
AI 编译器系列(七)《(MLIR)AscendNPU IR 编译堆栈》
本文系统阐述了AscendNPUIR架构的设计原理与实现方法。该架构基于MLIR构建,包含HFusion和HIVM两层核心方言:HFusion负责高层语义预处理和算子简化,HIVM则面向昇腾NPU硬件特性进行轻量化抽象。通过多级方言转换流程、专用OP设计及内存优化技术,实现了从DSL到硬件指令的高效编译。架构还整合了调优选项和Compiler Hint机制,支持细粒度性能优化。AscendNPUI
目录
本文主要讲解 AscendNPU IR 架构。
AscendNPU IR 架构概述
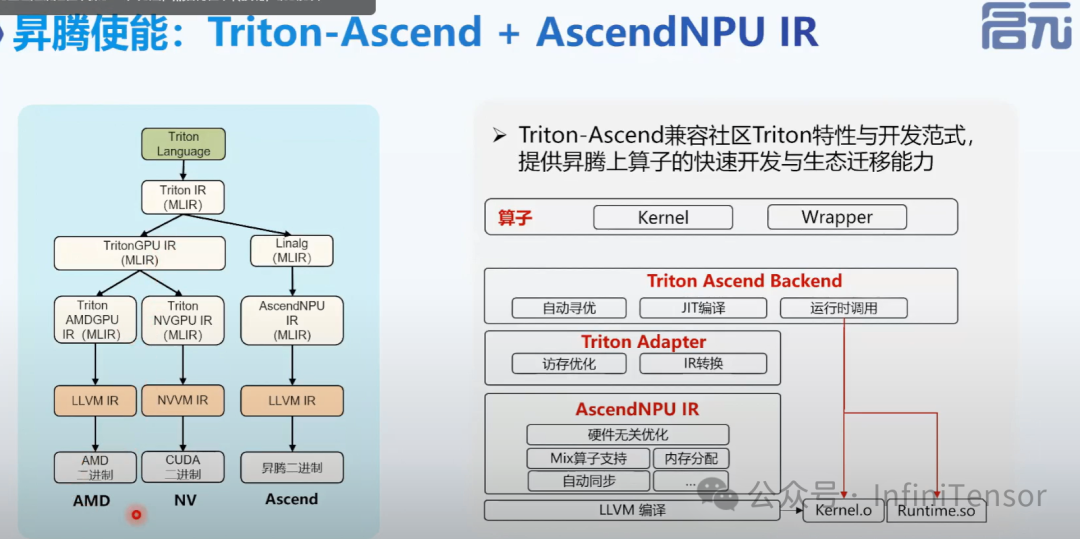
