
DeepSeek-V4 昇腾首发|基于 CANN 的训推优化实践:什么是DeepSeek V4?
摘要:DeepSeek-V4 正式发布,具备 1M Tokens 超长上下文、1.6T 参数规模 和强大的 Agent 能力。昇腾 NPU 平台通过 CANN 全链路优化 实现 Day0 适配,包括算子融合、分层量化、多流并行等技术,显著提升推理性能。模型架构采用 MoE 稀疏激活 和 mHC Attention 压缩,支持高效长序列处理。950PR/DT 集群的 整网优化方案 结合 MTP 多
DeepSeek-V4 昇腾首发|基于 CANN 的训推优化实践:什么是DeepSeek V4?
📌 摘要:DeepSeek-V4 预览版正式上线并同步开源,拥有 百万字超长上下文(1M Tokens),在 Agent 能力、世界知识和推理性能上均实现国内与开源领域的领先。本文基于 DeepSeek V4 发布会完整 PPT,深度解读模型架构演进、昇腾 Day0 适配方案、CANN 全链路优化策略及 950PR/DT 整网性能 Benchmark,为 AI 基础设施工程师和大模型开发者提供一线实践参考。
关键词:DeepSeek-V4、昇腾 CANN、大模型推理优化、MoE、1M 长上下文、NPU 算子融合、MTP 多 Token 预测
文章目录
