
【第2篇-续】从零开始helloworld使用openAI通用模型的完整实现示例
一、概述
本文示例代码:spring-ai-helloworld
1.1 说明
本文将对于上一篇【第2篇】helloworld解析和部署,并改造为使用openAI模型, Spring AI 框架的 AI 聊天服务示例,演示如何以最少的代码将大语言模型(LLM)能力集成到 Spring Boot 应用中的具体实现。
采用兼容 OpenAI 协议的昇腾模型(GitCode),用了它的模型 Qwen/Qwen3.5-35B-A3B,通过统一的抽象层屏蔽了底层模型差异,最终实现可以像调用普通 Service 一样调用 AI 能力。
如下图所示:
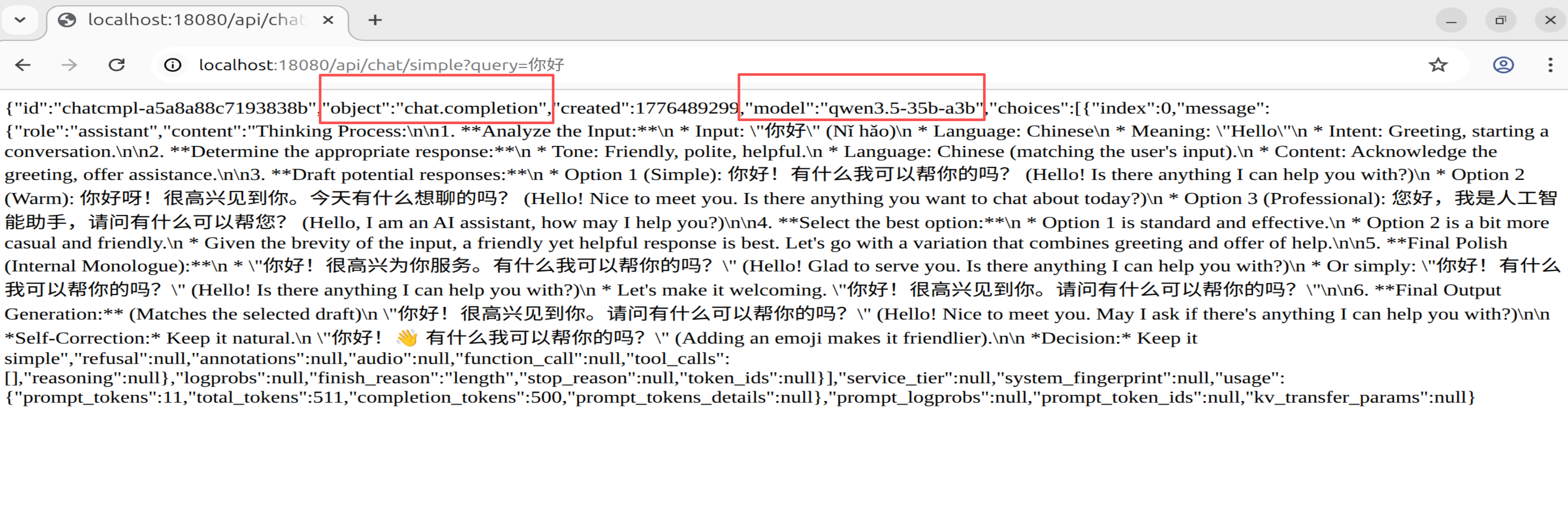
- RestClient 聊天端点:
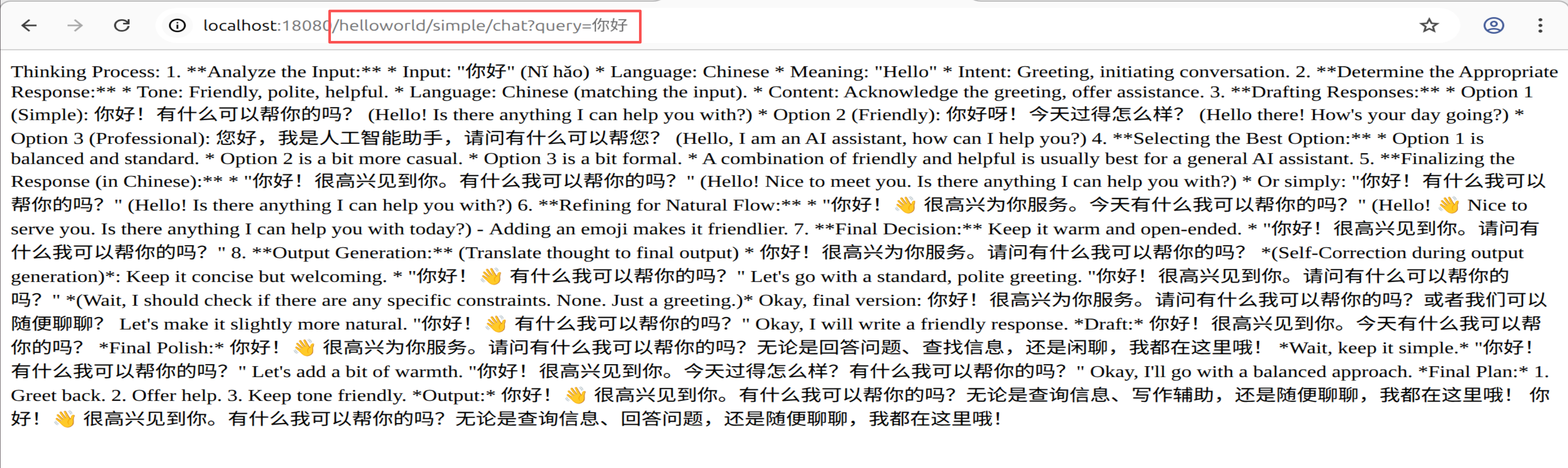
- Spring AI ChatClient 聊天端点:
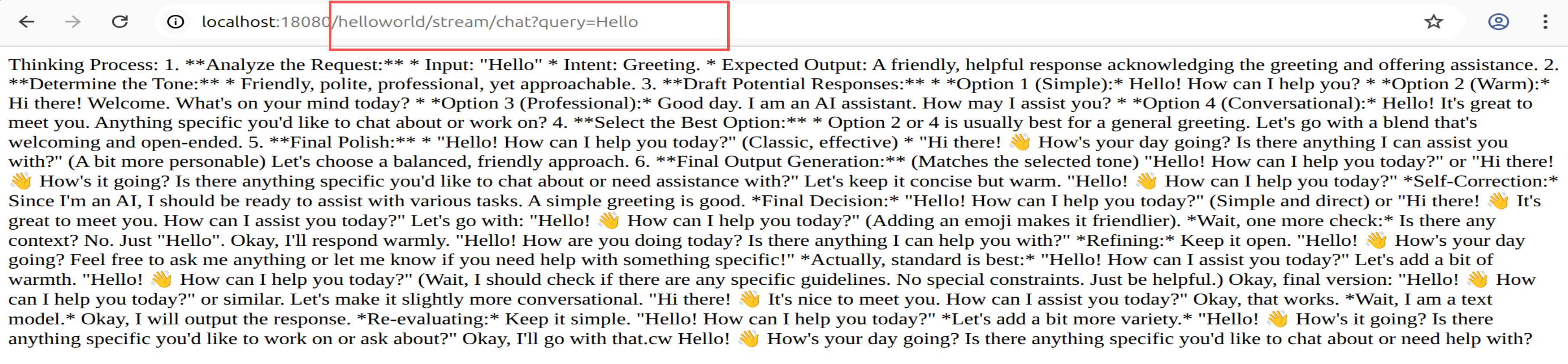
- 流式聊天端点:
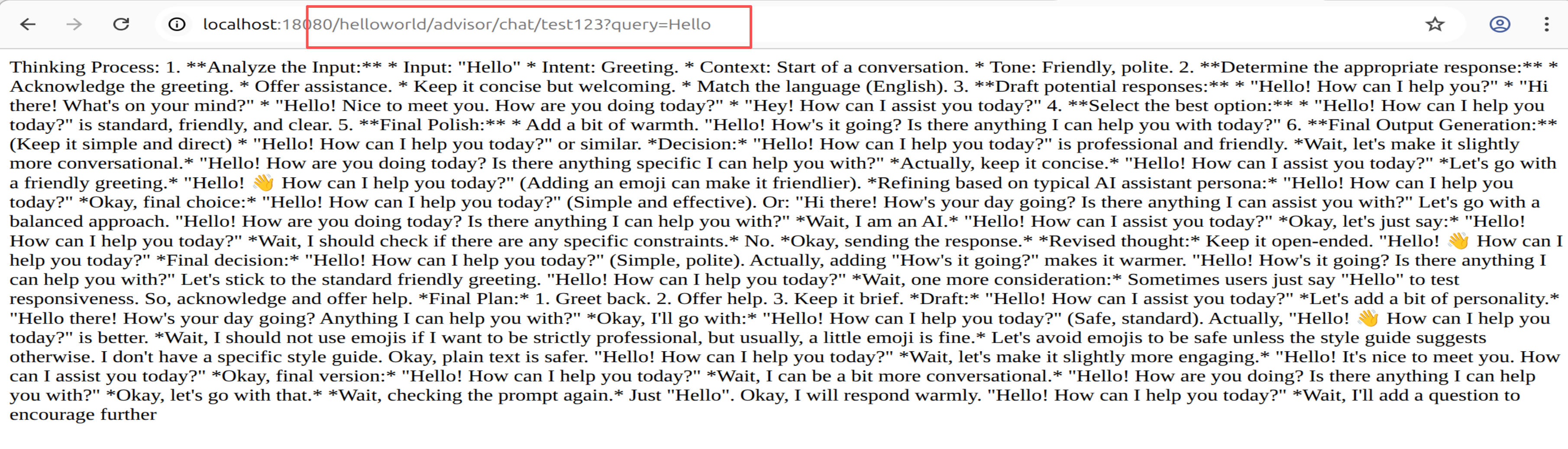
- 对话历史端点:
1.2 核心目标
- 低门槛接入:提供开箱即用的 HTTP API,支持 Web、移动端、CLI 等多种客户端调用。
- 多种交互模式:支持简单对话、ChatClient 聊天端点、流式(SSE)响应、多轮上下文对话(历史对话)。
- 工程化实践:展示依赖注入、配置外部化、统一异常处理、可观测性等最佳实践。
二、技术架构设计
2.1 整体的架构比较简单
这个小项目采用经典的分层架构,自上而下分为客户端层、网关层、业务逻辑层、外部服务层。
2.2 技术栈详解
| 层级 | 技术选型 | 说明 |
|---|---|---|
| 基础框架 | Spring Boot 3.2.5 | 自动配置、内嵌 Tomcat、Actuator 监控 |
| AI 集成 | Spring AI 1.0.0-M6 | 统一 LLM 调用抽象,支持 Prompt、Chat、Embedding |
| HTTP 客户端 | RestClient (Spring 6.1+) | 声明式 HTTP 调用,替代已废弃的 RestTemplate |
| 响应式支持 | Spring WebFlux | 提供流式(Streaming)API 能力 |
| 缓存 | Caffeine | 本地高性能缓存,减少重复请求成本 |
| 监控 | Micrometer + Prometheus + Grafana | 指标采集、存储、可视化 |
