
魔搭evalscope模型昇腾NPU评测流程汇总
在人工智能模型开发与部署过程中,模型评测是验证模型性能、精度及可靠性的关键环节。随着昇腾计算设备在AI计算中的广泛应用,开发者常需将训练好的模型迁移至NPU平台进行推理加速与效能验证。本文系统介绍在昇腾NPU硬件环境下,使用魔搭EvalScope框架开展多维度模型评测的完整流程,涵盖环境配置、多种评测后端工具的使用、结果可视化及性能压测方法,旨在为开发者提供一套可复现的标准化评测方案。
作者:昇腾实战派
背景概述
在人工智能模型开发与部署过程中,模型评测是验证模型性能、精度及可靠性的关键环节。随着昇腾计算设备在AI计算中的广泛应用,开发者常需将训练好的模型迁移至NPU平台进行推理加速与效能验证。本文系统介绍在昇腾NPU硬件环境下,使用魔搭EvalScope框架开展多维度模型评测的完整流程,涵盖环境配置、多种评测后端工具的使用、结果可视化及性能压测方法,旨在为开发者提供一套可复现的标准化评测方案。
硬件与软件环境
- 硬件信息:
- 服务器型号:Atlas 800I A2推理服务器
- 软件信息:
- 操作系统内核:OpenEuler 22.03 SP3
- Python版本:3.10
- PyTorch及torch_npu版本:2.6.0
- CANN版本:8.2.RC1
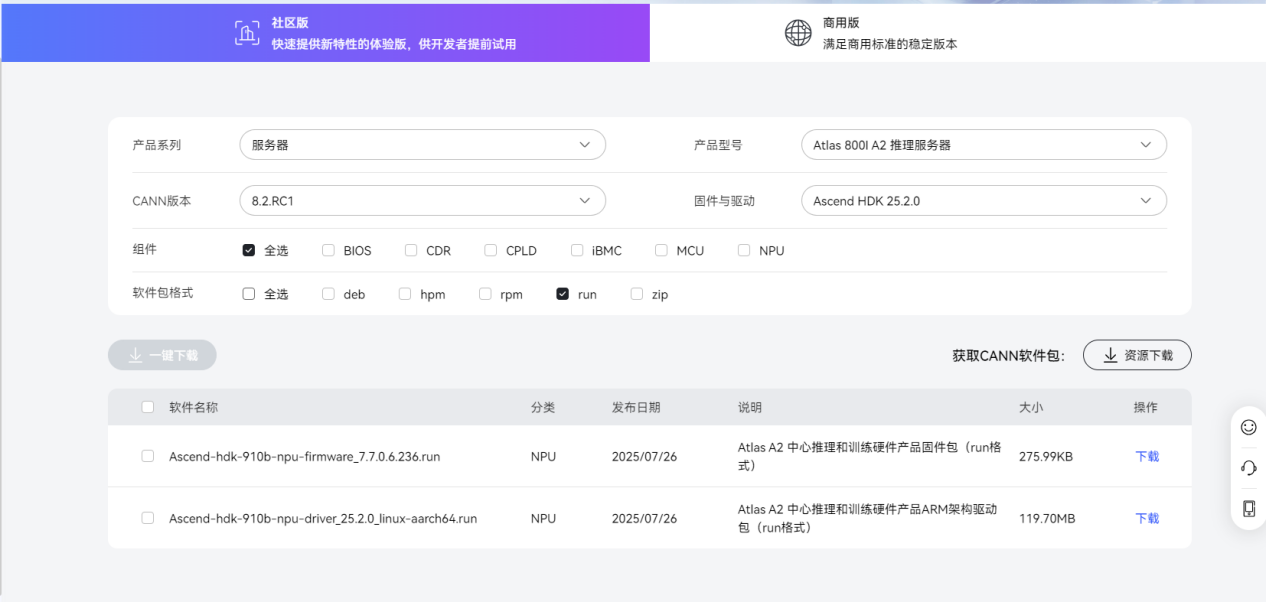
