
GLM-5.1 发布:SWE-Bench Pro 58.4% 登顶全球第一,智谱 AI 终于出手了
2026年4月7日,智谱 AI 旗下平台 Z.ai 发布并开源 GLM-5.1。SWE-Bench Pro 拿下 58.4%,全球第一,超越 GPT-5.4(57.7%)和 Claude Opus 4.6(57.3%)。单次任务自主工作 8 小时,MIT 协议完全开源。还有一个被低估的细节:全程用华为昇腾 910B 训练,零英伟达。
🤵♂️ 个人主页:小李同学_LSH的主页
✍🏻 作者简介:LLM学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
📖 前言:「智谱 AI」变成「Z.ai」,这是一次蛰伏后的出击
什么是 Task-Completion Time Horizon?
一句话开门见山:2026年4月7日,智谱 AI 旗下平台 Z.ai 发布并开源 GLM-5.1。SWE-Bench Pro 拿下 58.4%,全球第一,超越 GPT-5.4(57.7%)和 Claude Opus 4.6(57.3%)。单次任务自主工作 8 小时,MIT 协议完全开源。还有一个被低估的细节:全程用华为昇腾 910B 训练,零英伟达。

📌 基本信息
- 📅 发布时间:2026年4月7日
- 🏢 出品:Z.ai(智谱 AI 旗下平台)
- ⚙️ 架构:GlmMoeDSA,754B 总参数(~40B 激活)
- 📖 上下文:200K Token,最大输出 128K
- 🔓 开源:MIT License,HuggingFace(zai-org/GLM-5.1)
- 🖥️ 训练芯片:华为昇腾 910B(零英伟达)
📖 前言:「智谱 AI」变成「Z.ai」,这是一次蛰伏后的出击
在国内大模型圈,智谱 AI 是一个特殊的存在。
它是清华大学唐杰团队孵化的公司,GLM 系列是国内最早一批开源大模型,技术积累深厚。但过去一年里,DeepSeek 的横空出世、Kimi 的强势崛起、阿里 Qwen 的持续迭代,让智谱的声音越来越小。
直到 4月7日,Z.ai(原智谱 AI 更名)深夜发布 GLM-5.1。
一张 SWE-Bench Pro 排行榜截图开始在 AI 圈流传——第一名,是一个中文名字。
这是国产开源模型,第一次在软件工程最重要的基准测试上,击败了所有顶尖闭源模型。
本文适合:
- 🎓 想了解 GLM-5.1 技术细节的学生
- 🧑💻 在评估编程 AI 工具的开发者
- 🎯 关注国产 AI 竞争格局的同学
🎯 速览核心规格
| 指标 | GLM-5.1 |
|---|---|
| 发布方 | Z.ai(智谱 AI) |
| 总参数 | 754B(MoE) |
| 激活参数 | ~40B(每 Token 激活 8+1 个专家) |
