
Flutter for OpenHarmony:html 纯 Dart 版 DOM 解析器,爬虫与富文本处理利器(支持 CSS 选择器) 深度解析与鸿蒙适配指南
摘要: 本文介绍了Dart官方html库在OpenHarmony开发中的应用,该库提供纯Dart实现的HTML5解析能力,无需依赖浏览器环境。通过示例代码展示了HTML字符串解析、DOM节点查询/修改等核心功能,并重点讲解了其在鸿蒙应用中的典型场景: 富文本处理:提取新闻客户端HTML内容并转换为Flutter Widget 安全防护:清洗用户生成的HTML内容防止XSS攻击 编码处理:解决GBK
欢迎加入开源鸿蒙跨平台社区:https://openharmonycrossplatform.csdn.net

前言
在 Web 开发中,DOM 操作是家常便饭。但在 Flutter(以及 Dart Server)环境中,我们没有浏览器的 window 或 document 对象。如果我们想解析一段 HTML 字符串,提取其中的文本、图片链接,或者修改某些标签的属性,该怎么办?
html package (pkg:html) 就是为此而生的。它是 Dart 官方移植的 HTML5 解析器,纯 Dart 实现,不依赖浏览器 DOM API。
对于 OpenHarmony 开发者,这意味着你可以在鸿蒙应用中轻松实现:
- 网络爬虫:抓取并解析网页数据。
- 富文本清洗:处理后台返回的富文本 HTML,提取内容或过滤危险标签。
- EPUB/电子书解析:处理基于 HTML 的文档格式。
一、核心功能概览
html 库的核心是实现了一个兼容 DOM 标准的对象模型。
- Parse: 将 HTML 字符串解析为
Document对象。 - Query: 支持标准的 CSS 选择器(
querySelector,querySelectorAll)。 - Manipulate: 修改节点内容、属性、添加/删除节点。