NPU驱动与固件安装
1. 安装驱动和固件
Tips:
- 如果报错内核文件缺失,需要执行
yum install kernel-source - 注意npu卡型号版本需要匹配
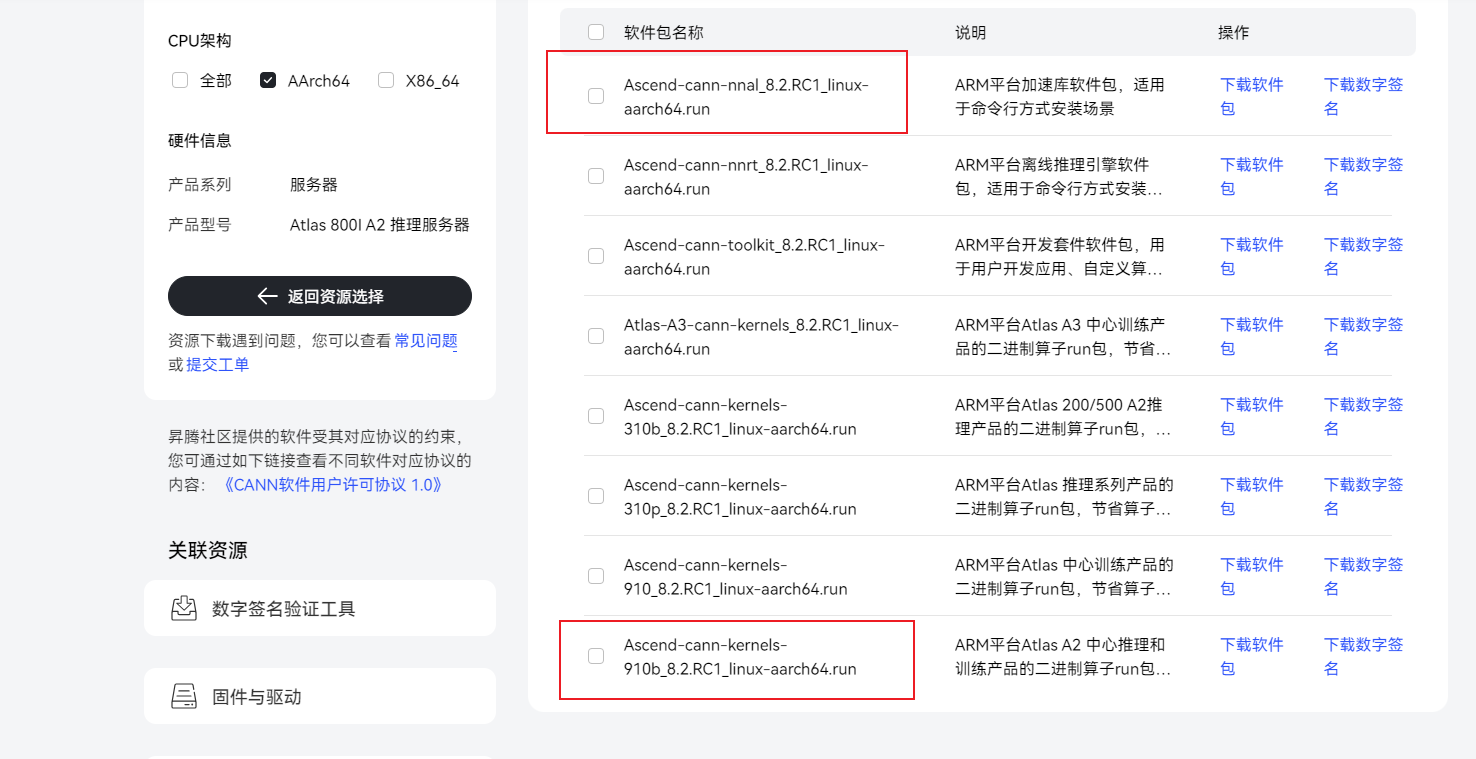
2. 安装cann以及二进制算子包
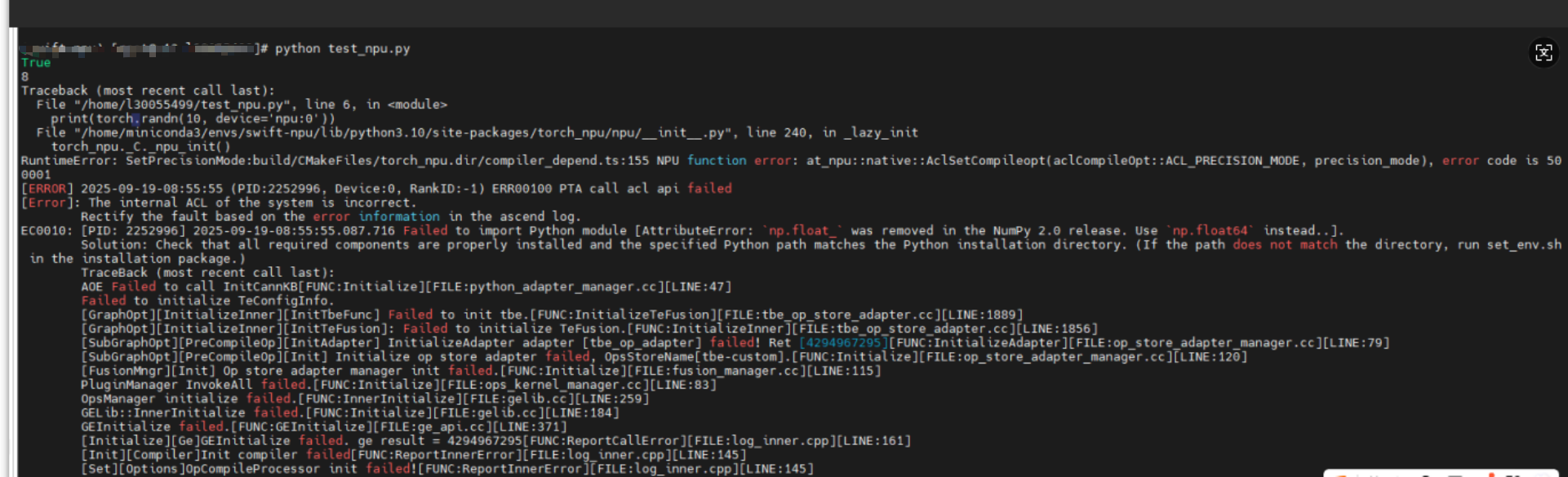
安装完成后测试环境是否安装正确,NPU能否被正常加载:
from transformers.utils import is_torch_npu_available
import torch
print(is_torch_npu_available()) # True
print(torch.npu.device_count()) # 8
print(torch.randn(10, device='npu:0'))
Tips:如果调用npu失败,检测cann二进制算子包是否安装

如果报错 NumPy 版本不匹配,尝试降级 NumPy 版本,例如pip install numpy==1.21.6
模型评测
推荐使用虚拟环境,需要安装conda 环境安装参考:https://modelscope.cn/docs/model-evaluation/get-started/installation
