
DeepSeek V4震撼发布!国产大模型正式登顶,全面拥抱华为昇腾,性能逆袭GPT-5!
DeepSeek V4预览版重磅发布,国产大模型实现重大突破。该版本拥有1.6万亿参数规模,全面适配华为昇腾芯片,性能媲美Claude Opus和GPT-5。关键技术亮点包括混合注意力架构降低长文本处理成本、流形约束超连接提升训练稳定性,以及三档推理强度选择。V4在多个基准测试中表现优异,推理速度提升35倍,能耗降低40%。此次发布不仅展示了国产大模型的技术实力,更标志着AI竞争进入系统工程时代,
DeepSeek V4预览版正式上线并开源,标志着国产大模型的重要突破。V4拥有1.6万亿参数规模,全面超越前代产品,并首次全面适配华为昇腾芯片,性能表现强劲,与Claude Opus和GPT-5正面竞争。V4引入混合注意力架构和流形约束超连接等技术,显著提升长上下文处理能力,同时提供三档推理强度选择。对于开发者而言,V4降低了长文档和代码处理的门槛,API迁移成本低,且国产算力部署更为便捷。此次发布不仅展现了国产大模型的竞争力,更标志着AI竞争进入系统工程时代。
2026 年 4 月 24 日,DeepSeek V4 预览版正式上线并同步开源。
这不只是一次版本更新,而是国产大模型宣告登顶的一次**“亮剑”**。
一句话总结
距离 R1 发布整整 15 个月,DeepSeek 憋出了一个大招——V4 不仅在跑分上正面叫板 Claude Opus 和 GPT-5,更重要的是,它全面跑在了华为昇腾芯片上。
如果说 2025 年初的 R1 是"性价比的一次证明",那么 2026 年 4 月的 V4 就是"全栈自主的一次宣言"。
DeepSeek V4
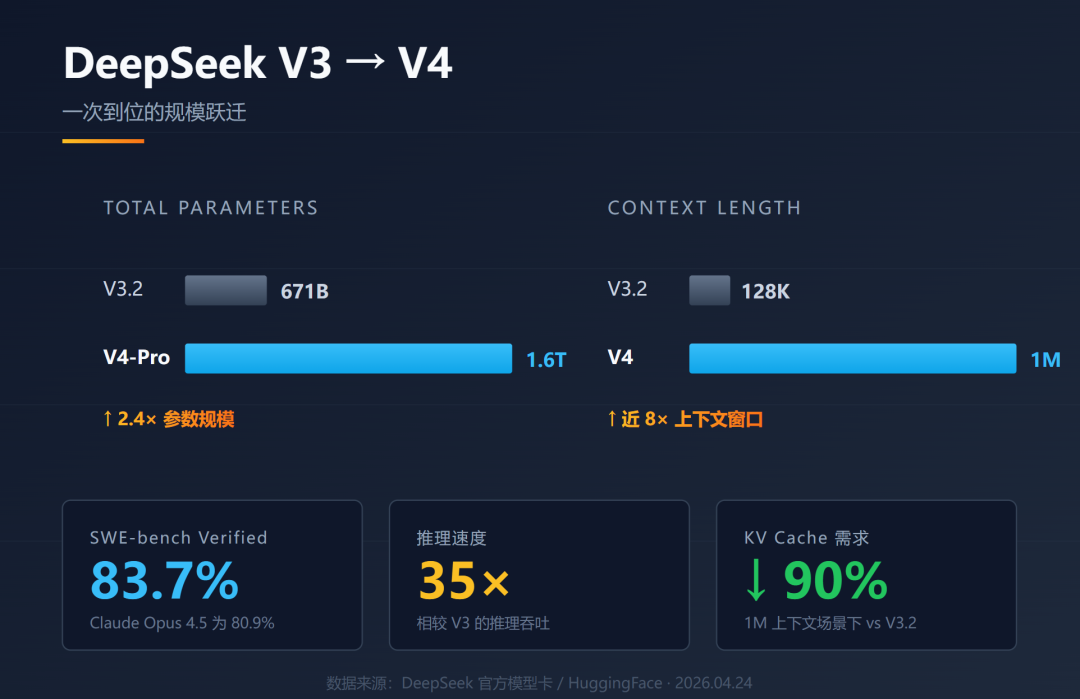
一、参数规模:一次到位的"万亿俱乐部"
这次 DeepSeek 一次给了两个版本:
| 版本 | 总参数 | 激活参数 | 上下文长度 |
|---|---|---|---|
| DeepSeek-V4-Pro | 1.6 万亿 | 49B | 1,000,000 tokens |
| DeepSeek-V4-Flash | 2850 亿 | 13B | 1,000,000 tokens |
几个关键信号:
-
1.6T 总参数
,正式迈入万亿俱乐部(作为参考,GPT-4 被推测在 1.5–2T 之间)。
-
49B 激活参数
,MoE 架构"按需激活专家",推理成本依旧控制得死死的。
-
100 万 tokens 上下文
,比前代 V3.2 的 128K 直接涨了近 10 倍——相当于一次性塞进《三体》三部曲还有富余。
🎨 规模跃迁:V3 vs V4
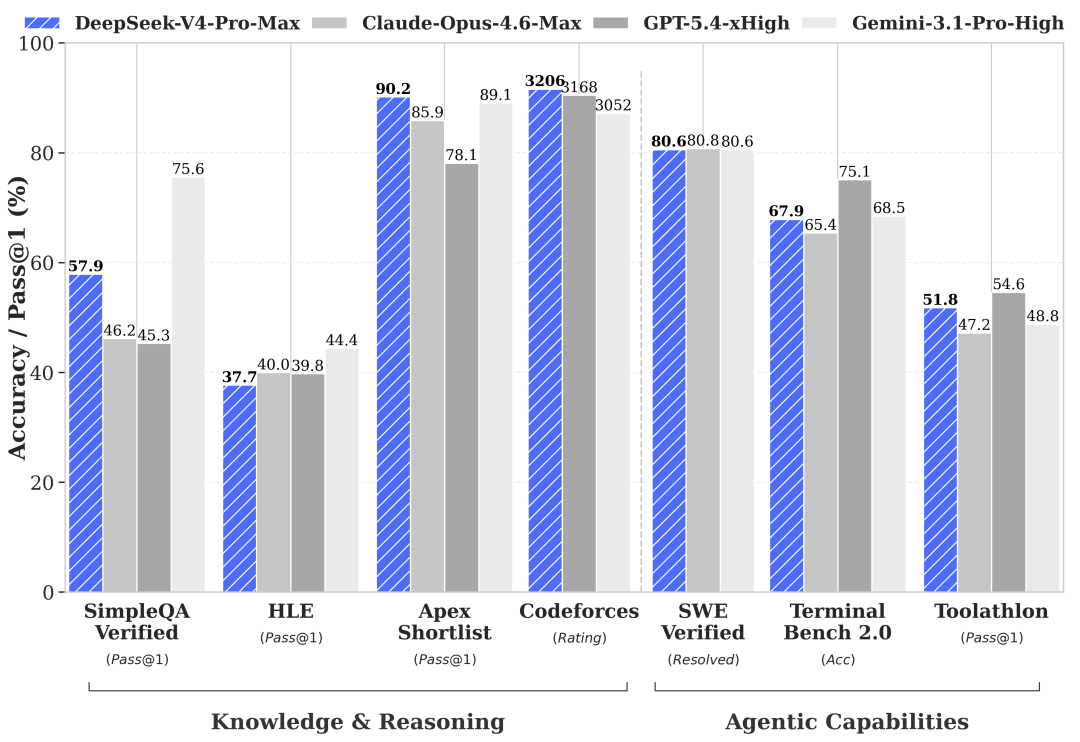
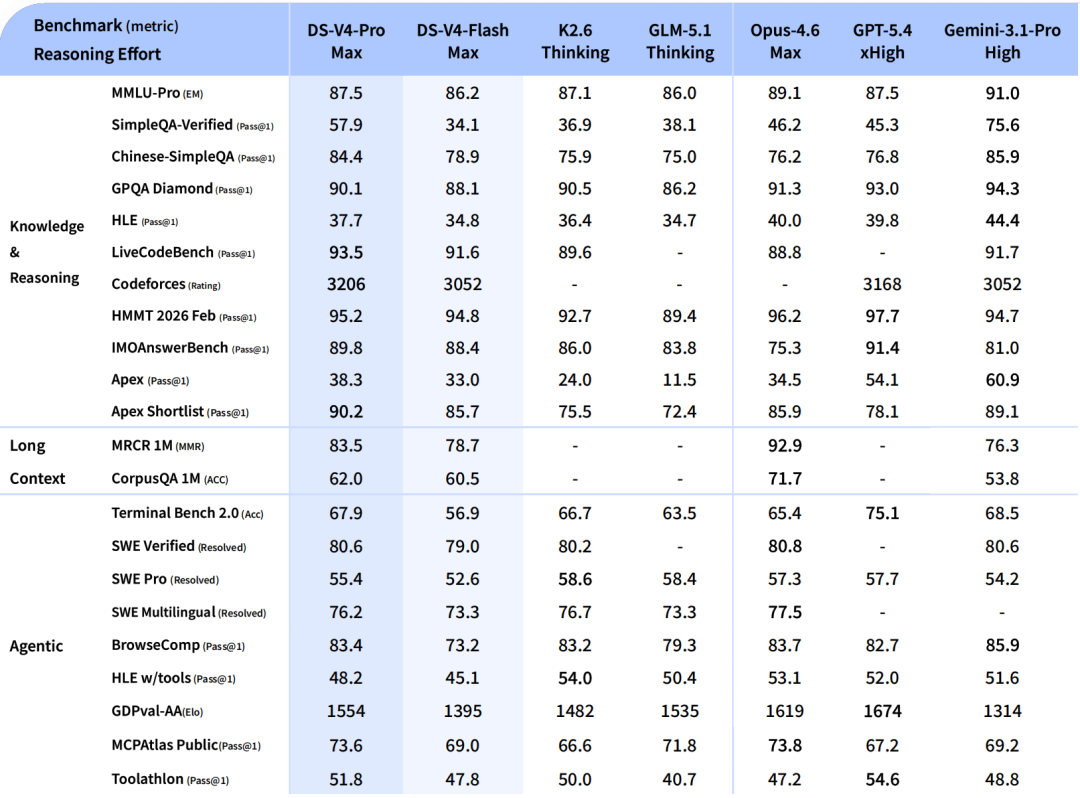
二、性能跑分:和 Claude、GPT 正面硬刚
根据官方及社区流出的基准测试数据:
- SWE-bench Verified:83.7%(Claude Opus 4.5 为 80.9%,GPT-5.2 为 80%)
- AIME 2026 数学:99.4%
- IMO Answer Bench:88.4%
- MMLU:92.8%
- HumanEval:90%
更关键的是工程指标:推理速度较 V3 提升 35 倍,能耗降低 40%。
这些数字当然还需要第三方独立复现,但信号已经足够明确——一款真正能与国际顶级闭源模型同台竞技的开源大模型,来了。
三、技术突破:不是堆参数,是真改架构
很多人把 V4 误解成"又一个更大的模型"。其实它的看点在架构层:
1. 混合注意力架构(Hybrid Attention)
V4 把**压缩稀疏注意力(CSA)和重度压缩注意力(HCA)**组合在一起,专治长上下文的计算爆炸问题。
官方数据非常惊人:在 1M token 场景下,V4-Pro 的单 token 推理 FLOPs 只需 V3.2 的 27%,KV Cache 仅需 10%。
翻译成人话——上下文拉长 10 倍,成本不仅没涨,反而大幅下降。
2. 流形约束超连接(mHC)
这是为万亿参数训练的"稳定剂"。参数越多,训练越容易"塌方"(梯度消失、不收敛)。mHC 相当于给每层之间的残差连接加了一层几何约束,让训练过程更丝滑。
3. 三档推理强度可选
Pro 和 Flash 都支持 Think Lite / Think / Think Max 三档推理预算,开发者可以按任务复杂度调档,不用再为"是否开 R1 模式"纠结。