| 日志 | Logback + Logstash | 结构化日志,支持 ELK 聚合 |
版本注意:Spring AI 1.0.0-M6 属于里程碑版本,未发布到 Maven Central,需要额外配置
spring-milestones仓库。
三、核心组件设计
3.1 应用启动类:一切自动化的起点
@SpringBootApplication
public class HelloworldApplication {
public static void main(String[] args) {
SpringApplication.run(HelloworldApplication.class, args);
}
}
说明:@SpringBootApplication 是一个组合注解,它内部包含了三个关键元注解:
@Configuration:将当前类标记为配置类,允许通过@Bean定义第三方组件。@EnableAutoConfiguration:启动自动配置机制。Spring Boot 会读取META-INF/spring/org.springframework.boot.autoconfigure.AutoConfiguration.imports,根据你引入的依赖(如spring-ai-openai)自动创建ChatClient、RestClient等 Bean。@ComponentScan:自动扫描同级及子包下的@Component、@Service、@Controller等注解类,纳入 Spring 容器管理。
不需要 web.xml
Spring Boot 内嵌了 Tomcat,启动时会自动创建并启动 Web 服务器。application.yml 中的 server.port 会被绑定到内嵌 Tomcat 的连接器上,无需外部 Servlet 容器。
3.2 Spring AI 方式:ChatClient
@RestController
@RequestMapping("/helloworld")
public class HelloworldController {
private final ChatClient chatClient;
public HelloworldController(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder.build();
}
@GetMapping("/simple/chat")
public String simpleChat(@RequestParam String query) {
