
TileLang-Ascend“Developer模式” 开启高效新范式
它通过重组循环内的操作顺序,让不同迭代的计算与内存传输重叠执行,从而实现计算与通信的并行化。在昇腾 NPU 算子开发中,共享内存的高效利用是突破性能瓶颈的关键:一方面,昇腾 NPU 将内存划分为多个层次并存在严苛的容量上限,内存资源极度稀缺,而计算过程中需要创建大量临时缓冲区用于存储中间计算结果。TileLang-Ascend Developer模式的发布,标志着一个关键的转折点:昇腾NPU的高性
一、引言:拥抱昇腾NPU高效开发新范式
在昇腾(Ascend)NPU上开发高性能计算内核,一直是一项对专家经验要求极高的工作。开发者不仅需要精确驾驭Cube与Vector核心的异构架构,还必须手动管理复杂的内存层次与同步机制,才能充分释放硬件潜力。这一过程开发门槛高、调试复杂,严重制约了创新算法的快速实现与迭代。
为此,我们正式推出 TileLang-Ascend的“Developer模式”。这一模式旨在为算法开发者提供一套全新的高效编程范式,在保持对硬件架构的清晰感知与性能控制的同时,大幅降低编程复杂性。
“Developer模式”的核心思想是智能自动化与高级抽象。它将我们从繁重、易错的底层手工优化中解放出来——例如,不再需要手动插入每一处同步指令、精心计算每一块内存的布局与复用,或是为不同的计算核心分别编写指令。编译器将基于对昇腾NPU架构的深刻理解,自动完成大量底层优化工作。
这意味着,开发者可以将主要精力集中于算法逻辑本身与高层次的计算组织,而将性能优化的重任交给“Developer模式”。它让你以更直观、更高效的方式,编写出兼具高性能与高可维护性的Ascend NPU内核代码。
接下来,我们将深入解析这一模式如何重塑开发体验,并逐一展示其关键特性如何协同工作,共同开启昇腾NPU内核编程的新篇章。
二、 核心亮点
Developer模式致力于将开发者从复杂、易错且重复的底层硬件优化中解放出来,实现生产力与性能的双重提升。以下特性构成了Developer模式的基石:
- 硬件流水自动同步:自动在需要时插入核内及核间同步指令,确保数据一致性,开发者无需再手动管理复杂的同步标志,避免因同步遗漏导致的隐晦错误。
- 内存规划与复用:分析内核中的buffer生命周期,在片上内存(如L1、UB)中自动规划布局并重用内存空间,显著提升内存利用效率,减轻手动管理负担。
- 自动拆分CV指令:根据昇腾NPU的CV分离架构,自动将CV融合算子的复合操作拆分为C、V核上的指令,开发者无需关注这一底层细节。
- T.Pipelined原语:提供声明式的流水线编程抽象,轻松实现“计算-搬运”重叠以及跨核流水并行执行,最大化硬件利用率,显著提升吞吐量。
- T.Persistent原语:支持持久化内核执行模式,将计算任务均分到各个核上,提升整体执行效率。
- T.Parallel原语:将直观的并行循环语义(如对数据元素的并行操作)自动编译为高效的向量指令,简化数据并行编程模型,提升开发效率。
通过这些特性,Developer模式让开发者能够站在一个更高的抽象层次进行思考与编程,同时确保生成的代码具备专家级的手工优化质量,实现 “所想即所得”的高性能开发。
三、特性深度解析
3.1 硬件流水自动同步
首先我们需要理解为什么需要同步指令。昇腾 NPU芯片集成了多种硬件单元(如 Cube 计算单元、Vector 计算单元、数据搬运单元等),这些单元是异步并行工作的,如果没有正确的同步,可能会导致:
- 数据竞争:后续计算使用了未就绪的数据
- 执行乱序:指令执行顺序不符合预期依赖关系
- 结果错误:最终计算结果不可预测
在自动同步特性出现前,开发者需要手动管理所有同步点,这可能会带来几个问题:
- 容易遗漏:复杂的计算图中可能漏掉关键同步点
- 过度同步:保守地插入过多同步,影响性能
- 死锁风险:错误的标志等待顺序导致死锁
- 代码冗长:同步代码可能占内核代码的30%以上
硬件流水自动同步特性解决昇腾 NPU 算子开发中手动插入同步指令的痛点,通过自动化分析实现同步指令的精准生成,兼顾算子正确性与运行性能。
使用示例:
设计思路拆解:
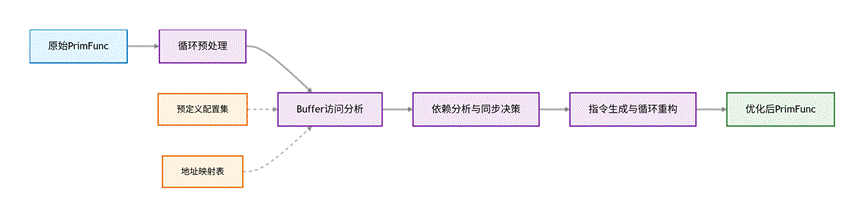
•循环预处理:将嵌套的 For 循环展开并标记迭代区间,把复杂的循环结构转化为线性的语句序列,方便后续逐句分析数据依赖。
•Buffer 访问分析:解析每一条语句对 Buffer 的操作(读 / 写),结合预定义配置集(如 copy/gemm 等操作与硬件 Pipeline 的映射关系),确定操作所属的硬件流水线(MTE1/MTE2/V 等)。通过地址映射表关联 Buffer 的物理地址,为相同地址不同名称的buffer间数据依赖检测提供依据。
•依赖分析与同步决策:对比当前语句与历史访问记录,基于物理地址和读写类型,识别 RAW(写后读)、WAW(写后写)、WAR(读后写)三类数据依赖。根据依赖关系和硬件特性,决策同步类型:同流水线用PipeBarrier,跨流水线用EventPair(SetFlag/WaitFlag),并通过同步图优化剔除冗余指令。
•指令生成与循环重构:生成同步指令插入到代码中,确保数据依赖的正确同步。将展开后的循环重构为原始嵌套结构,保证代码结构完整性。
3.2 内存规划与复用
在昇腾 NPU 算子开发中,共享内存的高效利用是突破性能瓶颈的关键:一方面,昇腾 NPU 将内存划分为多个层次并存在严苛的容量上限,内存资源极度稀缺,而计算过程中需要创建大量临时缓冲区用于存储中间计算结果。
传统的手动内存规划会存在核心痛点:
- 开发效率极低:需人工计算 L1/L0C/UB 等层级下每个 Buffer 的 Offset,维度 /dtype 变更需全量重算,迭代成本高
- 易出错且难调试:人工计算易出现地址重叠、32 字节对齐错误,触发 NPU 内存超限 / 执行异常,定位问题需逐行核对 Offset
- 硬件适配性差:昇腾不同内存层级有独立上限,不同型号内存规格也不相同,人工难以精准适配所有约束规则
由此Developer模式带来了内存规划与复用特性,它完全替代人工 Offset 计算,开发效率显著提升,维度 / 类型变更无需手动适配。自动规避地址重叠、对齐错误,消除内存超限 / 执行异常的人为因素。自动考虑内存复用降低总占用率 ,最大化利用昇腾 NPU 有限的共享内存资源。address_map固化到函数属性,可追溯、可调试,适配多版本昇腾硬件
使用示例: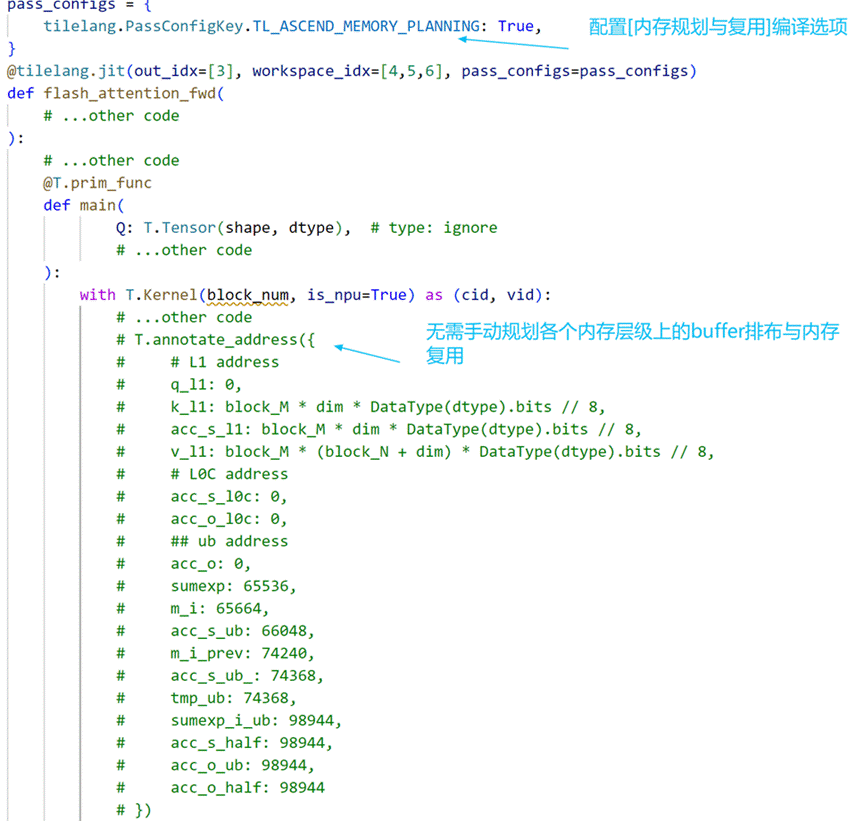
设计思路拆解:
该特性 是面向昇腾 NPU 的核心内存优化组件,通过精准的缓冲区生命周期分析与高效的线性扫描内存分配算法,为每个buffer分配内存空间,提高昇腾 NPU 内存利用率。

缓冲区生命周期分析
- 遍历 TIR 抽象语法树(AST),全量采集昇腾 NPU 共享内存缓冲区的访问行为;