Triton-Ascend + AscendNPU IR
MLIR 简介:
1. 定义:
-
• MLIR(Multi-Level Intermediate Representation)是一种开源的编译基础设施,旨在通过统一且可扩展的中间表示解决软件碎片化和编译效率问题。
2. 特点:
-
• 多层方言(Dialects)支持,从高层计算图到低层硬件指令的全栈抽象。
AscendNPU IR 引入:
-
• 背景:为了支持更多前端编程语言和硬件平台,特别是在NPU(如昇腾NPU)上的优化。
-
• 目标:通过 AscendNPU IR 实现高效编译和硬件优化。
AscendNPU IR 架构详解
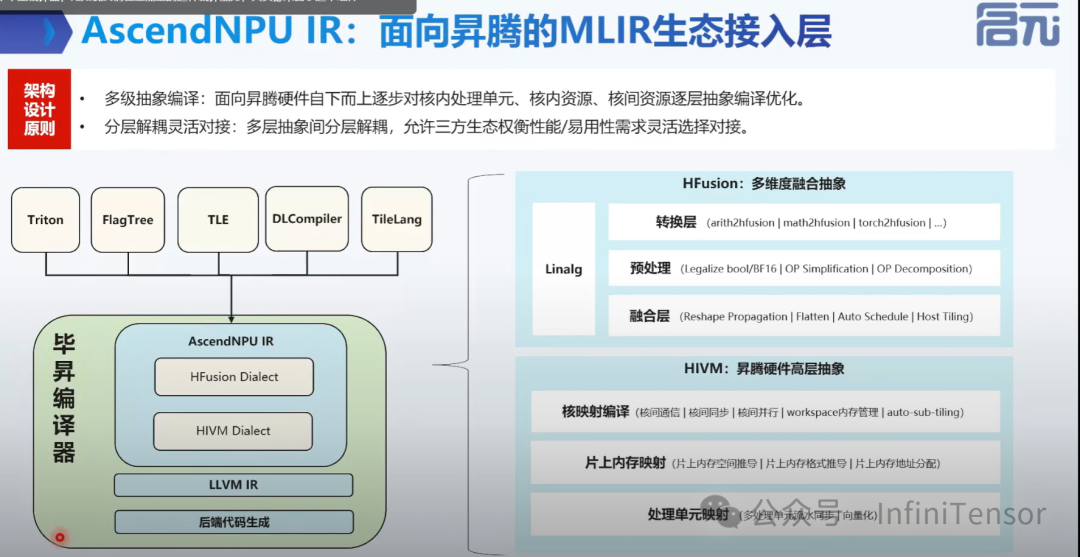
