
DeepSpeed ZeRO-3 源码解析:前向与反向
作者:昇腾实战派 * silas
DeepSpeed ZeRO-3 源码解析:前向与反向
本文介绍DeepSpeed ZeRO-3的HOOK机制与前反向的完整时序,重点解析AllGather的触发时机、梯度桶归约链路以及梯度累积的实现细节。
当前昇腾已适配DeepSpeed开源库:DeepSpeed_NPU-PyTorch-模型库-ModelZoo-昇腾社区
0. 引言
ZeRO-3 对 PyTorch 模型的改造本质上是一套 Hook 系统:在每个模块的前向/反向进出口插入参数 AllGather 与释放逻辑,在每个参数的梯度累积完成后插入归约逻辑,让参数从"常驻 GPU"变成"按需聚合、用完即还"。
这套系统管理两条生命周期:参数的生命周期(模块级 Hook)和梯度的生命周期(参数级 Hook)。本文先给出完整画面,再依次深入每个环节。
1. 完整数据流总览
在深入任何实现细节之前,先建立一张全局地图。
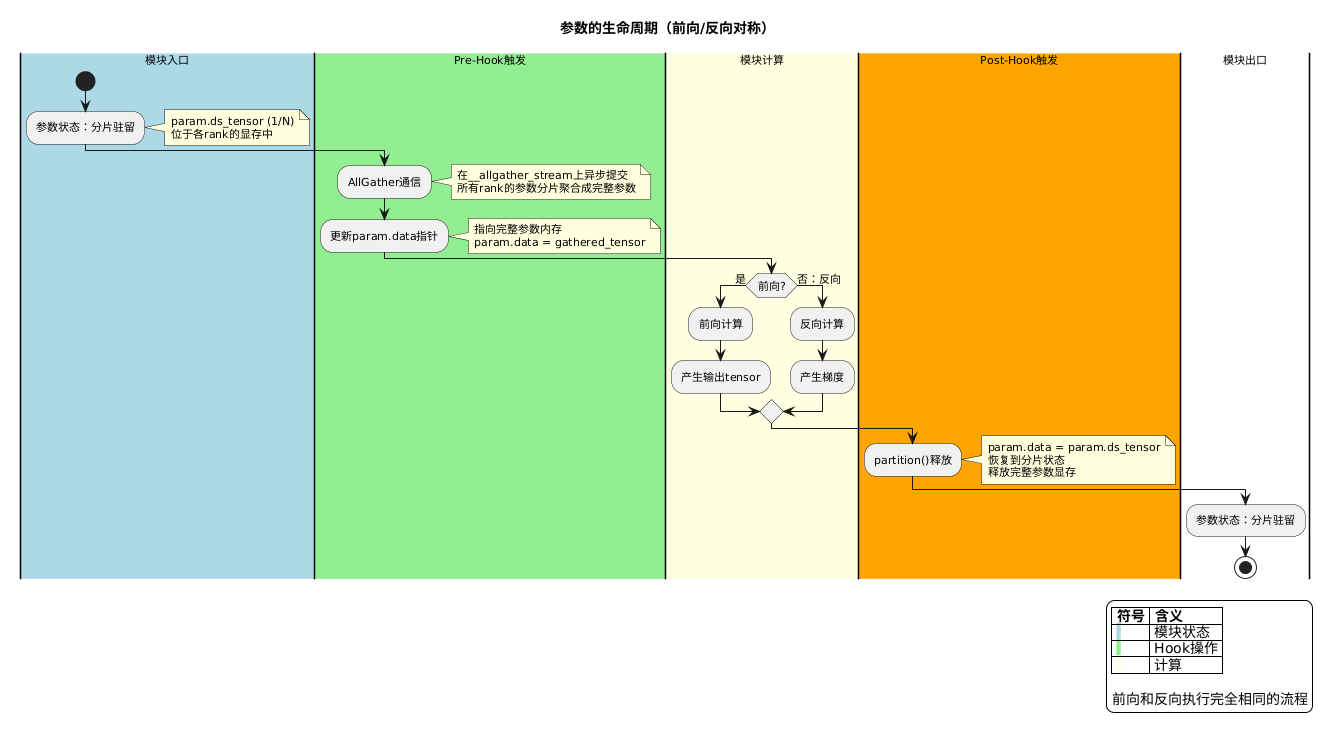
参数的生命周期(每个模块,前向和反向各一次):
分片驻留(ds_tensor,1/N)
↓ Pre-Forward / Pre-Backward
AllGather → 完整参数(param.data)
↓ 模块计算 / 梯度计算
↓ Post-Forward / Post-Backward
partition() → 分片驻留(ds_tensor,1/N)
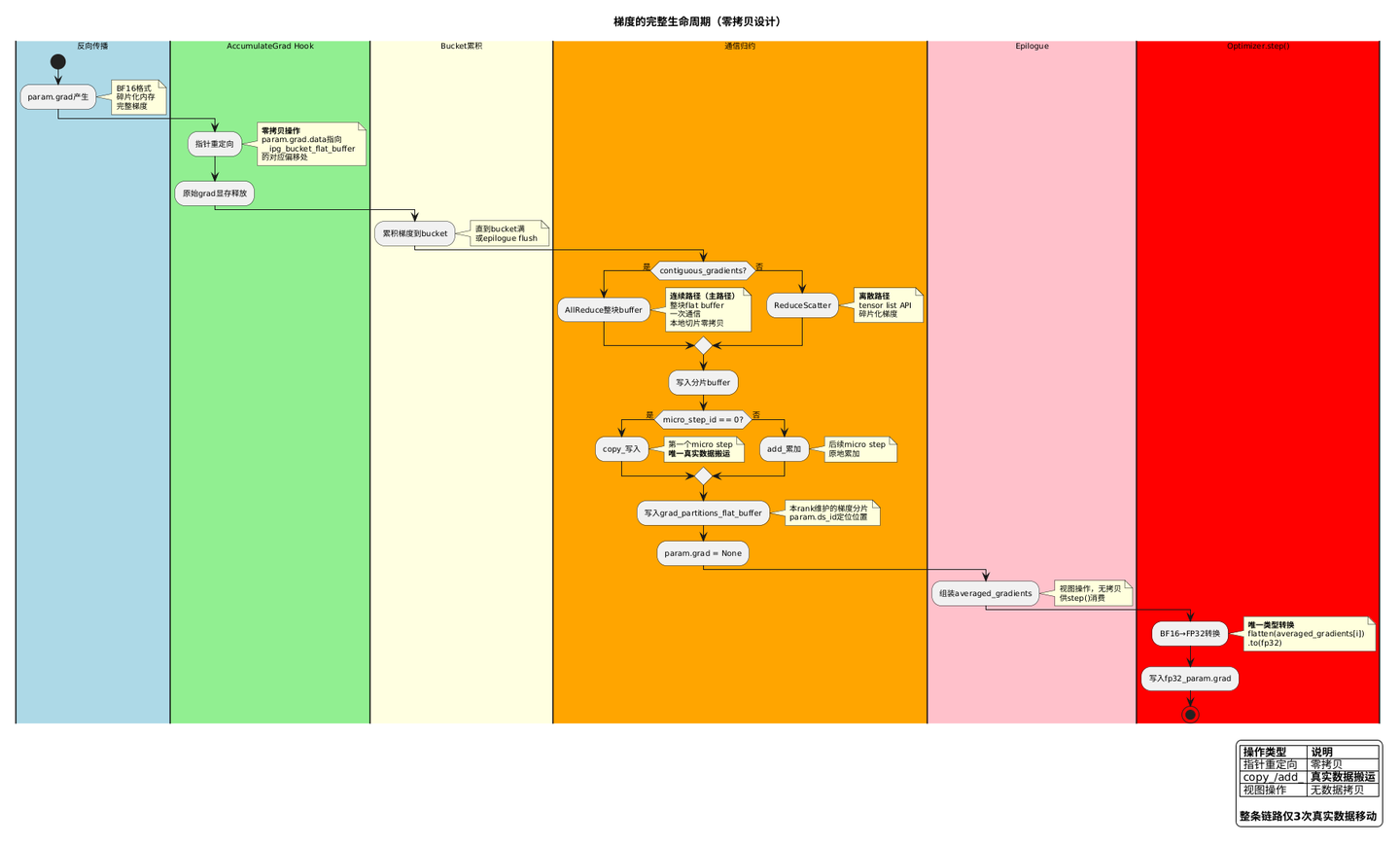
梯度的生命周期(每个参数,反向时):
param.grad(BF16,完整梯度,碎片化)
↓ AccumulateGrad hook → 指针重定向(零拷贝)
__ipg_bucket_flat_buffer 切片
↓ bucket 满 或 epilogue flush
AllReduce(连续路径)/ ReduceScatter(离散路径)→ 本 rank 梯度分片
↓ copy_(唯一一次真实数据搬运)
grad_partitions_flat_buffer[param.ds_id]
↓ epilogue 组装(视图,无拷贝)
averaged_gradients[sub_group_id]
↓ step() 里 to(fp32)(唯一一次 BF16→FP32 类型转换)
fp32_partitioned_groups_flat[i].grad
带着这张地图,后面的所有实现细节都是在填充其中的某一步。
2. 参数的生命周期:前向与反向的对称性
前向和反向对参数的管理方式完全对称——进入模块时 AllGather,退出时 partition(),前向反向做的是同一件事。本节以前向为主线展开,并在末尾说明反向的差异。
2.1 fetch_sub_module 的三步结构
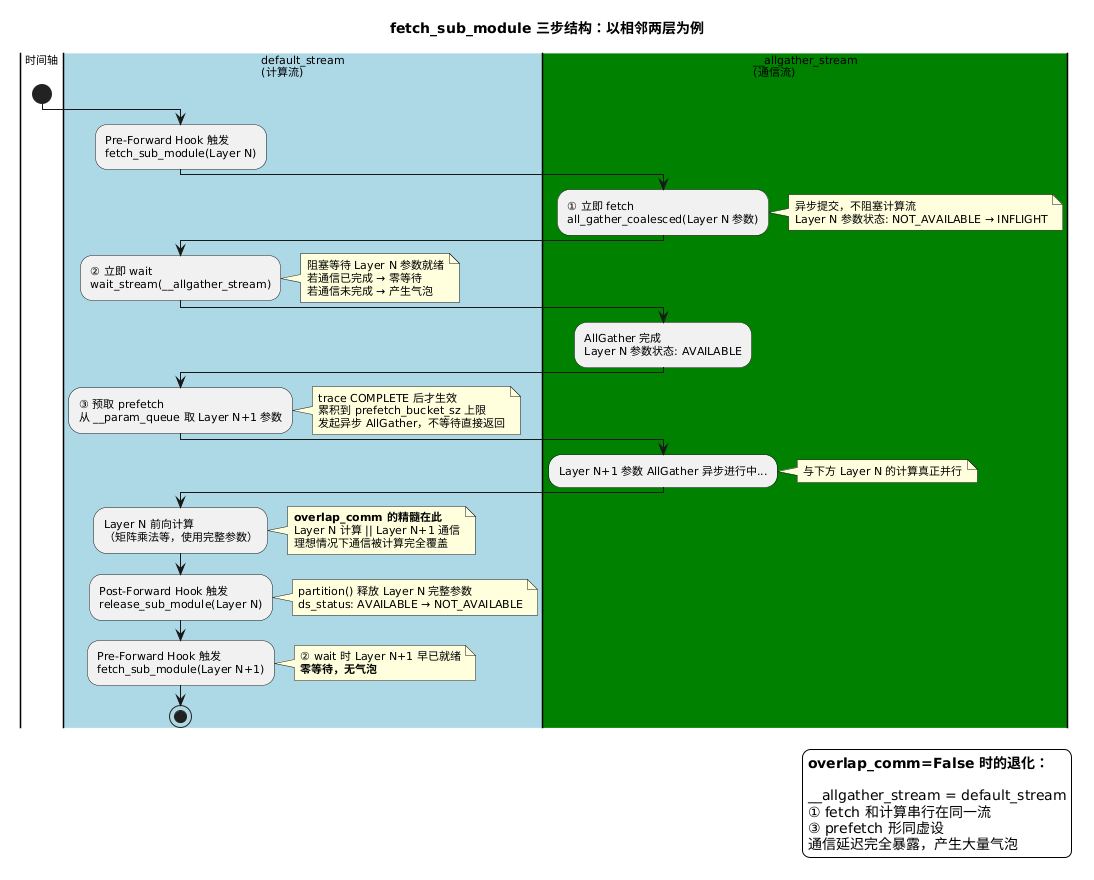
每个模块进入 Pre-Forward Hook 时,都会调用 param_coordinator.fetch_sub_module。这个函数内部严格按顺序执行三步:
① 立即 fetch
对当前模块所有 NOT_AVAILABLE 的参数发起 all_gather_coalesced
在独立的 __allgather_stream 上异步提交,不阻塞计算流