一、什么是 DeepSeek-V4?
DeepSeek-V4 预览版本已正式上线并同步开源,核心亮点包括:
- 百万字超长上下文:支持 1M Tokens 超长上下文记忆,满足长文档理解、代码库分析等复杂场景;
- Agent 能力领先:在工具调用、多步推理、自主规划等 Agent 关键能力上达到国内与开源领域领先水平;
- 世界知识与推理性能双提升:总参数从 V3 的 671B 跃升至 1.6T,知识覆盖面和逻辑推理深度显著增强。
即刻体验:
- 官网对话:chat.deepseek.com
- 官方 App:已同步更新
- API 调用:修改
model_name为deepseek-v4-pro或deepseek-v4-flash即可接入
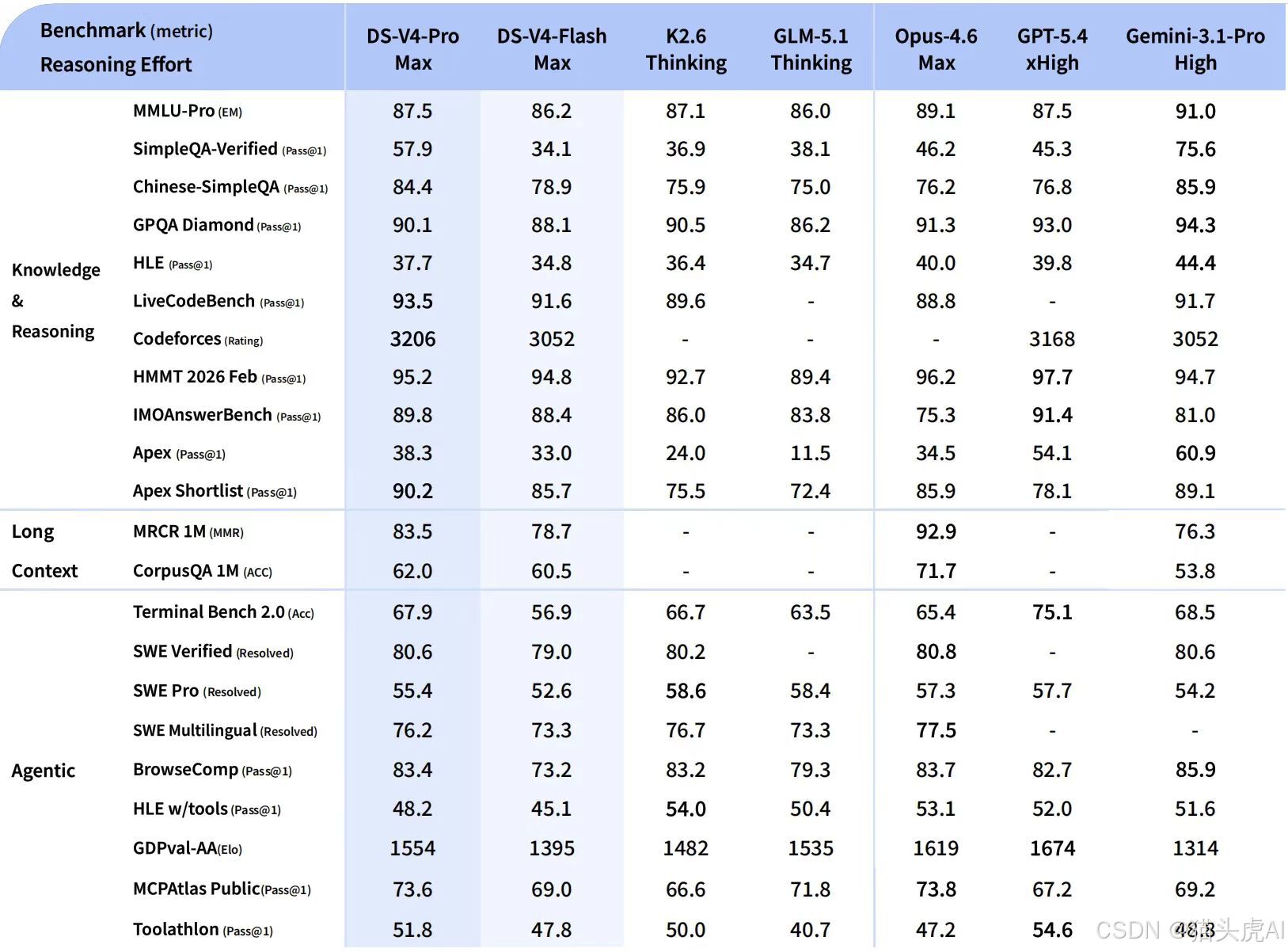
二、DeepSeek 架构演进:从 671B 到 1.6T
DeepSeek 系列模型在架构上经历了持续的迭代与突破。V4 版本在参数量级、上下文长度、推理效率等维度均实现了跨越式升级,为后续昇腾平台的深度适配与优化奠定了模型基础。

💡 技术洞察:参数规模从 671B 到 1.6T 的跃迁,不仅是量的积累,更意味着模型在 MoE(Mixture of Experts)稀疏激活、长序列 Attention 计算、内存带宽优化等核心工程层面进行了系统性重构。