整体架构:
1. 方言层级:
-
• AscendNPU IR 采用多层方言设计,主要包括 Hfusion 和 HIVM 两层核心方言,辅以Annotation、HACC、Scope等辅助方言。
2. 转换流程:
-
• 从前端 DSL 到 Triton IR,再到 TritonGPU IR(或 MLIR 公共方言如 Linalg),最终转换为AscendNPU IR,并编译成二进制文件。
3. 核心方言解析:
-
• Hfusion:
-
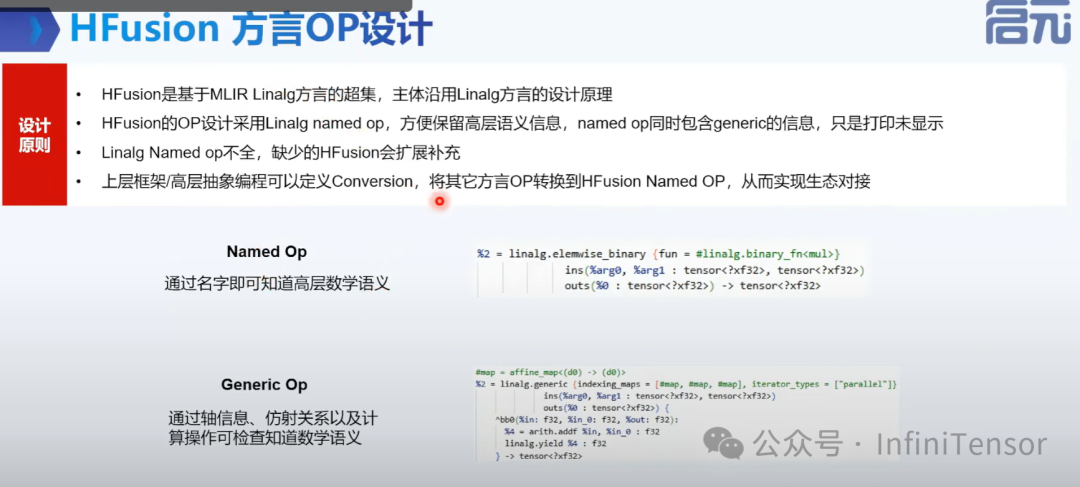
• 设计原理: 基于 Linalg 的扩展,采用命名 OP 保留高层语义信息。
-
• 功能: 数据预处理、OP 简化、类型转换等,不直接涉及硬件细节。