② 立即 wait
阻塞等待当前模块参数就绪
计算流执行 wait_stream(__allgather_stream)
如果 ① 的通信已完成则零等待,否则在此处产生气泡
③ 预取 prefetch(仅 trace 完成后)
从 __param_queue 取接下来若干参数,累积到 prefetch_bucket_sz 上限
对这批参数发起异步 AllGather,不等待,直接返回
overlap_comm 的精髓在第③步:预取是在当前模块参数已就绪、矩阵运算即将开始时发出的。下一层的 AllGather 和当前层的计算真正并行,理想情况下当下一个模块的 Pre-Forward 走到第②步时,通信早已完成,等待时间为零。
overlap_comm=False 时,__allgather_stream 退化为 default_stream(),AllGather 和计算串行在同一个流上,通信延迟完全暴露,速度显著下降。
2.2 预取的上限控制:两把锁
预取并非无限激进,fetch_sub_module 里有两把锁同时约束每次预取量:
max_params_to_prefetch = min(
self.__max_n_available_params - self.__n_available_params, # 锁1:显存上限
self.__prefetch_bucket_sz # 锁2:单次预取量
)
__n_available_params 记录当前显存里所有完整参数的 numel 总量,__release_param 时 -= param.ds_numel,__all_gather_params 时 += all_gather_numel,实时追踪显存里"活着"的参数总量。两把锁共同保证:无论模型多大,显存里同时存在的完整参数量始终不超过 max_live_parameters(对应初始化参数 max_available_parameters_in_numel)。
这三个超参共同决定预取的激进程度:
| 外部配置(ds_config) | 内部变量(PartitionedParameterCoordinator) | 默认值 | 控制的 tradeoff |
|---|---|---|---|
| prefetch_bucket_size | __prefetch_bucket_sz | 50 MB | 单次预取量:越大通信批次越少,但单次启动延迟越高 |
| max_live_parameters | __max_n_available_params | 1e9(约 1B 参数) | 显存里最多存多少完整参数:越大预取越激进,峰值显存越高 |
| max_reuse_distance | __max_reuse_dist_in_numel | 1e9 | 保守释放窗口(见下一节) |
此外,__max_ongoing_fetch_events 硬编码为 2,限制同时排队的异步 fetch 事件数。Host 线程发起异步 AllGather 时,显存在调用时就已分配(不是在 GPU 执行时),无限排队会导致大量显存被提前占用而不释放。上限 2 是预取激进度与显存压力之间的工程折中,代码注释里也提到理想方案是 cudaMallocAsync,但目前尚未实现。
2.3 Trace 机制:从录制到冻结
预取的前提是知道"接下来要用哪些参数",这依赖 Trace 机制。param_coordinator 有三个状态:
| 状态 | 含义 | 何时进入 |
|---|---|---|
| INVALID | 无有效 trace | 初始状态,或 trace 被invalidate |
| RECORD | 正在录制 | 第一次 reset_step() 后 |
| COMPLETE | trace 已冻结,预取生效 | 第一次完整 forward+backward 结束后 |
RECORD 阶段,每个模块被 fetch 时都调用 record_module,把模块顺序追加到 __submodule_order。reset_step() 里调用 construct_parameter_trace_from_module_trace,从模块顺序推导出参数顺序(__param_order),并记录每个参数最后一次被使用的 step_id。随后 __submodule_order 和 __param_order 被冻结为 tuple,状态切到 COMPLETE。
此后每次 trace_prologue 都校验当前模块是否符合预期顺序,不符合则 _invalidate_trace() 退回 INVALID 重新录制——这是动态图(含条件分支的模型)的安全保障。
2.4 保守释放:__params_to_release
退出模块时不是简单地"用完就释放"。release_sub_module 调用 __params_to_release(用 lru_cache 缓存,trace 完成后结果不变),它会向前扫描 max_reuse_distance_in_numel 范围内的后续模块,如果某个参数在这个窗口内还会再次出现,就从释放集合里剔除:
params_traversed = 0
for module in self.__submodule_order[step_id:]:
if params_traversed >= self.__max_reuse_dist_in_numel:
break
for param in iter_params(module):
params_to_release.discard(param.ds_id) # 窗口内还会用到 → 不释放
params_traversed += param.ds_numel
这是为权重共享(weight tying)等场景设计的——比如 embedding 和 lm_head 共享权重,如果释放了再重新 AllGather,不如直接留着。max_reuse_distance_in_numel 控制这个"向前看"的窗口大小,设得越大则共享参数越可能被保留,显存开销越高但通信次数越少。
2.5 前向与反向的对称性
反向阶段的参数管理与前向完全对称,fetch_sub_module 的三步结构、预取逻辑、保守释放策略全部相同。forward 参数传 False 的唯一作用是区分性能计数器的事件标签(FORWARD_ALL_GATHER vs BACKWARD_ALL_GATHER),逻辑路径无任何差异。
3. 梯度的生命周期:设计机制
在看代码之前,先理解梯度管理的三个核心设计决策,它们共同决定了第 5 节所有实现细节的形状。
3.1 为什么要入桶:通信次数 vs 通信量
反向传播产生梯度的顺序是逐参数的,如果每个参数梯度就绪后立即发起 AllReduce,通信次数是 O(参数数),大模型有几亿个参数,海量小消息会把 NCCL 的调度开销打满,实际带宽利用率极低。