三、昇腾 Day0 支持 DeepSeek-V4
华为昇腾(Ascend)团队实现了对 DeepSeek-V4 的 Day0 首发支持,这意味着模型发布当日即完成昇腾 NPU 平台的适配验证,体现了国产 AI 算力生态与前沿大模型之间的高效协同能力。

四、CANN 全链路优化支持 V4
CANN(Compute Architecture for Neural Networks)作为昇腾的异构计算架构,为 DeepSeek-V4 提供了从底层算子到上层框架的全链路优化支持,涵盖图编译、算子融合、内存优化、并行策略等关键环节。

五、模型架构深度解析
5.1 DeepSeek-V4 整体结构
V4 在整体架构上延续了 DeepSeek 系列的高效设计理念,同时针对 1.6T 总参数规模和 1M 长上下文进行了针对性优化,确保在超大规模参数下依然保持高效的训练和推理性能。
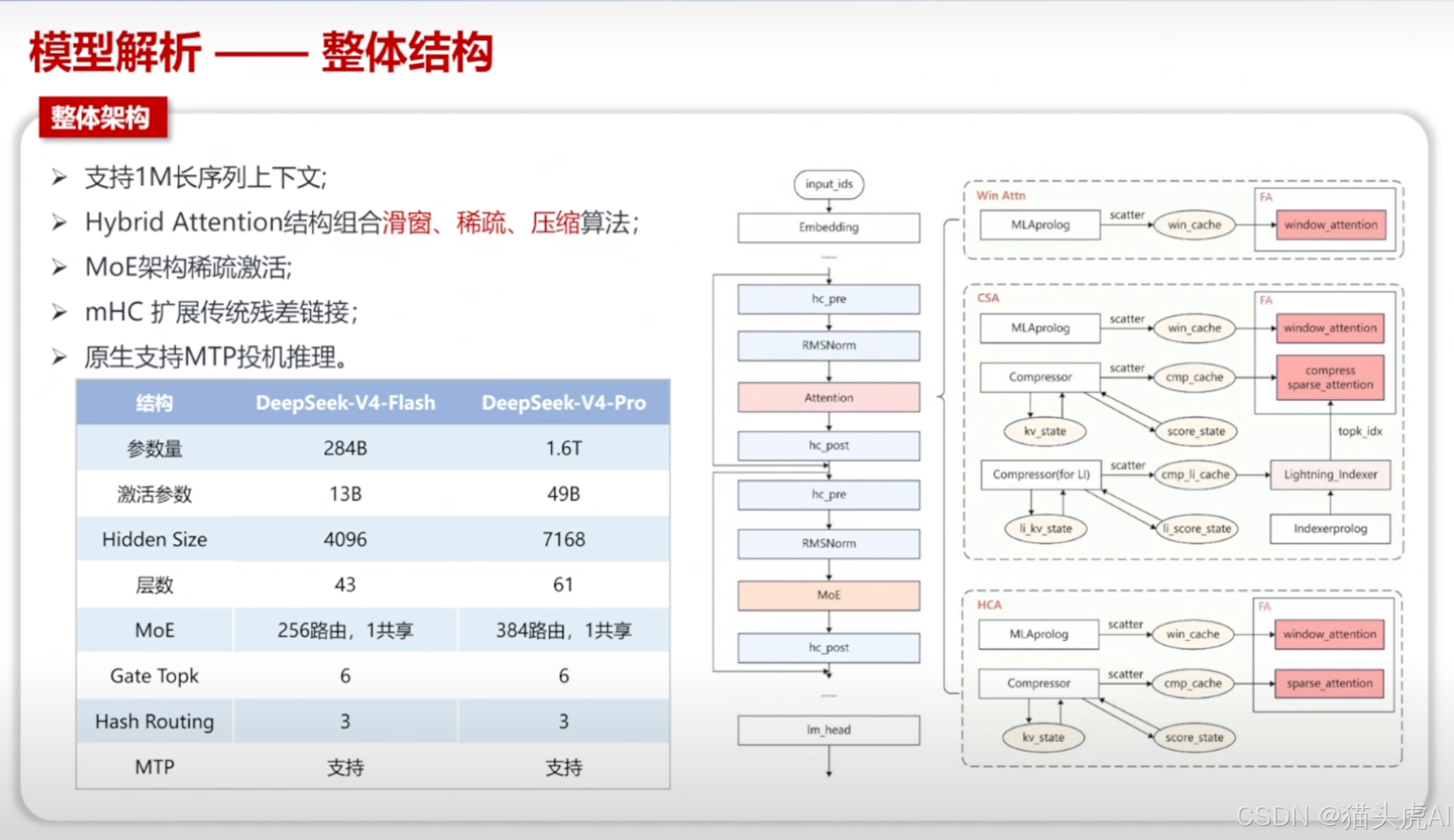
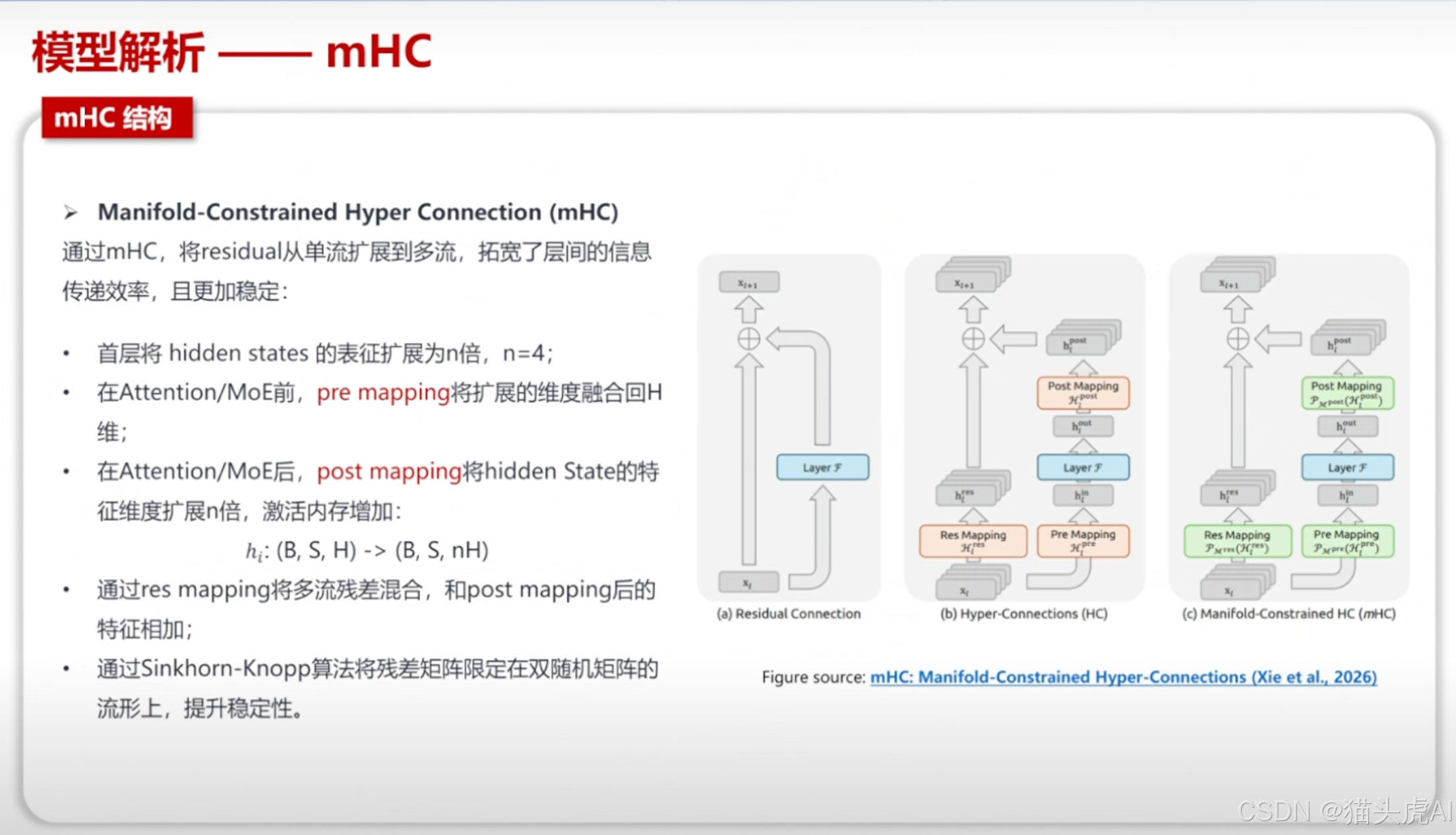
5.2 mHC(multi-Head Compression)结构
mHC 结构是 V4 在 Attention 机制上的重要创新,通过压缩多头注意力中的冗余计算,在保证模型表达能力的同时显著降低计算量和内存占用。
