
昇腾NPU 环境变量控制开关梳理
NPU上有许多相较于其他计算硬件上特有的加速特性,本文系统整理了使用NPU硬件的关键调优技巧,涵盖推理后端切换、通信算法优化、任务调度机制、内存管理等多个维度,旨在帮助开发者充分发挥昇腾硬件潜力,实现高效稳定的模型推理。
作者:昇腾实战派
背景介绍
NPU上有许多相较于其他计算硬件上特有的加速特性,本文系统整理了使用NPU硬件的关键调优技巧,涵盖推理后端切换、通信算法优化、任务调度机制、内存管理等多个维度,旨在帮助开发者充分发挥昇腾硬件潜力,实现高效稳定的模型推理。
性能相关
切换vllm注意力计算后端
export VLLM_ATTENTION_BACKEND=XFORMERS

注:需要注意某些后端在一些比较老的vllm-ascend版本内并不支持
AIV
export HCCL_OP_EXPANSION_MODE="AIV"
HCCL_OP_EXPANSION_MODE环境变量用于配置通信算法的编排展开位置,支持如下取值:
- AI_CPU:代表通信算法的编排展开位置在Device侧的AI CPU计算单元。
- AIV:代表通信算法的编排展开位置在Device侧的Vector Core计算单元。
- HOST:代表通信算法的编排展开位置为Host侧CPU,Device侧根据硬件型号自动选择相应的调度器。
