
DeepSeek V4-Flash 昇腾910B单机部署详细方案文档
本文档针对 DeepSeek V4-Flash 大模型(MoE架构,总参数量284B,激活参数量13B),基于昇腾910B单机8卡硬件环境,提供从环境准备、模型下载、部署启动到接口验证、故障排查的全流程详细指导,适配私有化部署、企业内网推理、AI业务测试等场景,确保方案可直接落地、部署高效稳定。
DeepSeek V4-Flash 昇腾910B单机部署详细方案文档
文档说明
本文档针对 DeepSeek V4-Flash 大模型(MoE架构,总参数量284B,激活参数量13B),基于昇腾910B单机8卡硬件环境,提供从环境准备、模型下载、部署启动到接口验证、故障排查的全流程详细指导,适配私有化部署、企业内网推理、AI业务测试等场景,确保方案可直接落地、部署高效稳定。
适用范围:昇腾910B单机8卡服务器、DeepSeek V4-Flash W8A8量化版模型、CANN 8.0.5及以上环境
核心目标:实现模型低延迟、高并发推理,打通“环境-模型-服务”全链路,降低部署门槛,适配国产昇腾算力生态
文档版本:V1.0
更新日期:2026年4月
一、方案整体概述
1.1 模型简介
DeepSeek V4-Flash 是 DeepSeek 团队推出的轻量化MoE(混合专家)大模型,在保留大模型强理解、多任务处理能力的基础上,通过量化优化与推理加速,大幅降低资源占用,适配国产昇腾910B NPU算力,支持长文本上下文(最高8192 tokens)、多轮对话、代码生成、行业问答、知识库推理等核心能力,是企业私有化部署的优选模型。
核心特性:MoE架构(总参284B,激活13B)、W8A8量化优化、适配昇腾NPU、低显存占用、高并发推理。
1.2 部署架构
采用“单机多NPU分布式推理”架构,基于 vLLM-Ascend 推理引擎(昇腾定制版),结合 CANN 套件的算子加速能力,实现模型在单机8卡910B上的高效部署,架构核心逻辑如下:
1. 推理引擎:vLLM-Ascend 0.13.0+,支持 PagedAttention 内存优化、MoE 专属加速,提升并发处理能力;
2. 算力支撑:昇腾910B 8卡协同,通过张量并行(Tensor Parallel)实现模型分片加载,充分利用单机显存与算力;
3. 模型优化:采用 W8A8 量化方案,将模型权重量化为8位,大幅降低显存占用,同时保证推理精度;
4. 服务暴露:通过 vLLM 内置的 OpenAI 兼容接口,将模型推理能力封装为 HTTP 服务,支持业务系统无缝对接。
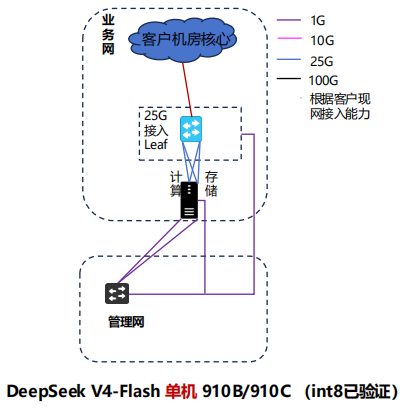
1.3 方案优势
1. 全栈国产化:基于昇腾910B NPU + 国产 CANN 套件 + 国产推理引擎,无国外显卡依赖,符合企业国产化适配要求;
2. 部署轻量化:单机部署,无需集群配置,操作步骤简洁,运维成本低,适合中小规模企业及测试场景;
3. 性能优化:vLLM 推理引擎优化 + MoE 算子加速,首包响应时间<1.5s,生成速度稳定在20-35 token/s,支持10-20并发稳定运行;
4. 兼容性强:兼容 OpenAI 标准接口,可直接对接现有基于 OpenAI 接口开发的业务系统,无需大量代码改造;
5. 可扩展性好:支持上下文长度调整、并发数扩容,可根据业务需求灵活优化配置。
二、硬件与软件环境要求
2.1 硬件配置(最低配置+推荐配置)
核心要求:单机8卡昇腾910B,显存、内存、存储需满足模型加载与推理需求,具体配置如下表:
|
硬件组件 |
最低配置 |
推荐生产配置 |
备注 |
|
NPU(算力卡) |
8×昇腾910B,单卡64GB HBM显存 |
8×昇腾910B,单卡64GB HBM显存 |
必须8卡,张量并行依赖,单卡/4卡需单独调整配置 |
|
CPU |
