
一天一个昇腾 Agent-Skills 小技巧:轻松完成 MindSpeed-MM FSDP2 自动迁移
模型迁移和开发对基准模型类进行结构化改造,构建 from_pretrained 与 _from_config 等标准化接口。利用 model_register 注册模型,实现模型模块调用的动态加载。数据集迁移和开发识别基准框架的数据构建逻辑,通过 data_register 注册器将其集成至 MindSpeed-MM 框架下。通过解耦数据构建与调用逻辑,实现数据模块的动态加载与标准化调用。配置文件
MindSpeed-MM FSDP2 是基于 Fully Sharded Data Parallel 2 构建的高性能训练后端,旨在支撑多模态开源模型在昇腾平台上的适配与高效训练。当前面向这套目标的多模态迁移任务面临一些效率瓶颈:迁移链路环节繁杂、人工排查成本高昂、重复性工作占比大。
本文将介绍一套模块化的自动迁移 Skills,用于将多模态模型从原生框架向 MindSpeed-MM FSDP2 框架的迁移过程,拆解为可复用、可验证、可交付的工程流程。内容包括这套 Skills 的架构设计、使用方式,以及 InternVL3.5 的迁移实战案例。
一、背景介绍
将多模态模型迁移到 MindSpeed-MM FSDP2,通常需要涉及模型、数据、配置脚本和验证四个阶段:
-
模型迁移和开发
对基准模型类进行结构化改造,构建 from_pretrained 与 _from_config 等标准化接口。利用 model_register 注册模型,实现模型模块调用的动态加载。
-
数据集迁移和开发
识别基准框架的数据构建逻辑,通过 data_register 注册器将其集成至 MindSpeed-MM 框架下。通过解耦数据构建与调用逻辑,实现数据模块的动态加载与标准化调用。
-
配置文件和启动脚本构建
构造 yaml 配置文件,涵盖并行策略、训练配置、数据处理、模型结构四部分,建立配置字段与模型/任务类型的强映射关系,确保配置参数的一致性。
-
端到端训练流程适配验证
执行全栈训练流程拉起,针对迁移过程中可能遇到的问题进行闭环修复。

