
HarmonyOS 数据持久化该怎么选型和落地?
Preferences 是轻量键值存储,适合保存主题模式、字体大小、首次启动标记、功能开关、草稿状态等少量数据。很多鸿蒙应用一开始只是把页面状态放在内存里,功能跑通后才发现用户切后台、进程被回收、设备重启、应用升级都会让数据丢失。对于备忘录、记账、设备控制、阅读历史、登录偏好这类应用,持久化设计会直接影响用户体验。手机号、定位、身份证、支付信息、聊天内容都不是普通字符串。还要测旧版本数据升级、新版
1. 为什么要专门设计持久化层
很多鸿蒙应用一开始只是把页面状态放在内存里,功能跑通后才发现用户切后台、进程被回收、设备重启、应用升级都会让数据丢失。持久化层要解决的不是“能不能保存一个值”,而是数据在应用生命周期之外仍然可靠存在,并且能被后续版本继续读取。对于备忘录、记账、设备控制、阅读历史、登录偏好这类应用,持久化设计会直接影响用户体验。
2. 先按数据类型选方案
数据存储方案不能只看 API 简单不简单,而要看数据规模、结构、查询方式和生命周期。少量用户偏好适合 Preferences;结构化业务数据适合关系型数据库 RDB;图片、录音、导出文件更适合文件或媒体 URI;接口缓存和临时搜索记录要有过期清理策略。选错方案后,短期也许省事,后期会在查询、排序、迁移和隐私治理上付出更多成本。

图 1 数据持久化选型关系
3. Preferences 适合什么场景
Preferences 是轻量键值存储,适合保存主题模式、字体大小、首次启动标记、功能开关、草稿状态等少量数据。它的优势是调用简单、读写直观、数据结构轻。它的限制也很明显:不适合存大量列表,不适合复杂查询,不适合保存强业务关系。把订单列表或聊天记录塞进 Preferences,本质上是把数据库当字符串用,维护成本很高。
4. Preferences 的写入要及时 flush
写入 Preferences 后要关注持久化时机。很多示例会先 put 再 flush,原因是写入内存对象并不等于一定已经落盘。对于主题、开关等用户操作,通常在用户确认或离开页面时持久化;对于输入草稿,可以结合防抖策略减少频繁写入。不要每输入一个字符就立刻 flush,也不要等到应用退出才保存,因为移动端进程退出并不总按你想象的路径发生。
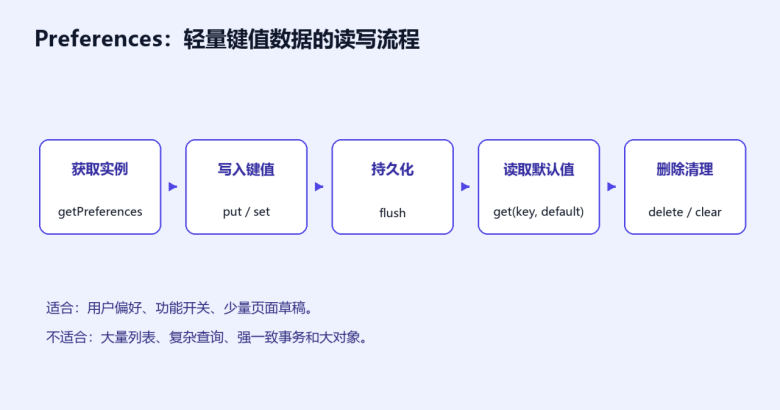
图 2 Preferences 读写流程
5. RDB 适合结构化业务数据
关系型数据库适合保存有字段、有主键、要查询排序过滤的数据。例如笔记应用需要按更新时间排序,记账应用需要按月份汇总,商品收藏需要按分类和关键字筛选,这些都更适合 RDB。RDB 的价值在于表结构清晰、查询能力强、后续可以加索引和迁移脚本。它比 Preferences 重一些,但对中等复杂度业务更稳。
6. 表结构要从业务问题反推
建表不是把接口返回字段原样搬进去,而是根据本地查询需求设计。比如笔记表至少需要 id、title、content、updatedAt、deleted、syncState;如果经常按更新时间排序,就要考虑 updatedAt 字段和索引;如果有云同步,就要有本地修改状态和服务端版本。表字段不是越多越好,关键是能支撑本地业务闭环。
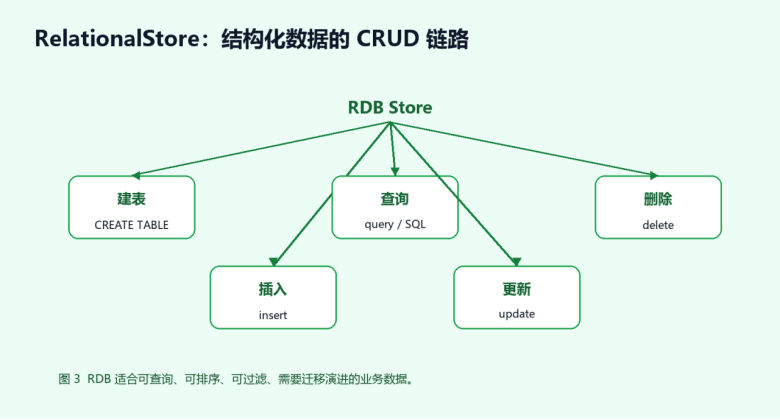
图 3 RDB 结构化数据 CRUD 链路
7. Repository 层隔离数据库细节
页面不应该直接拼 SQL 或到处调用数据库实例。更推荐的做法是封装 Repository 层,让页面只调用 addNote、queryNotes、updateNote、deleteNote 这类业务方法。这样数据库表名、字段名、迁移逻辑都集中管理。后续从 Preferences 切到 RDB,或者给 RDB 加同步状态,也不会影响所有页面。
8. 查询结果要转成业务模型
数据库返回的是行数据,页面需要的是业务对象。把结果转换成 Note、Bill、DeviceRecord 这类模型,可以让 UI 层更干净。不要让 Text 组件直接读取数据库字段名,也不要把 ValuesBucket 传到页面组件里。数据层负责存取,模型层负责表达业务,UI 层负责展示,这是最基本的分层。
9. 更新和删除要考虑软删除
很多业务不适合直接物理删除。比如笔记、账单、收藏记录,如果涉及云同步或误删恢复,直接 delete 会让后续同步很难判断。可以设计 deleted 字段做软删除,等同步完成或超过保留期后再清理。软删除会让查询条件稍微复杂,但能换来更好的恢复能力和同步一致性。
10. 事务用于保证多步操作一致
当一次业务操作要同时修改多张表或多条记录时,要考虑事务。例如删除一个项目时,需要删除项目表、任务表、附件表中的关联记录;记账转账时,需要同时写入支出和收入两条流水。没有事务时,中途失败会留下半成功数据。事务的目的不是提高速度,而是保证一组操作要么全部成功,要么全部回滚。
