
HarmonyOS 6 自定义人脸识别模型8:MindSpore Lite框架介绍与使用
本文介绍了如何在HarmonyOS 6中使用MindSpore Lite框架进行AI模型推理开发。MindSpore Lite是鸿蒙内置的轻量化AI引擎,支持CPU/GPU/NNP多硬件加速。文章首先解析了其在鸿蒙AI架构中的位置,位于MindSpore Lite Kit层,通过NNRt Kit桥接底层硬件。然后提供了两种开发方案:ArkTS API快速原型验证和C++ Native API高性能
HarmonyOS 6 自定义人脸识别模型8:MindSpore Lite框架介绍与使用
入坑鸿蒙 AI 开发,光会用系统自带的 Vision Kit 肯定是不够的。如果我们想搞点更有技术含量的,比如跑一个自己训练的、甚至是网上淘来的大模型,想要实时预览识别,那就得认识一下今天的主角——MindSpore Lite。
1. MindSpore Lite 是什么?
简单来说,MindSpore Lite 是 HarmonyOS 内置的轻量化 AI 引擎。它不只是一个库,而是一套端到端的全场景 AI 解决方案。
- 轻量化:专门为移动端优化,模型更小,启动更快。
- 全场景:一套架构支持 CPU、GPU 以及 NNP(神经网络处理器)。
- 高性能:内核算法经过汇编级优化,支持算子融合、量化策略,能最大化榨取硬件算力。
它目前被广泛应用在图像分类、目标识别、人脸识别和文字识别等场景中。
2. 它在鸿蒙 AI 架构里的“地位”
为了让大家更有全局观,我们得看下鸿蒙 AI 的开放层次:
- MindSpore Lite Kit:最上层的通用推理引擎。
- Neural Network Runtime (NNRt) Kit:中间桥梁,对接各种 AI 加速芯片。
- CANN Kit:华为海思的底层计算架构,负责算子级的深度优化。
这种分层设计意味着你可以用统一的接口(mslite)编写代码,而底层会自动匹配最合适的加速芯片。
3. 如何上手:两套开发方案
在 HarmonyOS 中使用 MindSpore Lite 方案主要有两种:
- 方式一:使用 ArkTS API:直接在 JS/ArkTS 层调用。代码写起来飞快,适合快速原型验证。
- 方式二:使用 Native (C++) API:这是高性能应用的唯一选。 它可以规避频繁的跨语言数据拷贝,在高频图像处理(如人脸识别)中优势巨大。
4. 实战干活:高性能 Native 推理全流程
追求极致性能的应用,通常会选择将 MindSpore Lite 集成在 C++ 侧,以彻底规避 ArkTS 与 Native 之间大数据拷贝带来的开销。下面我们将通过完整的代码实现,拆解一个图像分类任务的全过程。
4.1 Native C++ 推理核心实现
这是 AI 算法的“心脏”。主要逻辑封装在 NAPI 层中,负责从文件读取模型、构建引擎并执行预测。
(1) 环境准备与日志宏
首先,我们需要引入 MindSpore Lite 的核心头文件,并定义一套用于调试的日志工具。
#include <hilog/log.h>
#include <rawfile/raw_file_manager.h>
#include <mindspore/model.h>
#include <mindspore/context.h>
#include <mindspore/tensor.h>
#include "napi/native_api.h"
#define LOGI(...) ((void)OH_LOG_Print(LOG_APP, LOG_INFO, LOG_DOMAIN, "[MSLiteNapi]", __VA_ARGS__))
#define LOGE(...) ((void)OH_LOG_Print(LOG_APP, LOG_ERROR, LOG_DOMAIN, "[MSLiteNapi]", __VA_ARGS__))
(2) 优雅地加载模型文件 (RawFile)
模型文件通常放在系统的 resources/rawfile 下。我们使用 NativeResourceManager 来读取它。
void *ReadModelFile(NativeResourceManager *nativeResourceManager, const std::string &modelName, size_t *modelSize) {
auto rawFile = OH_ResourceManager_OpenRawFile(nativeResourceManager, modelName.c_str());
if (rawFile == nullptr) return nullptr;
long fileSize = OH_ResourceManager_GetRawFileSize(rawFile);
void *modelBuffer = malloc(fileSize);
// 从资源文件中读取数据到内存 Buffer
OH_ResourceManager_ReadRawFile(rawFile, modelBuffer, fileSize);
OH_ResourceManager_CloseRawFile(rawFile);
*modelSize = fileSize;
return modelBuffer;
}
(3) 构建推理上下文与模型 (Model Build)
这是调优的关键,我们可以在此开启 FP16 半精度加速。
OH_AI_ModelHandle CreateMSLiteModel(void *modelBuffer, size_t modelSize) {
// 1. 创建并配置 Context
auto context = OH_AI_ContextCreate();
auto cpu_info = OH_AI_DeviceInfoCreate(OH_AI_DEVICETYPE_CPU);
OH_AI_DeviceInfoSetEnableFP16(cpu_info, true); // 开启 FP16 加速
