
DeepSeek V4 正式发布:双版本齐发,百万上下文普惠时代来了!
千呼万唤始出来!在沉寂了 15 个月后,DeepSeek 终于在北京时间 4 月 24 日正式发布了全新一代模型——DeepSeek-V4 预览版。没有发布会,没有预热,一篇公众号推文,一个 API 文档更新,就这么低调地“炸场”了。但低调的背后,是硬核的实力:双版本、百万上下文、比肩闭源模型的性能,还有与华为昇腾芯片的深度适配。

V4 Pro vs V4 Flash:一张表看懂该怎么选
跟此前传闻一致,V4 一口气发了两个版本。两者都原生支持 100 万 token 上下文,最大输出 384K tokens,并且同时搭载“非思考模式”与“思考模式”。但到底选哪一个?下面这张核心参数对比表,让你一目了然:
| 对比维度 | DeepSeek-V4-Pro | DeepSeek-V4-Flash |
| 总参数规模 | 1.6T | 284B |
| 激活参数 | 49B | 13B |
| 上下文窗口 | 1M tokens | 1M tokens |
| 最大输出长度 | 384K tokens | 384K tokens |
| 思考模式 | ✅ 支持(high / max) | ✅ 支持(high / max) |
| 核心定位 | 极致性能,攻克复杂推理 | 轻量高速,极致性价比 |
| 推荐场景 | 高难度 Agentic Coding、长程规划、科研推理 | 日常对话、一般性代码辅助、大批量 API 调用 |
简单来说,追求极限表现,V4-Pro 是当之无愧的旗舰;如果看重响应速度与成本控制,V4-Flash 就是那把最快最轻的“快刀”。

百万上下文成标配,背后是一套聪明的注意力设计
从今天起,1M 上下文成为 DeepSeek 所有官方服务的标配。一年前,百万上下文还是少数闭源模型的奢侈功能,而 V4 不仅做到了,还把成本打了下来。
技术秘密是全新的 混合注意力架构——CSA(压缩稀疏注意力) 与 HCA(重度压缩注意力)。
CSA 把每 4 个 token 压缩成一个信息块,再用稀疏检索精准定向;HCA 则进行更极致的压缩,维持稠密计算的高效性。

