
鸿蒙高级课程笔记2—应用性能优化
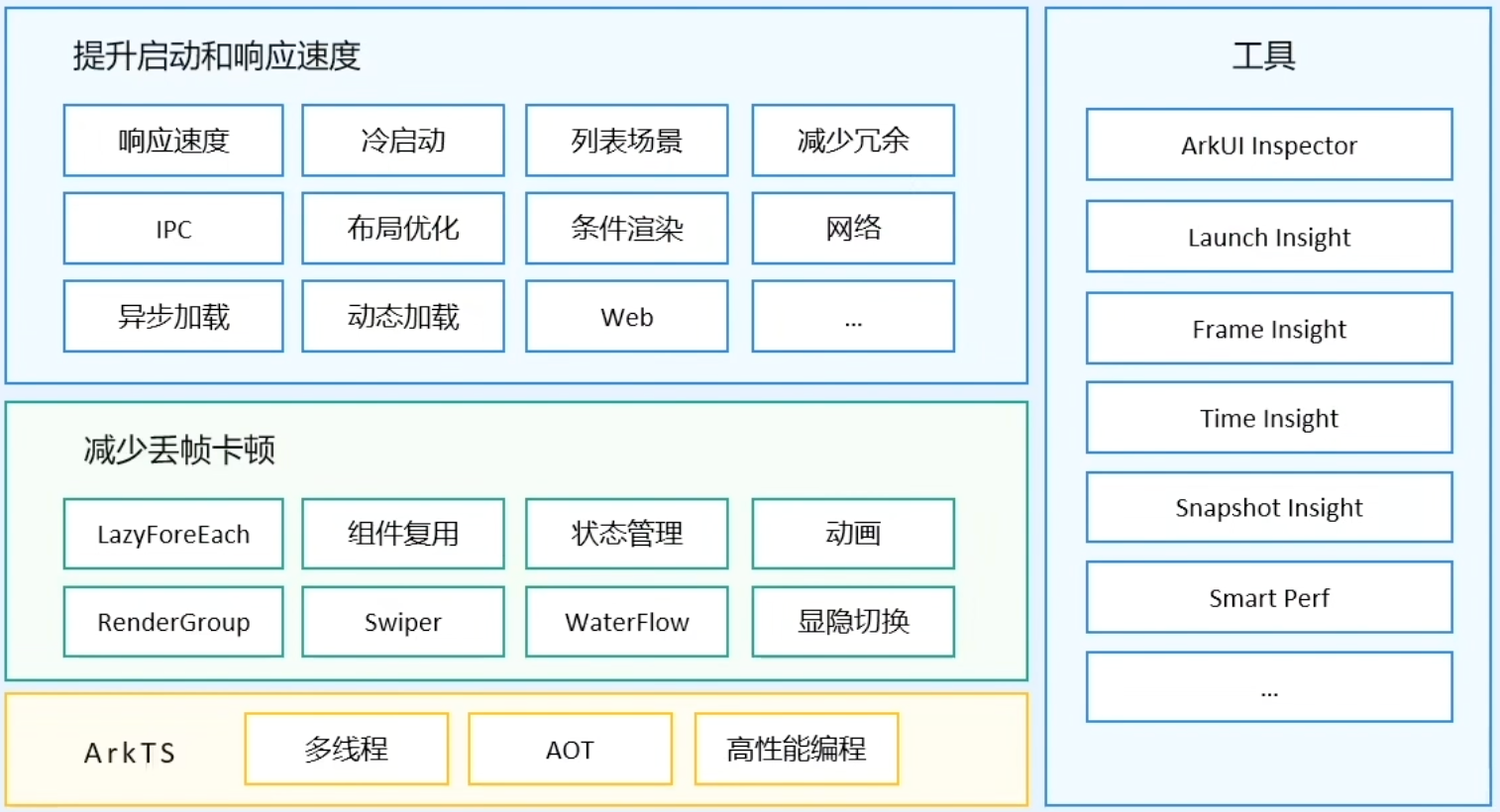
在开发HarmonyOS应用时,优化应用性能是至关重要的。课程从ArkTS高性能编程、减少丢帧卡顿、提升应用启动和响应速度,三方面讲解如何有效提升用户体验。然后会介绍一些常用的性能调优工具,去帮助开发者分析如何去做性能调优和调试问题定位。
在开发HarmonyOS应用时,优化应用性能是至关重要的。课程从ArkTS高性能编程、减少丢帧卡顿、提升应用启动和响应速度,三方面讲解如何有效提升用户体验。然后会介绍一些常用的性能调优工具,去帮助开发者分析如何去做性能调优和调试问题定位。
一、ArkTS高性能编程
高性能编程分三个方面内容:如何使用多线程、如何使用AOT、怎么利用ArkTS语言的特性实现高性能编程。
课程从两个方面讲解高性能编程:
1、首先讲解一些ArkTS高性能编程规则,这些规则更有利于方舟编译运行时进行编译优化,生成更高性能的机器码,保障程序运行得更快。
2、其次,讲解使用AOT模式对应用进行编译优化:当我们使用AOT时,我们可以利用方舟编译器运行时的一种性能优化特性,使它提前生成高性能的机器码,从而提升程序运行速度。方舟编译运行时通过采用PGO(Profile-Guided-Optimization,配置文件引导型优化)方式,提前生成高性能机器码。
ArkTS高性能编程规则
1、ArkTS是基于TypeScript设计的,但出于代码的稳定性和性能考虑,一些TypeScript的特
性被限制了。比如需要不支持属性的动态变更、变量或参数需要有明确的类型声明和
返回值声明等。
2、严格遵循ArkTS的编码规则,禁用@ts-ignore @ts-expect-error等屏蔽编译校验的命令,这些命令规避了系统的编译校验,容易引起稳定性问题。
3、开启TypeScript的严格模式,比如需要严格判空、严格函数类型检查、严格成员初始化等,提高代码的质量和可维护性,避免一些常见错误。
4、ArkTS不支持使用any和unknown,请使用明确类型,或者使用联合类型、泛型或者object替代any。必须使用any的场景可以使用ESObject代替,但是可能存在性能问题,谨慎使用。
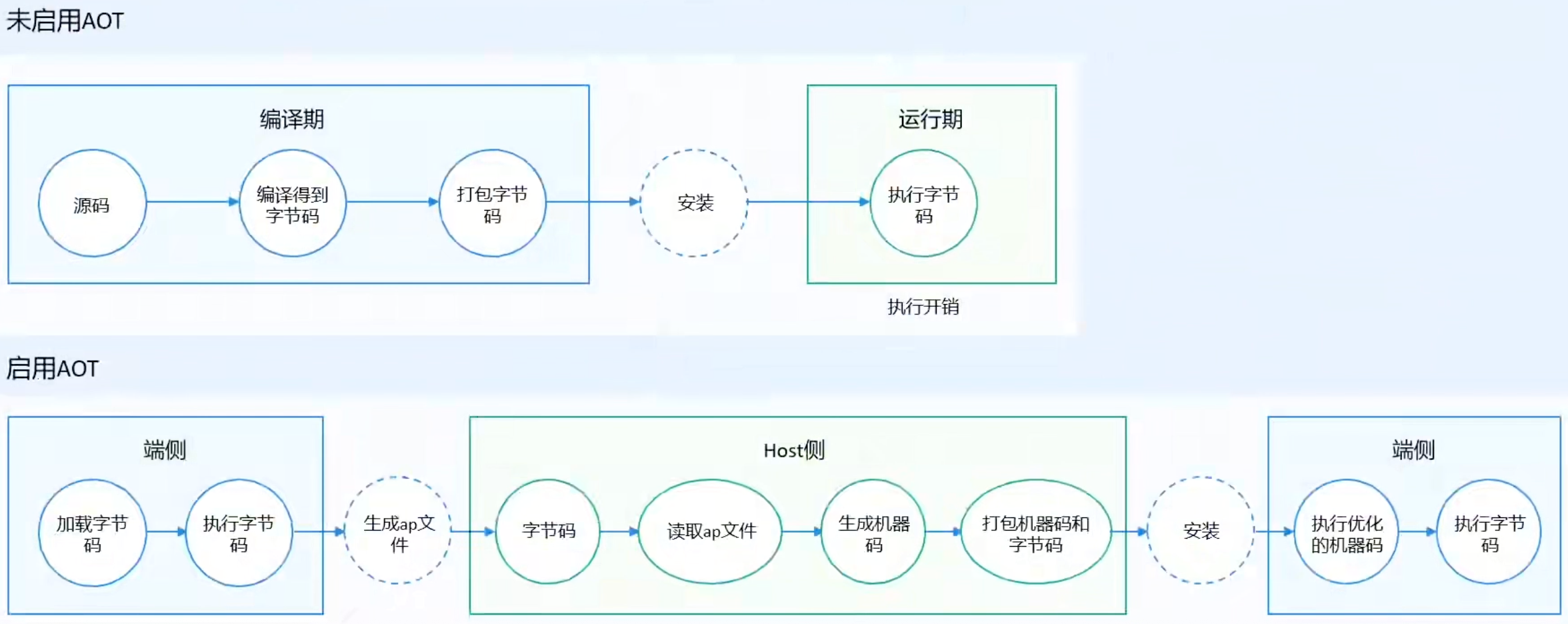
AOT模式
AOT (Ahead Of Time)即提前编译,能够在Host端将字节码提前编译成Target端可运行的机器码,这样字节码可以获得充分编译优化,放到Target端运行时可以获得加速。
多线程
二、提升应用启动速度和响应速度
冷启动过程简介
应用启动时,后台无该应用的进程,需要创建新的进程,这种质启动方式叫做冷启动。冷启动的过程大致可分成四个阶段:应用进程创建和初始化、App和Ability的初始化、Ability生命周期、加载绘制首页。

如何在这4个阶段对应用进行冷启动速度进行提升和优化?
1、缩短应用进程创建&初始化阶段耗时:设置合适分辨率的startWindowlcon
2、缩短Application&Ability初始化阶段耗时:减少首页Ability或者Page中import的模块,使用动态加载或者懒加载替代
3、缩短Ability生命周期阶段耗时:使用异步加载
4、缩短加载绘制首页阶段耗时:延迟加载
动态import
页面在引入依赖的加载模块时,如果不是首帧必须显示的内容模地快,可以使用动态加载的方式(await import),延迟模块的加载时间,加快首帧显示的加载速度。

懒加载