1. 使用evalscope native框架进行模型评测
参考文档:https://modelscope.cn/docs/model-evaluation/get-started/basic-usage
使用命令行进行评测:
evalscope eval \ --model Qwen/Qwen2.5-0.5B-Instruct \ --datasets gsm8k arc \ --limit 5
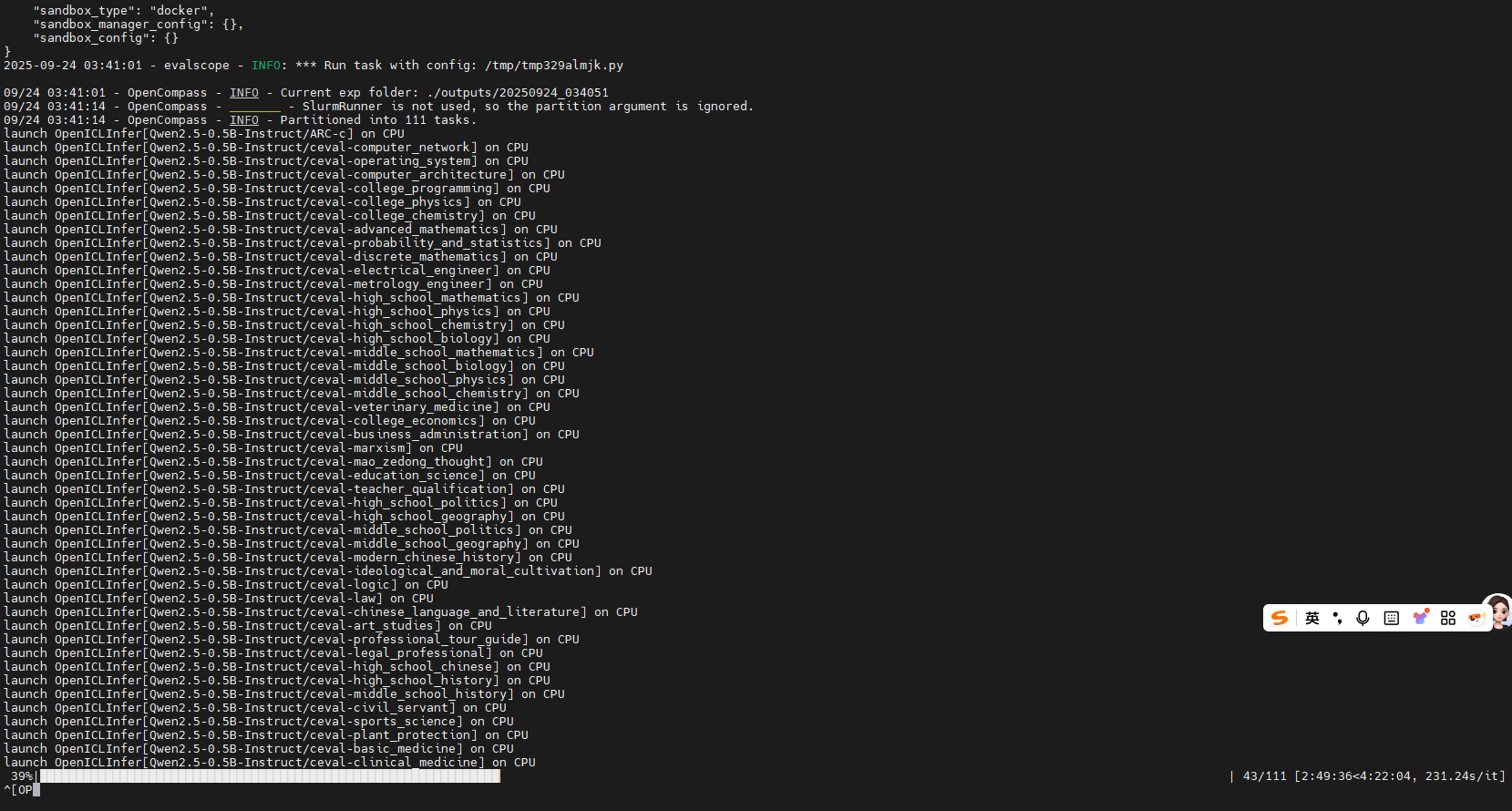
2. 使用opencompass进行模型评测
参考文档:
- https://modelscope.cn/docs/model-evaluation/user-guides/backend/opencompass-backend
- https://modelscope.cn/docs/llm-training-and-inference/best-practices/npu
评测示例: 使用ms-swift在npu0上部署模型:
ASCEND_RT_VISIBLE_DEVICES=0 swift deploy --model Qwen/Qwen2-7B-Instruct --max_new_tokens 2048
- 使用yaml传递评测参数并调用评测脚本
3. 使用VLMEvalKit进行模型评测