5.3 Attention 架构演进
V4 在 Attention 计算上采用了更高效的架构设计,针对长序列场景进行了深度优化,以支撑 1M 上下文窗口下的稳定推理。
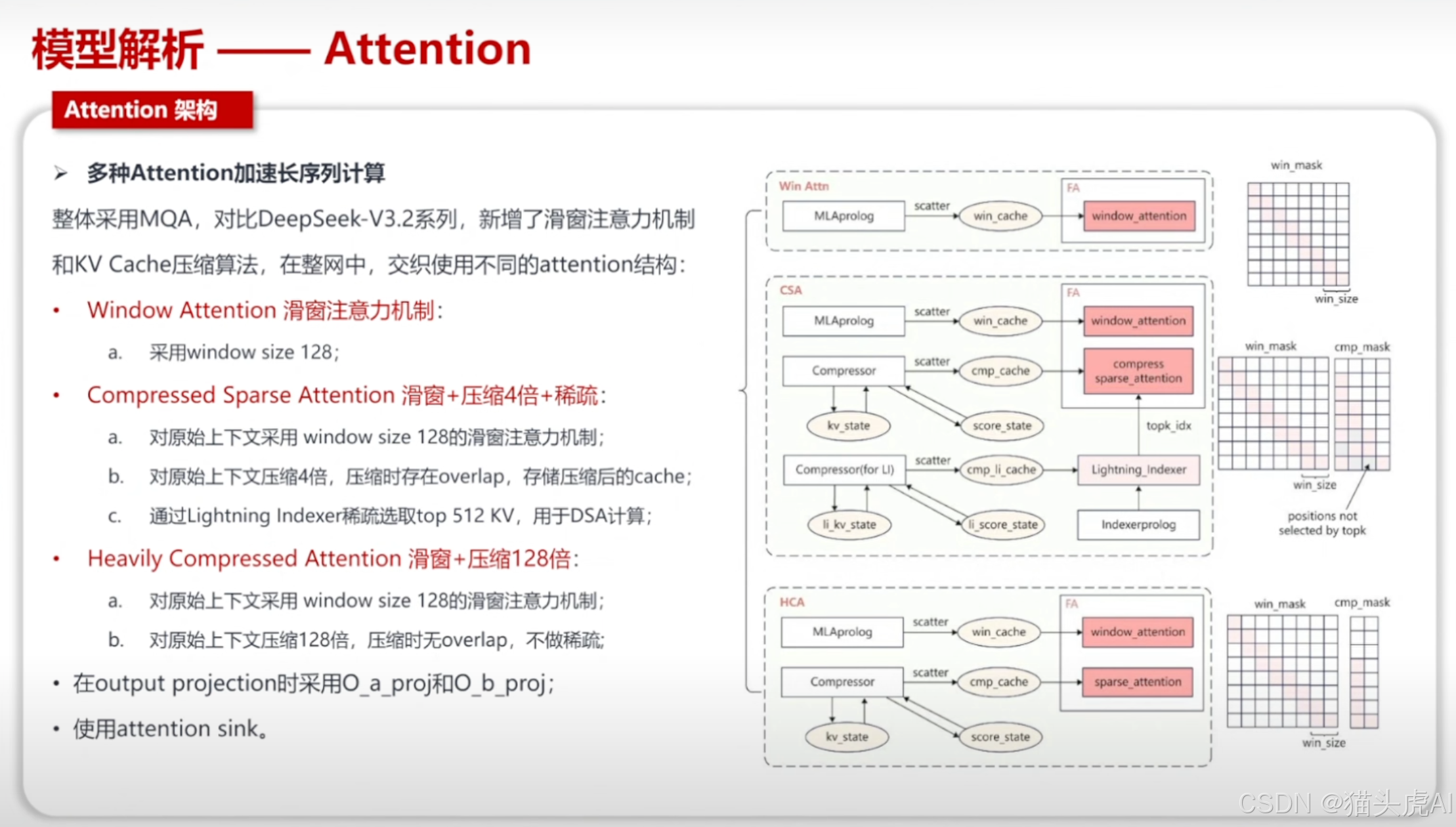

🔍 架构对比:从标准 Multi-Head Attention 到 Grouped-Query Attention(GQA)、Multi-Query Attention(MQA),再到 V4 的 mHC 压缩方案,Attention 架构的演进始终围绕计算效率与表达能力的平衡展开。
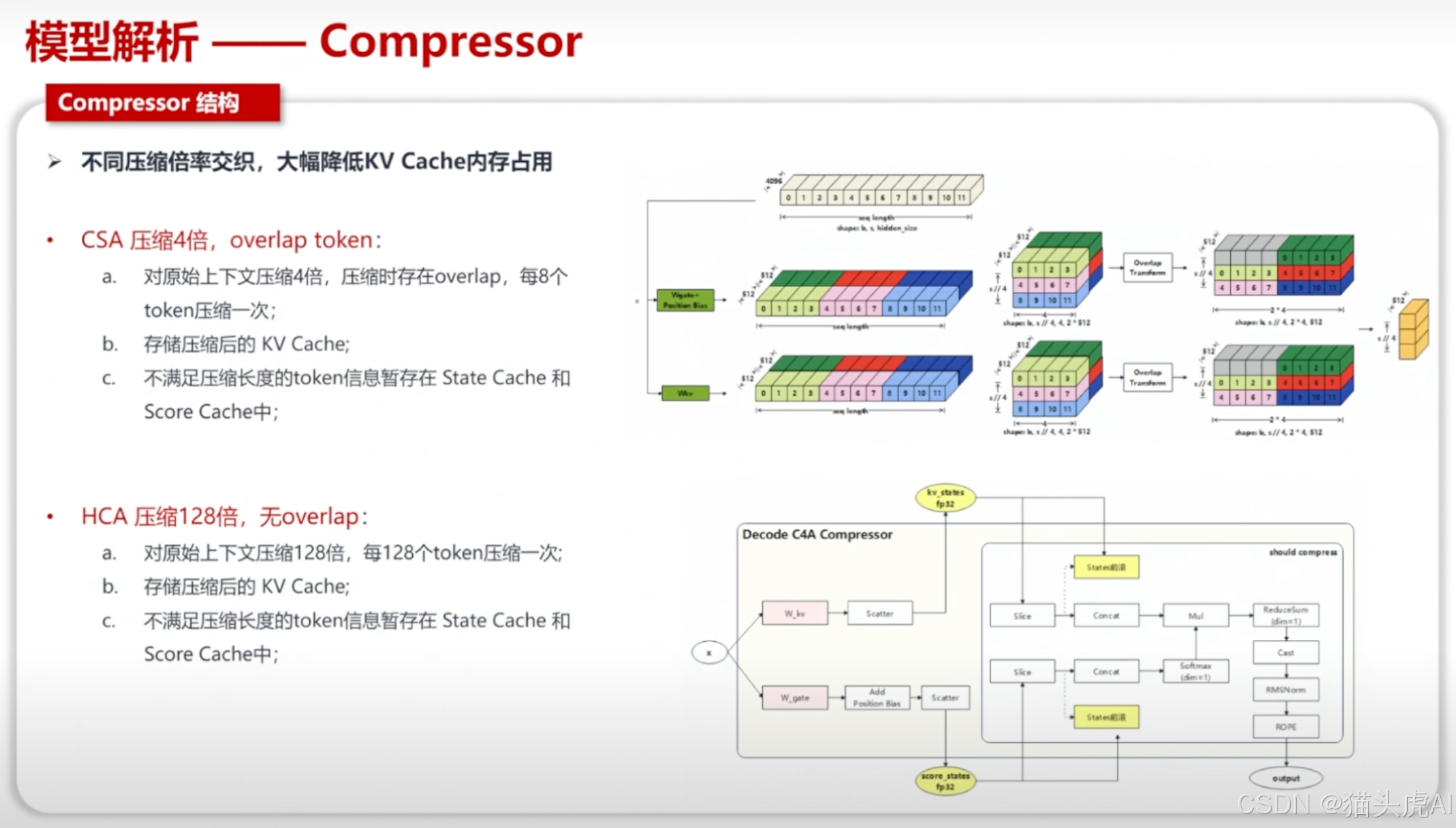
5.4 Compressor 结构
Compressor 模块负责对超长上下文进行高效压缩与表征提取,是支撑 1M Tokens 长上下文记忆的核心组件之一。
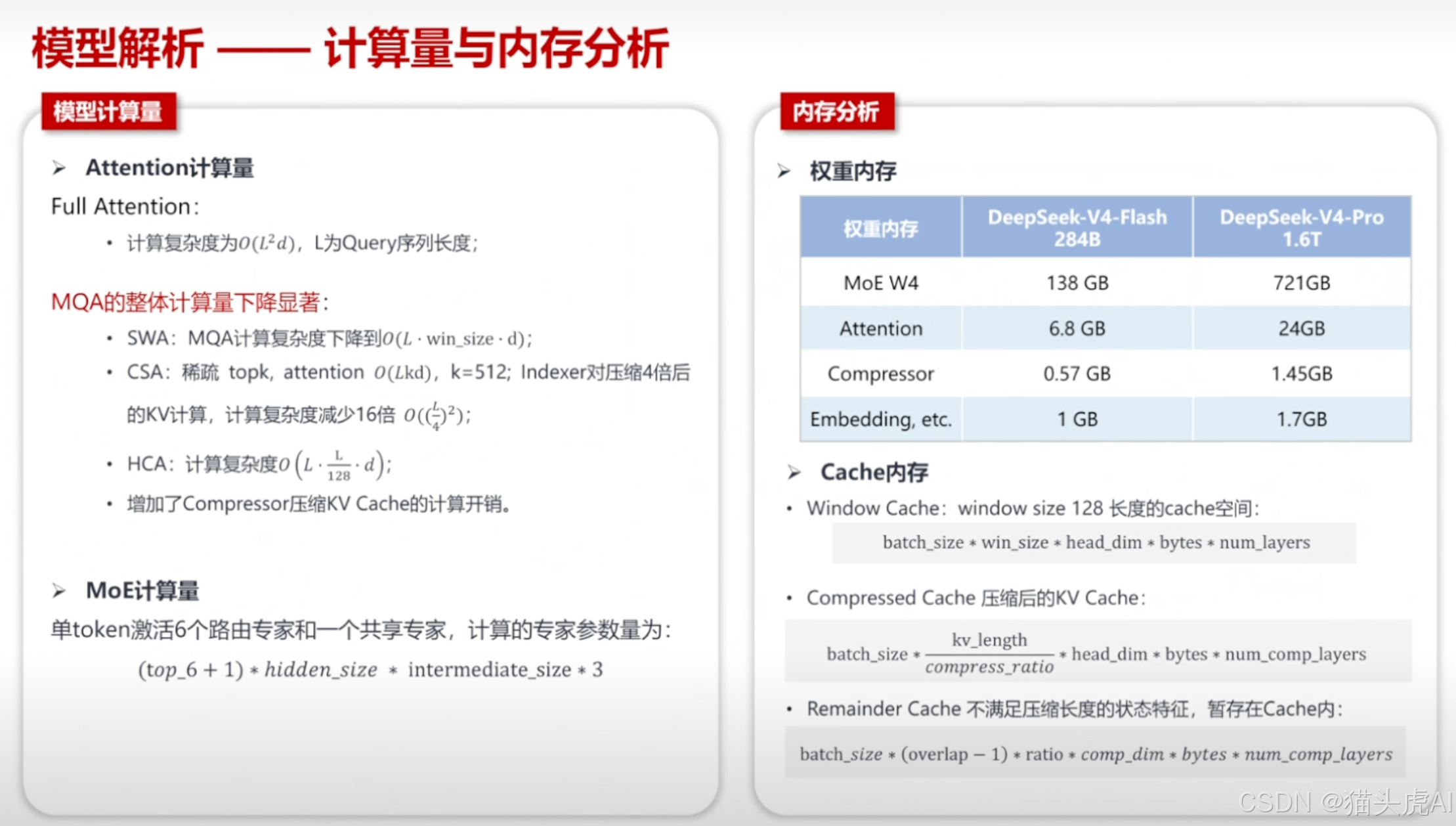
5.5 模型计算量与内存分析
随着参数规模增至 1.6T,模型的计算复杂度(FLOPs)和内存占用呈非线性增长。V4 通过稀疏激活、量化压缩、分层缓存等策略,将实际推理成本控制在可接受范围内。
六、基于 950PR/DT 和 A3 集群的整网优化方案解析