return chatClient.prompt(query).call().content();
}
}
原理说明:
Spring AI 的设计哲学是**“面向接口编程,屏蔽底层差异”**。无论底层是 OpenAI、Anthropic 还是 Ollama,上层代码都是 chatClient.prompt(...).call().content()。
- 依赖注入:
ChatClient.Builder由spring-ai-openai-spring-boot-starter自动配置,读取spring.ai.openai.*配置后生成。 - Builder 模式:允许链式配置,如
.defaultOptions(...)、.defaultSystem(...),创建不可变的客户端实例。 - 自动重试:底层集成了 Spring Retry,当遇到网络抖动或 API 限流(429)时会自动退避重试。
3.3 原生 HTTP 方式:RestClient
@RestController
@RequestMapping("/api")
public class EnhancedController {
private final RestClient restClient;
private static final String API_URL = "https://api-ai.gitcode.com/v1/chat/completions";
private static final String API_KEY = "${SPRING_AI_OPENAI_API_KEY}";
public EnhancedController(RestClient.Builder restClientBuilder) {
this.restClient = restClientBuilder.build();
}
@GetMapping("/chat/simple")
public String simpleChat(@RequestParam String query) {
Map<String, Object> body = Map.of(
"model", "Qwen/Qwen3.5-35B-A3B",
"messages", List.of(Map.of("role", "user", "content", query)),
"max_tokens", 500
);
return restClient.post()
.uri(API_URL)
.header("Authorization", "Bearer " + API_KEY)
