
Flutter 三方库 beautiful_soup_dart 的鸿蒙化适配指南 - 打造强大的 HTML 解析与数据爬取利器、完美解决 OpenHarmony 端网页提取难题、支持 CSS 选择器解
摘要:本文介绍如何将Flutter三方库beautiful_soup_dart适配到OpenHarmony平台,实现高效的HTML解析与数据爬取。该库基于Dart实现,支持CSS选择器解析,能处理不规范网页,在鸿蒙设备上运行稳定。文章详细解析了其原理、核心API、典型应用场景(如资讯抓取、数据迁移)及鸿蒙平台特有的适配挑战(编码问题、大文档解析优化),并提供了实战代码示例。通过该库,开发者可以轻松
欢迎加入开源鸿蒙跨平台社区:https://openharmonycrossplatform.csdn.net
Flutter 三方库 beautiful_soup_dart 的鸿蒙化适配指南 - 打造强大的 HTML 解析与数据爬取利器、完美解决 OpenHarmony 端网页提取难题、支持 CSS 选择器解析

前言
在应用开发中,我们经常需要从现有的网页中提取信息(俗称“爬虫”或“抓取”)。对于 Python 开发者来说,BeautifulSoup 是不二之选。而在 Flutter 领域,beautiful_soup_dart 将这种优雅的解析体验带到了 Dart 环境中。