桶式归约的思路是:把多个参数的梯度积攒到一个 flat buffer 里,凑满 reduce_bucket_size 再发起一次 AllReduce。通信次数降到 O(桶数),每次通信是大块连续内存,NCCL 效率最高。代价是梯度在 buffer 里等待期间需要占用额外显存。
reduce_bucket_size 直接控制这个 tradeoff:越大通信次数越少、效率越高,但 bucket 占用的峰值显存越高;越小则反之。
3.2 contiguous_gradients 的设计意图
反向传播产生的 param.grad 是碎片化的——每个参数各自分配一块显存,地址不连续。如果把这些碎片直接传给 NCCL,要么预先拷贝拼接(一次额外的显存分配+拷贝),要么用 tensor list API(多次内核调用,开销高)。
contiguous_gradients=True(默认开启)的解决方案是:在初始化时预分配一块连续的 __ipg_bucket_flat_buffer,反向传播时将 param.grad.data 的底层指针重定向到这块 buffer 的对应偏移处。梯度数据直接写入 flat buffer,原始碎片化显存立即释放,整个过程零拷贝。AllReduce 时直接传入整块连续 buffer,是对 NCCL 最友好的形态。
关闭 contiguous_gradients 时,梯度保留在各自碎片化的 param.grad 里,走离散路径的 ReduceScatter,通信效率和显存碎片化程度都更差,一般不建议关闭。
3.3 梯度归约流:与反向计算并行
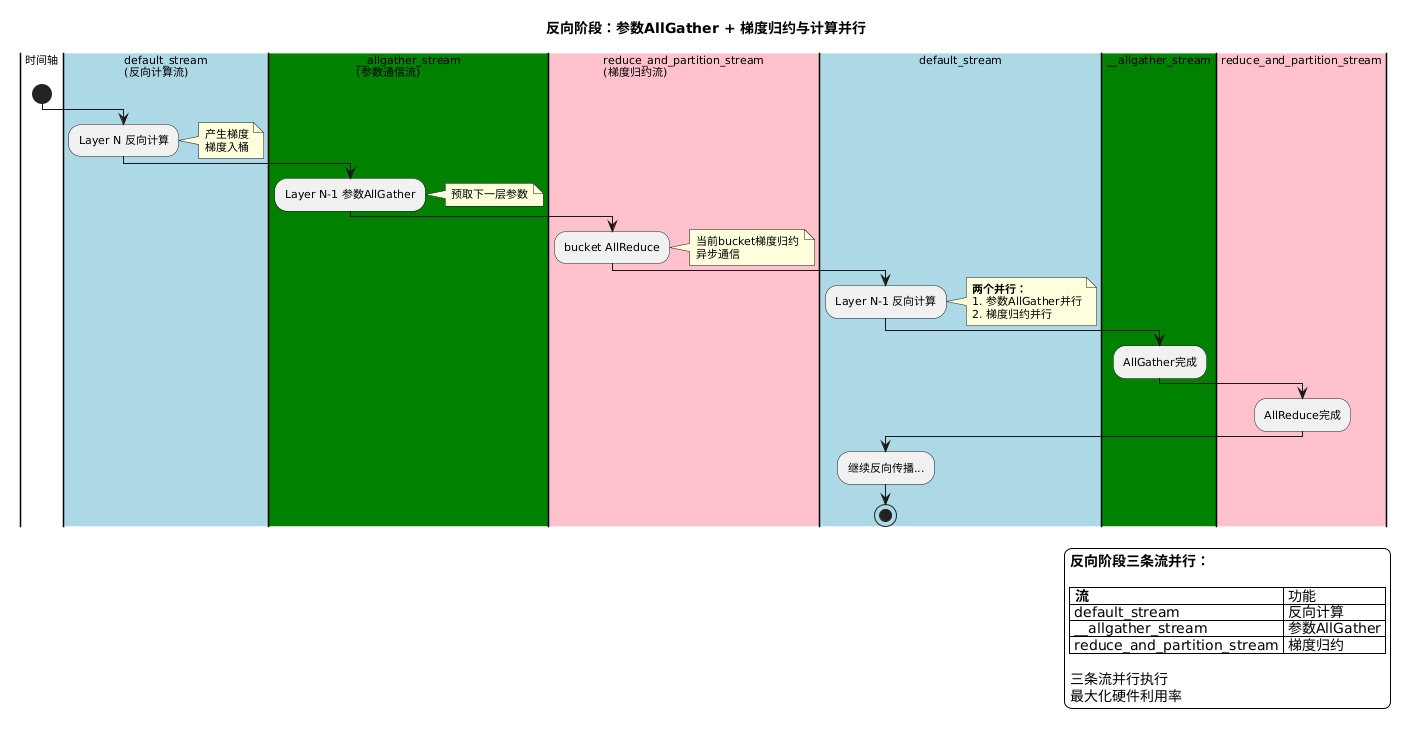
与参数侧的 __allgather_stream 对应,梯度归约运行在独立的 reduce_and_partition_stream 上。bucket 满时触发的 AllReduce 异步提交到这个独立流,不阻塞反向计算流继续处理后续层的梯度。
两条流并行的效果:当前 bucket 在通信的同时,后续层的反向计算和梯度入桶可以继续推进,通信延迟被计算时间覆盖。这是梯度侧的 overlap_comm,机制与参数侧完全对称。
| 参数侧 | 梯度侧 | |
|---|---|---|
| 独立 CUDA 流 | __allgather_stream | reduce_and_partition_stream |
| 异步操作 | AllGather(fetch 参数) | AllReduce / ReduceScatter(归约梯度) |
| 触发时机 | Pre-Forward/Backward Hook | AccumulateGrad Hook(bucket 满) |
| 等待时机 | wait_stream(下次 fetch 时) | epilogue synchronize(backward 结束后) |
4. Hook 系统:如何实现上述行为
上一节描述了"做什么",本节说明"怎么实现"。
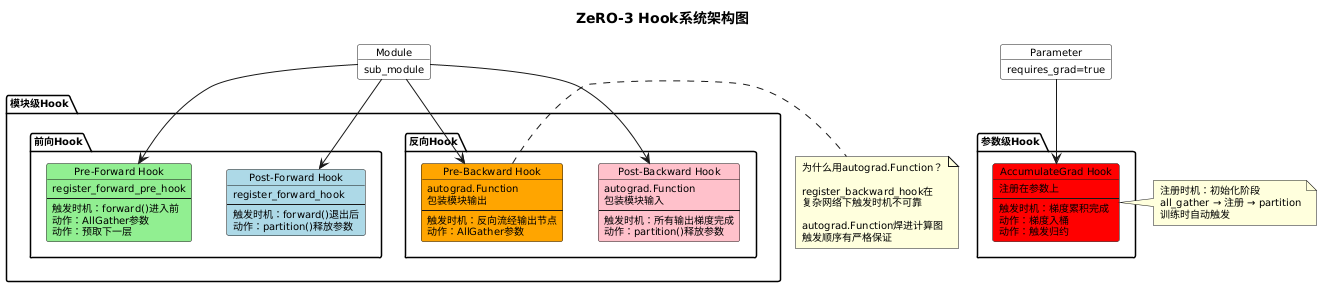
4.1 四类 Hook 总览
ZeRO-3 为每个模块注册四类钩子,注册入口是 _register_deepspeed_module(DFS 递归遍历整个模型树):
| Hook | 注册 API | 触发时机 | 核心动作 |