- Output: 将 DOM 树重新序列化为 HTML 字符串。
二、集成与用法详解
2.1 添加依赖
dependencies:
html: ^0.15.6
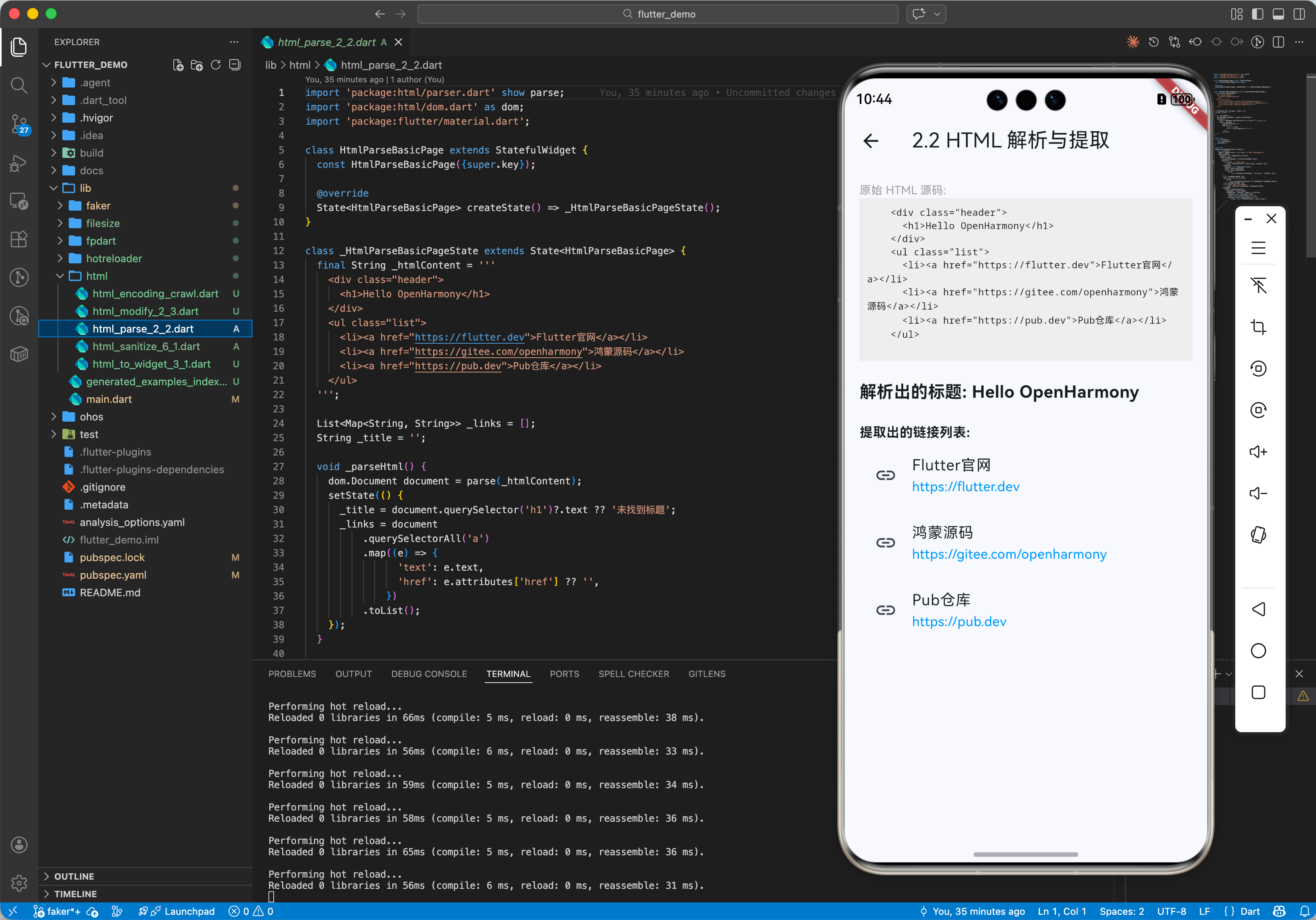
2.2 基础用法:解析与提取
假设我们需要从一个简单的 HTML 中提取标题和链接。
import 'package:html/parser.dart' show parse;
import 'package:html/dom.dart';
void main() {
var html = '''
<html>
<body>
<h1>欢迎来到 OpenHarmony</h1>
<div class="content">
<p>这是一个跨平台框架。</p>
<a href="https://flutter.cn" class="link">Flutter</a>
<a href="https://openharmony.cn" class="link">OHOS</a>
</div>
</body>
</html>
''';
// 1. 解析
Document document = parse(html);
// 2. 选择器提取
var title = document.querySelector('h1')?.text;
print('标题: $title'); // 标题: 欢迎来到 OpenHarmony
// 3. 列表提取
var links = document.querySelectorAll('a.link');
for (var link in links) {
print('${link.text}: ${link.attributes['href']}');
}
// Flutter: https://flutter.cn
// OHOS: https://openharmony.cn
}
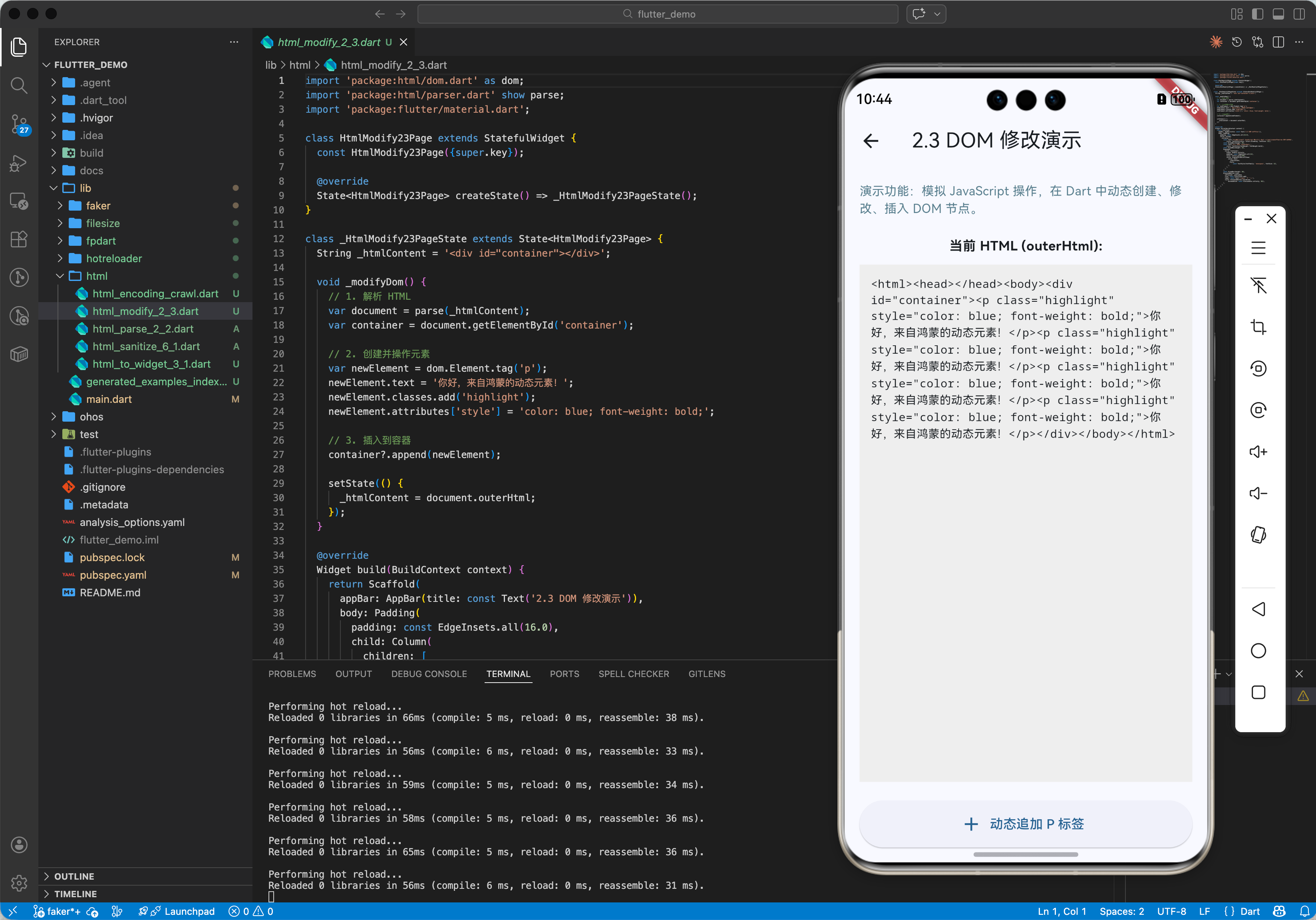