OH_AI_ContextAddDeviceInfo(context, cpu_info);
// 2. 创建并构建 Model
auto model = OH_AI_ModelCreate();
auto build_ret = OH_AI_ModelBuild(model, modelBuffer, modelSize, OH_AI_MODELTYPE_MINDIR, context);
free(modelBuffer); // 构建完成后即可释放原始 Buffer
return (build_ret == OH_AI_STATUS_SUCCESS) ? model : nullptr;
}
(4) 执行推理与数据交互 (Predict)
推理完成后,我们需要从 Tensor 对象中提取预测概率。
int RunMSLiteModel(OH_AI_ModelHandle model, std::vector<float> input_data) {
auto inputs = OH_AI_ModelGetInputs(model);
// 填充输入数据
float *data = (float *)OH_AI_TensorGetMutableData(inputs.handle_list[0]);
std::copy(input_data.begin(), input_data.end(), data);
auto outputs = OH_AI_ModelGetOutputs(model);
// 执行预测
auto predict_ret = OH_AI_ModelPredict(model, inputs, &outputs, nullptr, nullptr);
// 打印输出 Tensor 的前几个结果进行验证
auto out_data = reinterpret_cast<const float *>(OH_AI_TensorGetData(outputs.handle_list[0]));
LOGI("First probability: %{public}f", out_data[0]);
return predict_ret;
}
4.2 ArkTS 业务逻辑:图像预处理与 UI 展示
有了底层的心脏,还需要在 ArkTS 侧进行图像采集和复杂的预处理。AI 推理的成败,50% 取决于预处理(Preprocessing)是否与模型训练时一致。
(1) 图片采集与裁剪
使用 PhotoViewPicker 获取图片,并利用 PixelMap 将其处理为模型要求的尺寸(如 224x224)。
// 1. 选取图片
let photoPicker = new photoAccessHelper.PhotoViewPicker();
let photoSelectResult = await photoPicker.select(photoSelectOptions);
let uri = photoSelectResult.photoUris[0];
// 2. 预处理:缩放与裁剪 (以 MobileNetV2 为例)
let imageSource = image.createImageSource(fileIo.openSync(uri).fd);
let pixelMap = await imageSource.createPixelMap({ editable: true });
// 缩放并居中裁剪
await pixelMap.scale(256.0 / width, 256.0 / height);
await pixelMap.crop({ x: 16, y: 16, size: { height: 224, width: 224 } });
(2) 归一化与标准化 (Normalization)
这是最关键的一步。我们需要将像素值转换为 Float32Array,并执行常见的标准化公式:(pixel / 255.0 - mean) / std。
let readBuffer = new ArrayBuffer(224 * 224 * 4);
await pixelMap.readPixelsToBuffer(readBuffer);
const imageArr = new Uint8Array(readBuffer);
let means = [0.485, 0.456, 0.406]; // ImageNet 标准均值
let stds = [0.229, 0.224, 0.225]; // ImageNet 标准方差
let float32View = new Float32Array(224 * 224 * 3);
let index = 0;
for (let i = 0; i < imageArr.length; i += 4) {
// 提取 RGB,并执行:(x / 255.0 - mean) / std
float32View[index] = (imageArr[i] / 255.0 - means[0]) / stds[0]; // R
float32View[index + 1] = (imageArr[i + 1] / 255.0 - means[1]) / stds[1]; // G
float32View[index + 2] = (imageArr[i + 2] / 255.0 - means[2]) / stds[2]; // B
index += 3;
}
(3) 调用 Native 接口并展示 Top-5
最后将预处理后的数据传给 NAPI 接口,拿到结果后找到概率最大的前 5 个类别。
// 调用 C++ 侧封装的 runDemo
let output: Array<number> = msliteNapi.runDemo(Array.from(float32View), resMgr);
// 提取 Top-5 (ArgMax 逻辑)
// ... 排序逻辑 ...