- 标记每个缓冲区的 GEN(生成)/KILL(销毁)事件,精准界定其活跃区间 [start, end](首次使用→最后一次使用的执行阶段);
- 按昇腾硬件内存域分组缓冲区,适配不同分区的内存上限约束。
线性扫描分配算法
- 按活跃区间起始位置排序缓冲区,构建线性执行序列;
- 维护活跃队列与空闲内存块池,循环处理每个缓冲区的分配需求;
- 智能分配策略:优先复用已释放的空闲内存块,无可用块时分配新内存,所有操作遵循 32 字节硬件对齐规则;
- 最终生成缓冲区到物理地址 Offset 的映射表(address_map),固化到函数属性指导执行。
3.3 自动拆分CV指令
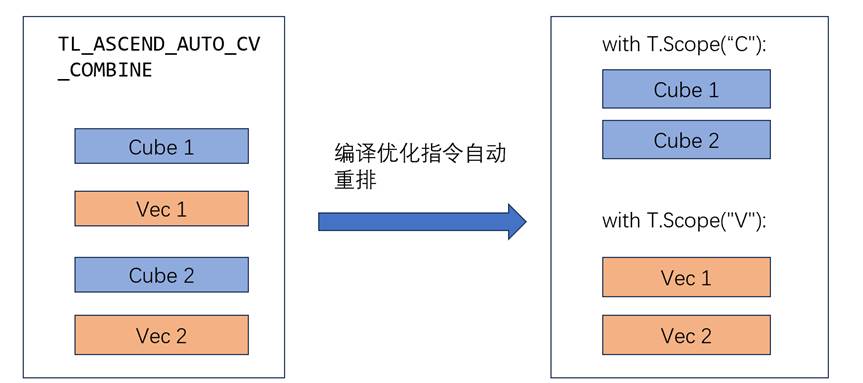
在传统的Ascend NPU编程中,开发者面临着一种非自然的编程约束。由于硬件架构的CV分离特性,开发者必须在代码中明确标注每段代码属于Cube还是Vector单元,这种显式作用域声明带来了几个问题:
- 思维割裂:算法逻辑被人为切割成两个独立的代码块,破坏了算法的自然连贯性
- 频繁切换:在复杂的算法中,CV之间的交互可能很频繁,导致代码结构支离破碎
- 代码结构的重复:由于Cube和Vector代码必须分开编写,许多控制结构不得不重复出现。修改算法时需要在两个地方做相同的更改,稍有不慎就会导致两个循环不同步
- 调试困难:当算法出现问题时,需要在两个独立的代码块间来回排查
例如在Flash Attention这样的复杂算子中,这种分割变得尤为痛苦。注意力机制中的softmax计算,前半部分在Cube单元进行矩阵乘法,后半部分在Vector单元进行归一化,但数学上这是一个连续的过程。人工拆分就像把一句话从中间截断,用两种不同的语言说出来。
正是为了解决这些问题,CV代码分离优化Pass应运而生。它的核心理念是:让开发者专注于算法逻辑,让编译器处理硬件适配。开发者按算法逻辑自然编写代码,Pass自动识别哪些操作属于Cube,哪些属于Vector。
3.4 T.Pipelined原语
在深度学习和高性能计算中,计算密集型任务(如矩阵乘法、卷积等)往往面临内存墙问题——计算单元因等待数据加载而频繁空闲,导致硬件利用率低下。传统的串行执行模式无法充分利用现代AI加速器的多层次内存架构和多样化的功能单元(矩阵计算、向量计算、内存传输单元)。如何让这些硬件资源并行工作,有效隐藏内存访问延迟,成为提升系统性能的关键挑战。
软件流水线技术正是为解决这一难题而生。它通过重组循环内的操作顺序,让不同迭代的计算与内存传输重叠执行,从而实现计算与通信的并行化。然而,手动实现软件流水线不仅复杂且容易出错,还需针对不同代码进行重复设计,严重影响了开发效率和代码可移植性。
T.Pipelined原语提供了一套完整的自动化软件流水线解决方案,通过简洁的编程接口和强大的编译器优化,让开发者能够轻松实现高性能的流水线并行。使用示例:
原始执行顺序:
使用pipeline后执行顺序:

通过Pipelined原语,开发者只需关注算法逻辑,编译器即可自动生成高度优化的流水线并行代码,在AI加速器上获得显著的性能提升。
设计思路拆解: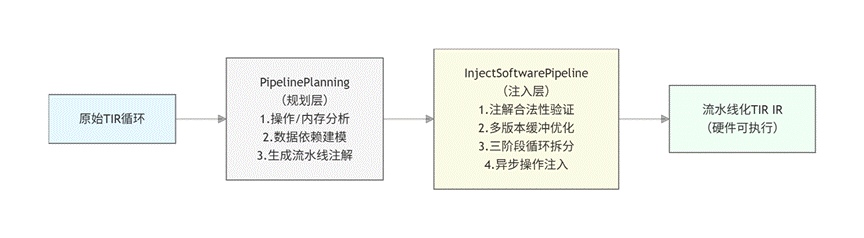
PipelinePlanning(规划层):深度解析循环内操作类型(拷贝 / 计算)与数据依赖关系,基于依赖合法性原则为每个操作分配流水线阶段与执行顺序,最终生成标准化注解,为后续提供清晰的调度依据。
