
小智Pro:接入长期记忆,一个更懂你、有灵魂的小智
本文分享了`小智Pro 接入长期记忆`的几种实现方案。
前文,分享了【小智Pro】系列文章:
小智Pro:在线点歌+歌词同步,支持打断和搜索,端云协同方案
零门槛为小智接入MCP,小智Pro焕新上线:MCP广场+自定义服务
我们知道,LLM天生是“健忘”的。每次与它交互,模型关注的只有一个“上下文窗口”。
因此,为了让小智更懂你,需要接入长期记忆👇:
今日分享,聊聊:
- 长期记忆的技术方案
- 开源方案梳理和评测
- 小智Pro如何接入
1. 长期记忆的技术方案
当前大模型普遍采用 Transformer 架构,其记忆核心在自注意力机制,也就是上下文窗口。
但窗口长度是有限的,文本长度超过窗口限制,信息就会被截断。
怎么解决?
学术界主要有两类技术方案:
-
基于外挂的记忆:本质上是为大模型配备了一个外部数据库,存储和用户相关的历史记录。当用户提问时,先去库里检索,再将检索结果喂给AI。
-
基于模型参数的记忆:本质是将记忆通过训练内化成模型参数的一部分,DeepSeek今年年初的论文就是聚焦这一点。
其实,业界目前在用的,主要还是第一种,底层还是 RAG(检索增强生成)那一套。
但相比 RAG,长期记忆还需要解决:
- 哪些内容需要保存?
- 什么时候保存?
- 怎么保存?
- 如何召回?
- 如何更新、合并?
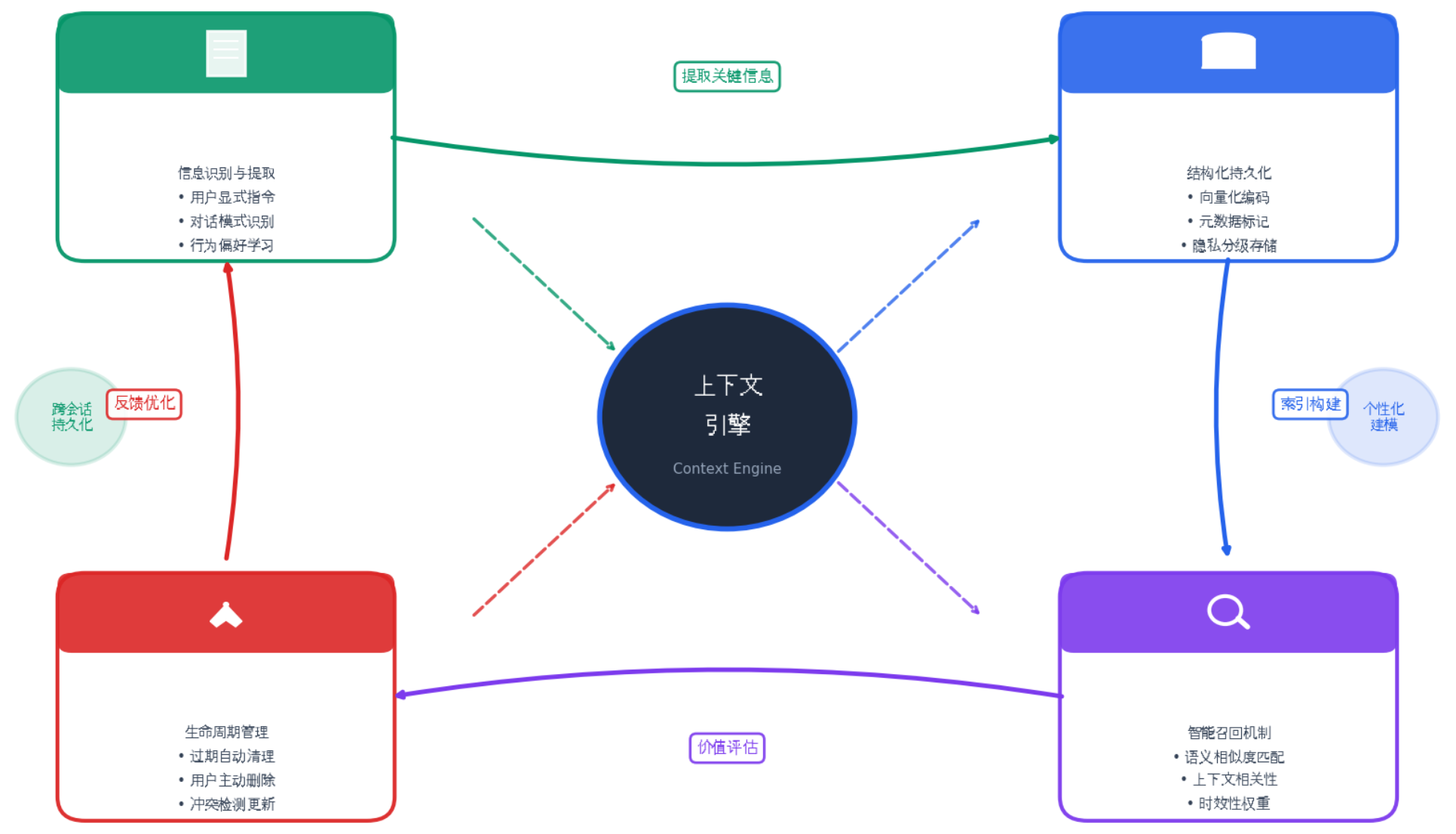
更确切地说,长期记忆是 Agent 中至关重要的上下文引擎:
2. 长期记忆的开源方案梳理
目前大部分方案,均提供自部署方案和云端API,大家可按需取用。
2.1 Mem0
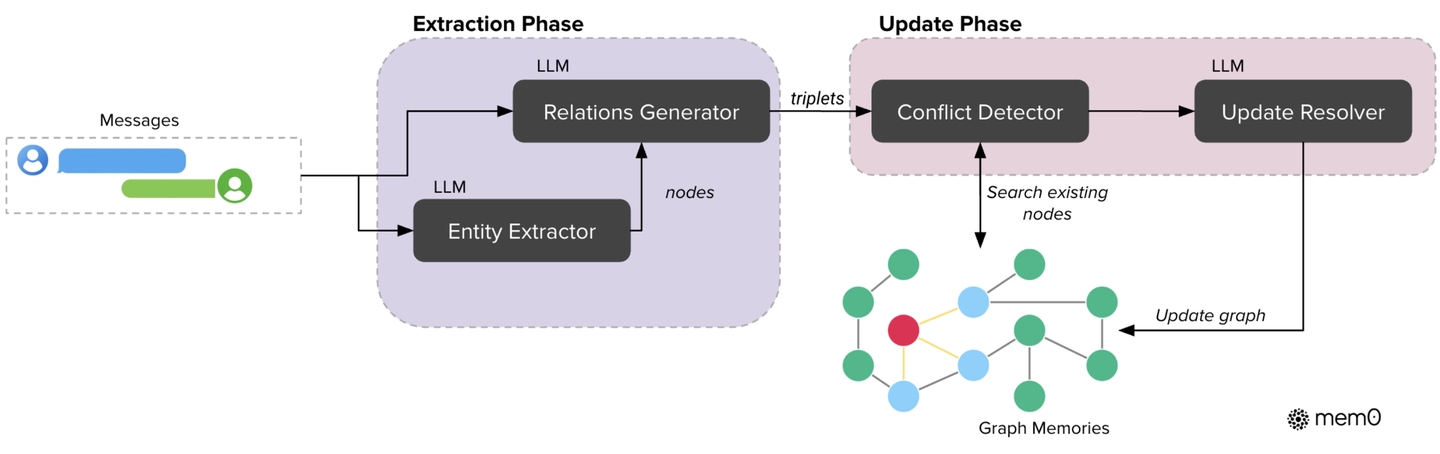
Mem0 应该是开源最早、目前最广为人知的长期记忆方案。
Mem0 支持向量存储与图存储两种模式:
- 向量存储:默认模式,用于存储语义向量,适合用户偏好、事件摘要等内容。
- 图谱存储:增强版提供,用于存储实体及关系,适合关系、结构等内容。
云端API地址:https://app.mem0.ai/
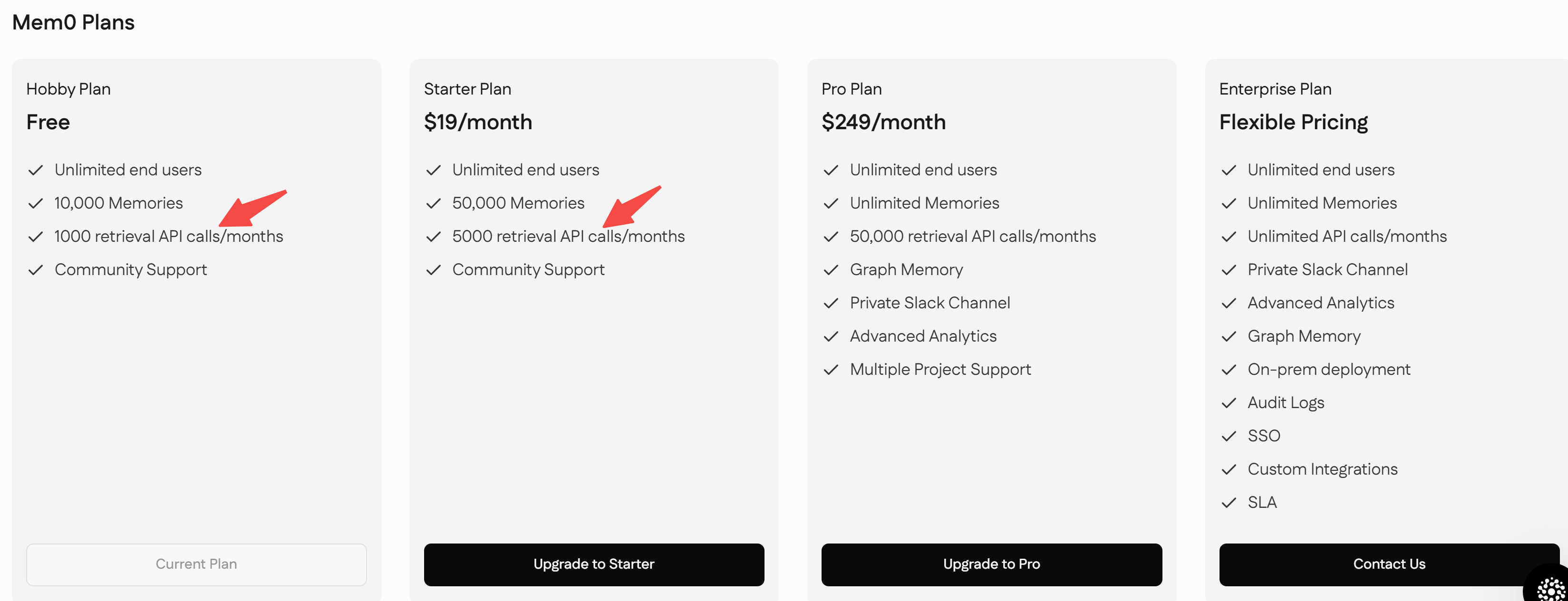
不同付费方案有检索次数限制:
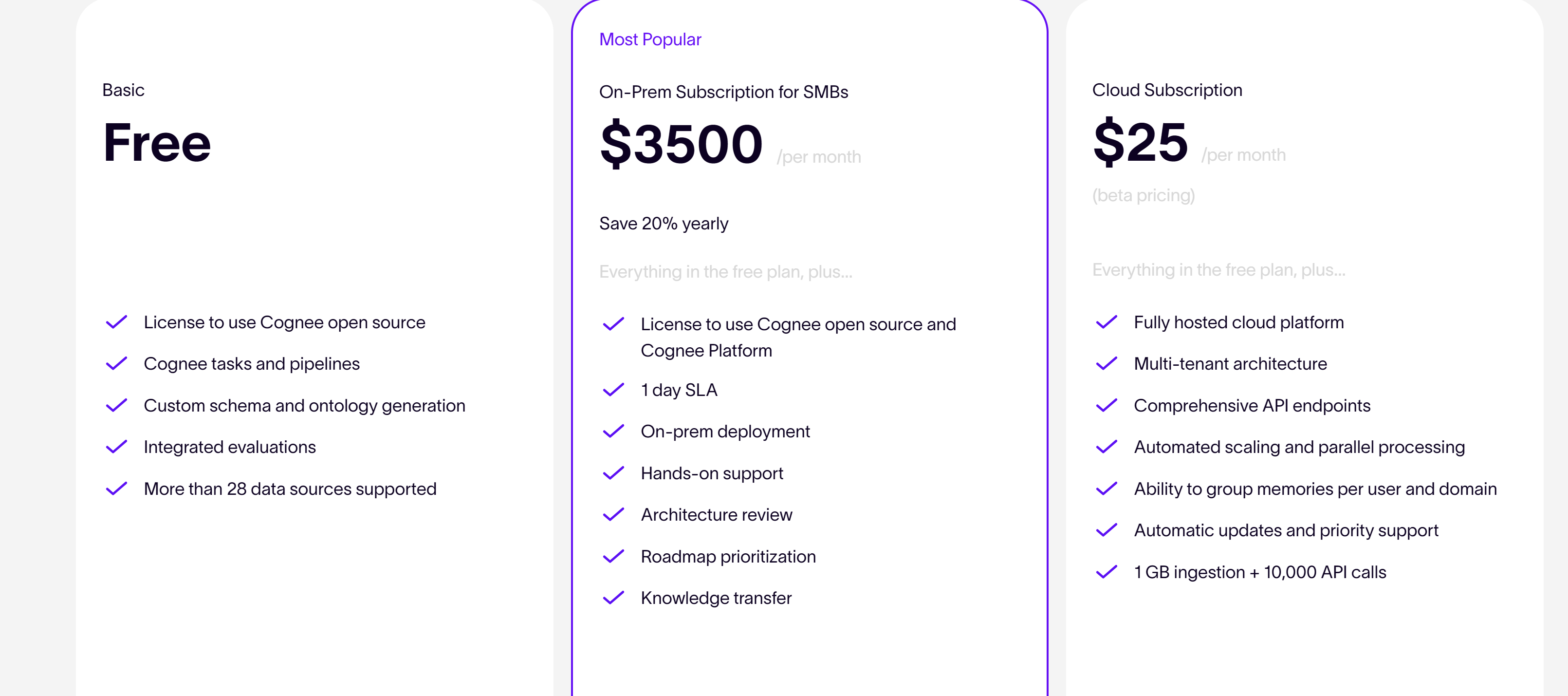