将不必要的资源延迟加载可以减少应用启动时间。使用List、Grid以及Swiper等容器组件时,配合系统提供的LazyForEach数据懒加载能力,可以有效减少应用启动时间和内存占用。
异步加载
生命周期中如果必须要运行耗时操作,可以考虑使用异步接口或者异步加载的方式,延迟耗时操作的运行时机,提升应用的启动速度。如网络请求。
使用缓存
选择合适的缓存策略可以提高应用程序的性能和响应速度,从而提升应用响应速度。如当使用LazyForEach时,可以搭配使用cachedCount方法,自定义控制列表的缓存数量,实现更优的滑动体验。
三、减少丢帧卡顿
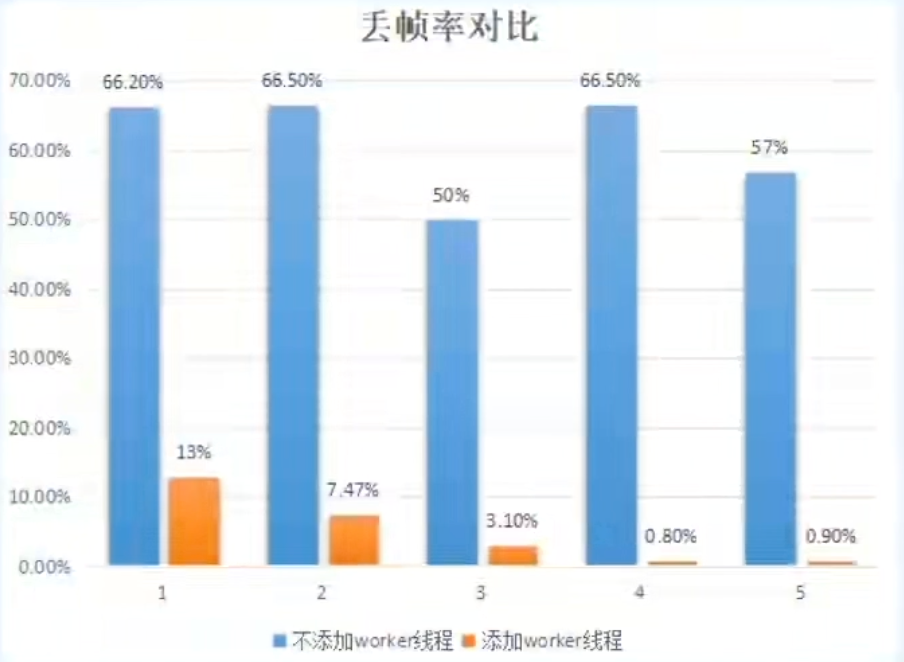
避免在主线程上执行耗时操作
UI主线程是HarmonyOS应用中最重要的线程之一,在主线程上执行耗时操作会阻塞UI渲染,从而导致UI主线程的负载过高。因此,可以将耗时操作放在TaskPool或者Worker等后台线程中执行。
减少渲染进程的冗余开销
使用资源图代替绘制、合理使用renderGroup、尺寸位置设置尽量使用整数,可以减少渲染所需的时间,从而减少丢帧卡顿。
下面以动画为例说明:
animateTo会将执行动画闭包前后的状态进行对比,对差异部分进行动画。为了对比,会在执行animateTo的动画闭包之前,将所有变更的状态变量和脏节点都刷新。如果多个animateTo之间存在状态更新,会导致执行下一个animateTo之前又存在需要更新的脏节点,可能造成冗余更新元。因此,连续的animateTo之间尽量不要更新状态。
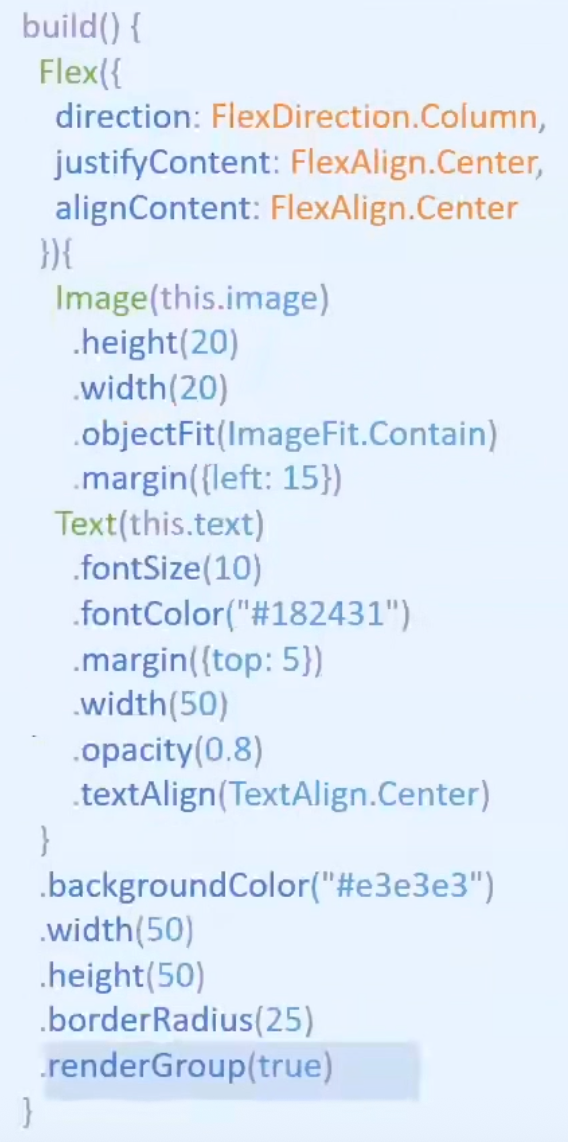
renderGroup离屏绘制
首次绘制组件时,若组件被标记为启用renderGroup状态,将对组件以及其子节点进行离屏绘制,将绘制结果进行缓存,此后当需要重新绘制组件时,就会优先使用缓存而不必重新执行绘制了,从而降低绘制负载,优化渲染性能。一般,一个固定的没有状态变量绑定的组件,且组件内容不会发生变化,可以对组件加renderGroup状态;如果组件内容发生变化,缓存就会失效。
合理布局/减少视图嵌套层级
应用开发中的用户界面(UI)布局是用户与应用程序交互的关关键部分。不合理的布局越多,视图的创建、布局、渲染等流程所需的时间就越长。因此,减少嵌套层次或者使用高性能布局节点,可以减少丢帧卡顿。
嵌套层级越深,会有更大的系统内存开销。因此在开发过程中,要尽可能减少布局嵌套,使布局更加扁平化。
布局扁平化:选用正确的布局组件,不但可以去除中间嵌套的组件层级,减少组件数量,使代码更易于维护,也避免系统绘制更多的布局组件,达到优化性能、减少内存占用的自的。
注意:合理布局在下面第五模块中详细介绍。
组件复用配合LazyForEach
使用Arkul开发范式提供的组件复用机制,通过重复利用已经创建过并缓存的组件对象,降低组件短时间内频繁创建和销毁的开销,提升组件加载效率,降低ul线程负载,从而减少丢帧卡顿页。
列表中的组件复用机制如下:
- 标记为@Reusable的组件从组件树上被移除时,组件和其对应的JSView对象都会被放入复用缓存中。
- 当列表滑动新的Listltem将要被显示,List组件树上需要新建节点时,将会从复用缓存中查找可复用的组件节点。
- 找到可复用节点并对其进行更新后添加到组件树中。从而节省了组件节点和JSView对象的创建时间。
列表中的组件复用推荐场景:
- 滑动场景下对同一类自定义组件的实例进行频繁的创建与销毁(配合LazyForeEach);