.body(body)
.retrieve()
.body(String.class);
}
}
两种方案对比:
| 维度 | Spring AI ChatClient | RestClient |
|---|---|---|
| 抽象层级 | 高,面向 AI 领域模型 | 低,面向 HTTP 协议 |
| 代码量 | 极少,一行调用 | 需手动构造 JSON Body |
| 灵活性 | 受限于框架支持的参数 | 完全自由,可调用任何端点 |
| 可移植性 | 切换模型只需改配置 | 需重写请求逻辑 |
| 适用场景 | 标准 Chat/Embedding 任务 | 需要自定义 Header、流式控制、特殊端点 |
选型建议:常规 AI 功能优先使用
ChatClient,遇到框架暂未支持的 API 特性(如特定的微调接口、自定义工具调用)时,使用RestClient作为补充。
四、配置设计详解
4.1 application.yml 核心配置
server:
port: 18080
spring:
application:
name: spring-ai-alibaba-helloworld
ai:
openai:
base-url: https://api-ai.gitcode.com/v1/
api-key: ${SPRING_AI_OPENAI_API_KEY} # 支持环境变量覆盖
chat:
enabled: true
options:
model: Qwen/Qwen3.5-35B-A3B
temperature: 0.7 # 创造性 vs 确定性(0-2)
max-tokens: 1024 # 最大生成长度
top-p: 0.9 # 核采样
原理说明:Spring Boot 的 Type-safe Configuration Properties 机制会将上述 YAML 自动绑定到 OpenAiChatProperties 类。这意味着:
- 你在 YAML 中写的
spring.ai.openai.api-key,对应 Java 对象中的apiKey字段(自动驼峰转换)。 - 支持多种配置源优先级:命令行参数 > 环境变量 > application.yml > 默认值。生产环境中推荐通过环境变量注入敏感信息,避免密钥硬编码。
环境变量映射规则:
Spring Boot 会将大写环境变量自动映射。例如 SPRING_AI_OPENAI_API_KEY 会精确覆盖 spring.ai.openai.api-key。
4.2 Maven 仓库配置