|---|---|---|---|
| Pre-Forward | register_forward_pre_hook | module.forward() 进入前 | AllGather 参数,预取下一层 |
| Post-Forward | register_forward_hook | module.forward() 退出后 | partition() 释放参数 |
| Pre-Backward | register_forward_hook + autograd.Function 包装输出 | 反向传播流经该模块输出节点时 | 重新 AllGather 参数 |
| Post-Backward | register_forward_pre_hook + autograd.Function 包装输入 | 该模块所有输出梯度计算完毕时 | partition() 释放参数 |
Pre/Post-Forward 用直接函数实现,干净简单。Pre/Post-Backward 的实现则绕了一个弯。
4.2 Pre/Post-Backward 为什么用 autograd.Function
直觉上应该用 register_backward_hook,但这个 API 在复杂网络(多输出、inplace 操作、部分参数不需要梯度)下触发时机不可靠。
autograd.Function 直接焊进计算图节点,触发顺序有严格保证。具体做法是在前向阶段包装模块的输出/输入 tensor,把反向逻辑藏在包装算子的 backward 方法里,等反向传播流经这些节点时自然触发:
# Pre-Backward:包装模块输出,反向经过时触发 AllGather
class PreBackwardFunctionForModule(torch.autograd.Function):
@staticmethod
def forward(ctx, outputs):
ctx.module = module
ctx.module.applied_pre_backward_ref_cnt += 1 # 每次 forward +1
return outputs.detach()
@staticmethod
def backward(ctx, *args):
ctx.pre_backward_function(ctx.module) # 委托给 _run_before_backward_function
return args
# _run_before_backward_function 的实际逻辑:
def _run_before_backward_function(sub_module):
if sub_module.applied_pre_backward_ref_cnt > 0:
pre_sub_module_backward_function(sub_module) # cnt > 0 就触发 AllGather
sub_module.applied_pre_backward_ref_cnt -= 1 # 触发后再 -1
# Post-Backward:包装模块输入,所有输出梯度算完后触发 partition()
class PostBackwardFunctionModule(torch.autograd.Function):
@staticmethod
def forward(ctx, output):