11. 版本迁移要提前规划
应用上线后,表结构一定会变化。新增字段、拆表、加索引、修改默认值都需要迁移。迁移脚本要能从旧版本平滑升级到新版本,不能只考虑全新安装。比较稳的做法是维护 schemaVersion,每次数据库结构变化都写清楚从旧版本到新版本要执行哪些 SQL。升级前最好备份关键数据,升级失败时给出兜底策略。

图 4 数据迁移与安全检查清单
12. 缓存数据必须有清理规则
缓存不是垃圾桶。接口缓存、图片缓存、搜索建议、临时导出文件都应该有过期时间或容量上限。没有清理规则的缓存会慢慢占满用户空间,也会让页面展示过期信息。缓存设计要回答三个问题:什么时候写入,什么时候命中,什么时候清理。能从服务端重新获取的数据,不应该被当成永久数据保存。
13. 隐私数据要最小化保存
持久化会带来隐私责任。手机号、定位、身份证、支付信息、聊天内容都不是普通字符串。开发时要坚持最小化原则:能不存就不存,能短期缓存就不要长期保存,必须保存时要考虑加密、访问控制和清理入口。调试日志里也不要打印敏感字段。用户退出登录时,应明确清理账号相关数据或切换到隔离空间。
14. 异常路径不能只写 console
存储读写会失败,原因可能是空间不足、数据库损坏、权限问题、版本迁移失败或数据格式不兼容。生产代码不能只 console.error 然后继续展示空页面。更好的方式是封装统一错误类型:可重试错误提示用户稍后再试,不可恢复错误进入修复流程,缓存错误允许降级,核心数据错误则要阻断危险操作。
15. 测试要覆盖升级和恢复
持久化测试不能只测新增和查询。还要测旧版本数据升级、新版本回退、空数据、异常数据、大量数据、删除后恢复、退出登录清理、设备重启后读取、应用被系统回收后恢复。很多数据问题只有在升级路径里出现,开发机全新安装永远发现不了。上线前准备几份旧版本数据库样本,是非常值得的投入。
16. 本文小结
鸿蒙数据持久化的重点不是记住某个 API,而是建立正确的选型和分层意识。Preferences 解决轻量配置,RDB 解决结构化业务,文件解决大对象,缓存解决可重建临时数据。页面不直接操作存储,Repository 封装业务方法,迁移和异常路径从第一版就设计进去。这样写出来的应用,才经得起版本迭代和真实用户数据的考验。
17. 存储方案对比表
|
方案 |
适合数据 |
不适合场景 |
实践建议 |
|
Preferences |
少量键值配置、开关、草稿标记 |
大量列表、复杂查询、强事务 |
写入后按时机 flush,键名集中管理 |
|
RDB |
笔记、账单、订单、收藏等结构化数据 |
大文件、纯临时缓存 |
Repository 封装,表结构版本化 |
|
文件存储 |
图片、日志、导出文档、附件 |
需要频繁字段查询的数据 |
只保存路径或 URI 到数据库 |
|
缓存 |
可重建的接口结果、搜索建议 |
核心业务数据和隐私数据 |
设置过期时间和容量上限 |
18. 案例代码:Preferences 保存主题模式
import { preferences } from '@kit.ArkData';
const STORE_NAME = 'user_settings';
const KEY_DARK_MODE = 'dark_mode';
async function saveDarkMode(context: Context, enabled: boolean): Promise<void> {
const store = await preferences.getPreferences(context, STORE_NAME);
store.put(KEY_DARK_MODE, enabled);
await store.flush();
}
async function readDarkMode(context: Context): Promise<boolean> {
const store = await preferences.getPreferences(context, STORE_NAME);
return store.get(KEY_DARK_MODE, false) as boolean;
}
这段代码适合主题开关这类少量配置。键名集中定义,读取时给默认值,写入后 flush。真实项目还可以把 SettingsRepository 封装成单例,让页面不直接感知 Preferences 文件名和键名。
19. 案例代码:RDB 建表与插入笔记
import { relationalStore } from '@kit.ArkData';