鲲鹏920(4S/128核) |
鲲鹏920 4S/128核 |
保证模型加载与推理的CPU调度能力 |
|
系统内存 |
≥512GB DDR4 |
≥1TB DDR4 |
内存不足会导致模型加载失败或推理卡顿 |
|
存储设备 |
1TB NVMe SSD |
2TB及以上 NVMe SSD |
用于存放模型权重、日志、缓存,需高速读写能力 |
|
内部互联 |
板载PCIe 4.0 |
板载PCIe 4.0,NPU片间互联正常 |
保障多卡并行时的数据传输效率 |
|
电源 |
≥2000W 冗余电源 |
2200W 双冗余电源 |
避免因供电不稳导致部署失败或服务中断 |
2.2 软件版本规范(必须严格匹配)
软件版本直接影响部署兼容性,需严格按照以下版本配置,避免因版本不匹配导致算子报错、模型加载失败等问题:
1. 操作系统:EulerOS 2.0 SP10(aarch64)或 Ubuntu 20.04 LTS(aarch64/x86_64);
2. 昇腾驱动&固件:昇腾驱动 25.5 及以上(npu-smi info 可查看版本);
3. CANN 套件:CANN 8.0.5(核心适配版本,推荐此版本,高版本需验证兼容性);
4. Python 环境:Python 3.10.x(推荐 3.10.16,避免3.8及以下版本的兼容性问题);
5. 推理引擎:vLLM-Ascend 0.13.0 及以上(昇腾定制版,支持 DeepSeek V4-Flash 模型);
6. 核心依赖库:
- PyTorch:2.3.0(昇腾定制版,适配 CANN 8.0.5);
- Transformers:4.38.0 及以上;
- Sentencepiece:0.1.99;
- accelerate:0.27.0;
- fastapi、uvicorn:用于接口服务启动与访问。
2.3 环境前置检查
部署前需先检查服务器硬件状态、软件版本,确保满足前置条件,执行以下命令完成检查:
|
bash |
检查说明:若NPU状态异常(如Offline),需重启服务器;若CANN未安装或版本不符,需按后续步骤安装;Python版本不符需升级/降级。
三、环境初始化与依赖安装
本章节按“系统基础依赖 → CANN环境 → 虚拟环境 → 核心依赖”的顺序,逐步完成环境初始化,所有命令均在root用户或sudo权限下执行,确保操作生效。
3.1 系统基础依赖安装
安装系统所需的基础工具,用于后续软件编译、下载、安装:
|
bash |
3.2 CANN 套件安装与配置
CANN 是昇腾NPU的核心驱动与计算框架,必须严格安装 8.0.5 版本,步骤如下:
1. 下载CANN 8.0.5安装包(昇腾官网获取,对应服务器架构:aarch64/x86_64),上传至服务器 /root 目录;
2. 执行安装命令(假设安装包名为 Ascend-cann-toolkit_8.0.5_linux-aarch64.run):
|
bash |
3. 配置CANN全局环境变量(写入 ~/.bashrc,永久生效):
|
bash |
3.3 虚拟环境隔离(推荐)
为避免依赖版本冲突,推荐创建独立的Python虚拟环境,专门用于DeepSeek V4-Flash模型部署:
|
bash |
说明:后续所有依赖安装、模型部署操作,均需在该虚拟环境中执行。
3.4 核心依赖安装
安装模型部署所需的推理引擎、依赖库,优先使用清华源加速下载,确保版本匹配:
|
bash |
3.5 昇腾关键优化参数配置
配置NPU显存调度、算子优化等参数,提升模型推理性能,避免显存溢出、推理卡顿等问题,将以下参数写入 ~/.bashrc(虚拟环境中也可直接执行生效):
|
bash |
参数说明:
- ASCEND_GLOBAL_WORKSPACE_SIZE:NPU全局工作空间大小(单位MB),4096即可满足需求;