2.3 进阶用法:DOM 操作与修改
你可以像在 jQuery 或 JS 中一样修改 DOM。
void modifyDom() {
var document = parse('<div id="container"></div>');
var container = document.getElementById('container');
// 创建新元素
var newElement = Element.tag('p');
newElement.text = '你好,动态世界!';
newElement.classes.add('highlight');
// 插入
container?.append(newElement);
print(document.outerHtml);
// <html><body><div id="container"><p class="highlight">你好,动态世界!</p></div></body></html>
}
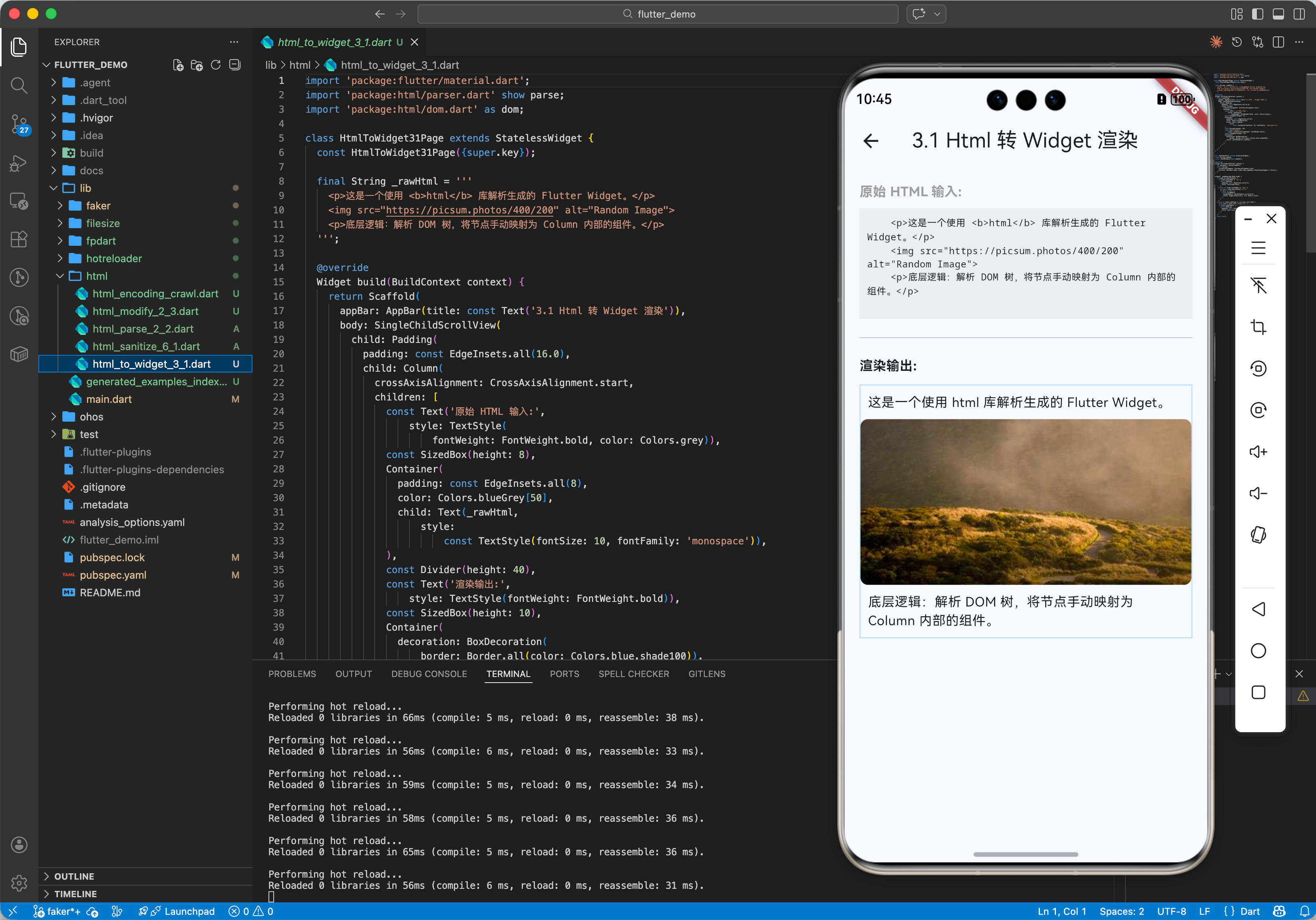
三、OpenHarmony 适配与实战:新闻客户端内容提取
在鸿蒙开发新闻类 App 时,API 往往返回一段包含特定排版的 HTML 字符串。为了适配鸿蒙的深色模式或自定义字体,我们通常需要先解析 HTML,去除内联样式,提取纯净内容,再用 Flutter 的 Widget 渲染。
3.1 场景:Html 转 Widget
虽然有 flutter_widget_from_html 这样的库,但有时我们需要更底层的控制。
import 'package:flutter/material.dart';
import 'package:html/parser.dart';
import 'package:html/dom.dart' as dom;
class HtmlRenderer extends StatelessWidget {
