
把TaskPool用顺后,才明白鸿蒙流畅度的关键,不是少做功能,而是别让重活堵UI线程
文章摘要:本文分享了在鸿蒙开发中优化页面性能的实战经验。作者通过图片处理页面卡顿案例,分析了线程边界划分的重要性,提出应区分一次性重活(适合TaskPool)和常驻任务(适合Worker)。重点讨论了并发设计、数据结构传输和任务拆分的平衡,强调"先挪走重活再优化组件"的思路,最终实现界面流畅的关键在于将计算密集型任务从UI线程剥离。文章提供了具体场景下的线程选择策略和优化步骤建
前段时间我在做一个鸿蒙工具型页面,功能本身不算复杂:
用户导入一批图片,做压缩、旋转矫正、灰度增强,再把结果交给后面的识别流程。
一开始我对这个页面挺有信心,因为逻辑不难,界面也不花。
结果真机一跑,问题马上就出来了:
- 点“开始处理”之后,页面会有点发闷
- 列表滚动不像平时那么跟手
- 进度区域虽然在动,但整体给人的感觉还是“卡”
- 连按钮反馈都显得慢半拍
后来我回头看,根子其实很简单:
不是功能太多,而是我把该挪出去的重活,留在了不该承受它的线程里。
所以这篇不打算讲那种泛泛的“性能优化建议”,而是想专门聊一个更偏实战的鸿蒙高级能力:
TaskPool。
更准确一点说,是围绕下面这几个并发能力来聊:
TaskPoolWorkerSendable
这三个东西很多人都知道,但项目里真正开始做图片处理、批量转换、数据预计算时,差别就会越来越明显。
我这次想写的,也不是 API 背诵,而是:
什么场景我现在会优先上 TaskPool,什么场景我反而不会乱上。
一、我后来才慢慢意识到:卡顿很多时候不是因为页面复杂,而是因为线程边界没画清楚
以前我也会下意识觉得,页面卡,可能是因为组件多、布局深、状态写乱了。
这些当然会有影响,但有一类问题特别典型:
界面本身并不复杂,可一旦点了某个按钮,整个页面就明显“不灵”。
这种时候,你就得开始怀疑:
是不是把太多计算型、批处理型、耗时型逻辑,直接压在了 UI 主线程附近。
像下面这些事,我现在都会特别警惕:
- 批量图片压缩
- 缩略图批量生成
- OCR 预处理
- 大量字符串 / JSON 转换
- 一次性的大批量数据整理
- 明显偏 CPU 密集型的循环计算
这些逻辑单看一段都不一定夸张,
但一堆到一起,页面的“手感”马上就会变差。
后来我越来越认同一个判断:
鸿蒙里很多看起来像“页面问题”的卡顿,本质其实是并发设计问题。

二、为什么我现在遇到“一次性重活”,会先想 TaskPool
我自己的理解很直接:
如果这件事符合下面几个特点,我就会优先想到 TaskPool:
1)它真的耗时
不是那种几十毫秒的小逻辑,而是用户能感知到“要等一下”的任务。
2)它是独立任务
比如一张图的压缩、一组文件的转换、一段数据的预计算。
它更像一次性被派出去做的工作,而不是一个长期待命的线程。
3)它不是持续常驻逻辑
任务做完就结束,不需要一直挂着,不需要长期监听,也不需要持续占着一个线程活着。
这类场景,TaskPool 用起来会比较顺。
因为你脑子里根本不用把它想成“另起一个长期线程”,它更像是:
把一次明确的重活,交给合适的并发执行环境。
这个思路一旦转过来,很多代码设计都会更清晰。
页面层就只负责:
- 接收用户操作
- 显示进度
- 更新状态
- 展示结果
至于那些真正费时费力的活,尽量别留在 UI 线程附近硬扛。
三、我现在不会一上来就问“能不能多线程”,而是先问“它到底属于哪一类任务”
这是我后来最大的变化之一。
以前一遇到性能问题,很容易直接想:
要不要多线程?要不要拉后台跑?
