
教育与科研的新基座:使用 CANN 构建高效费比的深度学习实验平台
目标: 指导学生为一个特殊的激活函数(如 Swish 激活函数) 开发一个自定义的昇腾 NPU 算子。# GM 区输入 / 输出# UB 缓冲区numel = prod(shape) # 元素个数burst = numel // 16 # 简单按 16 对齐,真实工程需按 shape 计算# 1) 把 x 从 GM 搬到 UB# 2) 计算 sigmoid(x) = 1 / (1 + exp(-x
特此声明:本文系原创测评体验,全程无任何广告植入及商业利益关联。内容旨在分享真实使用感受,为您的决策提供中立参考。产品效果因人而异,请理性看待。感谢理解!
一、引言:高校 AI 实验室的三座大山
在人工智能已成为核心竞争力的今天,为学生开设高质量的深度学习课程、为科研人员提供强大的计算平台,已成为高校的标配。然而,在实践中,许多高校实验室正面临着三座大山的困扰:成本高昂、环境分裂、黑盒化教学。如何构建一个性价比高、开发与运行环境一致、且能支持底层原理探索的深度学习实验平台?本文将提出一个创新方案,阐述如何基于华为昇腾 CANN 生态,打造一个能够有效解决上述痛点的新一代教学科研平台。
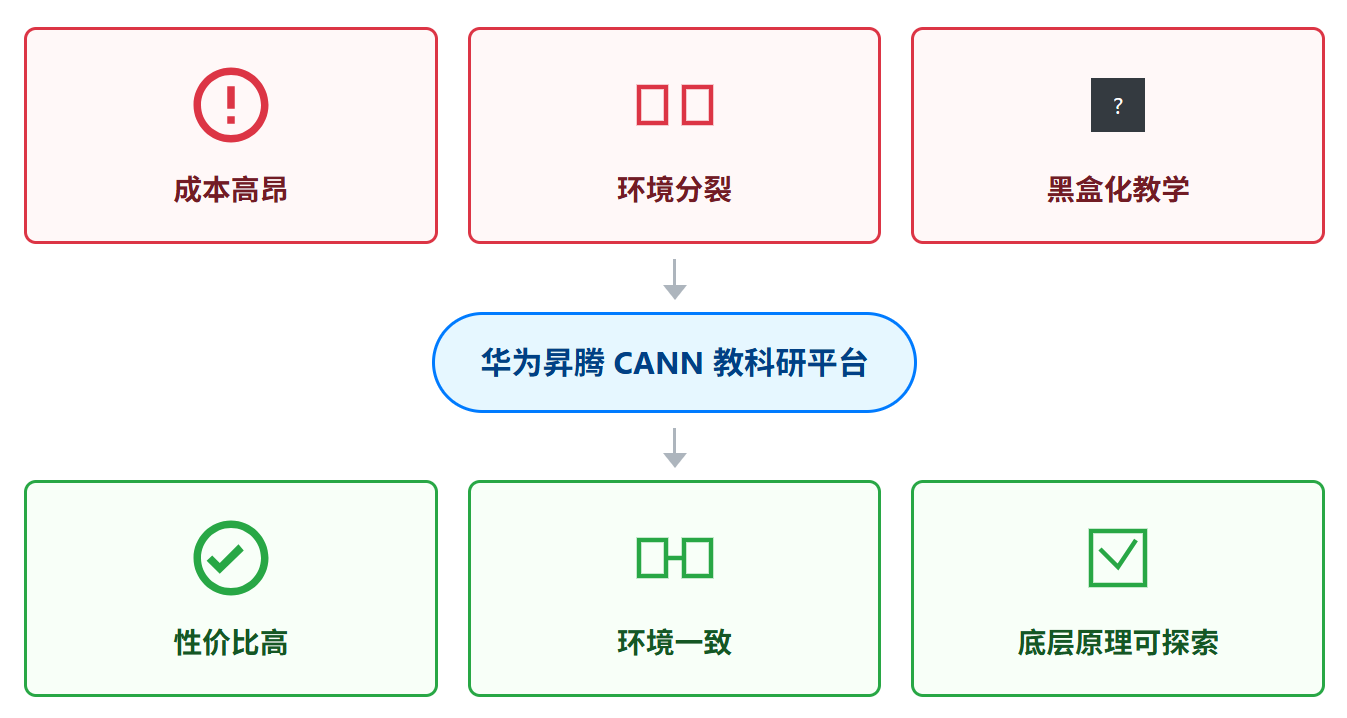
二、CANN 的独特价值:为教学科研量身定制
对于教育和科研场景,CANN 带来的价值远不止于性能。
| 教学科研痛点 | CANN 解决方案 | 核心优势 |
|---|---|---|
| 生均算力不足 | 提供从边缘 (Atlas 200) 到中心 (Atlas 800) 的全系列硬件,费效比高。 | 学生可在低成本的边缘设备上完成大量开发和推理实验,只在必要时使用中心服务器进行大规模训练。 |