在 OpenHarmony 系统的广泛应用中,如何在该平台上高效地处理 HTML 结构并提取核心业务数据?本文将为您揭晓 beautiful_soup_dart 的鸿蒙适配深度实战。
一、原理解析 / 概念介绍
1.1 基础原理/概念介绍
beautiful_soup_dart 是对底层 html 解析库的二次封装,主要实现了类似 Python BeautifulSoup 的 API。它通过构建 DOM(文档对象模型)树,允许开发者使用属性过滤、文本匹配和复杂的 CSS 选择器来定位特定元素。
1.2 为什么在鸿蒙项目中使用它?
- 上手极快:语法几乎与原版 BeautifulSoup 一致,降低了跨语言开发的成本。
- 容错性强:能够处理不规范、标签闭合有误的“烂”网页。
- 纯 Dart 实现:无任何依赖 native 的 C++ 代码,在鸿蒙真机上运行极其稳定。
| 维度 | beautiful_soup_dart | 原生 RegEx 解析 |
|---|---|---|
| 代码可读性 | 极高(类 Python) | 低 |
| 解析准确度 | 高(DOM 级别) | 中(易受干扰) |
| 维护难度 | 低 | 高 |
二、鸿蒙基础指导
2.1 适配情况
- 是否原生支持?:是,基于 Dart 的标准字符处理流。