| 架构 | GlmMoeDSA(Gated DeltaNet + 标准 Attention + 稀疏 MoE) |
| 上下文窗口 | 200K Token |
| 最大输出 | 128K Token |
| 长程工作 | 单次任务自主工作 8 小时 |
| 训练芯片 | 华为昇腾 910B(全国产) |
| 开源协议 | MIT License |
| 权重大小 | 1.51 TB(HuggingFace) |
📊 Benchmark 全景:赢了哪些,输了哪些
先上全景图,好的坏的都说清楚。
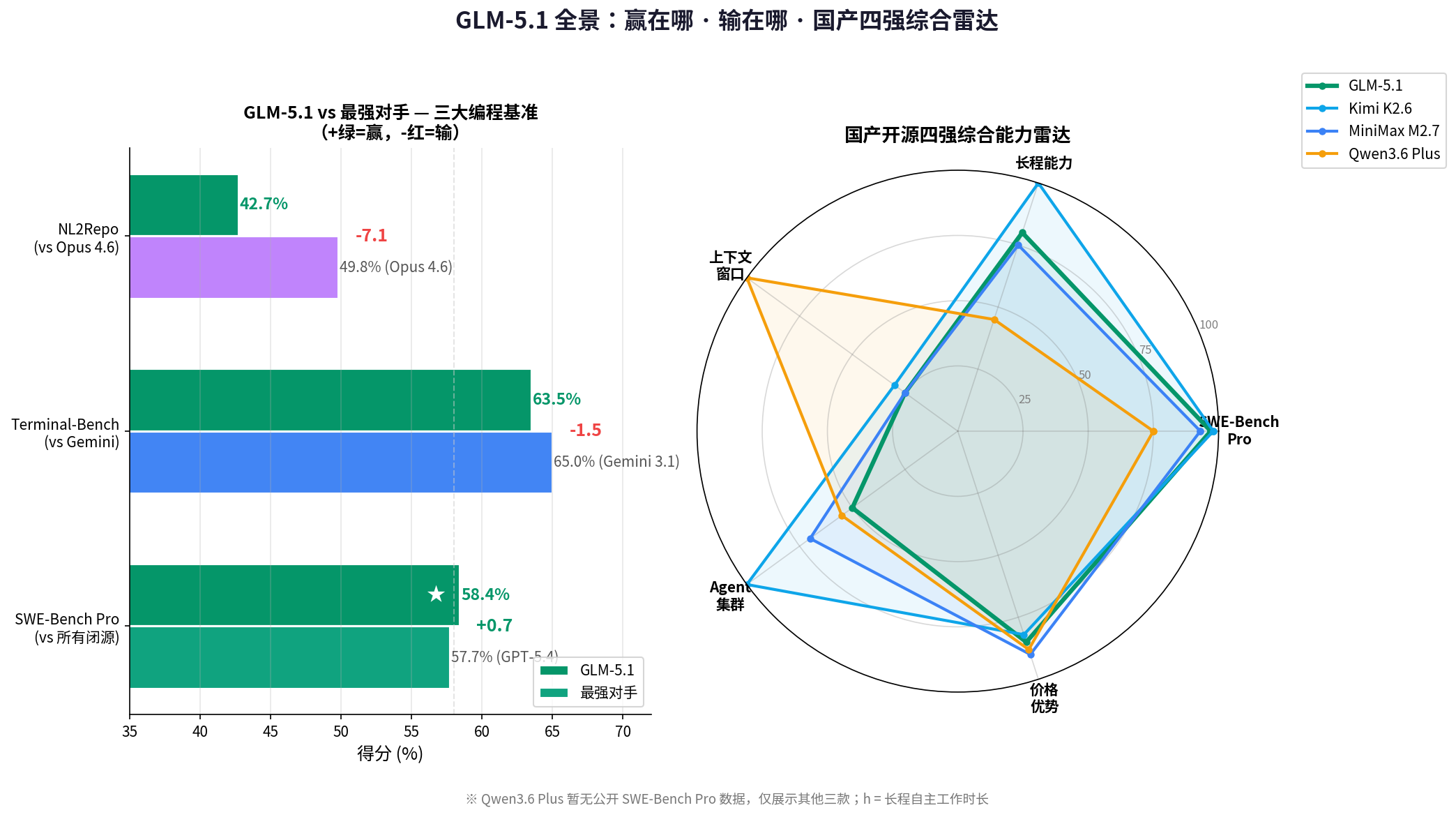
✅ GLM-5.1 赢了的
| Benchmark | GLM-5.1 | Claude Opus 4.6 | GPT-5.4 | 说明 |
|---|---|---|---|---|
| SWE-Bench Pro | 58.4% | 57.3% | 57.7% | 真实 GitHub Bug 修复,全球第一 |
| NL2Repo | 42.7% | 35.9%(GLM-5)→对比略有差异 | - | 从零构建完整代码仓库 |
| Claude Code Harness | 69.0% | - | - | 最佳 Agent 脚手架测试 |
💡 SWE-Bench Pro 是怎么考的? 不是写算法题,是给模型一个真实 GitHub 仓库的 Issue("第 237 行在某个边界条件下会报 IndexError"),要求模型自主定位问题、修改代码、通过原始测试套件。全局第一意味着它修 Bug 比 GPT-5.4 和 Claude Opus 4.6 都强。
❌ GLM-5.1 仍有差距的
| Benchmark | GLM-5.1 | 最强对手 | 说明 |
|---|---|---|---|
| NL2Repo vs Opus | 42.7% | Opus 4.6(49.8%) | 从零构建仓库仍落后 7 分 |
| Terminal-Bench 2.0 | 63.5% | Gemini 3.1 Pro(更高) | 命令行任务略逊 |
| HLE(博士级推理) | 31.0% | GPT-5.4(更高) | 纯推理有差距 |
| Vending Bench 2 | $5,634 | Opus 4.6($8,017) | 自主获利能力落后 |
| AIME / HMMT | - | GPT-5.4 领先 | 数学竞赛不是强项 |
结论:GLM-5.1 是一个专注于软件工程场景的模型,在编程/Agent 维度达到全球顶级,其他维度仍在追赶。这是一个有清晰取舍的技术路线,不是全能模型。
🏛️ 架构解析:GlmMoeDSA 是什么?