-
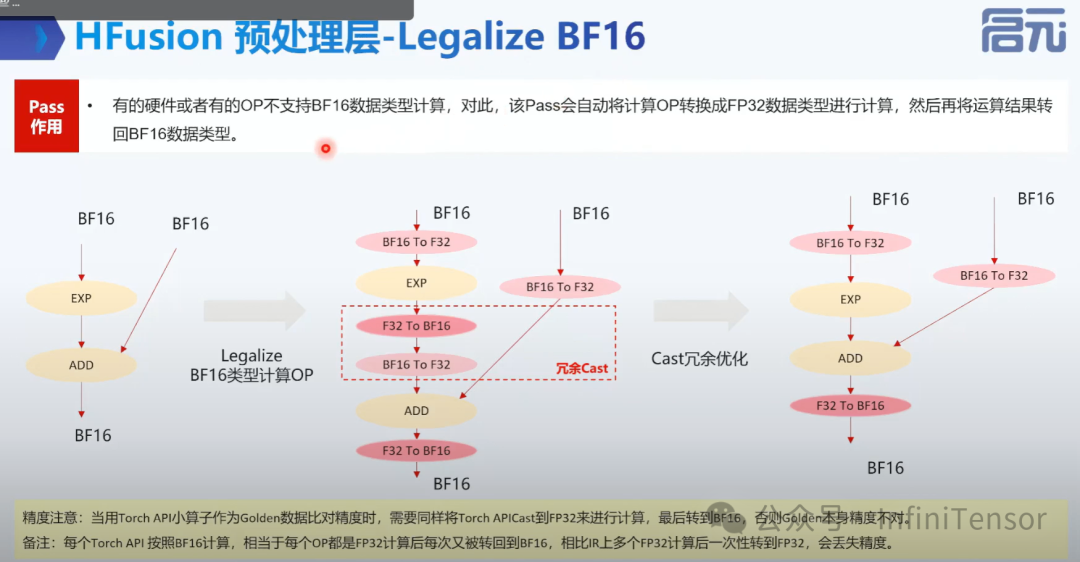
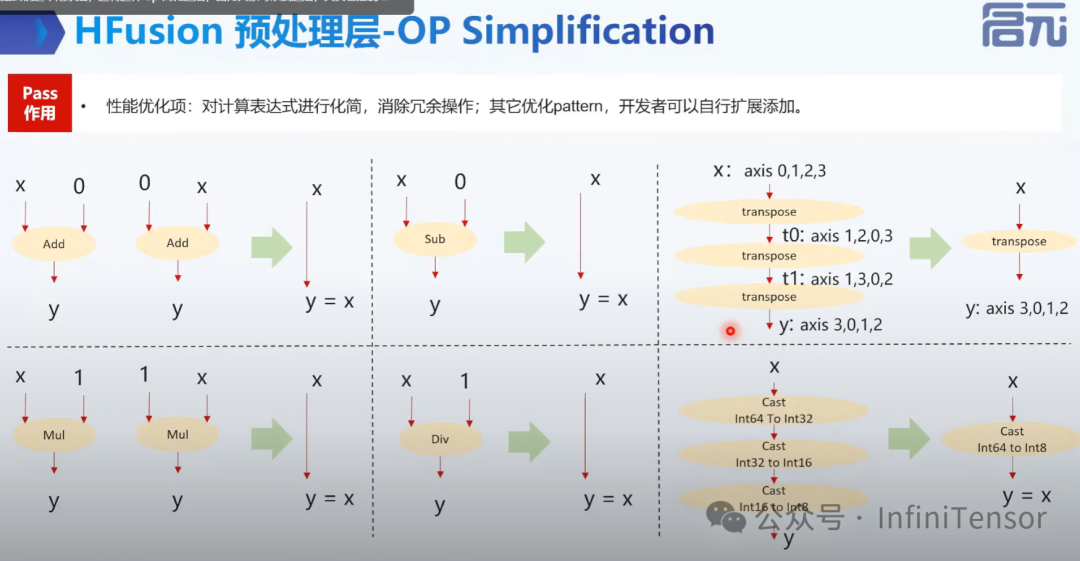
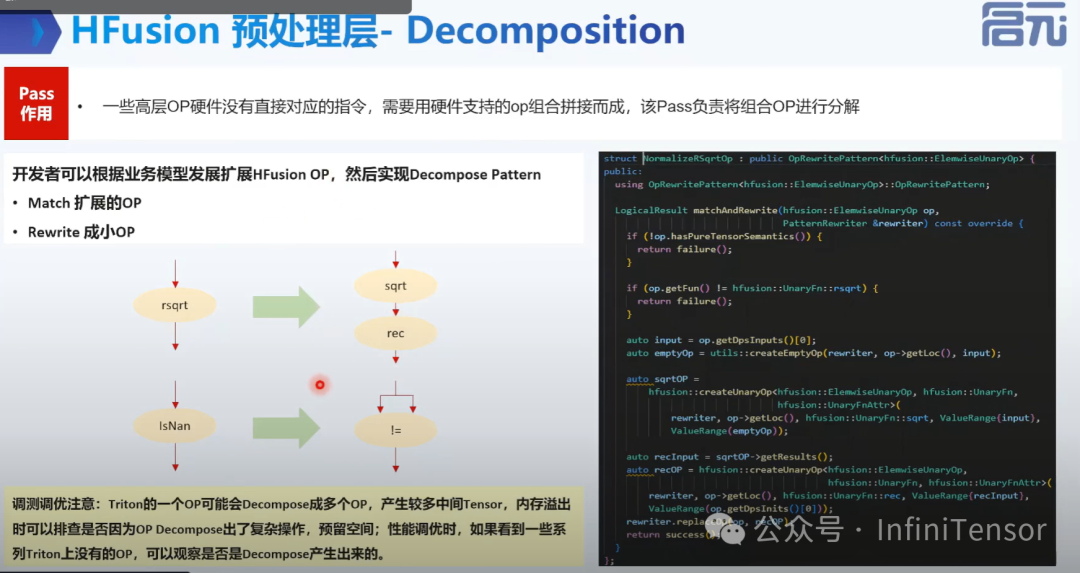
• 优化: 合法性检查、冗余操作消除、高层 OP 分解等。
-
-
• HIVM:
-
• 设计原则: 轻量化抽象硬件表达能力,每个 OP 处理一个单元操作。
-
• 功能: 支持硬件特定操作,如 Cube 类算子的快速构建,通过 Microop 封装复杂操作。
-
• 优化: 内存分配、指令映射、流水并行等。
-

4. 辅助方言:
-
• Annotation: 传递属性信息,如内存优化提示。