- HOST_TS:代表通信算法的编排展开位置为Host侧CPU,Host向Device的Task Scheduler下发任务,Device的Task Scheduler进行任务调度执行。
下面介绍两种展开机制
HOST展开
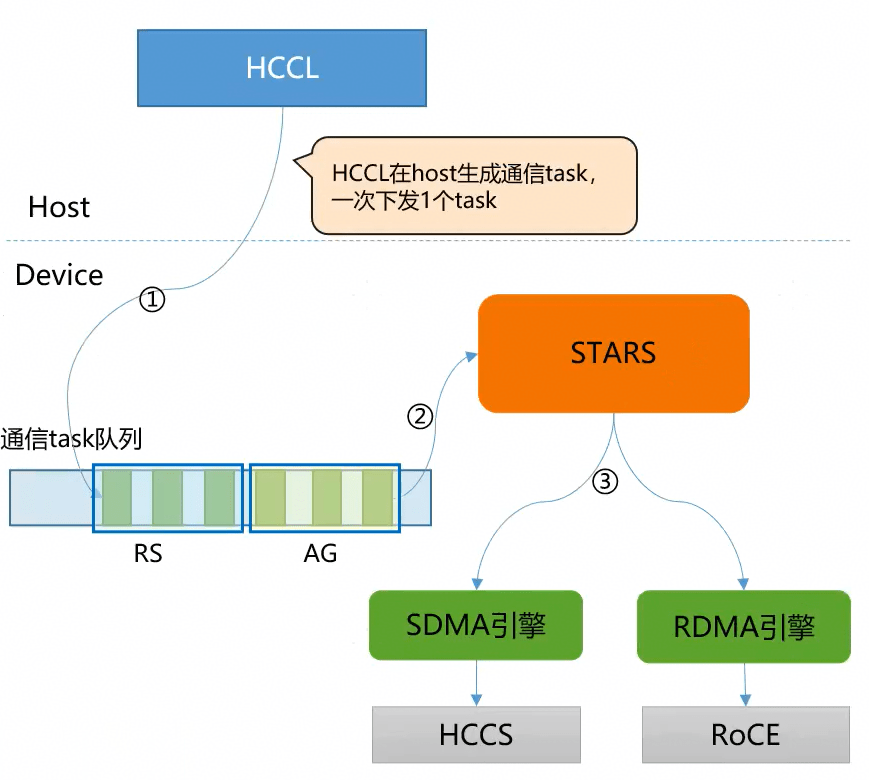
- 软件栈工作在hostcpu,通信算法展开一个个task
- 每个task调用runtime接口,下发到device的rtsqueue
- STARS从rstqueue上顺序拿取task
- 根据task类型分别调用掉SDMA和RDMA引擎。
单算子瓶颈:hostbound 每个task提交是2~5us,一个通信算子有几百个task,单算子场景不会在device上缓存,下发一个执行一个
AICpu机制展开
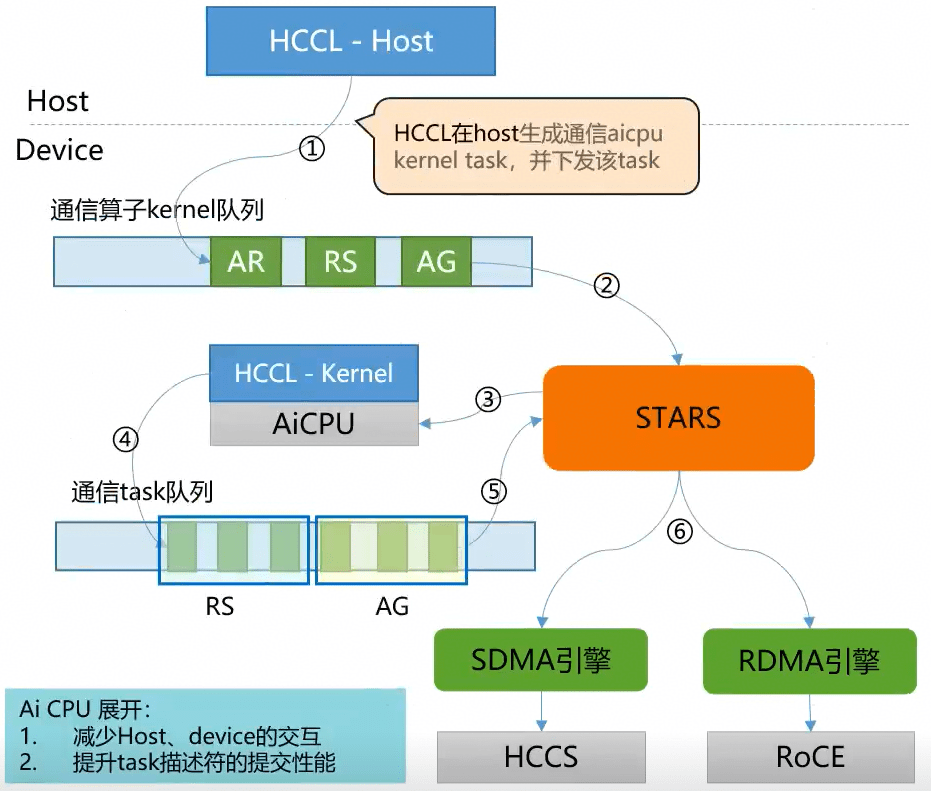
- host侧不下发一个个task,把通信算子作为一个个kernel,放在通信算子kernel的队列上去。
- STARS调度kernel队列流上的kernel,把kernel放到AiCPU上去执行。
- AICPU调用函数(kernel),用一个线程执行kernel 函数,在函数内把通信task展开,把task放到rstqueue上,STARS调用。
- 降低host和aicpu交互,由几百次降低为一次。
- task的提交在AICPU上提交,做了提交的部分合并。
TASK_QUEUE_ENABLE