如果主要依赖人工经验推进,这类任务通常会出现以下痛点:
- 模型、数据、配置修改互相耦合,难以快速定位问题源头
- 大量时间消耗在重复阅读源码、手动比对配置字段和环境排错上
- YAML 字段繁杂且关联性强,人工映射极易出错,且错误往往推迟至运行期才暴露
- 昇腾环境、迁移适配和训练启动过程中存在部分重复性排错工作
- 验证结果缺乏标准化证据支撑,迁移经验难以沉淀为可复用的资产
核心目标是把迁移任务整理成统一输入、分阶段执行和标准产物输出的技术流程,在减少重复劳动的同时,提高迁移和排错效率。
二、Skills 架构与能力介绍
Skills 架构介绍
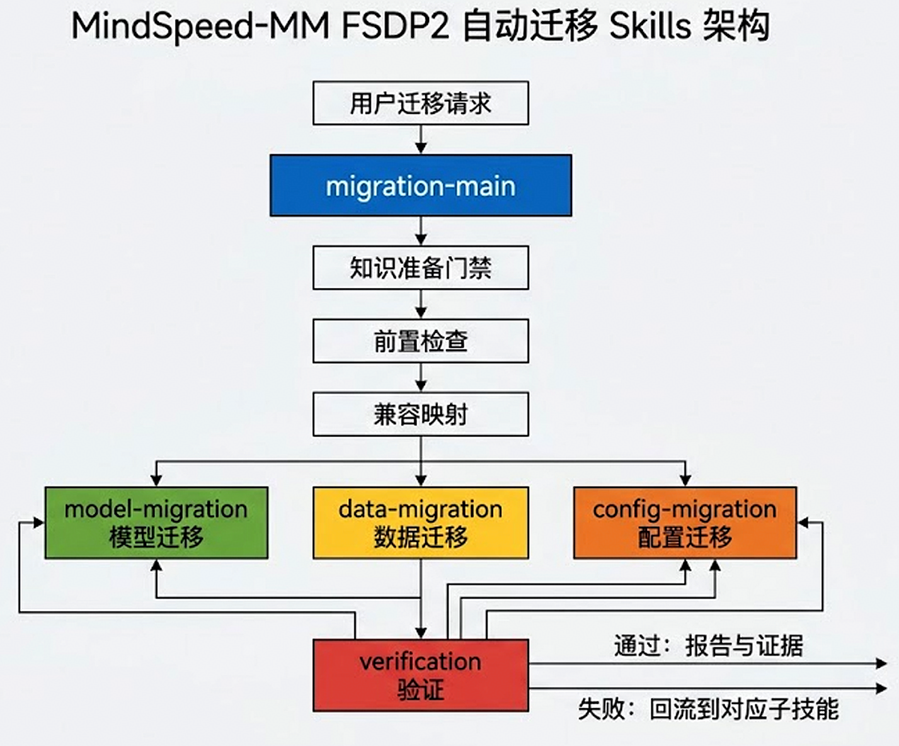
mindspeed-fsdp2-migration-main
├── mindspeed-fsdp2-model-migration
├── mindspeed-fsdp2-data-migration
├── mindspeed-fsdp2-config-migration
└── mindspeed-fsdp2-verification
| Skill | 功能范围 | 主要处理内容 |
|---|---|---|
| mindspeed-fsdp2-migration-main | 总控编排、知识准备、前置检查、汇总交付 | 路由、阶段推进、标准产物汇总 |
| mindspeed-fsdp2-model-migration | 模型侧适配 | model_id 注册、签名兼容、token / embedding、forward / loss |
| mindspeed-fsdp2-data-migration | 数据侧适配 | dataset_type 注册、字段要求、预处理复用、collate_fn |
| mindspeed-fsdp2-config-migration | 配置侧适配 | 配置一致性、训练配置逐项映射、strict / extra 分层、apply_modules 覆盖审计 |
| mindspeed-fsdp2-verification | 验收和回流 | 功能门禁、可靠性门禁、分布式端到端、证据收集 |