使用参考: https://modelscope.cn/docs/model-evaluation/user-guides/backend/vlmevalkit-backend
评测示例:
- 使用ms-swift在npu0上部署模型:
ASCEND_RT_VISIBLE_DEVICES=0 swift deploy --model Qwen/Qwen2.5-0.5B-Instruct --max_new_tokens 1024 - 使用yaml传递评测参数并调用评测脚本
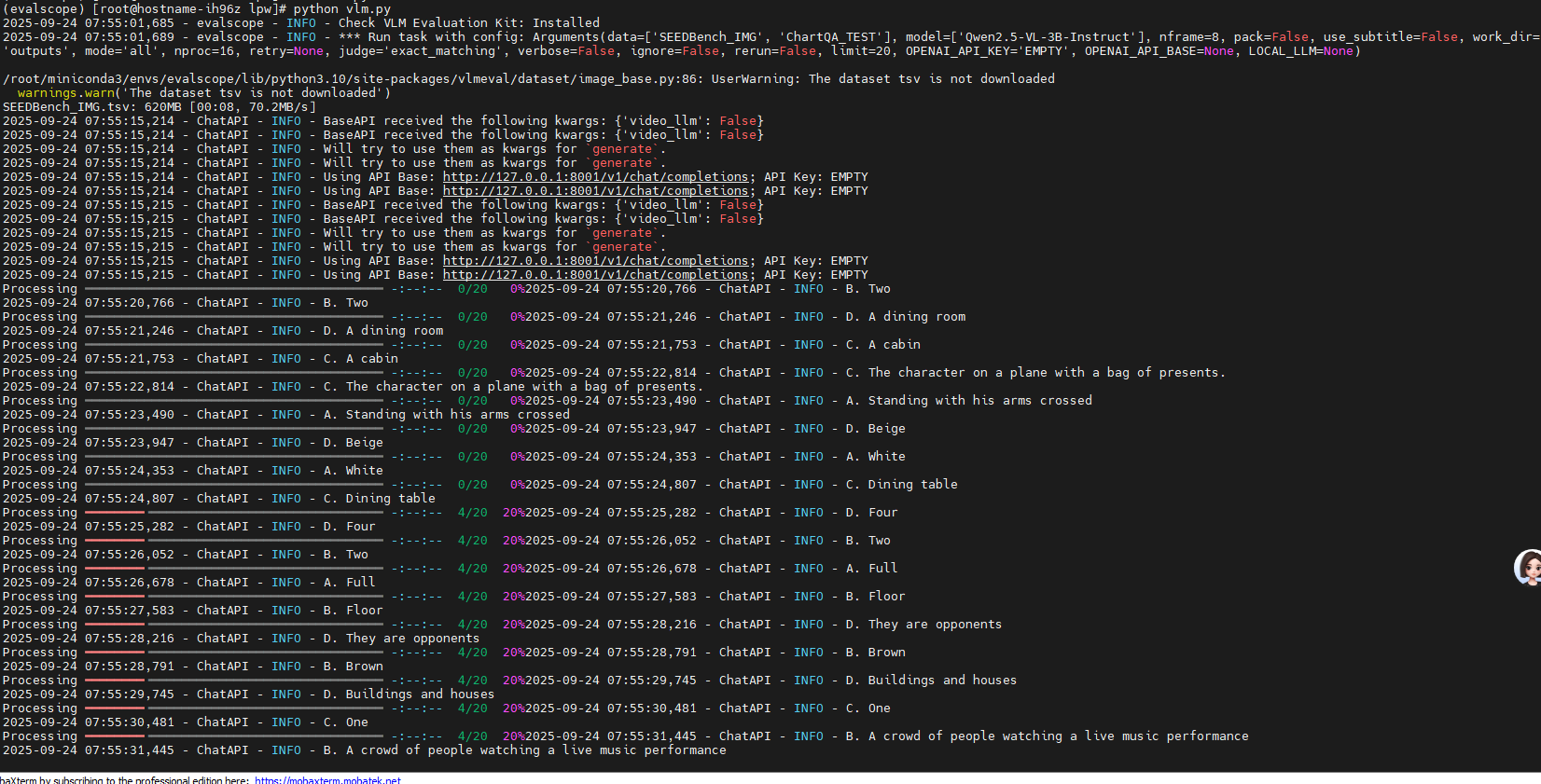
4. 使用RAG eval进行评测
CMTEB
参考文档:https://www.modelscope.cn/docs/model-evaluation/user-guides/backend/rageval-backend/mteb
CLIP Benchmark
参考文档: https://www.modelscope.cn/docs/model-evaluation/user-guides/backend/rageval-backend/clip-benchmark
5. 使用第三方工具τ-bench进行评测
参考文档:https://modelscope.cn/docs/model-evaluation/third-party/tau-bench