| 环境分裂与不一致 | 端云协同的统一架构,CANN 软件栈在所有昇腾硬件上保持一致。 | 模型和代码在边缘端和云端之间可以“零修改”迁移,保证了实验的可复现性。 |
| 黑盒化教学 | 开放的算子开发与图优化能力,工具链透明。 | 学生不仅能用,还能深入到底层进行自定义算子开发和性能调优,真正理解 AI 。 |
| 科研创新受限 | 提供原生 AscendCL 接口,支持非 Python 语言(如 C++)开发高性能应用。 | 科研人员可摆脱框架束缚,直接控制硬件,实现更底层的算法创新和性能压榨。 |
三、实验平台架构:Atlas 边缘 + 中心服务器的混合部署
我们构想的实验平台是一个混合云/边缘的架构。
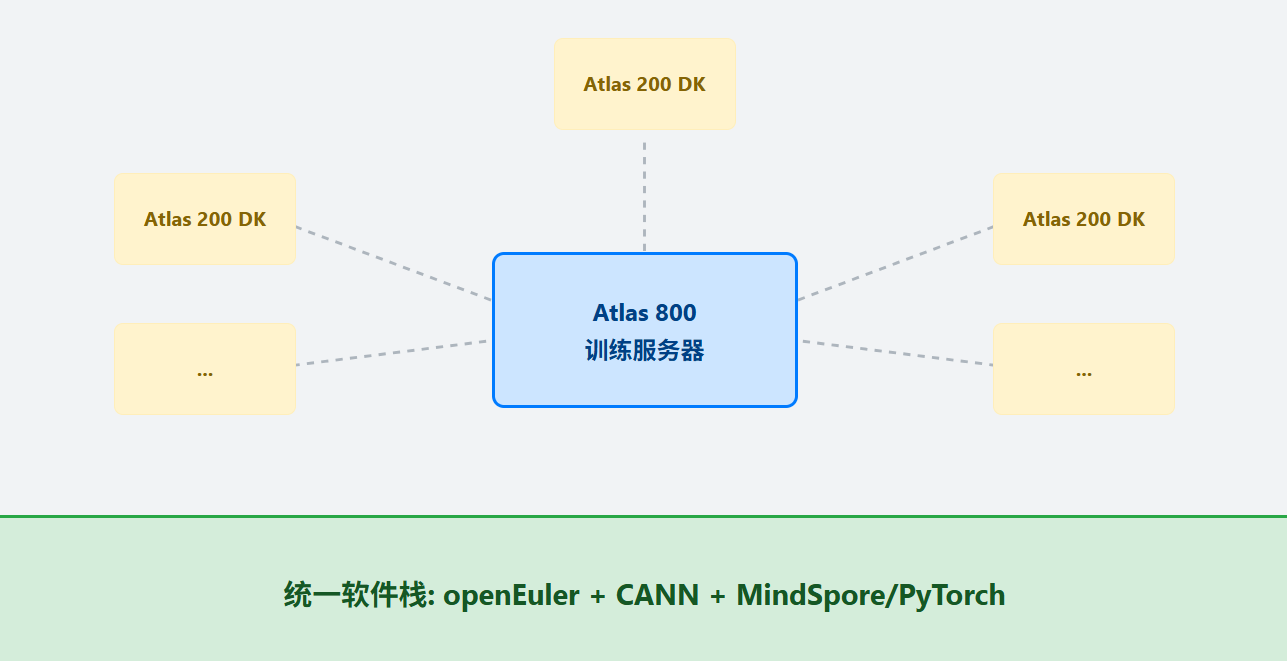
学生端 (边缘): 每个实验小组配备一台 Atlas 200 DK 开发者套件。
平台端 (中心): 实验室配备一台或多台 Atlas 800 训练服务器。
四、课程设计:从入门到精通的 CANN 实验阶梯
基于此平台,我们可以设计一套循序渐进的、覆盖 AI 全栈的课程实验。
4.1 实验一 (入门):端云一致,保证实验的可复现性
目标: 让学生在个人 Atlas 200 DK 上开发一个图像分类应用,并无缝迁移到中心服务器上进行批量推理。
# 1. 教师统一转换模型
atc --model=resnet50.onnx --framework=5 --output=resnet50_ascend --soc_version=Ascend310
# 2. 学生在 Atlas 200 DK 上编写并运行 infer_local.py
import acl
import numpy as np
from PIL import Image
MODEL_PATH = "resnet50_ascend.om"