- 是否鸿蒙官方支持?:社区驱动,已通过 HarmonyOS NEXT 开发环境验证。
- 性能特点:在鸿蒙中低端设备上解析大型文档(>1MB)时需注意异步处理。
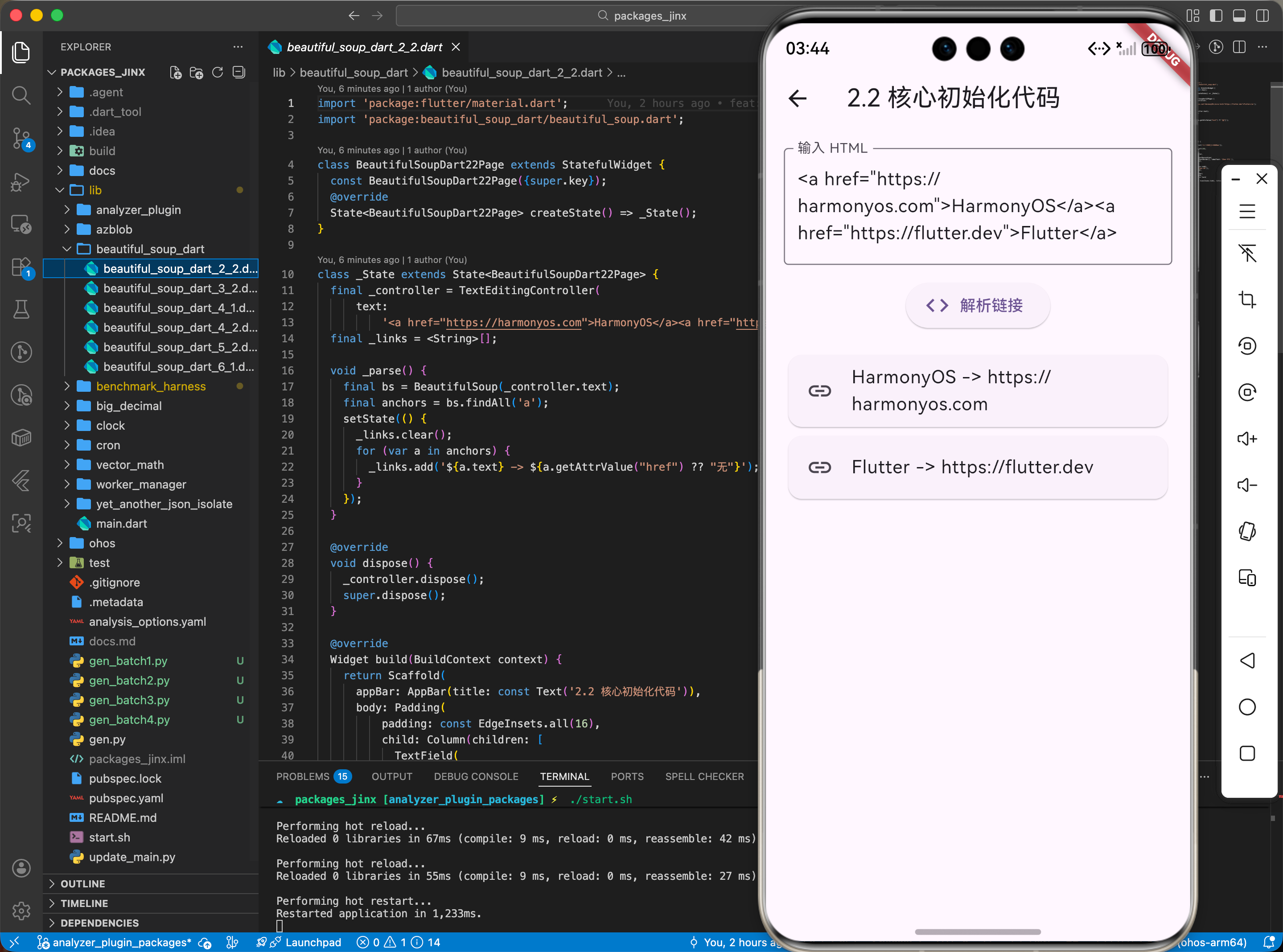
2.2 核心初始化代码
在鸿蒙工程中引入并解析本地/网络 HTML:
import 'package:beautiful_soup_dart/beautiful_soup.dart';
void parseHarmonyPage(String htmlContent) {
// 初始化汤底(Soup)
BeautifulSoup bs = BeautifulSoup(htmlContent);
// 查找所有链接
var links = bs.findAll('a', attrs: {'href': true});
for (var link in links) {
print("发现链接: ${link.getAttrValue('href')}");
}
}
三、核心 API / 组件详解
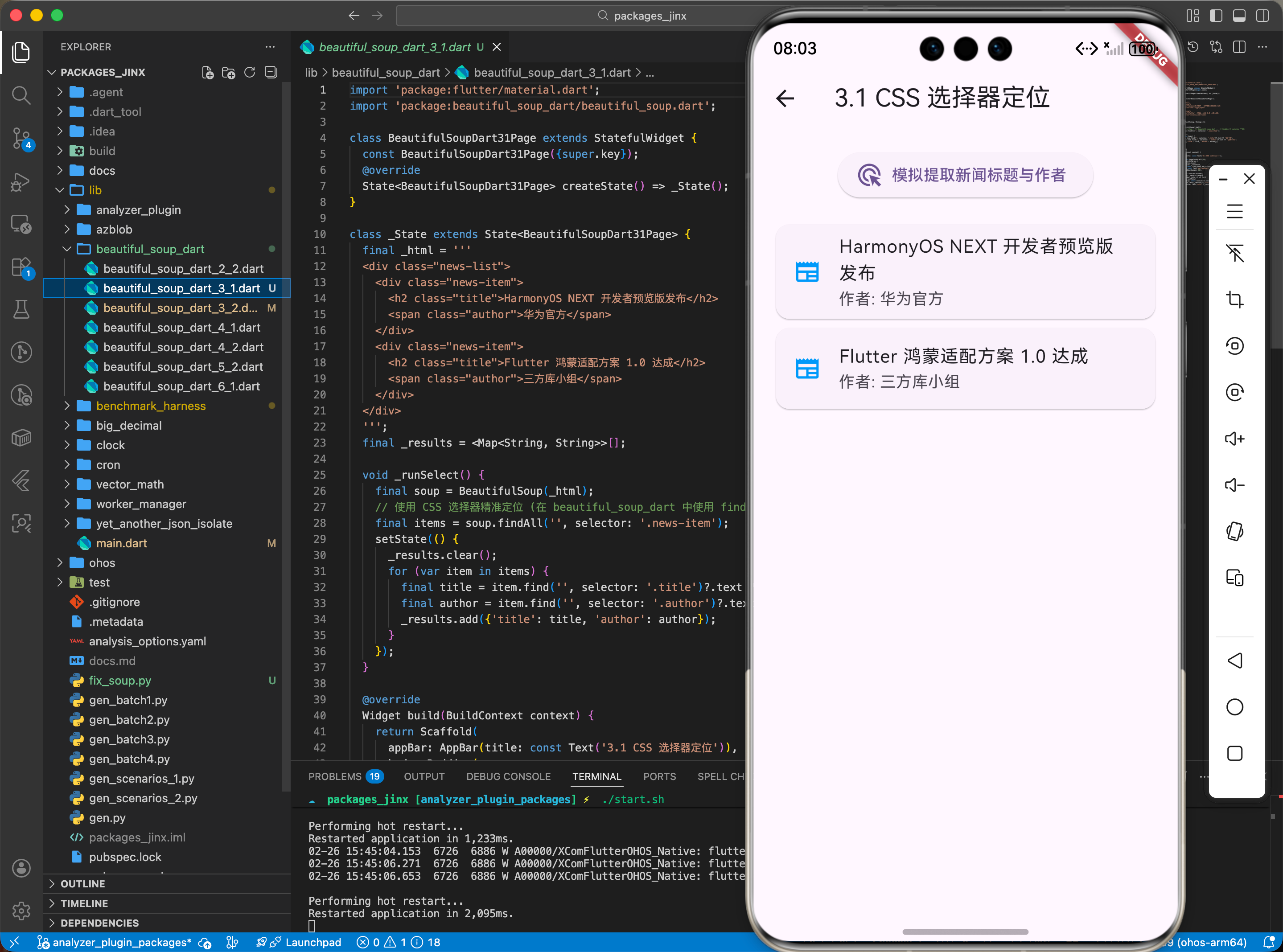
3.1 CSS 选择器定位
在鸿蒙新闻客户端中提取标题和作者信息。
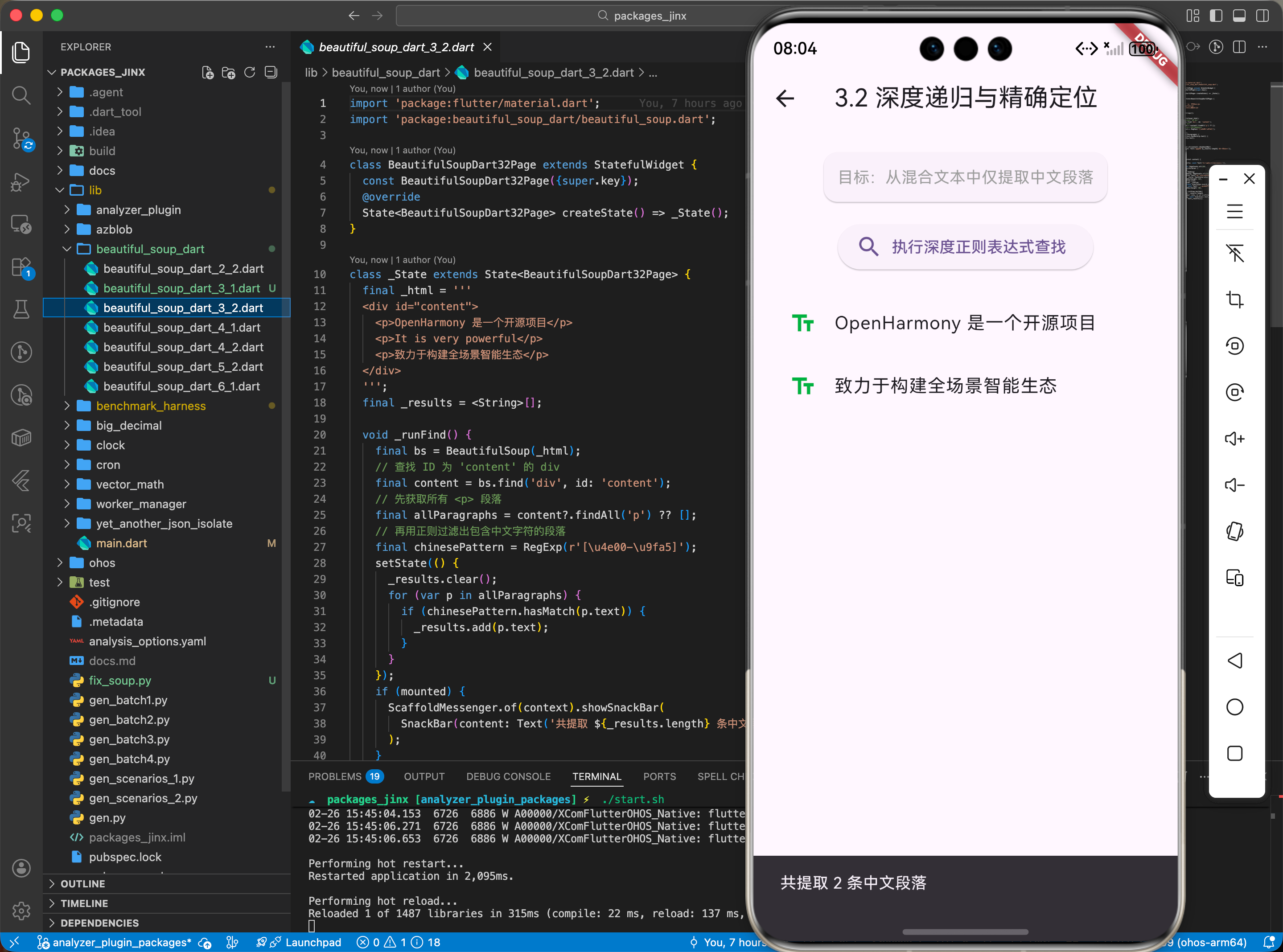