关键技术能力
这套 Skills 提供的能力主要包括以下六类:
- 知识准备与输入校验:在实施前检查文档、目录、入口路径、运行资产和可编辑范围,输出理解产物和前置检查结果。
- 模型适配:处理模型注册、加载签名、特殊 token、embedding、mask 和 forward / loss 适配。
- 数据适配:处理数据集注册、字段映射、预处理复用、__getitem__ 和 collate_fn 对齐。
- 配置迁移与检查:处理源仓训练配置到 MM 仓配置的逐项映射,检查 model_id、dataset_type、training.plugin 一致性,并校验 strict / extra 分层和 apply_modules 覆盖。
- 常见报错处理:覆盖迁移和训练过程中常见问题,例如 collate_param.model_name 缺失、apply_modules 与模型结构不匹配、torch_npu 后端扩展加载失败、插件关联错误和路径类型不兼容。
- 验证与回流:执行功能检查、可靠性检查和分布式端到端运行,并将失败映射到对应责任 skill。
与 MindSpeed-MM 的对应关系
将多模态模型从原生框架向 MindSpeed-MM FSDP2 框架的迁移过程,不仅是"改模型代码",还需要把模型构建、批次组织和训练入口整体接到 MM 训练链路中。
在目录结构上,迁移任务通常对应到以下位置:
mindspeed_mm/fsdp/models/:模型适配落点mindspeed_mm/fsdp/data/:数据适配落点examples/fsdp2/:训练配置和样例目录
几类常见迁移方式:
- 自定义模型接入:通过继承 BaseModel / WeightInitMixin 接入 FSDP2 训练,适用于用户自定义结构模型,需按 MindSpeed-MM 方式要求进行重构。
- Transformers 模型接入:通过适配类、模型注册和统一加载接口接入训练流程,适用于基于 Transformers 库的模型。