GLM-5.1 使用了一个专门设计的架构,全名 GlmMoeDSA(GLM Mixture of Experts with Deep Sparse Attention)。
三个组件的分工
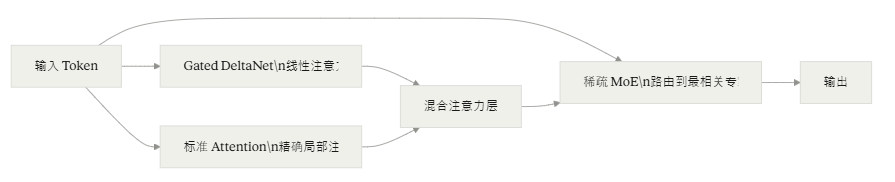
① Gated DeltaNet(线性注意力):处理超长上下文时,标准 Attention 的计算复杂度是 ,对于 200K Token 的序列来说代价极高。DeltaNet 用线性近似将复杂度降到
,让模型能高效处理长任务链。
② 标准 Attention:在关键层保留精确的注意力计算,确保细节不丢失。
③ 稀疏 MoE(256 路由 + 1 共享专家,每次激活 8+1): 每个 Token 只激活约 40B 参数,大幅降低推理成本——让 754B 的大模型在推理时的计算量接近 40B 的小模型。
加入 DeepSeek Sparse Attention(DSA) 进一步降低长上下文下的部署成本。
为什么这个架构适合 Long-Horizon 任务?
传统 Transformer 在处理几百轮工具调用时,有两个瓶颈:
- 注意力计算量随序列长度平方增长,几千步后速度急剧下降
- KV Cache 显存占用巨大,容易 OOM
GlmMoeDSA 的线性注意力 + 稀疏激活组合,让模型能在保持性能的前提下,把任务链拉长到 8 小时。
⏱️ 核心突破:Long-Horizon 8 小时工作能力
这是 GLM-5.1 最有前瞻性的设计目标,也是它对标的核心维度。
什么是 Task-Completion Time Horizon?
2025年3月,AI 安全研究机构 METR 提出了新指标:任务完成时间线(Task-Completion Time Horizon)。
不再用"准确率"衡量模型有多聪明,而是用"时间"衡量它能独立完成多长时间的人类专家任务。
研究数据显示,前沿模型的时间线每 7 个月翻一倍,红杉资本称其为"AGI 的核心方向":
- 2023-2024 年的 AI:会对话的"talker"
- 2026-2027 年的 AI:能真正落地做事的"doer"
GLM-5.1 是全球第一个在真实工程任务中验证了 8 小时持续工作能力的开源模型。
三个让人震撼的官方 Demo
Demo 1:向量数据库优化
GLM-5.1 自主优化一个向量数据库,执行超过 600 轮迭代,每轮自动测试性能、分析瓶颈、修改配置、验证结果——8 小时不间断,最终将查询速度提升了显著幅度。
Demo 2:机器学习工作负载优化
执行超过 1000 轮工具调用,覆盖特征工程、模型选择、超参调优、代码修复的完整研发流程。
Demo 3:Linux 桌面环境构建
从零开始,完全自主地构建一个 Linux 桌面环境,涵盖系统配置、软件安装、环境调试的全链路。
这三个 Demo 的共同特点:不是一次性生成,而是形成了「实验→分析→优化」的自主循环,不停地跑、不停地改、不停地验证——就像一个真正在工作的工程师。
可以连续工作多久,是怎么做到的?
核心机制是异步强化学习(Asynchronous RL)训练:
其中奖励 $r_t$ 不只针对单步结果,而是对整个长任务链的最终完成质量定义。这让模型学会了在数百步之后仍然记得最初的目标,而不是"做着做着忘了要干什么"。
🇨🇳 一个被低估的战略细节:零英伟达
GLM-5.1 was trained entirely on Huawei Ascend 910B chips with zero Nvidia hardware involvement.