6. 使用第三方工具BFCL-v3进行评测
参考文档:https://modelscope.cn/docs/model-evaluation/third-party/bfcl-v3
Tips:如果评测过程报错,尝试排查模型是否支持函数调用,将脚本中的"is_fc_model"改为false
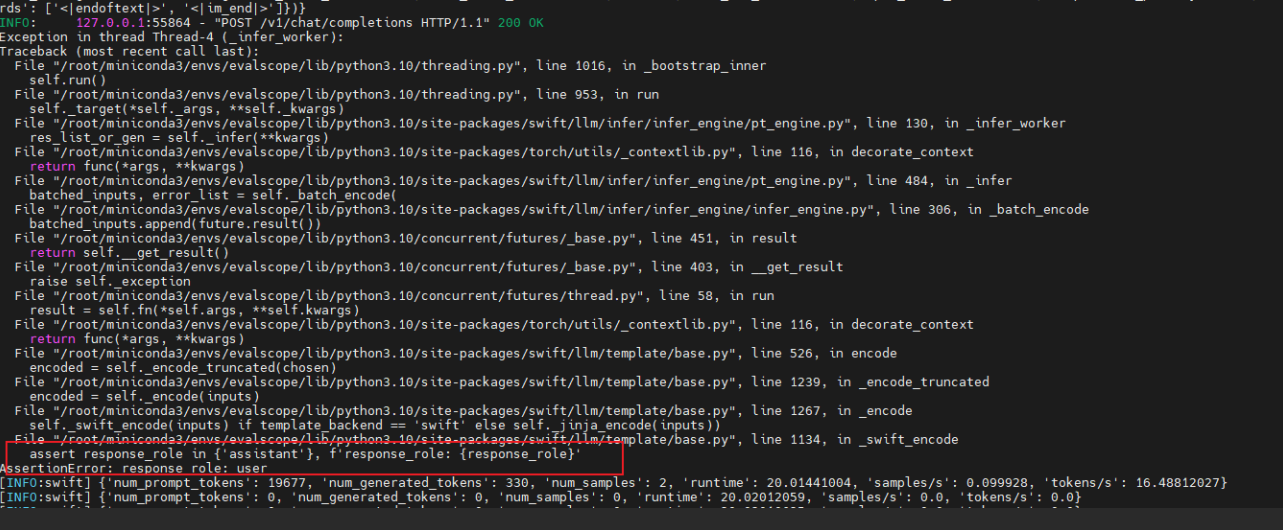
7. 使用第三方工具大海捞针测试
参考文档:https://modelscope.cn/docs/model-evaluation/third-party/needle-haystack
8. 使用第三方工具ToolBench测试
参考文档:https://modelscope.cn/docs/model-evaluation/third-party/toolbench
9. 使用第三方工具LongBench-Write测试
参考文档:https://modelscope.cn/docs/model-evaluation/third-party/longwriter
10.竞技场模式
参考文档:https://www.modelscope.cn/docs/model-evaluation/user-guides/arena 先部署需要PK的模型(以qwen2.5-7b和qwen2.5-0.5b为例),得到推理结果后再进行PK