ctx.module = module
if output.requires_grad:
ctx.module.ds_grads_remaining += 1
return output.detach()
@staticmethod
def backward(ctx, *args):
ctx.module.ds_grads_remaining -= 1
if ctx.module.ds_grads_remaining == 0:
_run_after_backward_function(ctx.module) # 所有输出梯度算完才释放
return args
💡 applied_pre_backward_ref_cnt 的真实语义:Qwen 系列每层参数独立,forward 中每个模块只调用一次,cnt 始终在 1 和 0 之间跳动,这个计数器对 Qwen 没有特殊意义。它是为层复用场景设计的——以 Albert 为例,同一个 Transformer Block 在 forward 中被复用 N 次,每次调用计数 +1,backward 每经过一次,只要 cnt > 0 就触发一次 AllGather,触发后 -1。语义是 forward 调用了几次,backward 就 AllGather 几次,引用计数保证两者严格匹配——不会少(每次 backward 都能拿到完整参数),也不会多(cnt 归零后再经过不触发)。
4.3 梯度 Hook 注册
梯度 Hook 独立于模块级 Hook,注册在每个参数的 AccumulateGrad 节点上:
for param in all_params:
if param.requires_grad:
param.all_gather() # 必须在完整参数上注册 AccumulateGrad hook
def reduce_partition_and_remove_grads(*_):
self.reduce_ready_partitions_and_remove_grads(param)
register_grad_hook(param, reduce_partition_and_remove_grads)
param.partition() # 注册完立刻归还分片
all_gather → 注册 → partition 三步都在初始化阶段完成,训练时 Hook 已就位,每次参数梯度累积完毕自动触发,无感知。
4.4 悬挂参数处理
某些模型把参数以 tensor 形式塞进输出的 tuple/dict 里,标准参数遍历无法发现。Post-Forward Hook 会递归展开输出结构,识别其中含 ds_id 的 tensor,将其注册到当前模块并立即 AllGather,避免后续计算因缺参数崩溃。
5. 梯度的生命周期:桶式归约实现
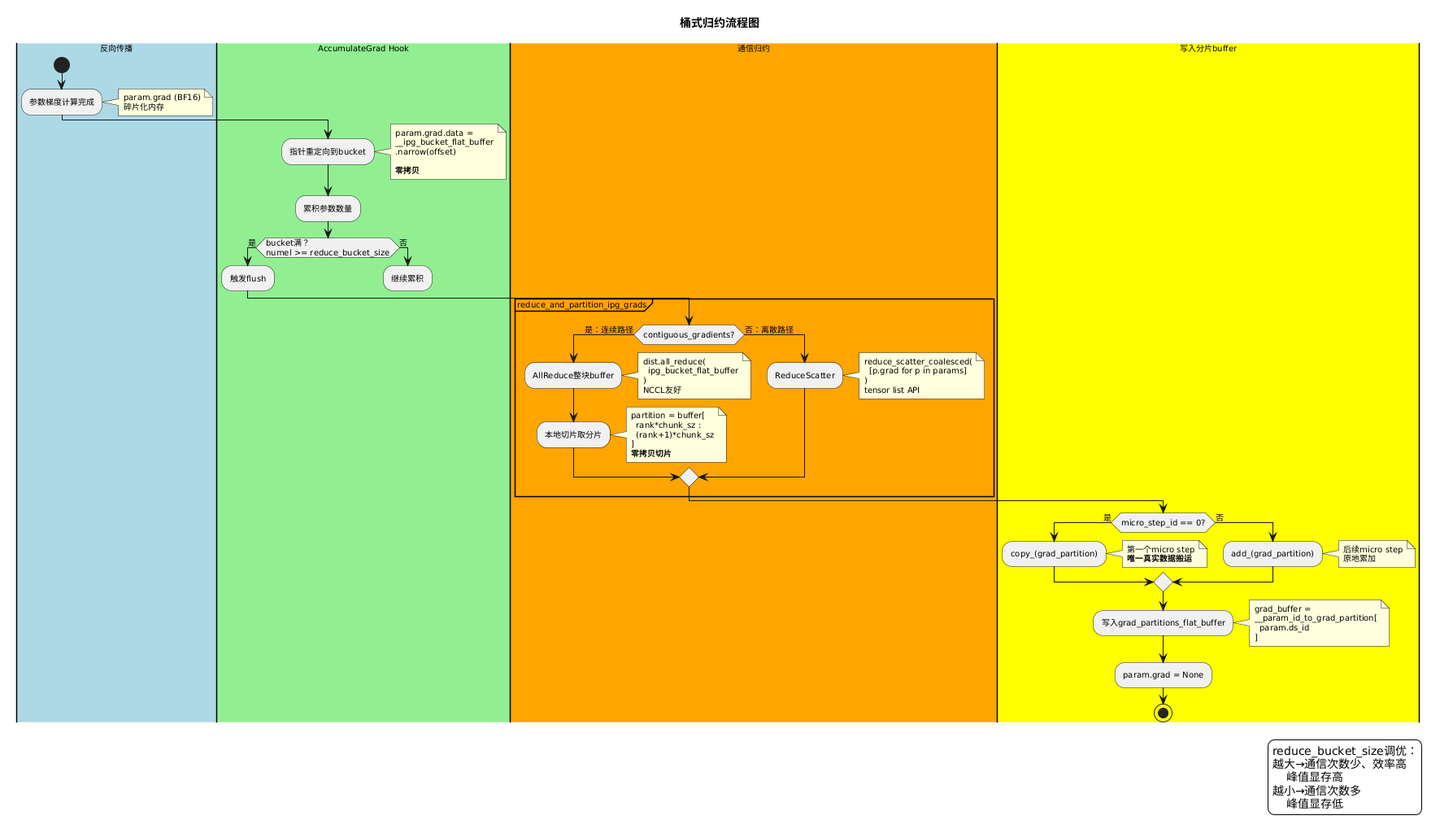
5.1 梯度入桶
每个参数梯度计算完毕后,不是独立存放在 param.grad 里,而是通过指针重定向写入预分配的 __ipg_bucket_flat_buffer:
# param.grad 的底层存储指针指向 flat buffer 的当前偏移处
# 梯度数据直接写入 flat buffer,原始碎片化 grad 显存释放,零拷贝
param.grad.data = __ipg_bucket_flat_buffer.narrow(0, offset, param.grad.numel())