const STORE_CONFIG: relationalStore.StoreConfig = {
name: 'note.db',
securityLevel: relationalStore.SecurityLevel.S1
};
const SQL_CREATE_NOTE = `CREATE TABLE IF NOT EXISTS note (
id TEXT PRIMARY KEY,
title TEXT NOT NULL,
content TEXT,
updated_at INTEGER,
deleted INTEGER DEFAULT 0
)`;
async function initStore(context: Context): Promise<relationalStore.RdbStore> {
const store = await relationalStore.getRdbStore(context, STORE_CONFIG);
await store.executeSql(SQL_CREATE_NOTE);
return store;
}
建表时要考虑主键、默认值、更新时间和软删除字段。不要等业务复杂后再补字段,因为线上数据迁移会更麻烦。这里用 updated_at 支撑排序,用 deleted 支撑软删除和后续同步。
20. 案例代码:Repository 封装查询
class NoteRepository {
constructor(private store: relationalStore.RdbStore) {}
async addNote(note: Note): Promise<void> {
const value: relationalStore.ValuesBucket = {
id: note.id,
title: note.title,
content: note.content,
updated_at: Date.now(),
deleted: 0
};
await this.store.insert('note', value);
}
async queryActiveNotes(): Promise<Array<Note>> {
const predicates = new relationalStore.RdbPredicates('note');
predicates.equalTo('deleted', 0).orderByDesc('updated_at');
const resultSet = await this.store.query(predicates);
return mapResultSetToNotes(resultSet);
}
}
Repository 让页面只关心业务动作,不关心表名、字段名和查询条件。后续要加分页、索引、同步状态或异常处理,都可以在 Repository 内部调整。
21. 案例代码:软删除与事务思路
async function softDeleteNote(store: relationalStore.RdbStore, id: string): Promise<void> {
const value: relationalStore.ValuesBucket = {
deleted: 1,
updated_at: Date.now()
};
const predicates = new relationalStore.RdbPredicates('note');
predicates.equalTo('id', id);
await store.update(value, predicates);
}
// 多表操作时,应使用事务或等价封装,避免半成功数据。
// 例如删除项目时,同时标记项目、任务和附件记录。
软删除适合需要恢复、同步或审计的业务。物理删除适合缓存和临时文件。涉及多张表时要把多步操作放进事务或统一封装,避免某一步失败后数据关系断裂。
22. 参考资料
- HarmonyOS 应用数据持久化官方指南:https://developer.huawei.com/consumer/en/doc/harmonyos-guides/app-data-persistence-V5
- HarmonyOS RelationalStore API 参考:https://developer.huawei.com/consumer/en/doc/harmonyos-references/js-apis-data-rdb
- 华为开发者文档中心:https://developer.huawei.com/consumer/cn/doc/

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)