final String rawHtml;
const HtmlRenderer(this.rawHtml, {super.key});
Widget build(BuildContext context) {
var document = parse(rawHtml);
// 只取 body 内的节点
return Column(
children: document.body!.nodes.map(_mapNode).whereType<Widget>().toList(),
);
}
Widget? _mapNode(dom.Node node) {
if (node is dom.Element) {
if (node.localName == 'p') {
return Padding(
padding: const EdgeInsets.all(8.0),
child: Text(node.text),
);
} else if (node.localName == 'img') {
var src = node.attributes['src'];
if (src != null) {
return Image.network(src); // 实际需处理网络错误
}
}
} else if (node.nodeType == dom.Node.TEXT_NODE) {
if (node.text!.trim().isNotEmpty) {
return Text(node.text!);
}
}
return null;
}
}
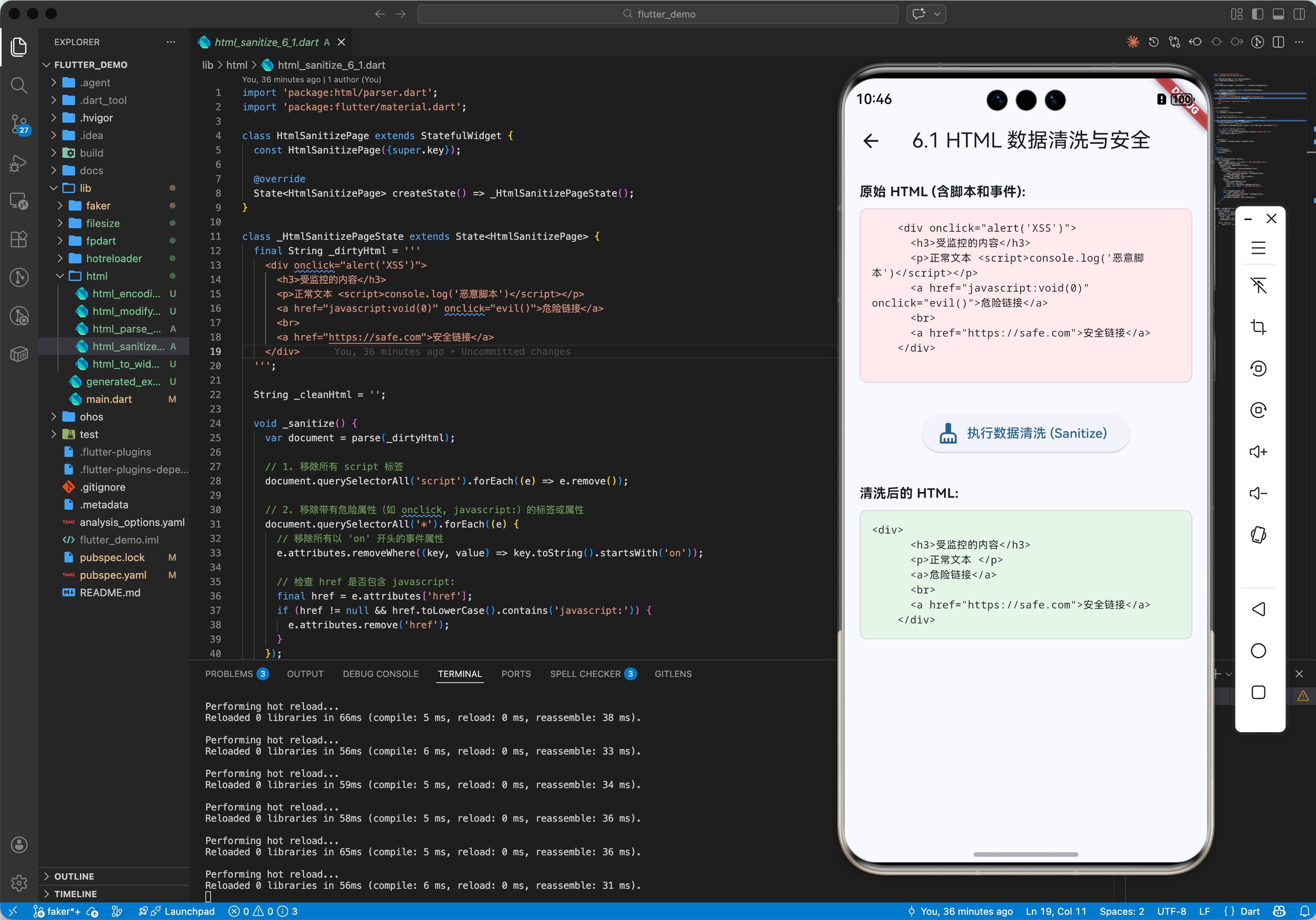
3.2 场景:数据清洗 (Sanitization)
在用户输入(UGC)场景,防止 XSS 攻击至关重要。我们可以用 html 库移除所有 <script> 标签。
String sanitize(String dirtyHtml) {
