
HarmonyOS-ArkUI Navigation (导航组件)-二 Router,Navigation, HMRouter 的区别
Router、Navigation、HMRouter三者的发展脉络,本质是鸿蒙导航方案从系统级页面导航向应用级组件导航的演进,核心是为了解决Router的Page页面过重、栈深度受限、灵活性差等痛点。Router作为初代方案,完成了鸿蒙页面导航的基础落地,但受限于系统级Page的设计,无法满足复杂应用的需求;Navigation作为新一代原生方案,从设计理念上颠覆了Router,将导航下沉到组件层
前文回顾
HarmonyOS-ArkUI Navigation (导航组件)-第一部分
目前关于鸿蒙应用页面跳转的方案主要有三个
- 采用系统原生的 Router,进行页面之间的切换
- 采用系统原生的 Navigation,进行页面之间的切换
- 采用三方 SDK HMRouter进行页面之间的切换
并且三个可以混搭使用。
同为跳转,这些都有什么区别呢?
Router
Router 是鸿蒙最初时候,给 Page 与 Page 之间进行跳转设定的 API。其使用方式如下:
@Entry({ routeName: 'RouterTestA' })
@Component
export struct RouterTestA {
...
}
// 在跳转的时候我们需要写
const options: router.NamedRouterOptions = { name: "RouterTestA" }
router.pushNamedRoute(options, router.RouterMode.Standard)界面便会跳转到RouterTestA。
看起来很普通是不是,对于 router 所操作的界面跳转,此时的‘界面’,也就是 Page,是很值得我们探讨的。因为它的机制,解释了华为官方文档弃用 Page,推荐使用 Navigation的原因。
何为 Page?何为组件?
我们在写一个Page 的时候,是强制必须加上@Entry() 注解的。为什么要加这么一个注解呢?不加就不行么--答案是不行。因为它的核心意义是标注当前你写的组件,是一个 Page。
这里面就涵盖了 Page 与组件之间的关系。组件是一个比较广泛的概念,Page 是一种特殊的组件。特殊在其上被标注了@Entry。它俩在概念上实际是,“组件包含 Page“ 的关系。
Page 的限制--router 栈不得超过 32 个元素
如果你好好的研究 router 的接口,你会发现router 有些代码是这样写的:
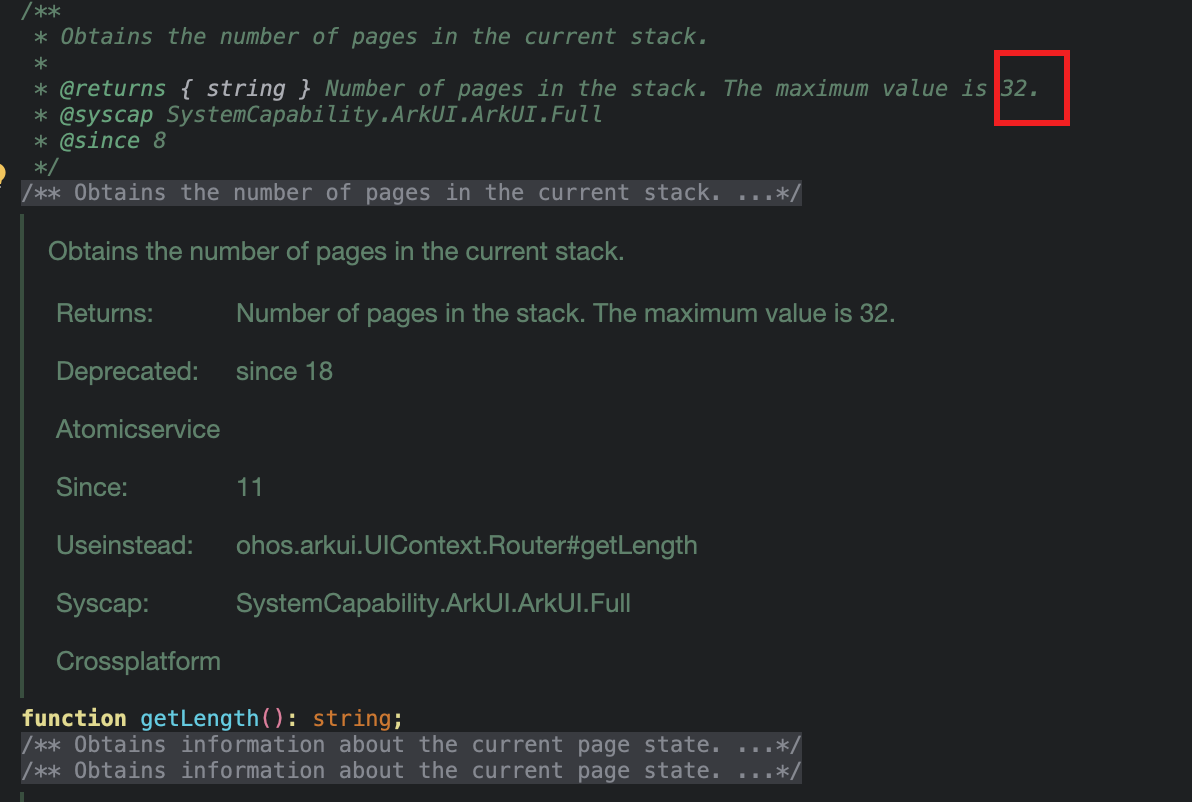
也就是,如果你要获得 router 维持的栈的长度,你会发现这个栈顶多 32 个元素。这个就是 Router 非常让人头疼的限制。 我们的 APP 随着不断的迭代,势必会变得越来越重, 超过 32 个页面,一定程度上,有可能出现。但是为什么要有这个限制呢?