InjectSoftwarePipeline(注入层):先验证注解的合法性以规避数据冲突风险;再通过多版本buffer解耦数据,三阶段拆分(Prologue、Body、Epilogue),最终将抽象注解转化为硬件可执行的流水线化 IR。
3.5 T.Persistent原语
Persistent在NPU上实现持久化内核调度原语,通过一次内核启动连续处理多个工作项,消除重复的内核启动/停止开销负载均衡保证:适应任意任务规模:任务数可大于、等于或小于核心数

3.6 T.Parallel原语
在 TileLang 的编程模型中,T.Parallel是用于表达 tile 内元素向量化计算 的核心原语。它在 IR 层以“并行循环”的形式描述数据并行,而不直接暴露底层硬件指令细节,极大的提升用户的算子编程体验。
目前已支持的运算场景
支持的双目运算符、支持的单目运算符、多运算场景、1D / 2D 场景、双目“向量 + 标量”场景、行切分场景、Buffer + 标量广播运算、拷贝场景。
使用示例:

四、结语:重新定义NPU开发体验
TileLang-Ascend Developer模式的发布,标志着一个关键的转折点:昇腾NPU的高性能编程,正从一门高度依赖专家手工“雕琢”的技艺,演进为一项依托智能工具链、聚焦算法创新的高效工程实践。
其核心价值,不在于单个特性的炫技,而在于它们共同构建的一套全新协作范式。这套范式将开发者从底层硬件的复杂性与重复性劳动中解放,使其角色从“硬件翻译官”回归为“算法架构师”。我们不再需要亲自管理每一处同步、规划每一块内存、拆分每一组指令,而是通过高级原语声明计算意图,由编译器这个“内置专家”将其转化为高度优化的硬件指令。开发者与硬件之间,不再是繁琐的、易错的、一对一的直接操控,而是通过一个强大的、可靠的抽象层进行高效对话。
这带来的深远影响是双向的:
- 对开发者而言,开发门槛被显著降低,迭代速度得以提升。更多算法研究人员和工程团队能够将其创新想法快速、高效地在昇腾NPU上实现和验证,极大地释放了创新潜能。调试和维护的复杂度也大幅下降,让开发者的心智聚焦于真正创造价值的逻辑。
- 对昇腾硬件与生态而言,更友好、更高效的编程模型是释放其顶尖算力的关键一环。Developer模式让硬件的卓越性能变得更易于获取,从而吸引更广泛的开发者社群,构建更繁荣的软件应用生态,形成“强大硬件 → 高效工具 → 丰富应用”的良性循环。
我们并非用黑箱魔法取代深度优化,而是通过可靠的自动化,将专家经验产品化、普惠化。Developer模式是TileLang-Ascend为致力于成为昇腾NPU“性能与效率最佳平衡点”这一目标的坚实一步。
我们诚挚邀请每一位在AI算力前沿探索的开发者,立即尝试TileLang-Ascend Developer模式,体验这种“专注于算法,收效于性能”的全新开发流程。您的实践、反馈与共建,将共同推动这一范式不断成熟,助力昇腾计算生态迈向更加高效、开放与繁荣的未来。
CANN开源社区tilelang链接:https://gitcode.com/cann/cann-recipes-infer/tree/master/ops/tilelang
Tilelang-Ascend开源社区链接:https://github.com/tile-ai/tilelang-ascend

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐
 19
19 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)