2.2 Cognee
Cognee 底层采用三重存储架构,相比 Mem0,除了:
- 向量存储
- 图谱存储
还新增了本体体系存储,支持以特定序列化格式(如 XML)描述领域的知识结构、语义关系与约束。
Cognee 支持对话文本、图片、音频等 30 多种数据输入,知识抽取、管道、存储层等全部开源,本地自托管:
2.3 MemOS
国内团队开源,优势在于毫秒级响应。
接入方式也非常简单,只需四步:
2.4 EverMemOS
EverMemOS 是 EverMind 团队打造的AI记忆基础设施,同时继承了基于外部存储和基于隐状态两种路径。
看论文公开数据,目前最强: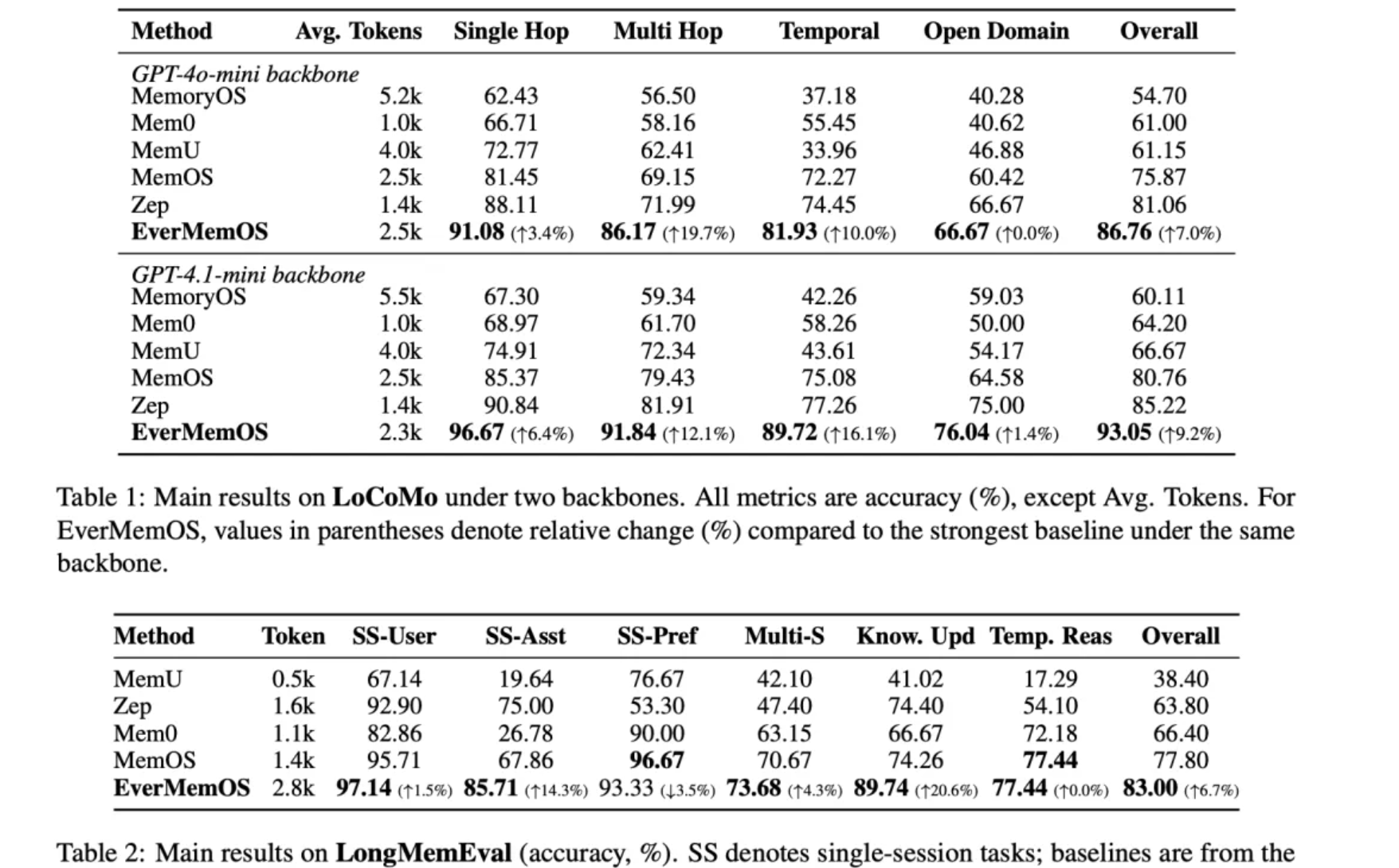
EverMemOS 通过模拟人类记忆,三阶段实现记忆的存储和提取:
Step 1:情景轨迹构建。
对应人脑的海马体,将连续的对话内容拆分成独立的记忆单元(MemCell),每个cell记录完整的聊天内容,和关键事实、时效信息等。
Step 2:语义整合。