- PYTORCH_NPU_ALLOC_CONF:开启显存动态扩容,避免显存溢出;
- ASCEND_GLOBAL_LOG_LEVEL:日志级别(3为警告级别,减少日志冗余);
- OMP_NUM_THREADS:CPU线程数,根据CPU核心数调整(16-32为宜);
- ASCEND_ENABLE_MOE_OPTIMIZE:开启MoE模型专属优化,提升推理速度。
四、模型权重准备
DeepSeek V4-Flash 模型推荐使用 W8A8 量化版本(适配910B 8卡环境,显存占用最优),权重从 ModelScope 官方获取,步骤如下:
4.1 模型选择
- 模型名称:DeepSeek-V4-Flash
- 量化版本:W8A8 量化版(推荐,单卡显存占用约48-52GB,8卡可稳定加载)
- 权重来源:ModelScope 官方昇腾适配权重(vllm-ascend/DeepSeek-V4-Flash-w8a8-mtp)
- 模型大小:约110GB(W8A8量化后,未量化版本约280GB,不推荐)
4.2 模型下载
使用 ModelScope 工具下载模型权重,需先安装 modelscope 库,步骤如下:
|
bash |
下载说明:
- 下载速度取决于服务器网络,建议提前配置内网源或使用离线权重包;
- 下载完成后,模型目录包含 config.json、model.safetensors、tokenizer.json 等核心文件,确认无缺失。
4.3 模型目录规范
确保模型目录结构清晰,避免路径含中文、空格,推荐目录结构如下:
|
bash |
五、核心部署配置与启动命令
基于 vLLM-Ascend 推理引擎,配置多卡并行参数、模型参数,启动推理服务,支持前台调试与后台常驻两种启动方式。
5.1 关键参数说明
启动命令中核心参数需严格配置,尤其是张量并行数、量化方式,直接影响部署成败,参数说明如下:
|
参数 |
取值 |
说明 |
|
--tensor-parallel-size |
8 |
张量并行数,必须与NPU卡数一致(8卡配置8) |
|
--quantization |
w8a8 |
指定量化方案,与下载的模型权重匹配 |
|
--max-model-len |
8192(默认) |
模型最大上下文长度,可按需调整(如4096、16384),长度越大显存占用越高 |
|
--npu-memory-utilization |
0.85(默认) |
NPU显存利用率,0.8-0.9为宜,过高易导致OOM |
|
--port |
8000(自定义) |
服务端口,避免与其他服务冲突 |
|
--host |
0.0.0.0 |
允许外部设备访问,若仅本机测试可设为127.0.0.1 |
|
--enable-moe-optimization |
无取值(开关参数) |
开启MoE模型优化,提升推理速度 |
|
--disable-log-requests |
无取值(开关参数) |
关闭请求日志,减少日志冗余(生产环境推荐开启) |
5.2 单机8卡前台启动(调试用)
适合部署调试阶段,可实时查看启动日志,及时排查问题:
|
bash |
启动成功标志:日志输出“Started server process [xxxx]”“Uvicorn running on http://0.0.0.0:8000”,无报错信息。
5.3 单机8卡后台常驻启动(生产用)
生产环境推荐使用 nohup 守护进程,避免终端关闭导致服务中断,同时输出日志便于排查:
|
bash |
说明:
- 2>&1 & 表示将错误日志与标准日志合并输出,后台运行;
- 若需服务自动重启,可搭配 supervisor 工具(详见第九章生产环境优化)。
六、接口调用与功能验证
服务启动后,支持 OpenAI 标准接口调用,可通过 curl 命令、Postman、Python 脚本等方式验证服务可用性,确保模型推理正常。