因为 Page,很重!换一个说法讲是,当你的 APP 中出现了一个新的 Page,其内存的占用量绝对比一个普通的组件要大得多。 如果您之前开发安卓的话,可以代入 activity,activity 是比 Fragment 要重的。
为什么重?
因Page 被纳入了Harmony 的系统管理中。那就意味着其必须要支持系统调度、生命周期、任务管理、窗口管理等能力。也就意味着,Page 必须要有很大一部分运行时内存以满足操作系统设计好的以下能力:
独立的生命周期体系
- Page 拥有完整生命周期:onCreate、onShow、onHide、onDestroy 等
- 系统需要为每个 Page 维护独立的生命周期状态机
- 普通组件只有构建 / 更新 / 销毁,没有独立生命周期
独立的窗口与渲染上下文(这个占据的内存是比较多的)
- 每个 Page 对应系统层面的一个当前窗口的,渲染的 UI 容器
- 拥有独立的渲染树、触摸事件分发、焦点管理、输入法关联
- 系统要为每个 Page 分配画布、图层、Surface 等渲染资源
独立的任务栈与路由上下文管理
- Router 栈本质是系统任务栈(Ability/Page 栈)
- 每个 Page 需要记录:路由参数、返回栈信息、权限状态、导航状态
- 系统要维护页面间的跳转关系、返回逻辑、动画上下文
系统级权限与能力依赖
- Page 可以直接申请和持有系统能力:权限、设备传感器、文件访问、网络、后台任务等
- 每个 Page 可能持有独立的 Service 连接、DataShare 连接、应用上下文
- 普通组件通常不直接持有系统能力,而是依赖 Page/Ability
独立的内存快照与状态保存
- 系统在内存紧张时,需要对 Page 做状态保存与恢复
- 每个 Page 会保存:导航状态、表单数据、滚动位置、ViewModel 实例等
- 栈越深,需要保存和恢复的状态越多,内存压力越大
系统进程级资源占用
- Page 属于 Ability 体系一部分,由系统进程统一调度
- 多个 Page 同时驻留会显著增加:
-
- 虚拟机对象数量
- 图像缓存、纹理缓存
- 事件监听器、定时器、异步任务
- 网络连接、数据库连接等
为了支持这些能力,Page 在实现上也不可能轻量化。因为要维持这套体系,要创建的对象太多了。为了让这个过程直观一些, 就仅仅拿 Page 渲染相关占据的资源:我画了一张图来表示
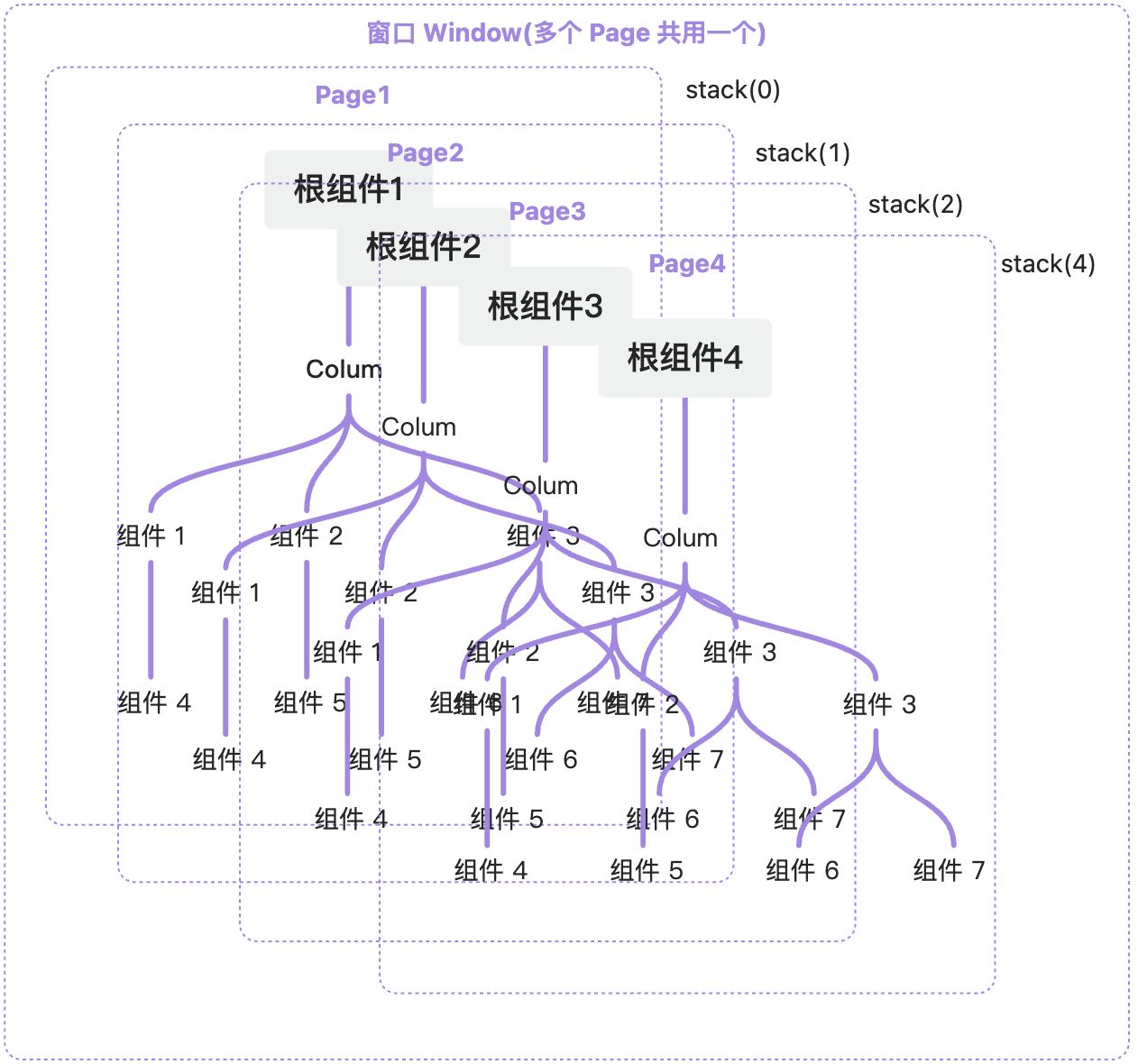
可以看出来,如果你的应用同时出现很多 Page,则其维护的真实对象大概率会如图这么多。
Router 的核心优缺点
优点
- 鸿蒙原生API,无需引入三方依赖,接入成本低;
- 与系统深度融合,支持Page的系统级生命周期、权限管理、状态保存,适配性好;
- 接口设计简单,基础的push、replace、back操作能满足简单应用的导航需求。
缺点
- 栈深度限制32个,无法满足复杂应用的开发需求;
- Page页面过重,多页面同时驻留会导致应用内存占用过高,易出现卡顿、闪退;