由于 Spring AI 尚未发布 GA 版本,需要在 pom.xml 中声明里程碑仓库:
<repositories>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
原理说明:Maven 解析依赖时,会按 pom.xml 中 <repositories> 的顺序查找。将 spring-milestones 放在前面,确保优先下载 Spring 官方发布的里程碑版本,而不是可能存在不兼容变更的快照版(snapshots)。
五、数据流与交互流程
5.1 一次完整的请求生命周期
5.2 流式响应(SSE)流程
对于需要"打字机效果"的场景,数据流略有不同:
关键概念:流式响应使用 SSE(Server-Sent Events) 协议,基于长连接单向推送。Spring WebFlux 的 Flux<String> 天然适合这种"异步多个返回值"的场景,配合 produces = MediaType.TEXT_EVENT_STREAM_VALUE 即可实现。
六、环境搭建与本地启动
6.1 前置要求
- JDK 17+
- Maven 3.8+
6.2 启动步骤
# 1. 克隆并进入项目
cd spring-ai-alibaba-helloworld
# 2. 编译打包(跳过测试加速)
mvn clean package -DskipTests
# 3. 启动应用(方式一:Maven插件,适合开发)
mvn spring-boot:run
# 4. 启动应用(方式二:Jar包,适合生产预览)
java -jar target/spring-ai-alibaba-helloworld-1.0.0.jar
6.3 快速验证
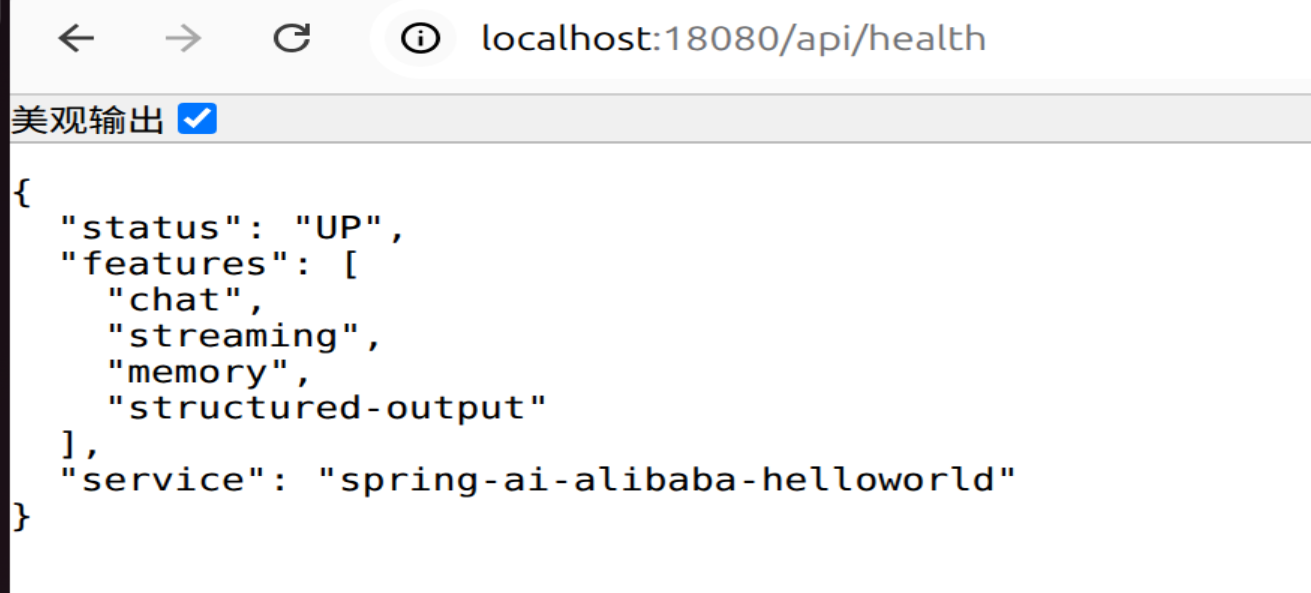
# 健康检查
curl "http://localhost:18080/api/health"
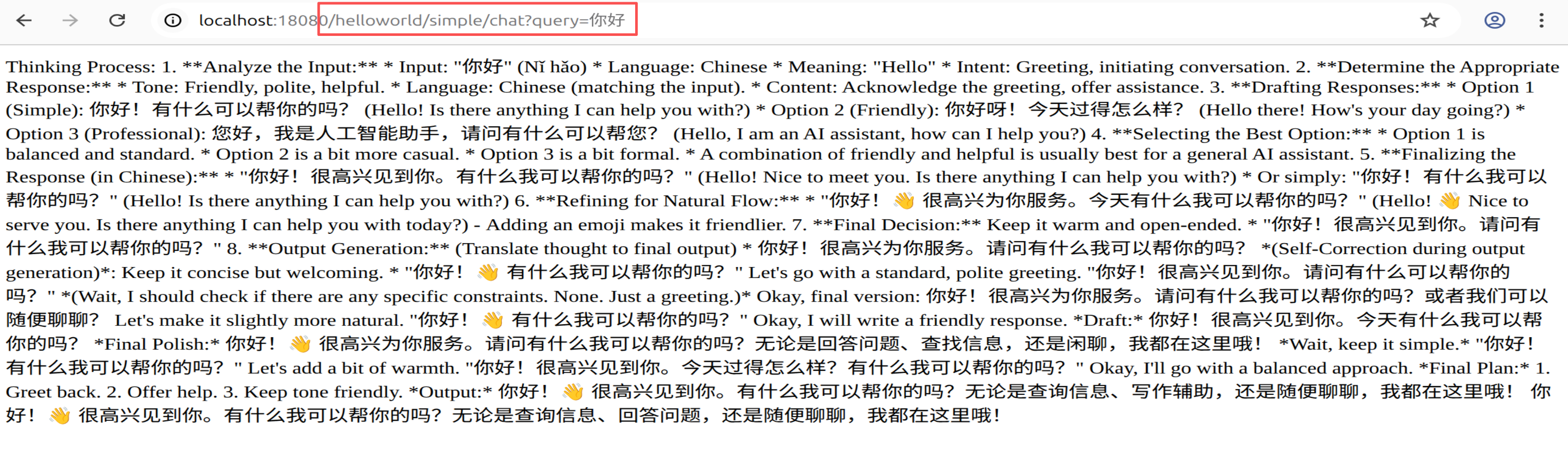
# 简单对话测试(Spring AI 路径)
curl "http://localhost:18080/helloworld/simple/chat?query=你好"
# 直连 API 测试(RestClient 路径)
curl "http://localhost:18080/api/chat/simple?query=Hello"

七、安全与配置管理
7.1 API 密钥安全
严禁将密钥提交到 Git! 生产环境推荐以下方式(按优先级排序):
- 环境变量:
export SPRING_AI_OPENAI_API_KEY=xxx,Spring Boot 自动绑定。 - 配置中心:如 Spring Cloud Config、Nacos、AWS Secrets Manager,支持动态刷新。
- 命令行参数:
java -jar app.jar --spring.ai.openai.api-key=xxx(仅在安全终端使用)。
7.2 HTTPS 与传输安全
使用 Let’s Encrypt 或内部 CA 签发证书,配置 application-prod.yml:
server:
port: 8443
ssl:
enabled: true
key-store: classpath:keystore.p12
key-store-password: ${KEYSTORE_PASSWORD}
key-store-type: PKCS12
若前端使用 Nginx 反向代理,建议在 Nginx 层卸载 TLS,后端保持 HTTP,降低 JVM 加解密开销。
八、扩展功能实现
8.1 多轮对话(上下文记忆)
HTTP 本身是无状态的,要实现多轮对话,需由客户端传入 conversationId,服务端维护对话历史:
@Service
public class ConversationService {
// 生产环境应使用 Redis,而非本地 Map
private final Map<String, List<Message>> histories = new ConcurrentHashMap<>();
public String chat(String conversationId, String query) {
List<Message> history = histories.computeIfAbsent(conversationId, k -> new ArrayList<>());
// 构建包含历史的 Prompt
Prompt prompt = new Prompt(history.stream()
.map(m -> new Message(m.getRole(), m.getContent()))
.toList());
String response = chatClient.prompt(prompt).call().content();
// 保存上下文
history.add(new Message("user", query));
history.add(new Message("assistant", response));
return response;
}
}
如下图所示:
为什么需要限制上下文长度?