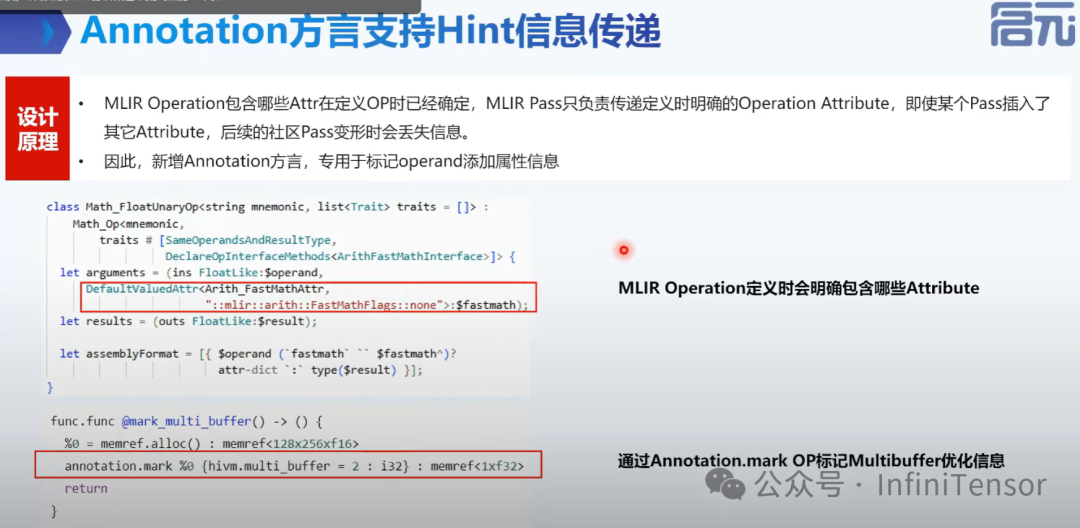
-
• HACC: 定义异构硬件相关信息,如函数类型、硬件单元信息。

-
• Scope: 代码区域标记,支持代码分块和函数提取。

HFusion 方言关键 Pass
昇腾硬件架构:
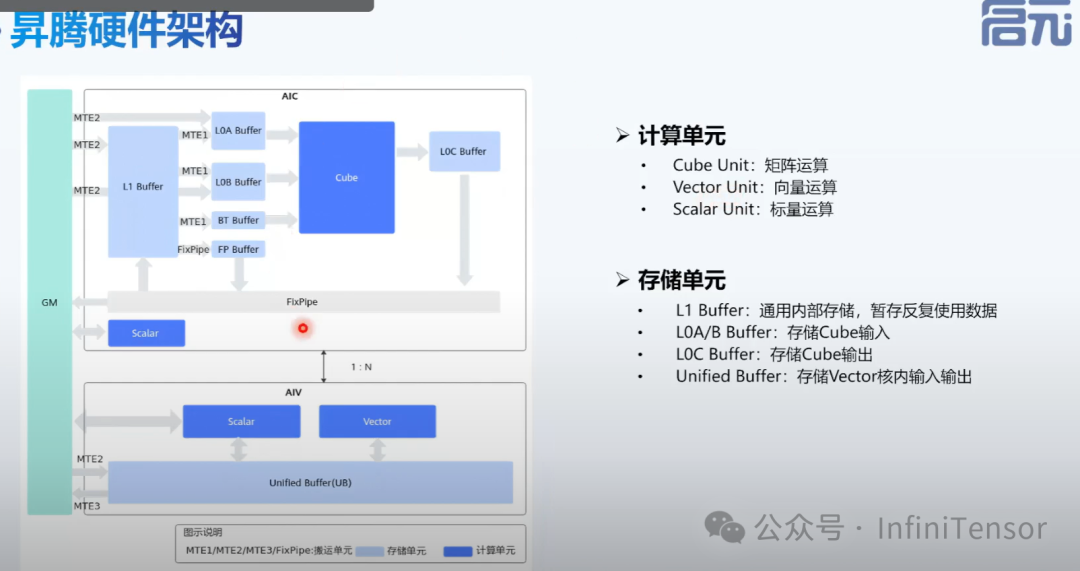
-
• AIC核与AIV核分离,各自拥有专属内存和计算单元。
-
• 核间数据交互通过Global Memory(GM)进行。
HFusion 方言 OP 设计
HFusion 预处理层
1. Legalize BF16
2. OP Simplification
3. Decomposition
HIVM 方言关键 Pass