在英文媒体的报道里,这被称为"政治上最重要的技术细节"。
背景:美国持续强化对华 AI 芯片出口管制,先后限制 H100、A100、H20。
GLM-5.1 的意义:用全国产算力(华为昇腾 910B)训练出了全球 SWE-Bench Pro 第一的模型——这直接证明了:
中国可以在算力封锁下,训练出前沿级别的大模型。
这和 DeepSeek V4 的国产化路线遥相呼应(V4 全面迁移至昇腾 950PR + CANN 框架)。两家头部中国 AI 公司相继完成对英伟达的"脱钩"验证,这不只是技术新闻,也是产业战略信号。
💻 5 分钟上手 GLM-5.1
方式一:API 调用(OpenAI 兼容)
from openai import OpenAI
client = OpenAI(
api_key="your-zai-api-key",
base_url="https://api.z.ai/api/paas/v4"
)
response = client.chat.completions.create(
model="glm-5.1",
messages=[
{
"role": "user",
"content": "分析这段代码的潜在 Bug,给出可运行的修复方案:\n\n[粘贴你的代码]"
}
],
max_tokens=4096,
temperature=0.6
)
print(response.choices[0].message.content)
方式二:OpenRouter(11 家供应商可用)
client = OpenAI(
api_key="your-openrouter-key",
base_url="https://openrouter.ai/api/v1"
)
response = client.chat.completions.create(
model="zai-org/glm-5.1",
messages=[{"role": "user", "content": "帮我优化这段 Python 代码的性能"}]
)
方式三:本地部署(需要大显存)
# 权重下载(注意:1.51 TB)
git lfs clone https://huggingface.co/zai-org/GLM-5.1
# vLLM 部署(推荐多卡)
pip install vllm
python -m vllm.entrypoints.openai.api_server \
--model ./GLM-5.1 \
--tensor-parallel-size 8 \
--max-model-len 32768
⚠️ 硬件要求:754B 模型权重 1.51 TB,本地部署需要多张 A100/H100 或等效国产显卡。普通开发者建议直接用 API。
🆚 国产开源四强横评
本周(4月第二周),四款重量级国产开源模型密集发布,正好做个横评:
| 模型 | SWE-Bench Pro | 上下文 | 长程能力 | 特色 |
|---|---|---|---|---|
| GLM-5.1 | 58.4%(#1) | 200K | 8 小时 | 全昇腾训练、Long-Horizon |
| Kimi K2.6 | 58.6%(#1) | 256K | 13 小时 | 300 Agent 并行、视觉设计 |
| MiniMax M2.7 | 56.22% | 200K | 长程稳定 | 自我进化,SWE-V 78% |
| Qwen3.6 Plus | - | 100万 | 中等 | 速度快,MCP 最优 |
💡 **GLM-5.1 vs Kimi K2.6:**两者 SWE-Bench Pro 仅差 0.2 分(58.4 vs 58.6),堪称平局。Kimi 上下文更长、Agent 规模更大;GLM-5.1 全昇腾训练、Long-Horizon 场景更专注。选哪个取决于你的具体场景,不存在全方位的胜负。
🔮 智谱的商业策略:敢涨价,说明底气足了
一个有意思的细节:GLM-5.1 发布的同时,智谱再次提价 10%。
这是智谱在半年内第三次涨价。调价后,编码场景定价已接近 Claude Sonnet 4.6 水平。
这说明什么?
一年前,国产模型用"比你便宜"来打市场。 一年后,智谱用"真能干活"来支撑更高的价格。
"从'我便宜所以用我',到'我真能干活所以我敢贵'——国产模型正在完成价值定位的转变。"
这个转变,比 Benchmark 数字本身,更能说明国产 AI 走到了哪一步。
🎁 总结
| 🔑 核心记忆点 | |
|---|---|
| 发布时间 | 2026年4月7日 |
| 最大亮点 | SWE-Bench Pro 58.4%,全球第一 |
| 架构 | GlmMoeDSA,754B 总参数,~40B 激活 |
| 长程能力 | 8 小时自主工作,数百轮迭代 |
| 战略亮点 | 全程华为昇腾 910B 训练,零英伟达 |
| 局限性 | NL2Repo / 纯推理 / 视觉仍落后头部模型 |
| 开源 | MIT License,可商用 |
GLM-5.1 不是全能冠军,但它选择了一个清晰的赛道——专注软件工程和长程 Agent 任务——然后在这个赛道上打到了全球第一。
更深的意义在于:它证明了用全国产算力可以训练出前沿级别的模型。这颗棋,落在了对的位置。
📣 最后
如果这篇让你搞清楚了 GLM-5.1 的价值:
- 👍 点赞 支持国产开源模型
- ⭐ 收藏 API 代码随时用
- 💬 评论 参与投票,聊聊你怎么看国产 AI 的崛起
- 🔔 关注 持续追踪开源大模型动态,一个正在学 AI 的大学生 👨🎓
📚 相关阅读:
- 《Kimi K2.6 深夜正式发布:对标 Opus 4.6,刷新开源编程天花板》
- 《MiniMax M2.7 深度解析:AI 第一次自己训练自己》
- 《DeepSeek V4 来了:长期记忆 + 编程能力双突破》
📖 参考资料:
- Z.ai 官方博客(z.ai/blog/glm-5.1,2026.04.07)
- 量子位:《开源模型首超 Opus 4.6!智谱 GLM-5.1 登场》(2026.04.08)
- MarkTechPost:《Z.AI Introduces GLM-5.1》(2026.04.08)
- buildfastwithai:《GLM-5.1: #1 Open Source AI Model?》
- 苏米客:《GLM-5.1 代码能力实测》(2026.04.08)

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)