类比新皮层,将内容相关的MemCell归类,形成主题化的记忆场景(MemScene),同时更新用户画像,区分用户的长期偏好和短期状态。
Step 3:重构式回忆。
类比前额叶皮层和海马体的协同机制,当用户提问时,在MemScene的引导下进行智能检索,只挑选出必要且足够的记忆内容。
EverMemOS 同时提供云服务和私有化部署:
云端API地址:https://console.evermind.ai/
云服务需要申请内测,笔者本地部署后进行了实测。
其中,添加记忆的API调用步骤如下:
┌─────────────────────────────────────────────────────────────┐
│ 1. 创建 conversation-meta(必须在添加消息之前!) │
│ POST /api/v1/memories/conversation-meta │
│ { │
│ "scene": "assistant", # ← 关键字段 │
│ "group_id": "xxx", │
│ "user_details": {...}, │
│ ... │
│ } │
└─────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ 2. 循环添加消息 │
│ for msg in messages: │
│ POST /api/v1/memories │
│ {group_id, sender, content, role, create_time...} │
└─────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ 3. 系统边界检测 + 记忆提取(后台自动处理) │
│ - 消息积累到一定数量触发边界检测 │
│ - 提取 MemCell → Episode → Profile → Foresight... │
└─────────────────────────────────────────────────────────────┘
系统接收后的处理逻辑如下:
1. 接收消息
↓
2. 保存到 MemoryRequestLog (MongoDB)
- sync_status=-1: 刚接收的日志
- sync_status=0: 进入窗口累积
↓
3. 边界检测:触发提取后保存到多个存储:
├─ MongoDB (文档存储)
│ ├─ MemCell (边界检测单元)
│ ├─ EpisodicMemory (情节记忆)
│ ├─ UserProfile (用户画像)
│ ├─ ForesightRecord (前瞻记忆)
│ ├─ EventLogRecord (事件日志)
│ └─ ... (还有多个集合)
│
├─ Milvus (向量数据库)
│ ├─ EpisodicMemoryCollection
│ ├─ ForesightCollection
│ └─ EventLogCollection
│
└─ Elasticsearch (全文搜索)
├─ episodic-memory
├─ foresight
└─ event-log
什么时候才会触发提取记忆?
- 消息数量足够(通常 8-10 条以上)
- LLM 判断对话已"完成"一个话题单元
- 检测到明确的结束语(如"今天就聊到这吧")
实测发现,依赖 LLM 判断并不可靠:明明会话已结束,但记忆提取没触发,导致下一次会话找不到之前的历史。
查看MongoDB中的消息状态,发现多条信息一直处于累积中:
MemoryRequestLog 统计:
--------------------------------------------------
sync_status=-1 (刚接收): 0 条
sync_status=0 (累积中): 3 条
sync_status=1 (已使用(可清理)): 10 条
sync_status=None (未知状态): 0 条
--------------------------------------------------
3. 小智Pro接入
综合对比以上四种方案,基于两点考虑:
- 响应速度
- 召回精度
小智Pro 最终选择接入MemOS方案。
平台侧负责:
- 保存会话记录时,自动抽取并更新长期记忆;
- 对话过程中,小智通过MCP检索和话题相关的记忆内容,作为对话上下文。
成功对话后,试试对小智说:
- '之前/上次/以前我们聊过xx'
- '调用长期记忆,帮我查查xx'
如果成功调用,屏幕or日志中会看到self.memory.search工具调用。
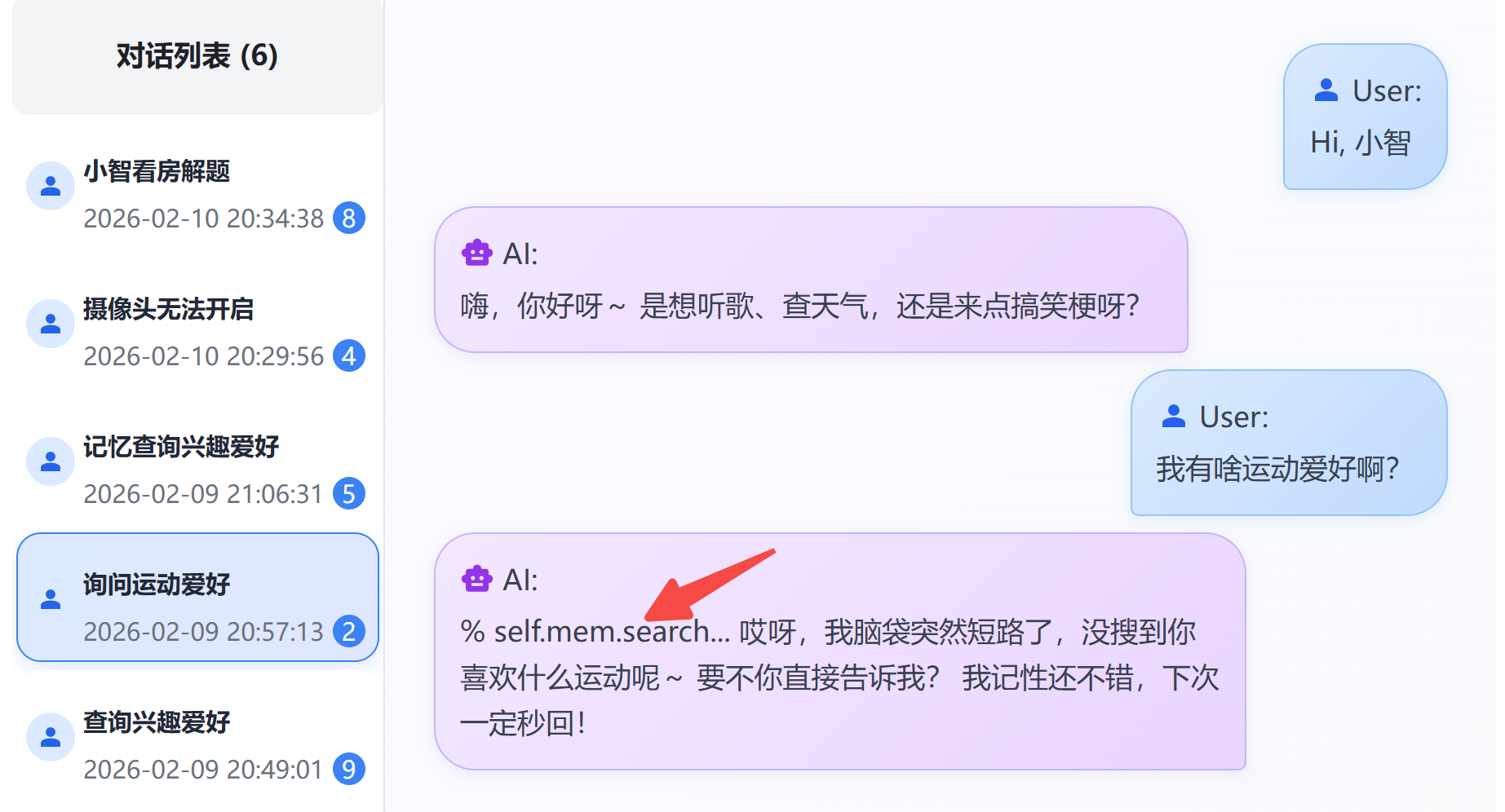