- 反复切换条件渲染的控制分支,且控制分支中的组件子树结构相同;
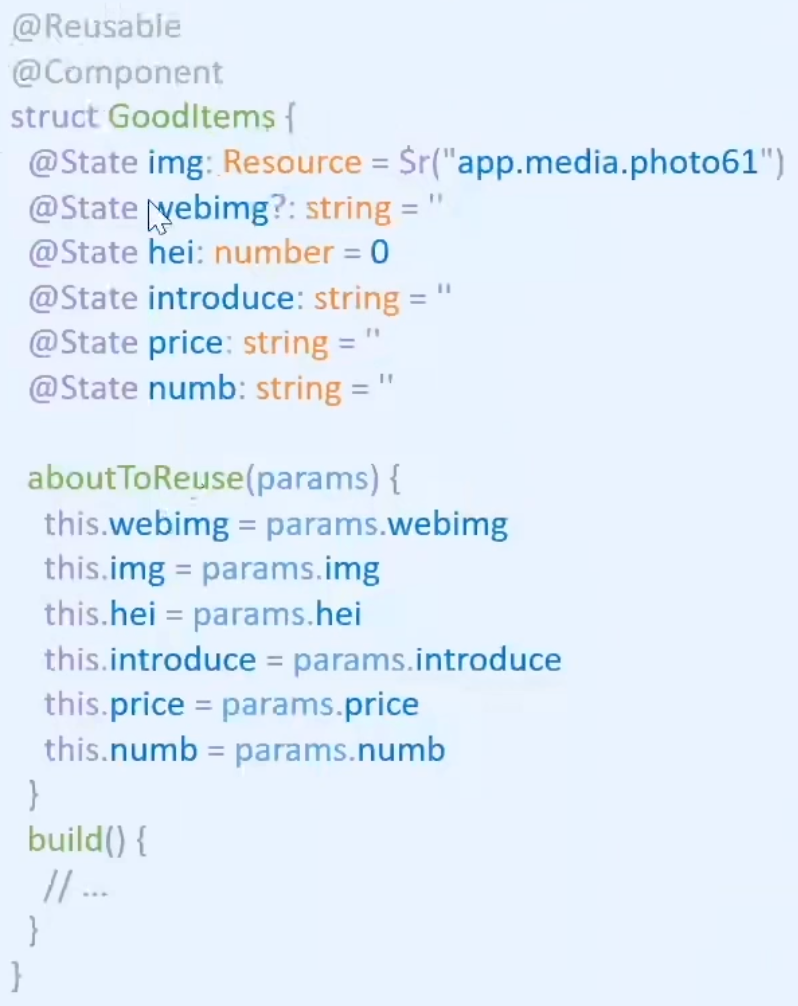
精确控制状态变量的关联组件数
@State等状态变量关联组件越多,状态数据变更时刷新的组件越多,UI线程负载越重,因此移除冗余的组件关联可以减少丢帧卡顿。
- 不推荐使用更新单个状态变量的形式自行控制多个组件更新时相机(命令式)
- 推荐使用状态变量和组件一一绑定的方式,以数据的变更驱动经阻件的刷新(声明式);
- 合理控制状态更新范围,避免关联刷新较大范围或者渲染较慢的组件。
在对象上谨慎使用状态变量关联
理解@Prop和@ObjectLink的区别:@Prop是深拷贝,@ObjectLiik是浅拷贝。
所以在@Prop和@ObjectLink使用效果相同的场景下,优先使用@ObjectLink的方式减少系统内存开销。
四、使用性能工具
- ArkUl Inspector:用于检查和调试应用程序页面布局的情况。
- Smart Perf:开源性能调优平台,支持对CPU调度、频点、进程线程时间片、堆内存、帧率等数据进行采集和展示,展示方式为泳道图
以上工具除了Smart Perf,都能直接在IDE中直接使用。
以下是Profiler工具提供的功能:

- 实时监控Realtime Monitor:自动开启,进行一些问题的初步定界,然后创建相应的会话(如CPU Insight)进行问题的详细定位。
- 执行效率Time Insight:通过周期性采集调用栈,识别CPU耗时高的热点代码段,用于分析卡顿、CPU占用高、运行速度慢等问题。
- 内存分析Allocation Insight:录制和分析内存分配记录,用于分析内存峰值高,内存泄漏,内存不足导致应用被强杀等问题。
- 内存快照Snapshot Insight:录制和分析应用程序中ArkTS对象的分布,通过过快照方式对比ArkTS对象分布区别,用于分析内存泄漏问题。
- 内核分析CPU Insight:录制CPU调度事件、线程运行状态、CPU核频率、Trace等数据,可用于分析卡顿、运行速度慢、应用无响应等问题。
- 启动分析Launch Insight:录制和还原从启动应用,到显示首帧过程中的CPU、内存等资源使用情况,用于分析启动耗时长的问题。
- 卡顿丢顿Frame Insight:录制卡顿过程中的关键数据,标注出应用侧、Renderservice侧卡顿帧,用于分析应用卡顿、丢帧的问题。
Profiler调优工具简介

工具特点
- 无需关注数据采集细节,分析启动、卡顿、耗时、内存、能耗等场景性能问题
- 操作简单、快速上手,帮助用户搭建鸿蒙应用性能模型
- Top-Down设计理念和数据展现范式,直通代码行体验,高效调优
打开方式
- 在DevEco Studio顶部菜单栏中选择View->Tool Windows -> Profiler
- 在DevEco Studio底部工具栏中单击Profiler
- 按"Double Shift"或者"Ctrl+Shift+A"打开搜索Profiler
会话区介绍
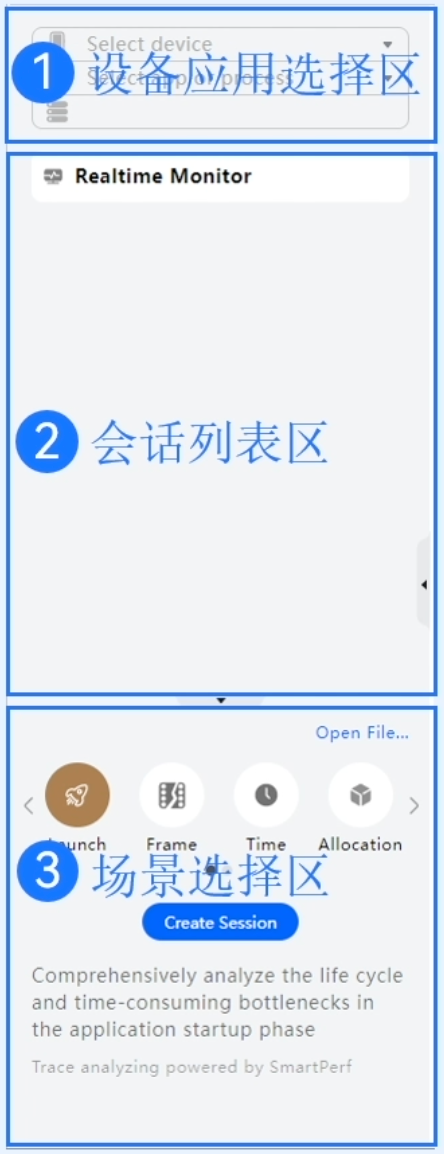
- 设备应用选择区:选择调优设备(目前支持真机),进程列表及当前应用进程。
- 会话列表区:展示已创建的调优分析任务。单击列表中某会话后,数据区显示其调优内容。选择设备和进程后,此处默认显示Realtime Monitor任务。
