
Ankh3-large模型迁移精度问题分析与解决
作者:昇腾实战派
知识地图:https://blog.csdn.net/Lumos_Lovegood/article/details/161455142
1 背景概述
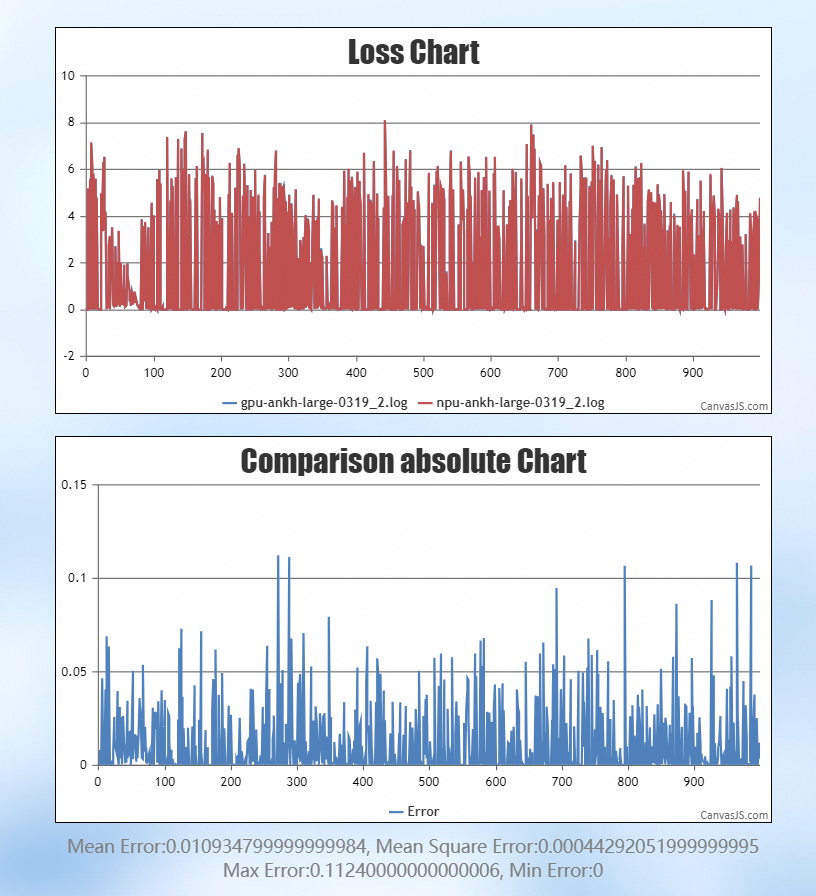
本文以 Ankh3-large 模型为例,介绍了在模型迁移到昇腾平台后训练过程中遇到的 Loss 未能严格对齐的问题分析及解决方法。通过系统性的排查与优化,最终将 Loss 误差控制在合理范围内,并为类似场景下的精度对齐工作提供参考。
硬件:Atlas 800T A2
组件版本信息
- CANN:8.3.RC1