- 页面间参数传递效率低,基于IPC通信,无法直接传递引用类型;
- 不支持嵌套跳转,页面切换只能是整页替换,灵活性差;
- 对不同设备大小的兼容性差,无法自适应分栏、折叠屏等场景;
- 动效单一,仅支持系统默认的Page切换动画,无共享元素动画等个性化动效;
- 组件树层面为“一个Page一个根组件”,多页面切换会频繁修改组件树,性能损耗大。
Router 核心跳转行为
Router的跳转行为主要依托pushNamedRoute和replaceNamedRoute两个核心方法,搭配Single和Standard两种模式,不同组合对应不同的栈操作逻辑,核心行为如下:
router.pushNamedRoute(option, RouterMode.Single):
若栈中已存在目标页面,销毁其上方所有页面并复用该页面;若不存在,新建页面入栈。
|
pushNamedRoute(B, Single) |
|
|
初始栈为[A B C D] |
[A B] (D,C清空, B复用) |
|
初始为[A] |
[A B] B 新建 |
router.pushNamedRoute(option, RouterMode.Standard)
无论栈中是否存在目标页面,均新建页面入栈,是最基础的入栈操作:
|
pushNamedRoute(B, Standard) |
|
|
初始栈为[A B C D] |
[A B C D B] (B为新建) |
|
初始为[A] |
[A B] (B为新建) |
router.replaceNamedRoute(option, RouterMode.Single)
若栈中已存在目标页面,销毁其上方所有页面并将其设为栈顶;若不存在,销毁当前栈顶页面,新建目标页面替换
|
replaceNamedRoute(B, Single) |
|
|
初始栈为[A B C D] |
[A B](D C 销毁,回到 B) |
|
初始为[A] |
[B] (A被销毁, B 替换) |
router.replaceNamedRoute(option, RouterMode.Standard)
销毁当前栈顶页面,新建目标页面入栈替换,不影响栈中其他页面。
|
replaceNamedRoute(B, Standard) |
|
|
初始栈为[A B C D] |
[A B C B](D销毁,替换为新建的 B) |
|
初始为[A] |
[B] (A被销毁, B 新建并替换) |
Navigation:鸿蒙原生组件级导航的新一代方案
Navigation 的本质:组件级导航容器
Navigation是鸿蒙推出的组件级导航方案,与Router的页面级导航有本质区别:Router管理的是系统级的Page页面,而Navigation本身就是一个鸿蒙原生的容器组件,其管理的是应用内的普通组件(需被NavDestination包裹),所有导航操作均在同一个Window中完成,不涉及系统级的Page创建与调度。
简单来说,Navigation的核心是将导航逻辑从系统层下沉到应用组件层,摆脱了系统对Page的各种限制,这也是其相较于Router的核心优越性所在。