offset += param.grad.numel()
params_in_ipg_bucket.append(param)
当累积元素数超过 reduce_bucket_size 时,提前 flush 触发归约。reduce_bucket_size 越大,通信效率越高但峰值显存越高;越小则反之,是继 sub_group_size 之后第二个值得关注的显存调优超参。
5.2 桶式归约:两条路径
bucket 满(或 epilogue flush)时进入 __reduce_and_partition_ipg_grads,走两条路径之一:
连续路径(主路径,contiguous_gradients=True)
# 整块 flat buffer 一次 AllReduce,本地按 rank 切片取分片
dist.all_reduce(ipg_bucket_flat_buffer, group=dp_process_group)
partition = ipg_bucket_flat_buffer[rank * chunk_sz : (rank + 1) * chunk_sz] # 本地零拷贝切片
离散路径(fallback,梯度碎片化时)
full_grads = [p.grad for p in params_in_ipg_bucket]
grad_partitions = reduce_scatter_coalesced(full_grads, dp_process_group)
💡 连续路径为什么用 AllReduce 而非 ReduceScatter? ReduceScatter 需要把连续 buffer 预切分成 N 份 tensor list 再传入 API,多一次内核调用;AllReduce 直接整块传入,少一步操作,整块连续内存对 NCCL 也更友好。AllReduce 后本地切片是零拷贝,两者通信量完全相同,结果等价。 离散路径梯度本来就是碎片化的 list,ReduceScatter 的 tensor list API 反而更适配。两条路径各取所长。
5.3 写入分片 buffer
归约结果按参数写入 grad_partitions_flat_buffer 的对应切片:
grad_buffer = __param_id_to_grad_partition[param.ds_id]
if micro_step_id == 0:
grad_buffer.copy_(grad_partition, non_blocking=True) # 第一个 micro step:直接写入
else:
grad_buffer.add_(grad_partition) # 后续 micro step:原地累加
param.grad = None # 释放原始梯度显存
梯度累积就在这里实现:多个 micro step 的梯度分片直接 add_ 到同一块 buffer,无需任何额外的临时存储,micro_step_id 驱动 copy_ 和 add_ 的分支切换。
5.4 Epilogue 收尾
每次 backward() 完成后,independent_gradient_partition_epilogue 做四件事:
- flush 剩余 bucket——把最后一批未满的 bucket 也触发归约
- 同步归约流——确保所有异步通信完成,下一步的读取安全