this.resultMessage = `分类结果: ${labels[maxIndex]} (置信度: ${maxScore})`;
4.3 运行效果
运行日志如下: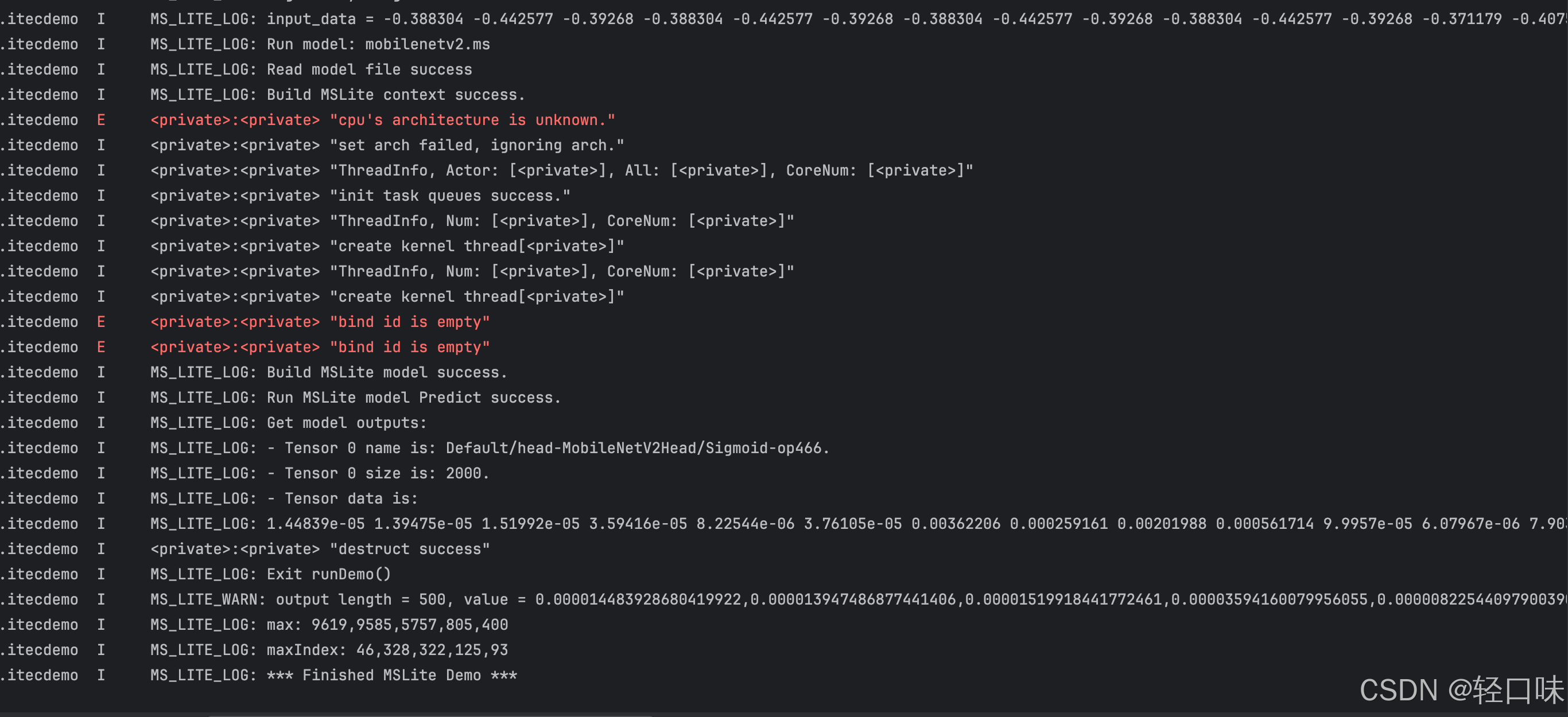
上传一个花朵图片后运行效果如下:
再以BLG战队定妆照为例:
5. 快速验证:ArkTS 接口方案(简洁版)
如果你只是想跑通一个简单的图像分类 Demo,或者模型逻辑比较简单,ArkTS 方案完全够用。它可以直接在 TypeScript 环境下完成模型加载与预测。
import { mindSporeLite } from '@kit.MindSporeLiteKit';
async function simplePredict(modelBuffer: ArrayBuffer, imgBuffer: ArrayBuffer) {
// 1. 设置推理上下文 (CPU 模式)
let context: mindSporeLite.Context = {
target: ['cpu'],
cpu: {
threadNum: 2,
threadAffinityMode: 1, // 绑大核以追求最高速度
precisionMode: 'enforce_fp16'
}
};
// 2. 从内存加载模型 (.ms 文件)
let msModel = await mindSporeLite.loadModelFromBuffer(modelBuffer, context);
// 3. 准备 Tensor 并执行预测
let modelInputs = msModel.getInputs();
modelInputs[0].setData(imgBuffer);
let outputs = await msModel.predict(modelInputs);
return outputs[0].getData(); // 返回 ArrayBuffer 结果
}
6. 避坑指南与性能调优建议
- 模型格式转换:MindSpore Lite 只认自己的 .ms 格式。如果你手头是 ONNX 或 TFLite 模型,必须使用华为提供的
converter_lite工具进行转换。 - 预处理一致性:这是 AI 推理最容易翻车的地方。图像的缩放方式(Bilinear vs Nearest)、归一化系数(Mean/Std)必须与训练脚本完全同步,否则准确率会大幅暴跌。
- 内存管理:在 Native 侧,手动申请的 Buffer 以及所有的
OH_AI_***_Create句柄,在使用完毕后必须调用对应的Destroy函数。切记:推理完成不等于资源释放。 - 利用 NRT 加速:如果你的设备支持 NPU,可以在 Context 中尝试添加
OH_AI_DEVICETYPE_NNRT硬件加速节点,进一步压榨推理时延。 - 模拟器支持:MindSpore Lite Kit 对模拟器支持良好,适合在没有真机时验证 N-API 的封装逻辑。
总结
MindSpore Lite 是我们在鸿蒙上复现高级 AI 算法的心脏。通过深入理解 Native 接口的 Context 配置和 Tensor 操作,我们可以构建出极致流畅的智能应用。在接下来的实战文章中,我们将以此为基础,正式将训练好的人脸识别模型部署到鸿蒙真机上,见证 AI 的力量!

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 2
2 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)