3.2 深度递归与精确定位
// 查找 ID 为 'content' 的 div 下的所有中文段落
Bs4Element? content = bs.find('div', id: 'content');
var paragraphs = content?.findAll('p', regex: r'[\u4e00-\u9fa5]+');
四、典型应用场景
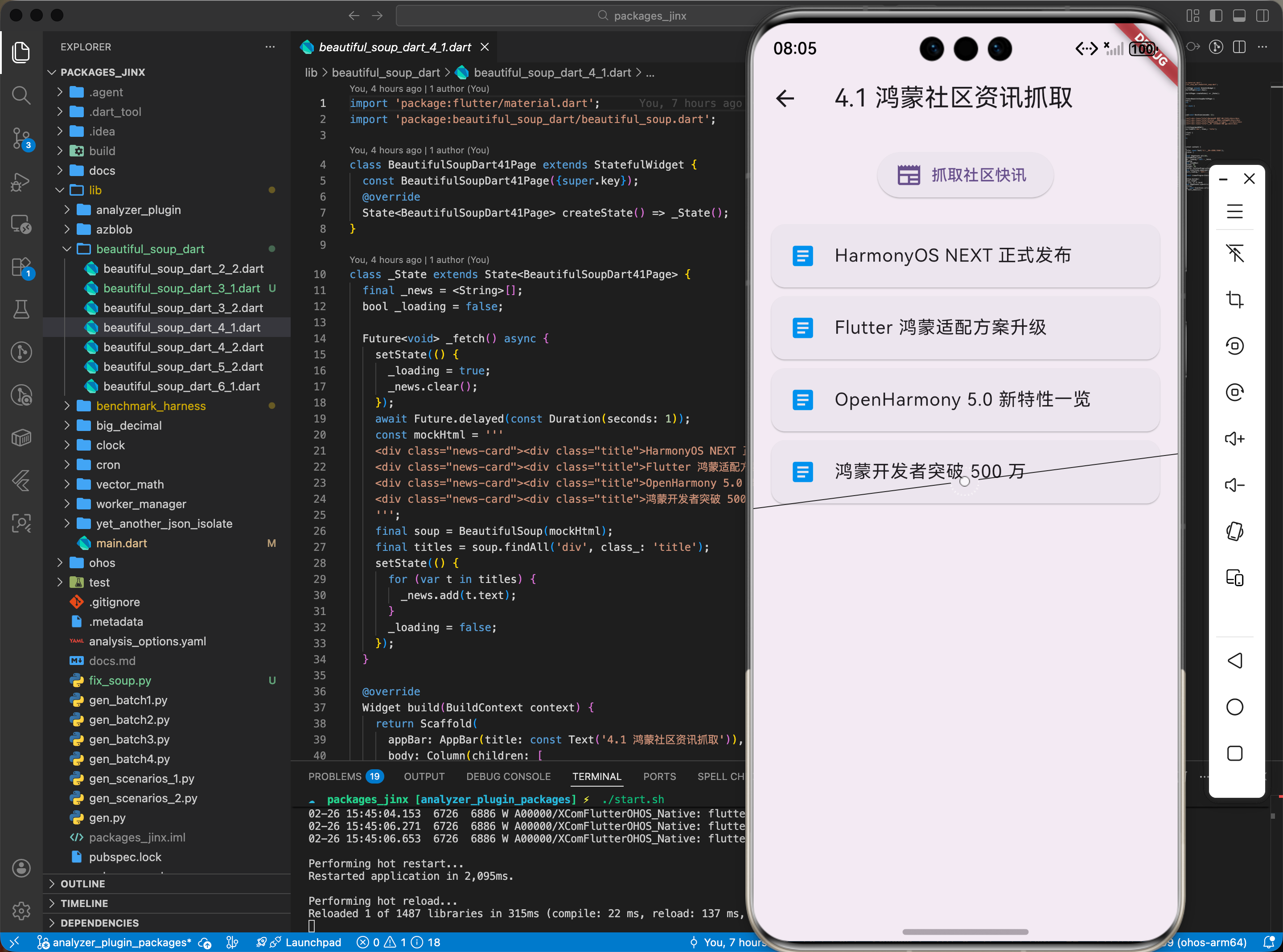
4.1 场景一:鸿蒙社区资讯抓取
从 OpenHarmony 官网提取最新公告标题。
// 汉化示例:抓取社区快讯
Future<void> fetchCommunityNews() async {
String responseBody = await fetchFromUrl("https://openharmony.org/news");
BeautifulSoup soup = BeautifulSoup(responseBody);
// 使用 CSS 选择器获取新闻卡片标题
List<Bs4Element> titles = soup.select('.news-card .title');
for (var title in titles) {