- 重置状态标记——params_already_reduced 清零,为下一轮 backward 准备
- 组装 averaged_gradients——从 __param_id_to_grad_partition 取视图列表,这是 step() 的消费入口,视图操作,无数据拷贝
6. 梯度累积的完整视图
梯度累积(gradient accumulation)是训练中的高频场景,值得单独梳理在 ZeRO-3 下的完整行为:
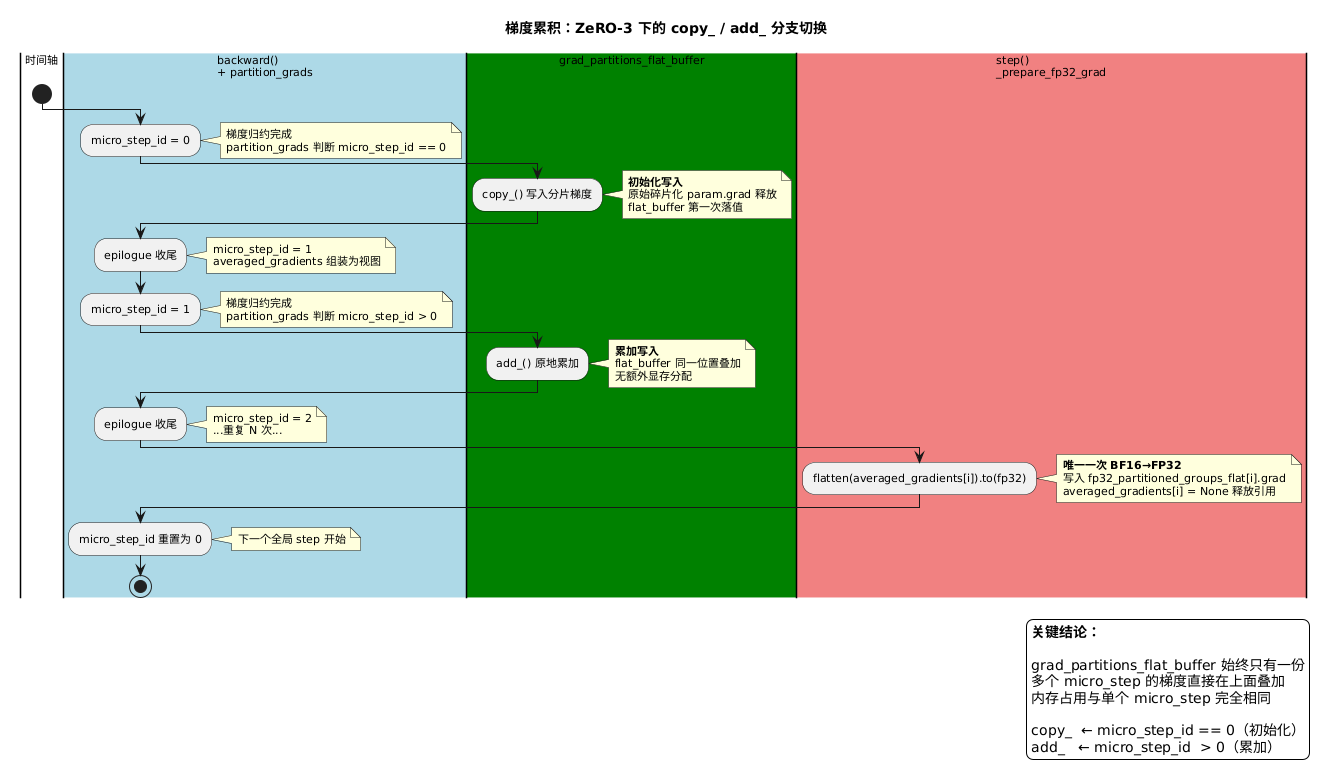
整个累积过程中,grad_partitions_flat_buffer 始终只有一份,多个 micro step 的梯度直接在上面叠加,内存占用与单个 micro step 完全相同。
7. 叶子模块(z3_leaf_module)优化
对于 MoE 等含有大量细粒度子模块的结构,逐参数挂梯度 Hook 会产生海量小消息,通信效率极差。
叶子模块机制将整个模块内所有参数的梯度归约合并为一次触发:在模块的 forward_pre_hook 里,对每个 requires_grad 的输入 tensor 注册 hook,等所有输入 tensor 的反向都完成(_leaf_module_inputs_remaining 减到 0),才统一触发模块内所有参数的归约。
通信次数从 O(参数数) 降到 O(模块数),对 MoE 场景效果显著。
8. 小结
| 生命周期 | 管理者 | 核心动作 | 通信原语 |
|---|---|---|---|
| 参数(前向) | 模块级 Pre/Post-Forward Hook | AllGather → 计算 → partition() | AllGather(可被 Trace 预取隐藏) |
| 参数(反向) | 模块级 Pre/Post-Backward Hook | AllGather → 梯度计算 → partition() | AllGather |
| 梯度 | 参数级 AccumulateGrad Hook | 入桶 → 归约 → copy_ 写入 flat buffer | AllReduce / ReduceScatter |
梯度链路中真正发生数据移动的只有三处,其余全部是零拷贝或 in-place:
| 步骤 | 操作类型 | 说明 |
|---|---|---|
| __add_grad_to_ipg_bucket | 指针重定向 | 原始 grad 显存释放,无数据拷贝 |
| partition_grads → copy_ | 真实数据搬运 | 归约结果写入 flat buffer,非阻塞 |
| _prepare_fp32_grad_for_sub_group | 类型转换 | BF16 → FP32,发生在 step() 里 |
如果你对多模态大模型、强化学习、昇腾 NPU 部署、模型性能优化感兴趣,欢迎持续关注公众号【AI模力圈】。
我们会持续更新:
- 多模态模型结构拆解
- 强化学习算法原理与实践
- 昇腾 NPU 迁移部署与踩坑复盘
- 模型训练与推理性能优化

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐
 11
11 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)