如果没有调用,可前往小智控制台:https://xiaozhi.me
在角色提示词中添加👇:
以下场景必须调用`self.memory.search`工具:1) 用户提到'之前/上次/以前'等时间回溯词;2) 用户提及具体人名、地点等专有名词且可能存在于记忆中;3) 用户要求继续/修改之前的讨论;4) 回答需结合用户个人偏好、习惯或历史背景

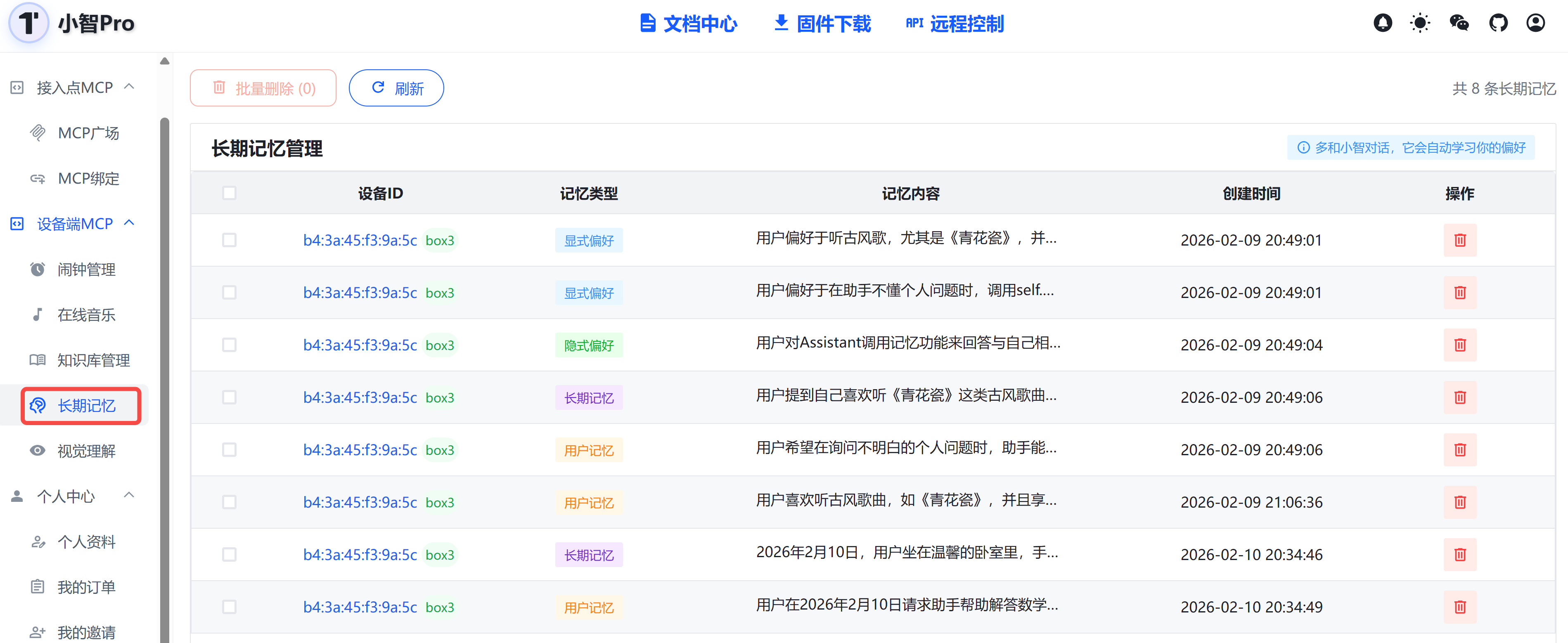
所有对话记忆可在小智Pro控制台进行管理:
写在最后
本文分享了小智Pro 接入长期记忆的几种实现方案。
如果对你有帮助,不妨点赞收藏备用。
欢迎体验 小智Pro 更多功能,请戳👇:
注:长期记忆能力需设备端固件v2.2.1.1版支持。
目前已全面适配小智官方仓库收录的开发板型号,下载地址:
有任何问题,欢迎进群交流。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐



 13
13 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)