
AscendNPU IR和众智FlagOS新语言Triton-TLE深度适配,通过FlagTree编译器接入昇腾,为高性能算子开发提供新路径
在人工智能技术指数级迭代的今天,算力的边界正被不断突破,而软件生态的开放与协同,则成为了释放硬件潜力的关键钥匙。作为一种 Python DSL 形式的算子编程语言,Triton 基于 Block 的编程理念屏蔽了复杂硬件细节,并通过编译器优化实现高性能算子。这些优点吸引了大量开发者围绕 Triton 形成庞大的社区生态。然而 Triton 在细粒度控制存储层和并行粒度上缺少抽象,导致算子性能难以进一步挖掘。
众智 FlagOS 社区基于 FlagTree(多芯片公共编译器)提出了全新语言 Triton-TLE(Triton Language Extentions),从三个层级扩展 Triton 能力,满足开发者在算子开发上的不同需求。Triton-TLE 通过 FLIR(针对DSA的公共中间表示层)与 AscendNPU IR(昇腾MLIR能力表达层)的深度适配,在昇腾上取得了里程碑式的落地成果。这不仅是一次技术层面的成功对接,更是国内AI开源生态与底层硬件深度融合的重要一步。现在,开发者可以下载 FlagTree 体验 Triton-TLE 的高效编程范式,在昇腾平台上获得高性能算子开发体验。
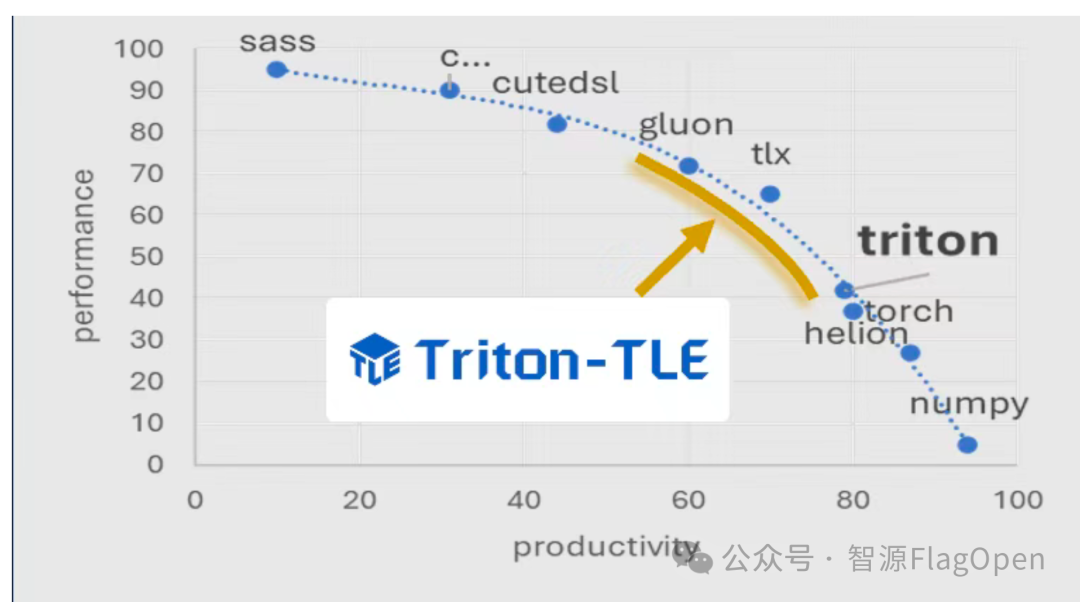
从“高效率”到“高性能”:FlagTree推出三层渐近式编程语言Triton-TLE
Triton-TLE(Triton Language Extensions)是 FlagTree 对 Triton 语言提供的扩展能力,针对不同专业度开发者采用三层渐进式架构设计。
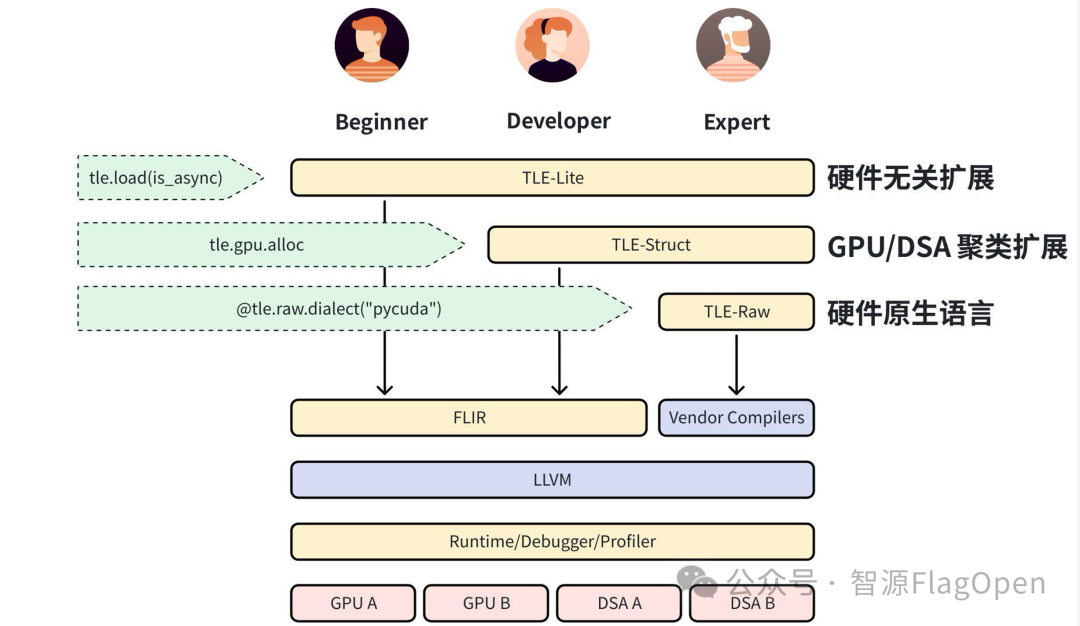
TLE-Lite 是对 Triton 的轻量级扩展,所有特性兼容各类硬件后端,仅需对原有 Triton kernels 少量修改即可拿到大幅性能提升。主要面向算法工程师和快速性能优化场景。
TLE-Struct 按硬件的架构聚类抽象,分类(如 GPGPU、DSA)提供扩展,满足进一步性能优化的需求。需要开发人员对目标硬件的特性和优化技巧有一定了解。
TLE-Raw 提供对硬件最直接的控制,可以使用硬件厂商的原生编程语言获取最极致的性能。需要开发人员对目标硬件的深入了解,主要面向性能优化专家。