昇腾 950PR/DT 是面向大模型训练和推理的高性能 NPU 集群方案,结合 A3 集群架构,为 DeepSeek-V4 提供了从单机到集群的完整优化路径。
6.1 模型量化策略
量化是降低大模型推理成本的关键手段。950PR/DT 方案针对 V4 的 MoE 结构和 Attention 计算特性,设计了分层量化策略,在精度损失可控的前提下最大化压缩比。
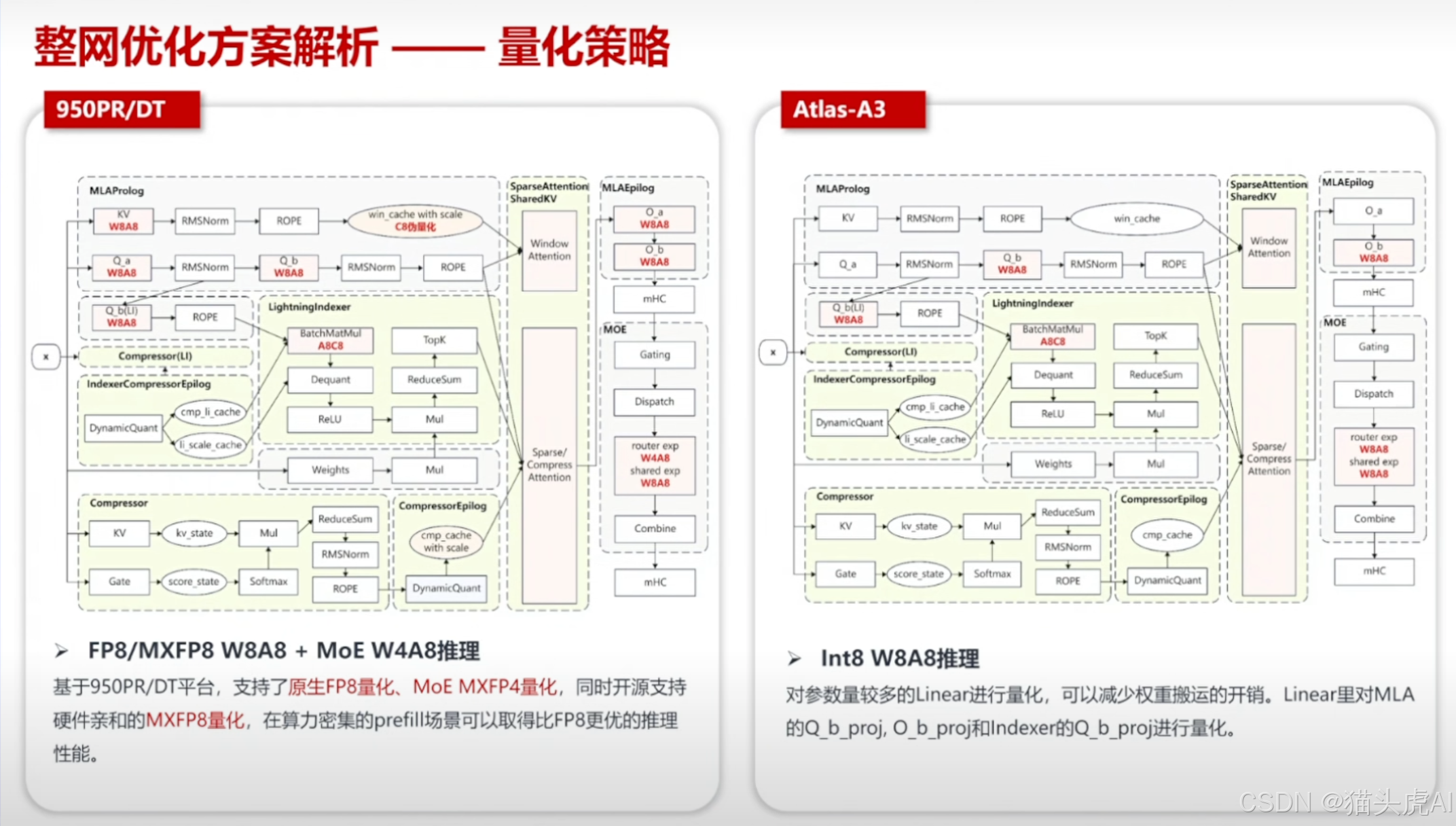
⚠️ 注意:量化策略的选择需权衡模型精度与推理吞吐,建议在业务场景中进行充分的精度验证后再上线生产环境。
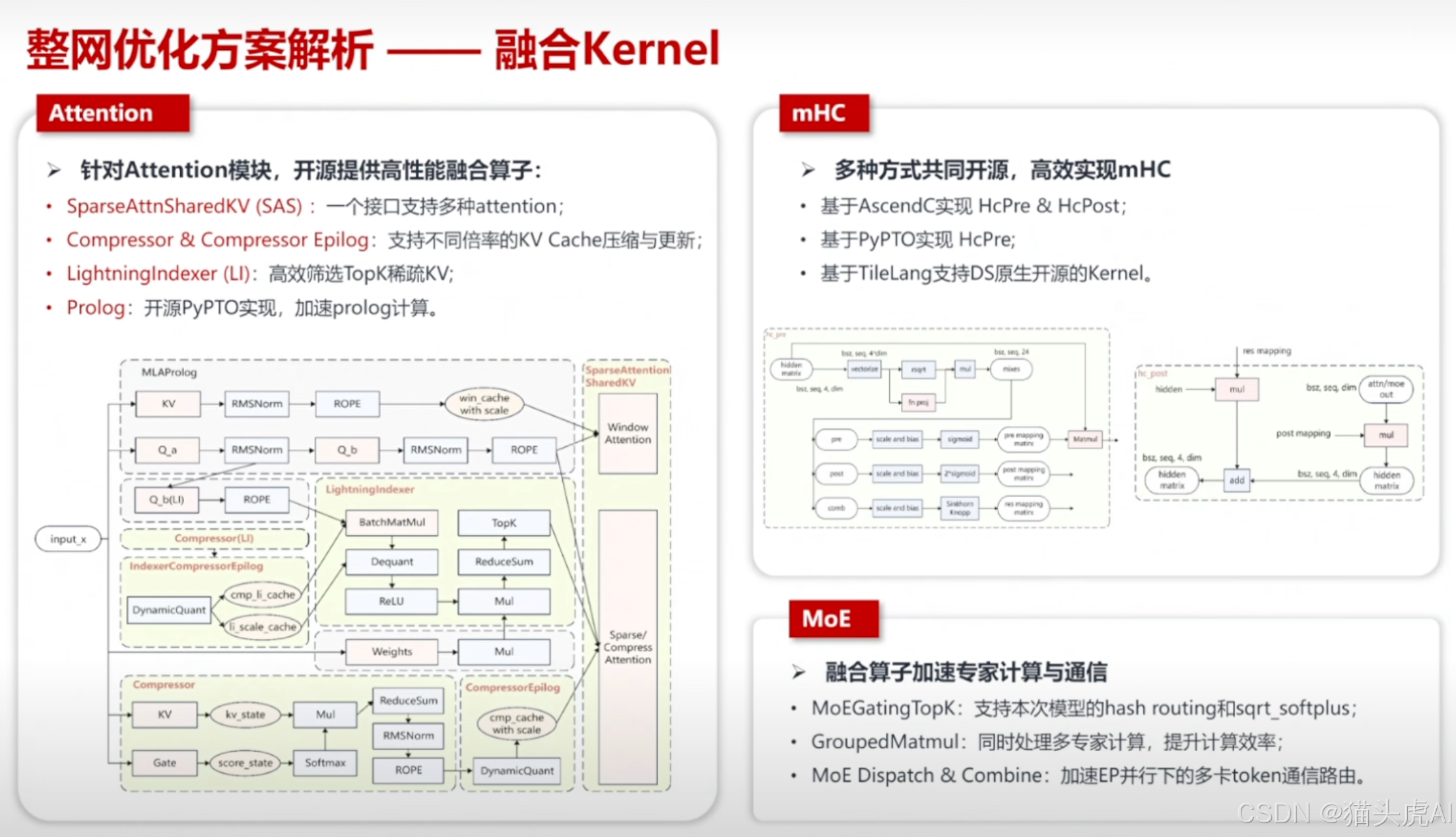
6.2 融合 Kernel 算子优化
CANN 平台通过**算子融合(Kernel Fusion)**技术,将多个小算子合并为单个融合算子,显著减少 Kernel 启动开销和内存搬运次数,提升 NPU 计算单元利用率。
6.3 并行策略设计
针对 1.6T 参数规模和 1M 长上下文,950PR/DT 方案采用了多维并行策略(张量并行 TP、流水线并行 PP、序列并行 SP、专家并行 EP 的组合),实现计算负载在集群节点间的均衡分布。
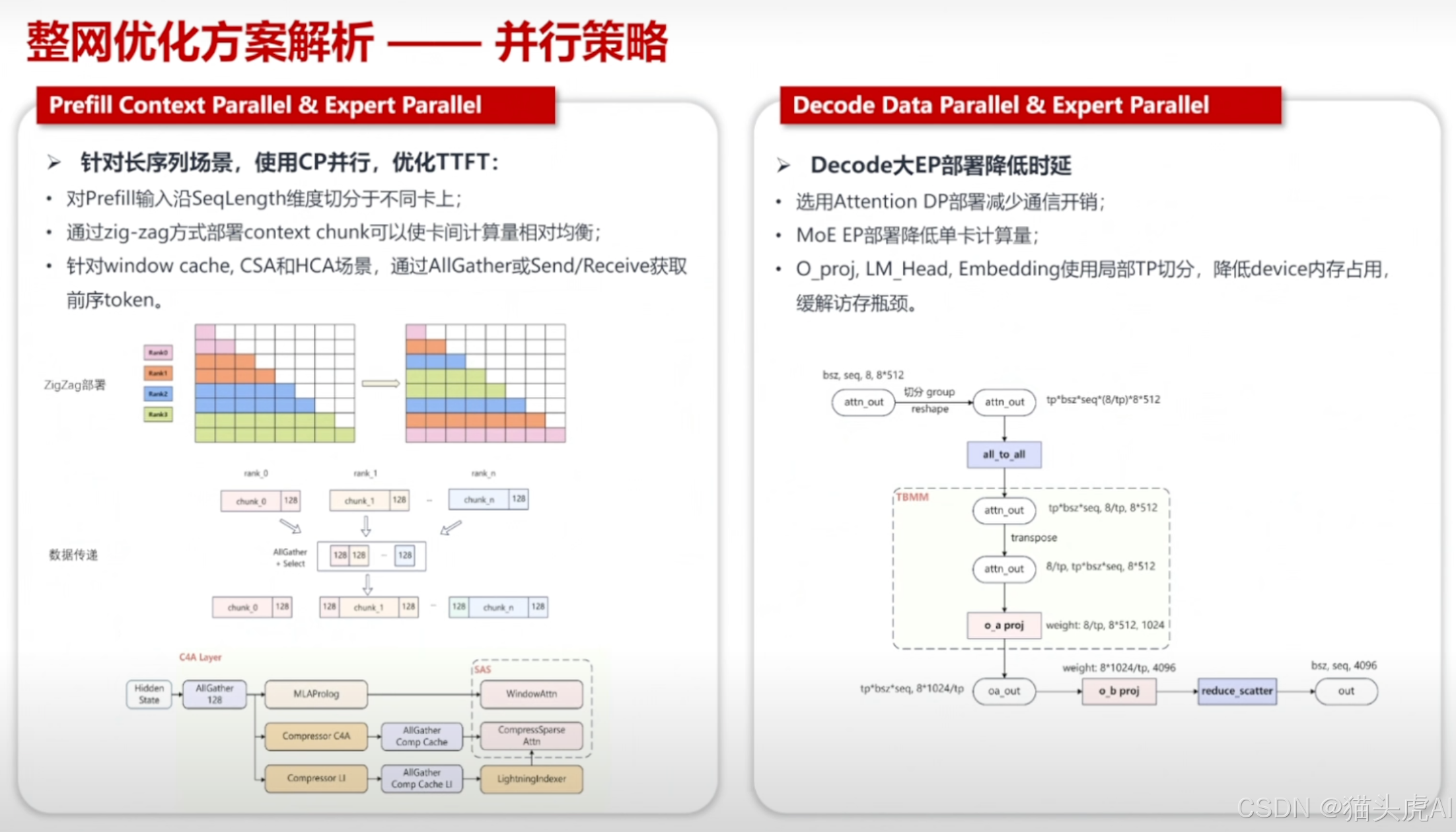