export TASK_QUEUE_ENABLE=2
TASK_QUEUE_ENABLE,下发优化,图模式设置为1(即开启图模式的时候这个要设置为1),非图模式设置为2
示意图: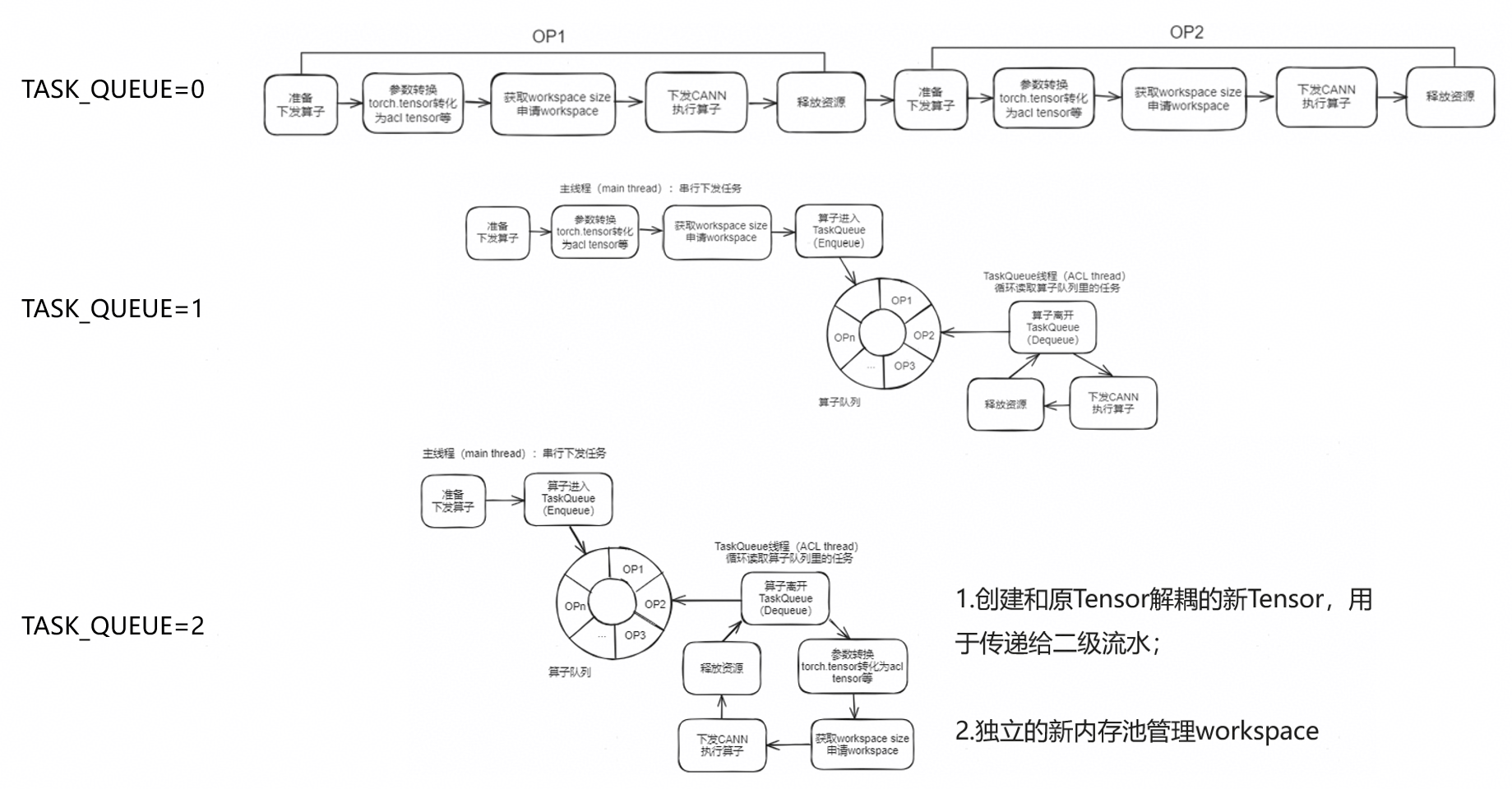
绑核优化
export CPU_AFFINITY_CONF=1
详细设置原理可看:https://www.hiascend.com/document/detail/zh/Pytorch/600/ptmoddevg/trainingmigrguide/performance_tuning_0059.html
多流复用
export MULTI_STREAM_MEMORY_REUSE=1
原理介绍:https://www.hiascend.com/document/detail/zh/Pytorch/600/ptmoddevg/trainingmigrguide/performance_tuning_0040.html
VLLM_ASCEND_ENABLE_FLASHCOMM
export VLLM_ASCEND_ENABLE_FLASHCOMM=1
启用昇腾 NPU 特有的FLASHCOMM高速通信优化技术
地址:https://vllm-ascend.readthedocs.io/zh-cn/latest/user_guide/release_notes.html