Tips:如果报错缺少NLTKd 资源导致计算指标出错,需要下载NTLK资源,如果网络下载仍然有问题,需要手动安装所需的 NLTK 数据:
- 创建 NLTK 数据目录
mkdir -p /root/nltk_data/tokenizers
-
手动下载并安装所需数据
- 下载 punkt_tab 数据。
wget https://raw.githubusercontent.com/nltk/nltk_data/gh-pages/packages/tokenizers/punkt_tab.zip -O /root/nltk_data/tokenizers/punkt_tab.zip - 下载 punkt 数据。
wget https://raw.githubusercontent.com/nltk/nltk_data/gh-pages/packages/tokenizers/punkt.zip -O /root/nltk_data/tokenizers/punkt.zip
- 下载 punkt_tab 数据。
-
解压数据
unzip /root/nltk_data/tokenizers/punkt_tab.zip -d /root/nltk_data/tokenizers/ unzip /root/nltk_data/tokenizers/punkt.zip -d /root/nltk_data/tokenizers/ -
清理压缩文件
rm /root/nltk_data/tokenizers/*.zip -
在代码中设置 NLTK 数据路径
import nltk nltk.data.path.append('/root/nltk_data')
测评结果可视化
参考文档:https://modelscope.cn/docs/model-evaluation/get-started/visualization
使用示例:
evalscope app --outputs outputs/20250929_032223/
浏览器输入对应服务器IP即可查看可视化结果
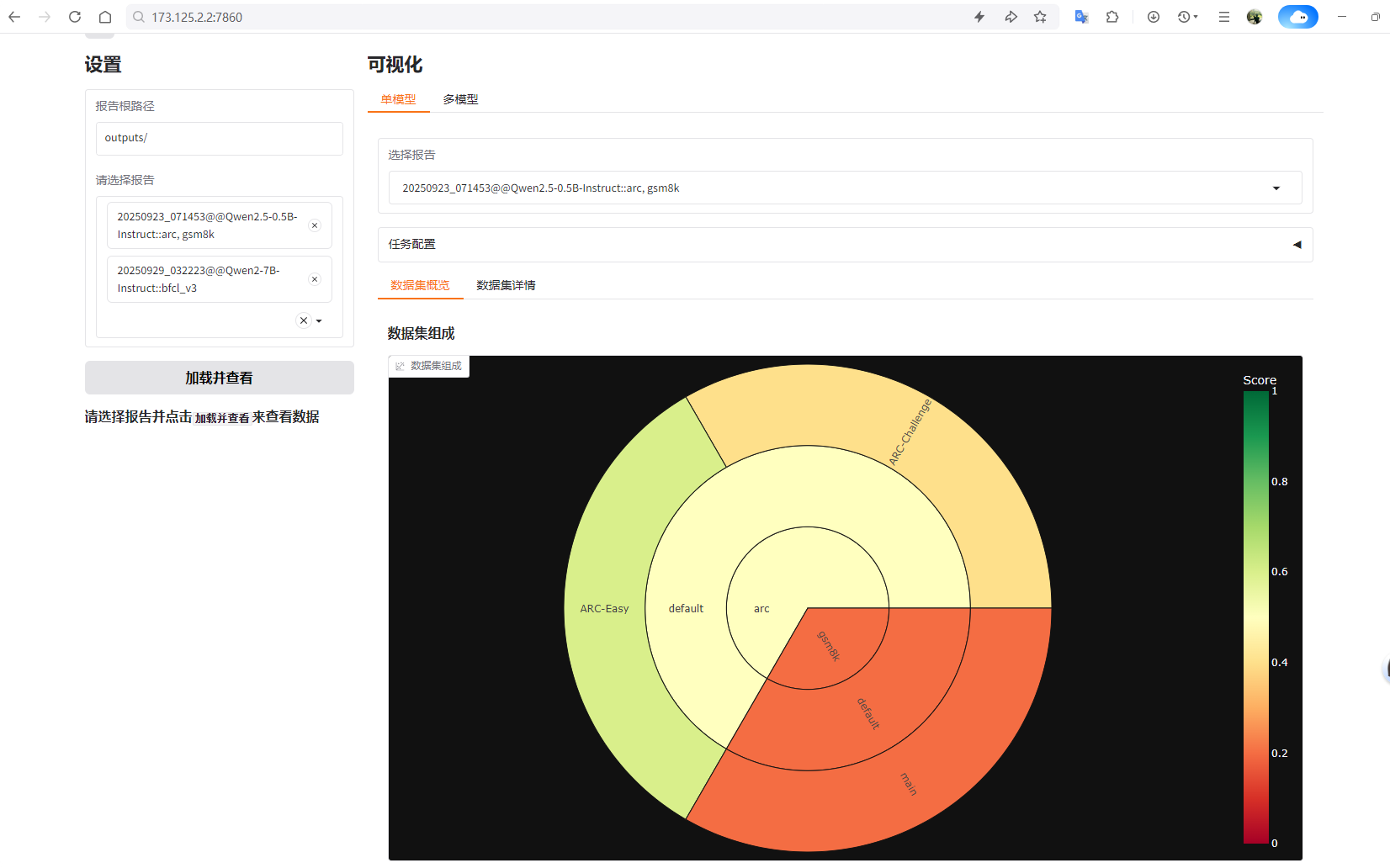
Tips: 如果浏览器访问失败,可尝试关闭防火墙,允许对应端口访问
- 允许7860端口访问。
sudo firewall-cmd --add-port=7860/tcp --permanent - 重新加载规则。
sudo firewall-cmd --reload
模型推理性能压测
参考文档:https://modelscope.cn/docs/model-evaluation/user-guides/stress-test/quick-start
- 部署模型