Navigation 取代 Router 的核心原因:全方位的优越性
Navigation从设计理念上解决了Router的所有痛点,在轻量化、灵活性、性能、兼容性等方面实现了全方位升级,也是鸿蒙官方推荐替代Router的核心原因,其优越性具体体现在以下8个方面:
- 无栈深度限制:Navigation的栈是应用内维护的组件栈,而非系统级的Page栈,由应用自身管理,无32个的硬性限制,可满足复杂应用的无限级导航需求。
- 轻量化,资源消耗低:Navigation管理的是普通组件,无需系统为其分配独立的渲染上下文、生命周期状态机、系统权限等资源,所有组件共享同一个Window的渲染资源,内存占用和性能损耗远低于Page。
- 参数传递效率高:基于引用传递实现组件间的参数传递,无需经过IPC通信,相较于Router的值传递,效率提升显著,还能直接传递复杂的对象、数组类型。
- 支持嵌套跳转:作为容器组件,Navigation可嵌套使用,支持页面内的局部导航、嵌套导航,灵活性远高于Router的整页跳转。
- 自适应多设备场景:天生支持分栏模式(split)、栈模式(stack)、自动模式(auto),可根据设备尺寸(手机、平板、折叠屏)自动适配,无需额外开发;而Router完全不支持多设备兼容。
- 丰富的动效支持:支持共享元素动画、自定义过渡动画等,而Router仅支持系统默认的老套Page切换动画。
- 组件树操作更高效:所有导航操作均在同一个组件树中添加/修改节点,无需频繁创建/销毁根组件,减少了组件树的重绘与重构,性能更高。
- 更精细的导航控制:提供了
pushPathByName、replacePathByName、moveIndexToTop、popToIndex等丰富的栈操作方法,支持将指定页面移到栈顶、弹出指定索引以上所有页面等精细化操作,而Router仅支持基础的push、replace、back。
Navigation 的核心设计要点
- NavDestination 是核心标识:所有需要被Navigation管理的组件,必须被
NavDestination包裹,这是Navigation识别导航目标的唯一标识,未包裹则会出现“大白页”问题。 - 两种跳转实现方式:支持纯代码实现和工程配置实现,且二者可混搭;工程配置需在
module.json5中注册routerMap,指定路由表文件路径,路由表中需配置页面名称、文件地址、构建函数等信息。 - 分栏模式与启动模式:分栏模式支持
auto(自动适配)、split(始终分栏)、stack(始终不分栏);启动模式通过NavPathStack设置,包括STANDARD(新建实例入栈)、MOVE_TO_TOP_INSTANCE(存在则移到栈顶)、POP_TO_INSTANCE(存在则弹出其上方所有页面)。 - 独立的生命周期体系:Navigation为包裹的组件提供了专属的生命周期,比普通组件更精细,比Page的系统级生命周期更轻量,核心包括
onWillAppear、onShown、onActive、onWillHide、onInActive、onWillDisappear等,且可与组件自身的aboutToAppear、onAppear、onDisappear联动。 - 支持拦截器与回调监听:通过