HIVM OP 设计原则
-
• 基础 OP:根据每条芯片指令自底向上轻量化抽象,根据芯片能力校验 OP 约束。
-
• Macro OP:根据业务场景抽象,由多个处理单元操作复合组成。

HIVM OP 属性设计

HIVM OP Interface 设计

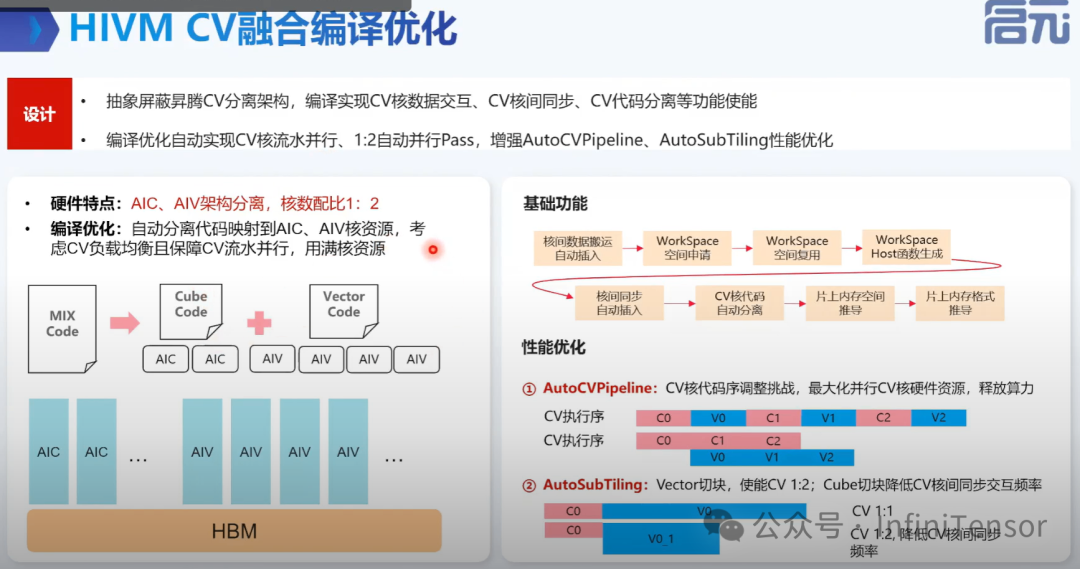
HIVM CV 融合编译优化
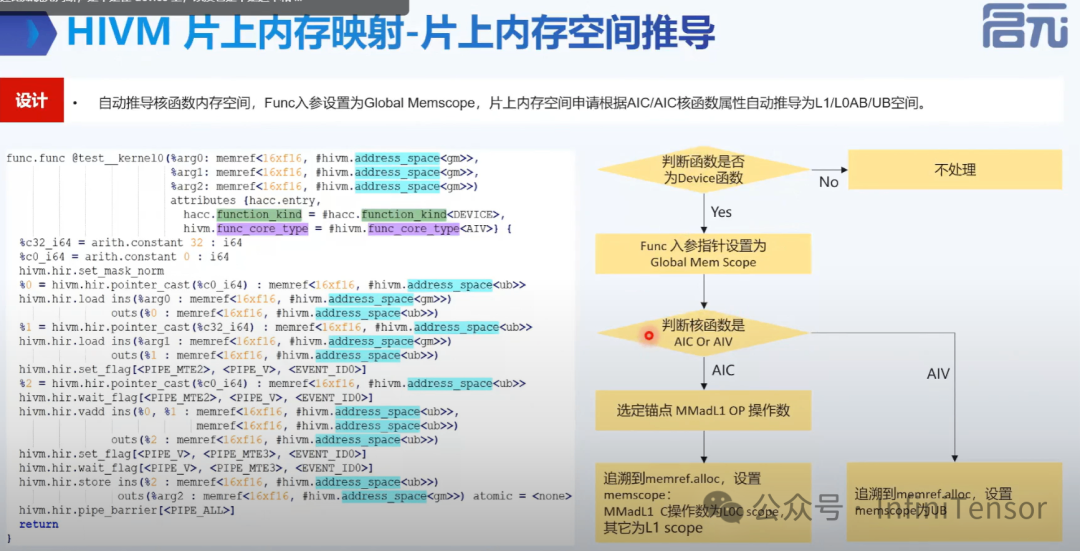
HIVM 片上内存映射
1. 片上内存空间推导
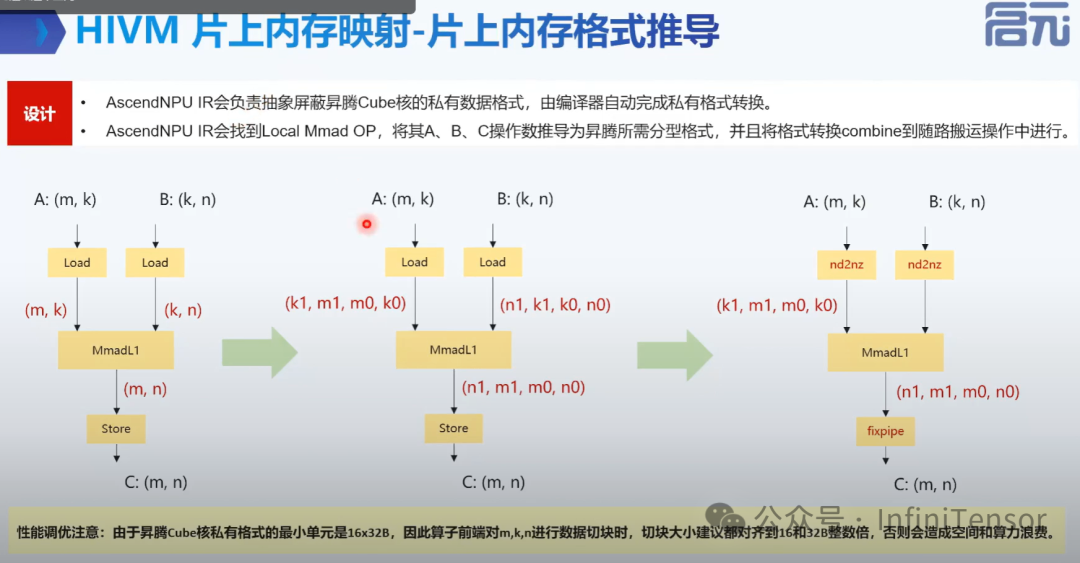
2. 片上内存格式推导
3. 片上内存自动对齐

调优选项及 Hint
