
小模型在昇腾NPU上的推理部署:【伪精度案例】
伪精度案例:当余弦相似度为 1 时,算子就一定没问题吗?在模型转换(ONNX → OM)过程中,精度比对是验证模型正确性的关键环节。本文记录了一个典型的“伪精度”问题案例,供参考。在精度比对中,通常使用随机输入(如)生成测试数据,这会引入大量小数点后的微小差异。但在实际业务场景中,模型的输入是固定的、符合真实分布的,并不会出现这些极端边界情况。
作者:昇腾实战派
小模型在NPU上的推理部署: 【知识地图】
简介
伪精度案例:当余弦相似度为 1 时,算子就一定没问题吗?
在模型转换(ONNX → OM)过程中,精度比对是验证模型正确性的关键环节。本文记录了一个典型的“伪精度”问题案例,供参考。
1. 精度比对流程
当 OM 模型出现精度问题时,通常使用 msprobe 工具对 ONNX 和 OM 的算子输入输出进行逐层比对。
比对指标采用余弦相似度,一般认为相似度低于 0.9995 时,OM 模型存在精度问题。
工具链接:
msprobe 离线模型比对文档
2. 问题现象
比对结果 result.csv 中,大量算子的相似度在 0.8 ~ 0.95 之间。
按照“从第一个输入正常、输出异常的算子开始,逐层定位”的原则,最终将问题锁定在 TopK 算子。
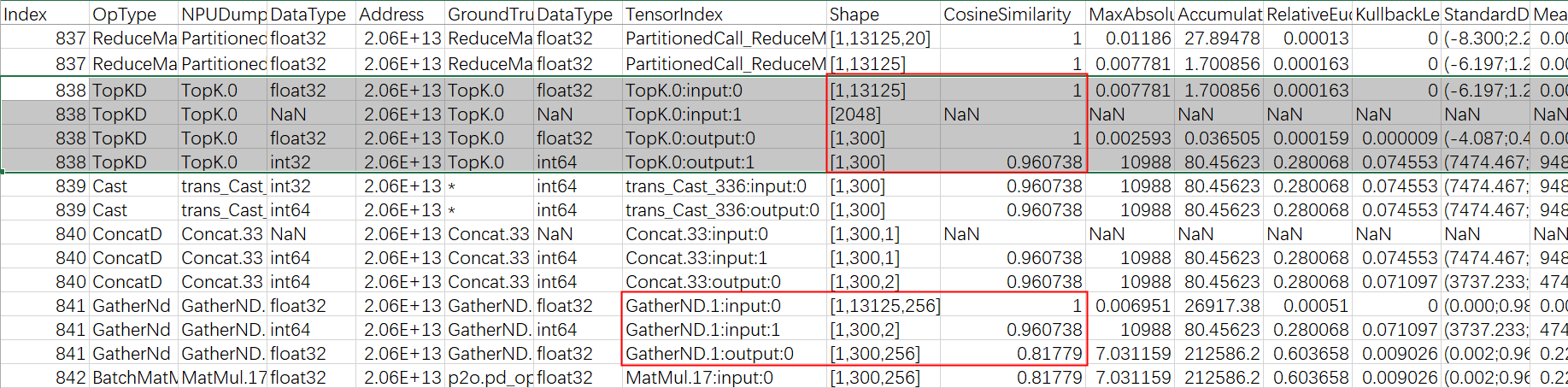
从 CSV 截图来看:
- TopK 算子的两个输入余弦相似度均为
1 - 两个输出中,第一个输出(值)相似度为
1,第二个输出(索引)相似度仅为0.96
进一步分析发现,后续的 gatherND 算子是首个出现精度显著下降的节点,其输出相似度从输入的 0.96 骤降至 0.81。由于 gatherND 的输入直接来源于 TopK 的输出,因此根因仍指向 TopK。
初步判断:TopK 算子可能存在精度问题。
3. 根因分析
3.1 输入并非完全一致
虽然 CPU 与 NPU 的输入 Tensor 余弦相似度为 1,但逐元素对比发现,两者存在微小数值差异,并非二进制完全一致。
3.2 TopK 对微小误差极其敏感
TopK 属于严格排序类算子,输入中的极小数值差异,可能直接改变元素的排序关系,从而导致输出索引出现明显差异。
4. 实验验证
为确认问题根源,进行了交叉验证:
- 用 CPU 输入喂给 NPU 算子:两个输出与 CPU 结果完全一致,严格符合 TopK 数学语义
- 用 NPU 输入喂给 CPU 算子:两个输出与 CPU 结果完全一致,严格符合 TopK 数学语义
结论:在输入完全一致的情况下,NPU 算子行为与 CPU 一致,算子本身无精度问题。
5. 现象解释
余弦相似度为 1,仅说明向量方向高度一致,并不代表 Tensor 二进制完全相同。
输入的浮点微小误差,经过 TopK 这类敏感算子后,被放大并体现在输出索引上。
这是“输入误差 + 算子敏感性”共同导致的正常现象,而非 TopK 算子的实现缺陷。
6. 总结
在精度比对中,通常使用随机输入(如 torch.randn)生成测试数据,这会引入大量小数点后的微小差异。
但在实际业务场景中,模型的输入是固定的、符合真实分布的,并不会出现这些极端边界情况。


作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐
 6
6 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)