
从零打造虚拟小智:用浏览器模拟 IoT 设备的实践之路
- 📢欢迎点赞 :👍 收藏 ⭐留言 📝 如有错误敬请指正,赐人玫瑰,手留余香!
- 📢本文作者:由webmote 原创
- 📢作者格言:2025年,一个巨大的转折点,开启自由职业,技术栈.NET、VUE、嵌入式C、大量低价接私活中,欢迎dddd…
- 📢作者勋章:古法写作非遗继承人、手敲写作非遗传承人
前言
小智 AI 硬件是一款基于 ESP32 的开源语音对话设备,通过 WebSocket /MQTT 与后端 AI 服务实时通信。在调试 WebSocket 协议和 AI 响应的过程中,我们一直有个痛点:每次测试都需要拿着真实硬件,场景受限,效率低下。
于是我开始思考——能不能让浏览器本身成为一台"虚拟小智"?
这篇文章记录了虚拟小智模拟器(SimDevice)从构想到落地的全过程,包括协议分析、音频编解码方案选型、实时通信架构设计,以及在浏览器里"假装"是一台 ESP32 的种种技巧。
在 ASP.NET Core 里写了一个 WebSocket 桥(SimXiaozhi),让浏览器通过它与小智服务器通信;前端用 Web Codecs API 解码 Opus 音频,用 ScriptProcessor 采集麦克风并编码上传,整个链路完全跑在浏览器里,无需任何原生插件。
1、为什么要造这个轮子
小智调试工具的核心场景是"监听真实设备",但开发者在以下场景会遇到麻烦:
- 只有电脑,没带硬件设备
- 想测试 AI 服务是否正常,但不想等设备重启
- 需要批量回归测试某个 TTS 音色或唤醒词识别
- 给非硬件团队的人演示 AI 对话效果
理想状态是:打开一个网页,点击"连接",就能像一台真实小智设备一样与 AI 服务对话——有情感表情变化、有语音识别、有 TTS 播放,还能随时打断。
做完之后发现,这个需求不仅是"调试工具的延伸",本身就是一个完整的产品功能:任何没有购买硬件的用户,都可以通过它体验小智 AI 对话。
2、架构设计:为什么需要服务端桥
最直觉的方案是"浏览器直连小智服务器",但这条路被浏览器的安全策略封死了:小智服务器要求客户端在 HTTP Header 里携带 Device-Id、Client-Id、Authorization 等自定义 Header,而浏览器的 WebSocket API 不允许设置自定义请求 Header。
此外,OTA 接入流程需要先通过 HTTP POST 请求获取 WebSocket 地址和 Token,再用 Token 建立 WebSocket 连接。这些步骤如果放在浏览器里做,会因为 CORS 跨域限制而全部失败。
因此我们设计了一个三层架构:
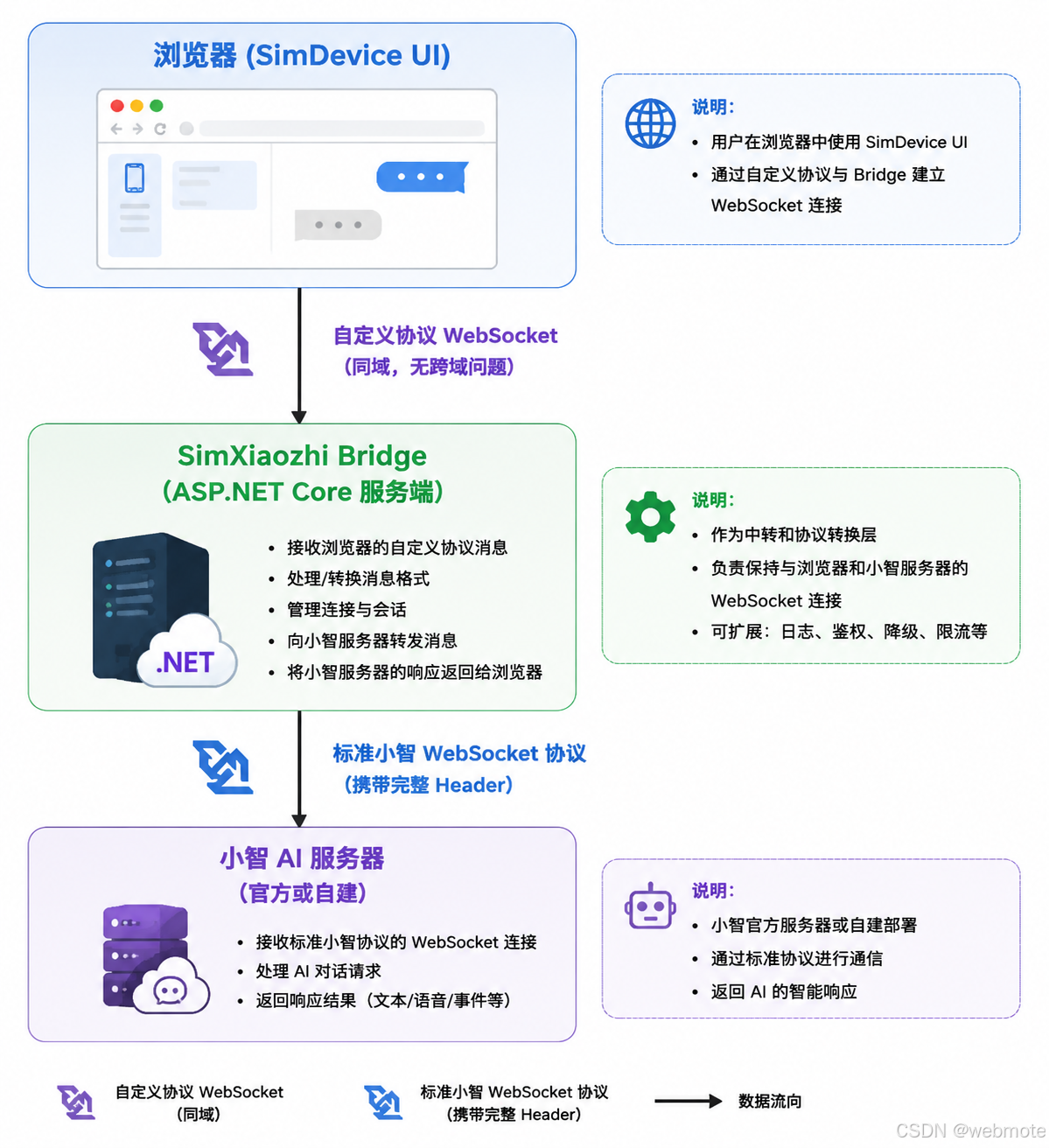
桥接层(SimDeviceBridge)负责:
- 代替浏览器执行 OTA HTTP 请求,携带所有必要 Header
- 用
ClientWebSocket连接到小智服务器 - 在浏览器 WebSocket ↔ 小智 WebSocket 之间转发消息
- 处理激活码轮询、重连逻辑等状态机
| 组件 | 职责 |
|---|---|
| SimDeviceBridge | C# 服务端桥,解决跨域和自定义 Header 问题 |
| ScriptProcessor | 浏览器麦克风采集,PCM → Opus 编码上传 |
| Web Codecs API | 浏览器原生 AudioDecoder,Opus 帧实时解码播放 |
| 21 种情感 GIF | 来自 noto-emoji,由服务器 emotion 字段驱动 |
3、OTA 协议与实现
小智设备上电后第一件事是请求 OTA 接口。通过抓包分析,这个接口是一个 HTTP POST,Request Body 是一个描述设备硬件信息的 JSON,Response 返回 WebSocket 地址和认证 Token。
有意思的地方在于"激活流程":如果设备未绑定用户,OTA 接口会在响应中返回 activation 对象,包含一个 6 位激活码。设备需要展示这个激活码,让用户在 App 里输入,完成绑定。绑定期间需要每隔一段时间轮询 /activate 端点,直到激活成功。
// 轮询激活状态,每 12 秒检查一次,最多 5 次
bool activated = false;
for (int i = 1; i <= 5 && !ct.IsCancellationRequested; i++)
{
await BrSendTextAsync(JsonSerializer.Serialize(new { type = "activating", attempt = i }));