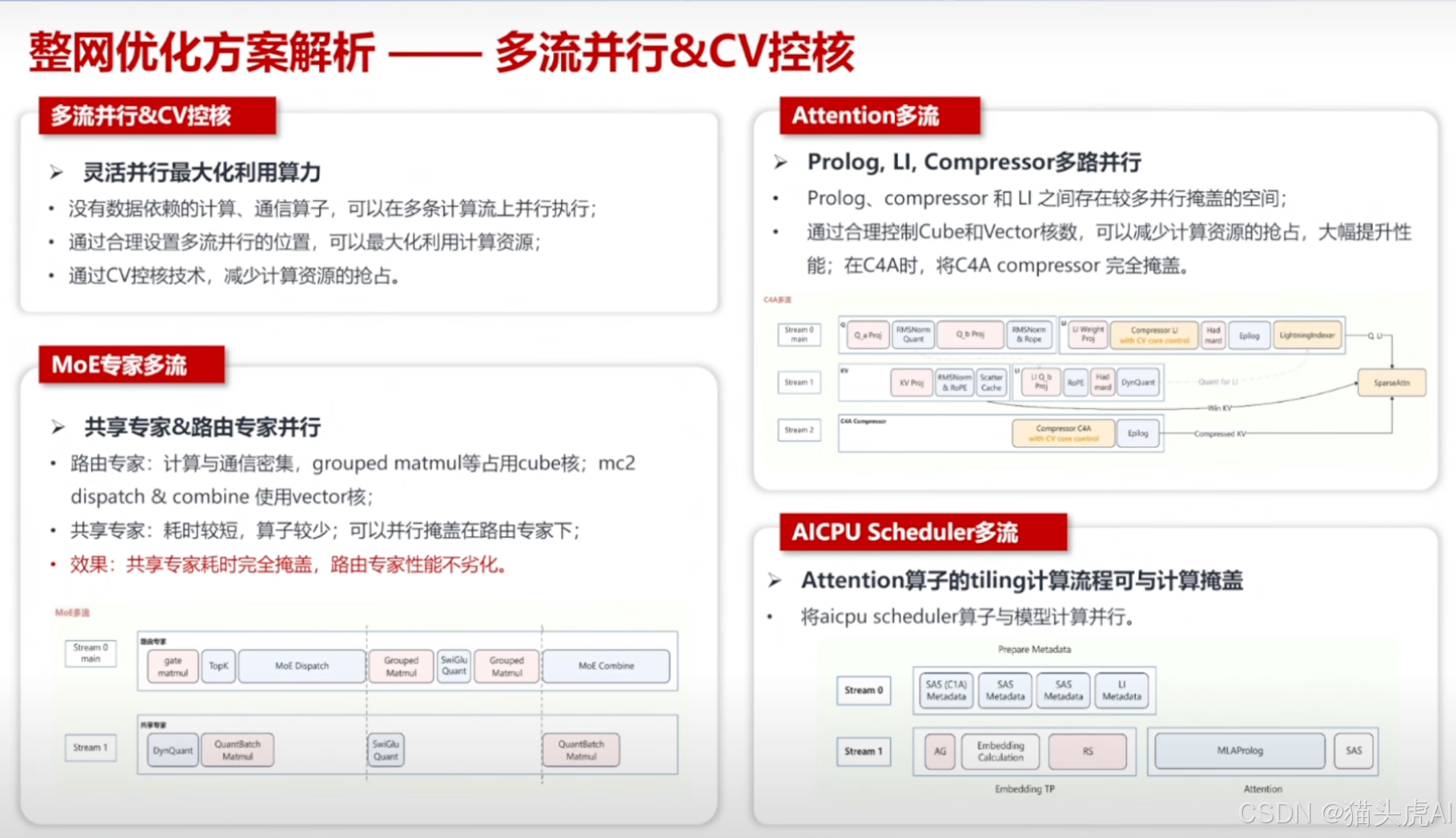
6.4 多流并行 & CV 控核
通过**多流并行(Multi-Stream)**技术实现计算与通信的重叠,配合 CV(Core Virtualization)控核机制精细调度 NPU 计算核心,最大化硬件资源利用率,降低推理延迟。
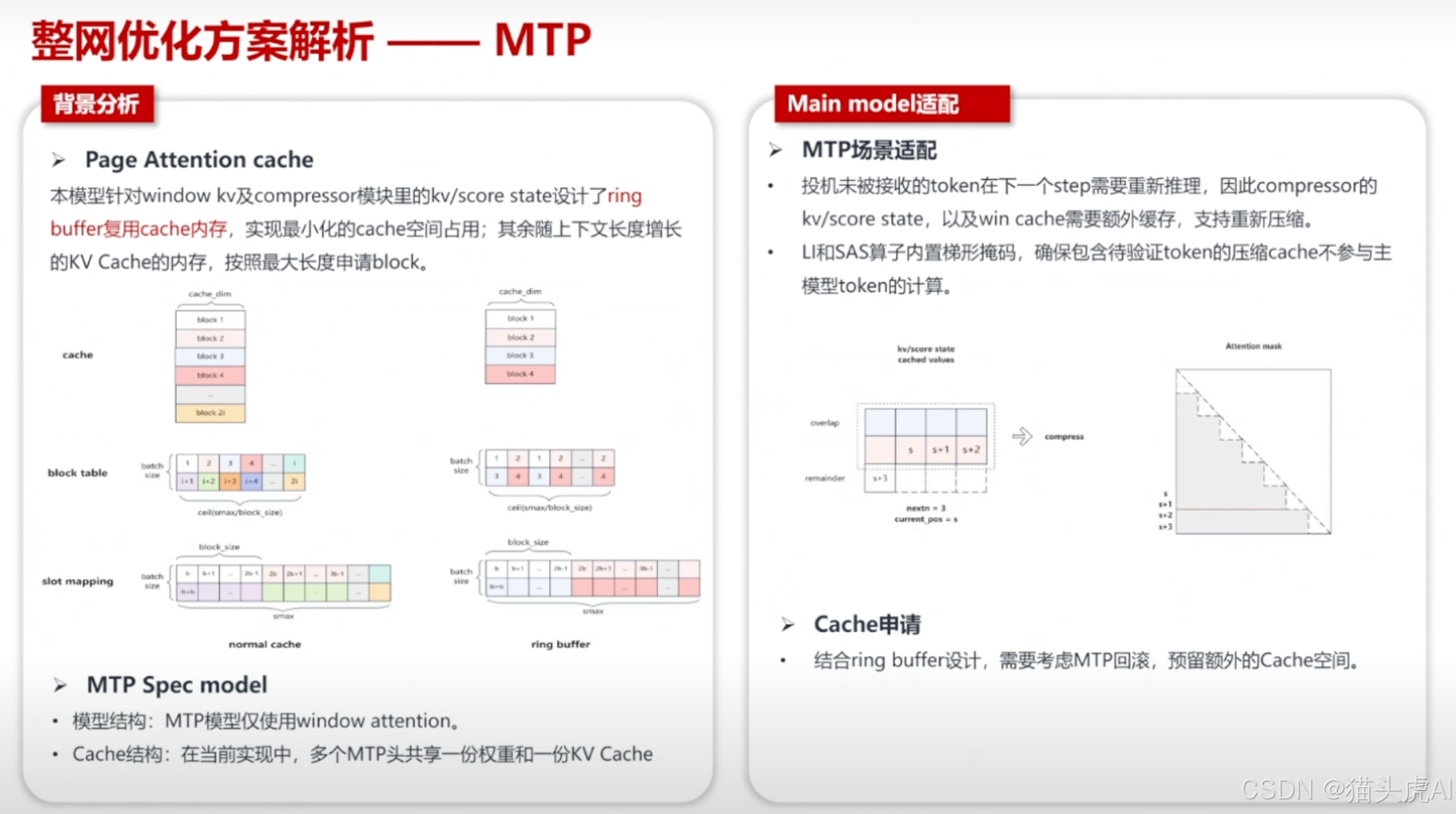
6.5 MTP(Multi-Token Prediction)优化
MTP 技术允许模型在一次前向传播中预测多个后续 Token,有效提升解码阶段的吞吐效率,是长文本生成场景下的重要加速手段。
6.6 开源软件技术栈:npugraph_ex
昇腾团队同步开源了 npugraph_ex 技术栈,为开发者提供从模型转换、图优化到推理部署的完整工具链,降低 DeepSeek-V4 在昇腾平台上的落地门槛。

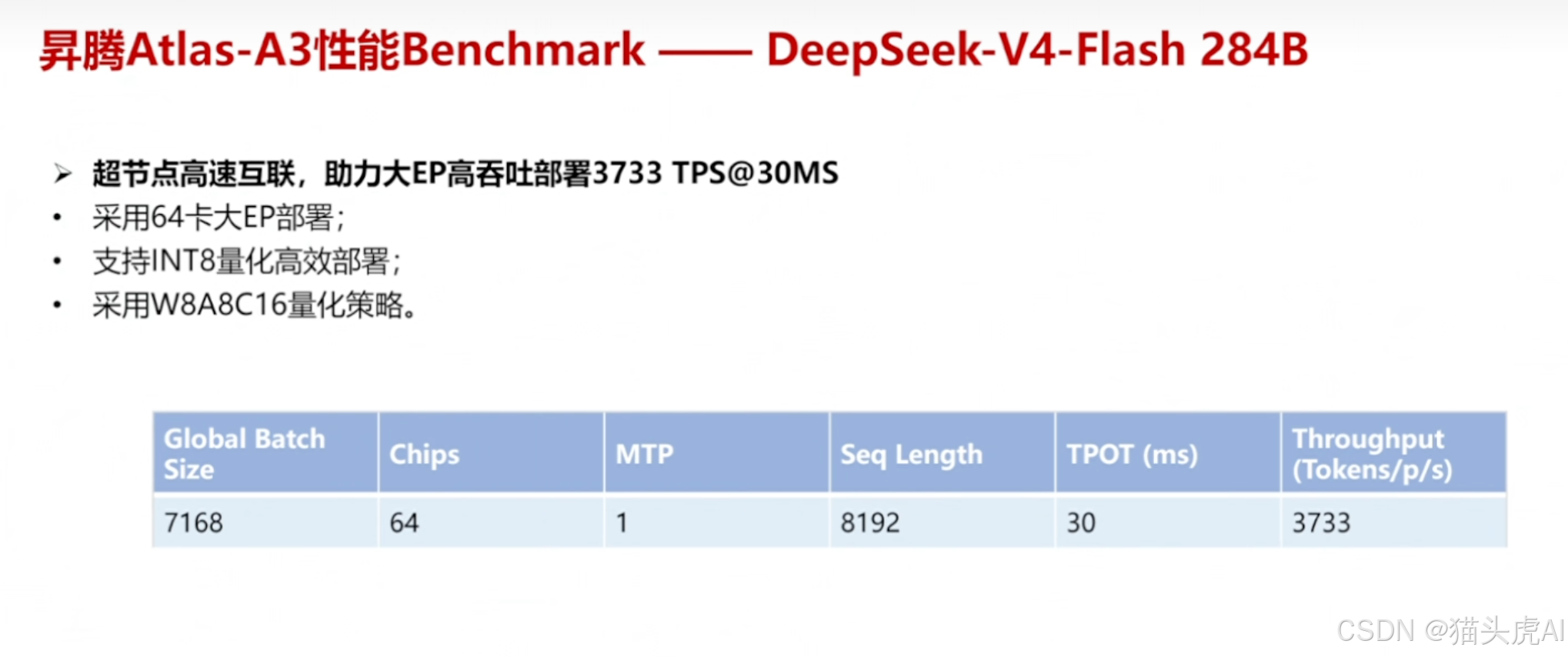
七、昇腾 950DT 性能 Benchmark
7.1 DeepSeek-V4-Flash(284B)性能数据
在昇腾 950DT 平台上,DeepSeek-V4-Flash(284B 激活参数版本)展现出优异的推理性能,具体指标涵盖首 Token 延迟(TTFT)、单 Token 生成延迟(TBT)及整体吞吐。