IMAGE_PATH = "test.jpg"
# 1. 初始化 ACL
acl.init()
acl.rt.set_device(0)
ctx = acl.rt.create_context(0)
# 2. 加载模型
model = acl.mdl.load_from_file(MODEL_PATH)
model_id = model["model_id"]
# 3. 读取并预处理图片
img = Image.open(IMAGE_PATH).resize((224, 224))
img = np.array(img).astype(np.float32)
img = np.expand_dims(img.transpose(2,0,1), 0).copy()
# 4. 推理
output = acl.mdl.execute(model_id, [img])
print("分类结果:", np.argmax(output[0]))
# 5. 资源释放
acl.mdl.unload(model_id)
acl.rt.destroy_context(ctx)
acl.rt.reset_device(0)
acl.finalize()
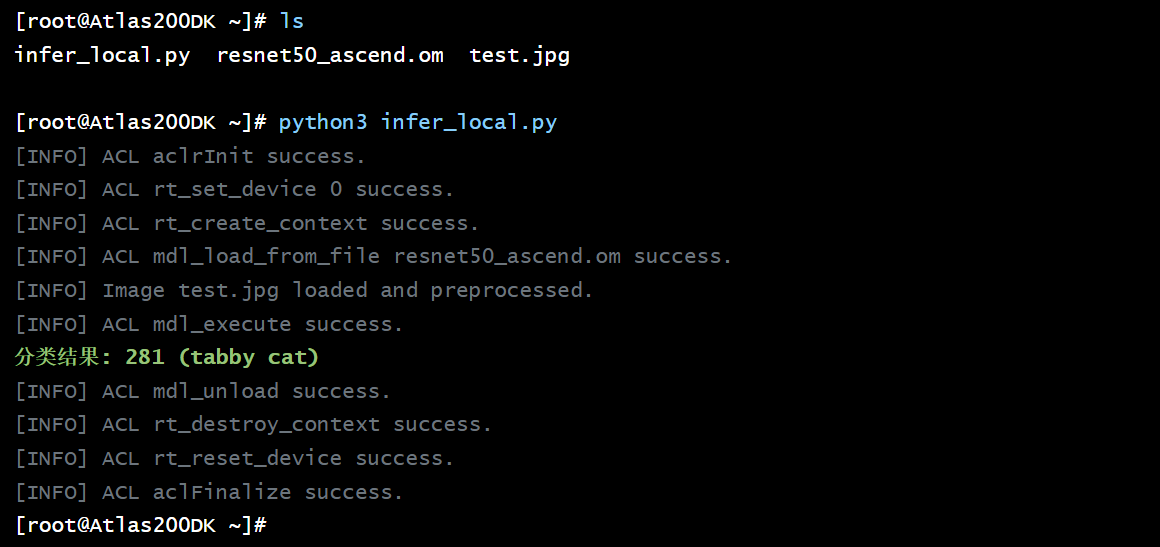
教学效果: 彻底消除了“在我机器上是好的”这一经典难题。学生可以专注于算法逻辑,而非环境调试。
4.2 实验二 (进阶):图执行优化,揭开 AI 框架的“黑盒”
目标: 向学生直观展示图优化 (Graph Fusion) 对性能的巨大影响。
# 使用 Ascend-profiler 分别对优化前后的模型推理过程进行性能画像
ascend-profiler start -p <pid_of_unoptimized_run> ...