var document = parse(dirtyHtml);
// 移除所有 script 标签
document.querySelectorAll('script').forEach((e) => e.remove());
// 移除所有 onclick 属性
document.querySelectorAll('*').forEach((e) {
e.attributes.removeWhere((key, value) => key.toString().startsWith('on'));
});
return document.body!.innerHtml;
}
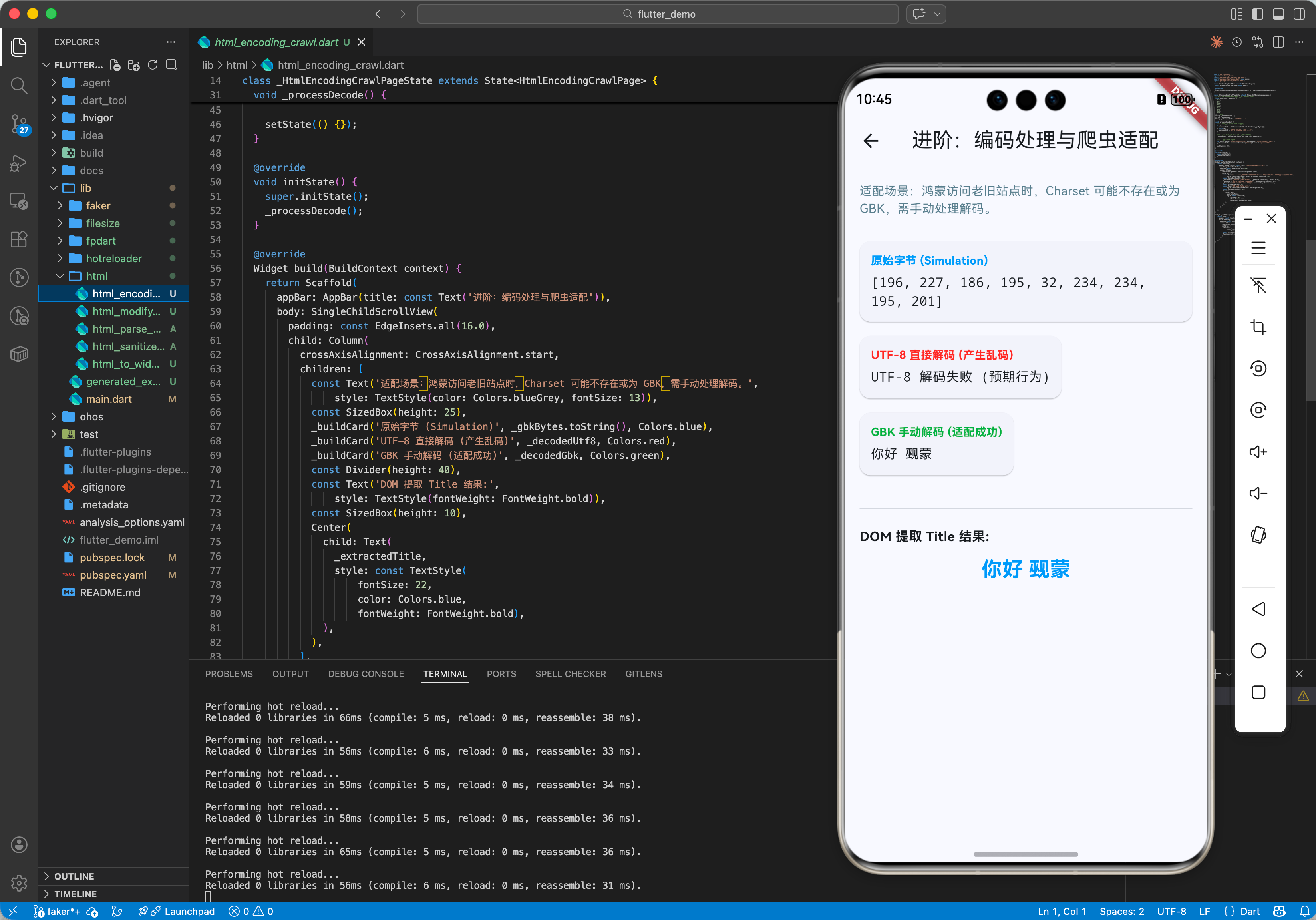
四、高级进阶:编码与乱码处理
pkg:html 默认假定输入是 UTF-8 字符串。如果你的数据来源是 GBK 或其他编码的二进制流(这种情况在爬取国内老旧网页时很常见),你需要先解码。
import 'package:http/http.dart' as http;
import 'package:html/parser.dart';
import 'dart:convert';
// 假设引入了 fast_gbk package
import 'package:fast_gbk/fast_gbk.dart';
Future<void> crawlLegacySite() async {
var response = await http.get(Uri.parse('http://www.old-site.com'));
// 检测 content-type 或手动指定解码
String decodedBody;
try {
decodedBody = gbk.decode(response.bodyBytes);
} catch (e) {
decodedBody = utf8.decode(response.bodyBytes);