VLLM_ASCEND_ENABLE_DENSE_OPTIMIZE
export VLLM_ASCEND_ENABLE_DENSE_OPTIMIZE=1
启用昇腾 NPU针对大模型推理的稠密计算优化
地址:https://vllm-ascend.readthedocs.io/zh-cn/latest/user_guide/release_notes.html
VLLM_ASCEND_ENABLE_PREFETCH_MLP
export VLLM_ASCEND_ENABLE_PREFETCH_MLP=1
启用 MLP 层的权重预取机制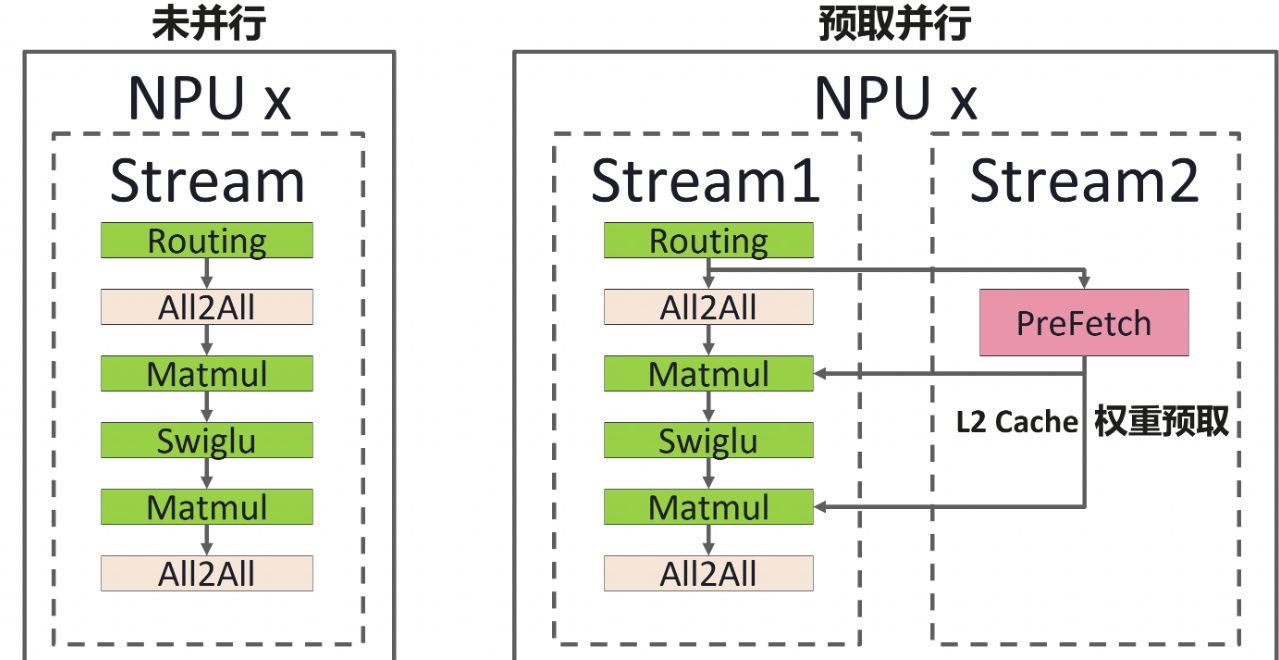
效率提升相关
打印prefill和decode详细信息
export VLLM_ASCEND_MODEL_EXECUTE_TIME_OBSERVE=1
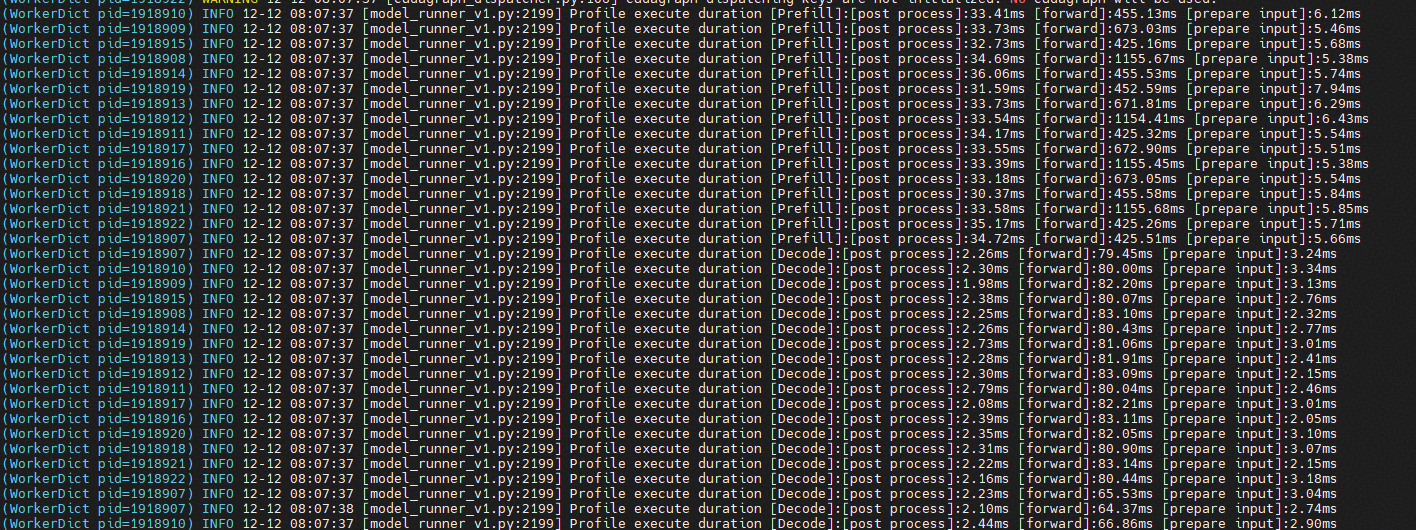
指定某几张显卡
export ASCEND_RT_VISIBLE_DEVICES=8,9,10,11,12,13,14,15

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 14
14 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)