# ...
ascend-profiler start -p <pid_of_optimized_run> ...

教学效果: 学生不再将 AI 框架视为黑盒,而是能直观地理解计算图优化这一核心概念。
4.3 实验三 (高阶):自定义算子开发,从调包侠到创造者
目标: 指导学生为一个特殊的激活函数(如 Swish 激活函数 x * sigmoid(x)) 开发一个自定义的昇腾 NPU 算子。
# swish_op.py
from tbe import tik
from math import prod
def swish(shape, dtype="float16", kernel_name="swish"):
tik_inst = tik.Tik()
# GM 区输入 / 输出
x_gm = tik_inst.Tensor(dtype, shape, name="x_gm", scope=tik.scope_gm)
y_gm = tik_inst.Tensor(dtype, shape, name="y_gm", scope=tik.scope_gm)
# UB 缓冲区
x_ub = tik_inst.Tensor(dtype, shape, name="x_ub", scope=tik.scope_ub)
tmp = tik_inst.Tensor(dtype, shape, name="tmp", scope=tik.scope_ub)
sig = tik_inst.Tensor(dtype, shape, name="sig", scope=tik.scope_ub)
numel = prod(shape) # 元素个数
burst = numel // 16 # 简单按 16 对齐,真实工程需按 shape 计算
# 1) 把 x 从 GM 搬到 UB
tik_inst.data_move(x_ub, x_gm, 0, 1, burst, 0, 0)
# 2) 计算 sigmoid(x) = 1 / (1 + exp(-x))
tik_inst.vec_muls(tmp, x_ub, -1.0, numel // 64, 1, 1) # tmp = -x
tik_inst.vec_exp(tmp, tmp, numel // 64, 1, 1) # tmp = exp(-x)
tik_inst.vec_adds(tmp, tmp, 1.0, numel // 64, 1, 1) # tmp = 1 + exp(-x)
tik_inst.vec_rec(sig, tmp, numel // 64, 1, 1) # sig = 1 / tmp