🎨 V4 三大技术暗线
四、最硬核的信号:告别英伟达,全面拥抱昇腾
这才是 V4 真正"划时代"的地方。
在过去,大模型发布前通常会先交给英伟达、AMD 做适配优化。但 V4 这次,没带英伟达玩。
据多家媒体披露:
- DeepSeek V4 将优先运行在华为最新的昇腾芯片上;
- 工程师已完成从 CUDA 生态 → CANN 架构的底层代码迁移;
- 花了整整几个月与华为、寒武纪等国产硬件厂商做深度磨合。
这也是 V4 从"春节档"一路跳票到 4 月底的核心原因。背后的逻辑已经很清楚:
**当国产模型团队开始主动"软件定义硬件",CUDA 的护城河第一次被正面挑战了。**这不再是"能不能用英伟达"的问题,而是"要不要依赖英伟达"的问题。
结语:抓住大模型时代的职业机遇
AI大模型的发展不是“替代人类”,而是“重塑职业价值”——它淘汰的是重复性、低附加值的工作,却催生了更多需要“技术+业务”交叉能力的高端岗位。对于求职者而言,想要在这波浪潮中立足,不仅需要掌握Python、TensorFlow/PyTorch等技术工具,更要深入理解目标行业的业务逻辑(如金融的风险控制、医疗的临床需求),成为“懂技术、懂业务”的复合型人才。
无论是技术研发岗(如算法工程师、研究员),还是业务落地岗(如产品经理、应用工程师),大模型都为不同背景的职场人提供了广阔的发展空间。只要保持学习热情,紧跟技术趋势,就能在AI大模型时代找到属于自己的职业新蓝海。
最近两年大模型发展很迅速,在理论研究方面得到很大的拓展,基础模型的能力也取得重大突破,大模型现在正在积极探索落地的方向,如果与各行各业结合起来是未来落地的一个重大研究方向
大模型应用工程师年包50w+属于中等水平,如果想要入门大模型,那现在正是最佳时机
2025年Agent的元年,2026年将会百花齐放,相应的应用将覆盖文本,视频,语音,图像等全模态
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
扫描下方csdn官方合作二维码获取哦!