- 场景选择区:新建任务的入口。Profiler提供 Launch(启动)、Frame(卡顿)、Time(耗时)、Allocation(内存)、Snapshot(内存快照)、CPU(内核)等场景化分析任务类型。
数据区介绍
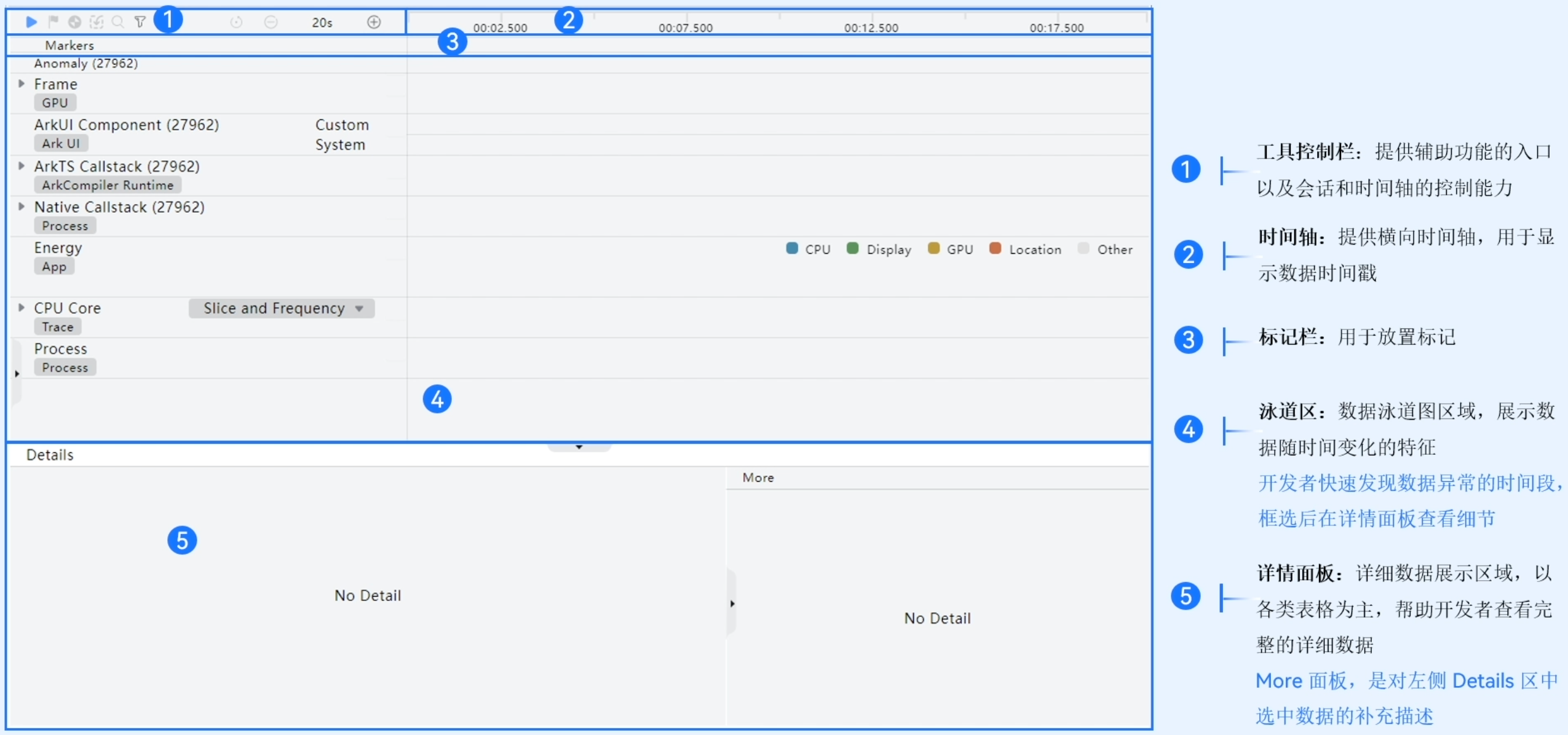
工具控制栏详细介绍如下:
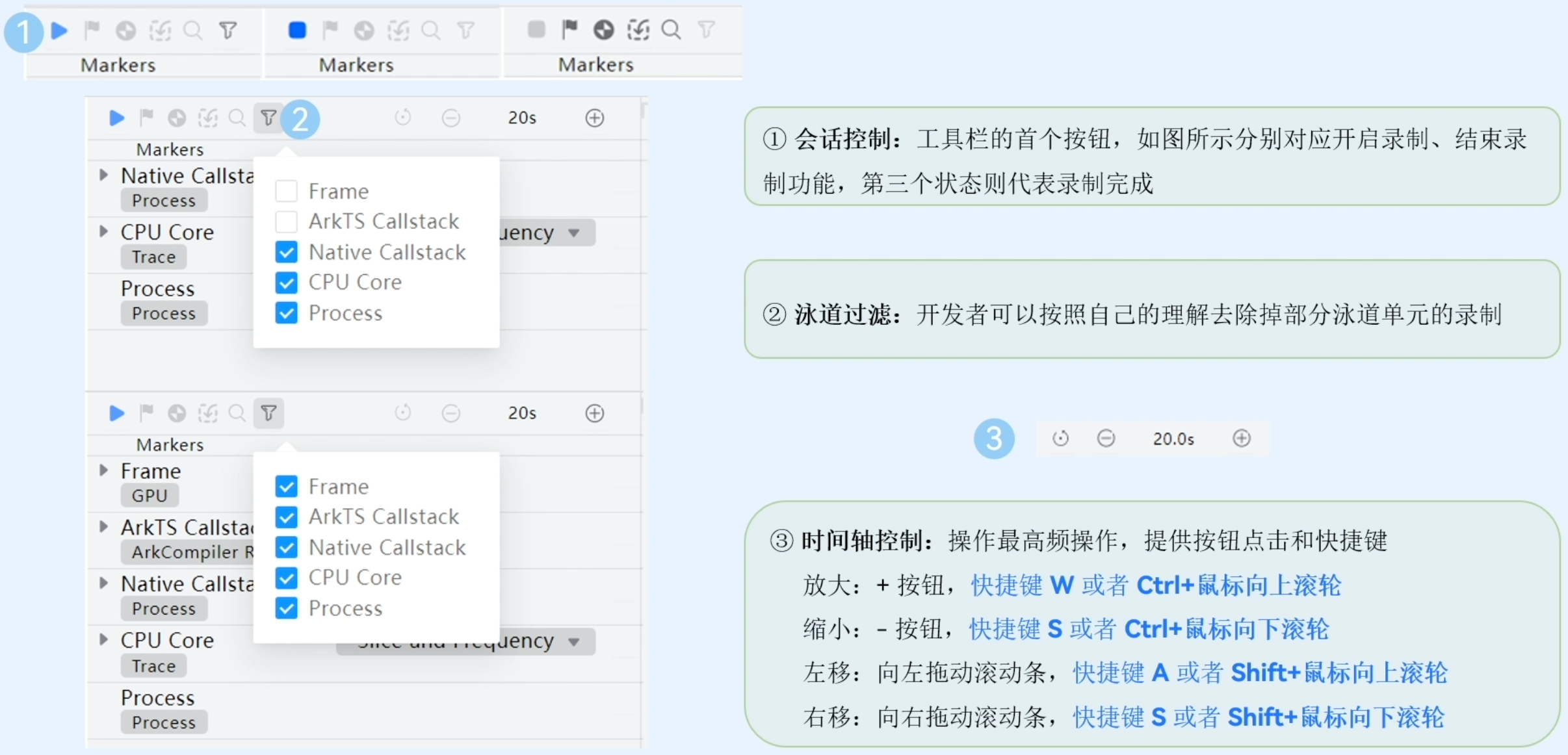
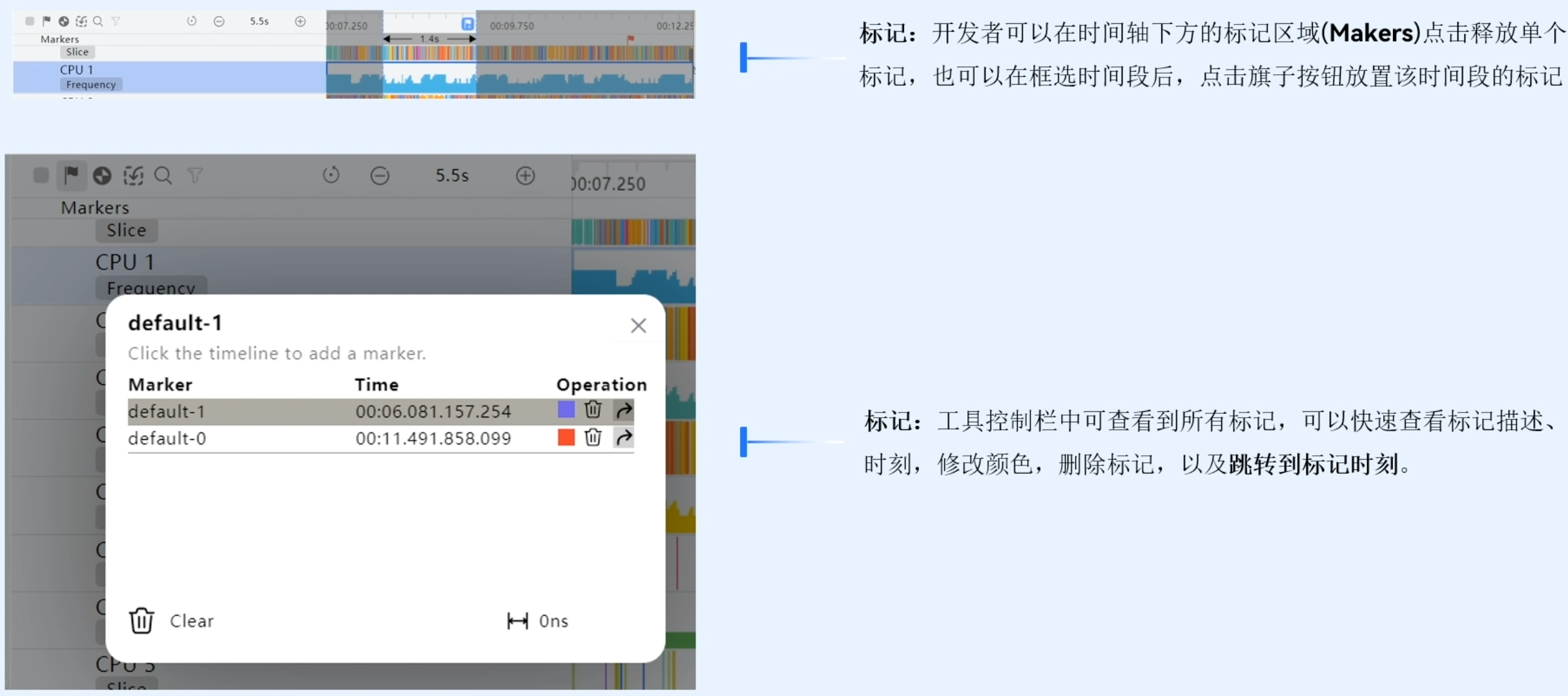
标记栏详细介绍如下:
标记的作用主要是为了在时间轴上快速找到某一个位置,方便用户去定位它之前找到的问题。
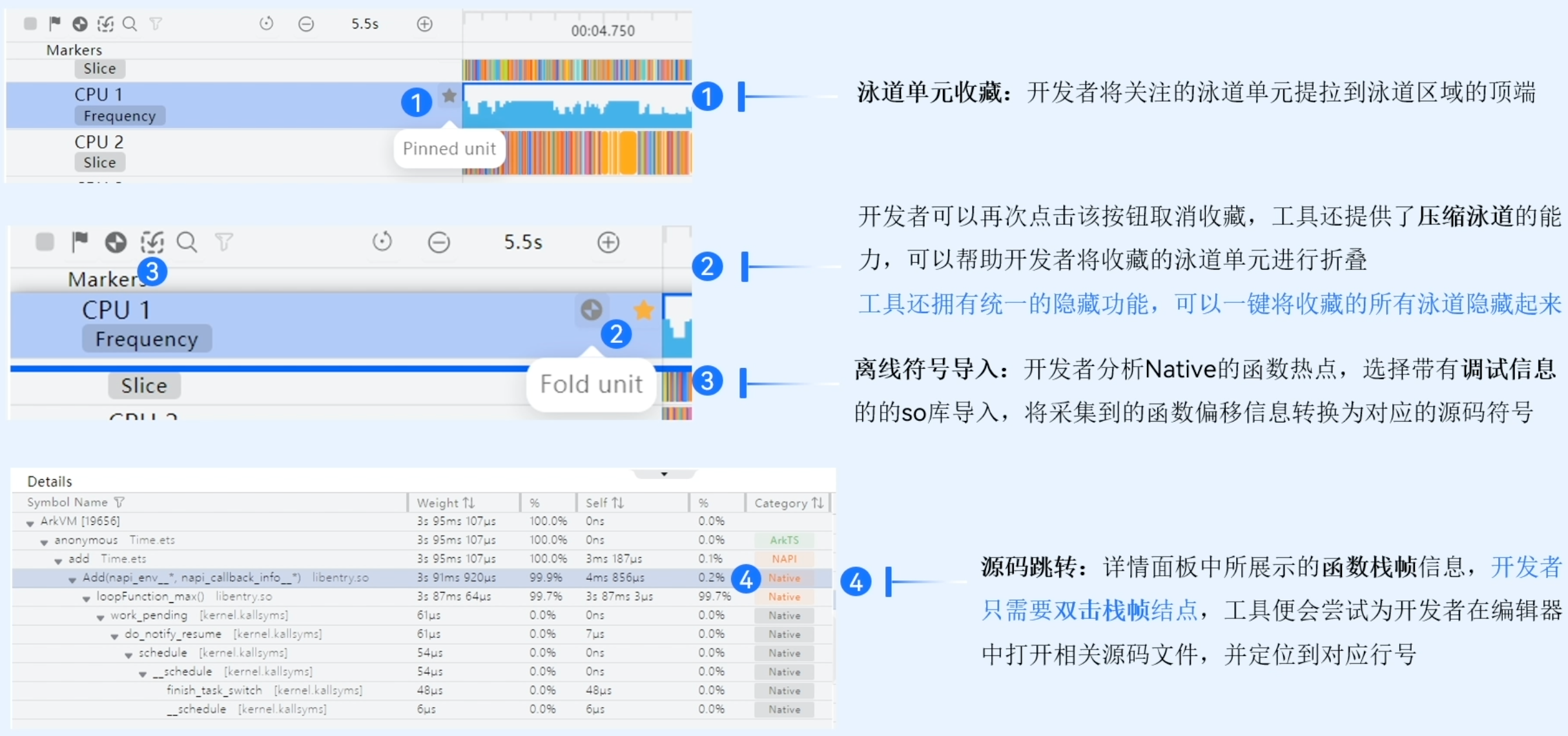
涌道区详细介绍如下:
Profiler性能优化步骤
- 1.使用Realtime Monitor发现性能瓶颈并定界热点区域;
- 2.创建场景化分析任务来定位性能问题出现的根因;
- 3.根据性能分析的结果优化代码;
- 4.再次使用Realtime Monitor来验证代码修改的可行性。
实时监控(Realtime Monitor)
Profiler提供实时监控(Realtime Monitor)能力,提供全方位立的设备资源监测,覆盖系统事件、异常事件报告、CPU占用、内存占用、实时帧率、GPU使用率以及能耗等多个维度的数据,帮助开发者初步识别性能瓶颈,定界问题所在。
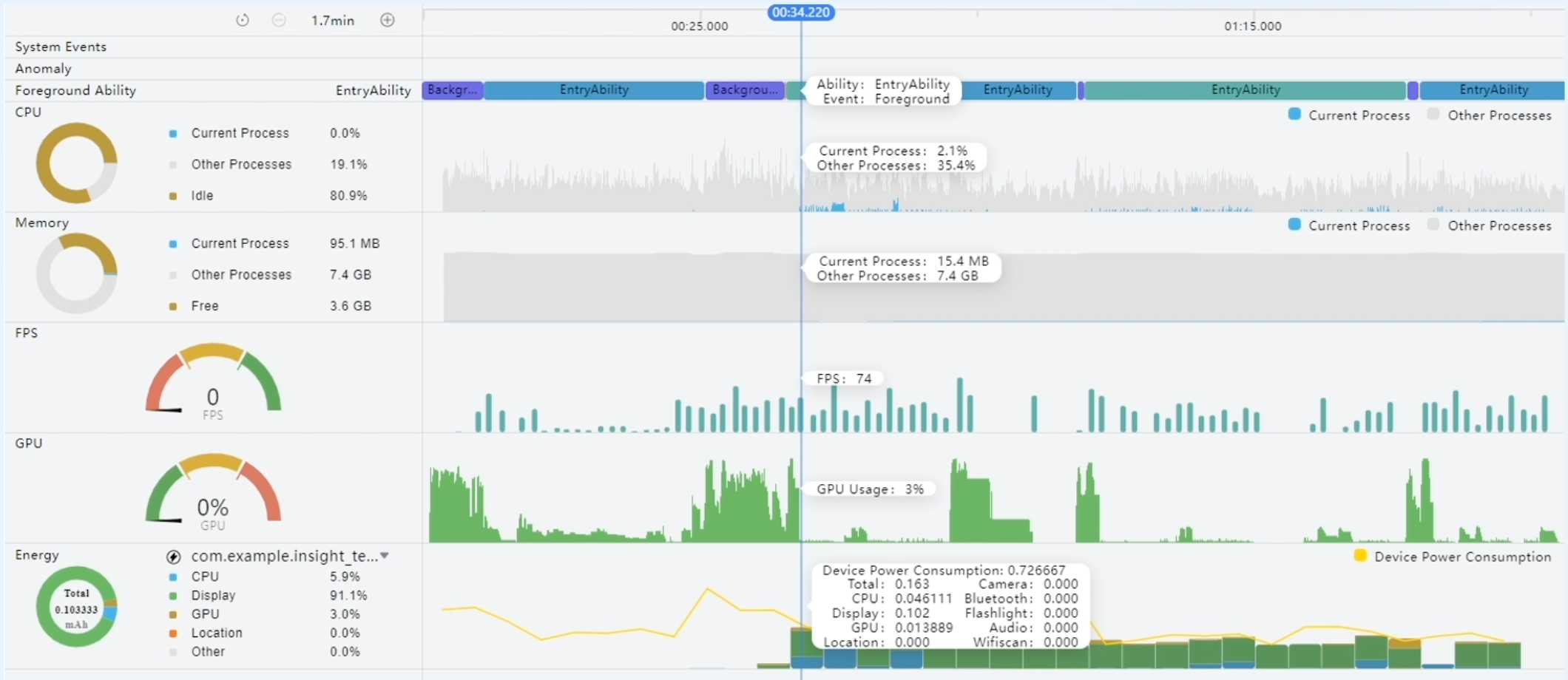
如上图,实时界面通过启停控制、详细数字展示、图列选择进行初步定位。从实时监控大概看出问题所在,然后通过深度录制更加详细的模板,分析应用可能存在的性能问题。
- 启停控制:可通过会话区域按钮来即时控制实时监控界面的录制状态。
- 详细数据展示:鼠标悬浮于所关心的泳道数据上时,界面上会出现当前时间点Tooltips。将鼠标悬浮于时间轴之上时,实时监控页面内的所有泳道均会以Tooltips展示出该时刻的数据。
- 图例选择:图例均支持选择/反选来增加/去除泳道内这一数据的展示,内容改变后泳道内的数据会自动缩放以适应泳道的高历度。
执行效率Time Insight
Profiler提供了基础的函数耗时场景分析Time Insight,通过周期性采集调用栈,识别CPU耗时高的热点代码段,用于分析卡顿、CPU占用高、运行速度慢等问题。
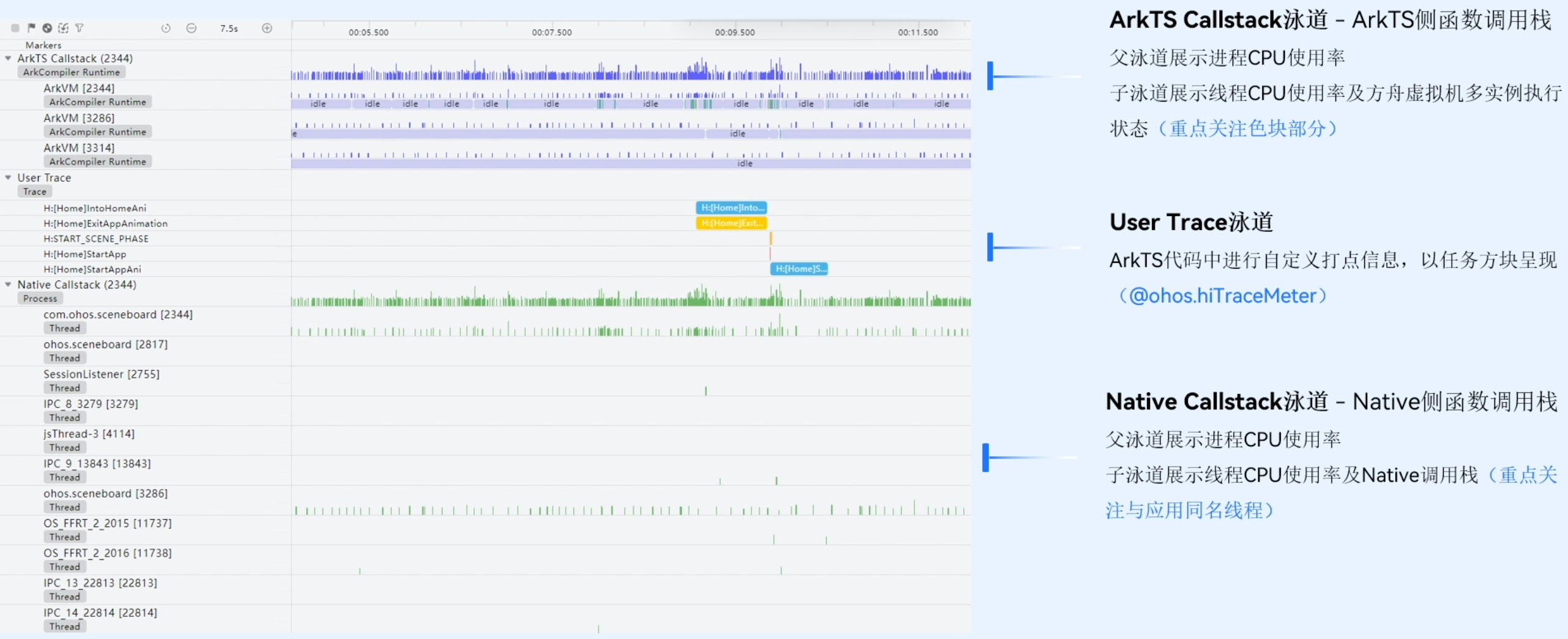
- 用户开发ArkTS代码是跑在方舟虚拟机上的,ArkTS Callstack泳道就是采集方舟虚拟机CPU的占用;
- User Trace泳道进行自定义打点信息分析函数耗时,在函数开始和结束的位置进行打点获取函数耗时;
- Native Callstack泳道会采集Native侧C或者C++的执行,展示函数调用方面的一些情况;
把泳道区框选后,就会出现详细区的信息。框选ArkTS Callstack泳道后,详细区展示函数耗时调用栈信息。所有的函数做了归并展示,展示当前函数在这个时间范围内运行时长、自身运行时长、它的子函数运行时长。
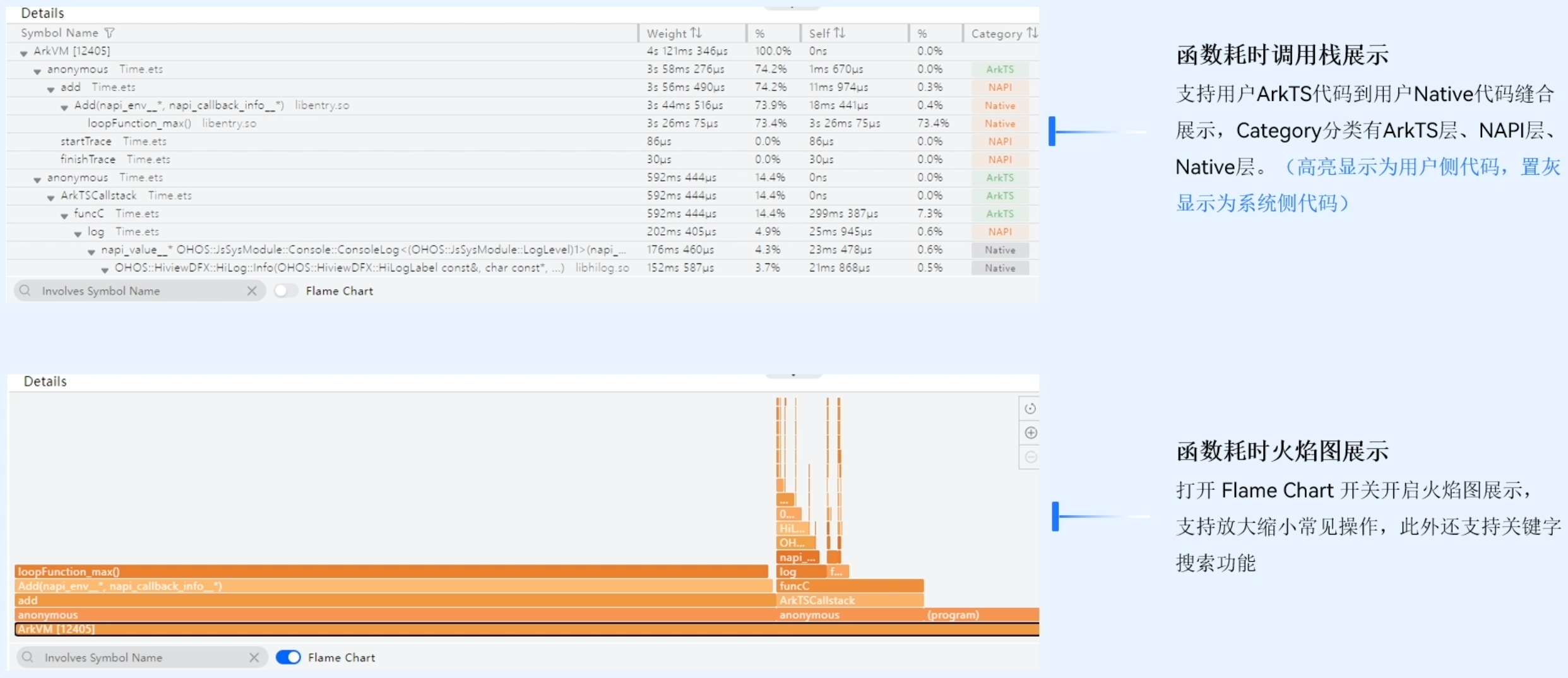
函数耗时调用栈展示:支持用户ArkTS代码到用户Native代码缝合展示;Category分类有ArkTS层、NAPI层、Native层。(高亮显示为用户侧代码,置灰显示为系统侧代码)
函数耗时火焰图展示:打开FlameChart开关开启火焰图展示,支持放大缩小常见操作,此外还支持关键字搜索功能。
内存分析Allocation Insight
概述