- 其他第三方模型接入:保留原模型主体,在外层补充适配类、注册逻辑和训练入口对接。
数据侧常见路径:复用 build_mm_dataset / build_mm_dataloader 等 MM 原生数据组件,并通过注册器调用目标任务所用的数据集。
配置侧需要处理四部分内容:构造 yaml 配置文件,包括并行策略、训练配置、数据配置、模型配置四大部分。
三、实战案例:InternVL3.5 迁移全流程
InternVL3.5 -> MindSpeed-MM FSDP2 是这套 Skills 的验证案例,下面按技术流程说明这套技能体系在真实迁移中的工作方式。
Step 0:准备上下文并开始使用
使用方式可参考链接下的 README 文档:https://gitcode.com/Ascend/agent-skills/tree/master/skills/mindspeed-mm-fsdp2-migration

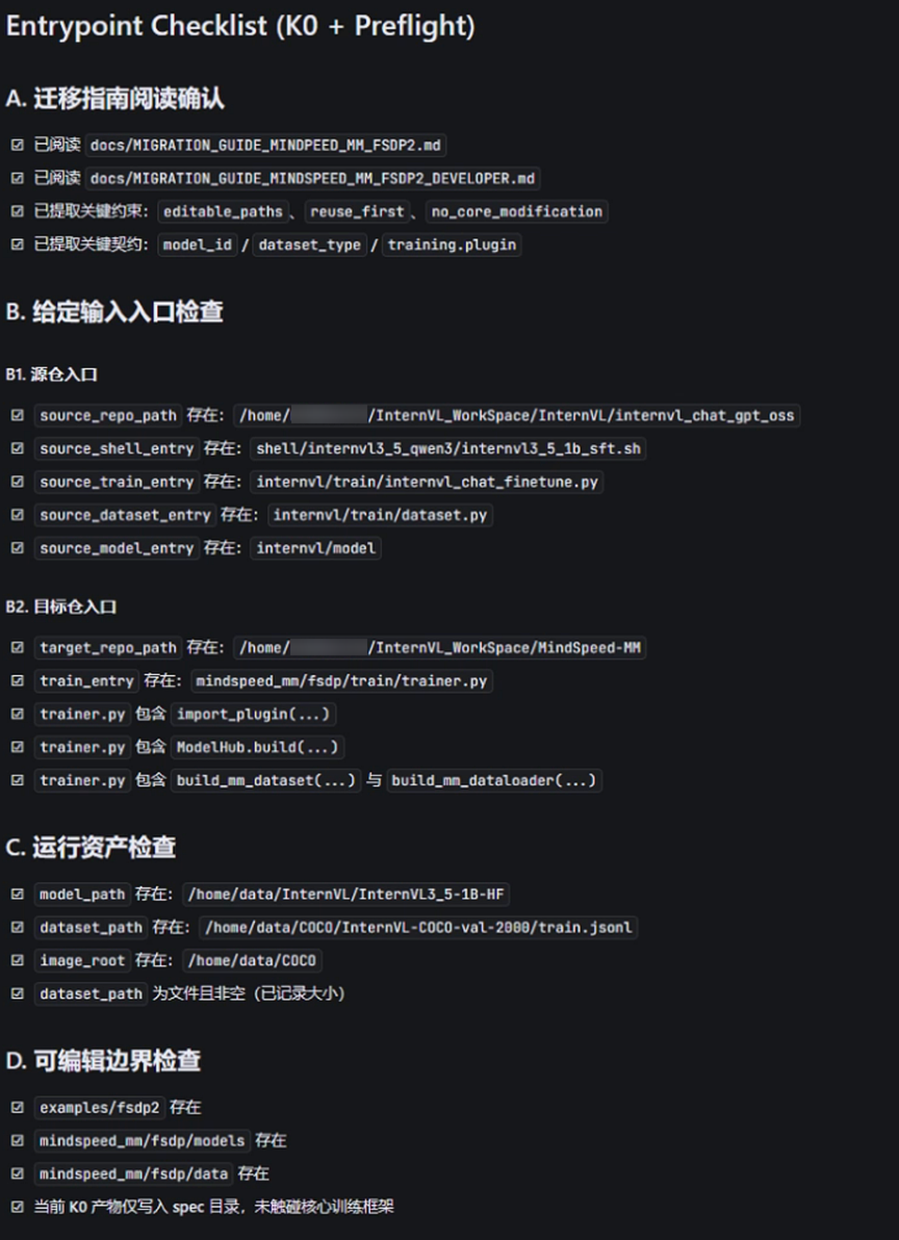
Step 1:完成知识准备门禁
在 Agent 真正开始实施前,会先完成:
- 目标框架文档阅读
- 关键目录扫描
- 架构链路、关键关系矩阵和相似案例分析
这一步用于先建立对目标框架的最小可执行理解,再开始代码和配置适配。
Step 2:完成模型侧适配
InternVL3.5 案例中,模型侧需要解决的问题主要包括:
- 模型注册
- 加载签名兼容
- 特殊 token 与 num_image_token
- 前向链路与 .loss
这也是为什么模型侧被单独拆成一个 skill,而不是和配置或数据阶段混在一起处理。
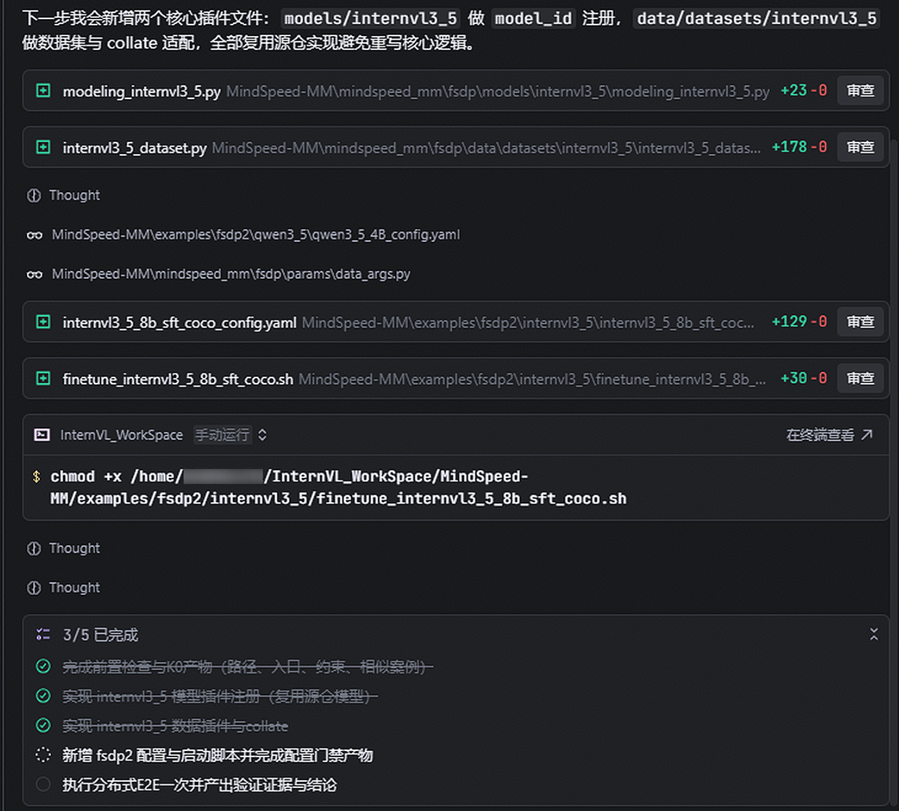
Step 3:完成数据侧适配
数据侧重点在于:
- 数据集注册
- 样本字段映射
- 多模态字段保留
- collate_fn 行为对齐
- 路径和 schema 的真实抽样校验
像 image_root 这类字段,不能只靠输入描述,必须结合真实数据做运行时验证。
Step 4:完成配置侧适配
配置侧最关键的是把以下三者真正对齐:
- model_id
- dataset_type