ASCEND_RT_VISIBLE_DEVICES=0 swift deploy --model Qwen/Qwen2.5-0.5B-Instruct --max_new_tokens 1024
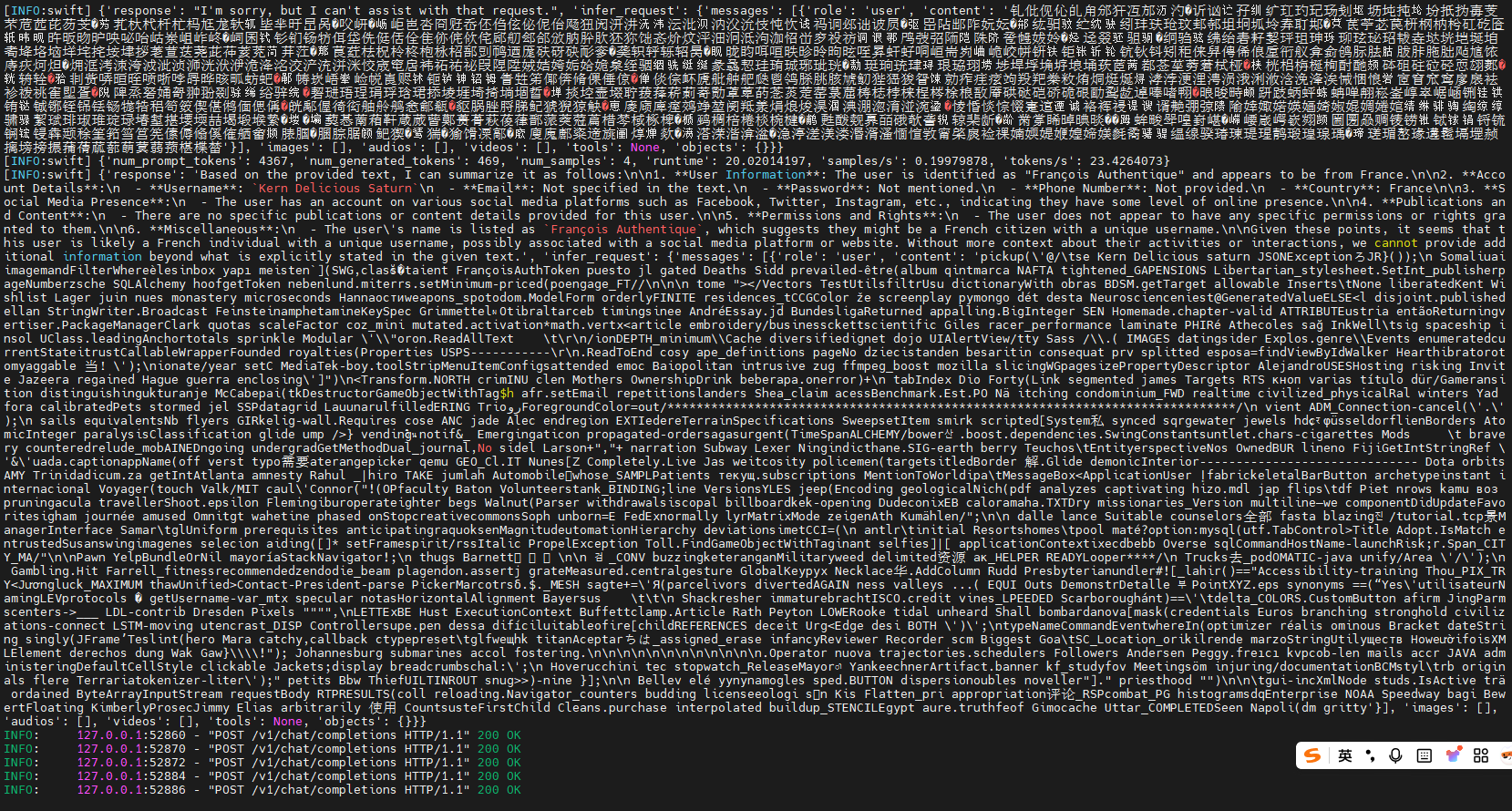
2. 使用命令行进行测试:
evalscope perf \
--parallel 1 10 50 100 200 \
--number 10 20 100 200 400 \
--model Qwen2.5-0.5B-Instruct \
--url http://127.0.0.1:8801/v1/chat/completions \
--api openai \
--dataset random \
--max-tokens 1024 \
--min-tokens 1024 \
--prefix-length 0 \
--min-prompt-length 1024 \
--max-prompt-length 1024 \
--tokenizer-path Qwen/Qwen2.5-0.5B-Instruct \
--extra-args '{"ignore_eos": true}'
作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)