录制和分析内存分配记录,用于分析内存峰值高,内存泄漏,内存不足导致应用被强杀等问题。
应用在开发过程中,可能会因为API使用错误、变量未及时释放、异常频繁创建/释放内存等情况引发各种内存问题。Profiler提供了基础的内存场景分析Allocation Insight,识别和定位内存泄漏、内存抖动以及内存溢出等问题,对应用或服务的内存使用进行优化。
Allocation Insight包括Memory泳道、ArkTS Allocation泳道、Native Allocation泳道。
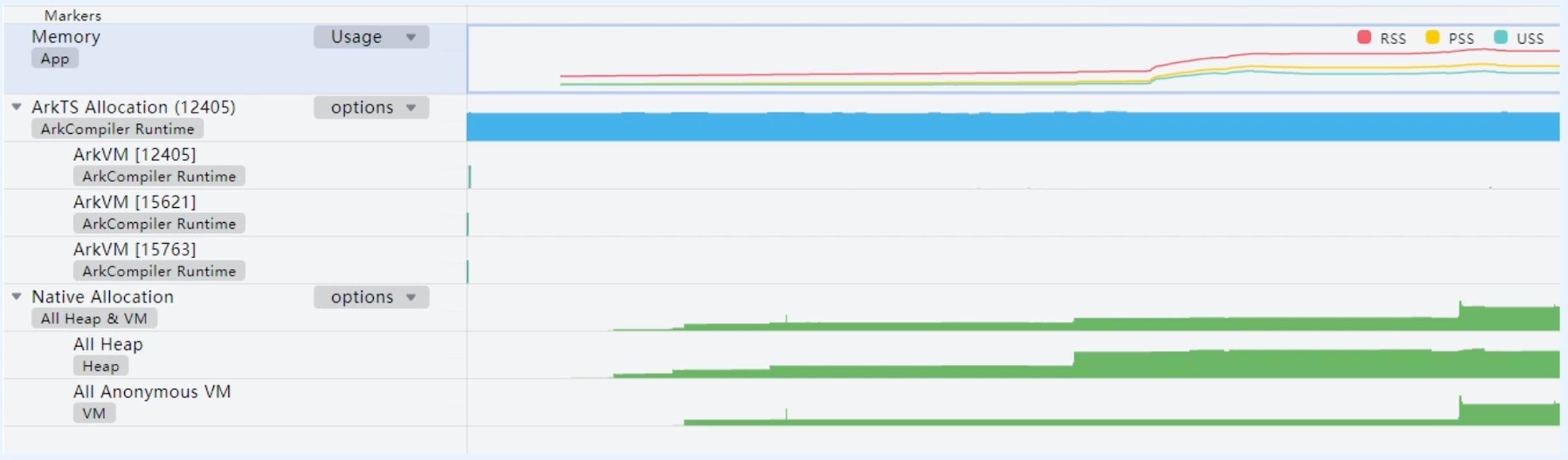
Memory泳道展示应用整体内存随时间的变化情况。
- PSS:进程独占内存和按比例分配共享库占用内存之和
- RSS:进程独占内存和相关共享库占用内存之和
- USS:进程独占内存
ArkTS Allocation泳道展示方舟虚拟机上的堆内存分配与使用情况。
- 主泳道展示进程的ArkTS堆内存总和
- 子泳道展示对应实例在录制过程中的内存分配情况,灰色柱子代表内存已释放,绿色柱子则代表内存在录制结束时仍未释放
Native Allocation泳道展示Native内存分配情况。
- 具体的Native内存分配情况(包含堆内存和匿名内存),包括内存统计数据、内存分配栈以及内存分配事件
选中具体的涌道后,下面就会展示当前框架时间段内存对象的详细信息。
ArkTS Allocation详情
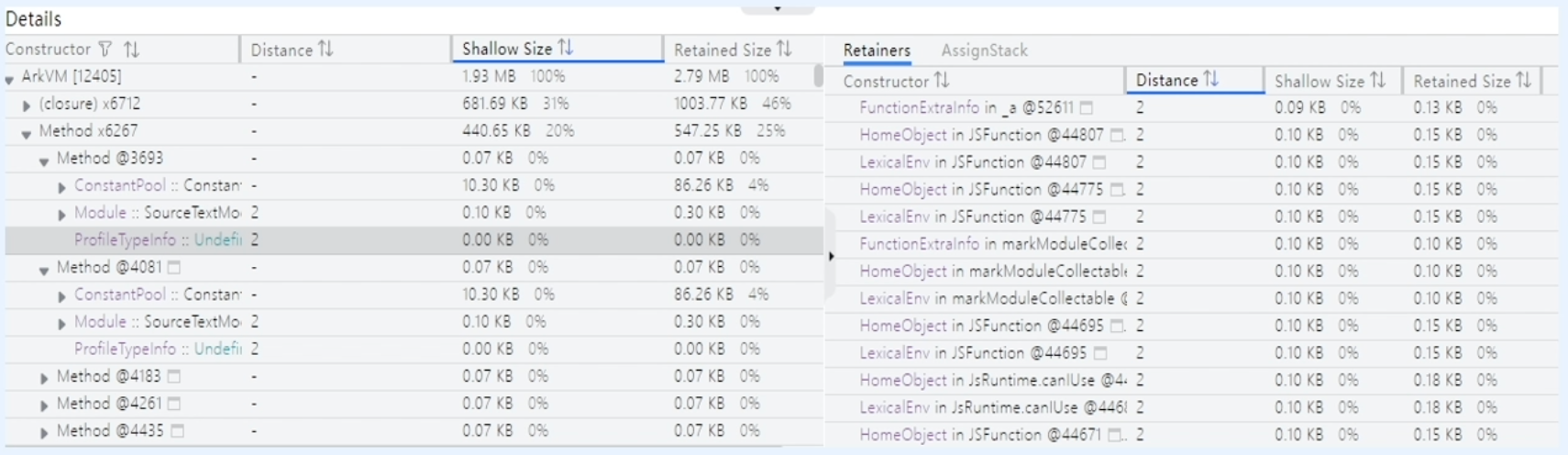
展示当前框选时段内存活对象的详细信息,包括距GCRoot的距离、对象自身内存大小、对象关联内存大小等,支持关联对象跳转。
Native Allocation泳道
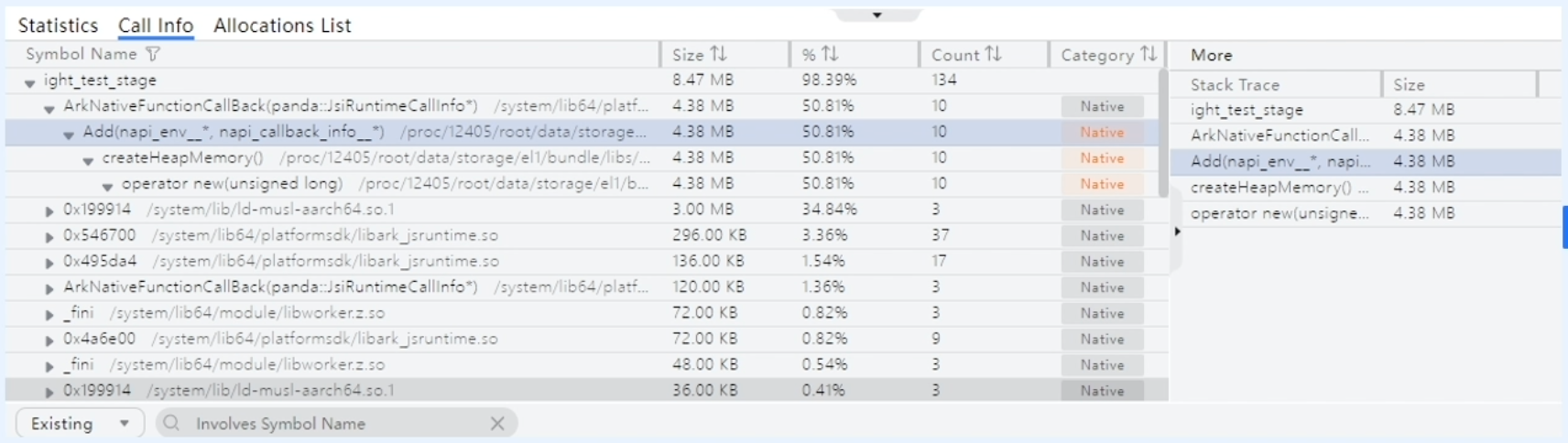
- Statistics页签中显示该段时间内存分配统计数据;
- Call Info页签显示线程的内存分配栈;
- Allocations List显示该时间段内的所有内存分配事件详细信息
Native Allocation泳道支持按内存状态(All/Existing/Release)筛选,支持按统计方式(大小/so库)筛选,支持搜索功能。
内存快照Snapshot Insight
录制和分析应用程序中ArkTS对象的分布,通过过快照方式对比ArkTS对象分布区别,用于分析内存泄漏问题。
针对方舟虚拟机,Profiler提供了内存快照分析能力,结合Memory实时占用情况,分析不同时刻的方舟虚拟机内存占用及差异。
在"Snapshot"的"Comparison"页签中,可以进行快照的差异对比,比较内容包括新增数、删除数、相对变化数、分配大小、释放大小、相对变化大小等等;分析快照间的对比数据,有助于定位内存问题的具体位置。这个模板主要就是来进行内存的对比的。
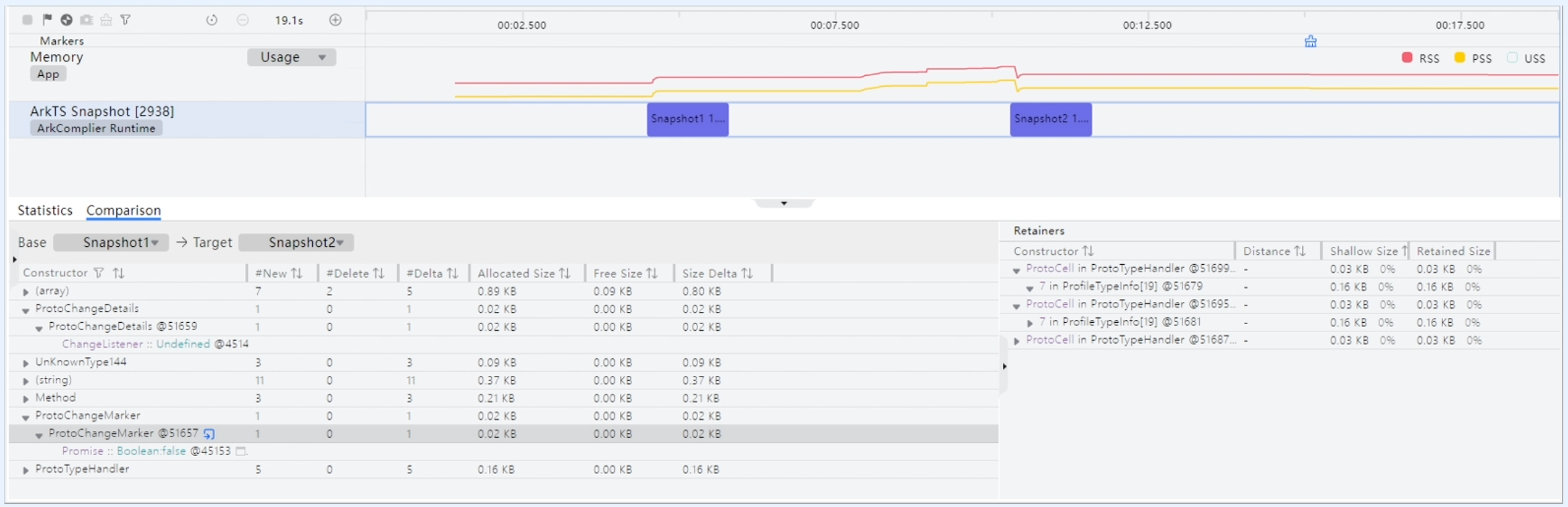
ArkTS Snapshot泳道:紫色区块代表方舟堆快照,区块的长度代表堆快照的生成时间,并显示该快照内存大小。
构造函数名称后的x数字,表示该类型对象数量,可单击叠按钮展开。
实例对象名称后的@数字,表示该对象实例ID。
单击列表中任一对象,Retainers区域会显示该对象的引用链,通过引用链信息可以分析对象被谁持有、如何持有,从而定位问题产生的原因。
录制过程中工具栏点击“照片”按钮进行方舟堆内存拍照;录制过程中工具栏点击“刷子”按钮触发方舟虚拟机GC。
内核分析CPU Insight