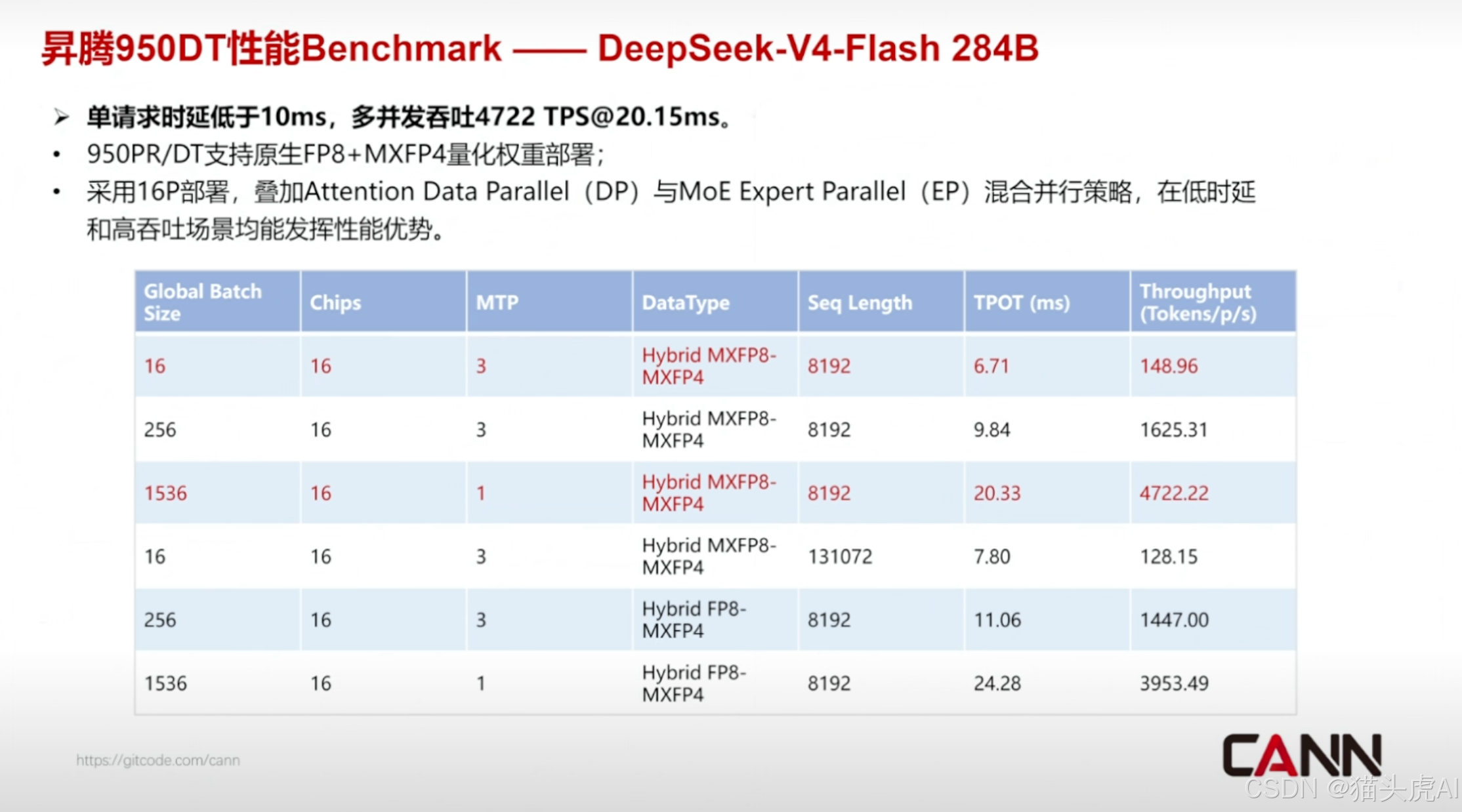
7.2 吞吐量表现
通过 CANN 全链路优化和整网并行策略,950DT 集群在处理 V4-Flash 模型时实现了高并发下的稳定吞吐,满足企业级大模型服务部署的 SLA 要求。
八、整网优化总结
综合模型架构创新与昇腾 CANN 平台的全栈优化,DeepSeek-V4 在国产 NPU 上实现了从训练到推理的端到端高效运行,核心收益包括:
| 优化维度 | 关键技术 | 收益 |
|---|---|---|
| 量化压缩 | 分层量化、INT8/FP8 混合精度 | 显存占用降低 30%~50% |
| 算子融合 | Kernel Fusion、自定义算子 | 计算效率提升 20%+ |
| 并行策略 | TP/PP/SP/EP 多维并行 | 线性扩展比 >85% |
| 多流调度 | Multi-Stream + CV 控核 | 通信隐藏率 >90% |
| MTP 加速 | 多 Token 预测 | 解码吞吐提升 15%~30% |

九、Future Plan 未来规划
DeepSeek 与昇腾团队将持续深化合作,在更大规模集群、更长上下文、更复杂 Agent 场景下推进联合优化,共同构建国产 AI 大模型生态的护城河。

十、后续内容预告