NavPathStack的setInteception方法设置拦截器,可拦截willShow、didShow、modeChange等导航行为;还可通过uiObserver监听navDestinationUpdate、navDestinationSwitch等事件,实现导航行为的精细化控制。
Navigation 核心跳转行为
Navigation的栈操作比Router更丰富,核心跳转方法包括pushPathByName、replacePathByName、moveIndexToTop、popToIndex,所有方法均基于Standard模式实现,核心行为如下:
Navigation.pushPathByName(name, param, animated):
新建目标组件实例入栈,与Router的Standard模式push一致。
|
pushPathByName(B) 相当于 Sdantard 模式执行 |
|
|
初始栈为[A B C D] |
[A B C D B] |
|
初始为[A] |
[A B] |
Navigation.replacePathByName(name, param, animated):
销毁当前栈顶组件,新建目标组件实例入栈替换,与Router的Standard模式replace一致。
|
replacePathByName(B) 相当于 Standard 模式执行 |
|
|
初始栈为[A B C D] |
[A B C B] |
|
初始为[A] |
[B](A被销毁, B 为新建) |
Navigation.moveIndexToTop(index):
将指定索引的组件移到栈顶,仅调整栈顺序,不销毁、不新建组件。
|
moveIndexToTop(1) |
|
|
初始栈为[A B C D] |
[A C D B] 仅仅是把 B 拿出来移动到栈顶 |
|
初始为[A] |
-出错,找不到 1 |
Navigation.popToIndex(index):
弹出指定索引以上的所有组件,将指定索引的组件设为栈顶,弹出的组件会被销毁。
|
popToIndex(1) |
|
|
初始栈为[A B C D] |
[A B] 弹出 1 之前的所有, 将 1 作为栈顶 |
|
初始为[A] |
-出错,找不到 1 |
HMRouter:基于Navigation的三方封装SDK
HMRouter 与 Navigation 的核心关系:封装与被封装
HMRouter是基于鸿蒙原生Navigation开发的三方导航SDK,其核心本质是对Navigation的底层API进行了封装、简化和扩展,并非独立的导航实现方案——HMRouter的所有导航操作,最终都会通过底层的Navigation完成,二者是封装与被封装的关系,简单来说:HMRouter = 封装后的Navigation + 简化的API + 扩展的能力。
HMRouter 与 Navigation 的核心区别