await Task.Delay(12000, ct);
activated = await CheckActivatedAsync(activateUrl, ct);
if (activated) break;
}
if (!activated)
{
// 5 次未激活,重新走 OTA 流程获取新激活码
await BrSendTextAsync("{\"type\":\"retry_ota\"}");
continue;
}
激活码在浏览器端会通过 Web Speech API 语音播报,就像真实硬件一样"说出"激活码:
function speakCode(code) {
if (!window.speechSynthesis || !code) return;
window.speechSynthesis.cancel();
var text = '激活码是 ' + (code + '').split('').join(',');
var utter = new SpeechSynthesisUtterance(text);
utter.lang = 'zh-CN'; utter.rate = 0.75;
window.speechSynthesis.speak(utter);
}
4、音频管道:Opus 上行与下行
小智协议使用 Opus 编码,16kHz 单声道,60ms/帧。这是整个模拟器里技术含量最高的部分。
4.1 上行:麦克风 → Opus → 服务器
浏览器通过 getUserMedia 采集麦克风 PCM,再用 ScriptProcessor(每次 2048 samples)将 Float32 转为 Int16,发送给 Bridge。Bridge 用 Concentus(C# 版 Opus 编码器)将 PCM 帧编码为 Opus 二进制,再通过 WebSocket 发给小智服务器。
scriptProcessor.onaudioprocess = function(ev) {
if (!isCapturing) return;
var f32 = ev.inputBuffer.getChannelData(0);
// Float32 → Int16 PCM
var int16 = new Int16Array(f32.length);
for (var i = 0; i < f32.length; i++)
int16[i] = Math.max(-32768, Math.min(32767, f32[i] * 32768));
wsSend(int16.buffer); // 发给 Bridge,由服务端编码为 Opus
};
服务端积累 PCM 数据,凑满一帧(960 samples = 60ms × 16kHz)再编码:
private byte[] EncodeOneFrame()
{
var samples = new short[UpFrameSamples]; // 960 samples
Buffer.BlockCopy(_pcmBuf, 0, samples, 0, UpFrameSamples * 2);
var outBuf = new byte[1276];
int n = _enc.Encode(samples, 0, UpFrameSamples, outBuf, 0, outBuf.Length);
return outBuf[..n];
}
4.2 下行:Opus 帧 → Web Codecs → 扬声器
早期方案用 Concentus.js(Opus 的 WebAssembly 编译版)在浏览器里解码,但延迟高、内存占用大。后来发现 Chromium 已经原生支持 Web Codecs API(AudioDecoder),可以直接硬件加速解码 Opus,延迟降低了一个数量级。
audioDecoder = new AudioDecoder({
output: function(audioData) {
// 把解码后的 PCM 塞进 Web Audio 调度队列
var buf = playCtx.createBuffer(1, audioData.numberOfFrames, audioData.sampleRate);
var f32 = new Float32Array(audioData.numberOfFrames);
audioData.copyTo(f32, { planeIndex: 0, format: 'f32' });
buf.copyToChannel(f32, 0);