}
var doc = parse(decodedBody);
// ...
}
OpenHarmony 注意事项:鸿蒙系统的 HttpClient 堆栈与 Android 略有不同,部分响应头可能不包含 charset 信息,因此建议手动处理编码转换,不要完全依赖 html 库的自动检测。
五、总结
html package 是 Dart 生态中处理 Web 内容的标准库。它不是一个浏览器引擎(不能执行 JS,不能渲染),但作为静态解析器,它足够快且足够健壮。
对于 OpenHarmony 开发者:
- 纯 Dart 实现:意味着在 x86, ARM, RISC-V 等所有鸿蒙支持的架构上都能完美运行。
- 无原生依赖:不会增加 HAP 包的体积,也不会通过 FFI 引入不稳定性。
无论是从网页抓取数据,还是处理后台下发的富文本,html 库都应该放在你的工具箱首层。
最佳实践:
- 不要用正则解析 HTML:正则无法处理嵌套标签,
pkg:html才是正道。 - 异步解析:虽然解析很快,如果 HTML 文档高达几 MB,建议放在
compute(Isolate) 中执行,以免阻塞 UI 线程。 - 注意容错:真实的 HTML 往往充满错误(未闭合标签等),
pkg:html兼容 HTML5 容错模式,能处理绝大多数"脏"代码。
六、完整实战示例
import 'package:html/parser.dart';
import 'package:html/dom.dart';
void main() {
// 1. 模拟一段复杂的 HTML 源码(包含错误和潜在风险)
var htmlString = '''
<div id="content">
<h1>文章标题</h1>
<p>这是第一段。</p>
<p class="highlight">这是<span style="color:red">高亮</span>段落。</p>
<!-- XSS 风险 -->
<script>console.log("XSS Attack");</script>
<a href="https://example.com">外部链接</a>
<p>未闭合的标签...
</div>
''';
// 2. 解析 (Document Object Model)
var document = parse(htmlString);
// 3. 提取特定数据
var title = document.querySelector('h1')?.text;
print('标题: $title');
// 4. 遍历提取
var highlights = document.querySelectorAll('.highlight');
for (var p in highlights) {
print('高亮内容: ${p.text}'); // 会自动去除内部的 span 标签,只留纯文本
}
// 5. 数据清洗 (Sanitize) 演示
// 移除所有脚本
document.querySelectorAll('script').forEach((e) => e.remove());
// 修改所有链接为新标签页打开
document.querySelectorAll('a').forEach((element) {
element.attributes['target'] = '_blank';
element.attributes['rel'] = 'noopener';
});
print('\n=== 清洗后的 HTML ===');
// body.innerHtml 包含清洗后的代码
print(document.body!.innerHtml.trim());
}

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 37
37 0
0- 0



 已为社区贡献44条内容
已为社区贡献44条内容

所有评论(0)