- HDK:25.3.rc1.2
- pytorch:2.7.1
2 问题根因分析
导致 Loss 不一致的主要原因包括:
- 数据处理流程未完全对齐:数据预处理中存在配置不一致,影响了输入数据的格式与内容。
- 硬件计算差异:不同计算硬件(如 NPU 与 GPU)在浮点计算中存在固有误差,属于合理偏差范围。
通过以下措施有效控制了 Loss 误差:
- 对齐数据处理流程中的关键配置;
- 在模型收敛后适当降低学习率,抑制 Loss 波动。
最终 Loss 误差控制在 0.01 以内,符合预期标准,如下图所示:
4 精度问题排查流程
4.1 超参数检查
首先确保训练过程中的关键超参数完全一致,包括 batch size、学习率以及是否启用 Dropout 等。比对结果显示,NPU 和 GPU 的超参数配置一致。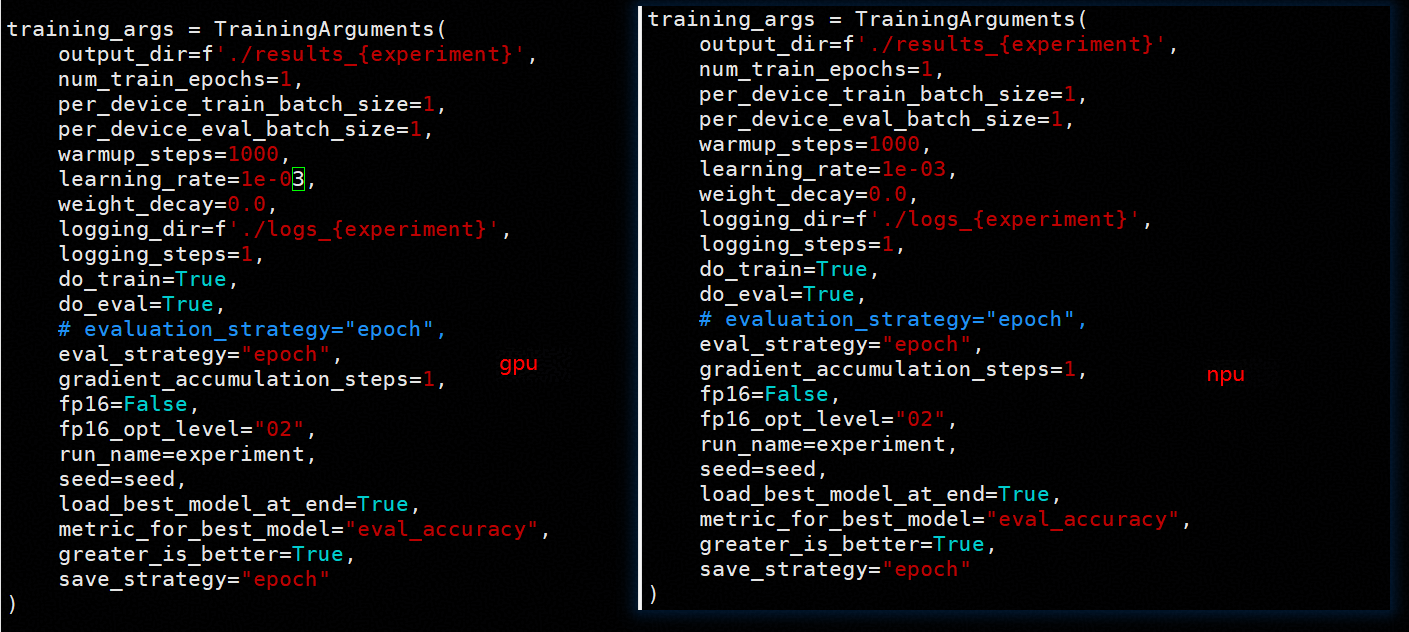
4.2 确定性计算与随机种子固定
为排除随机性影响,我们在训练中启用了确定性计算并固定随机种子:
NPU 设置: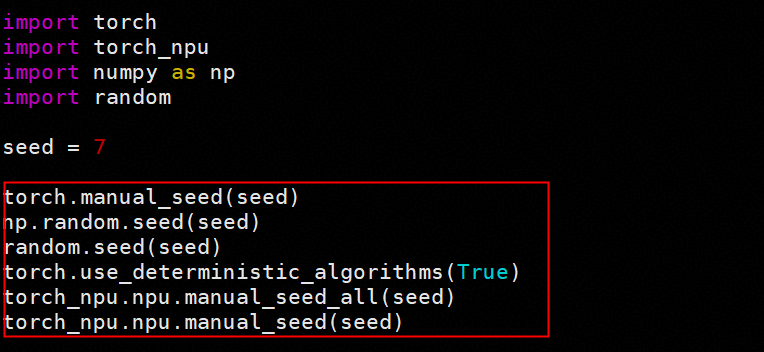
GPU设置: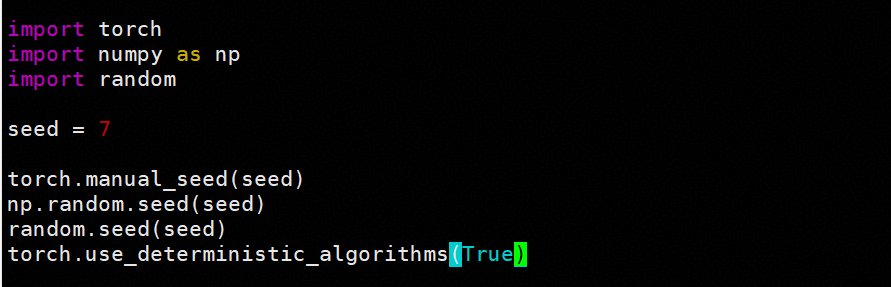
但此时 Loss 仍未完全对齐,说明问题不仅源于随机性。
4.3 输入数据比对
