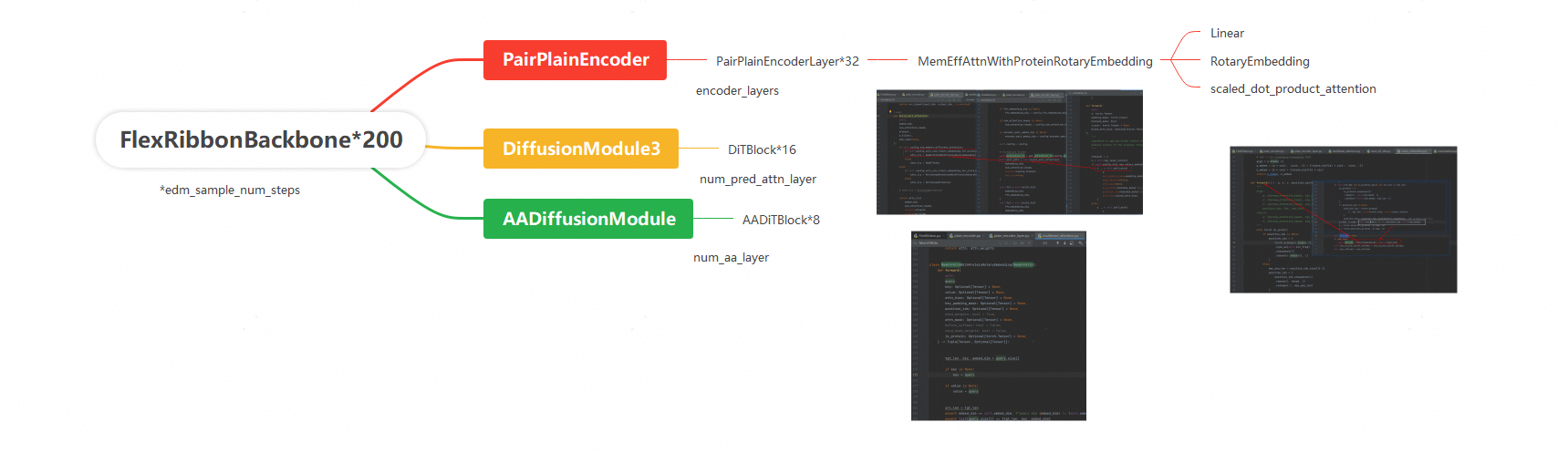
问题分析:原实现中存在大量张量重组操作(view、reshape、repeat等),导致显著的内存搬运开销和空闲等待时间。
优化方案:
4.2.1 npu_rotary_mul算子替换
初始实现中存在大量小算子拼接,计算效率较低。通过以下措施进行优化:
- 去除重复计算操作
- 使用
torch.einsum简化计算逻辑 - 采用
torch_npu.npu_rotary_mul专用算子进行替换
4.2.2 冗余转换消除
通过消除不必要的类型转换和冗余操作,进一步减少计算开销,提升执行效率。
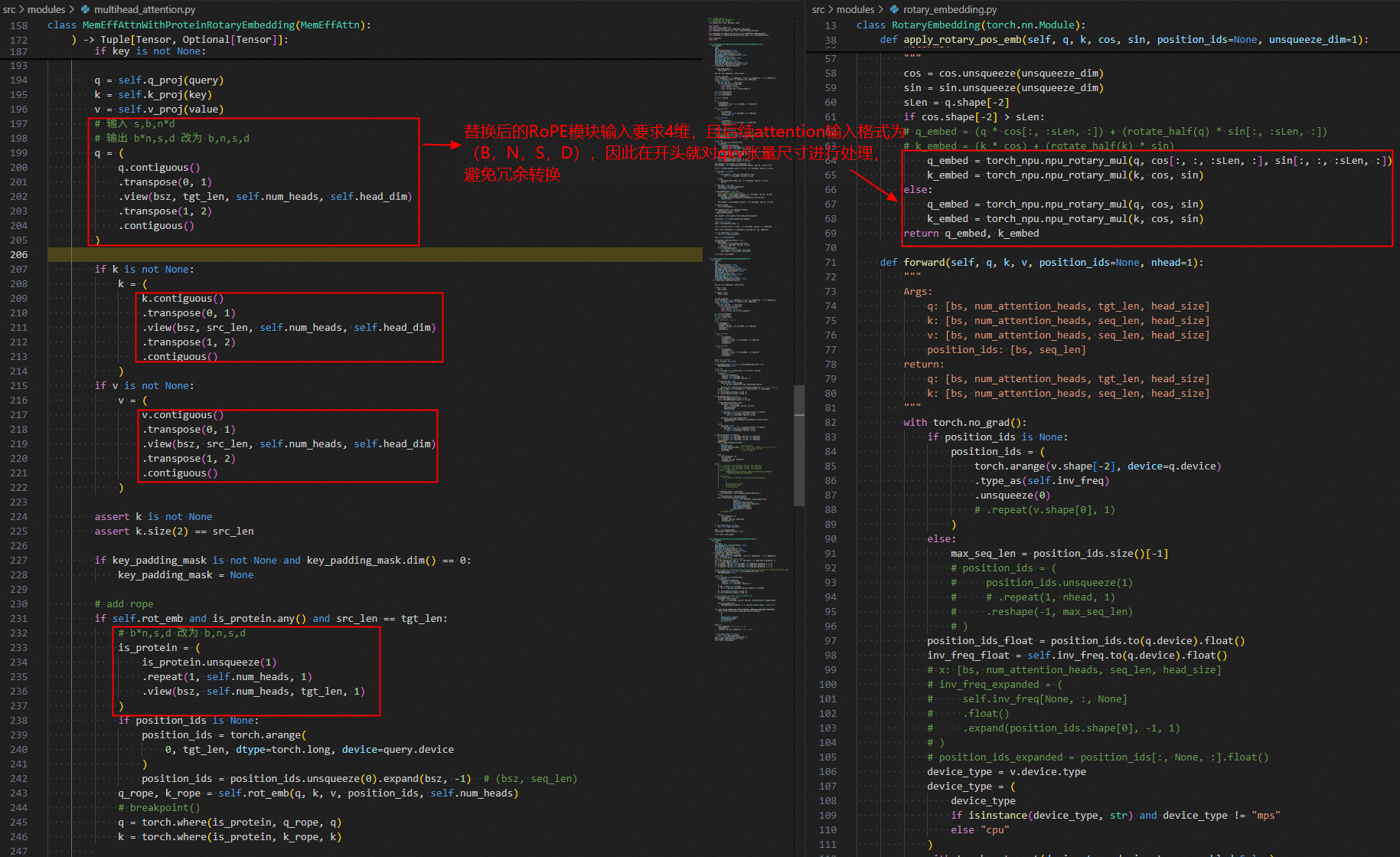
4.3 批处理大小与内存优化
通过调整批处理大小,充分利用显存资源。此优化减少了内存碎片化,提高了计算单元的利用率。
4.4 计算操作优化
最后阶段针对transpose和mask_fill操作进行专项优化:
- 去除冗余的transpose操作,减少不必要的维度变换
- 优化mask_fill实现,提高内存访问效率
这些微调带来了额外的性能提升。
5. 总结
本文详细介绍了FlexRibbon模型在Atlas 800I A3平台上的性能优化实践。通过系统性的分析和针对性的优化措施,极大地提升了模型性能。优化方案涵盖了流水线并行、算子替换、内存布局优化等多个层面,为类似模型在昇腾平台上的性能优化提供了有价值的参考。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐
 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)