var src = playCtx.createBufferSource();
src.buffer = buf;
src.connect(playGain);
// 精确调度:nextPlayTime 确保帧与帧无缝拼接
var start = Math.max(playCtx.currentTime, nextPlayTime);
src.start(start);
nextPlayTime = start + buf.duration;
audioData.close();
},
error: function(e) { console.warn('AudioDecoder error:', e); }
});
audioDecoder.configure({ codec: 'opus', sampleRate: 24000, numberOfChannels: 1 });
关键细节是 nextPlayTime 调度机制——每帧在上一帧结束时刻入队,避免了帧间空隙和重叠,听感平滑无撕裂。
5、实时模式与 AEC
普通模式下,服务器发 TTS 时,设备端会暂停上传麦克风数据(防止录到扬声器回声)。但真实的语音对话体验应该允许用户随时打断 AI 说话——这需要在 TTS 播放时同时上报麦克风音频,由服务端的 AEC(回声消除)来剔除扬声器输出的部分。
我们用 _listenMode 变量区分两种工作状态:
case "tts":
var ttsState = node?["state"]?.ToString();
// realtime 模式:AEC 已开启,保持上行音频,支持打断检测
if (ttsState == "start" && _listenMode != "realtime")
{
_listening = false; // 非 realtime 才停止上报
_pcmPos = 0;
}
await BrSendTextAsync(json);
break;
前端对应的逻辑:TTS 开始时,realtime 模式不停止采集,TTS 结束后状态从"说话中"恢复到"聆听中"而不是"空闲":
} else if (msg.state === 'stop') {
// realtime 模式 TTS 结束后恢复聆听,否则回空闲
setDeviceState(realtimeActive ? 'listening' : 'idle');
setEmotion(lastLlmEmotion);
if (realtimeActive && !isCapturing) startCapture();
}
6、情感系统:21 种 GIF 动图
小智服务器的 llm 消息里会携带 emotion 字段,例如 "emotion": "thinking"。我们从 noto-emoji 字体库中提取了 21 种情感的 128px GIF 动图,存放在 wwwroot/images/emotions/。
情感图片在 TTS 说话期间保持不变(不切换到"说话"图标),TTS 结束后恢复到最近一次 LLM 情感——这样 AI 在说话时,脸上的表情依然是"高兴"或"思考",而不是一个无聊的扬声器图标。
case 'llm':
if (msg.emotion) {
lastLlmEmotion = msg.emotion; // 保存,TTS 结束后恢复
setEmotion(msg.emotion); // 立即更新图标
}
break;
case 'tts':
if (msg.state === 'start') {
setDeviceState('speaking');
// 注意:不调用 setEmotion,保持 LLM 情感不变
} else if (msg.state === 'stop') {
setEmotion(lastLlmEmotion); // TTS 结束,恢复 LLM 情感
}
setEmotion 的实现只在 src 真正变化时才赋值——避免 GIF 动画因 src 重赋值而重播:
function setEmotion(name) {
var e = emotions[name] || emotions.neutral;
var img = document.getElementById('emotion-icon');
var newSrc = '/images/emotions/' + e.gif + '.gif';
if (img.src !== newSrc) img.src = newSrc; // 只有真正变化才赋值
}
7、唤醒词打断