二者的核心目标一致(均为组件级导航),但HMRouter在开发体验、API设计、工程配置上做了优化,与原生Navigation的区别主要体现在以下5个方面:
- API 更简洁,接入成本更低:原生Navigation需要手动处理
NavPathStack、NavDestination、路由表注册等细节,而HMRouter通过注解简化了开发,仅需在目标组件上添加@HMRouter注解,配置pageUrl即可实现导航,无需手动包裹NavDestination。 - 工程配置更简化:原生Navigation需要在
module.json5中注册routerMap,而HMRouter的路由配置更轻量化,仅需在注解中指定pageUrl,且仅识别常量作为pageUrl,不支持变量、静态属性等动态值。 - 根导航页设计不同:HMRouter的根导航页是
HMNavigation组件,该组件内部无需编写任何UI代码,仅需配置首个跳转页面即可;而原生Navigation的根容器需要手动配置NavPathStack、分栏模式等参数。 - 生命周期做了精简:原生Navigation的生命周期丰富但繁琐,HMRouter对其做了精简,仅暴露开发中常用的生命周期(如
onShown、onHidden、onBackPress等),屏蔽了底层不常用的生命周期回调,降低了开发复杂度。 - 栈操作方法做了简化:HMRouter仅暴露
push、pop、replace三个核心栈操作方法,屏蔽了原生Navigation的moveIndexToTop、popToIndex等精细化方法,满足大部分常规导航需求;若需精细化操作,可通过HMRouterMgr获取底层的NavPathStack实例,直接调用Navigation的原生API。
HMRouter 的核心实现原理
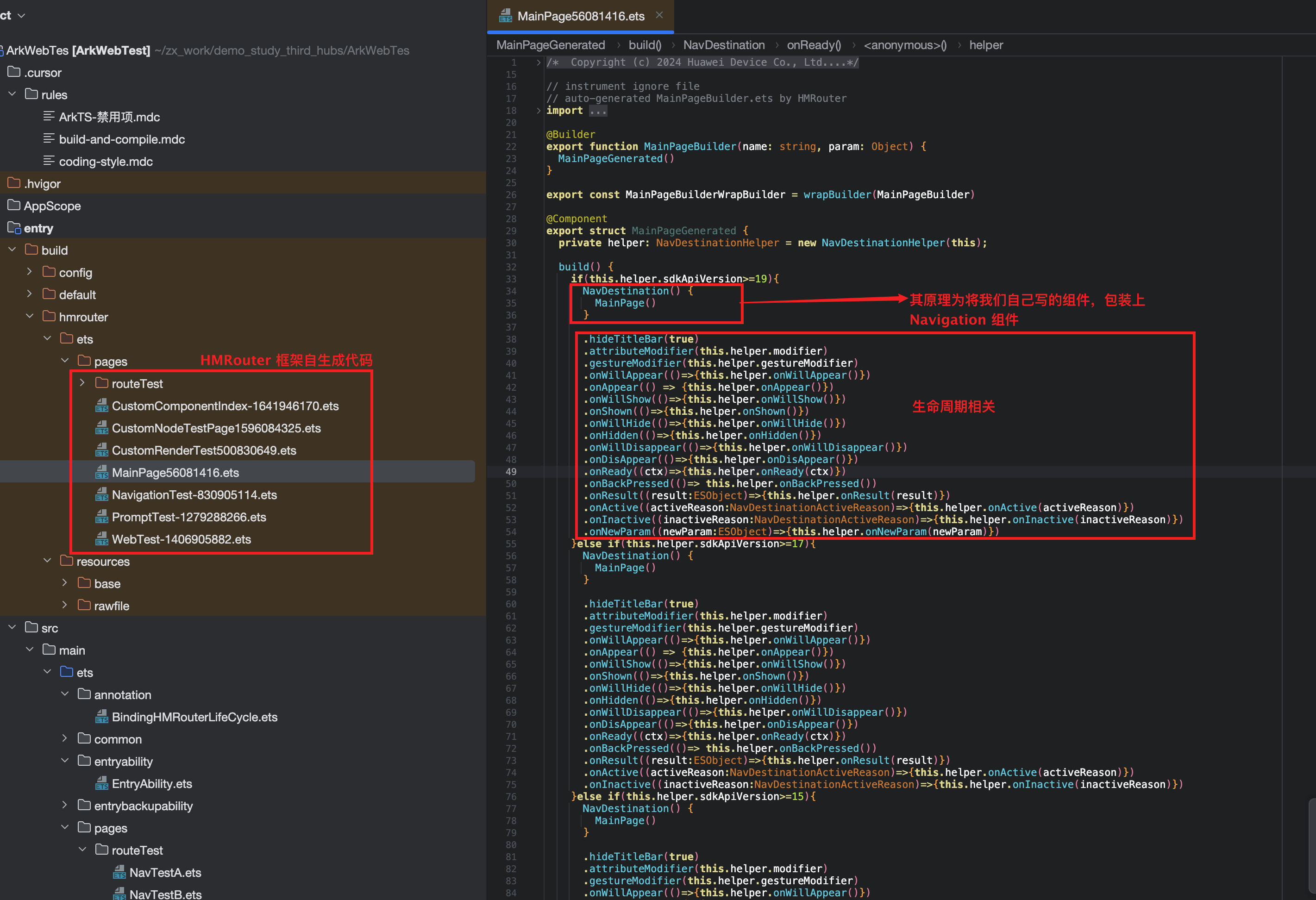
HMRouter基于注解驱动 + 代码生成 + Navigation原生API实现,其底层实现原理可分为3个核心步骤,本质是对Navigation的二次封装:
- 注解解析与代码生成:HMRouter通过编译时注解解析
@HMRouter注解的参数(如pageUrl),在构建工程时自动生成路由表代码、组件包裹代码(自动将目标组件包裹在NavDestination中),无需开发者手动编写,这是其简化开发的核心。 - 路由映射与组件匹配:HMRouter在应用启动时,会初始化内部的路由映射表,将注解中的
pageUrl与目标组件的构建函数进行绑定;当调用跳转方法时,通过pageUrl在路由映射表中匹配到对应的组件,完成导航目标的识别。 - 调用Navigation原生API完成导航:HMRouter接收到跳转请求后,会将开发者传入的参数(页面名称、跳转参数、动画配置)转换为Navigation的原生参数,然后调用
NavPathStack的pushPathByName、replacePathByName等原生API,完成组件的入栈、出栈、替换等操作,所有导航的底层逻辑仍由Navigation实现。
HMRouter 的核心使用注意点(我踩过的坑!)