给大家推荐一个大模型应用学习路线
这个学习路线的具体内容如下:
第一节:提示词工程
提示词是用于与AI模型沟通交流的,这一部分主要介绍基本概念和相应的实践,高级的提示词工程来实现模型最佳效果,以现实案例为基础进行案例讲解,在企业中除了微调之外,最喜欢的就是用提示词工程技术来实现模型性能的提升

第二节:检索增强生成(RAG)
可能大家经常会看见RAG这个名词,这个就是将向量数据库与大模型结合的技术,通过外部知识来增强改进提升大模型的回答结果,这一部分主要介绍RAG架构与组件,从零开始搭建RAG系统,生成部署RAG,性能优化等

第三节:微调
预训练之后的模型想要在具体任务上进行适配,那就需要通过微调来提升模型的性能,能满足定制化的需求,这一部分主要介绍微调的基础,模型适配技术,最佳实践的案例,以及资源优化等内容

第四节:模型部署
想要把预训练或者微调之后的模型应用于生产实践,那就需要部署,模型部署分为云端部署和本地部署,部署的过程中需要考虑硬件支持,服务器性能,以及对性能进行优化,使用过程中的监控维护等

第五节:人工智能系统和项目
这一部分主要介绍自主人工智能系统,包括代理框架,决策框架,多智能体系统,以及实际应用,然后通过实践项目应用前面学习到的知识,包括端到端的实现,行业相关情景等

学完上面的大模型应用技术,就可以去做一些开源的项目,大模型领域现在非常注重项目的落地,后续可以学习一些Agent框架等内容
上面的资料做了一些整理,有需要的同学可以下方添加二维码获取(仅供学习使用)


作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)