真实小智设备支持说"你好小智"来打断当前对话。在浏览器里,我们用 Web Speech Recognition API(webkitSpeechRecognition)做实时唤醒词检测,监听到"你好小智"后立即发送 abort 消息并停止 TTS 播放:
wakeRecog.onresult = function(e) {
for (var i = e.resultIndex; i < e.results.length; i++) {
var t = e.results[i][0].transcript;
if (t.indexOf('你好小智') !== -1) {
stopTtsPlayback();
wsSend(JSON.stringify({ type: 'abort', reason: 'wake_word_detected' }));
addSysMsg('检测到唤醒词"你好小智"');
break;
}
}
};
stopTtsPlayback 会关闭 AudioDecoder 并重置 Web Audio 的播放队列,确保 TTS 立即停止,没有残余音。
8、踩过的坑
ScriptProcessor 即将废弃
ScriptProcessor 是旧 API,现代推荐 AudioWorklet。但 AudioWorklet 与主线程通信的序列化开销在低端机上会引入延迟。由于我们只需要 PCM → Bridge 这个单向流,ScriptProcessor 依然是最简单的选择,等 AudioWorklet 的使用成本下降后再迁移。
Web Codecs 的 timestamp 必须严格递增
AudioDecoder.decode() 要求每个 EncodedAudioChunk 的 timestamp 严格递增,单位微秒。我们维护一个 opusTimestampUs,每帧加 frameDurationMs × 1000,解码器关闭重建时必须归零,否则 Chrome 会抛出 EncodingError。
WebSocket 自定义 Header 无解
浏览器的 new WebSocket(url) 不支持设置请求 Header,这是 W3C 规范的刻意限制。网上流传的各种 hack 方案要么只在特定浏览器有效,要么需要 Service Worker 拦截,引入大量复杂度。最终决定用服务端 Bridge 代理,反而让架构更清晰。
GIF 重播问题
同一个 GIF 文件反复赋给 img.src 会导致动画从头开始播放。加一行 if (img.src !== newSrc) 判断即可避免,但要注意浏览器会把相对路径转换成绝对路径存储在 img.src 里,比较时需要用完整 URL 或用 img.getAttribute('src') 获取原始值。我们改用完整路径赋值彻底规避了这个问题。
双重 disconnected 消息
XzReceiveLoopAsync 最初在 Close 帧处理里直接 return,导致 finally 块又发了一次 disconnected,浏览器端触发两次状态重置。修复方法是在 Close 分支去掉主动发送,统一交由 finally 块处理。
9、后续计划
- AudioWorklet 迁移:用 Worklet 替换 ScriptProcessor,降低在移动端的功耗
- 本地 AEC 实现:目前依赖服务端 AEC,如果能在浏览器端完成回声消除,可以进一步降低延迟
- 多语言唤醒词:扩展 Speech Recognition 支持英文和方言
- 调试日志联动:虚拟小智产生的会话自动显示在调试工具日志面板里
- 移动端优化:iOS Safari 的 Web Codecs 支持不完整,需要降级到 Concentus.js 兜底
10、写在最后
整个项目大约花了两周的业余时间,代码量不大,但涉及的技术点异常分散:从 C# Concentus 编码到 Web Codecs 解码,从小智私有协议到 Web Speech Recognition,从 SignalR 到 requestAnimationFrame ticker——每个点都得踩一遍才知道边界在哪里。
最让我满意的一个细节是:当 GIF 表情跟着 AI 的情感变化,说话中依然保持"高兴"而不是一个无聊的扬声器图标的时候,感觉这个"虚拟小智"真的有了一点灵魂。
不过,这个需要用户付费才能体验,不说开发费用,仅仅服务器费用都不容易啊,觉得有用,赞助一下吧。
地址: https://qa360.net
好了,你学废了码?

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)