- pageUrl 仅支持常量:
@HMRouter注解的pageUrl参数只能是字符串常量,不支持变量、类的静态属性、动态计算值等,否则会解析失败。 - 目标组件无特殊容器:HMRouter的目标组件无需手动包裹
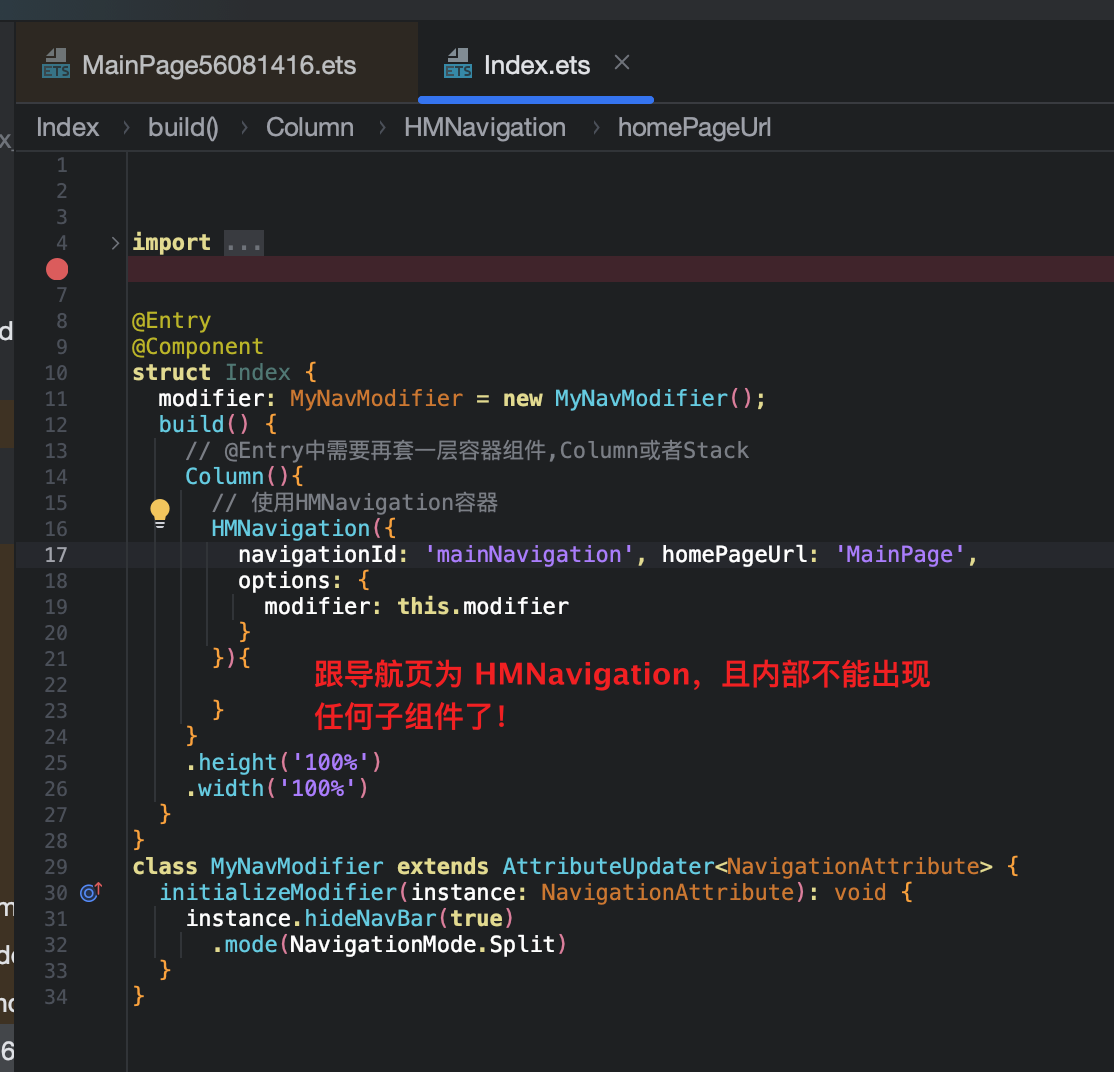
NavDestination,也无需添加@Entry()注解,仅需添加@HMRouter注解即可,底层会自动完成容器包裹。 - 根导航页为HMNavigation:应用的根页面必须是
HMNavigation组件,且该组件内部不能编写任何UI代码,仅需配置首个跳转的pageUrl。
- 精细化操作需获取NavPathStack:若需实现
移到栈顶、弹出指定页面等精细化操作,可通过HMRouterMgr.getNavPathStack()获取底层的NavPathStack实例,直接调用Navigation的原生API。
三者的核心对比与开发选型总结
核心维度对比表
|
对比维度 |
Router |
Navigation |
HMRouter |
|
导航类型 |
系统级页面导航 |
应用级组件导航 |
基于Navigation的三方组件导航 |
|
管理对象 |
被@Entry标注的Page页面 |
被NavDestination包裹的普通组件 |
被@HMRouter注解的普通组件 |
|
栈管理层面 |
系统维护的Page栈 |
应用维护的组件栈 |
封装后的应用组件栈(底层为Navigation栈) |
|
栈深度限制 |
最大32个 |
无限制 |
无限制(继承Navigation) |
|
资源消耗 |
高(Page页面重) |
低(普通组件轻) |
低(继承Navigation) |
|
参数传递 |
IPC值传递,效率低 |
引用传递,效率高 |
引用传递,效率高(继承Navigation) |
|
多设备兼容 |
不支持 |
原生支持(分栏、折叠屏) |
原生支持(继承Navigation) |
|
嵌套跳转 |
不支持 |
支持 |
支持(继承Navigation) |
|
动效支持 |
仅系统默认Page动画 |
共享元素、自定义动画 |
继承Navigation,可扩展 |
|
接入成本 |
低(原生API,无依赖) |
中等(需处理NavDestination、路由表) |
低(注解式,无需手动配置) |
|
灵活性 |
低(仅基础栈操作) |
高(精细化栈操作、拦截器) |
中等(简化栈操作,可扩展原生API) |
|
依赖情况 |
鸿蒙原生,无依赖 |
鸿蒙原生,无依赖 |
需引入三方SDK |
开发选型建议
小型简单应用:可直接使用Router,接入成本低,无需额外学习,基础的push、back操作能满足需求,且无三方依赖,适配性稳定。