通过在训练代码中插入统计代码,打印输入数据的最大值、最小值及均值,确认输入数据在数值层面已对齐:
输出结果验证数据一致性:
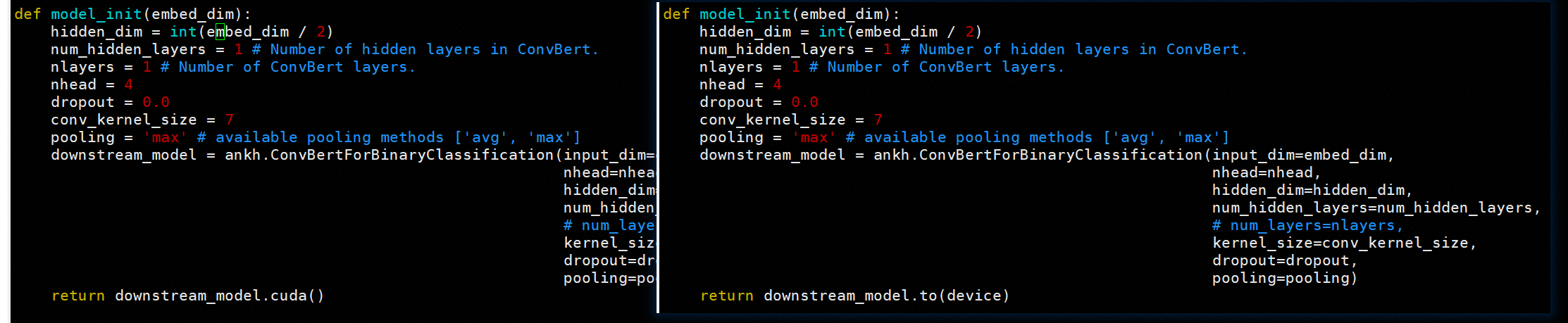
4.4 模型参数检查
人工比对了模型部分参数,确认模型初始化权重一致:
输出结果显示参数一致: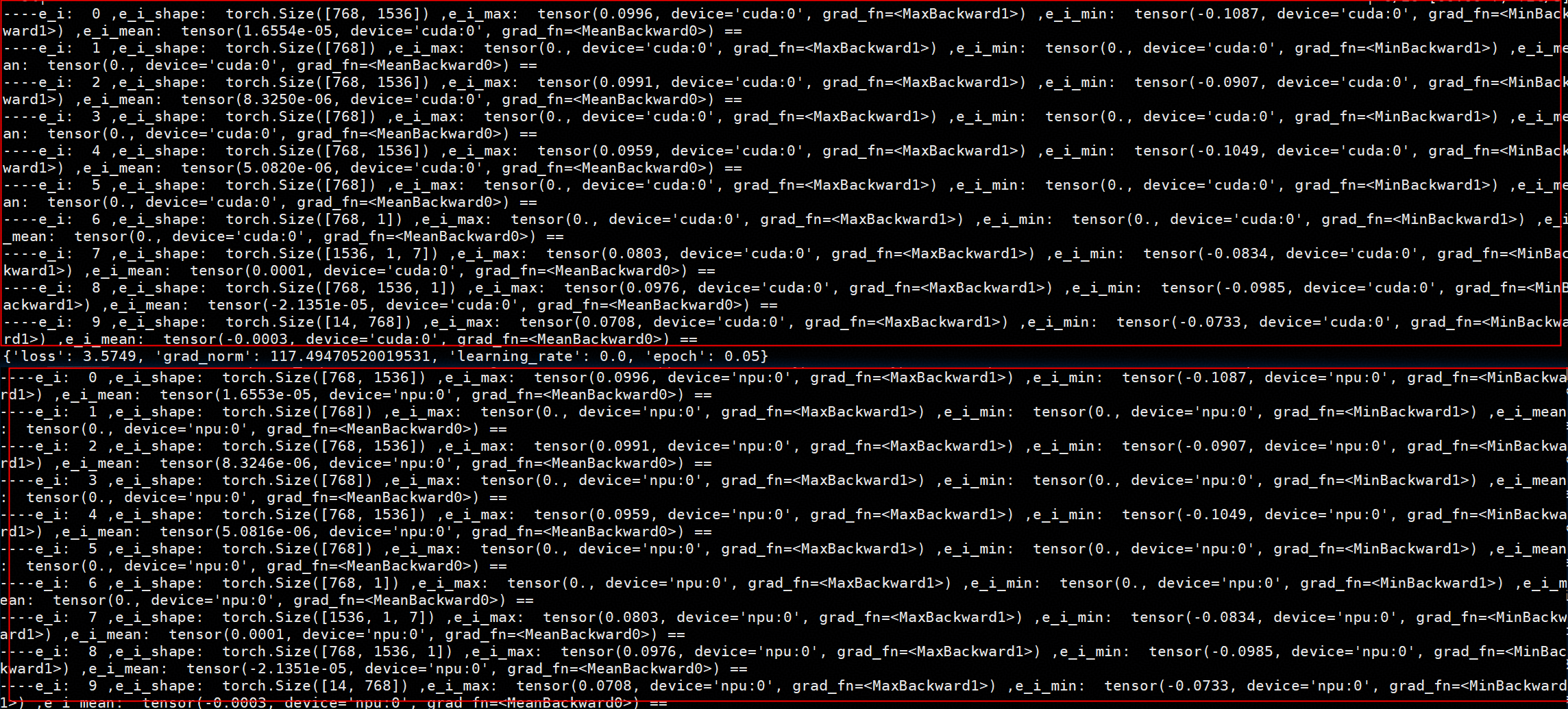
4.5 精度数据采集与对比分析
4.5.1 工具安装与配置
使用 mindstudio-probe 工具进行精度数据采集:
pip install mindstudio-probe --pre
配置统一的 dump 路径,并在训练代码中插入采集代码:
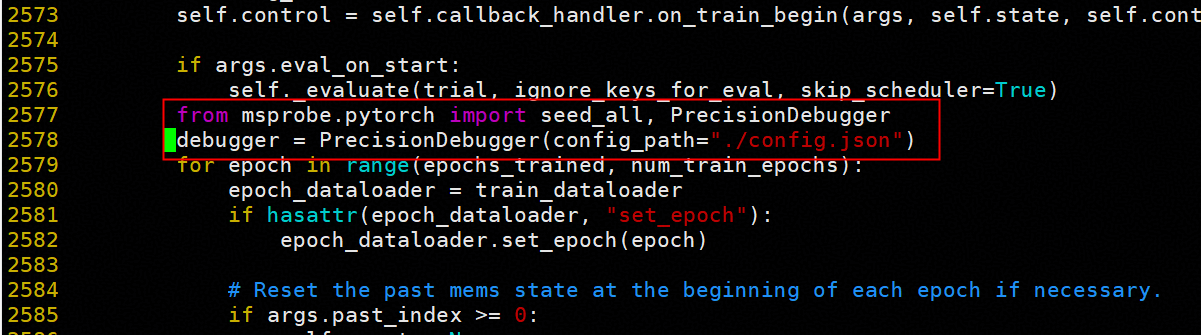
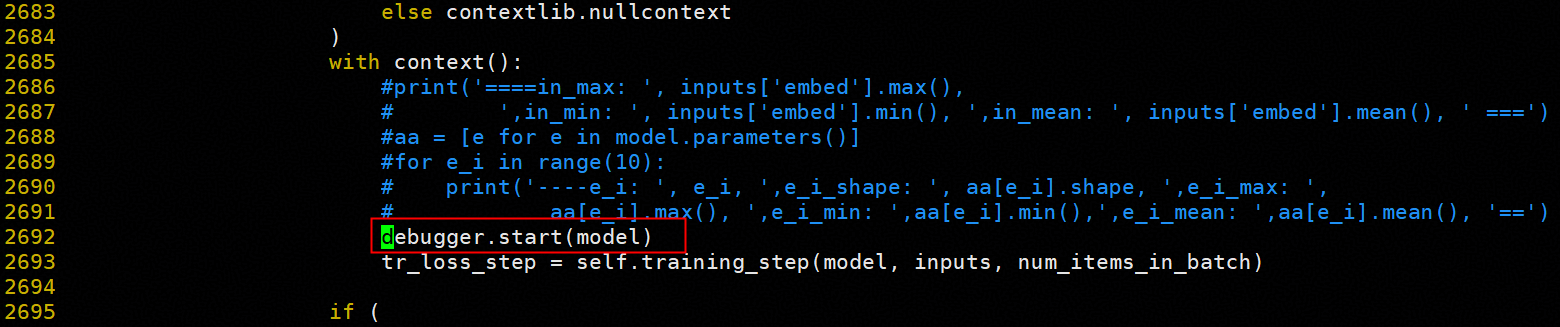
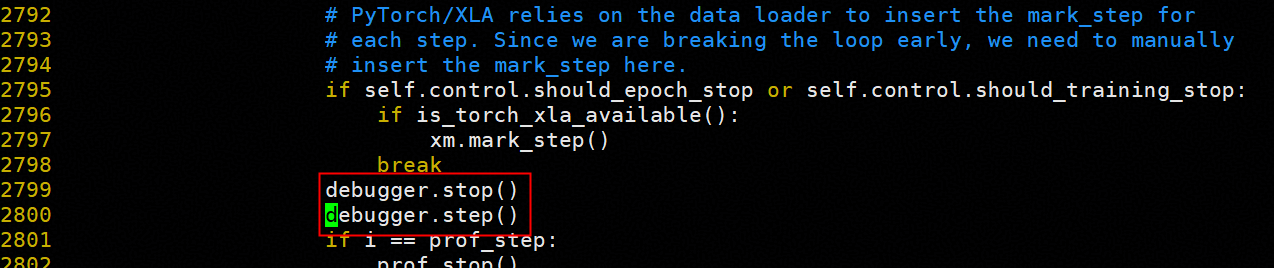
4.5.2 数据对比
运行以下命令进行数据对比:
msprobe compare -tp npu_data_dump_0316/step0/proc135336/dump.json -gp gpu_data_dump_0316/step0/proc1649012/dump.json -o ./dump_output_0316
4.5.3 分析结果