录制CPU调度事件、线程运行状态、CPU核频率、Trace等数据,可用于分析卡顿、运行速度慢、应用无响应等问题。
开发者可以使用CPU Insight,查看应用/服务的CPU使用率、调度信息和线程的运行情况,了解指定时间段内的CPU资源消耗情况;查看系统的关键打点,进行更具针对性的优化。
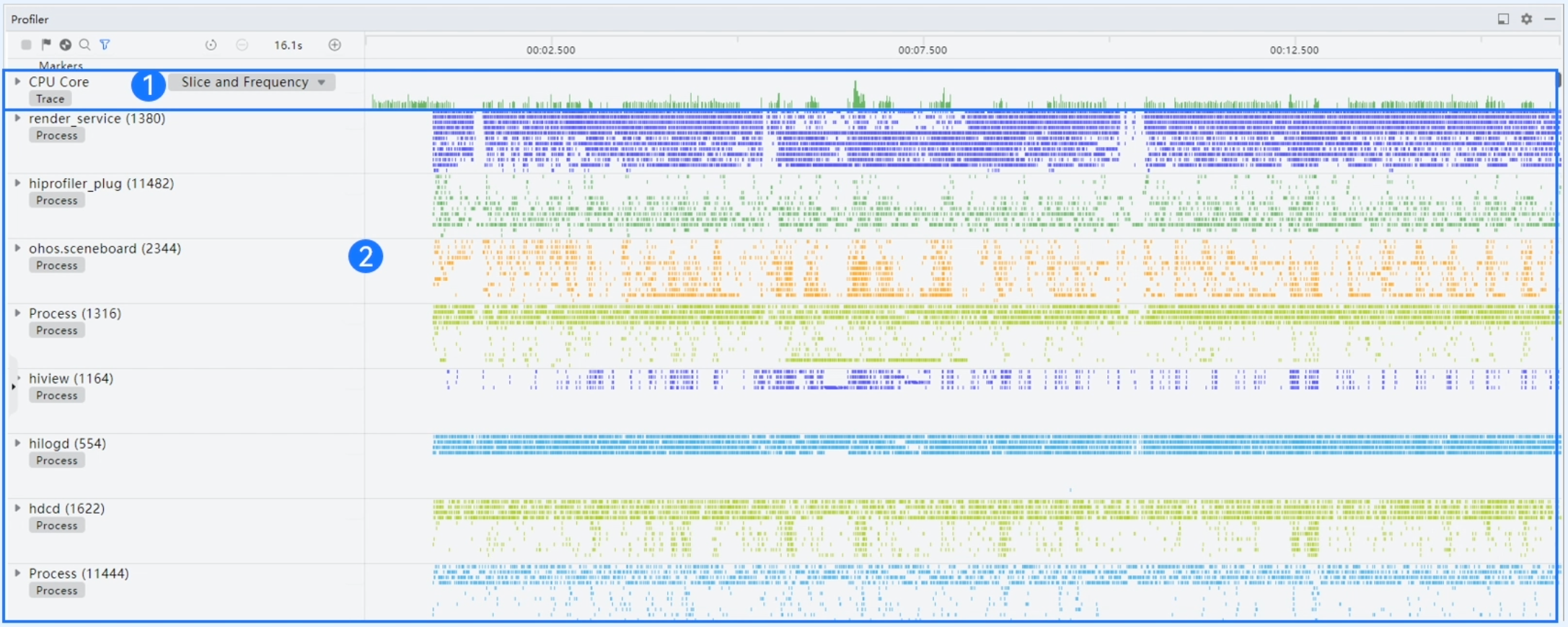
CPU Core泳道:父泳道展示当前进程CPU使用率;子泳道展示各CPU核运行时间片、频率、使用率。
Process泳道:父泳道展示各进程CPU核使用概览;子泳道展示各线程运行状态和打点任务运行情况。
CPU Core子泳道的功能
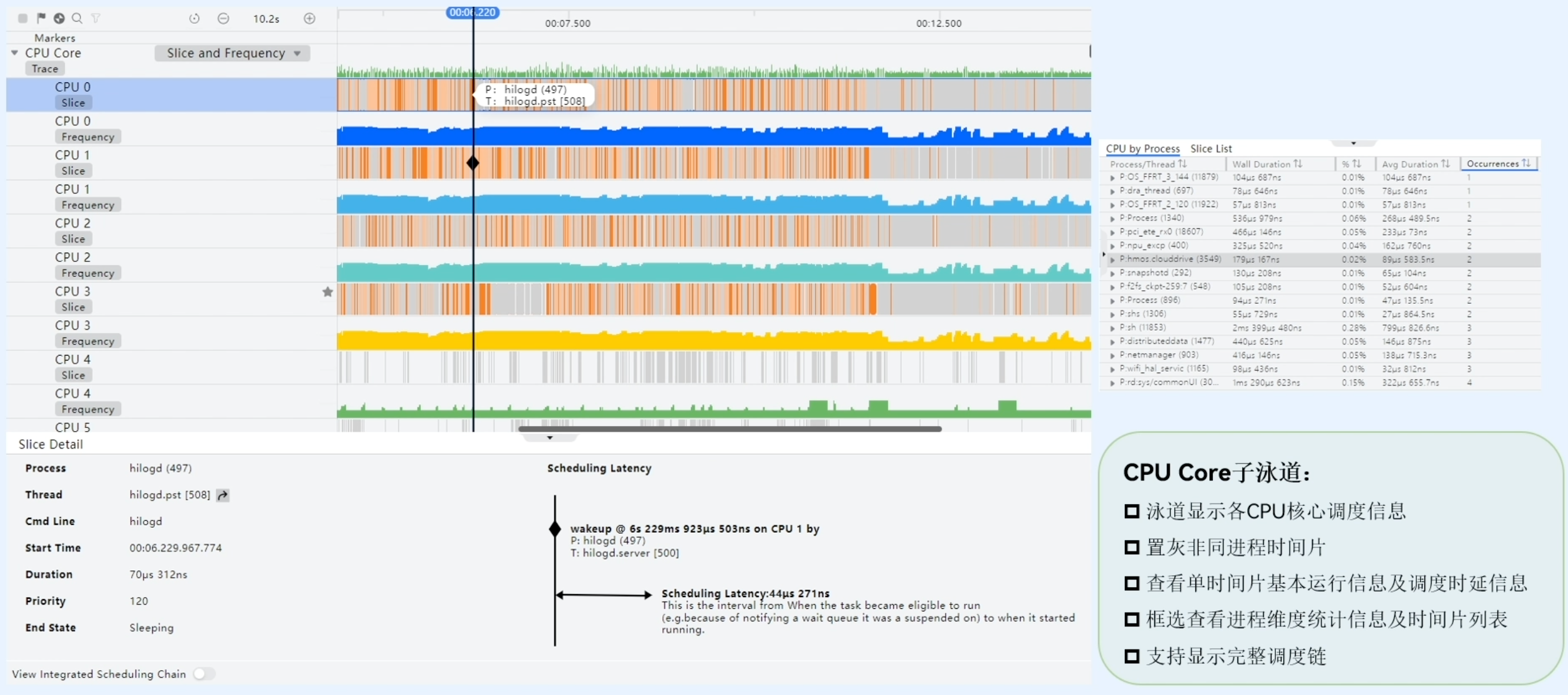
CPU Core子泳道主要是为了显示CPU方面的一些信息:核心调度信息、时间片信息、进程维度统计信息及时间片列表信息,也可以支持显示完整的调度链信息。
这个模板可以很方便地帮助用户分析CPU方面的问题。
Process泳道
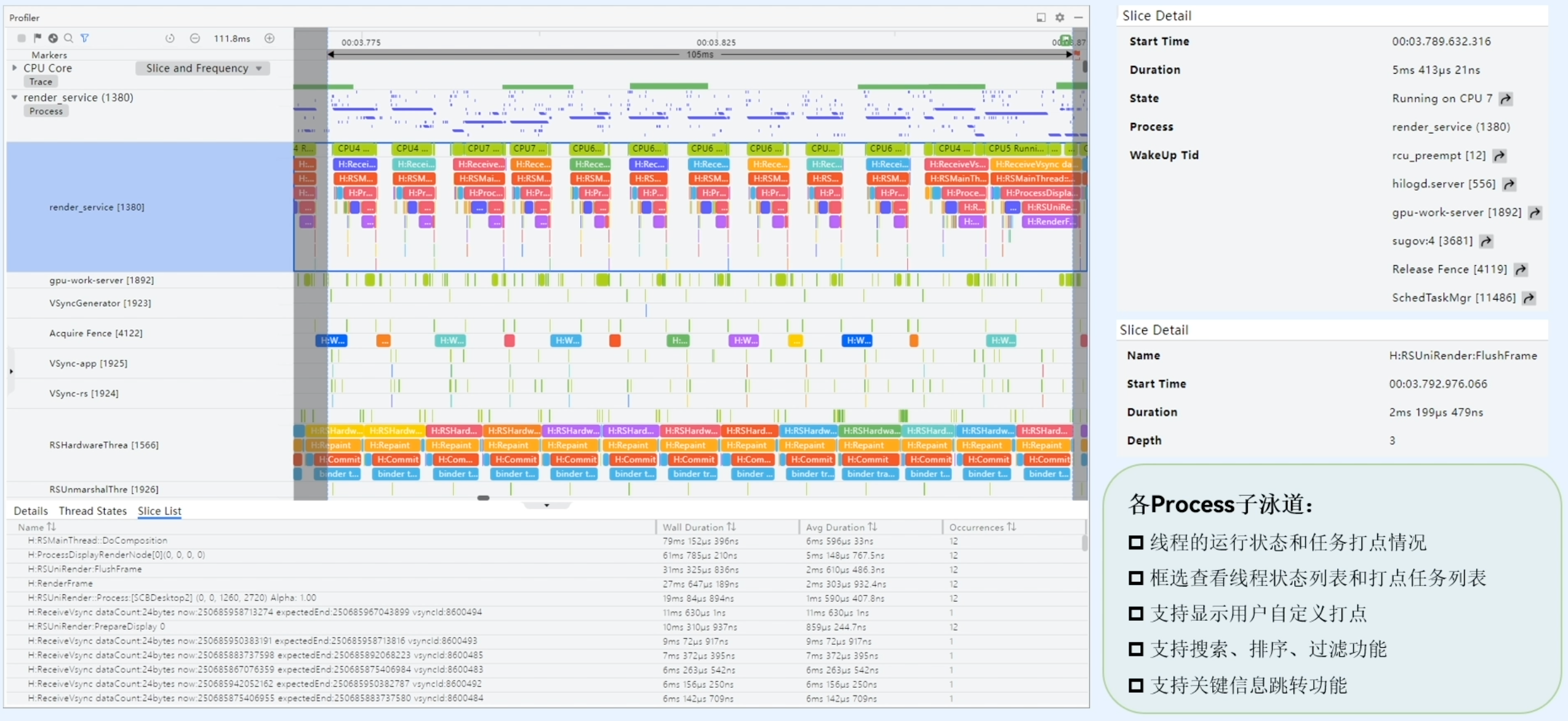
Process子泳道功能如下:
- 显示线程的运行状态和任务打点情况;
- 框选查看线程状态列表和打点任务列表;
- 支持显示用户自定义打点;
- 支持搜索、排序、过滤功能;
- 支持关键信息跳转功能。
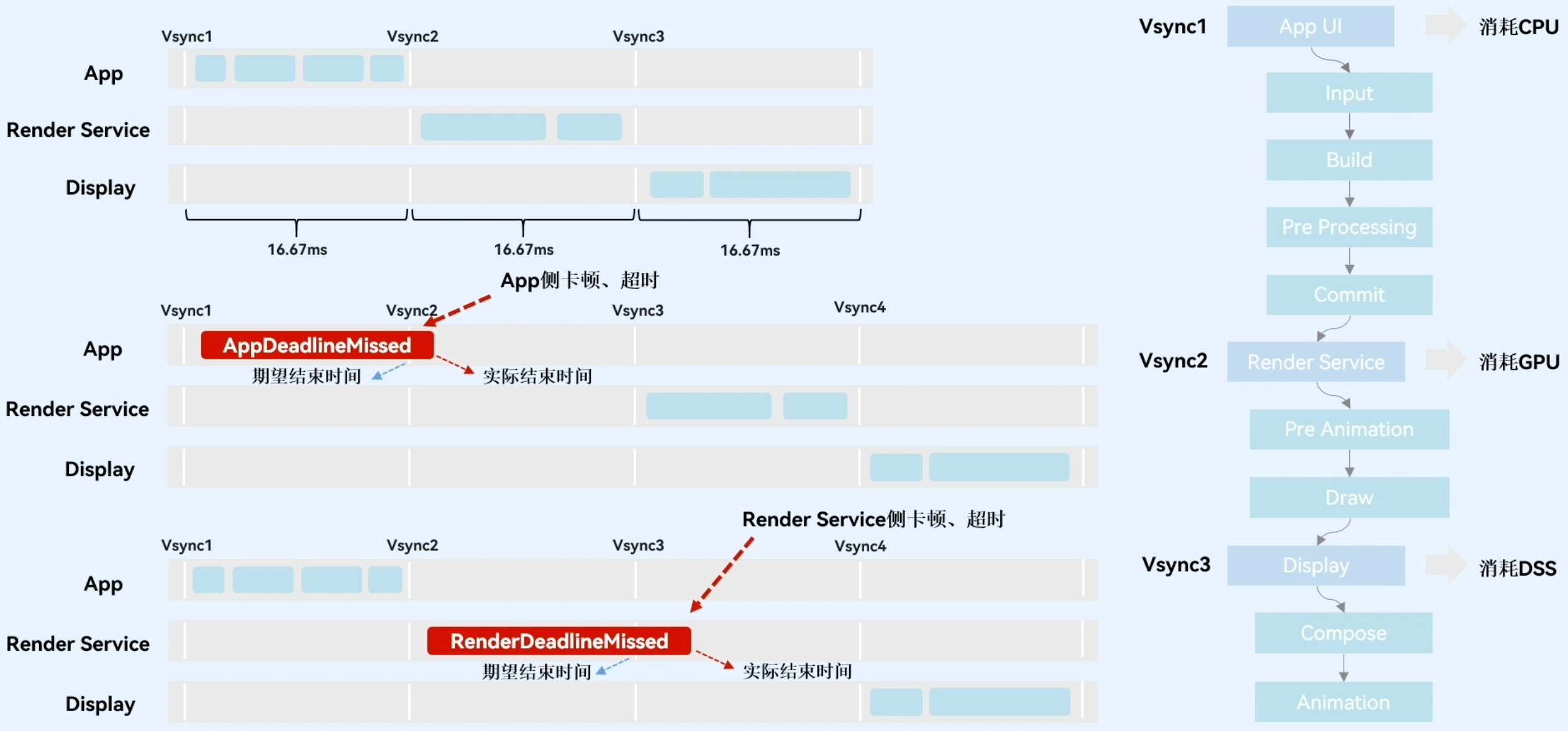
卡顿丢顿Frame Insight
概述
录制卡顿过程中的关键数据,标注出应用侧、Renderservice侧卡顿帧,用于分析应用卡顿、丢帧的问题。
当某一帧的实际结束时间晚于该帧的期望结束时间时,该帧即被识别为卡顿帧。目前卡顿顿仅被分为APP与Render Service两种,且APP与Render Service侧的卡顿并非一定同时出现。
Frame Insight主要功能
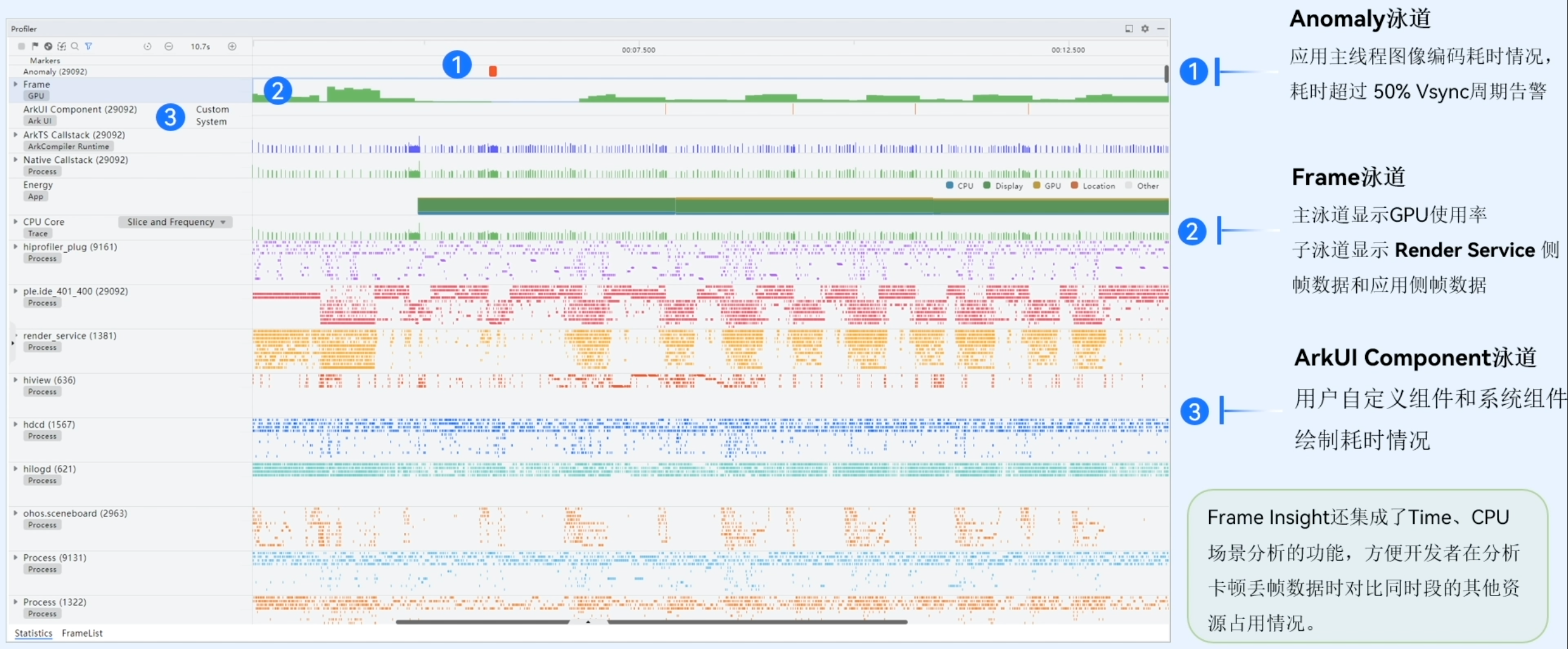
如上图所示,Frame Insight是一个复合模版
Frame泳道
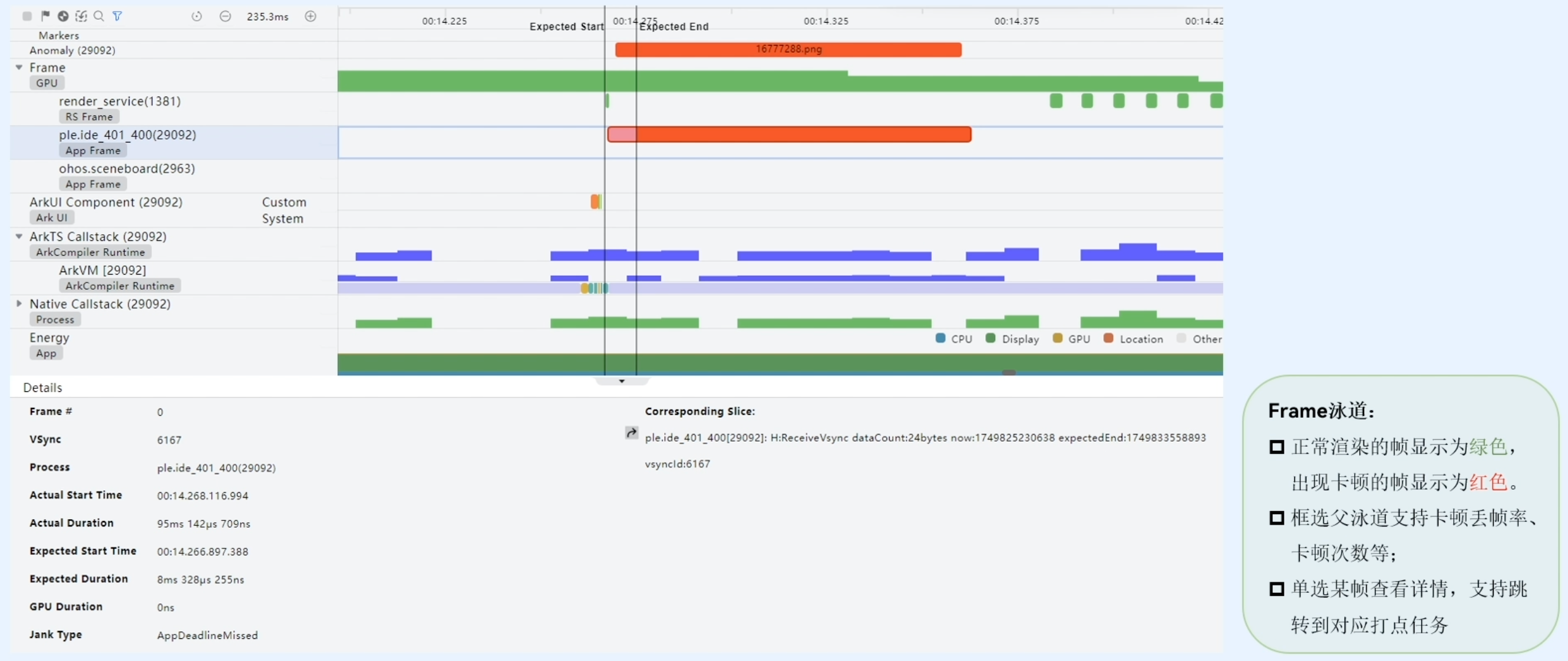
Frame模板里面还包括了ArkUl Component泳道,其功能如下:
- 支持显示系统组件和用户自定义组件的耗时情况;
- 框选查看各组件节点个数,耗时统计情况

这个泳道主要是对组件的打点,让用户对自己组件使用过程中的耗时进行进一步的分析。
启动分析Launch Insight
录制和还原从启动应用,到显示首帧过程中的CPU、内存等资源使用情况,用于分析启动耗时长的问题。
开发应用或服务过程中启动耗时是很重要的一个指标,如果开发者需要分析启动过程的耗时瓶颈,优化应用或服务的冷启动耗时,可使用Profiler提供的Launch场景分析能力,录制采集应用或服务过程中的关键数据进行分析,识别出应用/服务启动耗时长的问题。
此外Launch Insight模版还集成了Time、CPU、Frame场景分析的功能,方便开发者在分析启动阶段数据时对比同时段的其他资源占用情况。
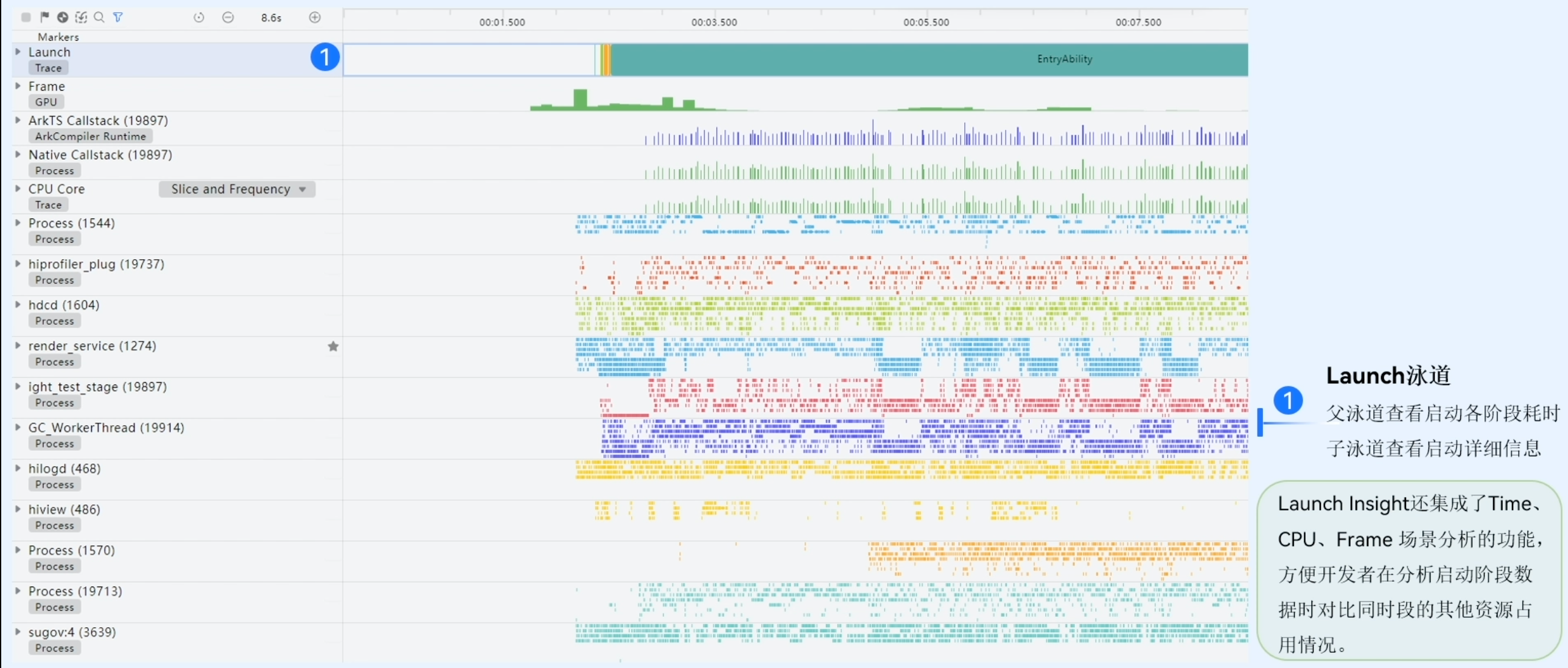
Launch模版主要功能:
- 支持分析静态资源库加载耗时
- 支持查看核心线程在CPU Core的运行情况
- 支持查看启动过程关键线程Trace数据。这个Trace数据对用户来定位启动过程中的问题是非常重要的
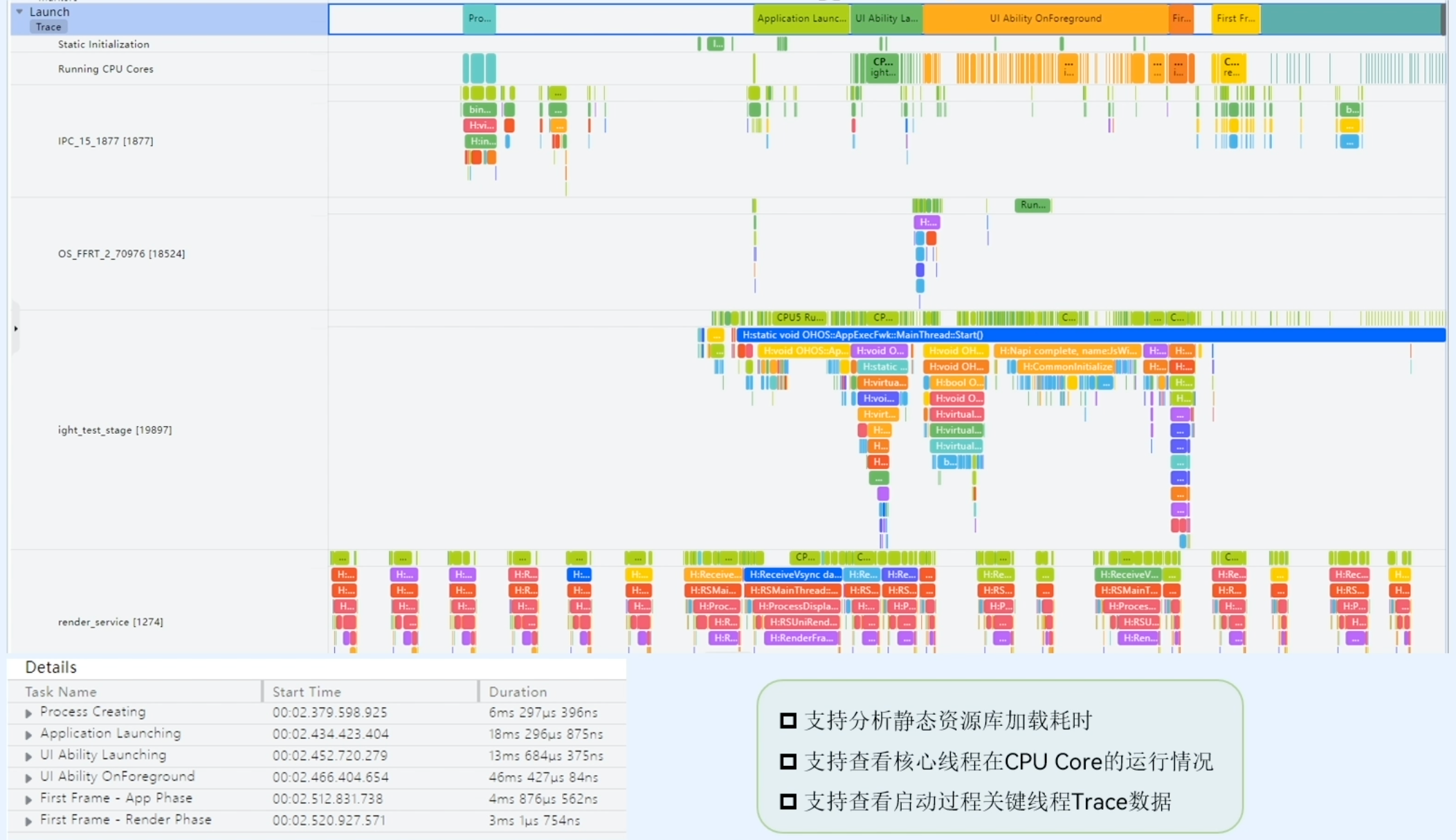