但现在我会先做一个很简单的分类:
第一类:一次性、独立、明显耗时
这种更像 TaskPool 的地盘。
比如:
- 生成 20 张缩略图
- 对 10 张图片做压缩
- 批量算一组展示数据
- 做一次识别前的预处理
第二类:长期存在、持续协作、需要反复通信
这种我就不会再强行往 TaskPool 里塞。
它更像 Worker 的领域。
尤其是当业务开始出现这些特征时:
- 线程要长期存在
- 逻辑不是“一次干完就走”
- 一组任务之间要共享同一个句柄
- 某个类对象要持续被同一个线程使用
- 你需要的是“常驻工作者”,不是“一次性派单”
这个判断其实很重要。
因为很多并发方案不是“不会用”,而是方向一开始就选歪了。
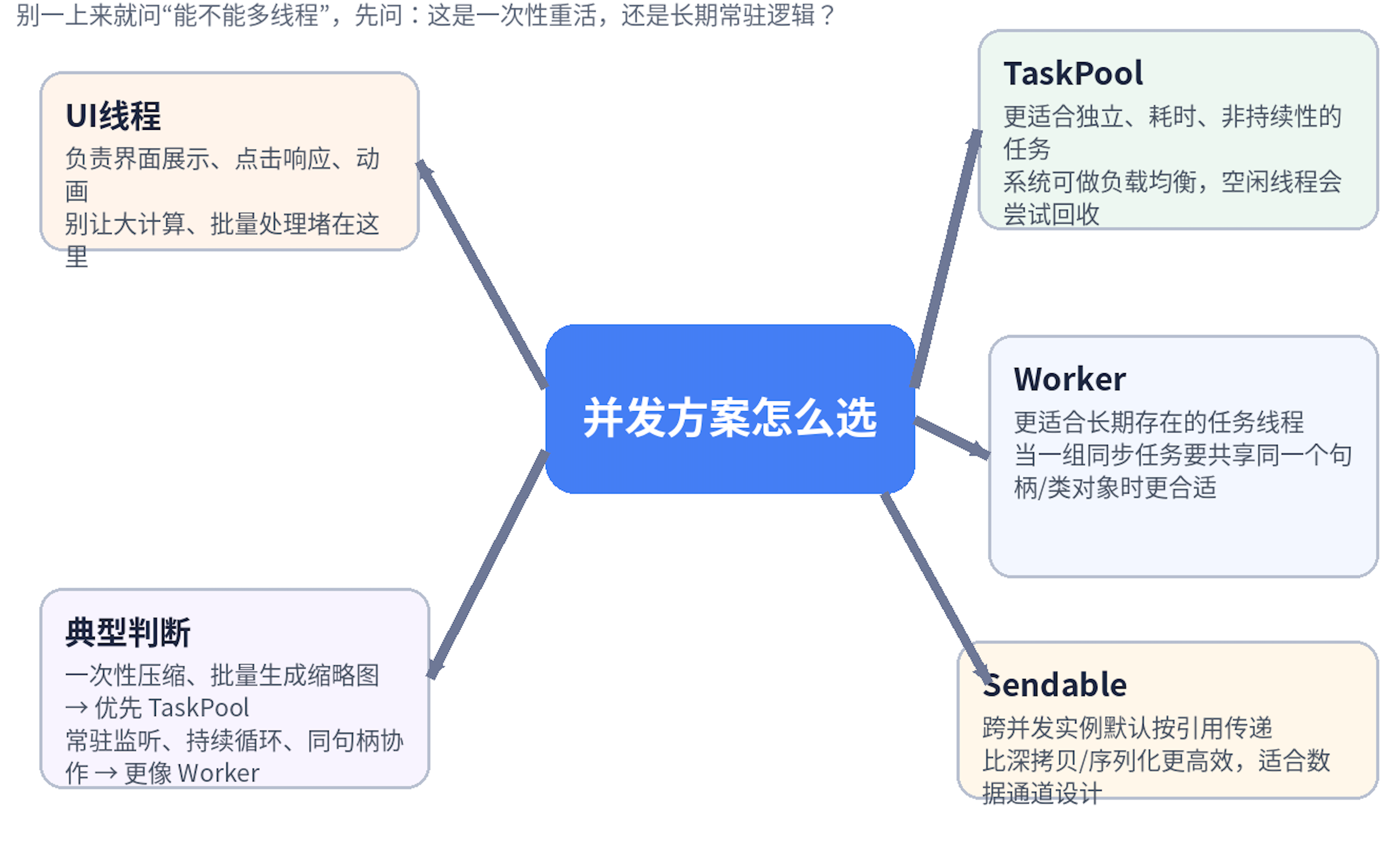
四、为什么有时候不是 TaskPool 不行,而是你本来就更像该用 Worker
这一点我以前也容易忽略。
看到并发能力以后,很自然会想把能挪的都挪出去。
但后面我发现,TaskPool 很适合“干完就收”的任务模型,
而有些业务本身压根不是这个气质。
比如下面这种:
- 后台长期等指令
- 要持续监听某类变化
- 多个任务之间必须围绕同一个对象协作
- 线程上下文需要长期保留
这时候如果你还坚持把它拆成一个个独立任务去扔,
表面上好像也能做,
但代码会越来越别扭。
所以我现在更认同一句话:
并发不是越多越高级,线程模型和业务模型对得上,才是真的顺。
五、跨线程这件事,真正难的不是“能不能传”,而是“你打算怎么传”
我以前刚接触这一块的时候,注意力经常放在“怎么把任务跑起来”。
后来才发现,很多坑其实藏在数据通道里。
比如:
- 传什么结构
- 什么时候拷贝
- 什么时候共享
- 哪些对象后面还要继续被主线程用
- 哪些数据干脆就应该设计成更适合跨线程传递的形式
如果这些前面不想清楚,后期补会很痛苦。
我现在的习惯是:
先把数据边界想清楚
哪些数据只是任务入参,
哪些是任务结果,
哪些只是中间态,
哪些以后还要被持续共享。
再决定传输形式
不要今天图方便传一套对象,明天又改成另一套结构。
这类问题前期看着没什么,项目一大之后就会越来越乱。
尤其是图片处理、批量数据处理这种场景,
你会很快发现:
线程边界不只是执行边界,也是数据设计边界。
六、任务不是拆得越碎越好,这点我现在挺有体感
刚开始做并发优化时,很容易有一种错觉:
是不是任务切得越细、开得越散,看起来就越“高级”?
但实际做下来并不是。
任务拆分本身也有成本:
- 调度有成本
- 通信有成本
- 状态回收有成本
- 合并结果也有成本