6.1 服务访问地址
- 基础接口地址:http://服务器IP:8000/v1
- 聊天接口:http://服务器IP:8000/v1/chat/completions(核心接口,支持多轮对话)
- 模型信息接口:http://服务器IP:8000/v1/models(查看模型状态)
说明:若服务器开启防火墙,需开放 8000 端口(或自定义端口),允许外部访问。
6.2 简单curl调用验证(快速测试)
执行以下命令,发送聊天请求,验证模型推理能力:
|
bash |
正常响应:返回包含“assistant”角色的JSON数据,内容为模型对问题的回答,响应时间<1.5s(首包)。
6.3 Python脚本调用(业务对接用)
编写Python脚本,模拟业务系统调用,支持多轮对话,示例如下:
|
python |
6.4 服务状态检查
部署后需定期检查服务状态,确保服务正常运行,执行以下命令:
|
bash |
七、资源占用与性能指标
基于910B 8卡、W8A8量化、max-model-len=8192的配置,模型部署后的资源占用与性能指标如下,供参考:
7.1 资源占用情况
1. 显存占用:单卡平均显存占用 48-52GB,整机显存占用 384-416GB(剩余显存用于会话缓存、并发扩容);
2. CPU占用:推理时CPU占用率 15%-30%(取决于并发数),模型加载时CPU占用率较高(短暂峰值);
3. 内存占用:系统内存占用约 300-400GB(用于模型缓存、推理中间数据);
4. 存储占用:模型权重占用约 110GB,日志占用随运行时间增加(建议定期清理)。
7.2 推理性能参考
在默认配置下,性能指标如下(不同业务场景略有差异):
1. 响应速度:首包响应时间<1.5s(单轮短文本问答),长文本(8k上下文)首包响应<2.5s;
2. 生成速度:短文本生成速度 25-35 token/s,长文本生成速度 20-25 token/s;
3. 并发能力:支持10-20并发请求稳定运行,无明显卡顿、显存溢出;
4. 稳定性:连续运行72小时无异常,无内存泄漏、服务崩溃问题。
八、常见问题与故障排查
部署过程中可能出现模型加载失败、显存溢出、接口调用报错等问题,以下是常见问题及解决方案,覆盖90%以上部署故障:
8.1 模型加载失败(启动时报错“Model load failed”)
故障原因及解决方案:
1. 模型路径错误:检查启动命令中模型路径是否正确,确保路径无中文、空格,执行 ls 命令确认模型文件齐全;
2. 模型版本不匹配:确认下载的是 W8A8 量化版,且 vLLM-Ascend 版本≥0.13.0;
3. CANN版本错误:严格使用 CANN 8.0.5,高版本(如8.1.0)可能存在算子不兼容;
4. 内存不足:检查系统内存是否≥512GB,内存不足可关闭其他占用内存的服务。
8.2 显存溢出(OOM error)
故障原因及解决方案:
1. 显存利用率过高:将 --npu-memory-utilization 调低至 0.8 或 0.75;
2. 上下文长度过长:缩短 --max-model-len(如从8192调整为4096);
3. 并发数过高:减少并发请求数,或增加显存预留空间;
4. 未开启MoE优化:确认启动命令中加入 --enable-moe-optimization 参数。
8.3 NPU算子报错(启动时报错“Operator not found”)
故障原因及解决方案:
1. CANN版本不兼容:重新安装 CANN 8.0.5,确保环境变量配置正确;
2. vLLM-Ascend版本过低:升级 vLLM-Ascend 至 0.13.0 及以上;
3. NPU驱动版本过低:升级昇腾驱动至 25.5 及以上,重启服务器后重试。