实际操作
整个Profiler是集中在IDE里面的,在IDE下方可以打开Profiler。官方课程视频中介绍了Profiler中内存模版和帧率模版的实际操作过程。
Smart Perf与Profiler对比
概述
在鸿蒙生态中,“Profiler”和“Smart Perf”并不是竞争关系,而是一对定位清晰、分工明确的“黄金搭档”。它们共同构成了鸿蒙应用性能分析的完整闭环。
简单来说,可以这样理解它们的分工:
-
DevEco Studio Profiler 更像是为你准备的一把 “手术刀”,它深度集成在IDE中,用于精准地剖析代码层面的问题,比如定位某个函数的执行耗时或内存泄漏。
-
Smart Perf 全家桶 则像是一套 “全景医疗设备”,覆盖从开发者到测试专家,从简单指标到深度Trace分析的各种场景,尤其擅长从系统全局视角看待性能问题。
为了让你更清晰地了解它们的区别,我整理了一个详细的对比表格:
| 对比维度 | DevEco Studio Profiler | Smart Perf 全家桶 |
|---|---|---|
| 核心定位 | IDE内置的代码级性能分析工具,专注于帮助开发者深入分析和优化应用代码。 | 独立的、全方位的性能调优工具集,覆盖从开发、测试到上线的全流程。 |
| 工具形态 | 作为DevEco Studio IDE的一个内置窗口/插件,开箱即用。 | 工具全家桶,包含: • HiSmartPerf-Device (设备端APP) • HiSmartPerf-Editor / Smart Perf Host (PC端专业分析平台) • SmartPerf-Daemon (命令行工具) |
| 主要功能 | • CPU分析:实时监控CPU占用、分析函数调用栈、生成火焰图。 • 内存分析:实时监控内存占用、捕获Heap Dump(堆转储文件)分析内存泄漏。 • 网络分析:监控网络请求流量和时间。 • 帧率分析:监控UI渲染帧率。 |
• 全栈数据采集:覆盖FPS、CPU/GPU负载及频率、温度、功耗、内存、网络等几乎所有性能指标。 • 深度Trace分析:如SmartPerf Host的渲染链路泳道图分析。 • 专项测试:游戏性能评估、整机测试、RS(Render Service)树可视化等。 |
| 核心优势 | • 代码关联性强:分析结果能直接关联到具体的代码行、类和方法。 • 开发闭环:在编码的同时即可进行性能分析,发现问题-修改代码-验证的流程非常短。 |
• 覆盖全面:从开发者的深度分析,到测试人员的快速验证,再到自动化集成,都能找到对应工具。 • 系统视角:能提供系统级别的Trace分析(如CPU调度、跨进程调用),不仅限于应用本身。 • 数据准确:工具本身对设备性能影响小,采集的数据更接近真实情况。 |
| 典型使用场景 | 1. 定位函数热点:发现某个方法CPU占用特别高,用Profiler的CPU火焰图找到它。 2. 排查内存泄漏:怀疑应用内存不断增长,用Profiler抓取Heap Snapshot(堆快照)进行比较。 3. 分析列表滑动卡顿:在滑动列表时开启Profiler,查看主线程的耗时任务。 |
1. 游戏性能评估:测试人员用HiSmartPerf-Device快速采集多款游戏在真机上的帧率和温度数据。 2. 渲染链路优化:开发者用SmartPerf Host分析渲染管线的每一帧,定位冗余绘制。 3. 自动化测试集成:QA团队编写脚本,调用SmartPerf-Daemon在自动化测试中同步采集性能数据。 |
如何选择?