# 3) y = x * sigmoid(x)
tik_inst.vec_mul(y_gm, x_ub, sig, numel // 64, 1, 1, 1)
# 4) 结果写回 GM(示例里直接算到 y_gm 了,可以省一次 data_move)
# tik_inst.data_move(y_gm, y_ub, 0, 1, burst, 0, 0)
tik_inst.BuildCCE(kernel_name=kernel_name,
inputs=[x_gm], outputs=[y_gm])
return tik_inst
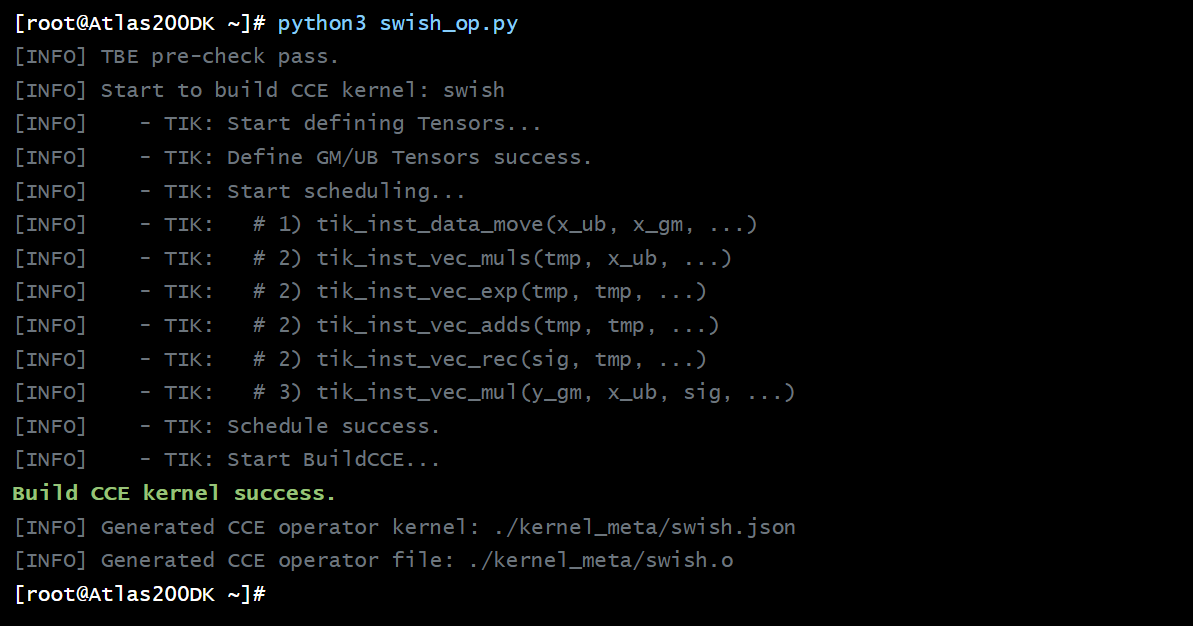
教学效果: 引导学生深入到 AI 计算的最底层,理解数据搬运、片上计算和并行编程等核心概念,为培养顶尖的 AI 系统人才打下坚实基础。
4.4 新增实验 (科研级):AscendCL + C++ 实现高性能推理服务
目标: 摆脱 Python GIL 的束缚,用 C++ 和 AscendCL 开发一个多线程、高吞吐的推理服务器,服务于科研项目。
// server.cpp (示意代码)
#include <thread>
#include "acl/acl.h"
void worker_thread(int deviceId, Model& model) {
aclrtSetDevice(deviceId); // 线程绑定 NPU 设备
aclrtContext context;
aclrtCreateContext(&context, deviceId); // 线程独占上下文
while (true) {
// 从任务队列获取图片
Image img = task_queue.pop();
// 异步执行推理
model.ExecuteAsync(img.data, stream);
// ...
}
}
int main() {
// ... 加载模型 ...
std::thread t1(worker_thread, 0, model);
std::thread t2(worker_thread, 0, model); // 在同一 NPU 上启动多线程
t1.join();
t2.join();
}
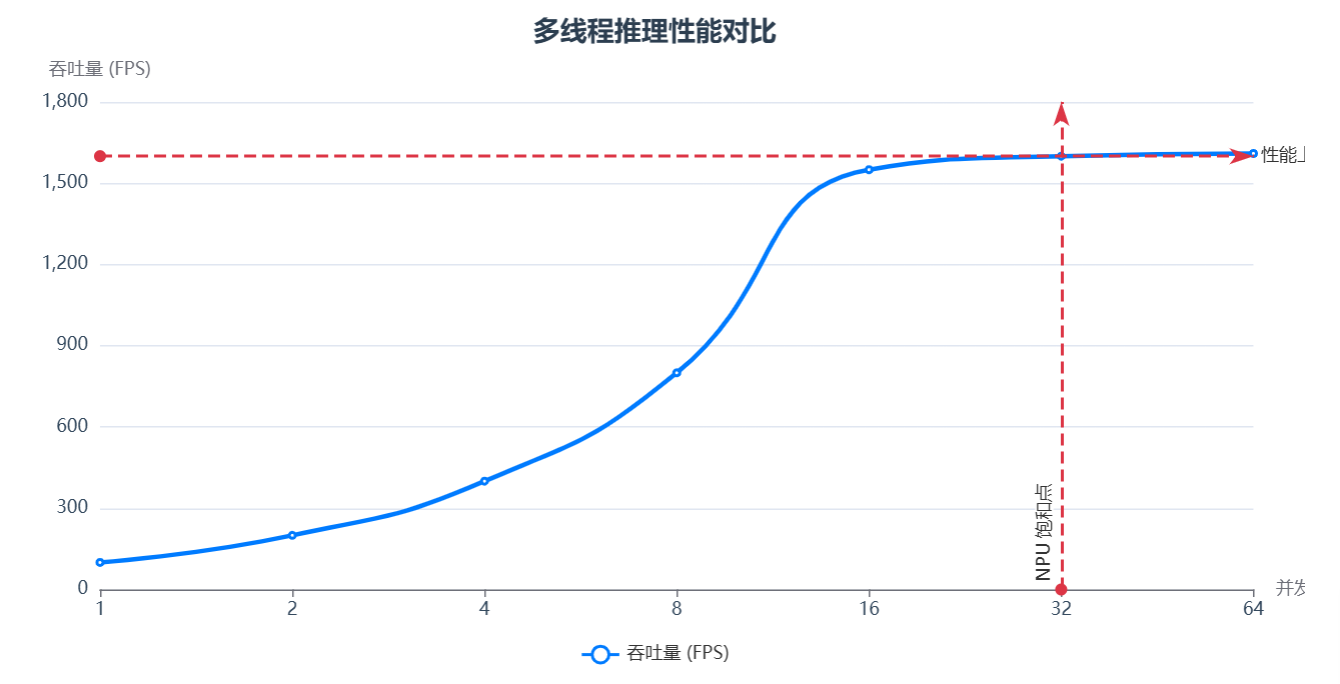
科研价值: 对于追求极致性能的科研场景,C++ 和 AscendCL 的组合提供了最大的优化空间。
五、超越课程:CANN 社区与开源贡献
一个优秀的教学平台,还应该能引导学生参与到真实的开源社区中。