LLM 按 Token 计费,过长的历史会:
- 增加单次请求成本。
- 可能超出模型最大上下文窗口(如 4K/8K/128K),导致早期信息被截断。
建议实现滑动窗口:当历史超过 10 轮或 3000 Token 时,丢弃最早的对话。
8.2 流式输出(打字机效果)
@GetMapping(value = "/chat/stream", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<String> streamChat(@RequestParam String query) {
return chatClient.prompt(query)
.stream() // 关键:启用流式模式
.content(); // 返回 Flux<String>
}
SSE 前端接收示例(JavaScript):
const eventSource = new EventSource('/chat/stream?query=你好');
eventSource.onmessage = (event) => {
document.getElementById('output').innerHTML += event.data;
};
eventSource.onerror = () => eventSource.close();
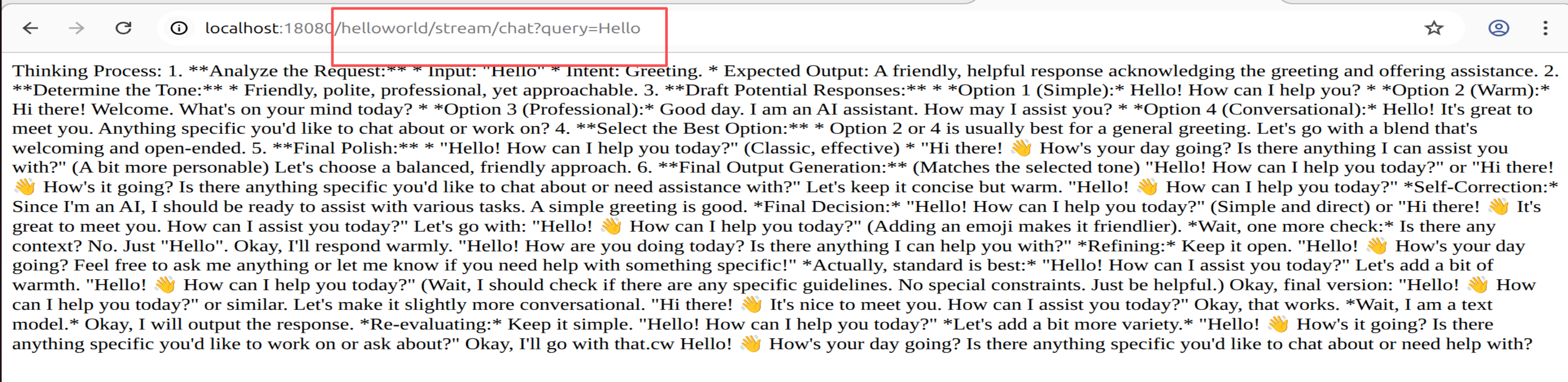
流式聊天端点验证,或者在浏览器中验证:
curl "http://localhost:18080/helloworld/stream/chat?query=Hello"
如下图所示:
九、故障排查手册
9.1 常见问题速查
| 现象 | 可能原因 | 排查方法 |
|---|---|---|
404 Not Found |
GitCode API 路径或模型名错误 | 检查 base-url 是否带 /v1/,模型名是否拼写正确 |
401 Unauthorized |
API Key 无效或过期 | 检查 Header 是否为 Bearer token 格式 |
| 响应缓慢/超时 | LLM 生成慢或网络抖动 | 调整 max-tokens、增加响应超时时间、检查线程池是否打满 |
OOM Killed |
内存不足或并发过高 | 查看 JVM 堆内存使用,降低并发或扩容 |
| 启动端口冲突 | 18080 被占用 | lsof -i :18080 查看并杀掉占用进程 |
9.2 线上诊断工具:Arthas
Arthas 是阿里开源的 Java 诊断神器,无需重启即可查看运行时状态:
# attach 到目标进程
java -jar arthas-boot.jar
# 查看实时面板:线程、内存、GC、运行时信息
dashboard
# 查看某个方法的入参和返回值
watch com.example.ChatService chat '{params,returnObj}' '#cost>1000' -n 5
# 反编译线上代码,确认是否生效
jad com.example.ChatService
十、快速参考
A. Maven 常用命令
mvn clean package -DskipTests # 打包
mvn spring-boot:run -Dspring-boot.run.profiles=dev # 指定环境运行
mvn dependency:tree # 查看依赖树,排查冲突
Spring AI 的价值在于将 LLM 调用从"网络编程"降级为"方法调用",让你可以像使用任何 Spring Bean 一样使用 AI 能力。而 RestClient 则作为"逃生舱",在需要精细控制时提供底层访问能力。两者结合,足以应对绝大多数 AI 应用场景。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐
 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)