print("今日头条: ${title.text}");
}
}
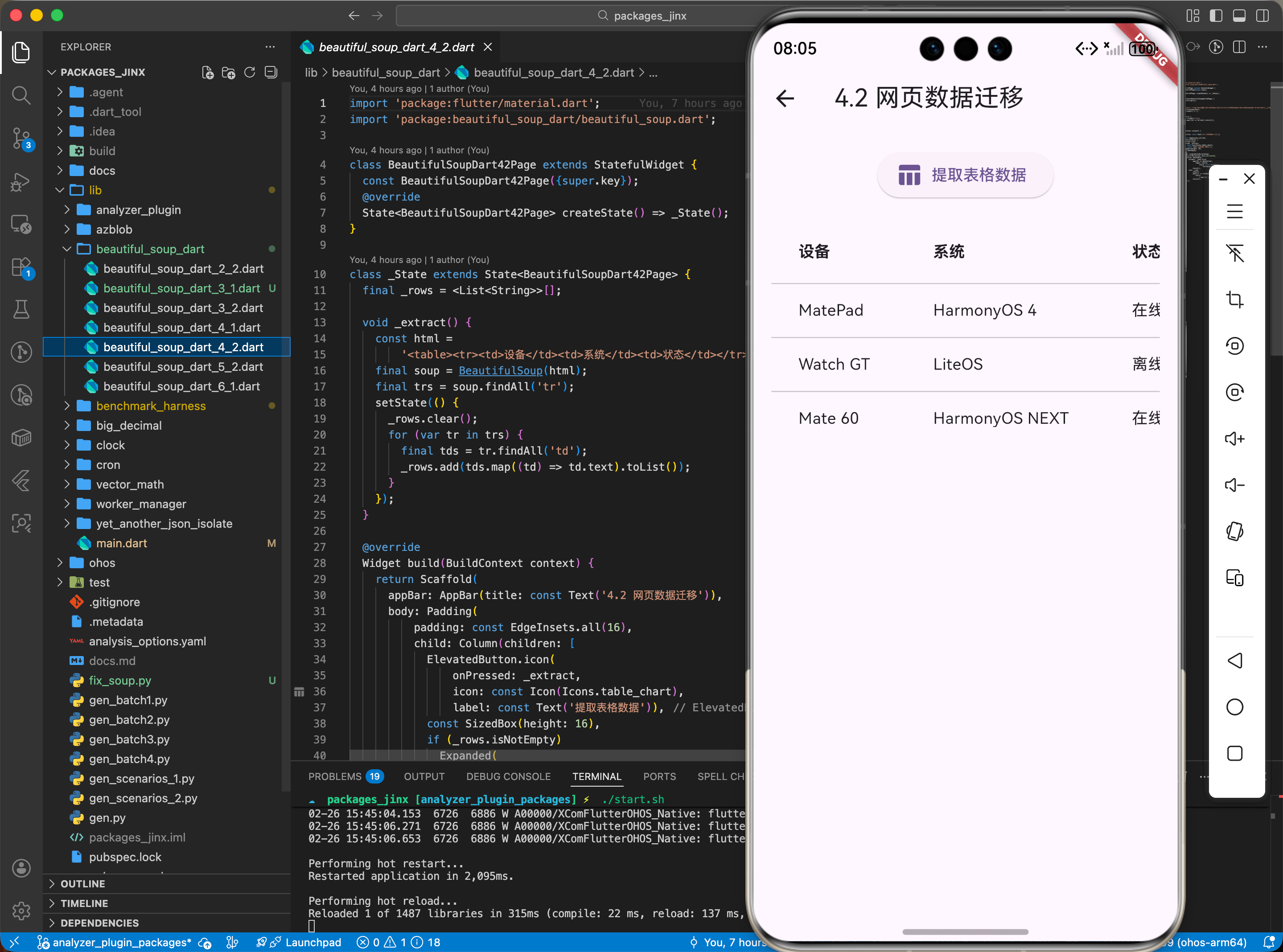
4.2 场景二:网页数据迁移与辅助工具
将旧版 Web 系统的表格数据提取并直接显示在鸿蒙 App 内部。
// 遍历表格提取数据
var tableRows = soup.find('table')?.findAll('tr');
五、OpenHarmony 平台适配挑战
5.1 编码问题(GBK vs UTF-8)
部分国内老旧 Web 系统依然使用 GBK 编码。在鸿蒙端直接用 http 获取的文本可能会出现乱码,导致 BeautifulSoup 无法正确构建索引。
解决方案:先使用 fast_gbk 等库将字节流转换为 UTF-8 字符串,再喂给 BeautifulSoup 处理。
5.2 大文档解析的 UI 卡顿
在鸿蒙设备上同步解析复杂的 DOM 树会阻塞 UI 线程。
解决方案:使用 compute 函数将解析逻辑放入后台 Isolate。
// 鸿蒙端后台解析实践
final extractedData = await compute(parseLogic, heavyHtmlString);
六、综合实战演示
import 'package:flutter/material.dart';