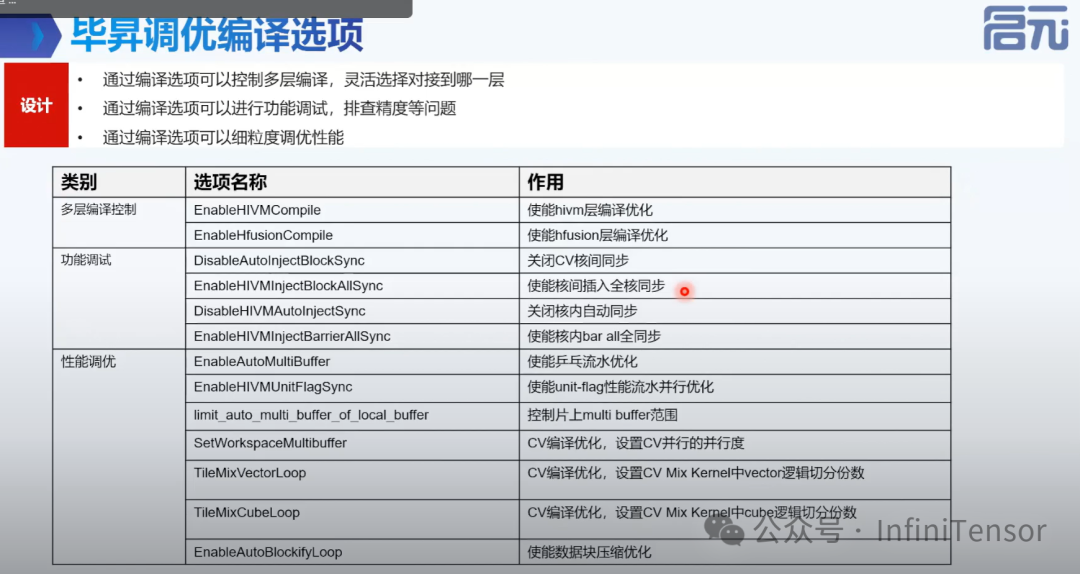
毕昇调优编译选项
-
• 控制多层编译,灵活选择对接层
-
• 进行功能调试,排查精度
- • 细粒度调优性能
细粒度调优 Compiler hint

总结
AscendNPU IR 作为 MLIR 的开源编译组件,通过多层方言设计和丰富的优化技术,有效支持了多种前端编程语言和昇腾 NPU 的硬件优化。未来将吸引更多开发者和研究者参与,共同推动编译器技术和高性能计算的发展。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 14
14 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)