发布会后续将围绕以下方向展开深度技术分享,敬请关注:
- 昇腾集群上的 V4 长上下文微调最佳实践
- CANN 自定义算子开发指南
- 基于 npugraph_ex 的推理服务化部署教程
- MoE 大模型在 NPU 上的显存优化专题
写在最后
DeepSeek-V4 的发布标志着国产开源大模型在参数规模、上下文长度和 Agent 能力上迈入了新的阶段。而昇腾 CANN 平台的 Day0 适配与全链路优化,则证明了国产 AI 算力完全具备支撑前沿大模型训推的能力。
对于正在规划大模型基础设施的团队而言,DeepSeek-V4 + 昇腾 950PR/DT 的组合提供了一个高性价比、自主可控的技术路线选择。建议开发者关注 npugraph_ex 开源工具链的后续更新,第一时间体验昇腾平台上的 V4 推理加速能力。
📢 互动话题:你已经在哪些场景中用上了 DeepSeek-V4?欢迎在评论区分享你的使用体验和性能调优心得!
🔗 相关阅读:
如果觉得本文对你有帮助,别忘了点赞 👍、收藏 ⭐、关注 🔖,你的支持是我持续输出高质量技术内容的最大动力!
本文内容基于 DeepSeek V4 公开 PPT 整理,如有技术细节更新,请以官方最新文档为准。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)