import 'package:beautiful_soup_dart/beautiful_soup.dart';
import 'package:flutter/foundation.dart';
class SoupDemo extends StatelessWidget {
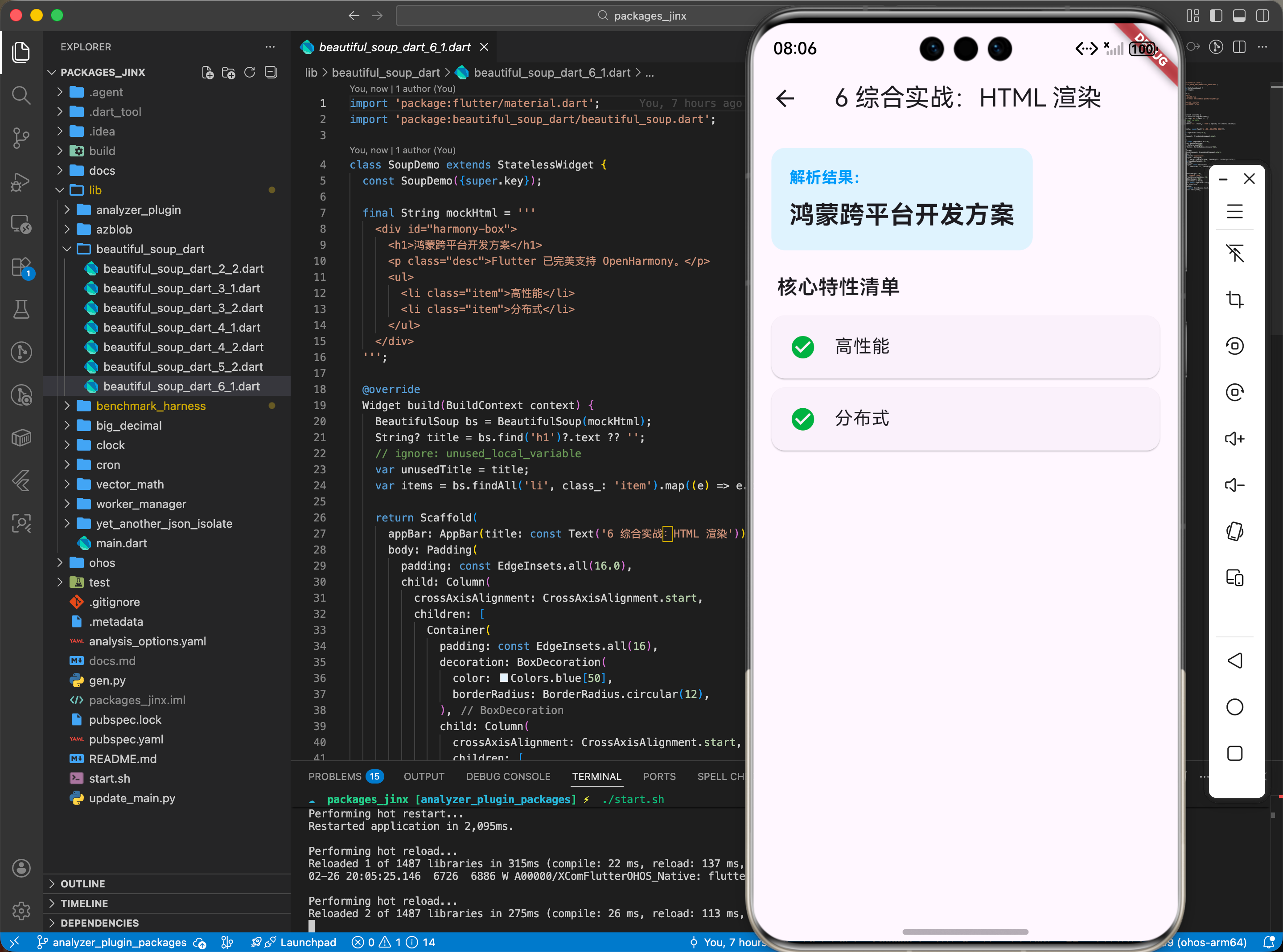
final String mockHtml = """
<div id="harmony-box">
<h1>鸿蒙跨平台开发方案</h1>
<p class="desc">Flutter 已完美支持 OpenHarmony。</p>
<ul>
<li class="item">高性能</li>
<li class="item">分布式</li>
</ul>
</div>
""";
Widget build(BuildContext context) {
BeautifulSoup bs = BeautifulSoup(mockHtml);
String? title = bs.find('h1')?.text;
var items = bs.select('.item').map((e) => e.text).toList();
return Scaffold(
appBar: AppBar(title: Text('鸿蒙 HTML 解析实战')),
body: Padding(
padding: const EdgeInsets.all(16.0),
child: Column(
children: [
Text("解析到的标题: $title", style: TextStyle(fontSize: 20, fontWeight: FontWeight.bold)),
...items.map((item) => Card(child: ListTile(title: Text("技术特性: $item")))),
],
),
),
);
}
}
七、总结
beautiful_soup_dart 的适配极大地增强了鸿蒙应用处理非结构化 Web 数据的功能。无论是构建聚合类资讯应用,还是处理后端返回的复杂 HTML 片段,它都能提供如同 Python 开发般优雅的体验。掌握这一技巧,意味着您能打破数据壁垒,将互联网上的海量网页知识库轻松转化为鸿蒙原生的精美 UI。
配合
dio的拦截器使用,可以实现更强大的自动化登录抓取逻辑。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 4
4 0
0- 0



 已为社区贡献118条内容
已为社区贡献118条内容

所有评论(0)