- training.plugin
案例中还验证了另外两个检查点:
- strict / extra 字段分层必须明确
- parallel.fsdp_plan.apply_modules 需要根据真实模型结构做覆盖审计
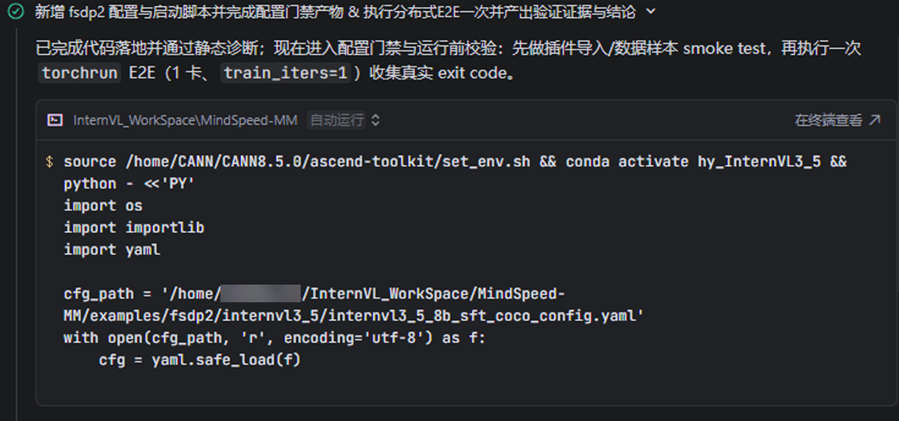
Step 5:进入统一验证与证据输出
最终验证环节需要完成:
- 功能门禁检查
- 可靠性门禁检查
- 至少一次分布式端到端成功
- 正式输出 verification_report.md 和 evidence.json

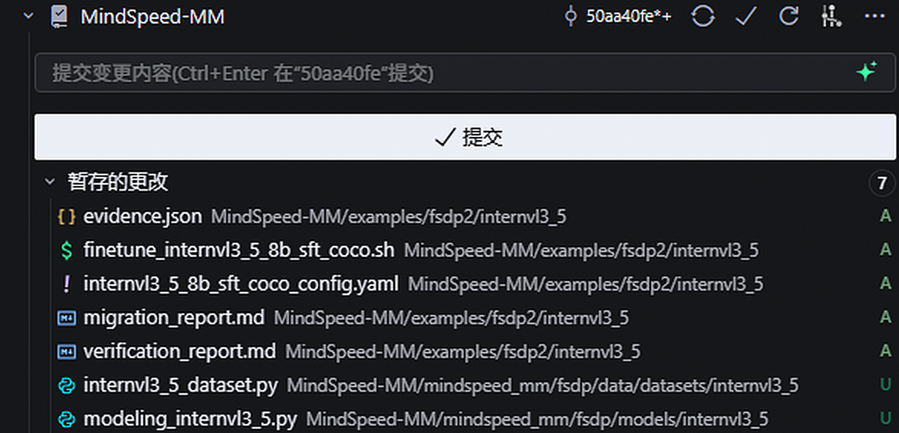
Step 6:启动训练
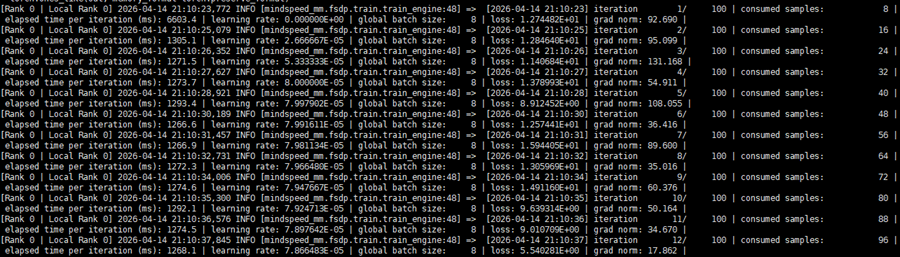
bash examples/fsdp2/internvl3_5/finetune_internvl3_5_8b_sft_coco.sh
拉起训练,100 步训练正常:
四、核心价值与优势
和传统迁移方式相比,这套 Skills 存在以下几项工程收益:
- 效率提升:首轮迁移时间从以往的 1-3 人天,可压缩到约 1 小时级别
- 形成闭环:把迁移流程标准化为 知识准备 -> 实施 -> 验证 -> 回流
- 前移问题发现:关键失败可以在配置和前置阶段暴露
- 增强结果可信度:通过 verification_report.md 留下显式证据
- 沉淀可复用资产:让迁移经验能够服务下一次模型迁移任务
五、未来规划
后续演进方向将会集中在四个方面:
- 扩大模型覆盖范围,逐步补齐更多理解型模型的自动迁移规则和案例
- 通过完善失败反例库和常见报错处理规则,继续降低首轮迁移失败率
- 推进对生成模型和全模态模型的迁移支持
- 加强对精度对齐的持续优化
社区共建:欢迎开发者贡献新模型支持与优化建议,共同完善昇腾生态。开源地址:https://gitcode.com/Ascend/agent-skills

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)