效果究竟多夸张?直接看数据:
| 推理效率指标 | V3.2(128K) | V4-Pro(1M) | V4-Flash(1M) |
| 单 token 推理 FLOPs | 基准(100%) | 仅 27% | 仅 10% |
| KV Cache 占用 | 基准(100%) | 仅 10% | 仅 7% |
上下文从 128K 扩展到 1M,理论信息承载量扩大近 8 倍,但算力需求不升反降。这就是 V4“既要又要还要”的底气。
此外,V4 还引入 流形约束超连接(mHC) 增强信号传播,搭配 Muon 优化器,进一步提升训练稳定性与收敛速度。
Agent 能力大考:开源最强,部分指标触平闭源
Agent 能力是 V4 的主打升级点。官方直言,V4-Pro 在 Agentic Coding 上已达 当前开源模型最佳水平,内部员工已将 V4 作为日常 Agent 工具,感受是:优于 Claude Sonnet 4.5,接近 Opus 4.6 非思考模式,但与 Opus 4.6 思考模式仍有差距。
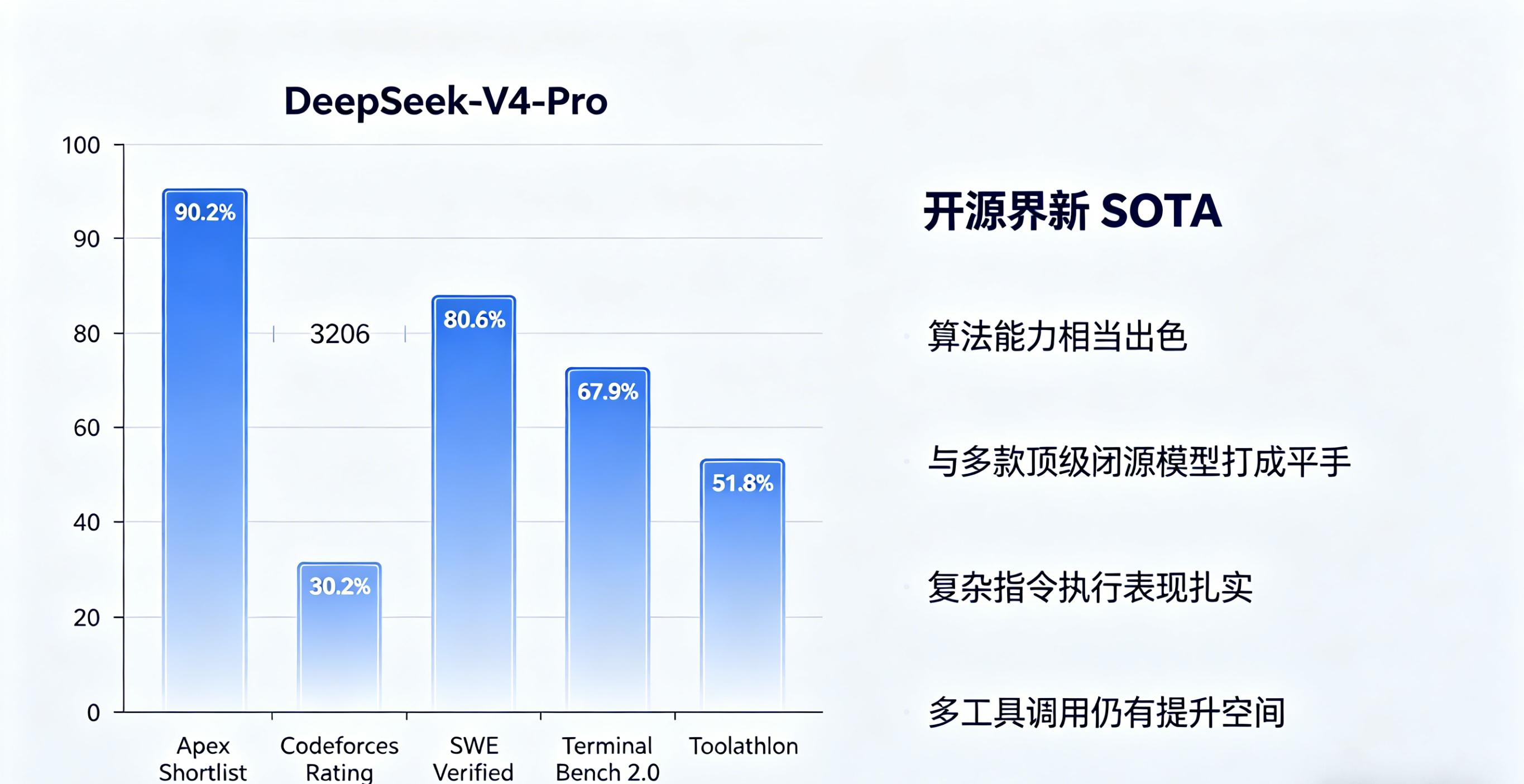
DeepSeek 给出的定位客观冷静——整体大约 滞后前沿闭源模型 3 至 6 个月。不过,多项硬核评测的数字仍然亮眼,我们可以通过下面这张成绩单来感受:
| 评测任务 | DeepSeek-V4-Pro | 横向对比参考 |
| Apex Shortlist | 90.2% | 极强推理标杆 |
| Codeforces Rating | 3206 | 算法能力相当出色 |
| SWE Verified | 80.6% | 与多款顶级闭源模型打成平手 |
| Terminal Bench 2.0 | 67.9% | 复杂指令执行表现扎实 |
| Toolathlon | 51.8% | 多工具调用仍有提升空间 |
不算意外的是,在经典的“绝望的父亲”生物遗传学情景题里,V4 还是踩了一次坑——父系红绿色盲的关键逻辑点,第一轮没能抓住。顶级大模型,同样还在进化。
华为昇腾芯片深度适配,国产算力迈出里程碑式一步
V4 发布的一大彩蛋,是与 华为昇腾芯片的深度适配。
官方明确表示,V4 从模型设计之初就已深度适配国产算力,并在华为昇腾芯片生态上完成实测跑通,成为全球首个在国产算力底座上完成训练与推理的万亿参数级模型。寒武纪也在当天宣布完成基于 vLLM 推理框架的 Day 0 适配。
这标志着中国 AI 产业在“去 CUDA 化”的探索中实现了一次关键跃迁。当然,受限于高端算力供给,目前 Pro 版本的吞吐量还比较有限,预计下半年昇腾 950 超节点批量上市后,局面会大幅改善。
极致性价比,价格又“卷”到了新高度
在 API 定价上,DeepSeek 又一次摆出了“打穿地板”的架势:
| 模型 | 输入价格(缓存命中) | 输入价格(缓存未命中) | 输出价格 | 竞品参考(OpenAI GPT-5.5) |
| DeepSeek-V4-Flash | 0.2 元 / 百万 token | 1 元 / 百万 token | 2 元 / 百万 token | 输入 5 美元,输出 30 美元 |
| DeepSeek-V4-Pro | 1 元 / 百万 token | 12 元 / 百万 token | 24 元 / 百万 token | (约 36 元 / 216 元) |
注:1 美元 ≈ 7.2 元人民币,GPT-5.5 不区分缓存命中。V4-Flash 的输入起步价仅为 GPT-5.5 的 1/180 级别。
对于开发者来说,只需修改 model_name 为 deepseek-v4-pro 或 deepseek-v4-flash,即可通过 OpenAI Chat Completions 接口或 Anthropic 接口直接调用。
写在最后
V4 的发布,从技术层面看,是混合注意力架构对长上下文成本的彻底重构;从产业层面看,是国产算力从“能用”到“好用”的关键一跃;从用户角度看,是百万上下文真正步入“家用电器”级普惠的时刻。
DeepSeek 在发布推文末尾,引用了《荀子·非十二子》中的一句话:
“不诱于誉,不恐于诽,率道而行,端然正己。”
这份超然与定力,或许正是他们能在喧嚣中持续突破的底色。
即日起,登录 chat.deepseek.com 或官方 App,就可以亲自体验 V4 的强大能力。
你对 DeepSeek V4 有什么期待或真实体感?欢迎在评论区聊聊。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)