5.1 CANN 开源社区
CANN 的许多组件,包括算子库和工具,都在 Gitee 等平台开源。Gitee 地址: gitee.com/ascend
5.2 新增实验 (社区贡献级):为开源算子库贡献代码
目标: 引导学生参与 CANN 开源社区,为一个现有的开源算子(如 nn.GELU)增加一个新的功能或性能优化,并提交 Pull Request。
# 1. Fork 并 Clone CANN 开源仓
git clone https://gitee.com/ascend/CANN.git
# 2. 找到 GELU 算子的 TBE 实现源码
# (在 /tbe/impl/gelu.py)
# 3. 修改代码,例如增加一种新的近似计算方法
# 4. 在本地编译并运行单元测试,验证修改的正确性
# 5. 提交 Pull Request 到社区
育人价值: 这不仅是技术锻炼,更是对学生开源协作精神和工程能力的培养。
六、总结:CANN 实验平台的核心优势
| 维度 | 传统平台方案 (e.g., CUDA + GPU) | CANN 实验平台方案 |
|---|---|---|
| 硬件成本 | 较高,生均算力有限 | 高性价比,可通过边缘+中心组合降低生均成本 |
| 环境一致性 | 较差,依赖驱动、CUDA 版本,迁移困难 | 极佳,端云统一 CANN 软件栈,零修改迁移 |
| 语言支持 | 以 Python 为主,C++ 门槛高 | 灵活,同时支持 Python 快速开发和 C++ 高性能开发 |
| 社区参与 | 社区庞大,但贡献门槛高 | 友好,社区积极引导,提供从应用到算子的贡献路径 |
七、结论:CANN,点燃 AI 教育与科研的星星之火
基于 CANN 的实验平台,凭借其:
- 高性价比的硬件选择,有效解决了生均算力不足的问题。
- 端云一致的软件架构,保证了实验的稳定性和可复现性。
- 开放透明的底层能力,为学生从“使用者”成长为“创造者”提供了可能。
- 清晰的社区贡献路径,将教学与真实的开源世界紧密相连。
成功地克服了传统教学科研平台的核心痛点。它不仅是一个让学生跑通实验的平台,更是一个启发他们去探索、去优化、去创造、去贡献的AI 孵化器。通过 CANN,高校可以培养出真正理解硬件、懂得系统优化的新一代 AI 人才,点燃未来人工智能创新的星星之火

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐
 18
18 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)