中大型复杂应用:优先使用Navigation,无栈深度限制、轻量化、灵活性高,能满足多设备兼容、嵌套导航、精细化控制等需求,也是鸿蒙官方推荐方案,适合应用的长期迭代。
追求开发效率的中大型应用:可使用HMRouter,基于Navigation封装,保留了其所有核心优势,同时通过注解简化了开发,降低了接入成本,适合快速开发;若需精细化导航控制,可直接调用底层Navigation的API。
迁移建议:从Router到Navigation/HMRouter
目前鸿蒙开发的主流趋势是从Router迁移到Navigation/HMRouter,迁移过程中核心需注意3点:
- 移除@Entry注解:将原Page页面的@Entry()注解移除,使其成为普通组件,若使用Navigation则手动包裹NavDestination,若使用HMRouter则添加@HMRouter注解。
- 统一导航容器:应用根页面替换为Navigation/HMNavigation容器,所有页面均作为该容器的子组件,实现同一个Window中的组件级导航。
- 适配参数传递与生命周期:将原Router的IPC值传递改为引用传递,适配Navigation/HMRouter的组件级生命周期,替换原Page的系统级生命周期回调。最终总结
最终总结
Router、Navigation、HMRouter三者的发展脉络,本质是鸿蒙导航方案从系统级页面导航向应用级组件导航的演进,核心是为了解决Router的Page页面过重、栈深度受限、灵活性差等痛点。
Router作为初代方案,完成了鸿蒙页面导航的基础落地,但受限于系统级Page的设计,无法满足复杂应用的需求;Navigation作为新一代原生方案,从设计理念上颠覆了Router,将导航下沉到组件层,实现了轻量化、无栈限制、高灵活性,是鸿蒙官方的核心推荐方案;HMRouter则站在Navigation的基础上,通过注解驱动和代码生成简化了开发,降低了接入成本,是Navigation的优秀三方封装,适合追求开发效率的场景。
在实际开发中,无需纠结三者的“优劣”,而是根据应用的规模和需求选择合适的方案:小型应用用Router快速落地,中大型应用用Navigation保证扩展性,追求效率则用HMRouter。同时三者可混搭使用,在已有Router的项目中,可逐步将核心页面迁移到Navigation/HMRouter,实现平滑过渡。
整体而言,Navigation是鸿蒙导航的核心基础,HMRouter是其优秀的封装扩展,而Router则逐渐成为历史方案,这也是鸿蒙组件化开发的核心趋势——将更多的控制权从系统层下沉到应用组件层,让开发者拥有更高的灵活性和更优的性能表现

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)