其中 TLE-Lite 和 TLE-Struct 会通过 FLIR 最终 Lowering 到 LLVM IR,而 TLE-Raw 则通过语言对应的编译管线(如厂商的私有编译器)Lowering 到 LLVM IR。最后它们会被 Link 到一起,共同生成一个完整的 kernel 供 Runtime 加载和执行。
打通“任督二脉”:AscendNPU IR扮演关键桥梁
如果说 FlagTree 与 Triton-TLE 的结合是上层建筑的创新,那么 AscendNPU IR 的底层支撑则是这一切得以在昇腾硬件上高效运行的地基。
AscendNPU IR(AscendNPU Intermediate Representation)是基于 MLIR(Multi-Level Intermediate Representation)构建的,面向昇腾亲和算子编译时使用的中间表示,为生态框架提供面向昇腾的统一编译接入层和硬件完备表达优化能力,释放硬件算力。 AscendNPU IR 提供了多级方言,高层抽象 HFusion Dialect 屏蔽昇腾计算、搬运、同步指令细节,具备 tensor 及表达能力。硬件抽象 HIVM Dialect 实现了昇腾硬件的抽象资源管理,提供了细粒度的控制能力,自动面向昇腾优化。
FlagTree 中的 FLIR 则承担着 Triton-TLE 编译降级并对接到 AscendNPU IR 的工作,同时注册了一批二元算数算子的转换规则,将 tle.dsa.op 降级为 HIVM 方言的向量算子。例如 tle.dsa.copy 接口经过一系列的转换 pass,将 GM 到 UB 的数据搬移降级为 memref::CopyOp,将 GM->L1 的数据搬移降级为 hivm::ND2NZOp。
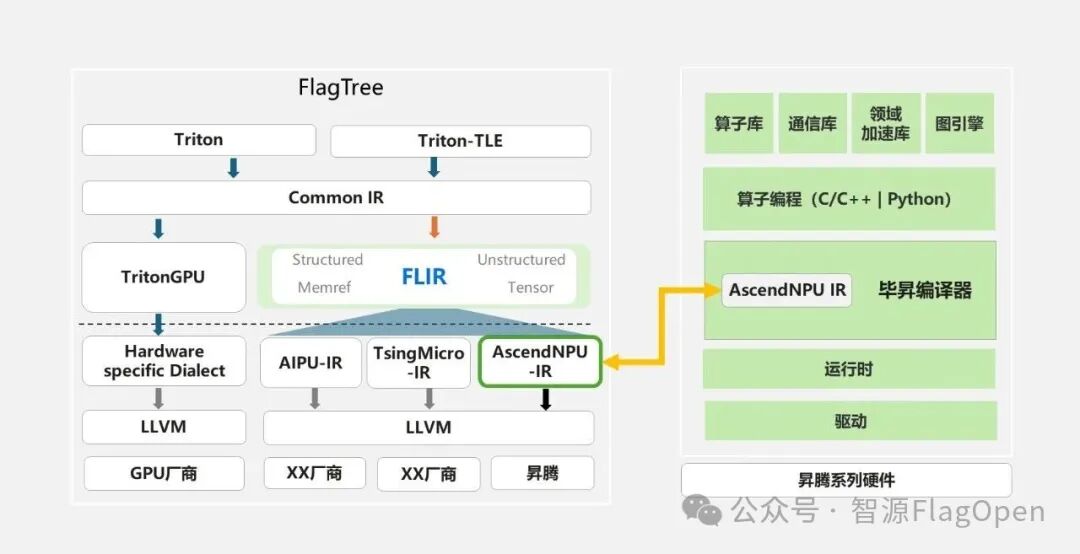
Triton-TLE+ FlagTree 通过 AscendNPU IR 的接入,是昇腾 CANN 生态 “分层解耦、开源开放、灵活扩展”的一次成功践行。通过该 IR 层的开放能力,验证了其在快速接纳不同的AI编程框架上的灵活性与低适配成本。这种开放策略,也使得 FlagOS 社区能够更高效地利用昇腾底层算力,共同构建开放共赢的 AI 开发生态。