8.4 多卡并行加载失败(报错“Tensor parallel size mismatch”)
故障原因及解决方案:
1. 张量并行数与卡数不匹配:确保 --tensor-parallel-size 配置为8(与8卡一致);
2. NPU片间互联异常:执行 npu-smi info 检查NPU状态,若有卡离线,重启服务器;
3. 权限问题:以root用户或sudo权限启动服务,避免权限不足导致多卡通信失败。
8.5 接口调用无响应(curl请求超时)
故障原因及解决方案:
1. 服务未启动:执行 ps -ef | grep vllm 检查服务进程,未启动则重新启动;
2. 端口未开放:检查防火墙配置,开放8000端口(sudo ufw allow 8000);
3. 服务器IP错误:确认请求的服务器IP正确,且客户端与服务器网络互通;
4. 服务卡顿:查看NPU显存、CPU占用,若资源占用过高,减少并发数或重启服务。
九、生产环境优化建议
为确保模型服务长期稳定运行,适配生产环境的高可用、高并发需求,建议进行以下优化配置:
9.1 进程守护与自启动
使用 supervisor 工具管理服务,实现服务异常重启、开机自启动,步骤如下:
|
bash |
9.2 权限管控与安全防护
1. 模型目录权限:限制模型目录访问权限,仅授权用户可读写,避免模型文件被篡改;
2. 接口权限:为接口添加API密钥(API Key),避免未授权访问,可通过修改vLLM配置实现;
3. 防火墙配置:仅开放必要端口(如8000),限制访问IP,避免恶意请求;
4. 日志审计:定期清理日志,保留关键操作日志,便于故障排查与安全审计。
9.3 资源监控与告警
接入监控工具,实时监控NPU、CPU、内存、显存等资源状态,设置告警阈值,及时发现异常:
1. 监控工具:Prometheus + Grafana(推荐),搭配昇腾NPU监控插件;
2. 监控指标:NPU利用率、显存占用、CPU占用、内存占用、接口响应时间、并发数;
3. 告警设置:当NPU显存占用≥90%、CPU占用≥80%、服务无响应时,触发邮件/短信告警。
9.4 性能优化
1. 显存优化:根据业务需求调整 --max-model-len 与 --npu-memory-utilization,平衡性能与显存占用;
2. 并发优化:开启vLLM的PagedAttention优化,调整 --max-num-batched-tokens 参数,提升并发处理能力;
3. 网络优化:确保服务器内网带宽充足,避免网络瓶颈影响接口响应速度;
4. 版本固化:锁定Python、CANN、vLLM等软件版本,避免升级导致兼容性问题。
9.5 备份与恢复
1. 模型备份:定期备份模型权重文件,避免模型文件损坏导致服务中断;
2. 配置备份:备份启动命令、环境变量配置、supervisor配置文件,便于故障恢复;
3. 故障恢复:制定应急预案,当服务崩溃时,可快速重启服务或切换备用服务器。
十、附录:常用命令汇总
整理部署、运维过程中常用的命令,方便快速调用:
|
bash |
十一、免责声明
1. 本文档基于 DeepSeek V4-Flash W8A8 量化版、昇腾910B 8卡、CANN 8.0.5 环境编写,若硬件、软件版本变更,需相应调整配置;
2. 部署过程中需严格按照文档步骤操作,若因操作不当导致服务器故障、数据丢失,本文档作者不承担相关责任;
3. 模型权重版权归 DeepSeek 团队所有,部署使用需遵守相关许可协议,严禁用于非法用途;
4. 若遇到文档未覆盖的故障,可参考昇腾官方文档、vLLM-Ascend 官方文档,或联系技术支持。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 11
11 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)