所以我现在不会为了“显得并发”而并发。
更愿意先问几个问题:
- 这一步真的值得单独拆出去吗?
- 拆完之后收益是不是比通信成本更大?
- 它和前后步骤耦合重不重?
- 用户感知最明显的卡点到底在哪?
很多时候,真正有效的不是把所有步骤都切开,
而是先把最重、最卡、最影响交互手感的那一段拿出去。
这个顺序很重要。
因为优化不是做展示,
最终还是为了让用户觉得页面更顺。
七、我后来很少把“异步”和“并发”混在一起说了
这两个概念太容易被说成一回事。
但项目里做着做着你会发现,不是所有异步都值得并发化。
比如普通请求、普通状态更新、普通事件响应,
它们本身并不一定是性能瓶颈。
真正值得你认真看线程方案的,往往是那种:
- 明显吃 CPU
- 明显占时长
- 明显会拖慢交互
- 一上真机就暴露手感问题
所以我现在判断得更保守:
先确定是不是“重活”,再决定要不要上并发。
不是所有东西都要搬,
搬对了才有意义。
八、如果让我重写一次这类页面,我现在大概率会这样做
如果再回到那个批量图片处理页面,
我大概率会按下面这个顺序来:
第一步:先把 UI 线程职责缩到最小
让页面只负责:
- 点按钮
- 看进度
- 更新展示
- 出结果
别顺手在这里面塞真正的大计算。
第二步:把明显的单次重活交给 TaskPool
像压缩、预处理、批量转换这种,一旦判断是独立耗时任务,就优先往外挪。
第三步:别急着过度切碎
先抓住最重的部分处理,
不要一上来把整个流水线拆得满天飞。
第四步:提前设计好跨线程数据结构
后面越改越麻烦的,往往不是任务本身,
而是数据到底怎么来、怎么回。
第五步:如果业务开始“常驻化”,就及时换思路
别明明已经更像 Worker 场景了,还硬用一次性任务模型去顶。
九、写在最后
我现在越来越觉得,鸿蒙里真正能让页面“体感变顺”的,不一定是你少写了什么功能,
而是你有没有把那些重活从错误的地方挪开。
TaskPool 这类能力最值钱的地方,不是让代码看起来更复杂,
而是让你终于能把:
- 交互
- 显示
- 计算
- 批处理
这几件本来就不该混在一起的事,慢慢分开。
页面不卡的时候,用户未必会夸你。
但页面一旦“点一下卡一下”,用户一定能感觉到。
所以如果你最近也在做鸿蒙里的图片处理、批量计算、数据预整理这类场景,
我的建议会很简单:
别先急着优化组件,先看看是不是把不该留在 UI 线程的活,留太久了。

你们项目里现在遇到明显吃性能的场景时,第一反应更偏向 TaskPool,还是会先自己拆 Worker?

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)