基于兼具高性能与高效率、灵活可定制的接入方式,开发者既能享受 Tensor 级别的高阶抽象带来的快速开发红利,也能在性能瓶颈处调用细粒度指令集进行深度优化。这种分层机制使得 FlagTree 编译的算子既能快速落地,又能通过定制化优化释放昇腾硬件的极致算力。
Triton-TLE+ FlagTree 与 AscendNPU IR 的深度融合,不是技术栈的简单连接,而是构建繁荣 AI 生态的坚实一步。它展示了国内AI框架与底层硬件协同创新的巨大潜力。我们相信,随着 AscendNPU IR 的进一步发展,以及 FlagOS 社区与昇腾生态的持续共建,开发者将获得更强大、更易用的工具链。未来,我们将继续推动前沿技术创新,降低AI应用门槛,与广大开发者一起,在昇腾算力平台上探索无限可能。
AscendNPU IR开源仓地址:https://gitcode.com/Ascend/AscendNPU-IR
众智FlagOS社区地址:https://github.com/flagos-ai/FlagTree/tree/triton_v3.5.x
欢迎广大开发者前往体验,共同参与这场开放与创新的技术变革!
关于众智FlagOS社区
为解决不同 AI 芯片大规模落地应用,北京智源研究院联合众多科研机构、芯片企业、系统厂商、算法和软件相关单位等国内外机构共同发起并创立了众智 FlagOS 社区。成员单位包括北京智源研究院、中科院计算所、中科加禾、安谋科技、北京大学、北京师范大学、百度飞桨、硅基流动、寒武纪、海光信息、华为、基流科技、摩尔线程、沐曦科技、澎峰科技、清微智能、天数智芯、先进编译实验室、移动研究院、中国矿业大学(北京)等多家在 FlagOS 软件栈研发中做出卓越贡献的单位。
FlagOS 是一款专为异构 AI 芯片打造的开源、统一系统软件栈,支持 AI 模型一次开发即可无缝移植至各类硬件平台,大幅降低迁移与适配成本。它包括大型算子库、统一AI编译器、并行训推框架、统一通信库等核心开源项目,致力于构建「模型-系统-芯片」三层贯通的开放技术生态,通过“一次开发跨芯迁移”释放硬件计算潜力,打破不同芯片软件栈之间生态隔离。
官网:https://flagos.io
GitHub 项目地址:https://github.com/flagos-ai
GitCode 项目地址:https://gitcode.com/flagos-ai

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)