面对这两个强大的工具集,你可能会问:“那我到底该用哪一个?” 答案很简单,看你的具体任务:
-
当你在DevEco Studio中写代码时:遇到性能疑虑,首选 Profiler。它能让你在不离开IDE的情况下,快速定位到是哪个函数、哪行代码拖慢了你的应用。
-
当你想全面评估App(尤其是游戏)的整体表现时:比如想知道它在不同手机上的帧率稳定性、发热和耗电情况,用 HiSmartPerf-Device 最合适。
-
当你需要分析复杂的系统级问题(如应用启动慢、滑动掉帧背后的渲染原理)时:Smart Perf Host/Editor 这类专业工具提供的泳道图、渲染指令分析功能,能帮你从系统全局看清问题本质。
ArkUl Inspector
鸿蒙ArkUI Inspector是DevEco Studio中一款完全免费的UI调试工具,可以把它理解为网页开发中的“检查元素”功能。它能让你像看透视图一样,直观地查看应用页面的UI层级结构、组件属性和状态变量,帮你快速定位布局错位、组件遮挡、冗余嵌套等各种UI问题。
如何使用ArkUI Inspector?
下面这份指南,可以帮你快速上手:
-
准备工作:在DevEco Studio中打开你的Stage模型项目,通过USB连接好开启了调试模式的真机或模拟器,并确保应用已在设备前台运行。
-
打开工具:在DevEco Studio底部工具栏找到并点击 ArkUI Inspector 按钮。如果找不到,也可以通过菜单栏
View > Tool Windows > ArkUI Inspector打开。 -
连接应用:工具面板打开后,在顶部的进程选择栏中,选择当前正在设备前台运行的应用进程。点击旁边的刷新按钮,即可加载当前页面的UI快照。
-
三大利器,精准定位:
-
三栏视图联动分析:工具界面主要分为三栏:
-
左侧(组件树):以树状结构展示页面所有组件,点击任一节点,中间画布和右侧属性面板会同步高亮。
-
中间(UI画布):实时显示应用界面的“快照”,你可以直接用鼠标点击画布上的任意UI元素,左侧组件树和右侧属性面板会自动定位到它。
-
右侧(属性面板):显示选中组件的详细属性,包括坐标、宽高、边距、背景色等所有样式信息。对于自定义组件,这里还能查看其状态变量的当前值,是调试动态UI问题的关键。
-
-
-
进阶技巧,提升效率:
-
开启3D视图:如果遇到组件相互遮挡、显示层级混乱的问题,可以点击画布上方的 3D View 按钮。它能将UI界面“立起来”,让你像拉开图层一样,清晰地观察组件的Z轴堆叠顺序,快速定位被遮挡的组件。
-
一键跳转源码:想修改代码?没问题。先通过
Run > Edit Configurations勾选Enable DebugLine开启功能。之后在Inspector中选中组件,点击属性面板里的源码跳转图标,IDE就会自动带你飞到定义该组件的代码行。 -
导出快照分享:可以将当前的UI分析状态导出为
.arkli文件。这样即使没有设备,你和团队成员也能通过导入这个文件,重现并分析问题,非常便于协作。
-
需要注意的使用限制
-
应用状态:只能分析运行在前台的应用,应用退到后台就无法选择了。
-
工程类型:仅支持 Stage 模型的项目。
-
应用签名:不支持分析已经上架的应用商店商用签名应用,主要用于调试开发版本。
-
连接要求:设备需保持在线(USB/Wi-Fi连接),并且应用须为debug编译模式。
五、合理布局
ArkUI框架执行流程
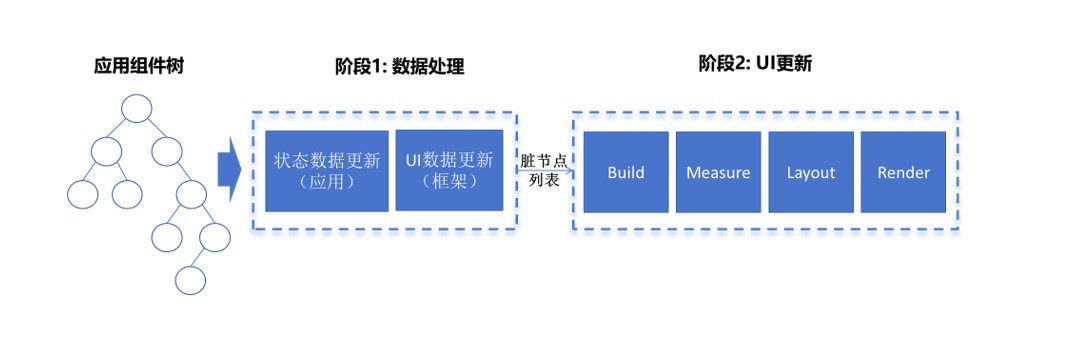
应用界面更新的过程主要分为两个过程:数据处理过程和UI更新过程。
- 数据处理过程中主要是对状态数据进行更新,状态数据指的是所定义的@State等相关的数据。数据变化时,会有一定的更新耗时,并且数据关联的组件数量,也影响下一步UI更新的耗时,在开发过程中需要避免无效的数据更新,从而减少冗余的UI更新耗时。关于这部分的优化措施可以参考《状态管理最佳实践》。
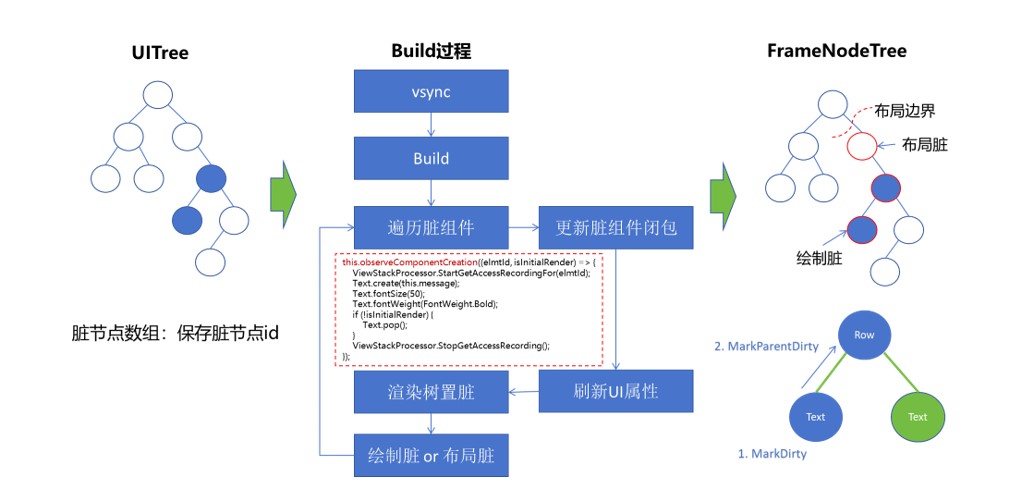
- UI更新过程中则是对需要更新的元素进行更新操作,对应的元素会经历Build、Measure、Layout和Render等阶段。其中Build是执行组件创建和组件标脏(即标记需要更新的组件,当组件的属性状态发生变化时,框架会将其标记为"脏"状态,表示需要进行重新构建)的过程,Measure是对组件的宽高进行测量的阶段,Layout是对元素进行在屏幕上位置进行摆放的阶段,而Render则是根据测量和布局得到的大小位置等信息,进行提交绘制的过程。
UI更新过程
UI更新过程包含组件标脏及布局计算。初始加载阶段,所有组件(排除if/else条件不成立的分支和LazyForEach不可视区域内容)都会完整经历Build、Measure、Layout、Render流程。界面更新阶段,当触发列表滑动、显示/隐藏切换、元素属性(内容/样式/位置/尺寸)变化时,UI线程会先将脏节点进行Build,Build的过程会按照组件id,依次更新组件设置的属性,如果属性发生改变,则进行组件标脏。
- 若布局属性变化(width/height/padding/margin等):标记为"布局脏" ,找到布局边界,进行子树更新。
- 若非布局属性(样式属性)变化(color/backgroundColor/opacity等):仅会影响自身属性,不会进行子树查找。
多数情况下,如果某个组件的布局发生变化,也会对其他组件的布局也会产生影响,所以当有组件的布局发生变化,最简单的办法就是对整棵树进行重新布局,但是这样对整棵树进行重新布局的代价太大。标脏过程就是用来确定布局最小影响范围,来减少对整棵树进行重新布局的代价,而这个影响范围就是布局边界以内。
一般来讲,如果一个组件设置了固定的宽高尺寸,那这个组件就是布局边界。其内部组件布局的变化,不会影响到此布局边界外部的布局情况,那么在查找的时候,只需要在布局边界内部判断哪些组件的布局会受到影响,可以避免在整棵树结构的查找过程。
确定实际的脏节点数组后,根据脏节点数组来拿到对应的脏节点对象,通过递归遍历children进行Measure过程,如果该对象布局参数没有发生变化,就会跳过对应的Measure阶段。当Measure执行完成后,进行layout阶段。
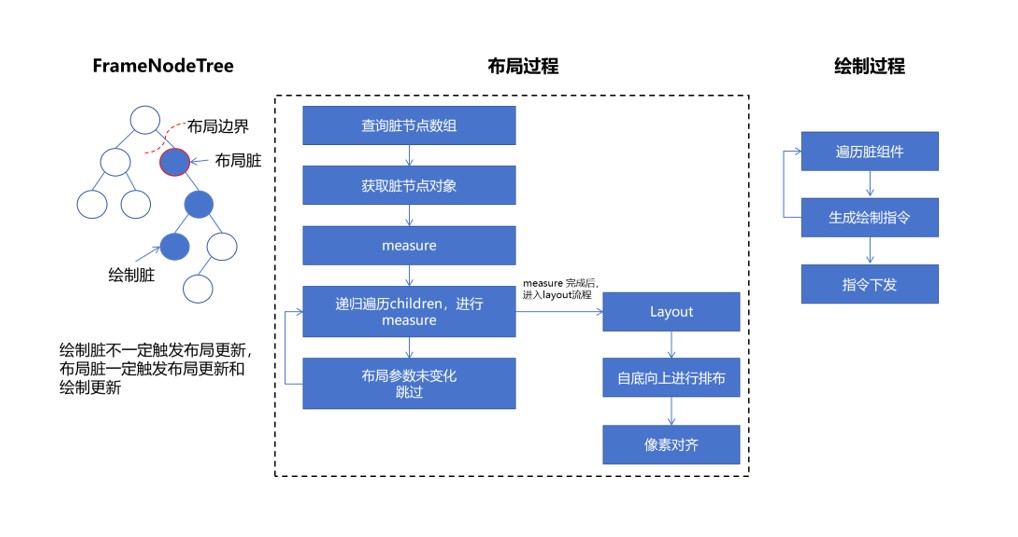
从以上的过程可以看出,影响UI更新过程的主要因素是参与更新的节点数量。
在初次加载的时候,由于所有的节点都要参与全过程,那么如果对首帧渲染的速度有要求,就需要降低整体页面的组件节点数量。
在页面内容更新过程中,由于状态变量的变化导致UI的更新,可以利用布局边界减少子树更新的数量以及减少布局的计算。
精简节点数
说明
建议开发者优先使用Code Linter扫描工具进行代码检查,重点关注@performance/hp-arkui-remove-container-without-property规则。若扫描结果中出现该规则相关问题,可参考本章节提供的优化建议进行调整。
布局阶段是采用递归遍历所有节点的方式进行组件位置和大小的计算, 如果嵌套层级过深,将带来更多的中间节点,在布局测算阶段下,额外的节点数将导致更多的计算过程,造成性能劣化。
表1 嵌套与平铺下的布局时间对比
展开
|
对比指标 |
10 |
100 |
500 |
1000 |
|
|---|---|---|---|---|---|
|
嵌套/层 |
首帧绘制 |
3.2ms |
5.8ms |
17.3ms |
32ms |
|
Measure |
1.88ms |
2.89ms |
5.93ms |
10.46ms |
|
|
Layout |
0.38ms |
1.12ms |
5.26ms |
10.88ms |
|
|
平铺 /个 |
首帧绘制 |
3.6ms |
4.5ms |
14ms |
24.3ms |
|
Measure |
2.15ms |
2.31ms |
5.61ms |
9.26ms |
|
|
Layout |
0.39ms |
1.38ms |
4.74ms |
9.92ms |
|

根据以上数据对比发现,组件平铺和嵌套在相同组件个数的情况下,其性能差异不大,并且整体上趋势保持一致,随着组件数量增加呈现线性增长的劣化,由此可以得到结论,真正影响布局性能的因素是参与布局的节点数量。所以在进行布局时,应该尽量减少整体的节点数,来减少布局的性能劣化。
针对减少总节点,主要有两个方向:
- 移除冗余的节点。
- 使用扁平化布局减少节点数。
移除冗余节点
实际开发中的布局往往非常复杂,冗余带来的开销可能非常影响布局性能,尤其是在列表中动态创建组件时,带来的性能影响是显著的。
使用扁平化布局减少节点数
在某些情况下,开发者所实现的布局在嵌套层级上是没有冗余的,但是嵌套层级仍然较深,唯一的解决方案可能是,通过切换到完全不同的布局类型来实现层次结构的扁平化。
当页面不存在冗余节点时,可以考虑是否能够通过替换为更高级的布局使得页面扁平化,来达到减少节点数的目的。主要方式可以参考:
- RelativeContainer 通过相对布局实现扁平化。
- 绝对定位 通过锚点定位实现扁平化。
- Grid 通过二维布局实现扁平化。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 1
1 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)