对比结果显示部分算子存在 Shape 不一致问题:
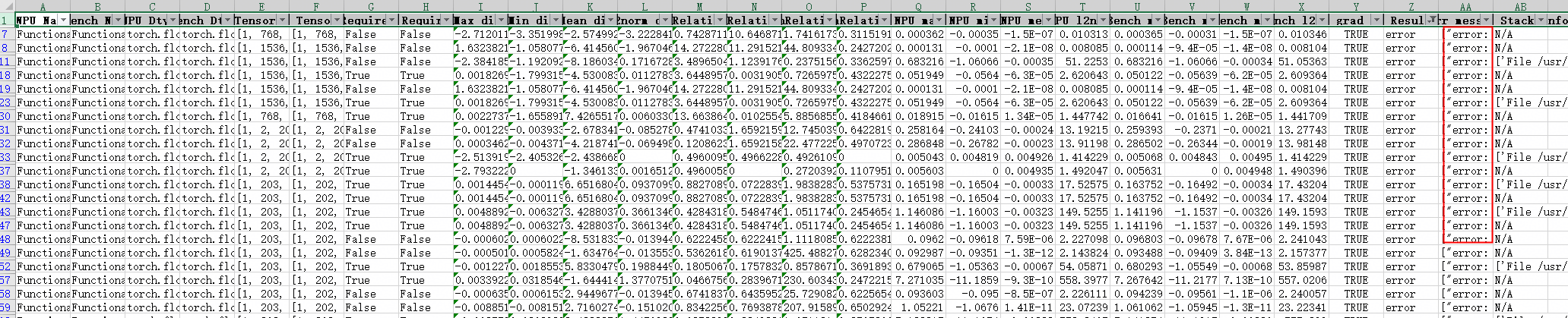
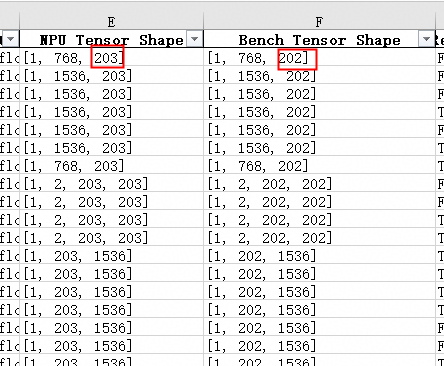
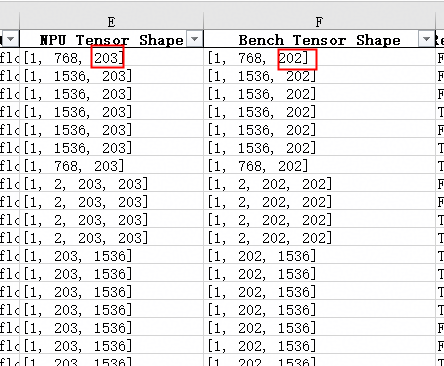
通过调用栈信息定位到数据处理中某一配置项不一致,修正后 Loss 对齐效果改善。
进一步分析发现,输入 Embedding 存在微小差异:
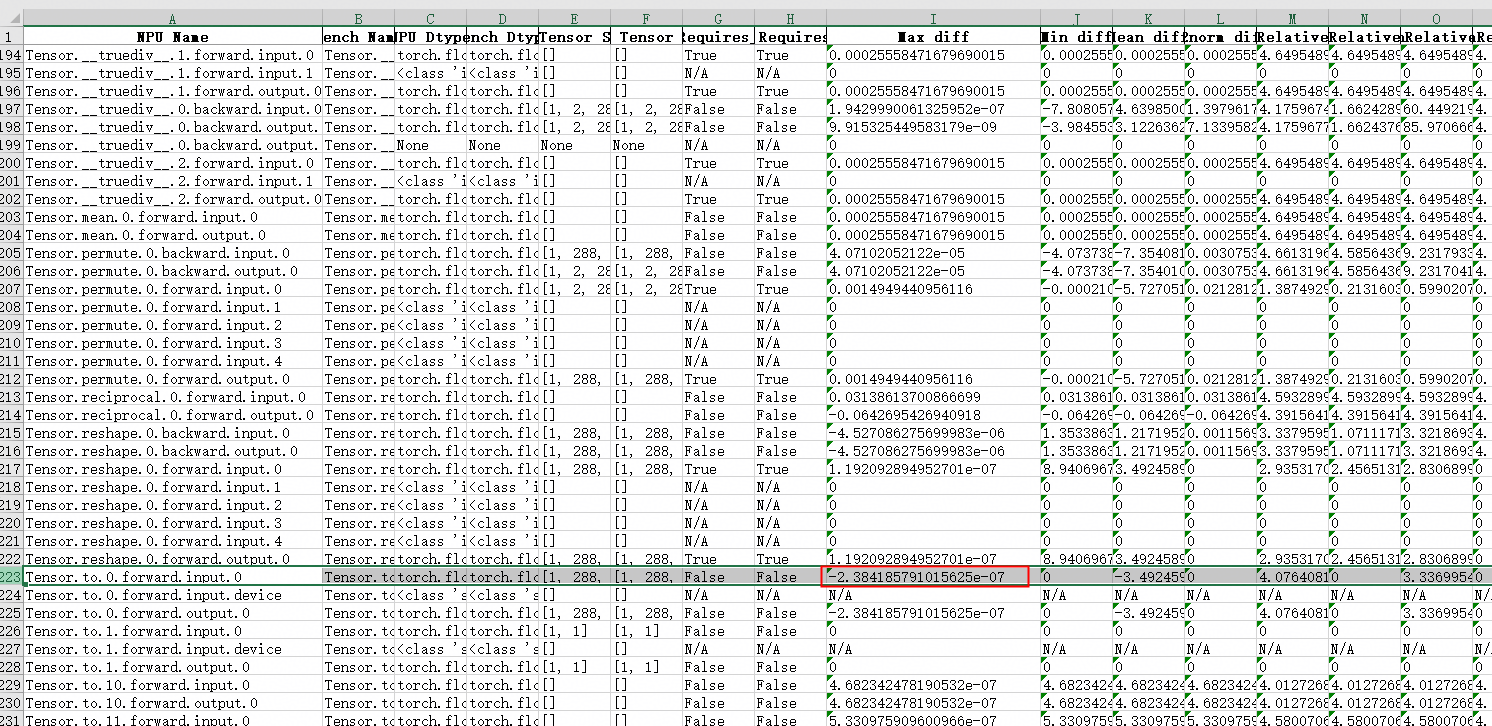
因此采用 NPU 预生成 Embedding 并加载至 GPU 的方式,确保输入严格一致:

最终输入数据实现对齐:
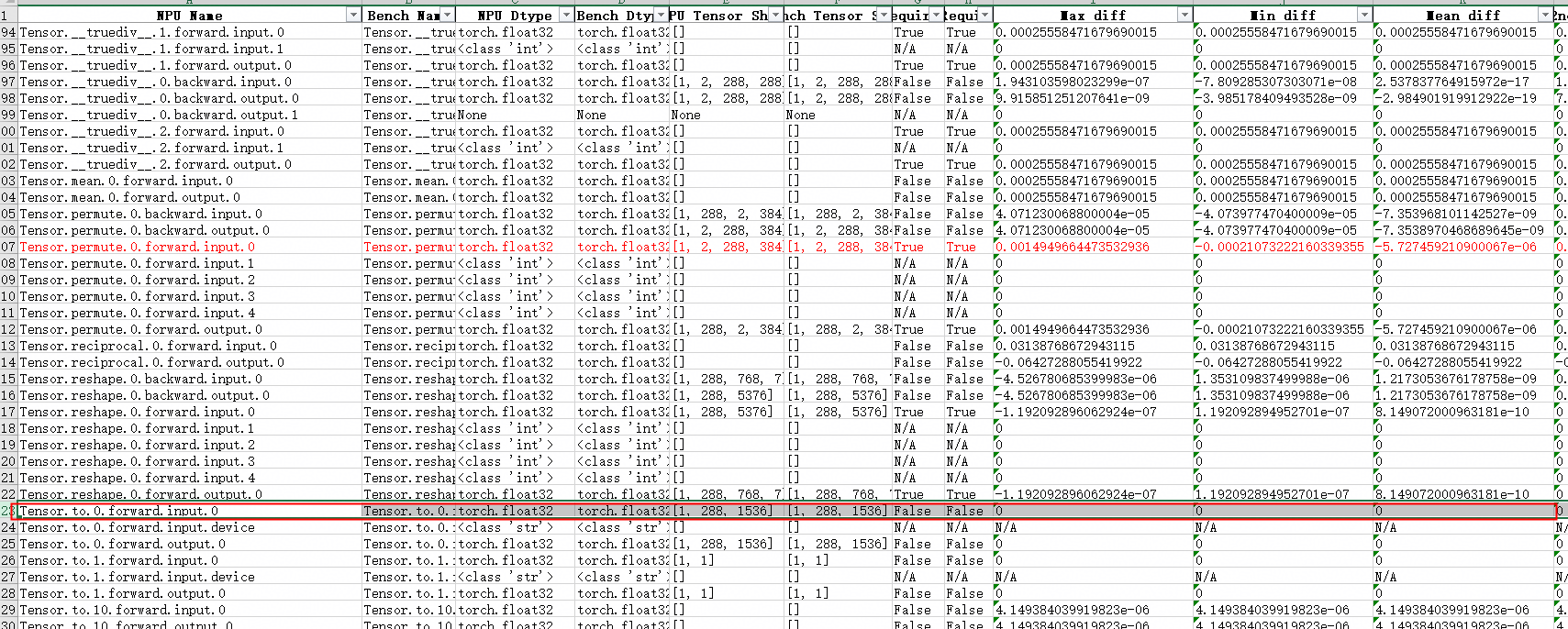
4.6 硬件差异与误差分析
在输入严格一致后,发现 Torch.matmul 算子在 NPU 和 GPU 上的输出仍存在差异:

代码位置:
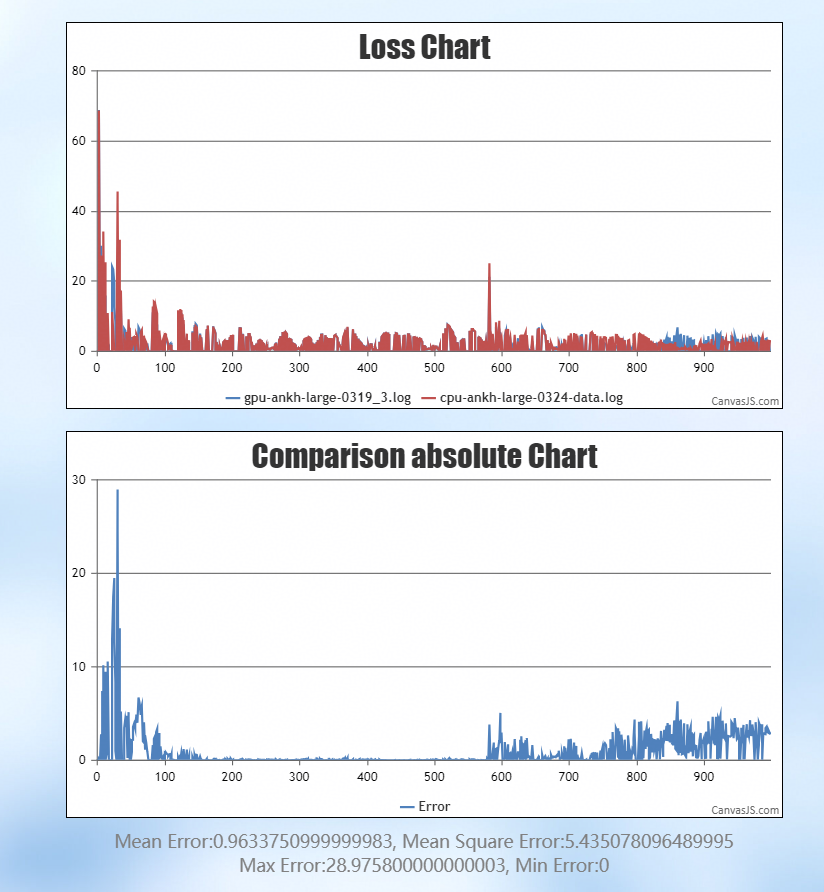
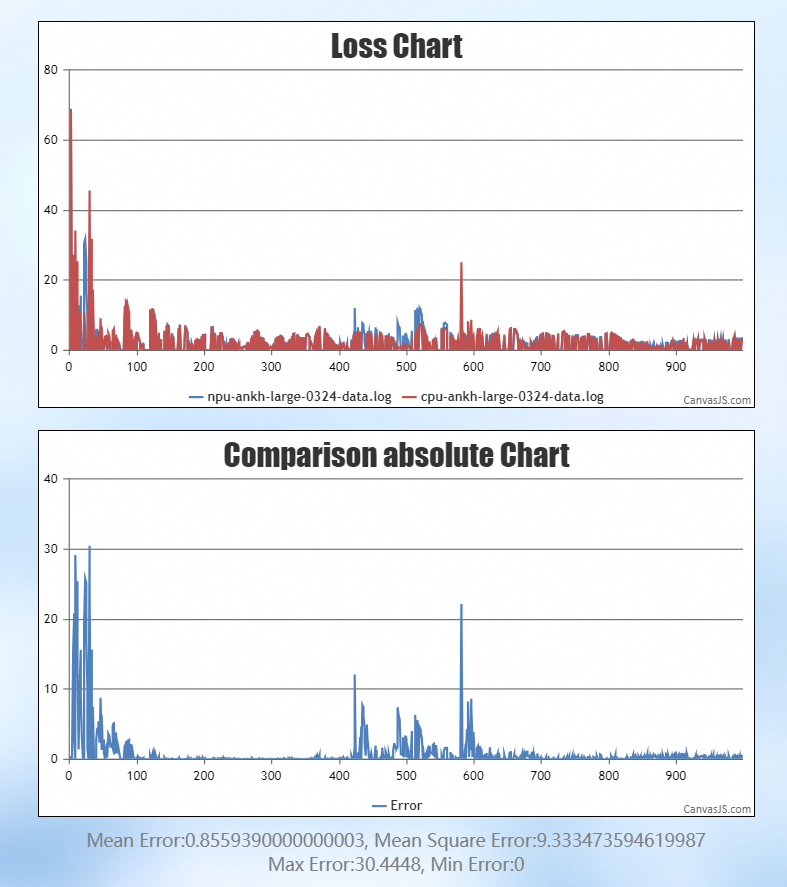
通过双标杆对比(以 CPU 为基准),NPU 与 CPU 的误差为 0.85,GPU 与 CPU 的误差为 0.96,说明 NPU 的整体精度表现优于 GPU:

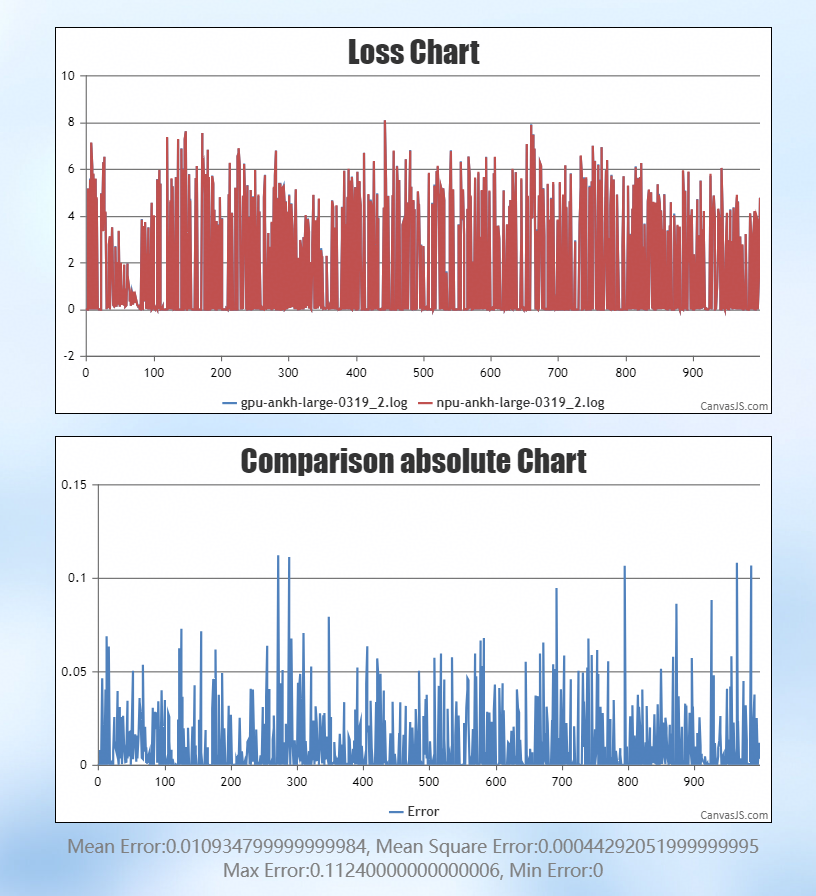
因此,将学习率调小至 e-5 量级,有效控制 Loss 波动,最终误差降至 0.01:
5 总结
本次精度问题排查表明,由于硬件架构差异,NPU 与 GPU 在训练中存在合理范围内的计算误差。通过严格对齐数据预处理、模型参数与输入,并结合学习率调整,可有效控制 Loss 波动,使其收敛趋势一致。该方法可为类似跨平台模型训练任务提供有益借鉴。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐
 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)